通过JDBC驱动/Python boto3 SDK调用Athena查询数据
本文详细介绍如何通过JDBC驱动和Python SDK连接AWS Athena进行数据查询。涵盖SQL Workbench J配置、IAM权限设置、JDBC连接参数、boto3和pyathenajdbc库的使用方法,解决了跨平台数据查询的集成问题。
一、通过JDBC使用SQL Workbench J工具连接
从官网下载:https://www.sql-workbench.eu/downloads.html
注意,运行环境需要Java。
1、下载Athena的JDBC驱动
从官网下载:https://docs.aws.amazon.com/athena/latest/ug/connect-with-jdbc.html
2、配置驱动
启动SQL Workbench J,点击Connection Profile左下角的 Manage Drives 按钮。如下截图。
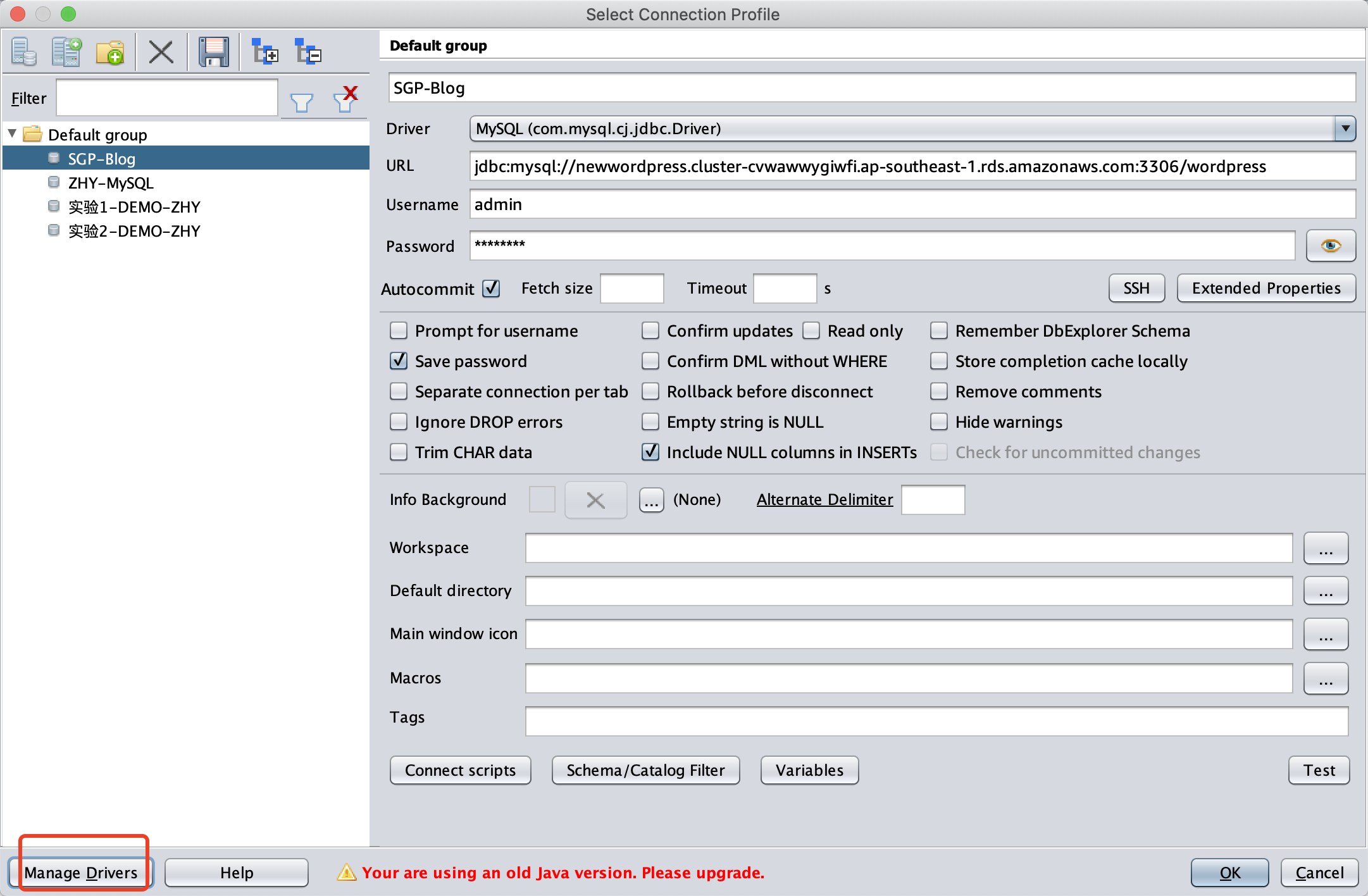
点击右上角的新建按钮。如下截图。
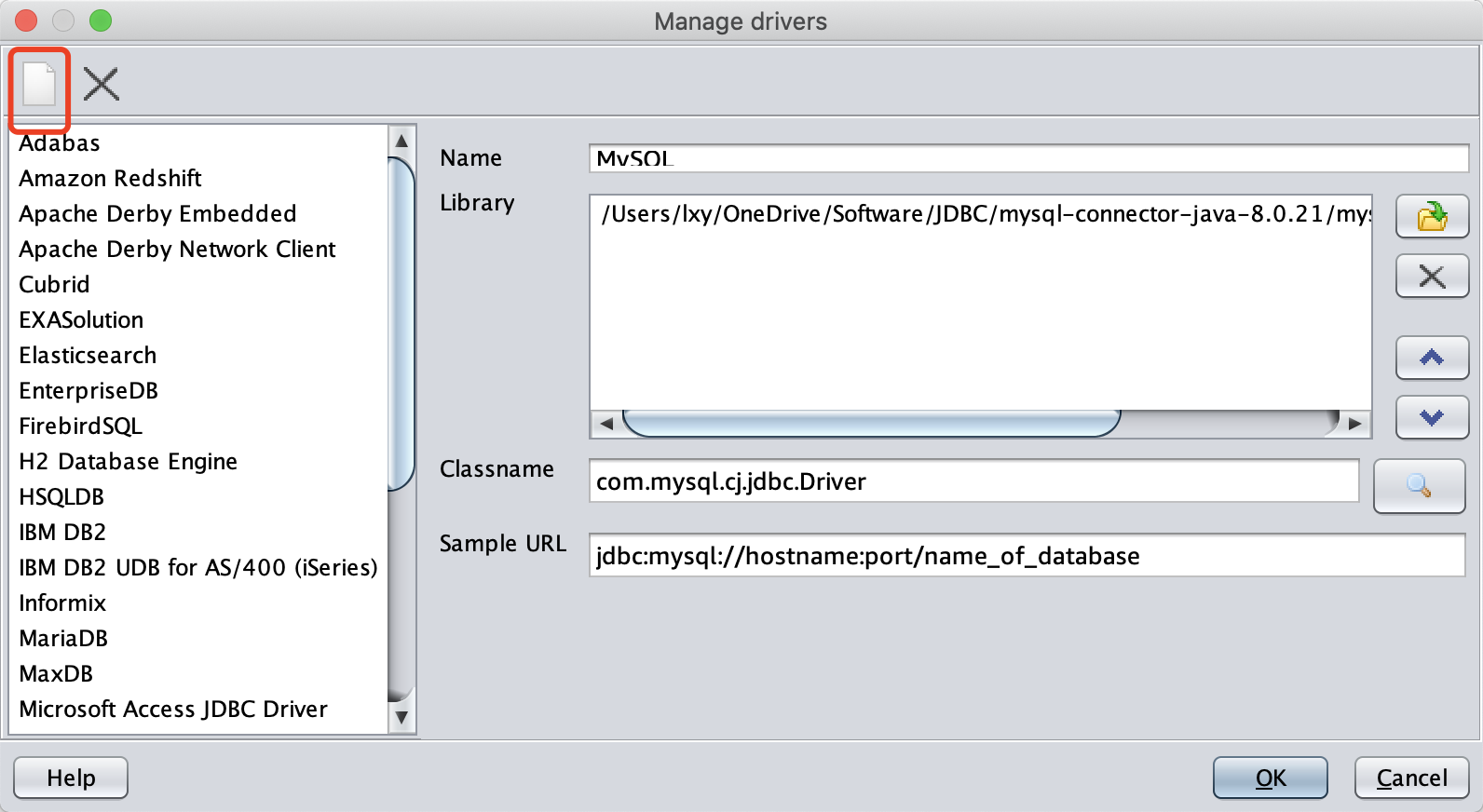
在弹出的新建界面,Name填写为Athena,Library请选择JDBC文件下载后保存的路径,Classname会自动生成,在Sample URL请给手工填写为jdbc:awsathena://AwsRegion=cn-northwest-1; 。如下截图。
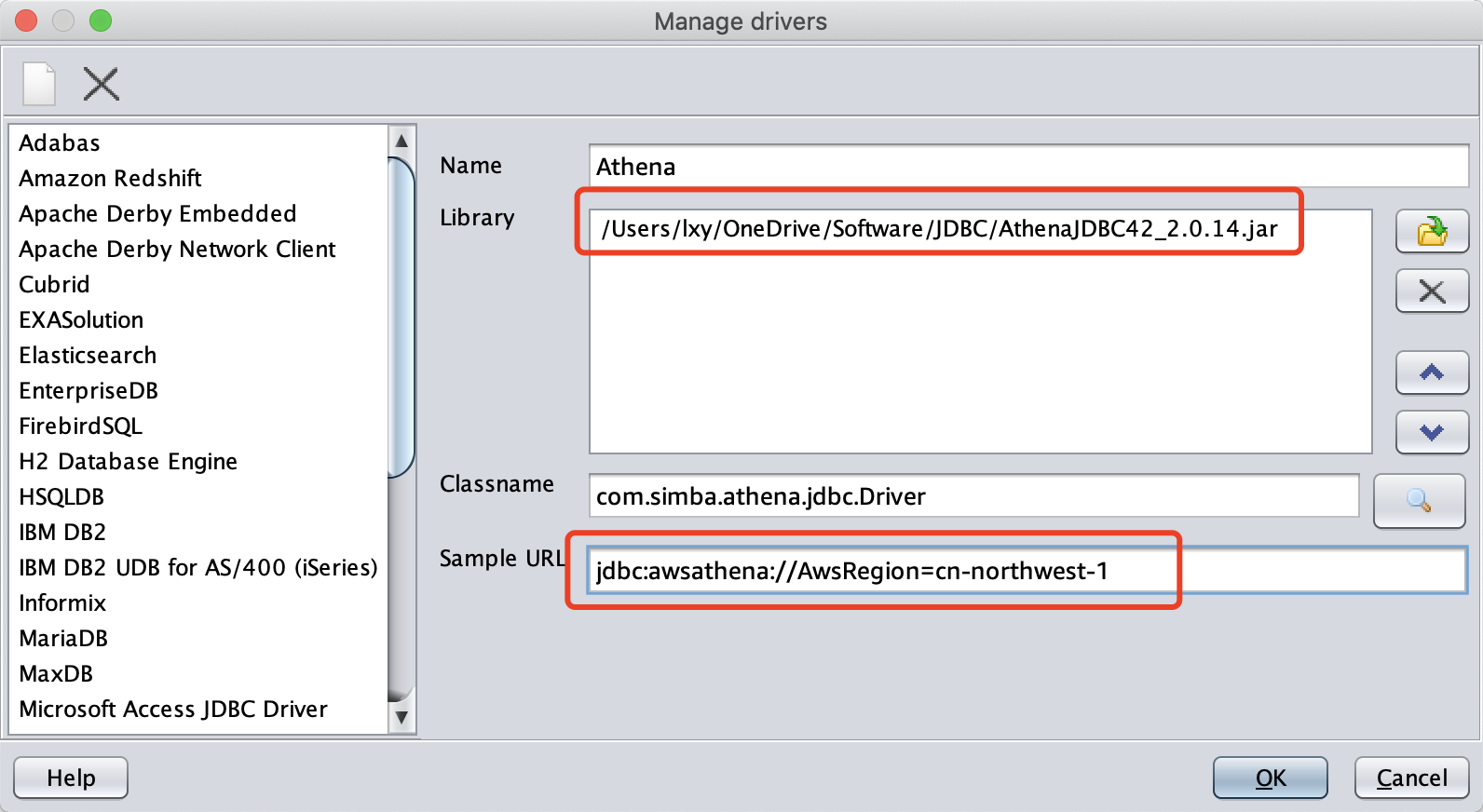
输入完成后,点击OK,即可创建新的驱动。
二、生成Athena需要使用的API访问账号和密钥
本步骤需要新建两个IAM策略,再新建一个用户,并绑定这两个策略,然后为这个用户生成API使用的Access Key和Secret Password。
1、新建数据桶S3访问策略
假设要查询的数据存放在S3桶 athena-stock-emr-convert-01中。
进入IAM模块,点击左侧菜单策略(Policy),点击新建,点击 JSON,进入配置编辑器界面。
删除掉页面内现有的的代码,重新填写如下代码,并替换Resouce字段中的存储桶的名字为实际的名字。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": [
"arn:aws-cn:s3:::athena-stock-emr-convert-01/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws-cn:s3:::athena-stock-emr-convert-01"
]
}
]
}
保存策略,并且记录下本Policy的名称。
2、新建查询结果桶S3的访问策略
假设要查询的数据存放在S3桶 athena-stock-demo-result-01中。
进入IAM模块,点击左侧菜单策略(Policy),点击新建,点击 JSON,进入配置编辑器界面。
删除掉页面内现有的的代码,重新填写如下代码,并替换Resouce字段中的存储桶的名字为实际的名字。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": [
"arn:aws-cn:s3:::athena-stock-demo-result-01/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws-cn:s3:::athena-stock-demo-result-01"
]
}
]
}
保存策略,并且记录下本Policy的名称。
3、创建用户
进入IAM模块,点击左侧菜单用户(Users),点击新建用户,在username位置输入athena,在访问类型的位置,选择 编程接口 Programmatic access,并点击下一步继续。如下截图。
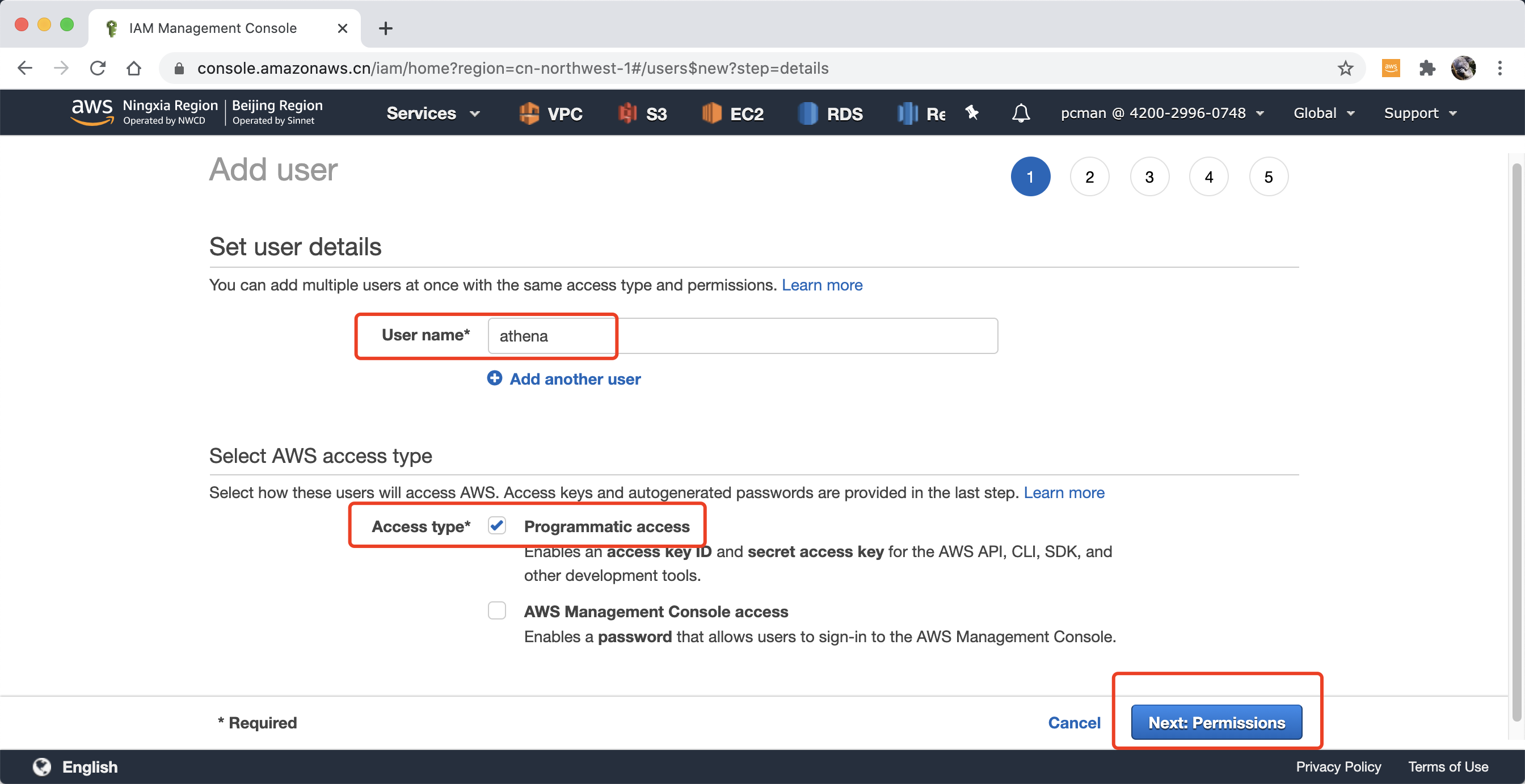
在设置权限界面,选择。如下挂载现有权限,然后从搜索框中查询关键字Athena,选中两个系统内置的规则,分别叫做AWSQuicksightAthenaAccess和AmazonAthenaFullAccess。此外,上一个步骤自定义的2的两个策略分别是对于数据存放的桶和查询结果桶的策略,也要绑定上。一共绑定4条策略。点击下一步继续。如下截图。
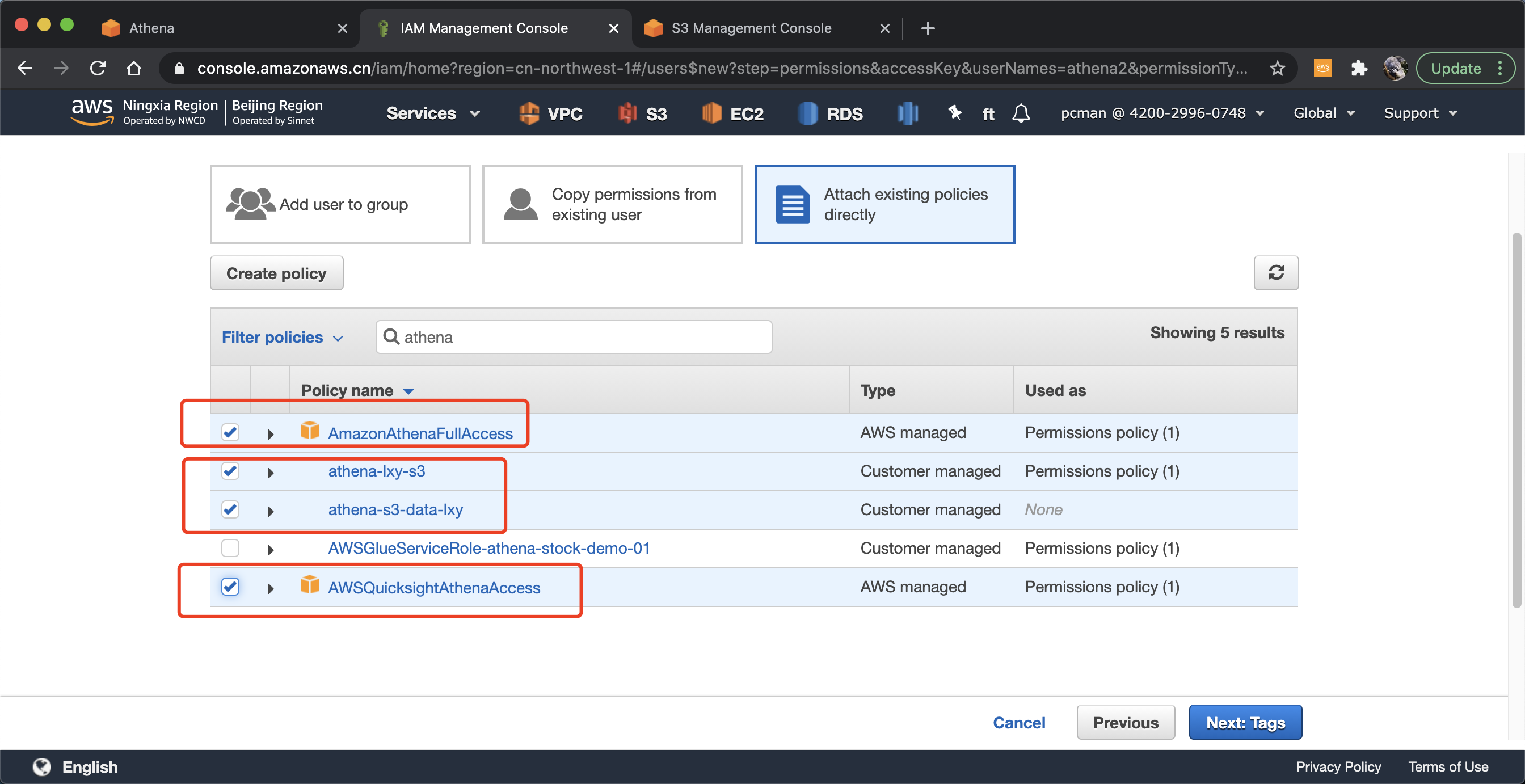
最后一个步骤,记录下本IAM用户对应的Access key和密码。注意,这个密码只能显示一次,需要复制下来妥善保管。如下截图。
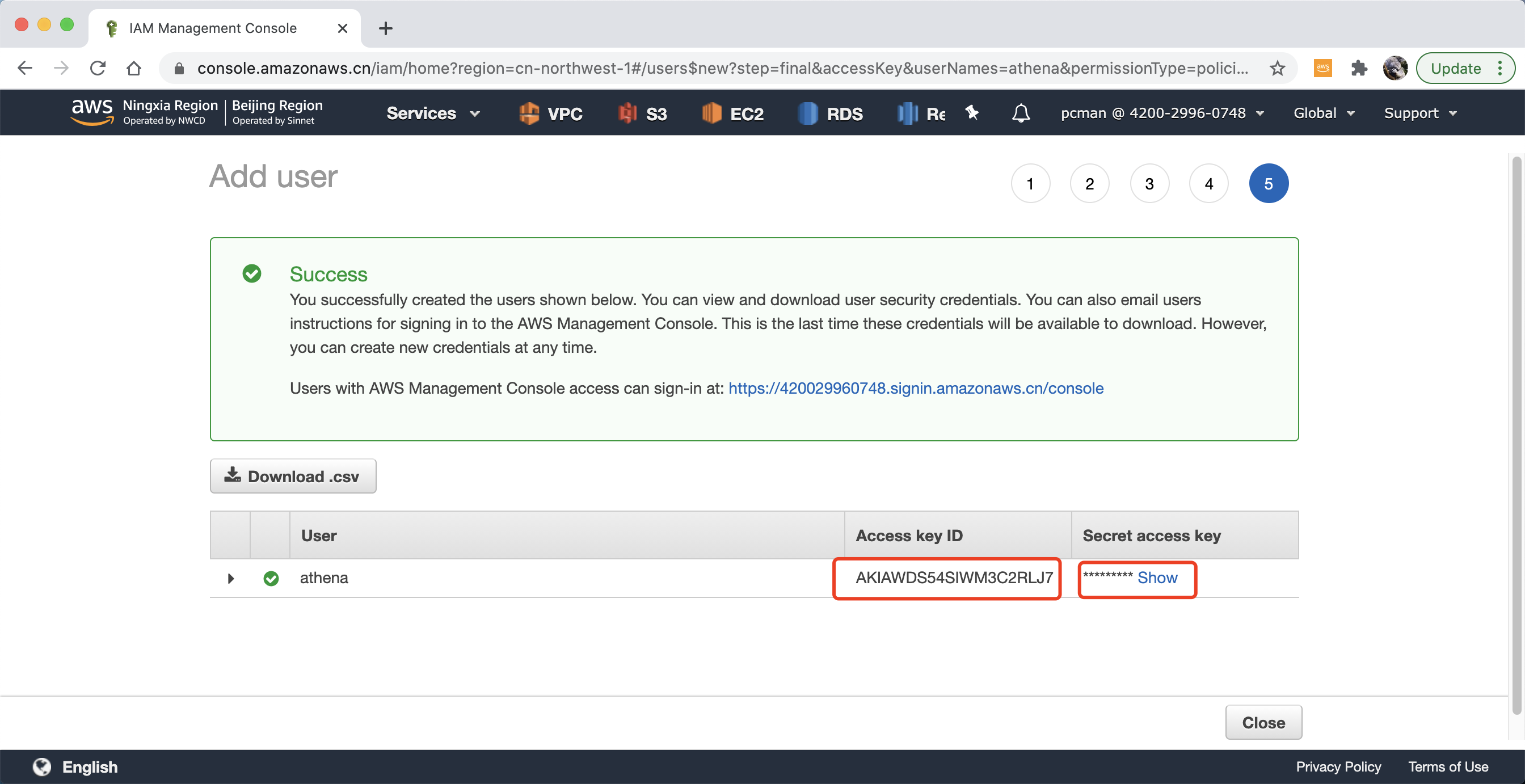
注意,这个密码只能显示一次,需要复制下来妥善保管。
三、使用JDBC连接到Athena
在开始使用JDBC和SQL Workbench/J查询之前,请确认已经通过AWS Console控制台的图形界面,配置了Glue爬虫,正确的识别了S3上的数据结构,并在Athena中建立了数据表。如果Athena中没有事先建立数据表,则本文后续操作无法使用。因此本文档适合已经在AWS控制台上正常使用Athena的用户,从AWS控制台访问切换到程序通过JDBC访问的场景。
在Connection管理器的界面,点击左上角第一个按钮,新建连接。如下截图。
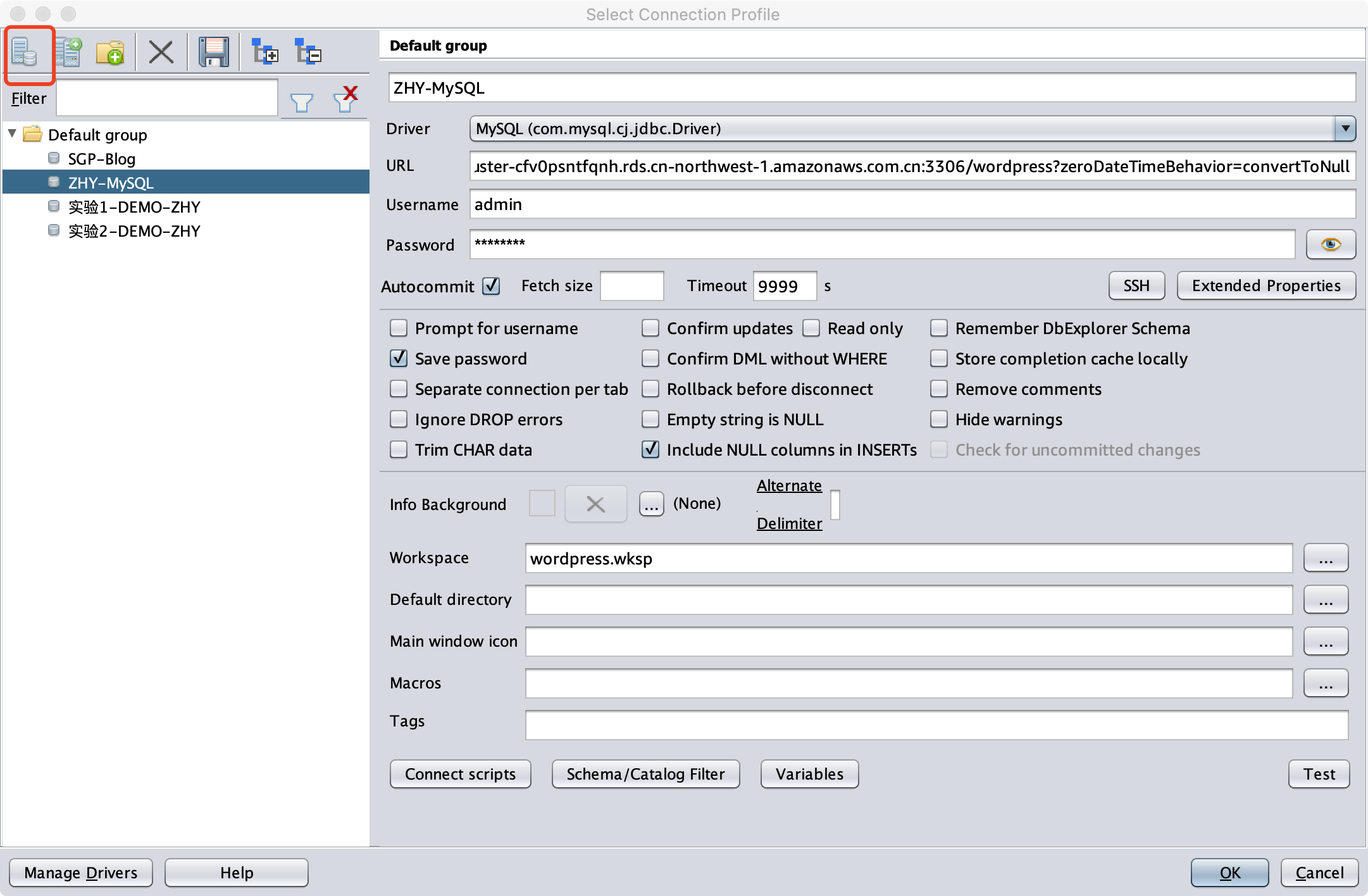
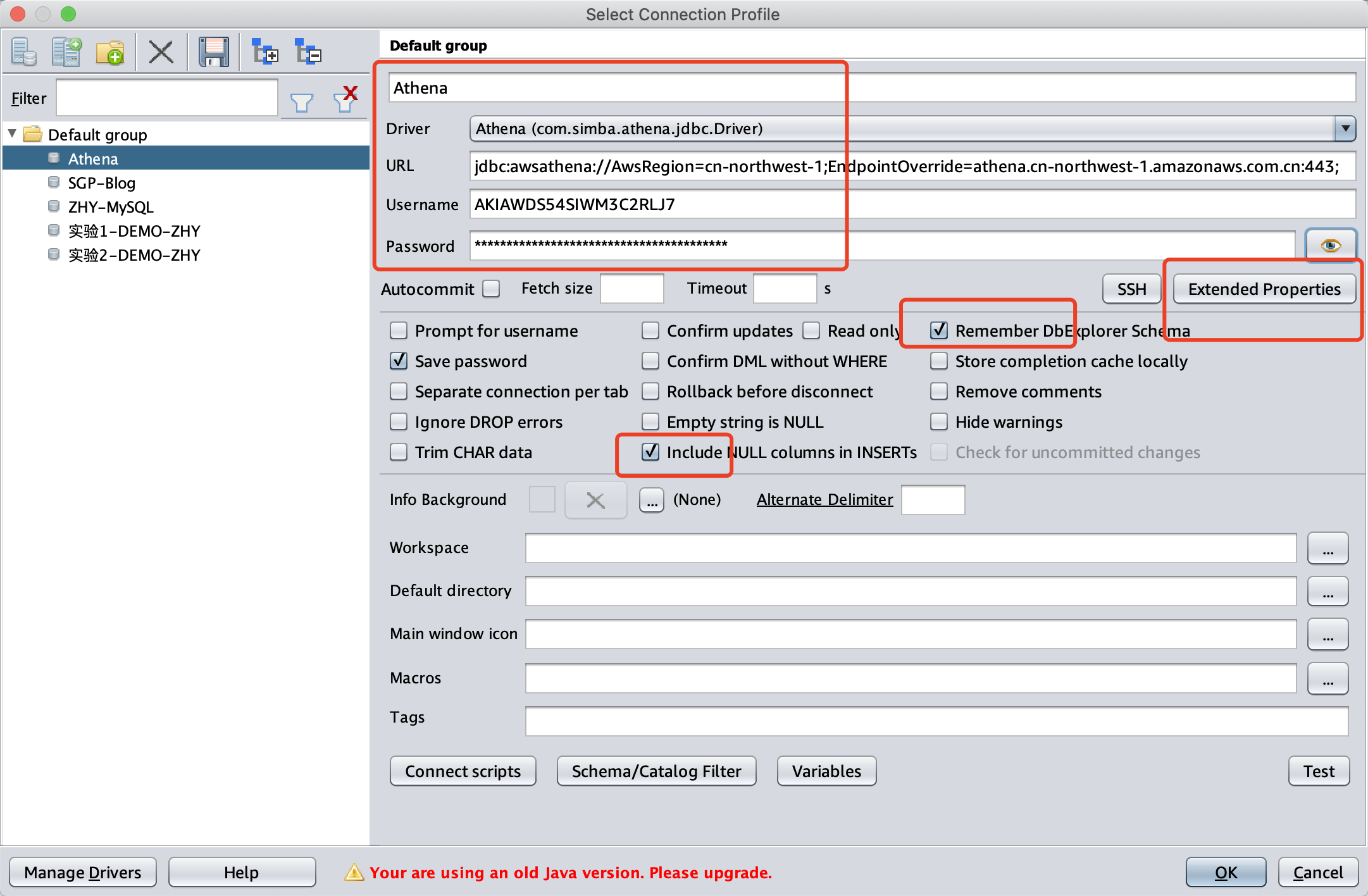
输入名称,选择Driver是Athena,URL输入如下信息:
jdbc:awsathena://AwsRegion=cn-northwest-1;EndpointOverride=athena.cn-northwest-1.amazonaws.com.cn:443;
继续配置,输入Access Key到Username位置,输入Secret Key到Password位置,然后点击下图中的Extended Properties 的选项,输入额外连接参数。在复制密码时候需要注意,MacOS的版本上的SQL Workbench/J需要按CTRL+V才能粘贴,而不是Command+V,请注意快捷键。如下截图。
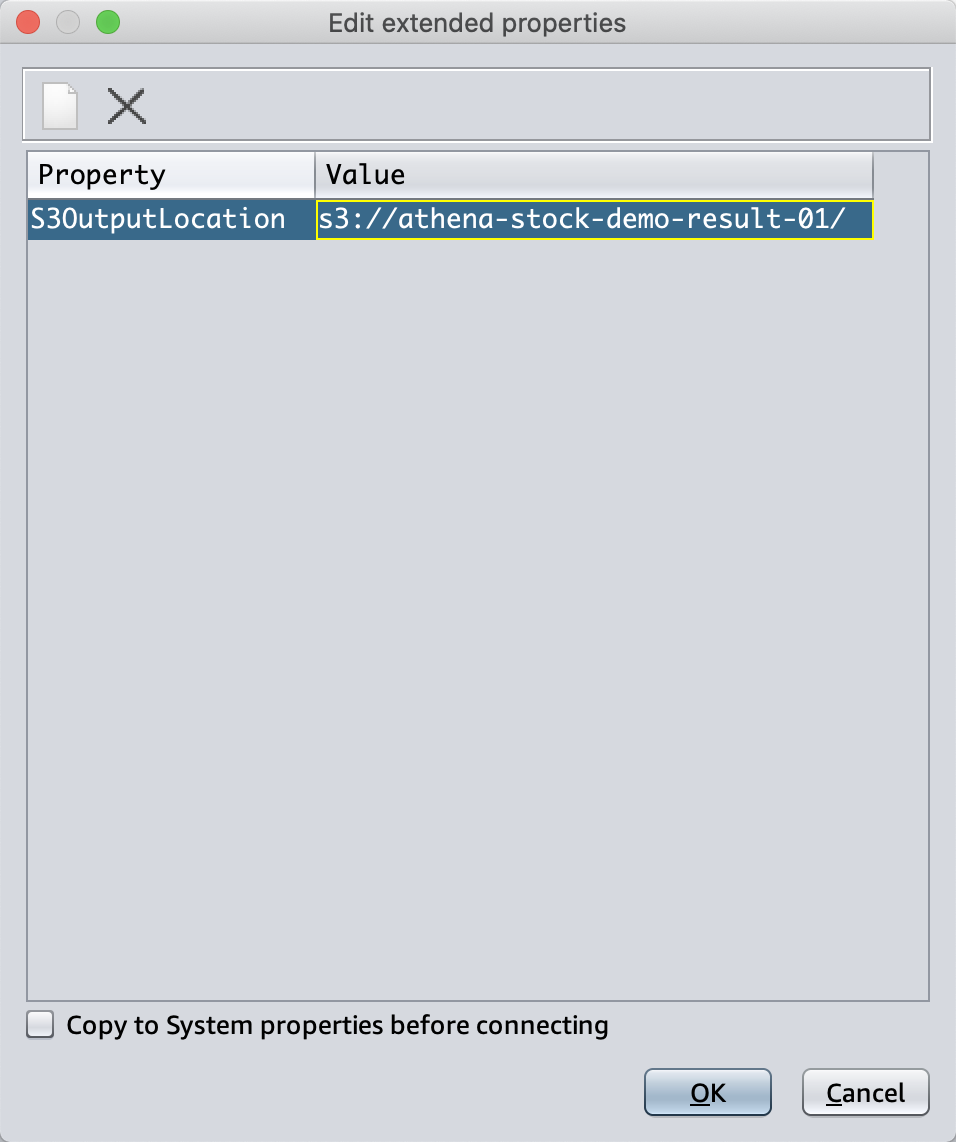
在额外连接参数界面,点击空白出,并输入如下的额外参数,Property输入S3OutputLocation,参数值位置输入s3://athena-stock-demo-result-01/ 。注意这个存储桶不是原始数据所在的桶,而是存放查询结果的桶。点击OK继续。如下截图。
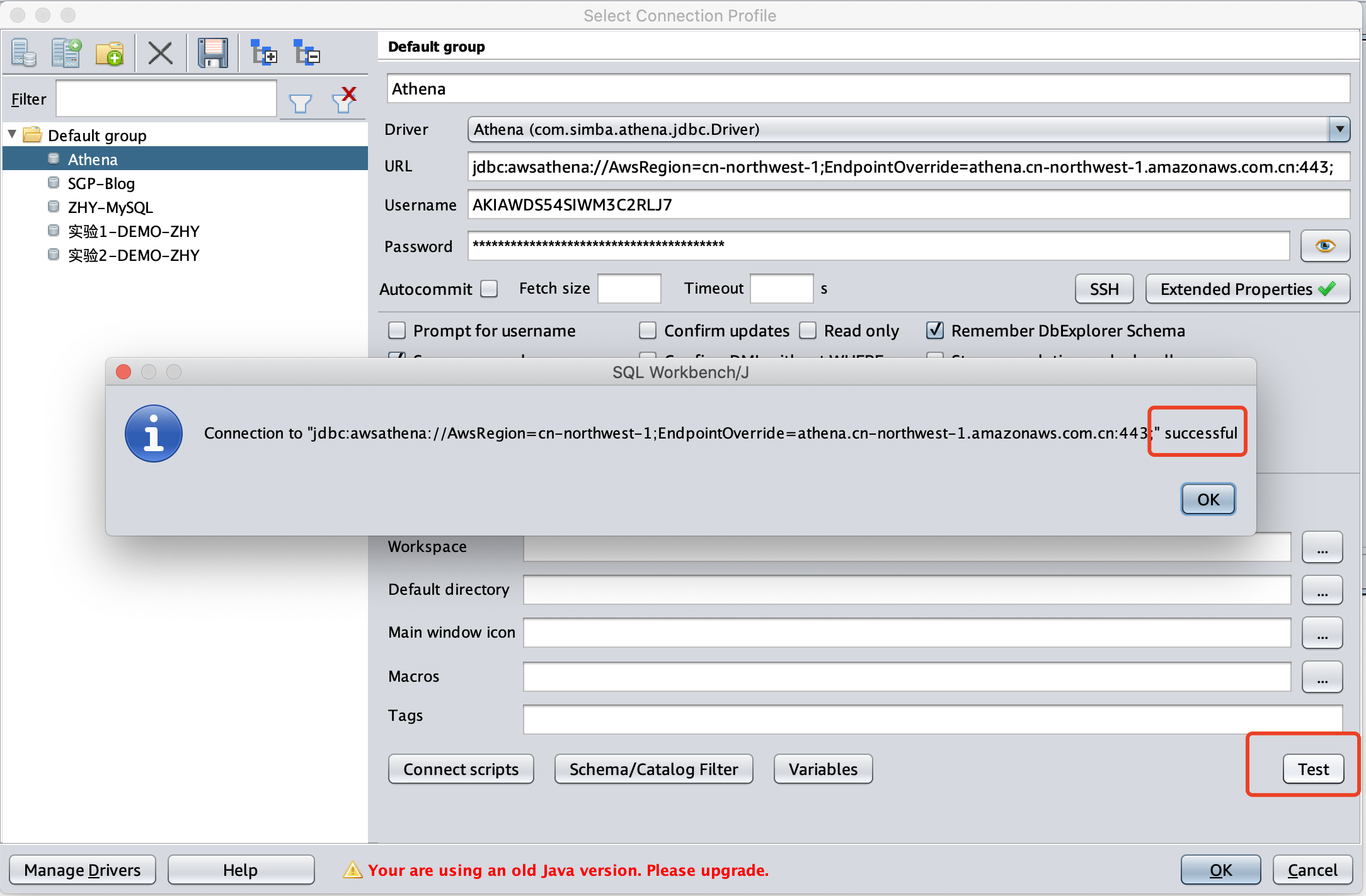
返回到连接参数界面,点击Test按钮测试连接,可以看到连接成功。
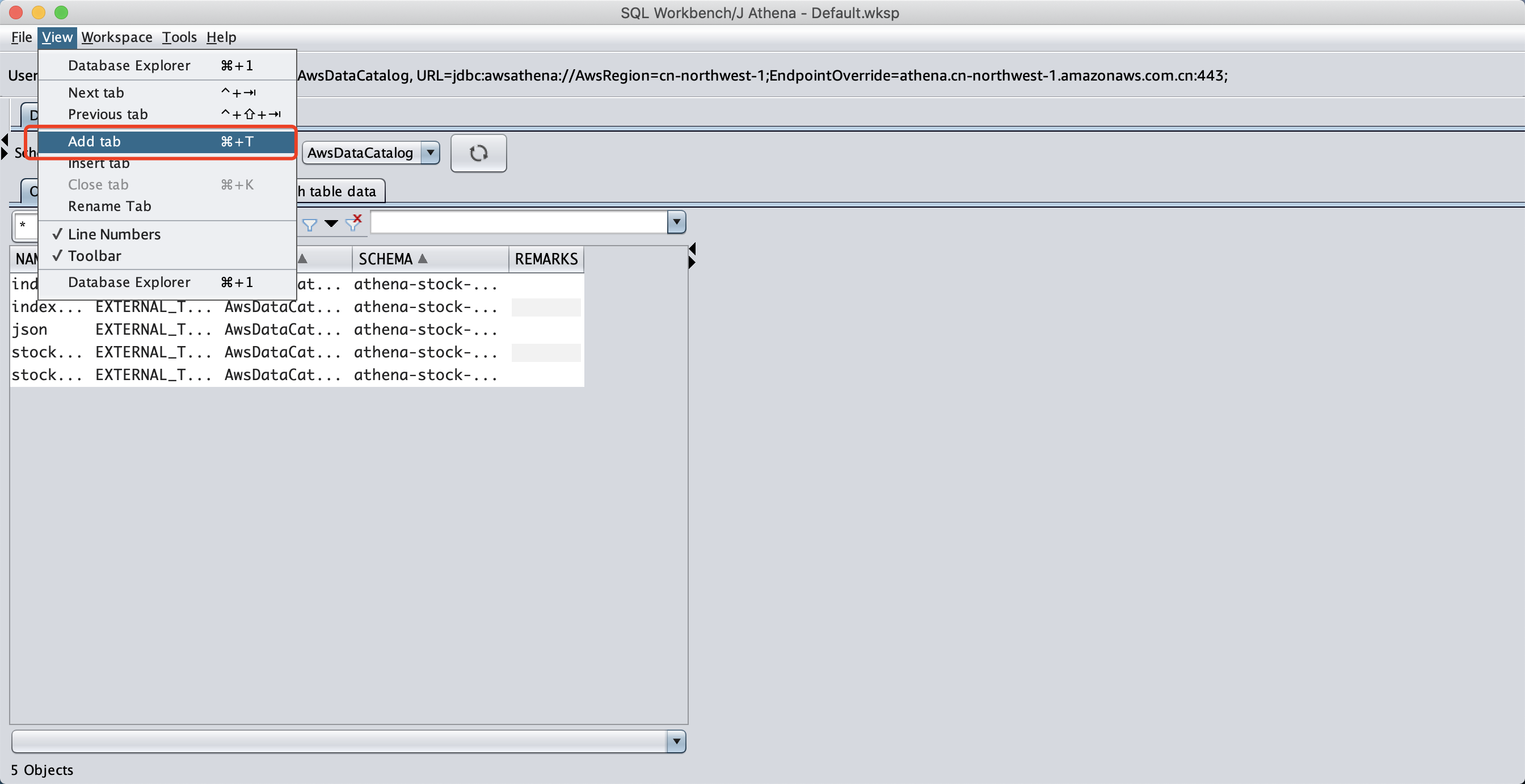
点击标题栏的View,在点击 Add Tab,即可打开查询窗口。如下截图。
在查询界面,点击左上角的小窗口,可看到External_Table的选项,选中后,左侧的菜单即可出现表名。然后在右侧输入要执行的查询。
SELECT * FROM "athena-stock-demo".stock_day where ticker='000300' ORDER by tradedate DESC limit 10;
查询结果如下。
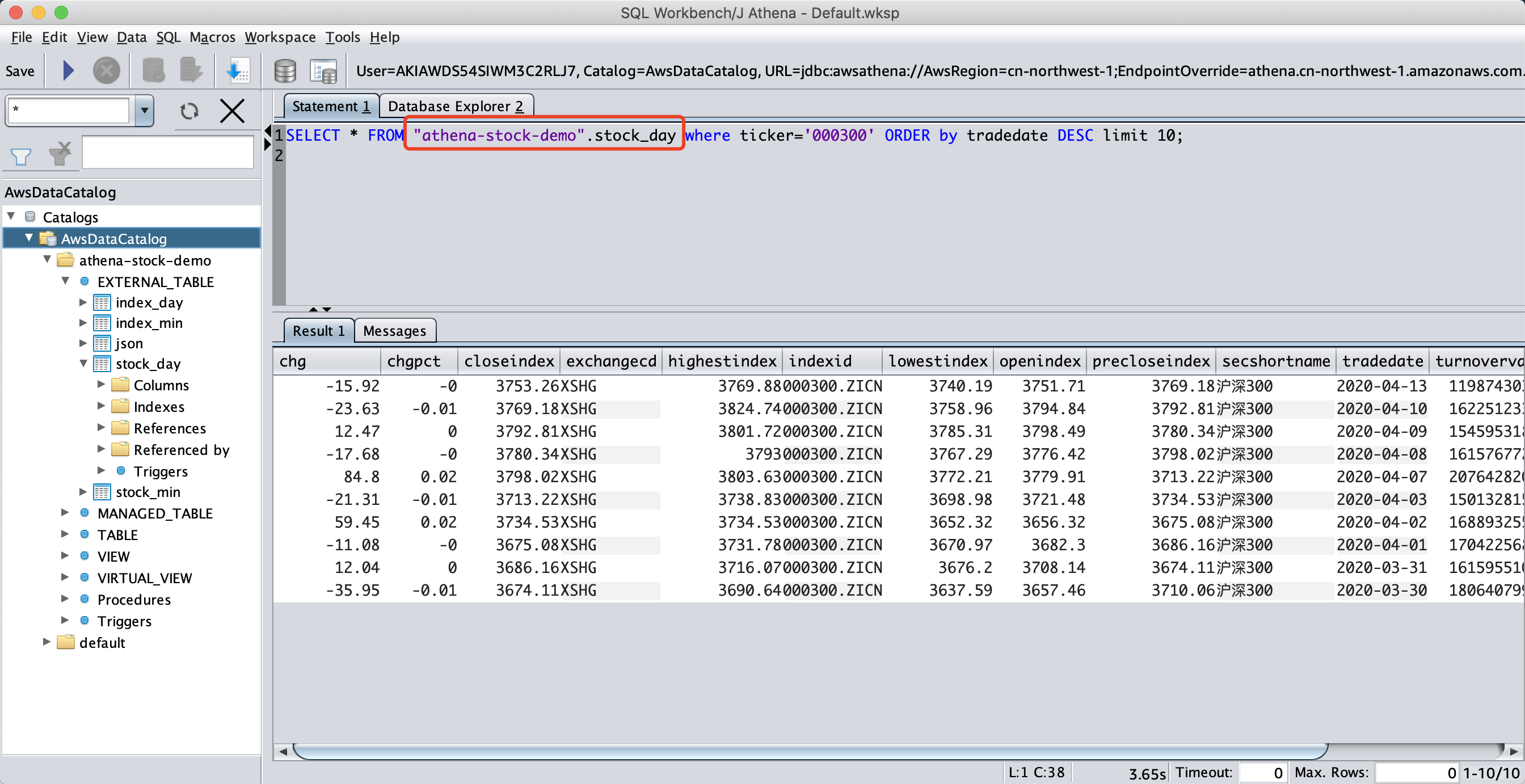
可以看到Athena查询正常返回了结果。
四、使用Python3 boto3库
实例代码如下:
import boto3
import pandas
import time
import csv
import athena_from_s3
import S3_cleanup
params = {
'region': 'ap-southeast-1',
'database': 'mydatabase',
'bucket': 'athena-test-buck',
'path': 'temp/athena/output',
'query': 'SELECT * FROM "mydatabase"."zipcode" limit 10;'
}
session = boto3.Session()
## Fucntion for obtaining query results and location
location, data = athena_from_s3.query_results(session, params)
print("Locations: ",location)
print("Result Data: ")
print(data)
## Function for cleaning up the query results to avoid redundant data
S3_cleanup.clean_up()
五、使用Python3 JDBC库
实例代码如下:
import os
import configparser
import pyathenajdbc
# Get aws credentials
aws_config_file = '~/.aws/credentials'
Config = configparser.ConfigParser()
Config.read(os.path.expanduser(aws_config_file))
access_key_id = Config['CONFIG-FILE']['aws_access_key_id']
secret_key_id = Config['CONFIG-FILE']['aws_secret_access_key']
class PyAthenaLoader():
def connect(self):
self.conn = pyathenajdbc.connect(
s3_staging_dir="YOUR-OUTPUT-S3-TABLE-NAME",
access_key=access_key_id,
secret_key=secret_key_id,
region_name="REGION-NAME"
)
def query(self, req):
self.connect()
try:
with self.conn.cursor() as cursor:
cursor.execute(req)
res = cursor.fetchall()
except Exception as X:
return X
finally:
self.conn.close()
return res
athena = PyAthenaLoader()
print(athena.query('SELECT * FROM DATABASE.TABLE LIMIT 5;'))
六、参考文档
最后修改于 2021-07-14