使用Aurora Babelfish的Single-DB和Multi-DB模式在T-SQL和PostgreSQL之间共享数据
演示Aurora Babelfish在Single-DB和Multi-DB模式下,如何通过T-SQL和PL/pgSQL接口实现数据共享。解决了SQL Server与PostgreSQL之间的数据互通问题,详解两种模式的映射关系和实现方式。
本文在AWS宁夏区Aurora PostgreSQL 15.3版本上测试通过。
一、背景
1、关于Babelfish
Aurora Babelfish通过Babelfish在TCP 1433端口上提供了对T-SQL(即SQL Server)的兼容。Aurora Babelfish的底层实现是PostgreSQL,工作在TCP协议5432端口,使用PL/pgSQL。因此,可以实现数据通过某一个接口写入,然后即可被任意接口读取的场景。
本文将演示Aurora Babelfish工作在Single-DB和Multi-DB两种配置下,如何在T-SQL和PL/pgSQL之间共享数据。
2、Single-DB和Multi-DB两种配置的映射关系介绍
创建过程中,当打开了Babelfish后,在创建Aurora界面会提示选择数据库类型。如下截图。
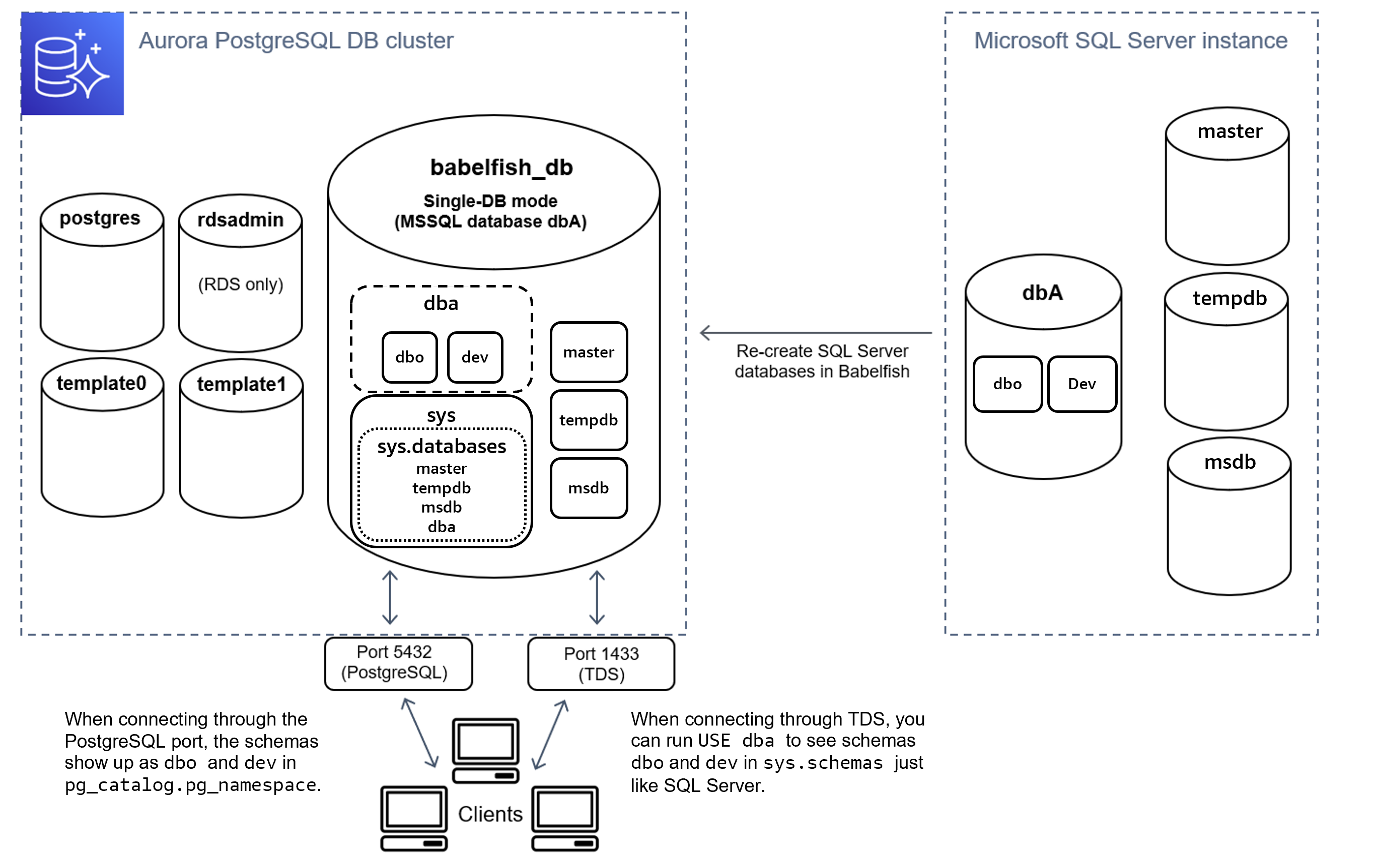
Single-DB架构如下:
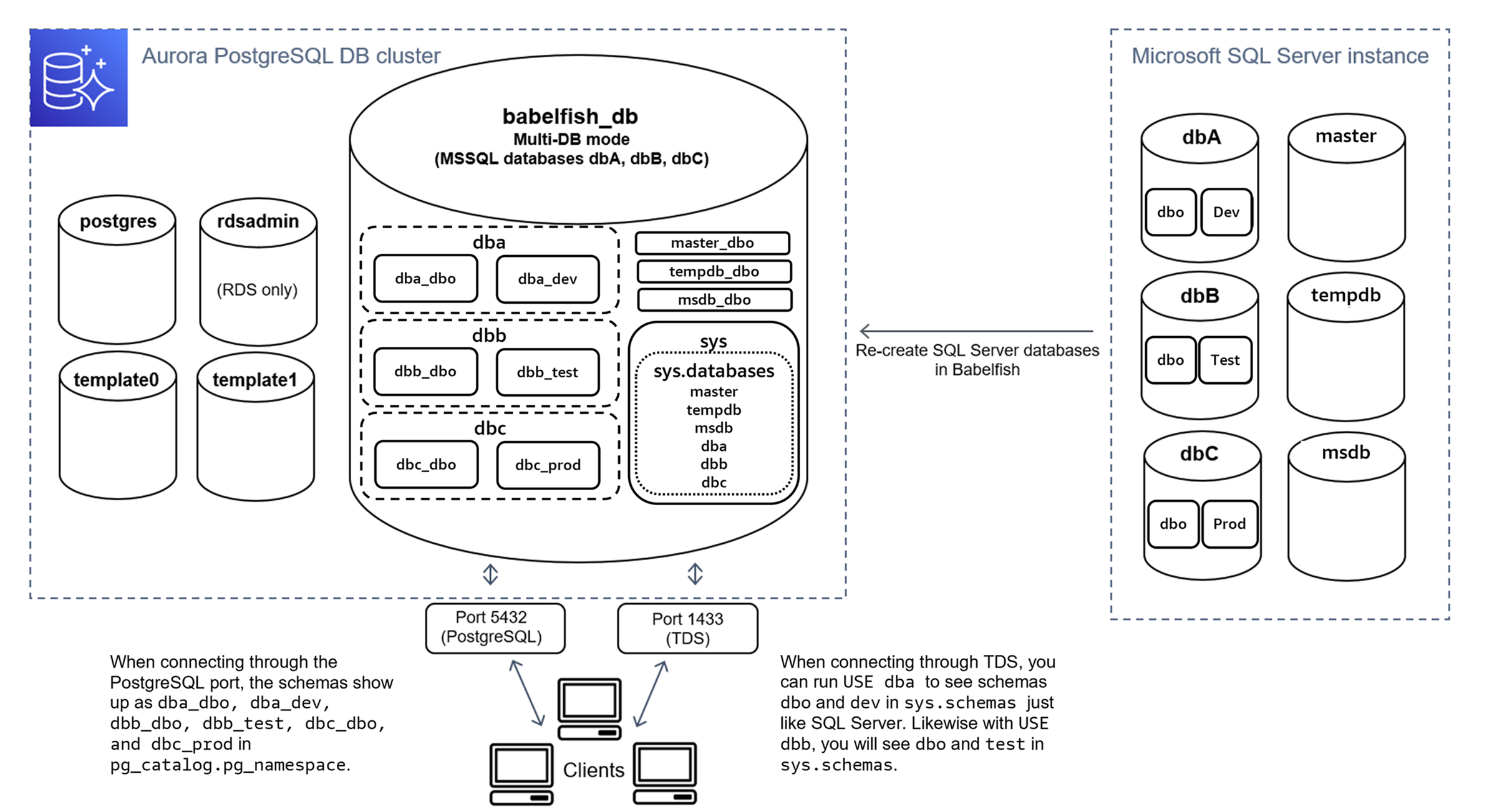
Multi-DB架构如下:
这两个选项的作用是指SQL Server的使用场景是单个SQL Server数据库还是多个SQL Server数据库。不管选择哪一个模式,SQL Server兼容的T-SQL接口和PostgreSQL兼容的PL/pgSQL接口都将同时可用。
两个模式之间,主要是用于SQL Server的T-SQL接口和用于PostgreSQL的PL/pgSQL接口之间的映射关系是不一样的:
- 当使用Single-DB模式时候,Babelfish将SQL Server上创建的单个数据库
dbA下Schema为dbo内的数据表xxx,映射为babelfish_db数据库上Schema为dbo下的数据表xxx; - 当使用 Multi-DB模式时候,Babelfish将SQL Server上创建的多个数据库
dbA下Schema为dbo内的数据表xxx1、以及dbB下Schema为dbo内的数据表xxx1,映射为babelfish_db数据库上Schema为Schemadba_dbo下的数据表dba_dbo.xxx1,以及Schema为dbb_dbo下的数据表dbb_dbo.xxx2。
本文接下来将分别演示这两种场景。
二、Single-DB的使用
1、通过T-SQL接口创建数据库、表并插入数据
首先连接到T-SQL接口。本文使用SQL Server Management Studio(SSMS)完成。连接时候使用默认参数。如下截图。
连接成功后,开始创建库:
USE master
GO
IF NOT EXISTS (
SELECT name
FROM sys.databases
WHERE name = N'TutorialDB'
)
CREATE DATABASE [TutorialDB]
GO
创建表:
USE [TutorialDB]
-- Create a new table called 'Customers' in schema 'dbo'
-- Drop the table if it already exists
IF OBJECT_ID('dbo.Customers', 'U') IS NOT NULL
DROP TABLE dbo.Customers
GO
-- Create the table in the specified schema
CREATE TABLE dbo.Customers
(
CustomerId INT NOT NULL PRIMARY KEY, -- primary key column
Name [NVARCHAR](50) NOT NULL,
Location [NVARCHAR](50) NOT NULL,
Email [NVARCHAR](50) NOT NULL
);
GO
插入数据:
-- Insert rows into table 'Customers'
INSERT INTO dbo.Customers
([CustomerId],[Name],[Location],[Email])
VALUES
( 1, N'Orlando', N'Australia', N''),
( 2, N'Keith', N'India', N'keith0@adventure-works.com'),
( 3, N'Donna', N'Germany', N'donna0@adventure-works.com'),
( 4, N'Janet', N'United States', N'janet1@adventure-works.com')
GO
查询数据:
-- Select rows from table 'Customers'
SELECT * FROM dbo.Customers;
由此可以看到,创建表、数据插入、查询成功。如下截图。
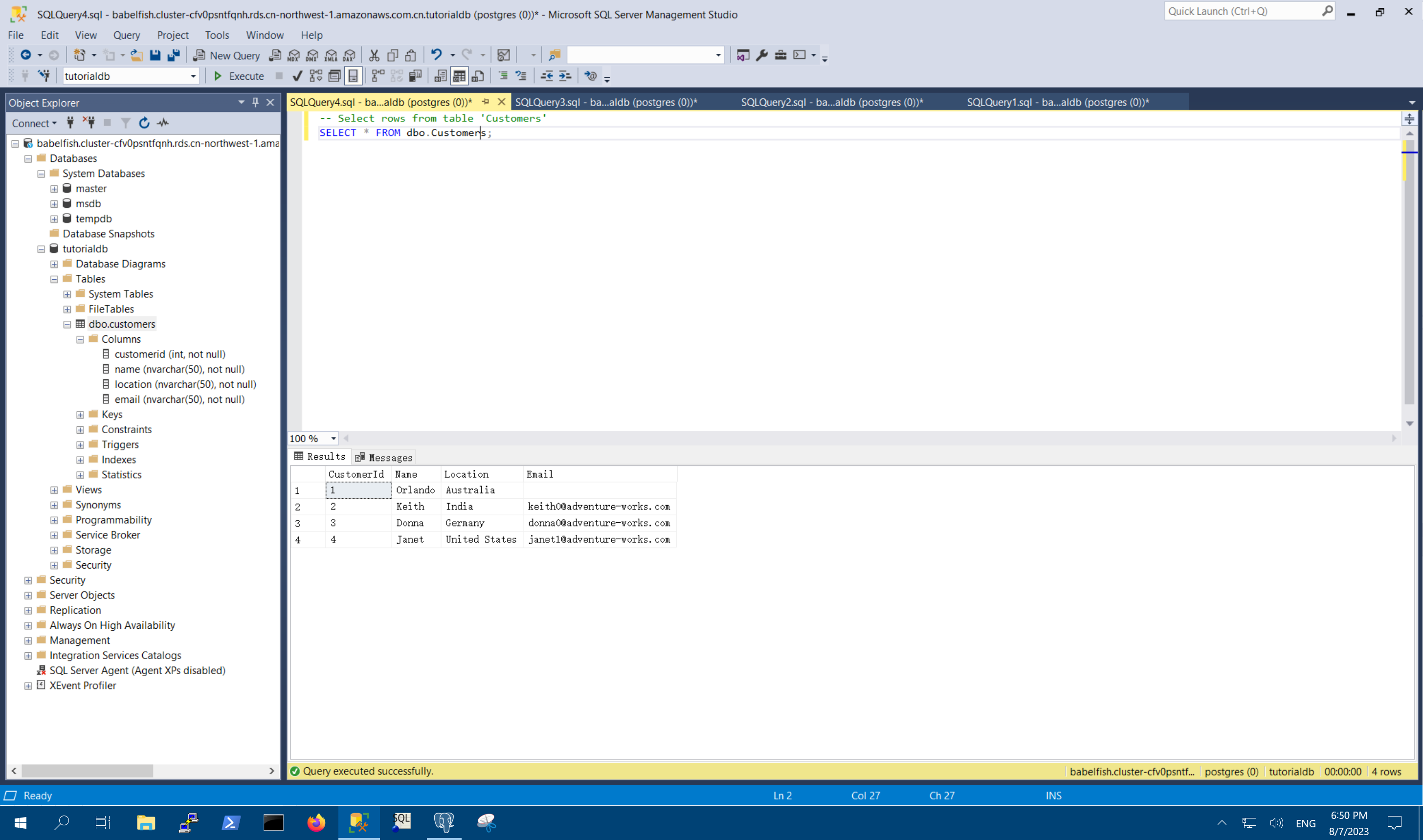
下来验证通过PL/pgSQL读取。
2、通过PL/pgSQL从PostgreSQL读取数据
PostgreSQL的连接,可使用多种客户端完成,包括PostgreSQL原生的psql命令行工具、pgAdmin图形管理工具,也可以是支持JDBC访问的其他GUI工具。
本文使用SQL Workbench J作为客户端工具,使用SQL Workbench J工具内驱动管理界面自动下载的JDBC作为连接协议。登录时候,除了输入用户名外,还需要输入数据库明,这里使用Aurora Babelfish要求的专用数据库名称babelfish_db作为数据库名称。连接成功如下截图。

连接成功后,执行如下命令查询刚才从T-SQL接口插入的数据。
SELECT * FROM dbo.customers
可看到查询成功,如下截图。
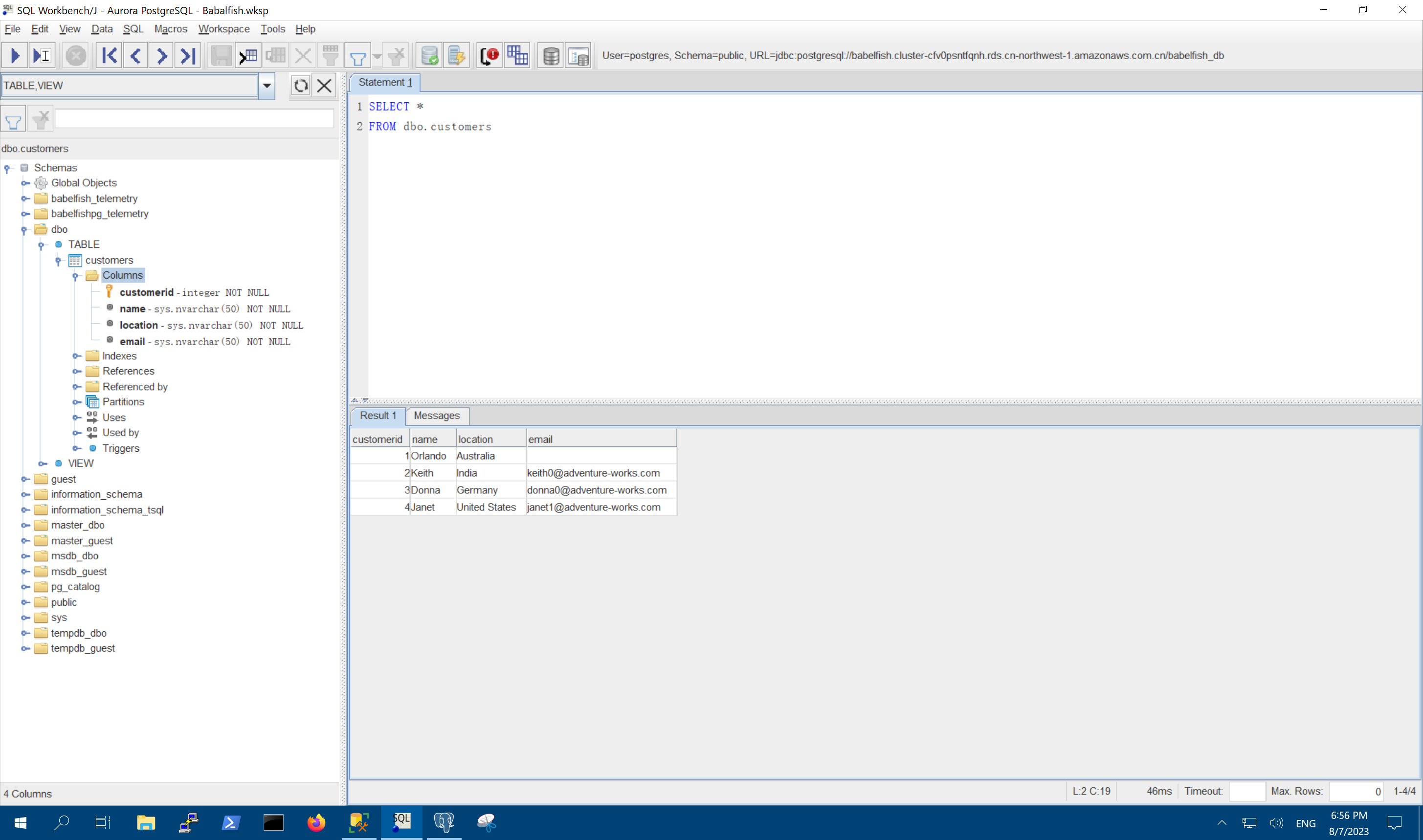
现在使用PostgreSQL官方推荐的pgAdmin图形管理工具,也可以看到Babelfish完成了T-SQL接口的数据库到PostgreSQL数据库的映射。如下截图。
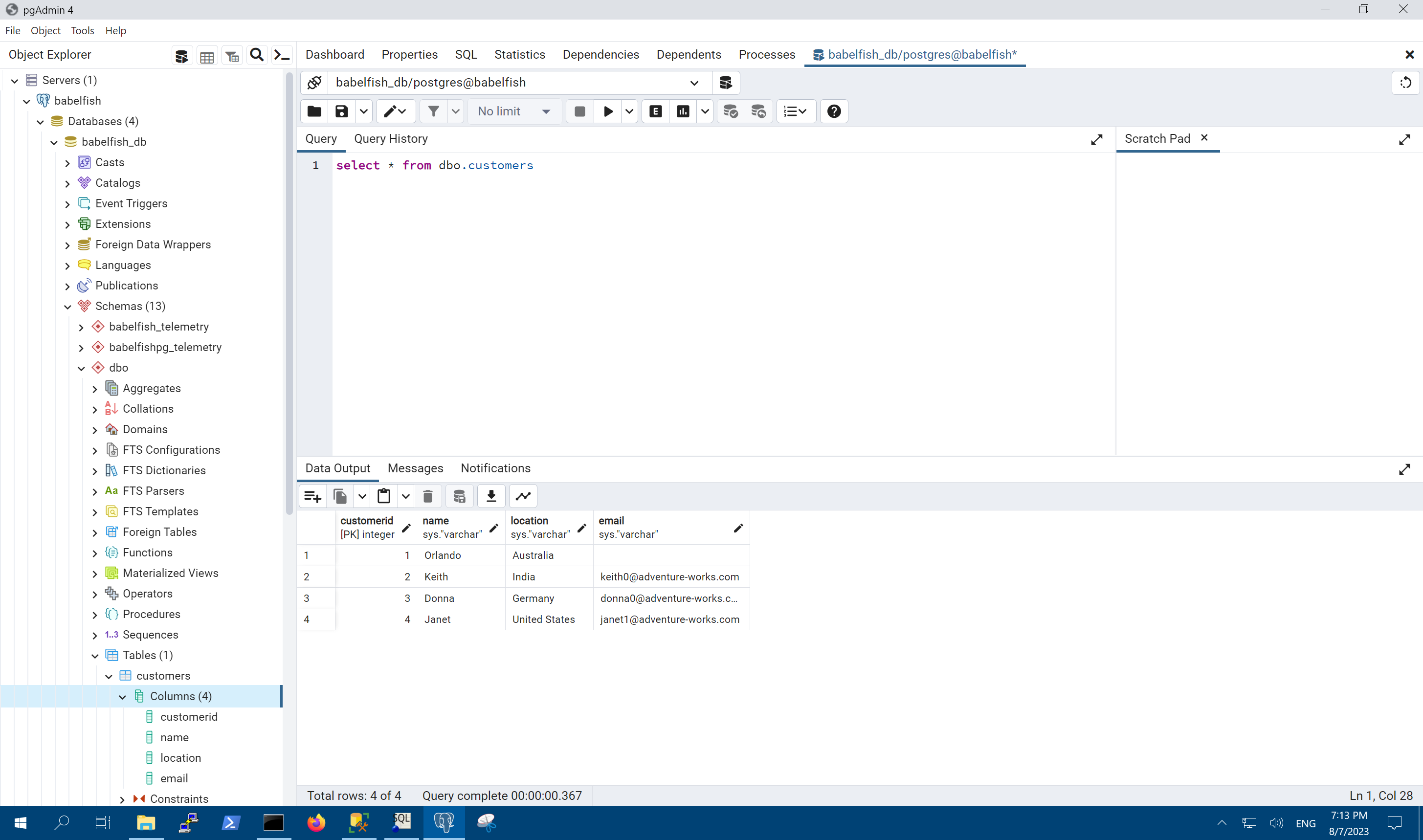
Single-DB场景测试完毕,现在进入Multi-DB场景。
三、Multi-DB的使用
1、通过T-SQL接口创建数据库、表并插入数据
Aurora Babelfish一旦创建集群后,就不能在修改Single-DB模式和Multi-DB模式的开关了。因此,这里需要在创建一个新的Aurora集群,并使用Multi-DB选项。
创建完毕后,重复上一步Single-DB的生成测试数据库、表和数据的操作,但是注意,在数据库名称位置,上一步数据库名称为TutorialDB,这里为了模拟多数据库,因此取名为TutorialDB1和TutorialDB2。数据库内的Schema依然使用默认的dbo,这里不修改schmea名称。分别执行如下命令。
创建第一个数据库TutorialDB1并插入数据:
USE master
GO
IF NOT EXISTS (
SELECT name
FROM sys.databases
WHERE name = N'TutorialDB1'
)
CREATE DATABASE [TutorialDB1]
GO
USE [TutorialDB1]
-- Create a new table called 'Customers' in schema 'dbo'
-- Drop the table if it already exists
IF OBJECT_ID('dbo.Customers', 'U') IS NOT NULL
DROP TABLE dbo.Customers
GO
-- Create the table in the specified schema
CREATE TABLE dbo.Customers
(
CustomerId INT NOT NULL PRIMARY KEY, -- primary key column
Name [NVARCHAR](50) NOT NULL,
Location [NVARCHAR](50) NOT NULL,
Email [NVARCHAR](50) NOT NULL
);
GO
-- Insert rows into table 'Customers'
INSERT INTO dbo.Customers
([CustomerId],[Name],[Location],[Email])
VALUES
( 1, N'Orlando', N'Australia', N''),
( 2, N'Keith', N'India', N'keith0@adventure-works.com'),
( 3, N'Donna', N'Germany', N'donna0@adventure-works.com'),
( 4, N'Janet', N'United States', N'janet1@adventure-works.com')
GO
创建第2个数据库TutorialDB2并插入数据:
USE master
GO
IF NOT EXISTS (
SELECT name
FROM sys.databases
WHERE name = N'TutorialDB2'
)
CREATE DATABASE [TutorialDB2]
GO
USE [TutorialDB2]
-- Create a new table called 'Customers' in schema 'dbo'
-- Drop the table if it already exists
IF OBJECT_ID('dbo.Customers', 'U') IS NOT NULL
DROP TABLE dbo.Customers
GO
-- Create the table in the specified schema
CREATE TABLE dbo.Customers
(
CustomerId INT NOT NULL PRIMARY KEY, -- primary key column
Name [NVARCHAR](50) NOT NULL,
Location [NVARCHAR](50) NOT NULL,
Email [NVARCHAR](50) NOT NULL
);
GO
-- Insert rows into table 'Customers'
INSERT INTO dbo.Customers
([CustomerId],[Name],[Location],[Email])
VALUES
( 1, N'Orlando', N'Australia', N''),
( 2, N'Keith', N'India', N'keith0@adventure-works.com'),
( 3, N'Donna', N'Germany', N'donna0@adventure-works.com'),
( 4, N'Janet', N'United States', N'janet1@adventure-works.com')
GO
数据插入成功。且可以通过SQL Server Management Studio(SSMS)看到其中的两个数据库的Schema和Table。如下截图。

接下来转向到PostgreSQL进行查询。
2、通过PL/pgSQL从PostgreSQL读取数据
使用JDBC连接到PostgreSQL时候请注意,要求填写数据库名称,此时还填写为babelfish_db,因为这是这是Babelfish默认的数据库。
执行如下查询:
SELECT * FROM tutorialdb1_dbo.customers
可看到查询结果被正常输出。如下截图。

由此可以看到,在多数据库模式下,通过T-SQL接口创建的tutorialdb1数据库下的Schemadbo下的数据表customers,被映射到了PostgreSQL下的babelfish_db下的Schematutorialdb1_dbo下的数据表customers。
更多数据库的命令逻辑按上述依次类推。
四、结论
注意事项1:希望在T-SQL和PL/pgSQL之间共享的数据库,必须使用符合Babelfish要求的命名规则,即位于系统默认的babelfish_db之内。如果直接通过PL/pgSQL接口,创建一个PostgreSQL数据库取名为demo1,此时,通过T-SQL接口将无法看到这个数据库。T-SQL接口只能看到系统默认的babelfish_db之内的Schema。
注意事项2:Aurora Babelfish一旦创建集群后,就不能在修改Single-DB模式和Multi-DB模式的开关了。因此,这里需要在创建一个新的Aurora集群,并使用Multi-DB选项。
注意事项3:查询一个已经创建好的Aurora Babelfish数据库的模式是Single-DB还是Multi-DB模式,可通过PL/pgSQL接口登录,执行show babelfishpg_tsql.migration_mode;命令,即可返回是Single-DB还是Multi-DB模式。
注意事项4:如果当前Aurora Babelfish数据库是Single-DB配置,且已经通过T-SQL接口创建了一个数据库,那么在通过T-SQL接口创建第二个数据库时候,将会提示Only one user database allowed under single-db mode. User database "tutorialdb1" already exists的提示。这表示本数据库的Babelfish配置为单数据库模式,因此是不支持第二个数据库被创建的。
五、参考文档
Babelfish architecture:
https://docs.amazonaws.cn/en_us/AmazonRDS/latest/AuroraUserGuide/babelfish-architecture.html
快速入门:使用 SQL Server Management Studio (SSMS) 连接和查询 SQL Server 实例:
PostgreSQL的pgAdmin图形管理工具下载:
最后修改于 2023-08-07