Glue ETL 生成单一文件
Glue ETL转换时生成多个小文件导致Athena查询性能下降,通过coalesce方法将多分区合并为单一文件,提升查询效率。
Glue在做ETL转换时候,因为数据源文件的格式和字段问题,可能无法正确的分区,因此会导致一个一个大文件被转换为若干个小文件,存在一个目录下。如下截图。
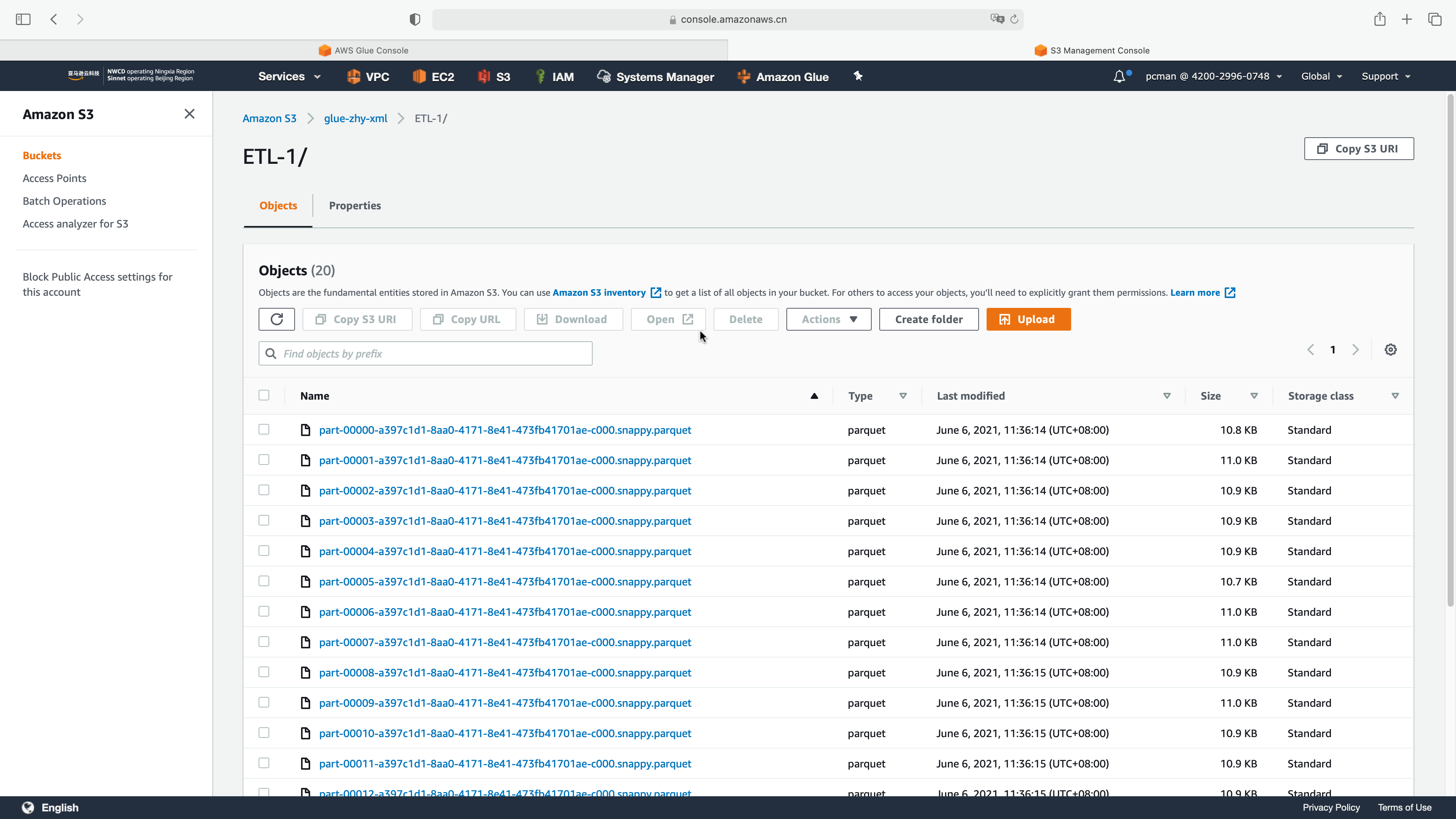
在此情况下,可以用Glue继续爬取S3目录内的结构,并使用Athena查询。生成多个文件并不会影响Athena查询数据,但是会降低查询性能,导致查询时间变长。Athena查询使用相对较大的单个文件,例如在几个GB一个文件的体量情况下做分区比较理想。因此对于这种场景,需要调整ETL代码,重新分区,生成单个文件。由此可通过repartition方法或者coalesce方法来进行。
再次运行Glue,所有选择参数与之前一样,进行到最后一步,生成代码后,先不要点击运行。将最后几行代码修改为如下。如下截图。
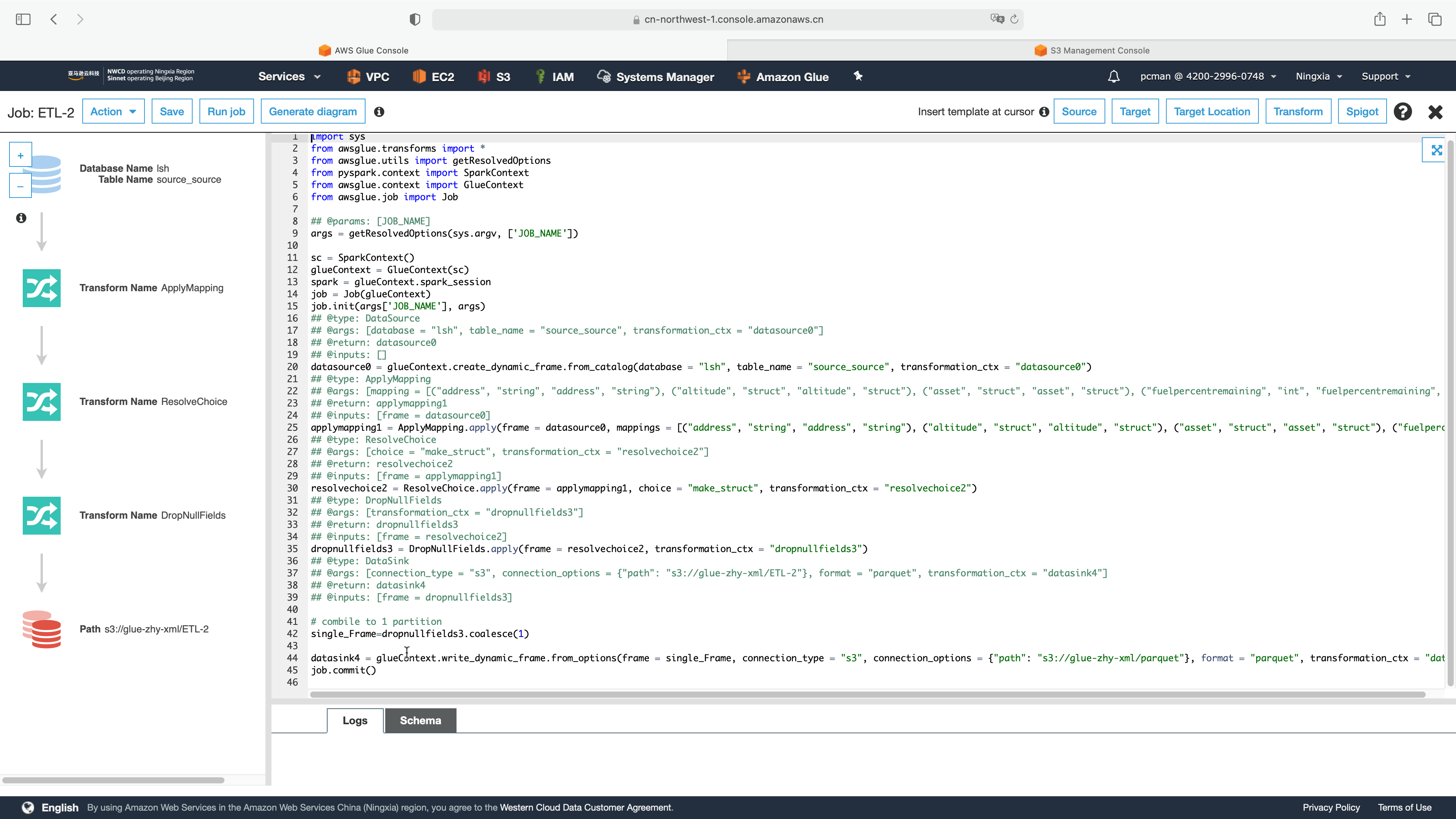
与之前的代码对比,有如下几行变化。如下代码。
\# combile to 1 partition
single\_Frame=dropnullfields3.coalesce(1)
datasink4 = glueContext.write\_dynamic\_frame.from\_options(frame = single\_Frame, connection\_type = "s3", connection\_options = {"path": "s3://glue-zhy-xml/parquet"}, format = "parquet", transformation\_ctx = "datasink4")
job.commit()
再次运行Glue ETL任务后,可以看到生成的就是单一文件。
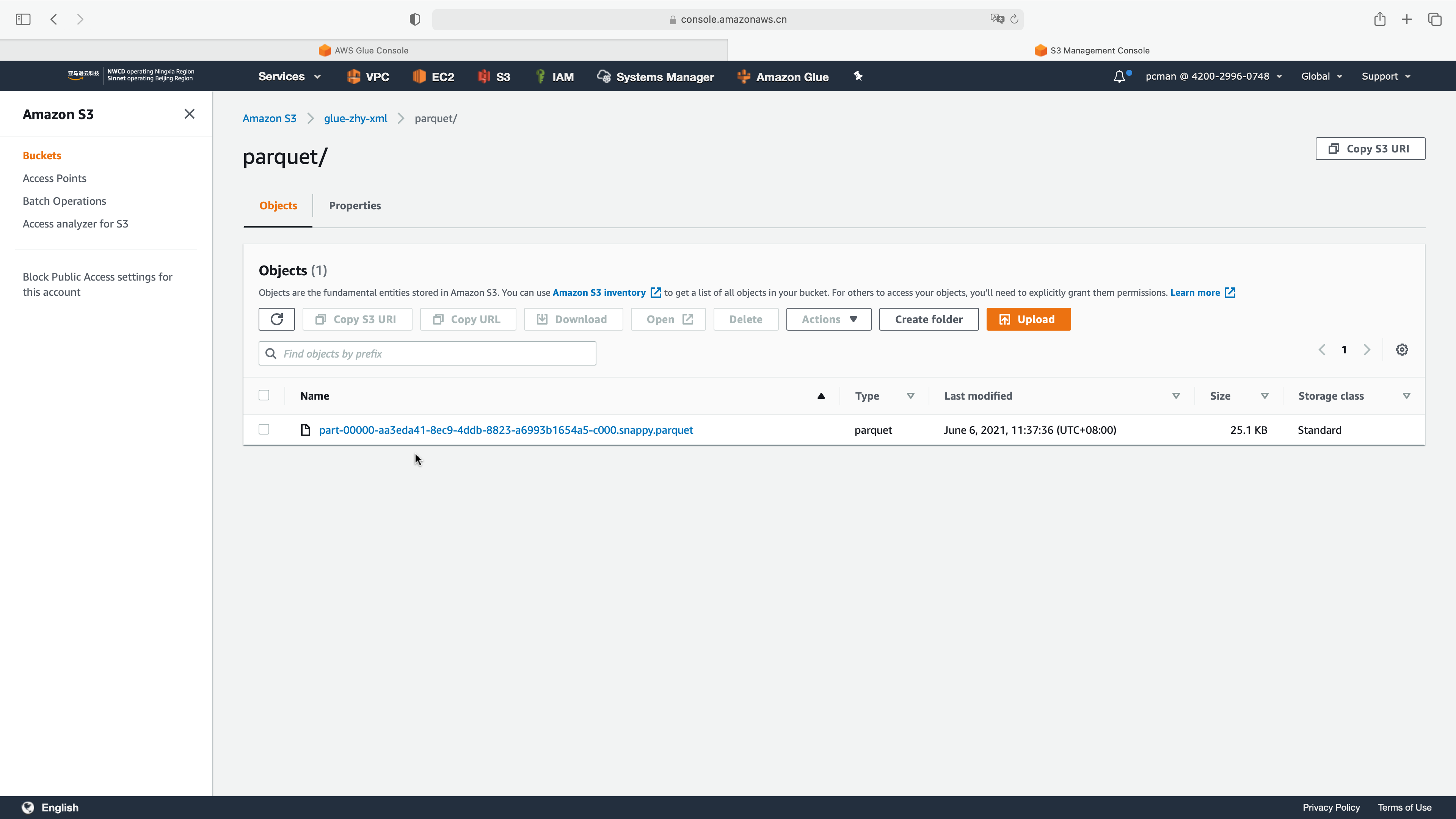
操作完成。
最后修改于 2021-06-06