使用Snowball客户端传输数据
详解使用Snowball客户端从IDC迁移大量数据到AWS S3的完整流程。涵盖设备申请、初始化配置、性能测试、并发复制等关键步骤,解决大规模数据迁移的挑战。
一、申请Snowball
Snowball可用于将IDC大量数据从本地迁移到云端S3。如果云端的市场场景不是在S3上,那么还需要通过EC2进行中转,将数据提取出来,放到EFS等服务上使用。申请Snowball的主要过程如下。
1、创建S3存储桶
Snowball的数据在导入云后是存入S3 Bucket桶内的。因此第一步是在要导入数据的区域创建S3存储桶。例如导入北京则在北京申请桶,在宁夏区域则导入数据则在宁夏创建一个桶。
创建桶时候,可以将桶设置为非空开状态,并禁用所有Public规则。
注意:直到数据导入完成并正常运行之前的这一段时间,请不要删除此存储桶。
2、申请Snowball
进入Snowball界面,选择区域为中国,选择业务类型是导入到S3。如下截图。
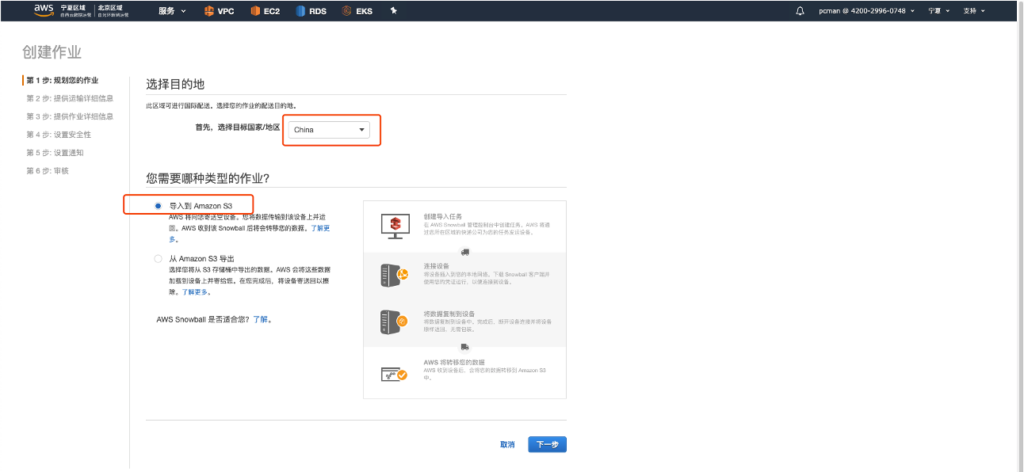
在下一步输入邮寄地址和联系人,Snowball会邮寄到这里。在国内使用的物流服务商是顺丰。
第三步选择要使用的S3的桶名字。如下截图。
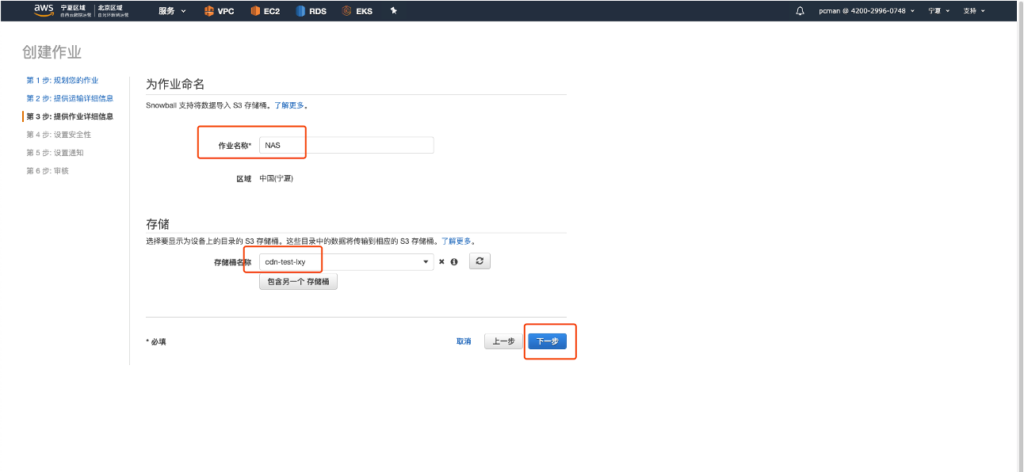
第四步选择创建IAM角色。点击创建按钮继续。
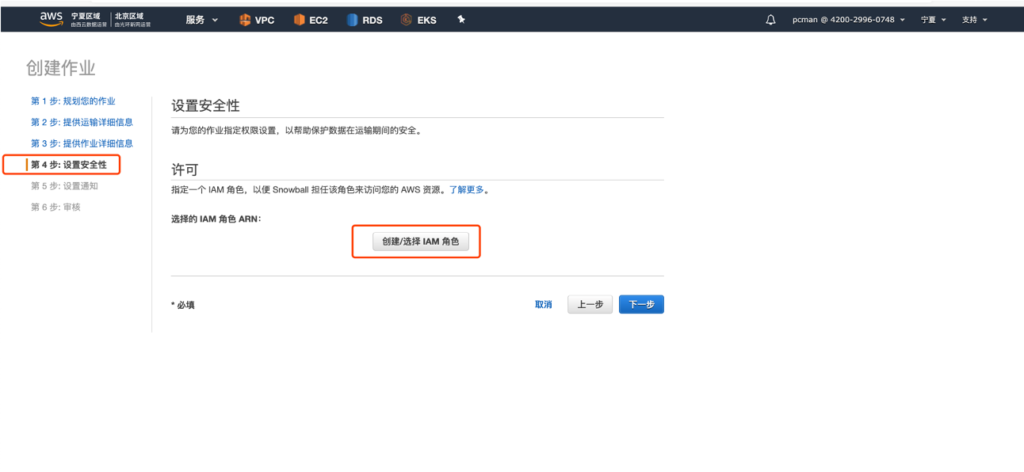
此时会弹出一个新窗口,保持选项默认,点击下一步就可以继续。
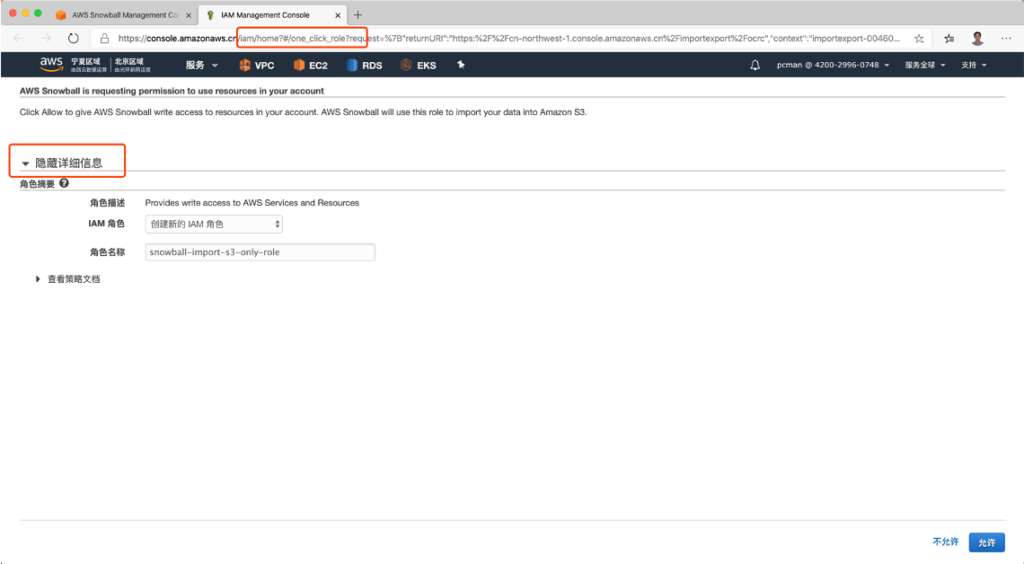
创建第五步,设置接受通知的SNS主题和邮件地址。如下截图。
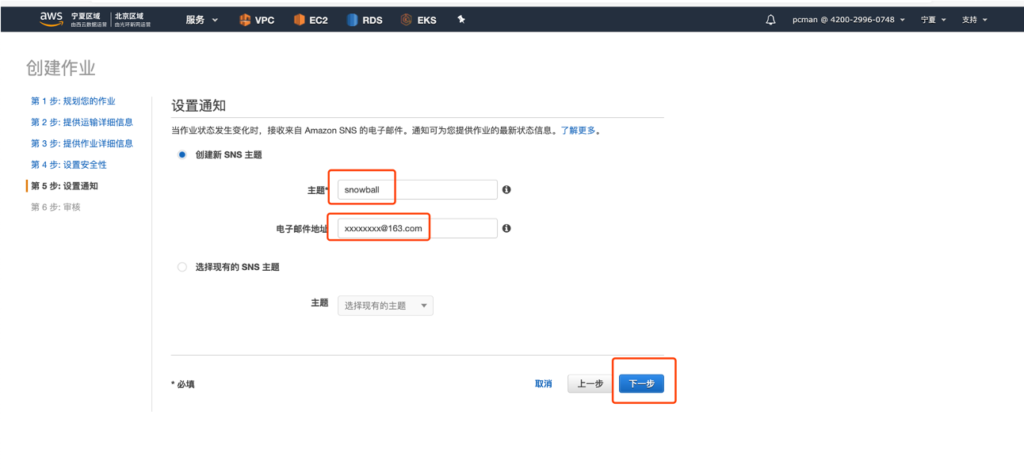
最后一步,提交请求等待设备发货。
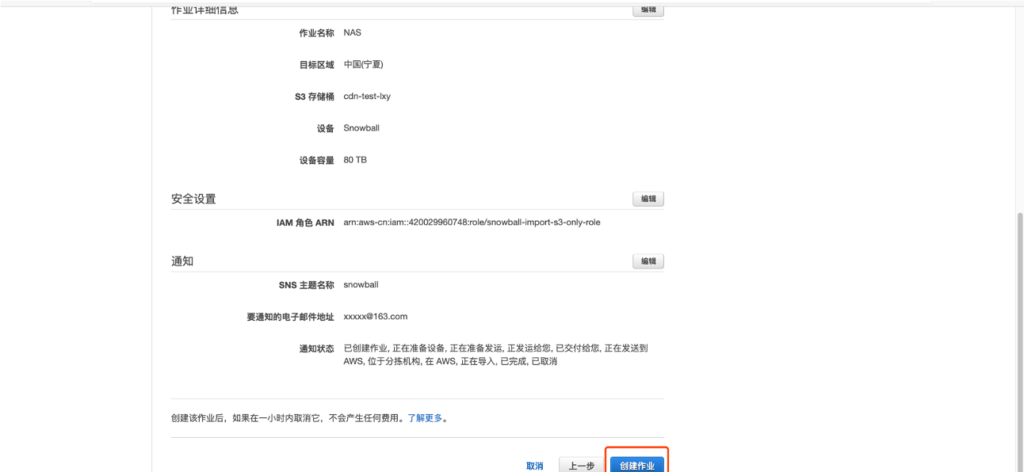
完成流程后,用户可以从AWS控制台上看到进度和步骤,分别会经过AWS审核、交付运输、在途、达到等多个状态。审核状态下,一般需要2-3天,且AWS会根据用户留下的联系方式,通过电话、邮件等方式联系。
如果在Snowball页面申请后,在第一个流程停留了3天还没有收到联系,请与support团队联系确认是否存在例外情况。
二、初始化Snowball客户端
1、收到Snowball
Snowball本身是一个坚固的运输设备,不需要包装箱,自身带有储存线缆的储物格,也有外置的E-Ink墨水屏幕(类似Amazon Kindle 电子书)的屏幕。外观如下。

收到设备后,大概储物格,可以找到电源线,用于连接到IDC。
2、硬件IP设置
分别打开前面板和后面板,暴露出来电子墨水屏幕和网络接口。启动电源。开机通电后大约5分钟启动完成,屏幕上将显示READY,方可进入下一步操作。如下截图。
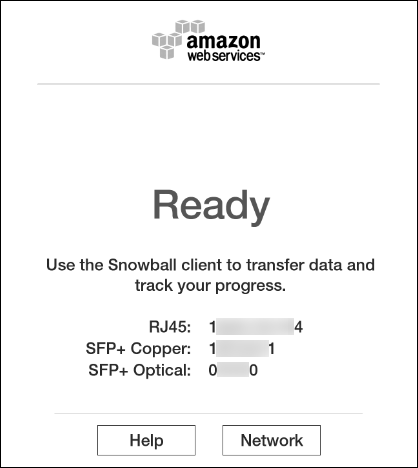
按触摸屏上的Network,可以选择DHCP或者Static IP。设置IP地址,连接到网络。配置完成后,通过网络ping检查是否正常联通。(Snowball允许ping)
网络准备完成后,需要准备用于拷贝数据的客户端环境。
3、操作环境要求
Snowball本身是一个存储设备,需要一个“高性能工作站”作为复制数据的发起者。这个高性能“工作站”可以是一台虚拟机,也可以是一台物理服务器,也可以是高配置的笔记本电脑。这台用于复制数据的“工作站”需要挂载IDC内的数据源(如NAS),并且在网络上具备访问Snowball IP的最近路径,也就是延迟越低越好,建议与要复制的数据在同一个交换机上。网络建议具备10GE光纤接入,可保持持续复制低延迟高带宽。
复制数据将消耗CPU用于校验,因此推荐16vCPU、16GB的虚拟机规格。每个复制任务最高需要7GB内存,因此如果配置不满足16核16GB,最低也应配置8核8GB。操作系统建议为CentOS 7 Linux或Windows Server 2016。
4、获取证书
在收到Snowball之后,通过AWS Console可以看到Snowball的状态也会发生相应的改变。如下截图。(截图为旧版,新版控制台可能外观略有不同)
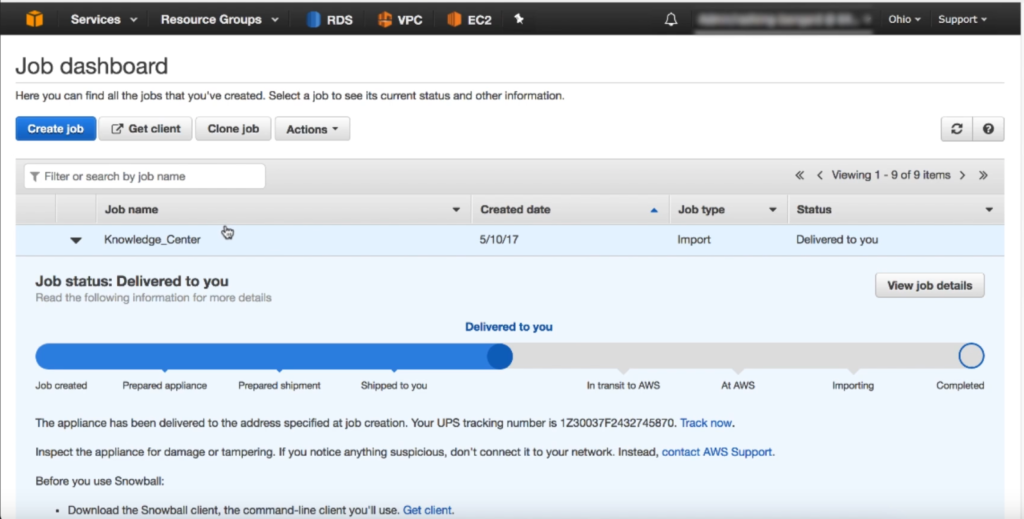
如果一次发起了多个Snowball导入任务,那么需要从中选取本次操作的任务。如果只有一个任务,那么点击详情,展开详细信息,可以从中找到 “Credentials” 解锁码和 “Manifest” 任务清单文件。如下截图。
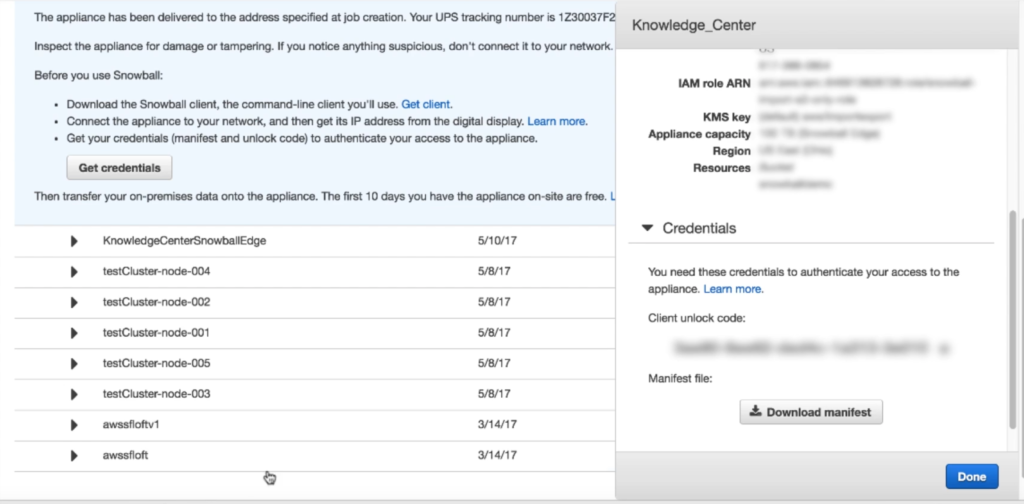
解锁代码是一串20位数字和字母混合的序列号,请将这个序列号复制下来,保存到记事本,或者另外的地方,不要丢失。如果忘记或丢失,可能导致本次导入失败,需要重新邮寄Snowball设备,重新导入。
Manifest 任务清单文件是一个配置文件,需要将这个文件上传到执行导入的客户端环境中。
5、下载客户端
从本地IDC向Snowball内复制数据需要使用专用的客户端软件。Windows点这里。Linux点这里。MacOS点这里。Snowball客户端是一个压缩包,体积约为150MB,是Java语言编写,自带JRE运行环境。下载后无需安装,解压缩,然后以root身份运行即可。
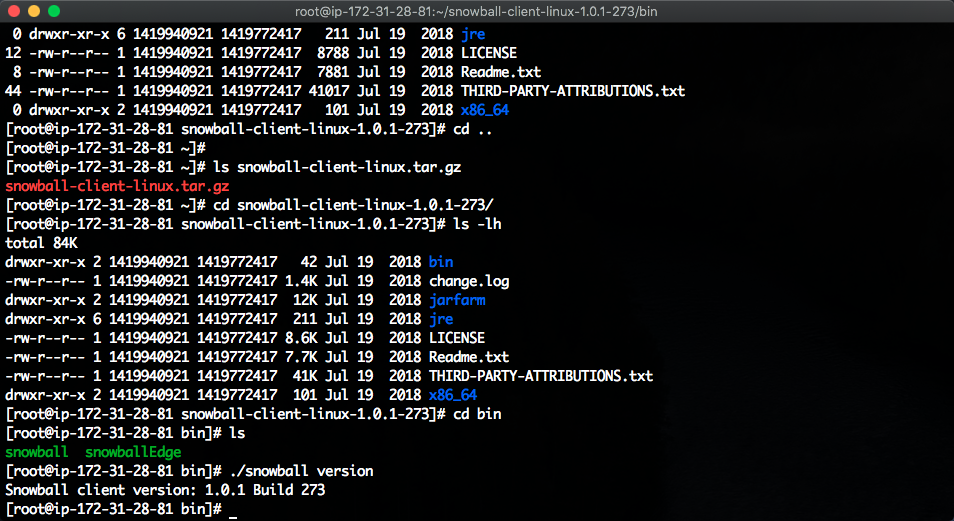
进入到解压缩后的目录,进入bin目录,运行如下命令检查版本。
./snowball version
输出返回了版本即为正常。如下截图。
如果运行snowball客户端的本机内存过小,低于8GB,则会提示内存不足。建议按照上文所介绍使用16vCPU、16GB的配置运行snowball客户端进行数据复制。
6、启动服务
为了避免操作过程的网络波动和断线造成干扰,推荐使用虚拟终端 screen 来执行后续所有操作。这样当发起操作中,用于调试的笔记本可以直接关机、休眠等,都不影响任务执行。第二天一早重新连接到虚拟终端即可。
安装虚拟终端使用如下命令。注:很多系统已经预装screen。可能会提示已经安装过了。
yum install screen
执行 screen 命令命令启动一个新的虚拟终端。测试直接关闭SSH工具都不会影响终端程序运行。当离开电脑很久后重新回来,SSH可能早已经超时,甚至电脑已经休眠,只需要重新登录到SSH,执行 screen -x 即可连接刚之前的虚拟终端。
第一次启动激活设备命令如下。
snowball start -i 10.85.118.201 -m /root/JID2EXAMPLE-0c40-49a7-9f53-916aEXAMPLE81-manifest.bin -u 12345-abcde-12345-ABCDE-12345
其中10.85.118.201是snowball的IP地址,之前调整好IP后,应该通过ping命令测试连通性。JID2EXAMPLE-0c40-49a7-9f53-916aEXAMPLE81-manifest.bin是前文下载的Manifest任务清单文件,后边的20位是数字和字母混合的激活代码。
启动成功,可执行 snowball status 命令确认状态。例如执行后如下返回:
Snowball Status: SUCCESS
S3 Endpoint running at: http://192.0.2.0:8080
Total Size: 72 TB
Free Space: 64 TB
至此设备激活完毕。
三、复制数据
1、评估传输速度
(1)执行测试
接上文操作,假设要复制到snowball上的数据在 /var/www目录,那么执行如下命令发起性能测试:
./snowball test -r -t 5 /var/www
在以上命令中,-r表示递归,即复制目录下的所有子目录,-t 5表示最大执行五分钟测试。如果被测试的目录下的数据量在5分钟内可以复制完毕,那么测试就会结束。执行结果如下图。
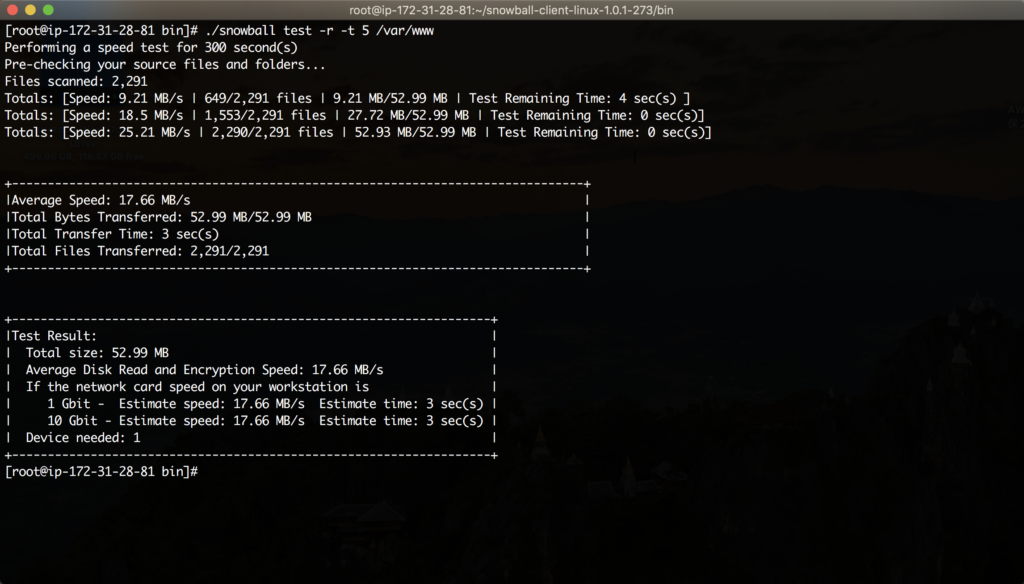
请将上述命令中的 /var/www 也就是数据路径替换为真实的路径,例如替换为NAS挂载到本Linux上的地址。测试程序将扫描被测试目录上的数据量,并且根据文件大小和磁盘性能,计算出大概的复制速度。测试时候加了 -t 5 的参数,表示最长测试5分钟。测试时间越长,结果越准确,测试时间短,或者数据量短,则不具有代表性。
(2)根据测试评估样本数据量和传输速度
测试是非常必要的,且意义重大。原因是复制过程对体积小数量多的场景下更耗时,对单个文件体积大数量少的场景反而更快。
例如,被测试的目录内有100个文件,那么运行测试,实际可能复制速度高达100MB/s,几秒钟就完成了测试,测试时间不会达到五分钟。这时候反应出来的复制速度,和真实数据场景是不一样的。假如真实数据场景有1000000个文件,每个文件1MB,那么执行测试,5分钟读取一遍全量数据显然是不够的,但是5分钟也能保证读取了相当多的文件样本,用来评估这个要迁移的目录的平均文件大小,平均传输速度等。测试使用 -t 5 参数表示达到5分钟后测试停止。由此就可以预估,在启动正式数据拷贝时候,要花多久时间。五分钟时间一般足以扫描足够多的文件,用于获得平均文件大小和传输了
(3)根据测试结果评估并发性能
测试数据将包含一个重要的参数是平均加密和传输时间,例如上述截图,因为都是小文件,所以测试近获得了17.66MB/s的平均速度(如上截图)。这个速度意味着,复制数据的瓶颈发生在读取过程的网络连接建立和会话过程,且加密也产生了性能损耗。
此测试结果表明,如果采用多个客户端同时发起复制,将能有效提升传输速度。(前提是目标目录下有多个二级子目录利于分别传输)。Snowball客户端不能对一个顶级目录同时发起多个并行传输,需要认为的定位到二级目录,分别从多个客户端传输。
多个客户端的传输时候,可以根据情况,确认是在一个虚拟机OS上打开多个SSH终端,发起多个传输;也可以是用多个虚拟机,每个虚拟机都运行一个snowball客户端,连接到同一个snowball设备,然后发起传输。
以上方法都将提升传输速度。
2、复制数据
复制前需要注意,文件名如果含有特殊字符,将不能被正常复制。请参考这里是对文件名的规范说明。
将源数据挂在到安装了Snowball客户端的复制主机上,例如上文运行测试的/var/www目录。假设在这个目录下的结构如下:
[ec2-user@ip-172-31-28-81 www]$ ls -l /var/www/
total 4
drwxrwsr-x 2 ec2-user apache 6 Apr 20 03:50 backup
drwxrwsr-x 2 ec2-user apache 6 Oct 22 22:59 cgi-bin
drwxrwsr-x 5 apache apache 4096 Apr 15 15:40 html
[ec2-user@ip-172-31-28-81 www]$
执行复制时候,可以整体一次性传输整个目录,子目录和文件将一并传输。
进入snowball客户端的bin目录下,查询snowball目录和文件使用如下命令。这里的MyBucketName就是在申请Snowball时候,在S3系统上创建的Bucketname。此名称不能更改,后续都必须使用同一个桶名称。
./snowball ls s3://MyBucketName/
在snowball上创建目录命令如下。(也可以不创建目录,复制到根目录下)
./snowball mkdir s3://MyBucketName/data1
复制数据命令如下。
./snowball cp -r -b /var/www s3://MyBucketName/data1
复制数据时候,可以增加参数 -r 表示复制整个目录。参数 -b 表示批处理,会讲小于1MB的文件批量出来复制。批处理是snowball客户端自动进行,对用户透明,复制完成后,数据也是单个文件的正常状态。默认情况下snowball客户端复制时候将10000个小文件一次批处理,这将消耗相当的计算和内存资源,这也是为什么运行snowball的客户端虚拟机,每个虚拟机需要8vCPU、8GB内存的原因。
复制期间如果遇到网络终端,客户端或者NAS源数据端宕机等问题,复制将停止。此时可以使用名下命令再次对同一个目录发起传输。
snowball retry
删除单个文件命令如下。
snowball rm s3://MyBucketName/data1/abc.pdf
删除整个文件命令如下。
snowball rm -r s3://MyBucketName/data1
3、查看日志
使用如下命令校验数据(时间可能很长 )
snowball -v validate
Linux客户端日志在如下目录下。
Linux – /home/<username>/.aws/snowball/logs/
Windows客户端日志在如下目录下。
Windows – C:\Users\<username>\.aws\snowball\logs\
4、性能提升说明
前文所提到的增加测试步骤,获取在当前数据样本下的平均复制性能非常重要。为了加快传输,可以采取以下办法:
- 增大复制客户端效果,例如将8核8GB提升到16核16GB;
- 让复制客户端和数据源在同一个柜顶交换机上;
- 增加 -b 参数批量复制小文件
- 传输目录而不是传输文件,例如在/var/www/data1目录下有100个文件,用-r和-b参数一次传输整个目录的速度,远大于运行100次snowball cp命令的速度
- 并发复制,例如/var/www目录下有data1和data2两个子目录,那么在同一个复制客户端上,可以开两个SSH进程,分别跑两个snowball cp进程,注意每个进程需要8GB内存;
- 多个客户端复制,如上一条,将多个子目录在多个客户端(虚拟机)上发起复制,每个任务至少需要8vCPU和8GB内存;
- 传输期间不要进行其他操作;
- 使用screen虚拟终端避免网络中端。
四、邮寄返回
1、关闭服务
在执行数据复制的客户端上,执行如下命令关闭snowball服务。
snowball stop
命令执行后等待程序正常退出到Linux shell提示符。
按 Snowball 电子墨水屏幕上的电源按钮,选择关机,并等待一段时间,系统将关机,风扇停转。此时可以拔下各种电缆,包括电源线,并将电源线收纳在储物格中,保持邮寄来的样子发送走。
关闭系统后的几分钟内,电子墨水屏上会出现邮寄代码,请记录下这个代码(可以用手机拍照),此代码非常重要,将用于联系AWS和物流运输。如果在关机几分钟后甚至10分钟后,电子墨水屏都没有显示任何信息,可能是Snowball设备发生故障,此时请联系AWS开技术支持工单。
2、联系物流运输
在获取到电子墨水屏幕上的邮寄代码后,请不要自行联系顺丰等物流公司。请与AWS联系,AWS会为您提供特定的联系方式。
请准备以下信息:
- Snowball 作业 ID(通过控制台查看)
- AWS 账户 ID
- 您希望上门提取设备的日期
- 最早上门取货时间
- 最晚上门取货时间
- 客户联系方式
请将以上信息发送给AWS提供的特定沟通渠道,顺丰会按照您要求的时间上门取件。
3、监控导入和后续使用
顺丰收取设备后,可以按照单号追踪运输过程。当设备抵达AWS后,控制台上的任务阶段会变更为At-AWS。这个过程是AWS接收了设备,但还没有开始对接导入。这个状态将持续大概一天左右时间。
随后,控制台上的任务阶段将显示 Importing,即导入中。数据将导入S3存储桶。此过程将持续1-3天,根据文件数量多少(单个文件体积小文件总量多会导致速度慢,单个文件体积大数量少反而更快)。导入完成后,任务阶段将显示Completed。
导入完成的数据已经位于S3上,如果使用场景是在EFS等场景,可以使用AWS CLI等工具,将数据复制到EFS上。也可以使用其他工具进行操作。
至此Snowball全过程完成。
五、参考资料
Snowball完整文档(在线阅读)
https://docs.amazonaws.cn/snowball/latest/ug/whatissnowball.html
Snowball中文使用手册PDF版本(可下载离线阅读)
https://docs.amazonaws.cn/snowball/latest/ug/AWSSnowball-ug.pdf#whatissnowball
文件名可接收的字符
https://docs.amazonaws.cn/AmazonS3/latest/dev/UsingMetadata.html#object-key-guidelines
最后修改于 2020-04-20