
一、准备工作
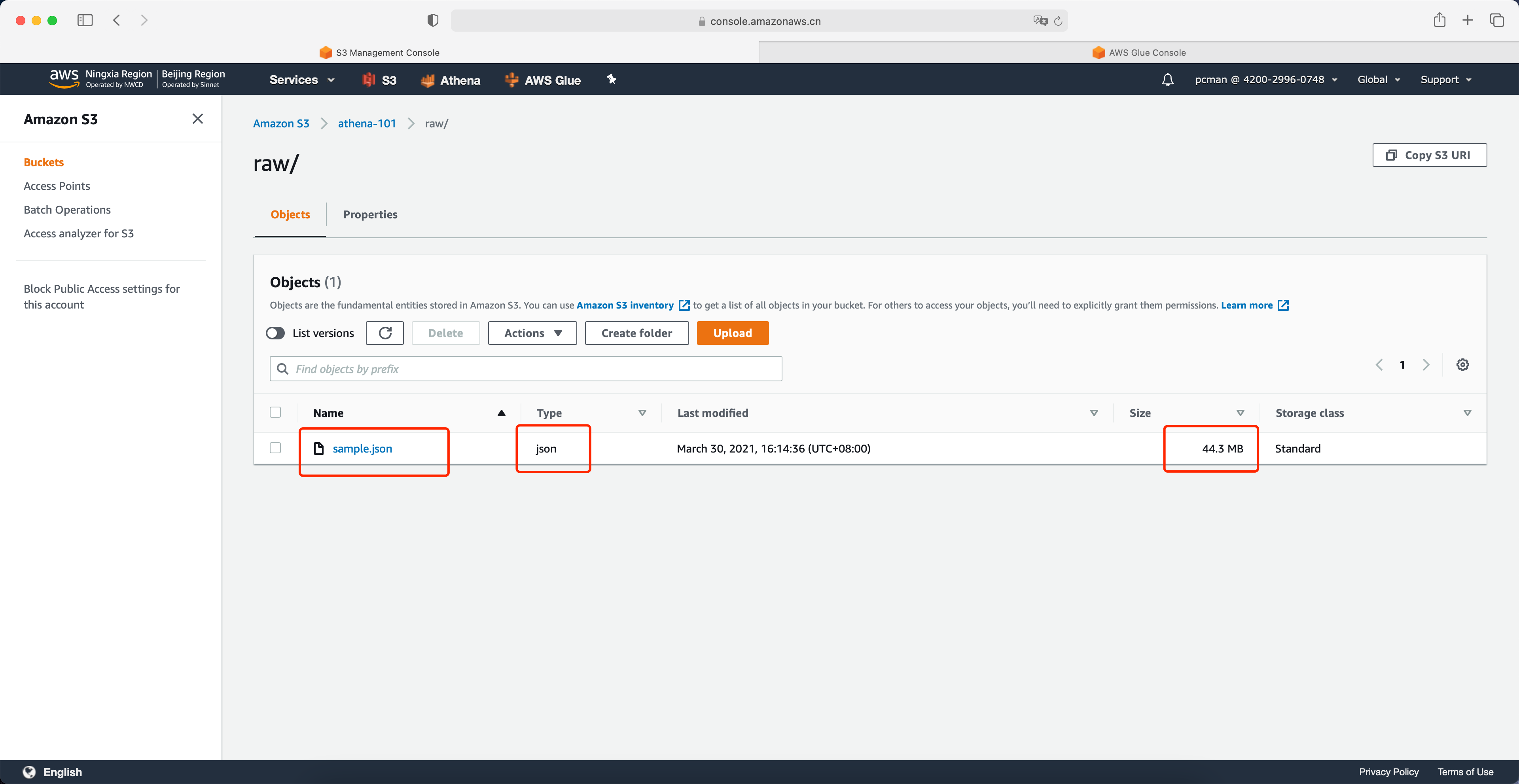
在S3上新建一个存储桶,多人实验时候请注意存储桶名称需要唯一。在存储桶内新建两个目录,一个名为 raw 用于存放原始数据,第二个目录名为 etl 用于存放转换过的数据。
请将测试数据 sample.json 文件上传到存储桶的raw目录内。请记住文件大小,稍后将会进行对比。
如下截图。
二、使用Glue爬取数据目录并通过Athena进行查询
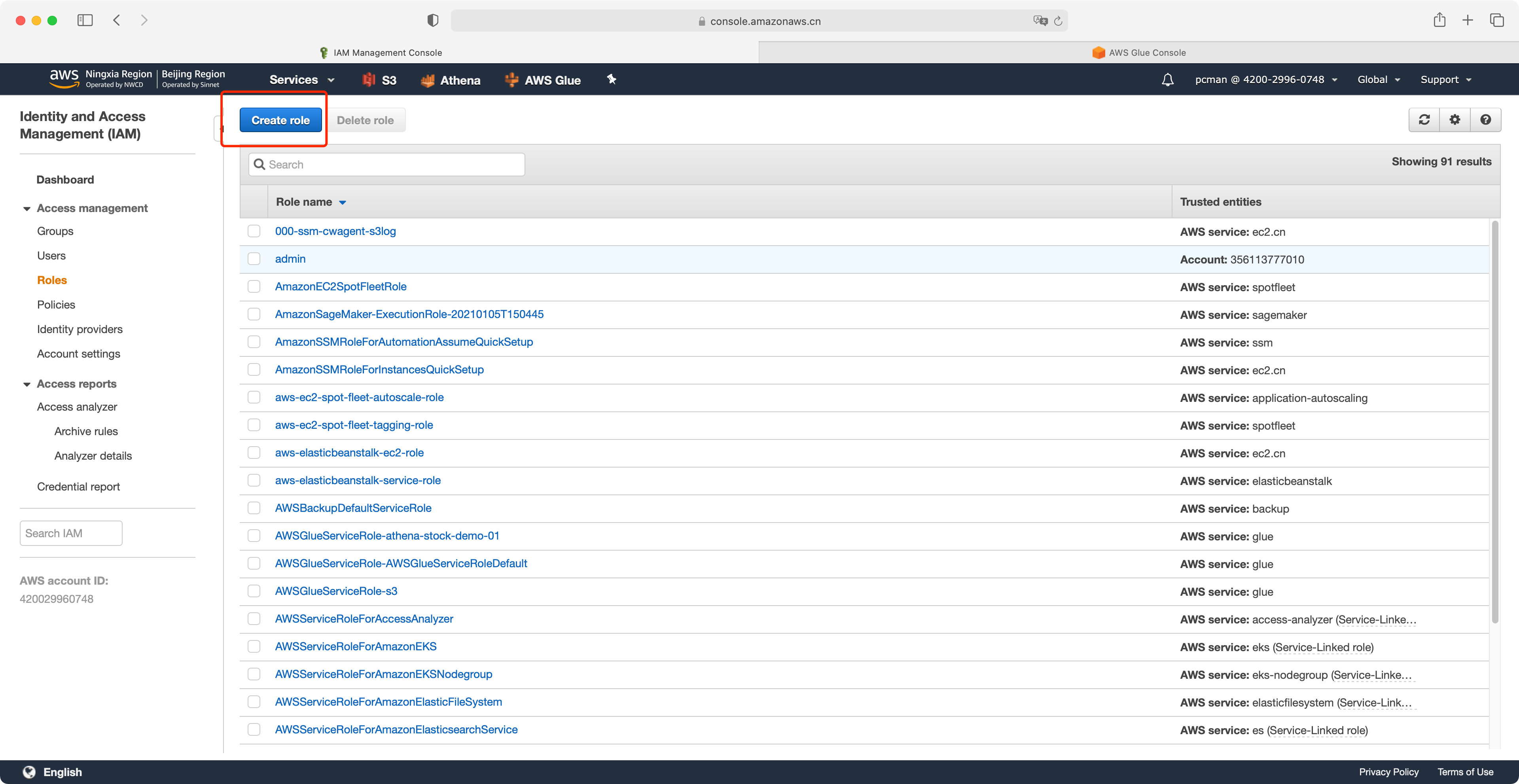
1、创建Glue需要的IAM角色
点击IAM服务,点击左侧的“角色”,再点击右侧的创建。如下截图。
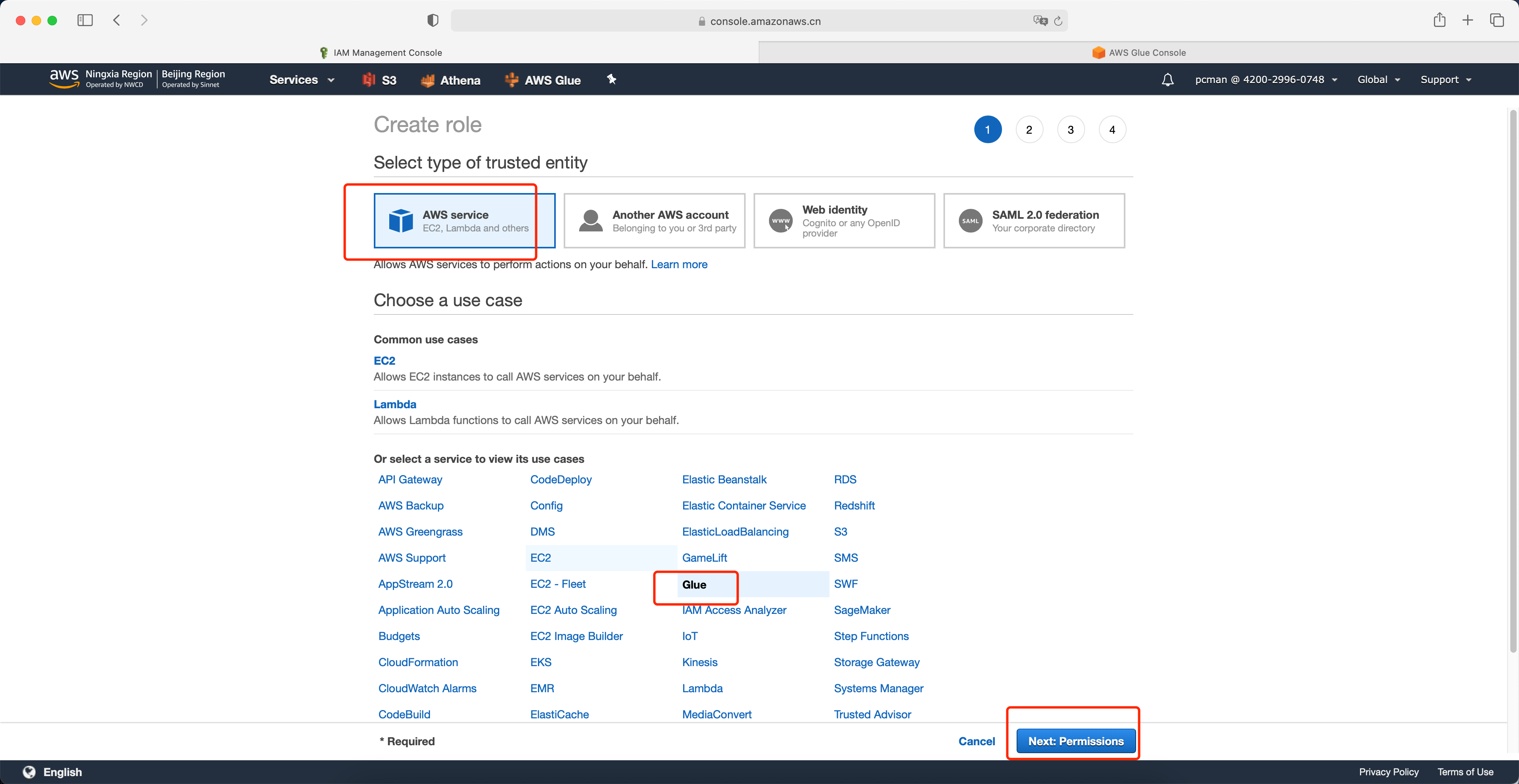
在选择服务类型对话框中,选择第一项AWS服务。在下方的服务清单中,找到Glue 服务,点击选中,然后点击下一步权限。如下截图。
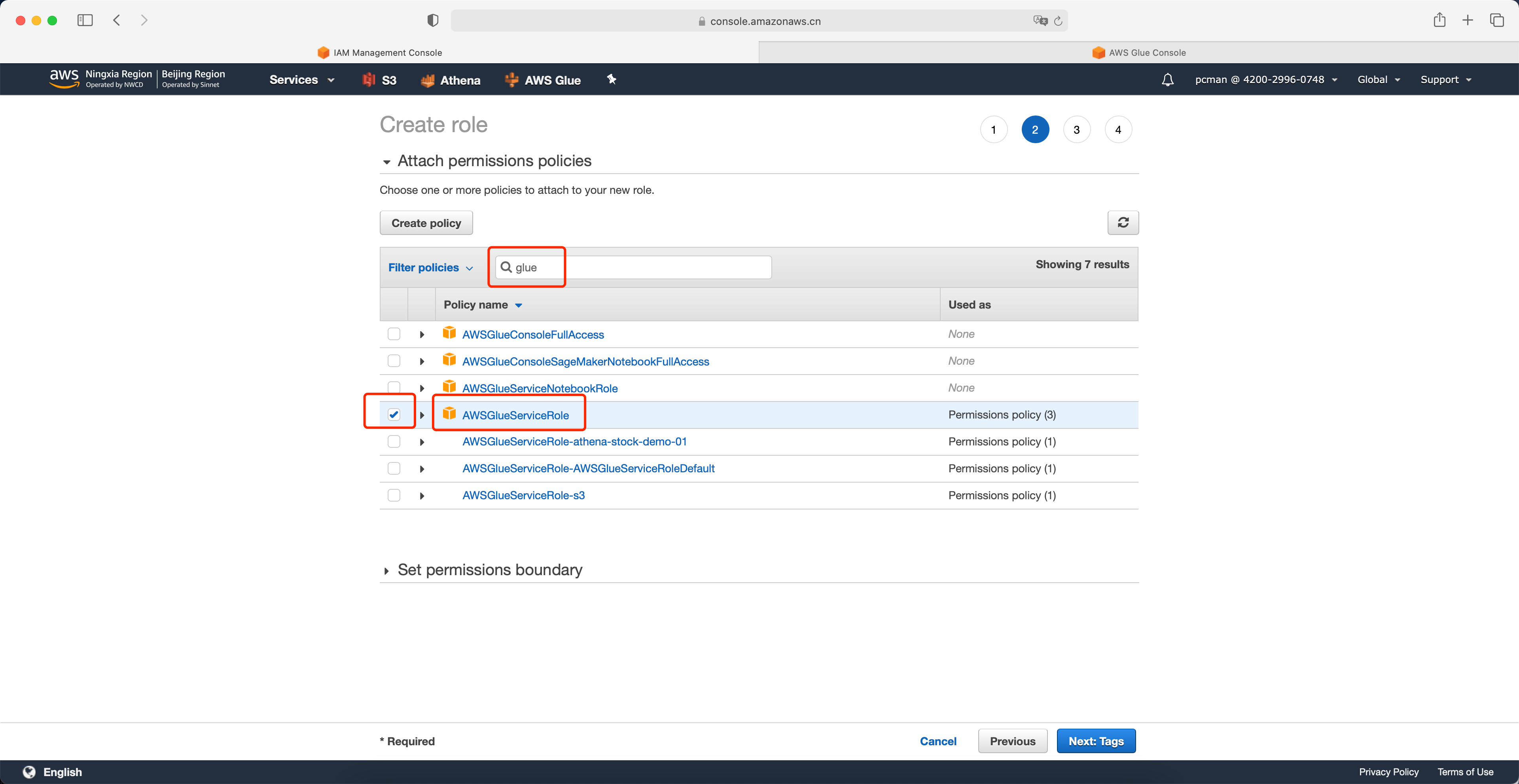
在策略搜索框中,输入搜索关键字 glue,然后在搜索出来的清单中,选中名为 AWSGlueServiceRole的角色。然后不要着急点击下一步,继续后续操作。如下截图。
在搜索了Glue角色后,再次搜索关键字 s3,并选择AmazonS3FullAccess 。选中后点击下一步继续。由于实验关系,为简化实验过程,将在实验中赋予S3 Full Access权限,真实生产环境请严格授权,不要使用这种过度赋权的策略。如下截图。
在创建标签界面,留空,点击下一步继续。
在向导最后一步,输入角色名称,例如 Glue-demo-101,注意多人实验需要避免重名。最后点击右下角的创建角色按钮完成创建。如下截图。
返回如下界面表示角色创建完成。
2、使用Glue创建数据目录
进入Glue服务界面,点击数据库,点击创建Database。如下截图。
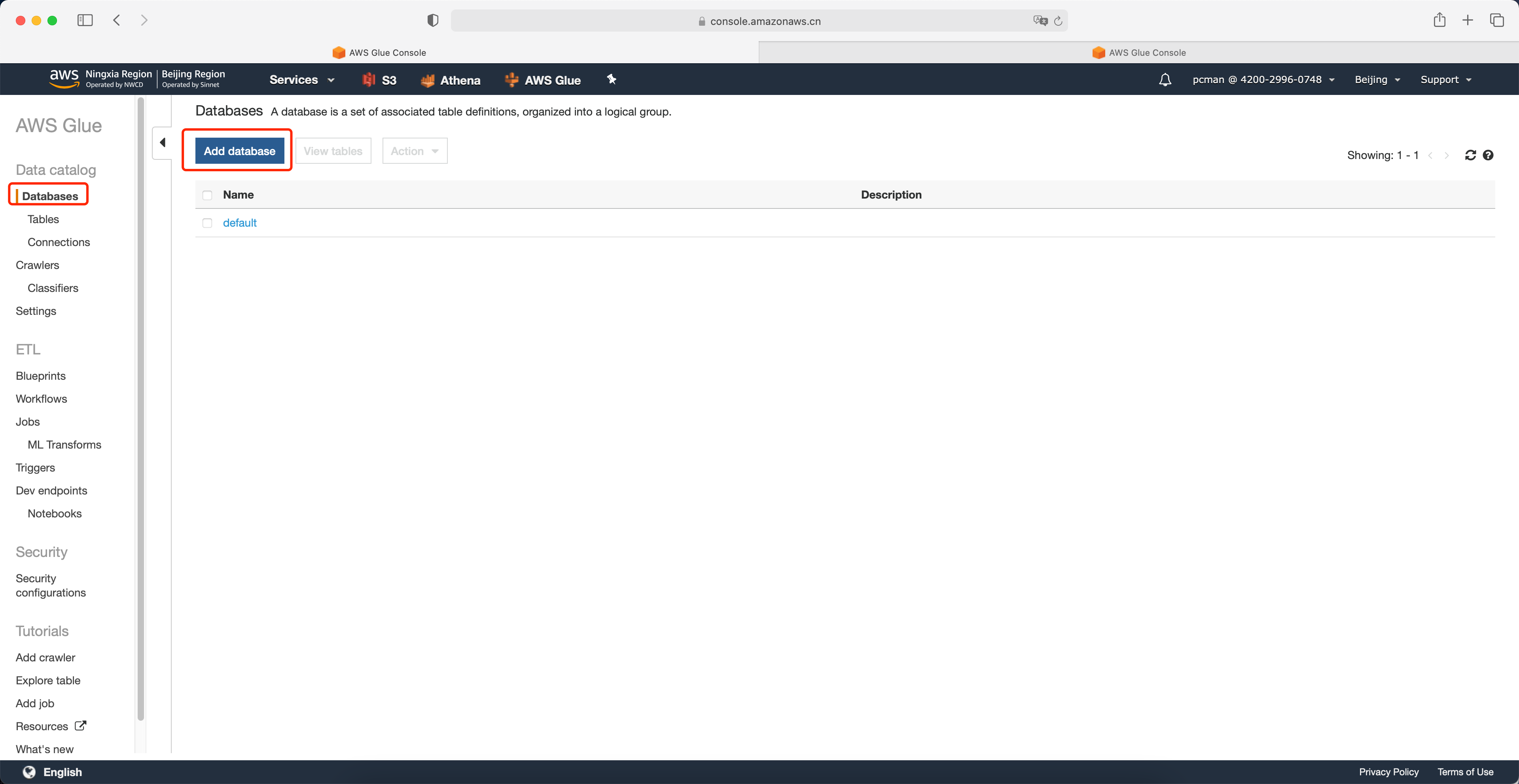
输入数据库名称叫做Glue101,多人实验需要注意避免重名。其他选项为可选,不需要调整,直接点击创建。如下截图。
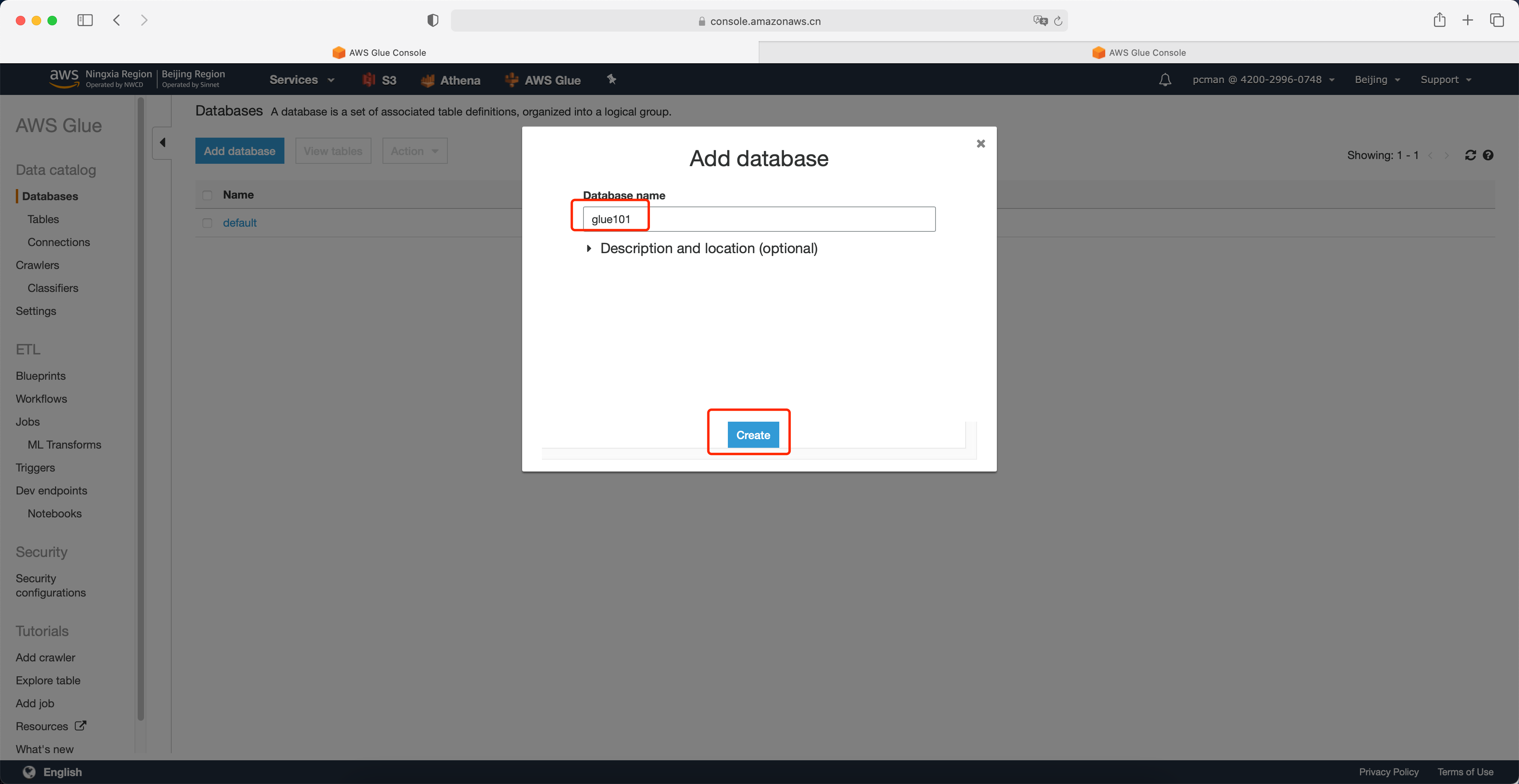
点击左侧的菜单下的数据库下的表格,然后从Add table中选择使用爬网程序添加表。如下截图。
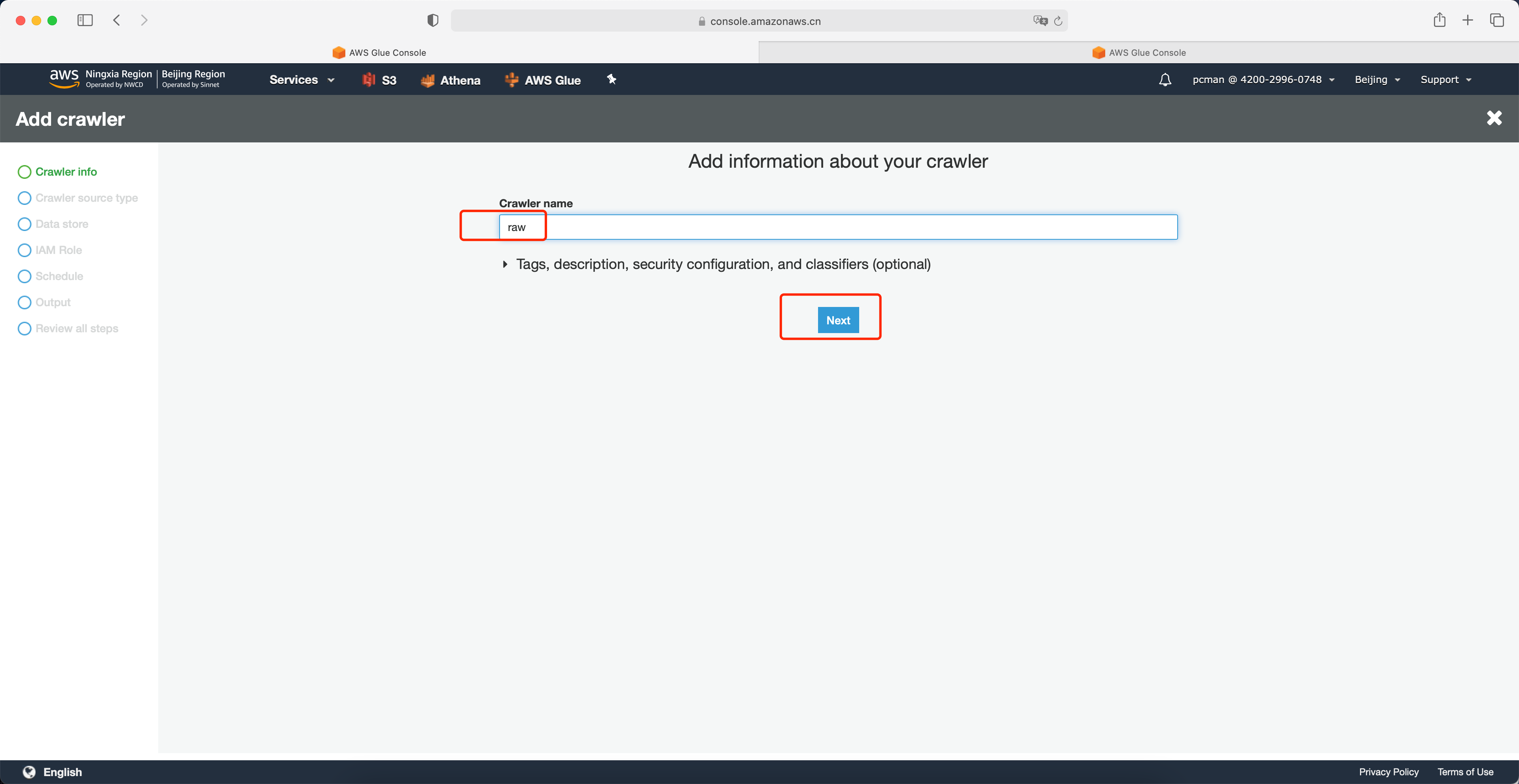
在弹出的向导第一步,输入爬网程序的名称,例如raw表示爬取原始数据。并点击Next继续。如下截图。
数据类型位置保留页面默认值,点击下一步继续。如下截图。
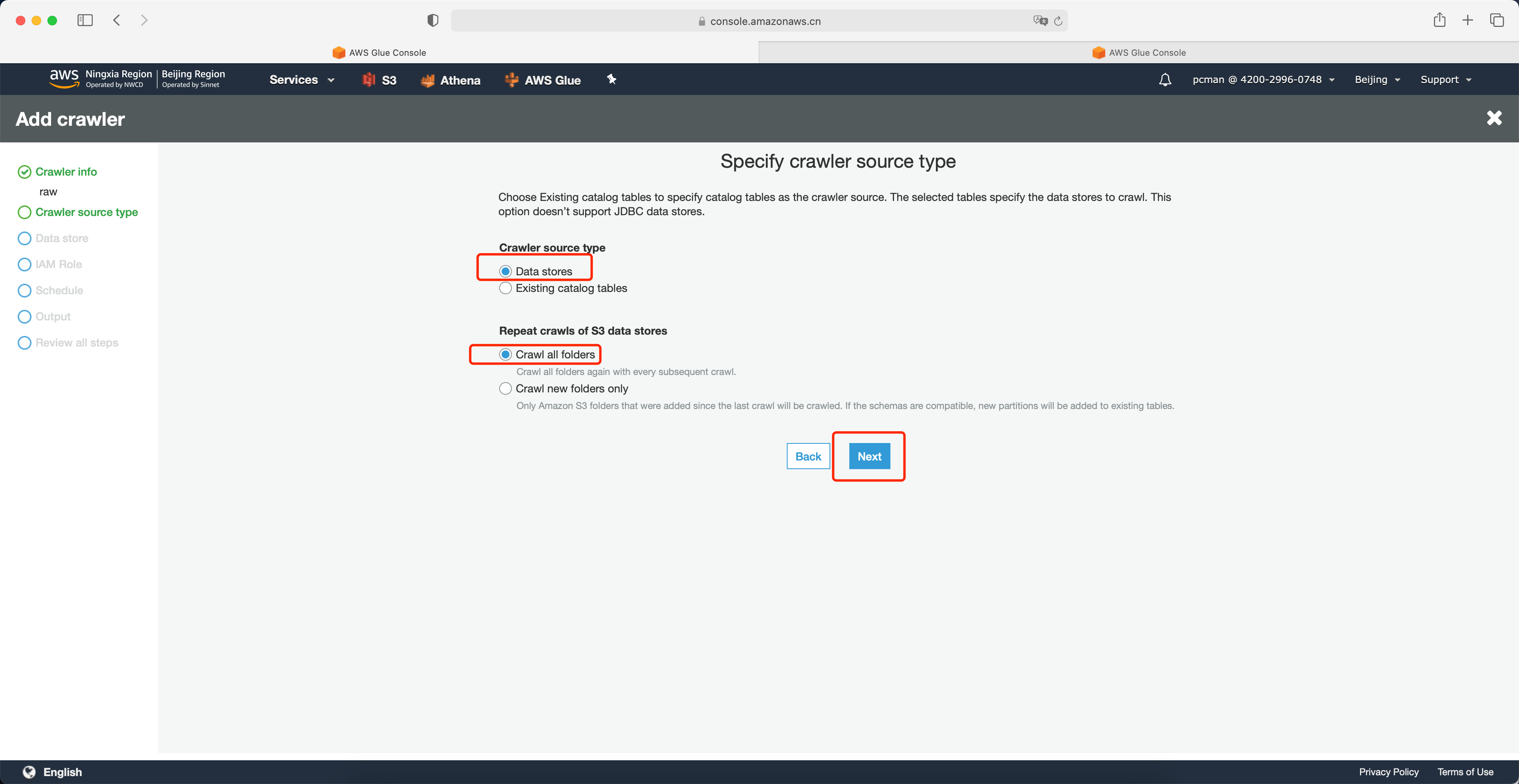
向导第三步数据源,点击右侧的浏览按钮。如下截图。
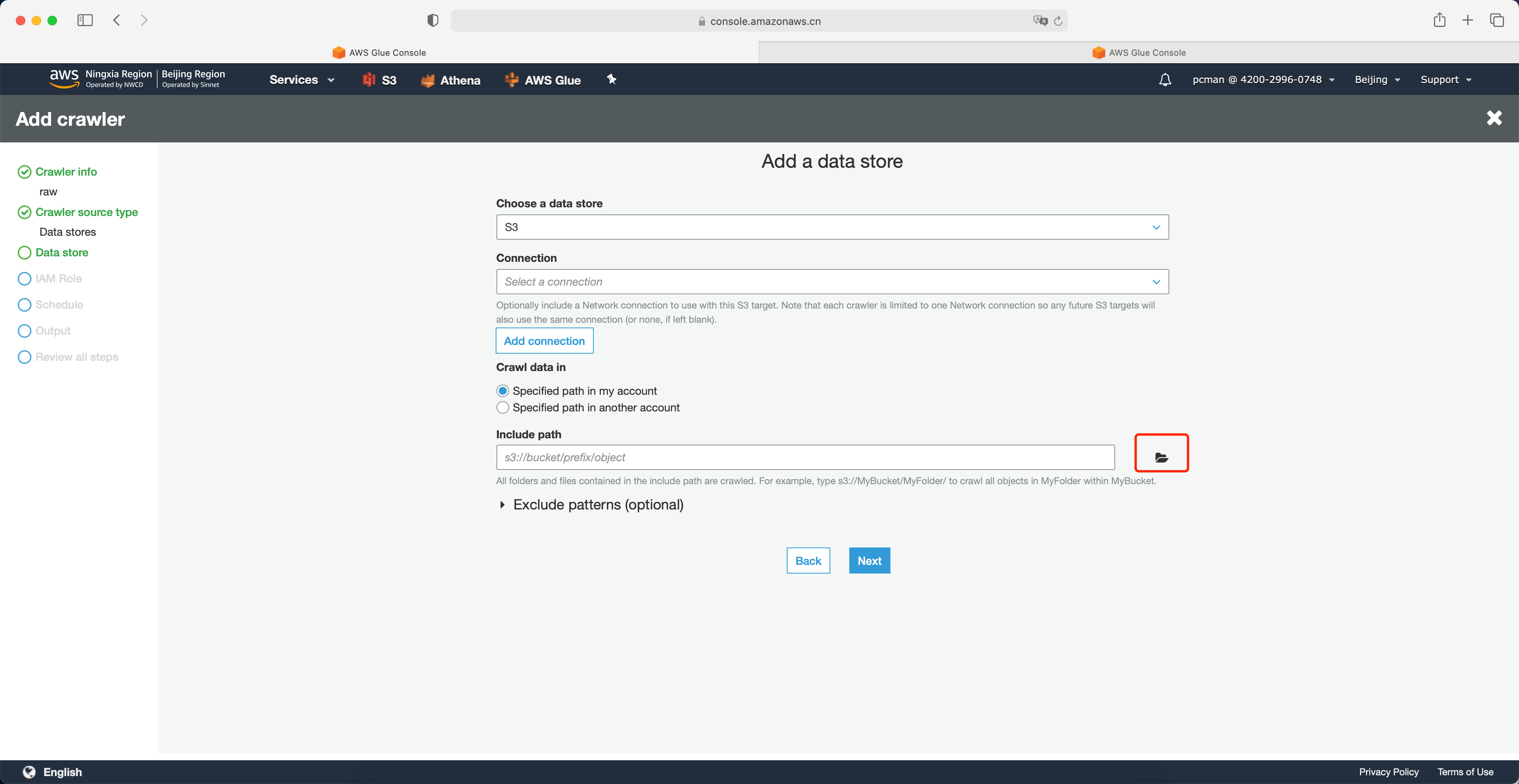
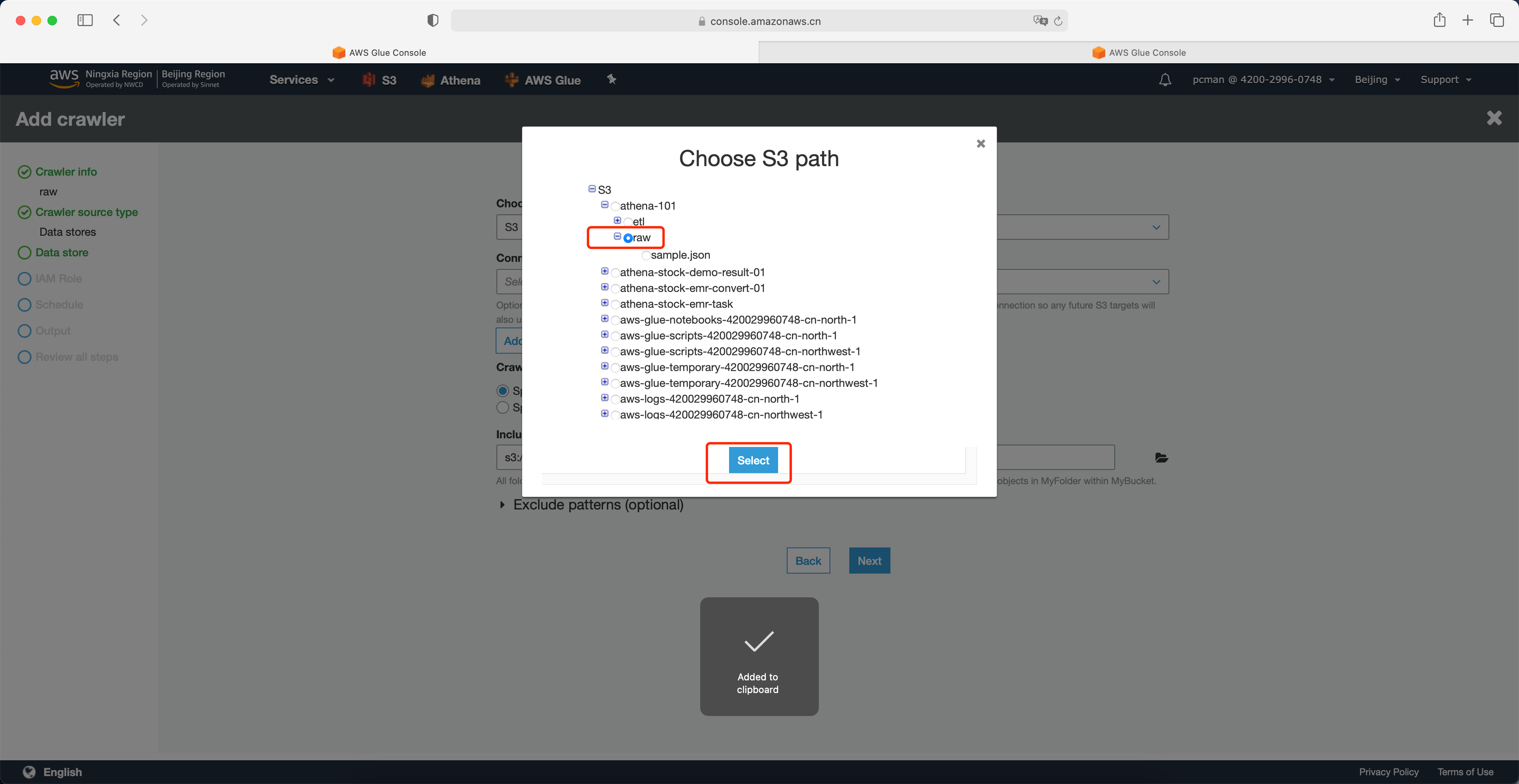
选择S3存储桶中,原始数据所在的raw目录。注意,这一步不要选择单个文件,而是原则目录。Glue会扫描整个目录内的多个文件。然后点击选中。如下截图。
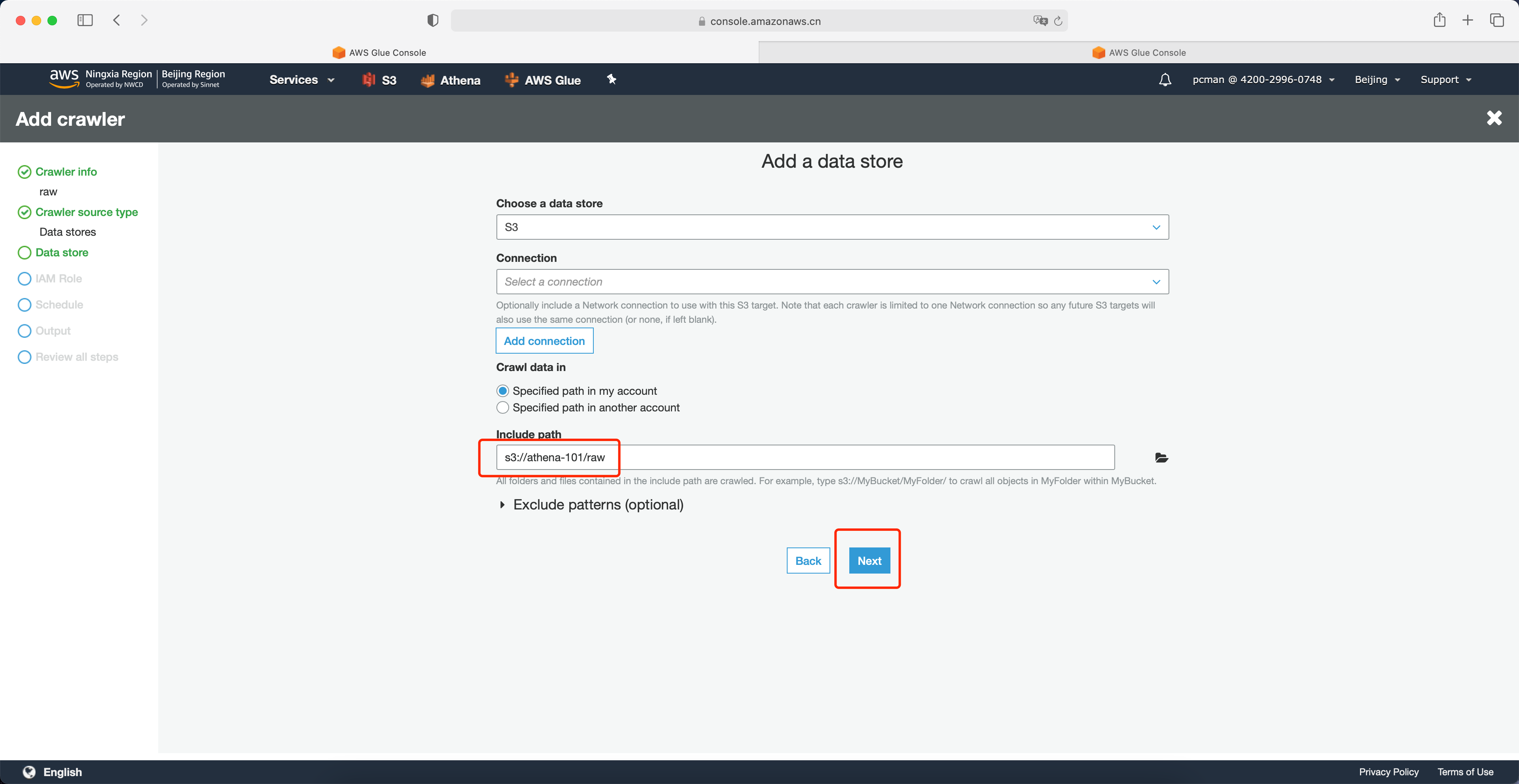
设置好路径之后,点击下一步。如下截图。
在下一个数据源位置,点击否,点击下一步。如下截图。
在角色配置页面,选择使用一个已经存在的IAM Role,从下拉框中选择实验第一步配置的角色,然后点击Next下一步继续。如下截图。
在频率位置选择按需运行,点击下一步继续。如下截图。
在输出位置选择数据库是前文创建的Glue数据库名字,再点击下一步继续。注意可选配置项目不需要展开,直接下一步即可。如下截图。
在配置界面点击完成。如下截图。
在爬网程序的清单页面,点击运行按钮。如下截图。
等待大约1分钟后,爬网程序运行完成。在页面右侧可以看到添加表的数量是1张。如下截图。
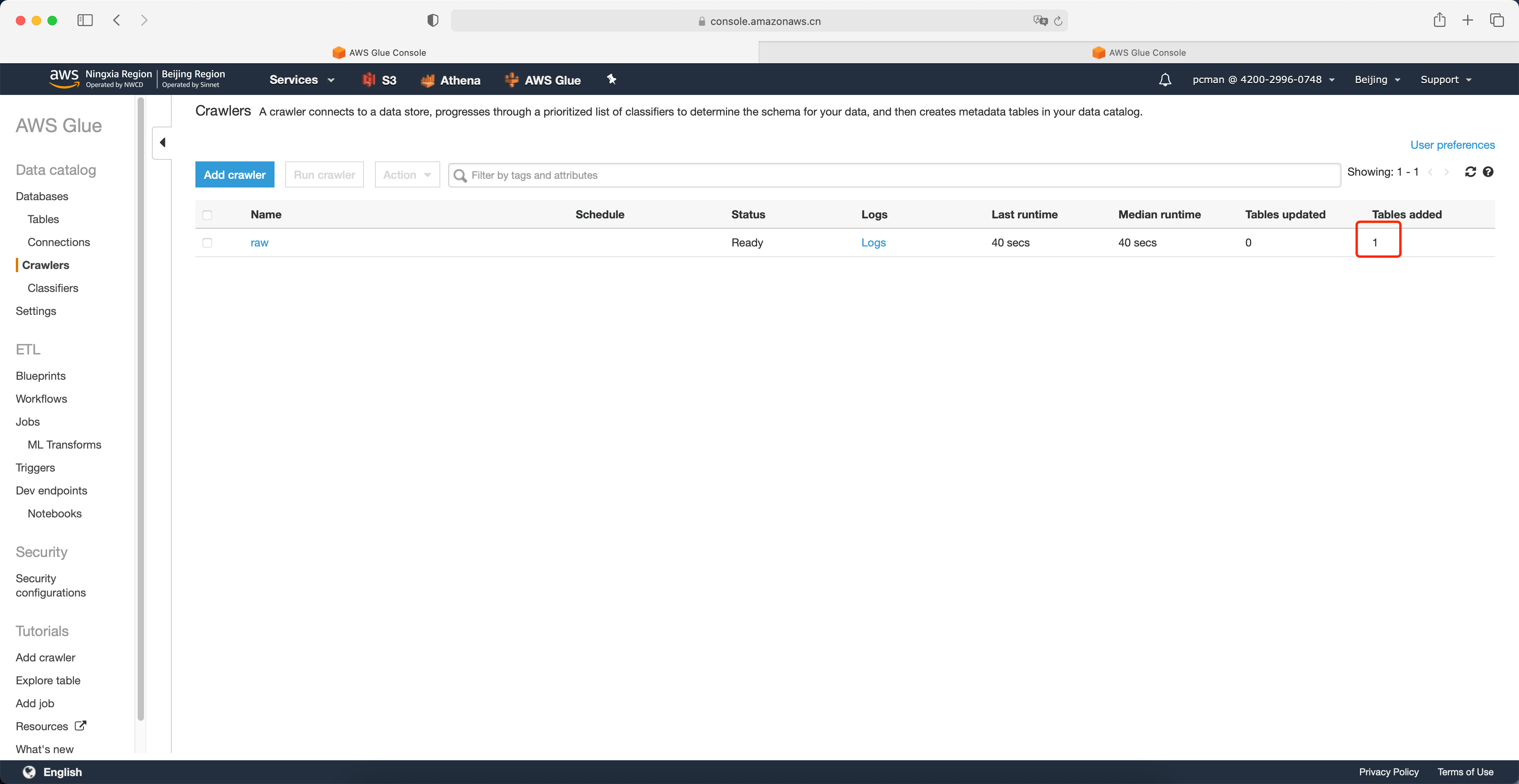
接下来回到表界面,可以看到爬网程序生成的表名字。点击名字查看详情。如下截图。
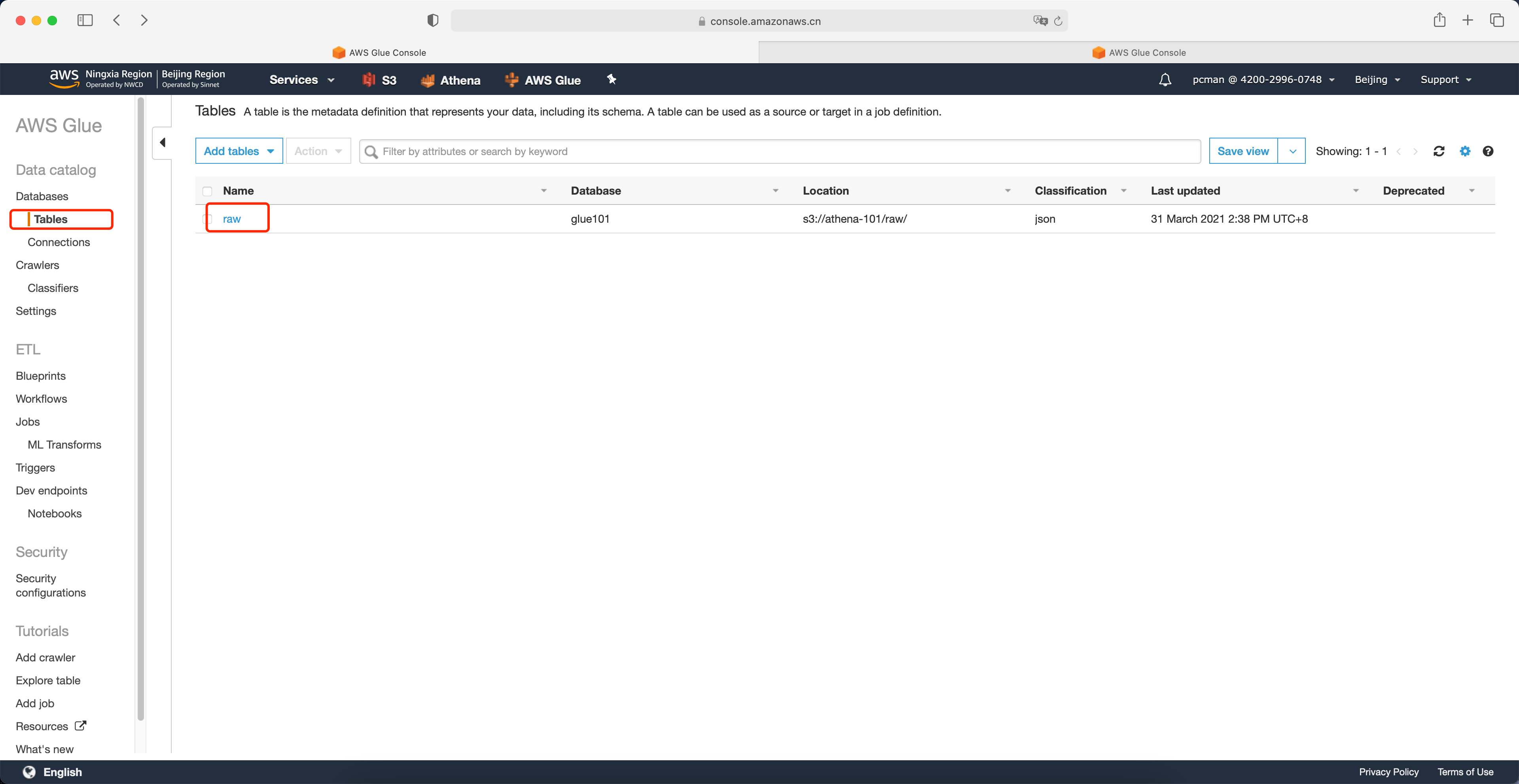
在页面的下方可以看到表的Schema。如下截图。
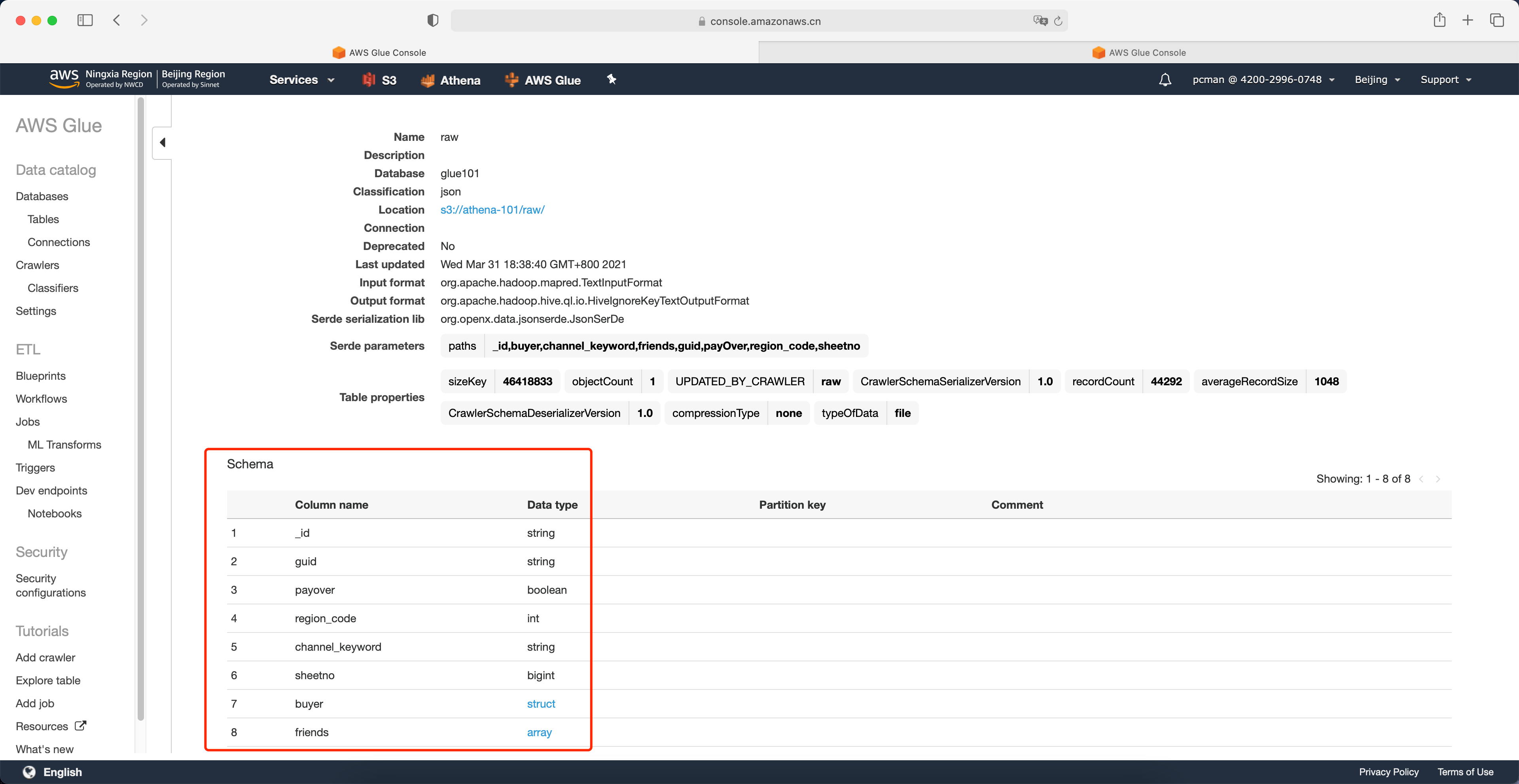
至此Glue生成数据目录完成。
3、使用Athena查询
进入Athena服务,从数据源中选择AwsDataCatalog,从Database下拉框中选择glue101即前文生成的数据库。左下方即列出库内的表 raw 是上一步有Glue爬网程序生成的表。点击右侧的小箭头,选择预览,此时右侧将生成查询代码。
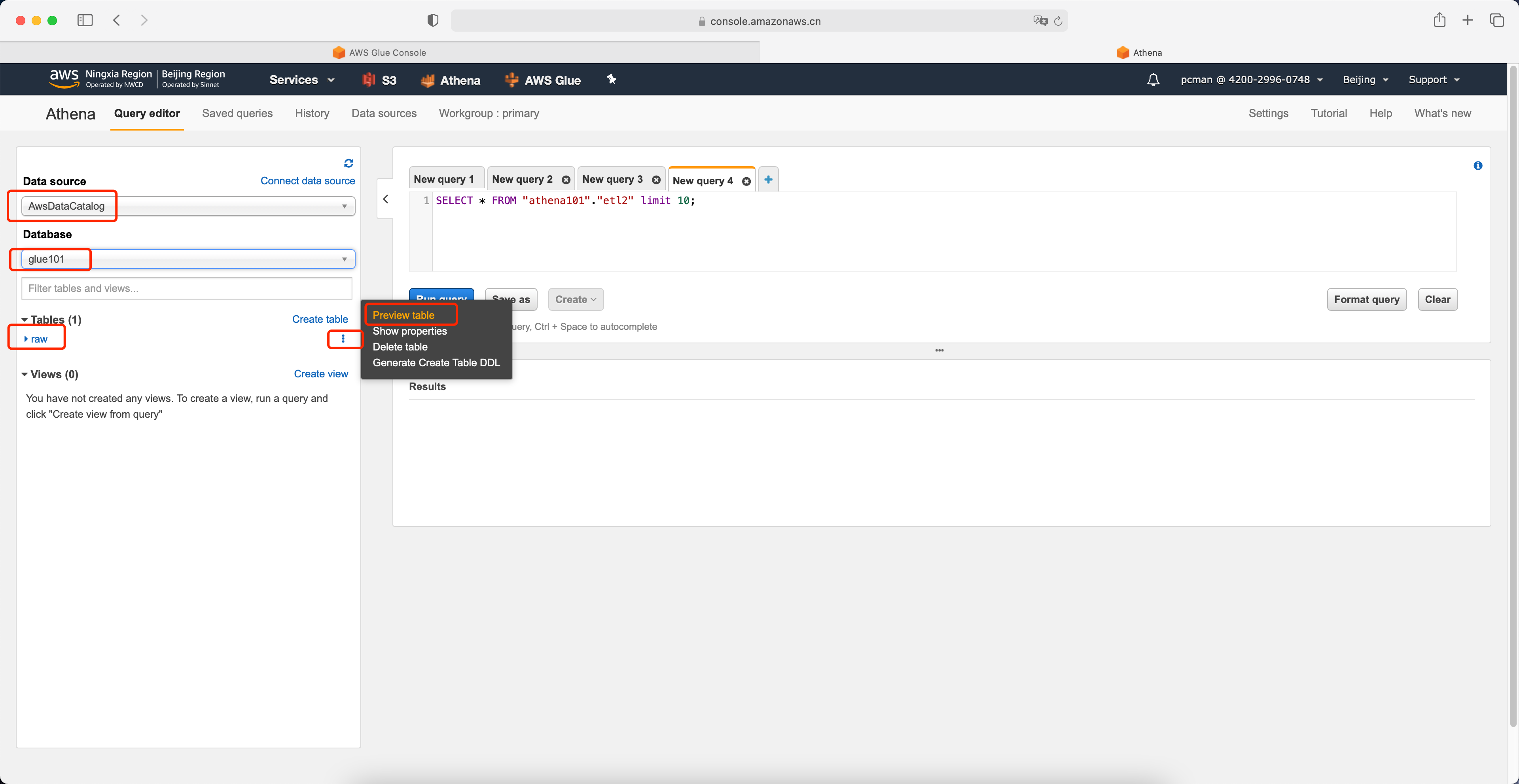
运行预览功能生成的SQL语句,即可返回Athena的第一个查询结果。如下截图。
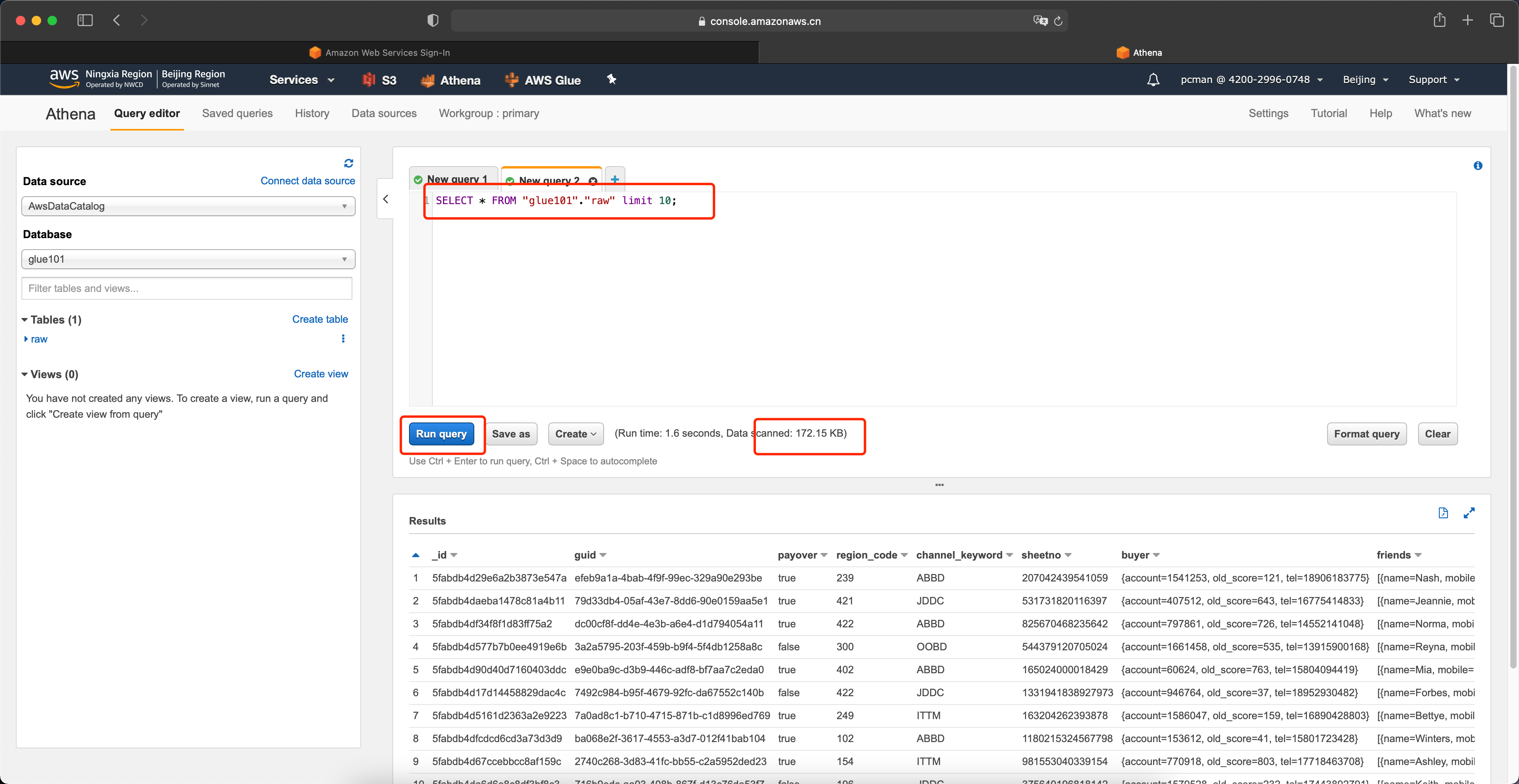
现在我们测试下如下语句的查询结果,并观察其扫描的数据。
SELECT count("_id") FROM "glue101"."raw";运行后可获知,本条查询结果为100000行,共计扫描了44.27MB。
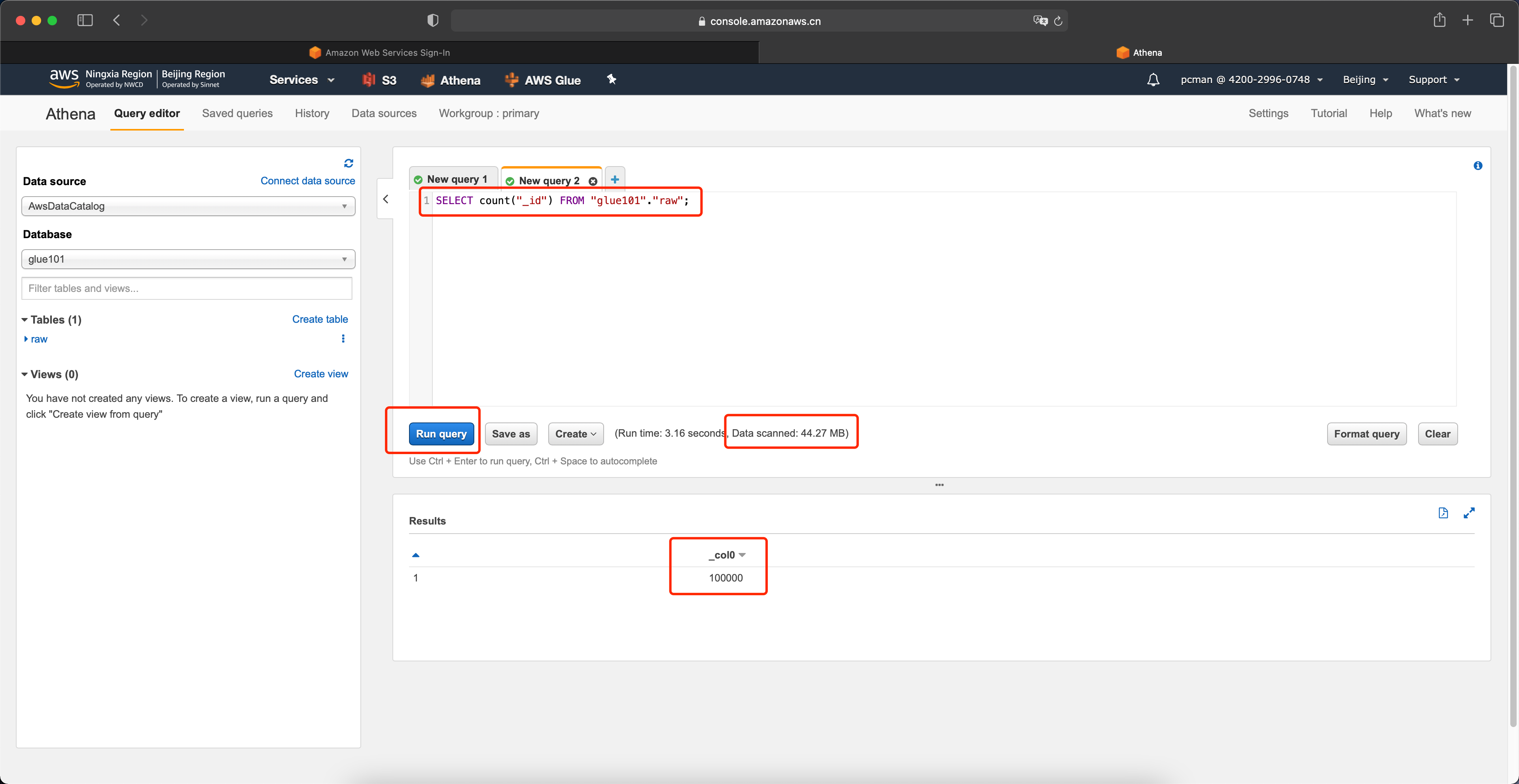
由于Athena是按照被扫描的数据量计费的,这里扫描100000行也就是全量,会产生不必要的费用,因此接下来将通过转换数据格式,将JSON格式转换为列格式,并进行压缩,以降低查询扫描的数据量。
三、使用Glue进行数据转换并通过Athena进行查询
1、使用Glue进行数据格式转换
本实验将使用Glue完成以下工作:
- 原始JSON中的某个字段是嵌套字段,进行展平
- 转换为Parquet列格式(并压缩)
进入Glue界面,在左侧菜单中点击作业,点击新建作业。如下截图。
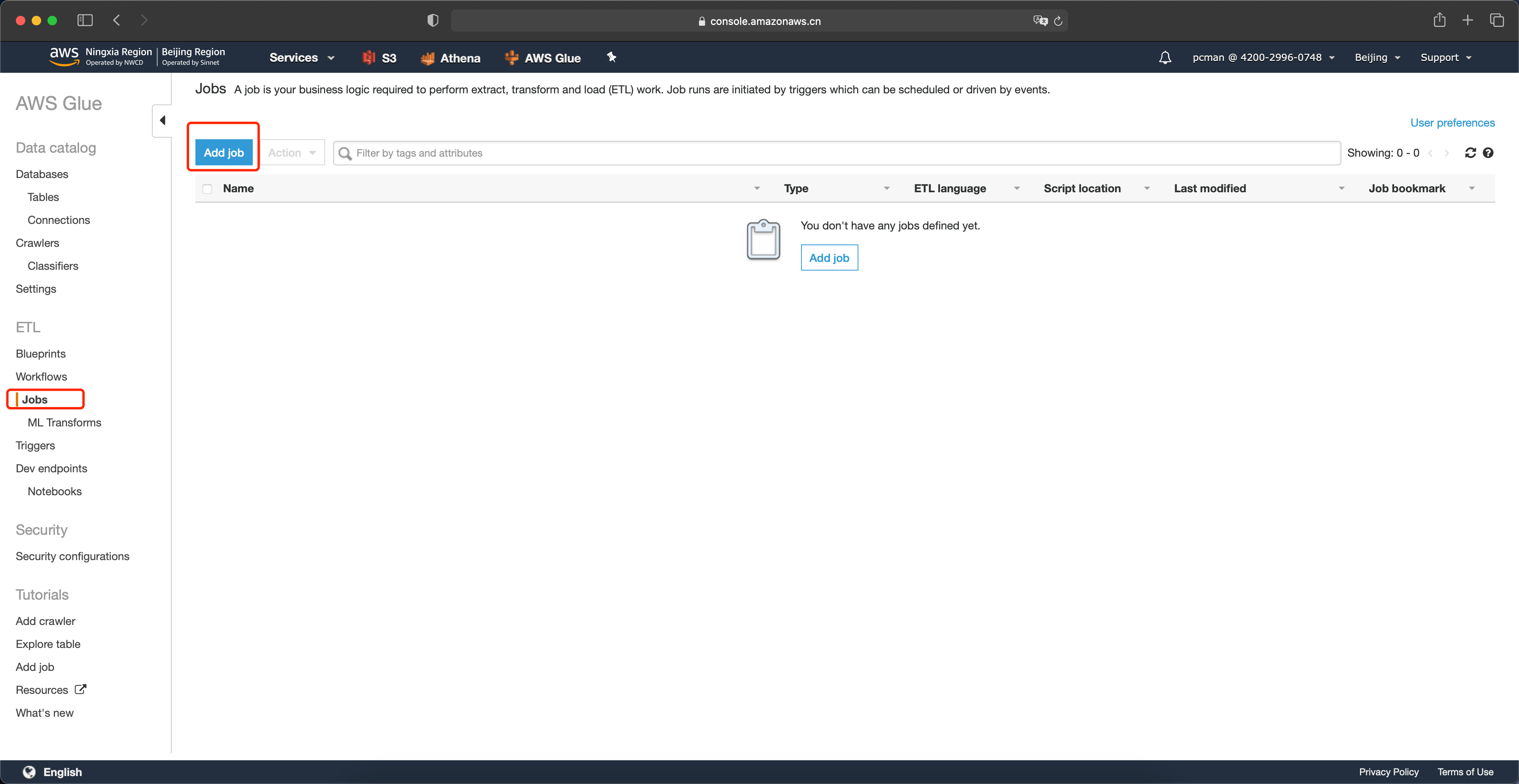
在Glue创建作业的界面上,输入新作业的名称,选择IAM Role是本实验第一步创建的角色,然后其余选项都保持默认,点击页面最下方的下一步按钮。如下截图。
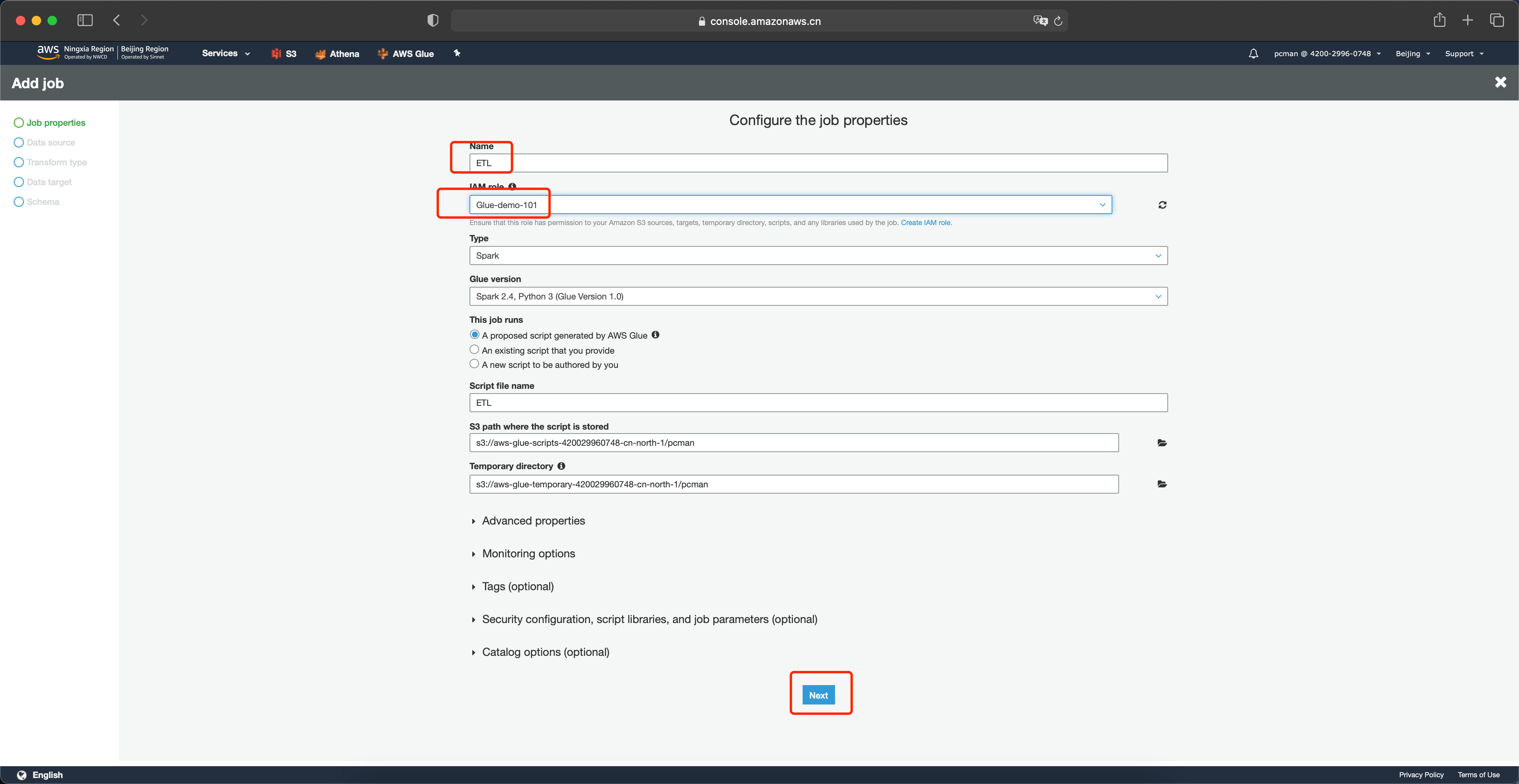
选择要转换的数据源是上一步由爬网程序扫描到的原始数据raw。并点击下一步继续。如下截图。
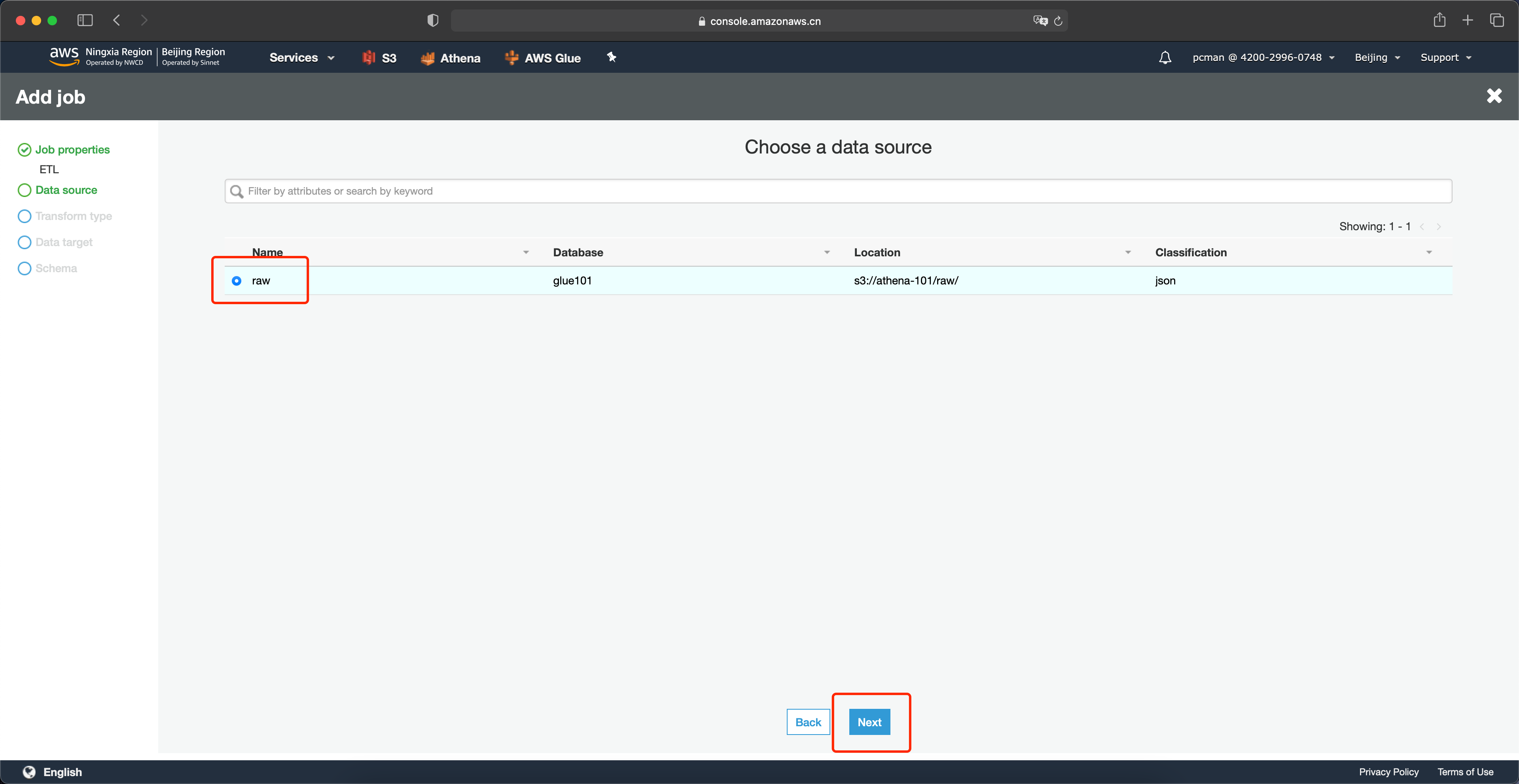
在转换类型位置点击修改架构。如下截图。
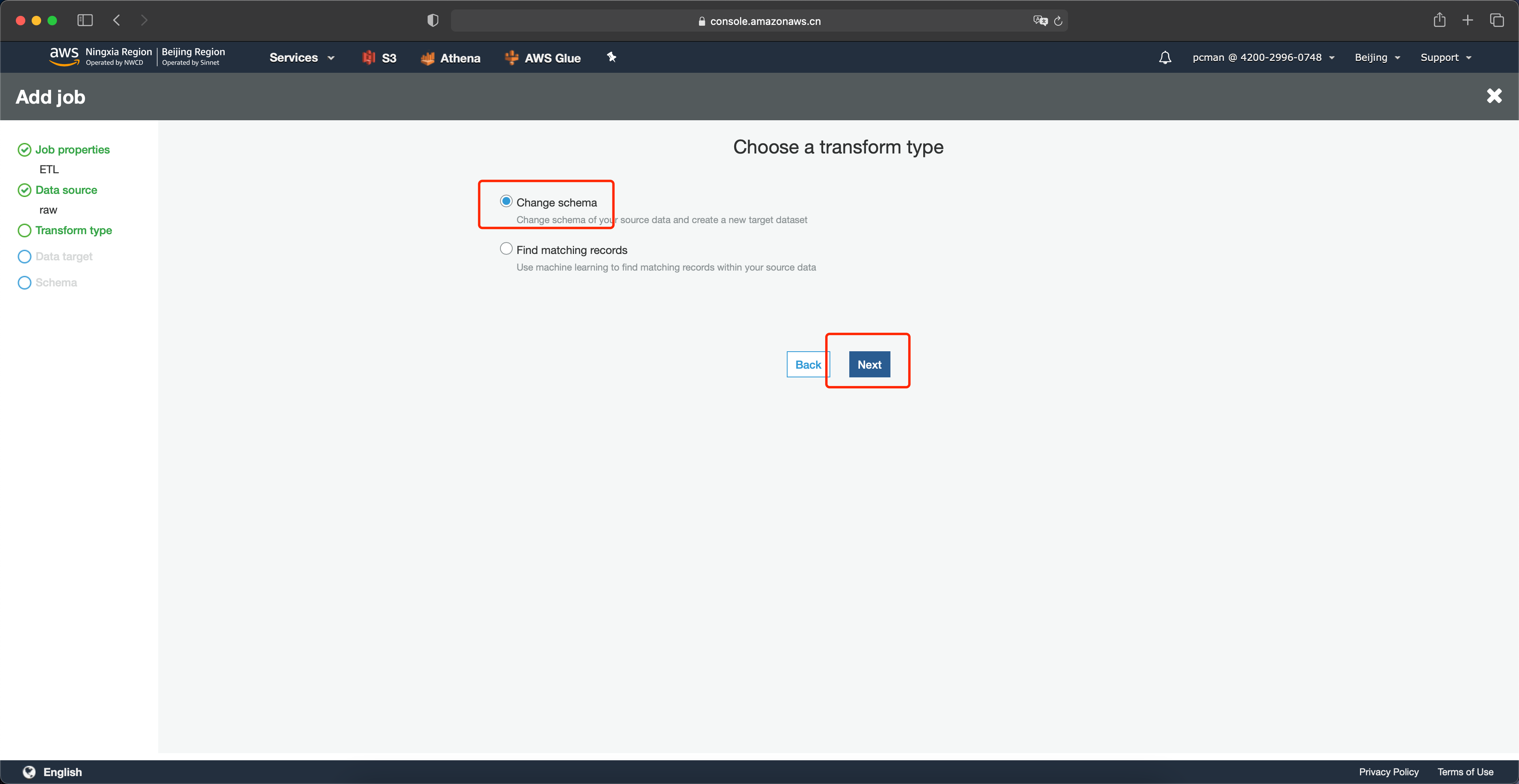
在数据目标架构这一步,首先选择页面上放的第一个架构——创建新的表,在右侧选择数据类型是Amazon S3,在格式位置选择Parquet,在目标路径这里点击浏览按钮。如下截图。
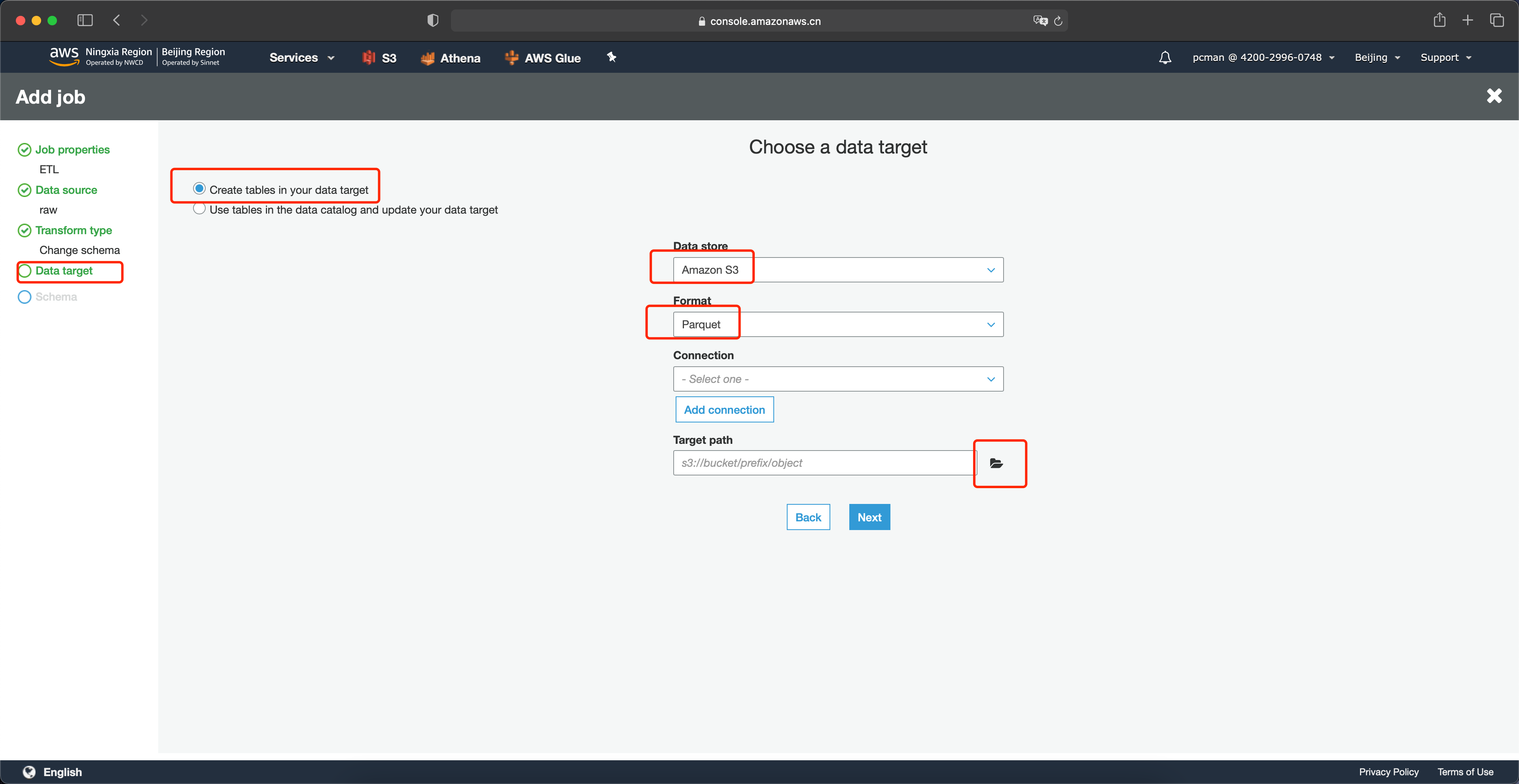
在选择目标存储桶的位置,选择同一个存储桶下的另一个目录,名为etl,即稍后Glue会将转换后的数据存放在这个目录下。
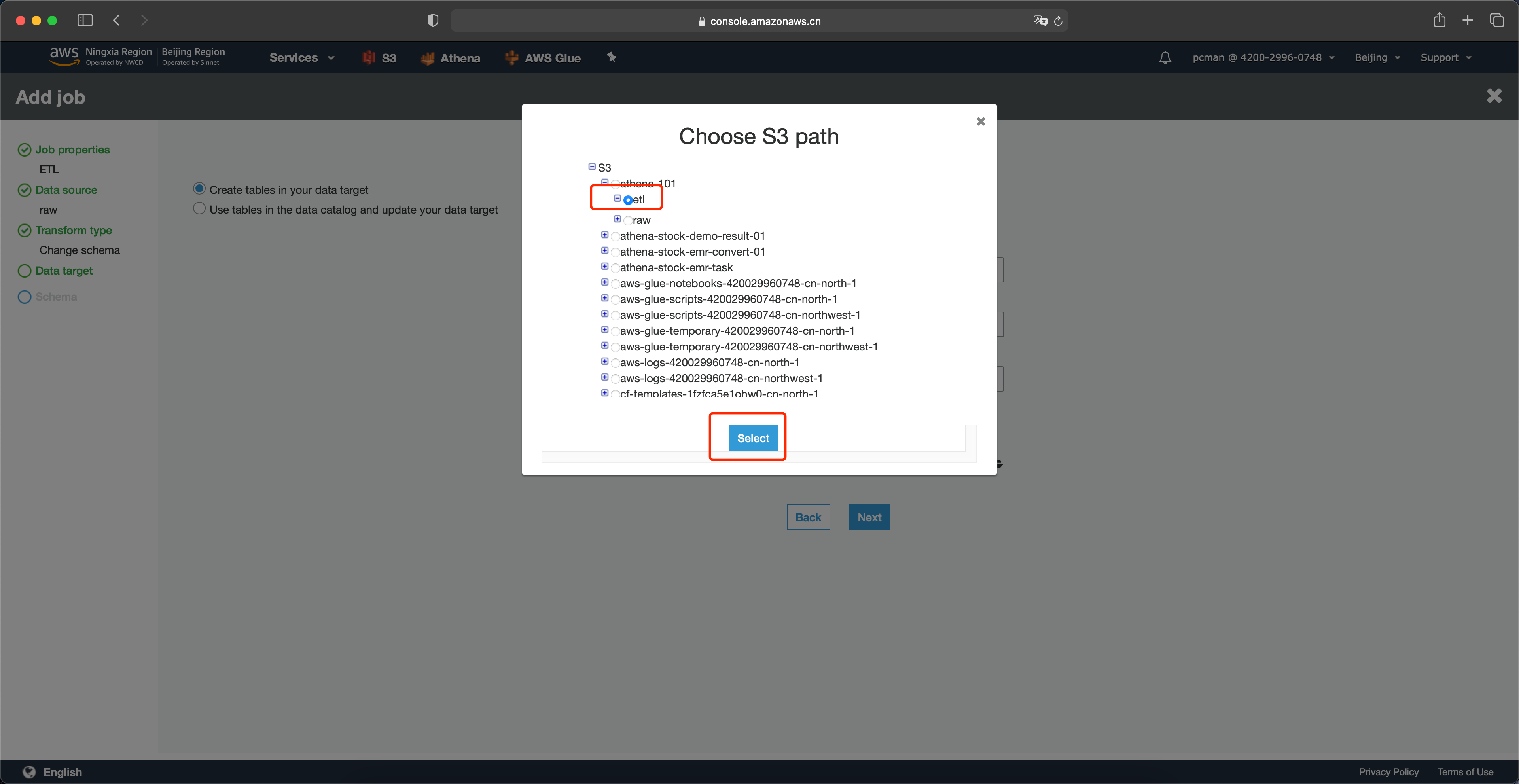
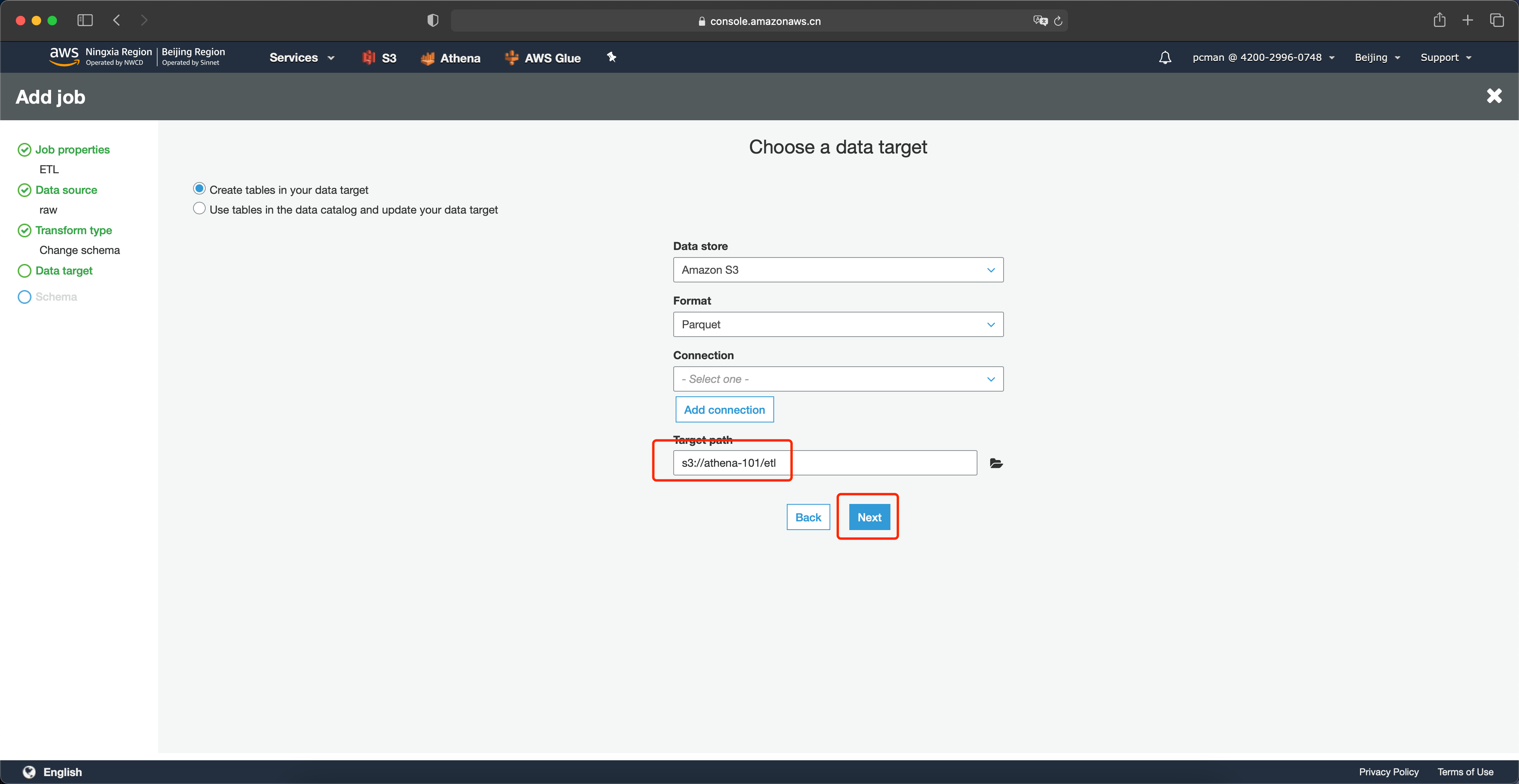
在选择存储桶后的界面上,点击下一步继续。如下截图。
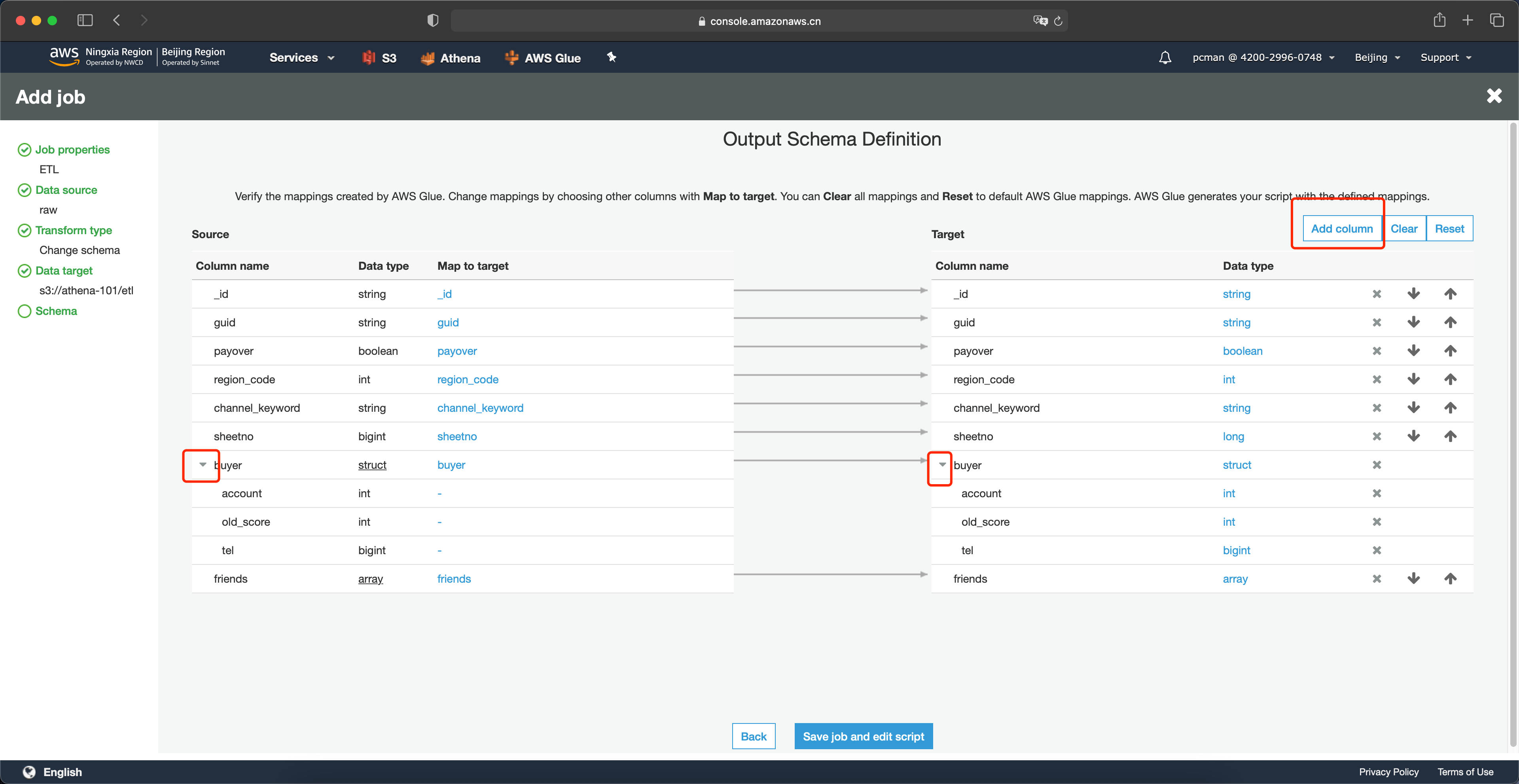
在字段映射界面上,接下来进行展平。点击要展平的 buyer 列前的小箭头,即可展开嵌套的列。然后点击右上角的增加列按钮。如下截图。
在添加列的界面上,输入列的名字为 buyer_account 表示展平后的列名称,类型选择int与源数据保持同一类型。然后点击添加按钮。如下截图。
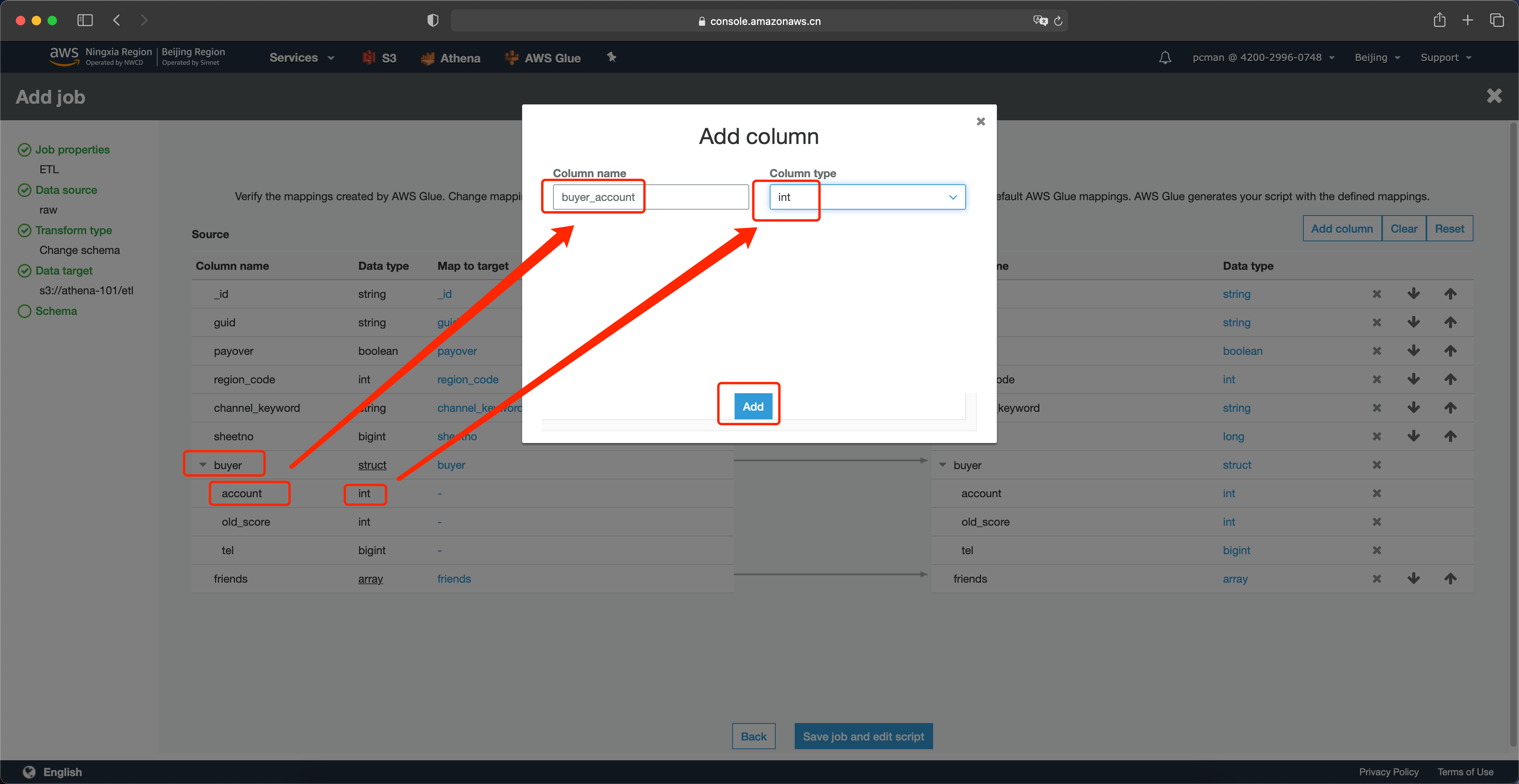
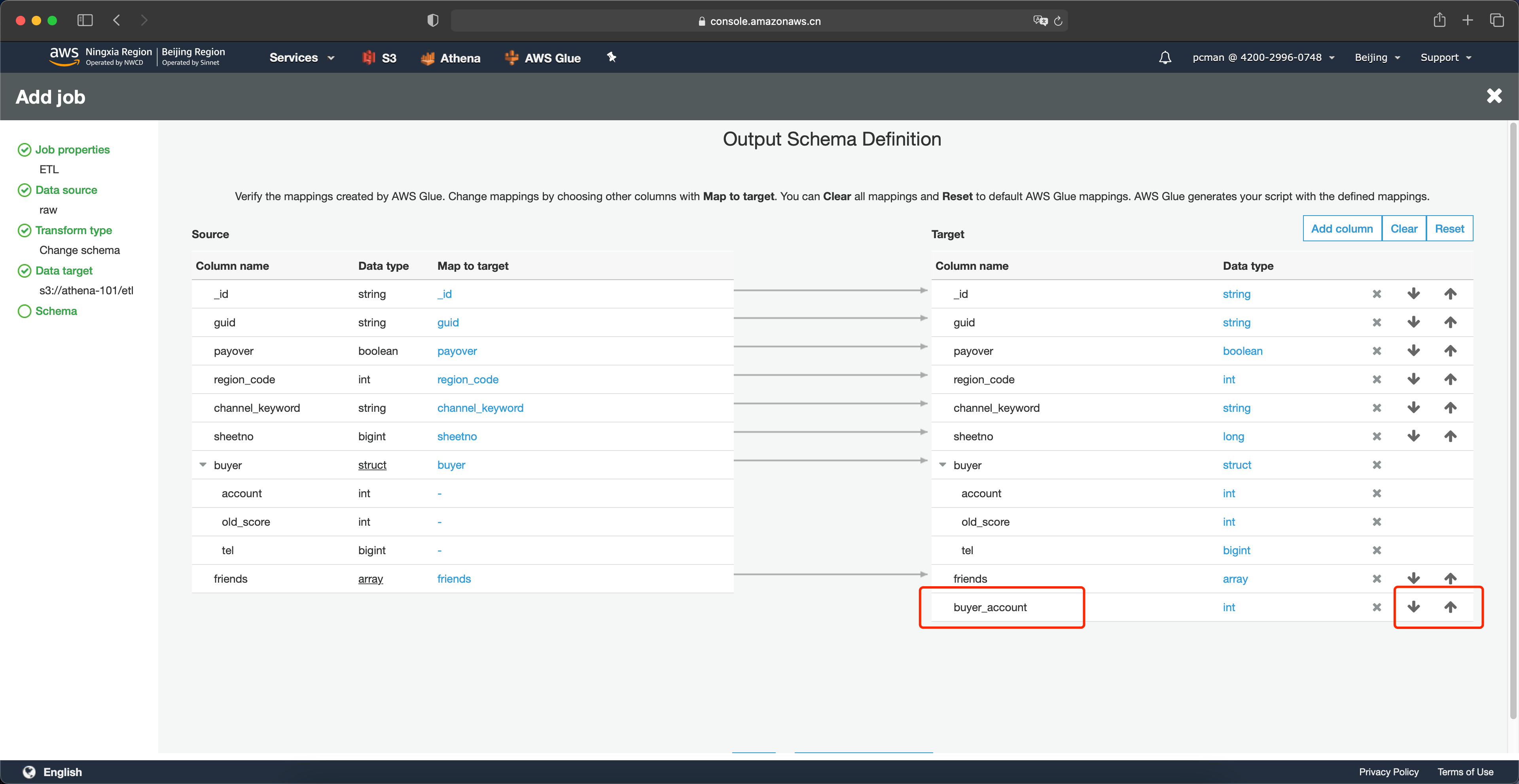
添加列完成后,可以在右侧的下方看到新加入的列。并且可以通过上下箭头移动这一列的前后位置。如下截图。
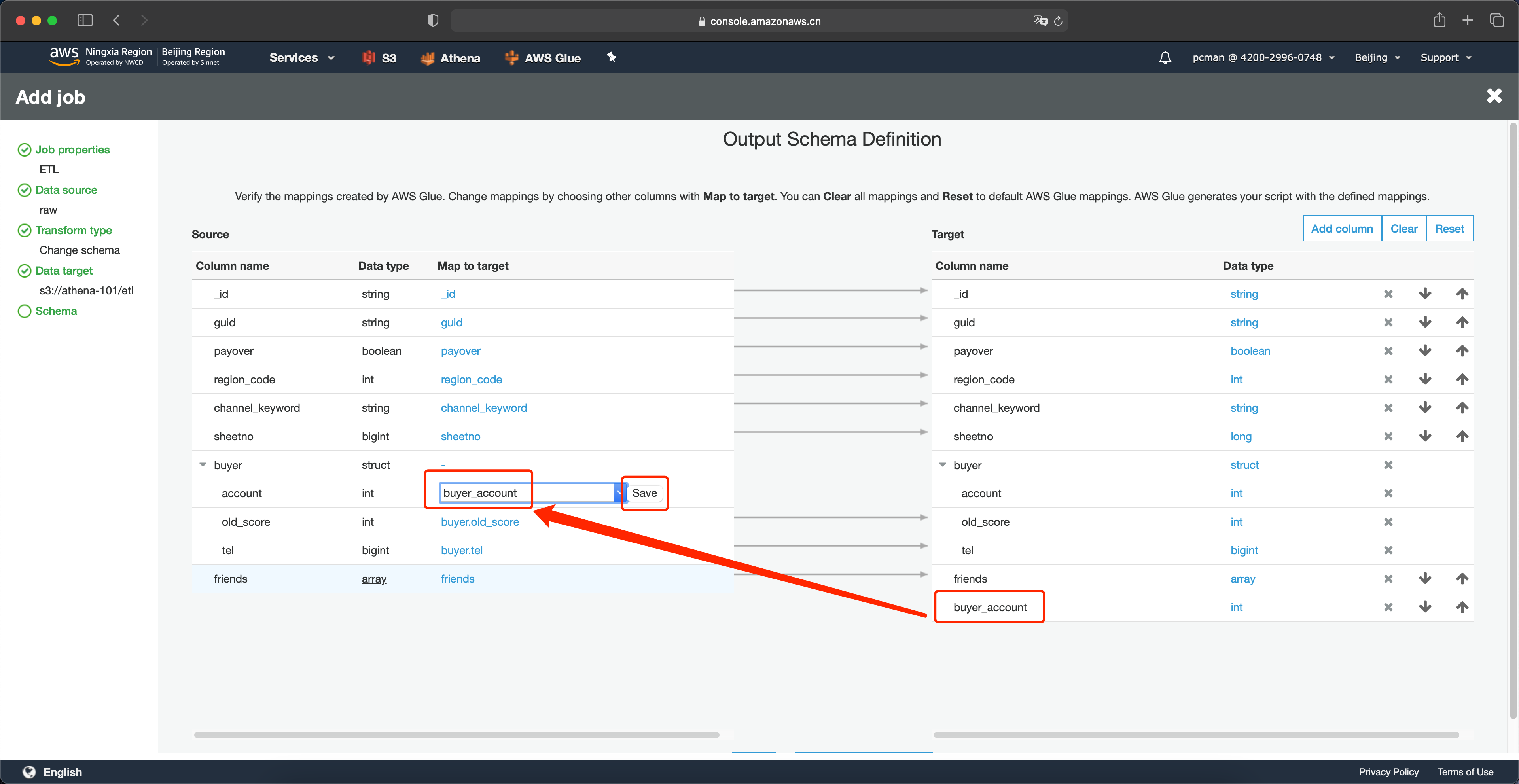
接下来调整列的映射关系。在左侧原始数据的架构上,找到要展平的account列,点击映射为这里的空白位置,就会出现下拉框,然后将其映射关系选择为buyer_account,并点击save按钮。这里要注意,在下拉框中,会出现两个相似的名字,其中格式为buyer.account表示的是嵌套关系,而buyer_account是上一个步骤创建的展平后的列,这里要注意区分,选择带有下划线的这个新列。然后点击保存按钮。如下截图。
这里就完成了嵌套字段里第一个字段的映射,可以看到系统自动生成了一条斜线。
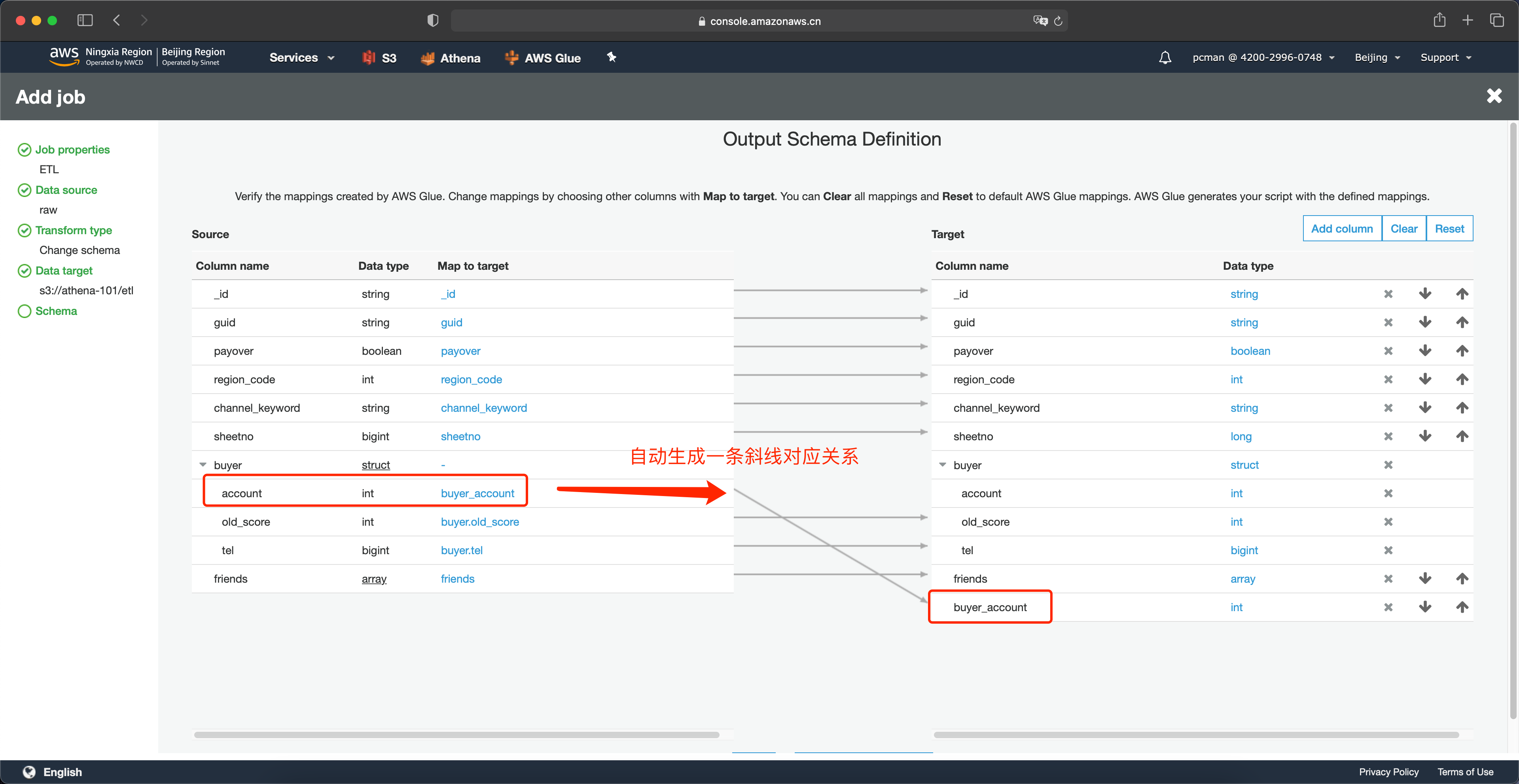
接下来如法炮制,将另外两个字段也做好映射。如下截图。
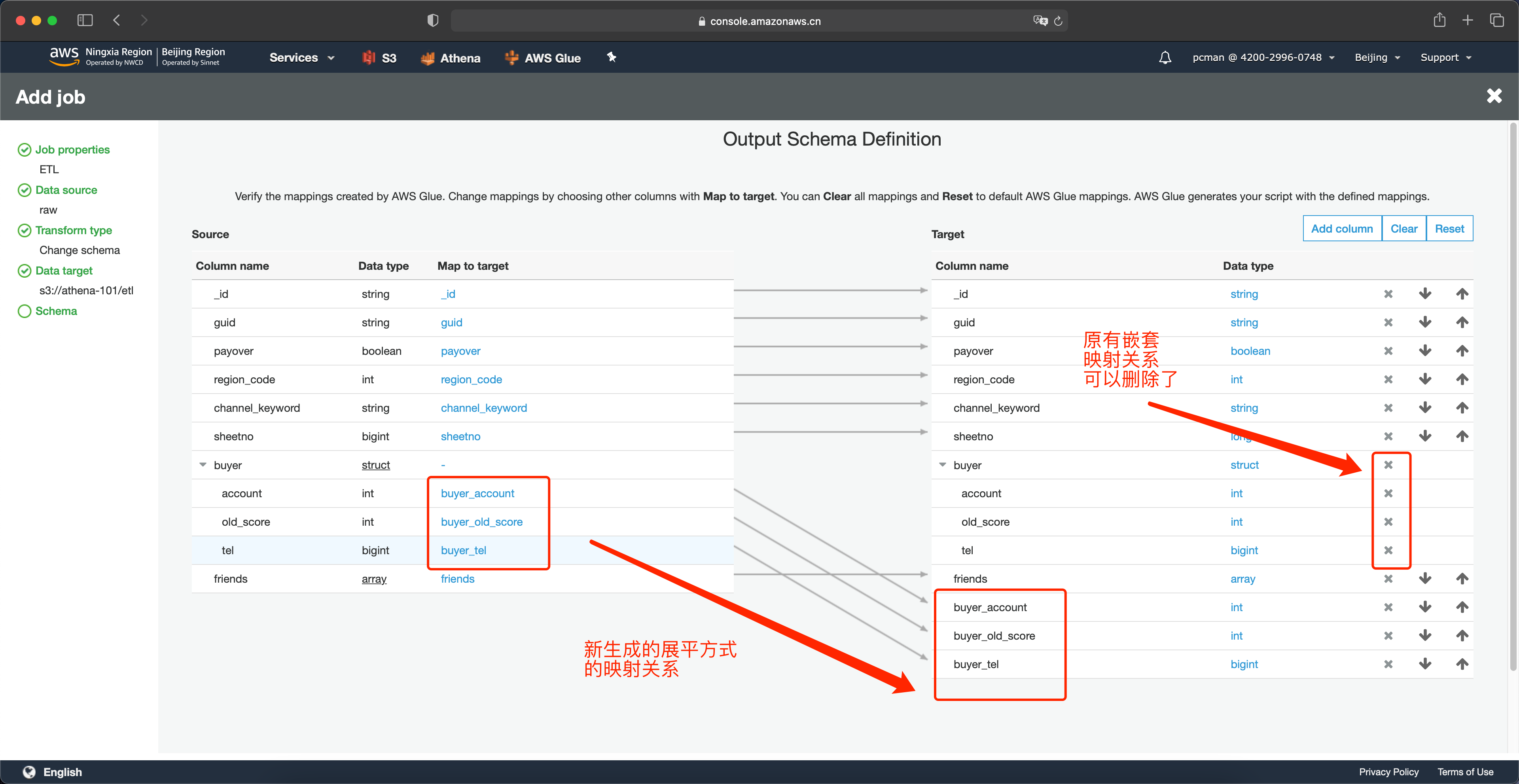
映射完毕最后一步,是要删除掉原油的嵌套映射关系。点击右侧目标架构的 X 图标即可删除掉。删除后的映射关系如下。接下来可以点击页面最下方的保存作业并编辑脚本按钮。如下截图。
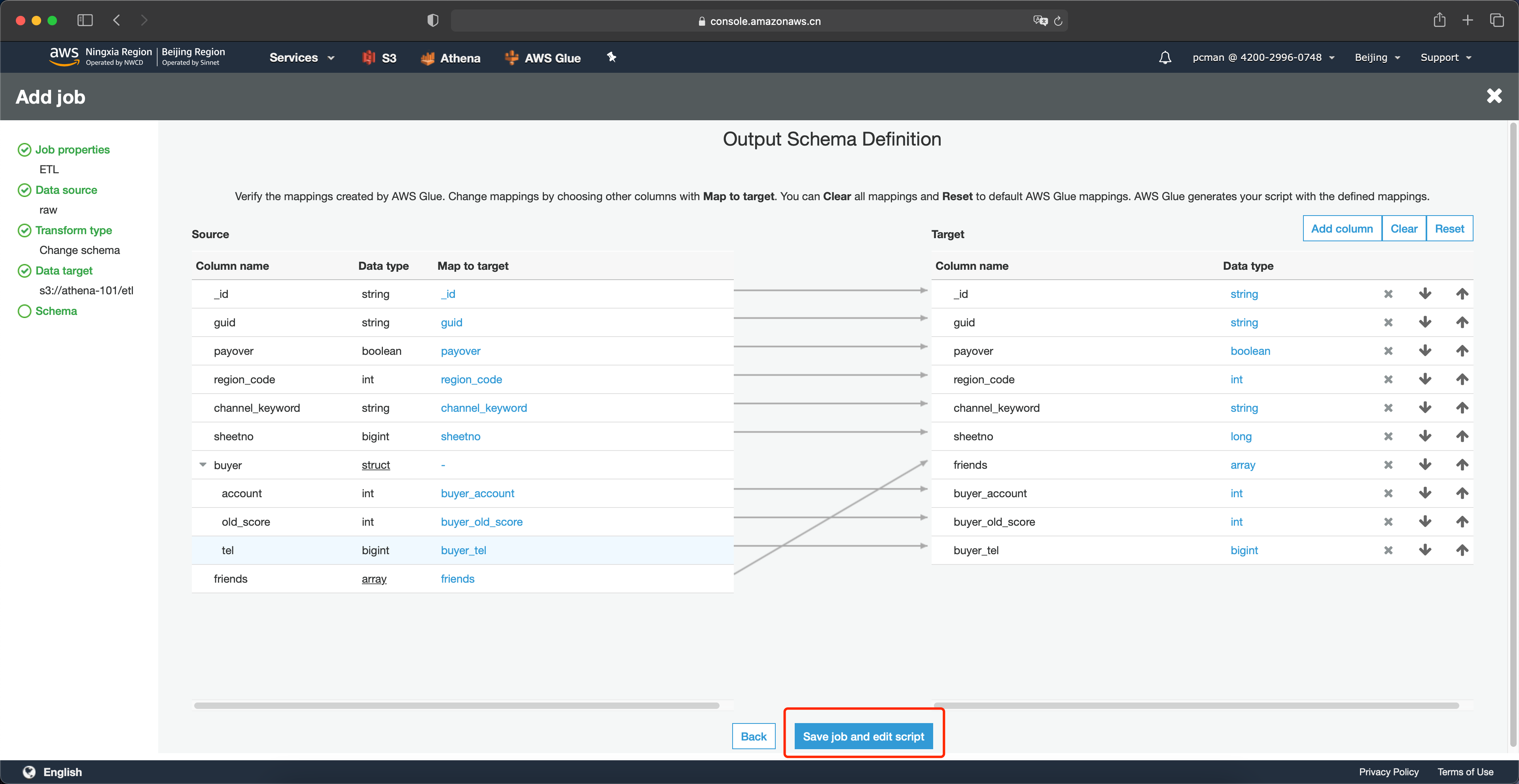
在系统自动生成的编辑Python脚本界面,无需修改,先点击保存按钮,然后点击运行任务。如下截图。
点击运行任务后,会弹出任务配置可选项。不做任何修改,直接点击运行任务。
运行任务需要5-10分钟。
等待5-10分钟后,可以看到页面下方输出了日志,任务转换完成。如下截图。
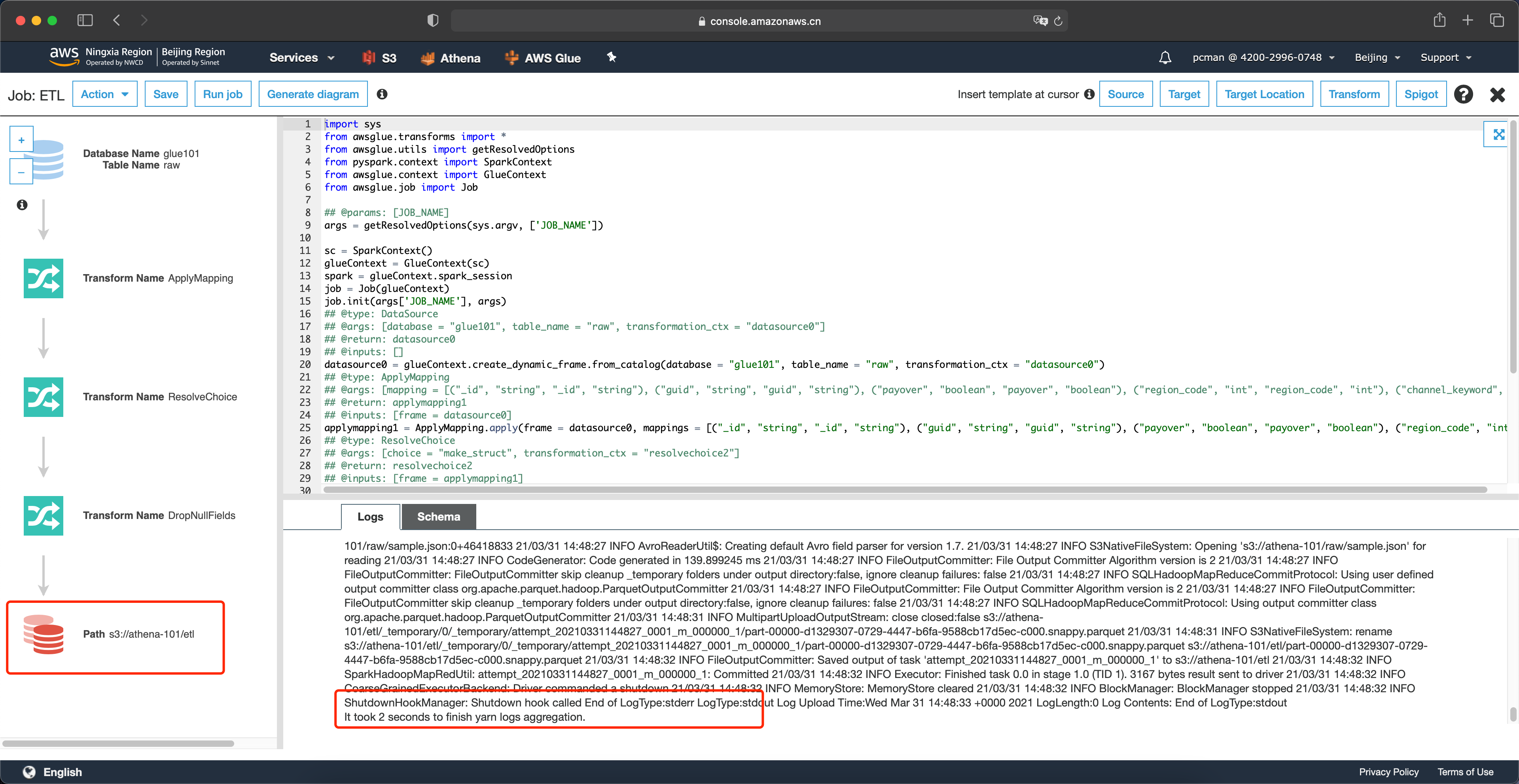
现在我们就可以在存储桶内,看到转换为parquet格式的数据了。通过S3界面可以看到,44MB的数据转换后大小仅为3.8MB,体积只有原先的十分之一。如下截图。
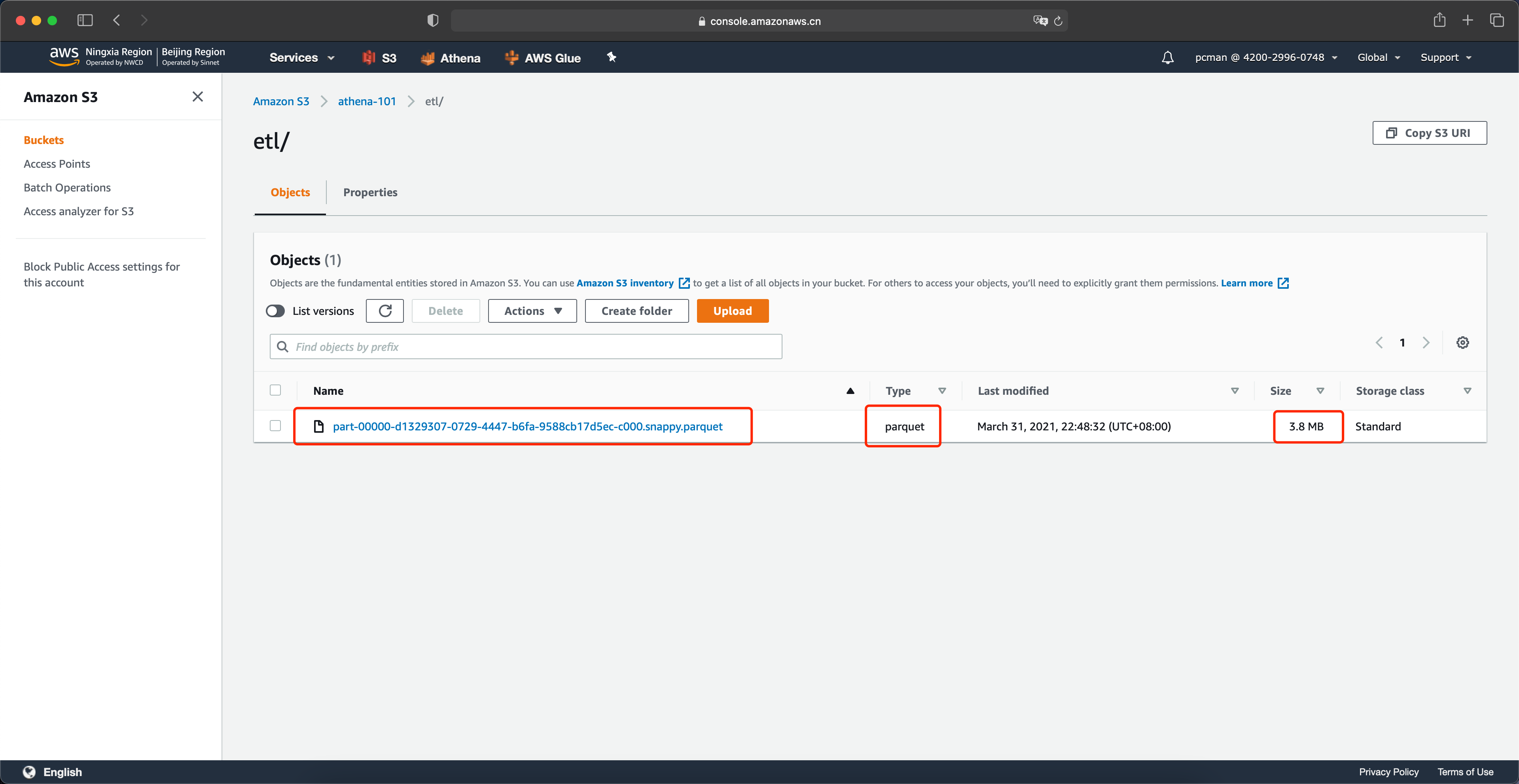
数据转换完成。
2、使用Glue重新爬取转换后的数据结构
要在Athena上查询转换后的数据,还需要让Glue的爬网程序去爬取新的etl目录。如下截图。
输入爬网程序的名称,例如etl表示爬取原始数据。并点击Next继续。如下截图。
数据类型位置保留页面默认值,点击下一步继续。如下截图。
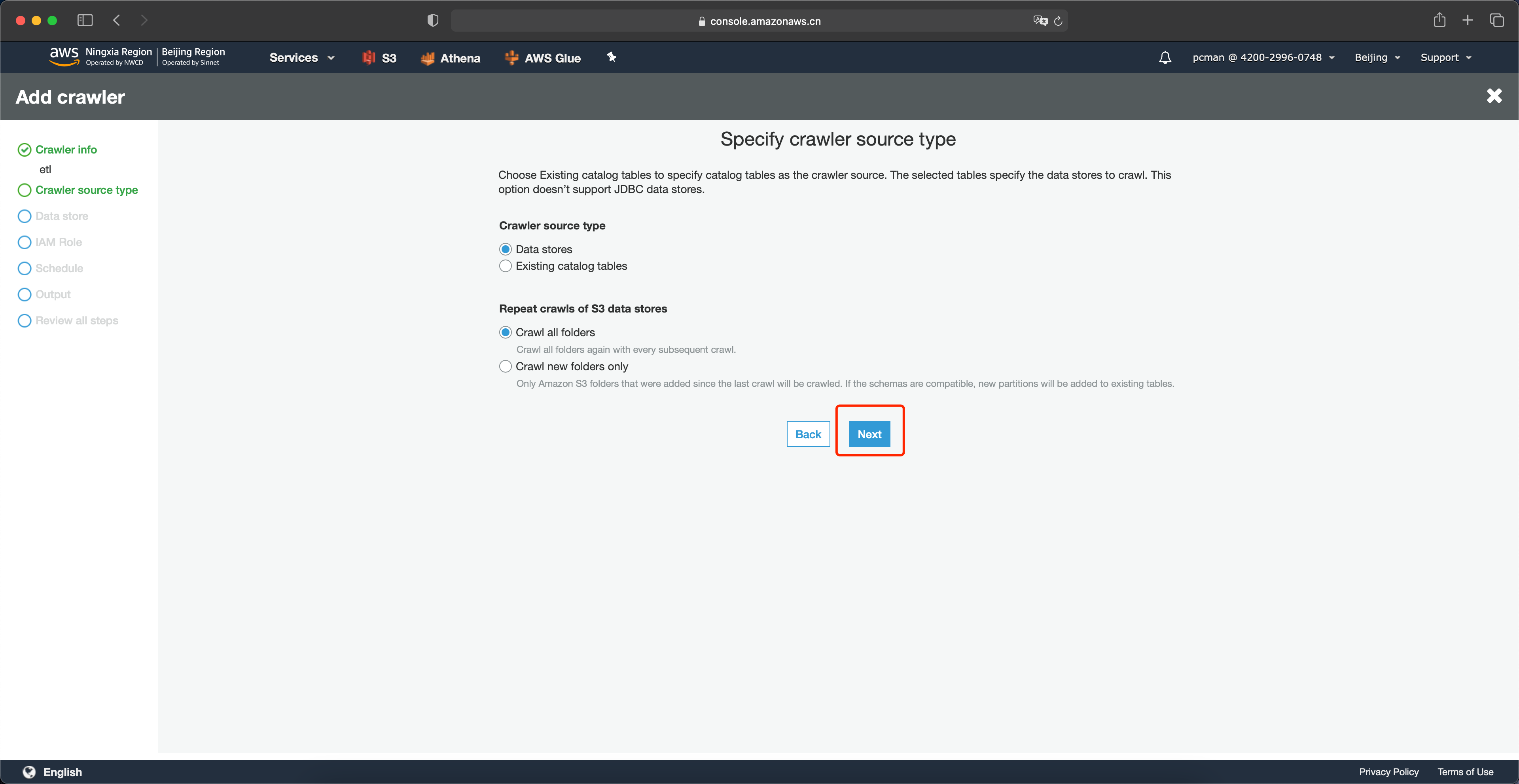
数据类型位置保留页面默认值,点击下一步继续。如下截图。
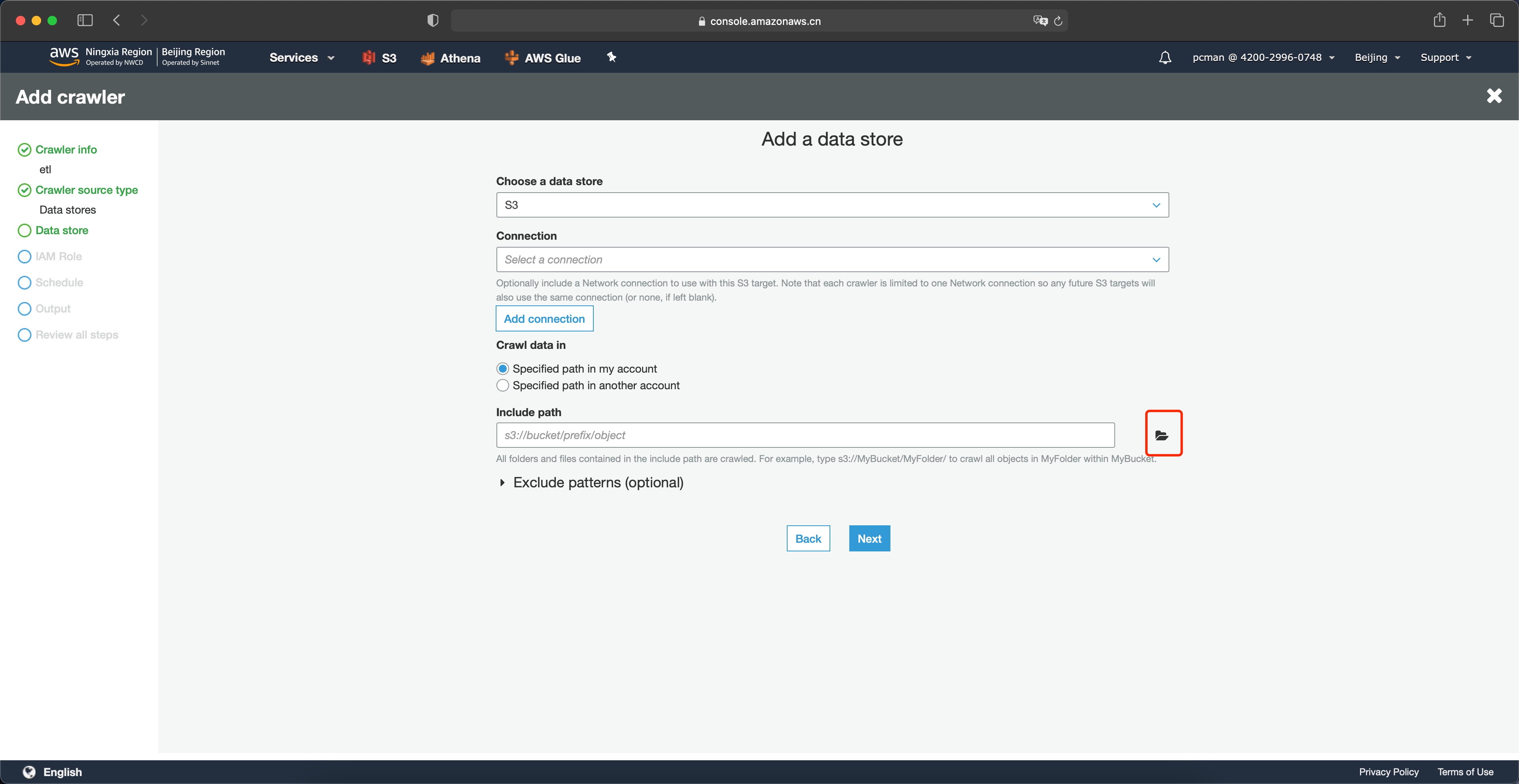
选择S3存储桶中,转换过的数据所在的etl目录。注意,这一步不要选择单个文件,而是原则目录。Glue会扫描整个目录内的多个文件。然后点击选中。如下截图。
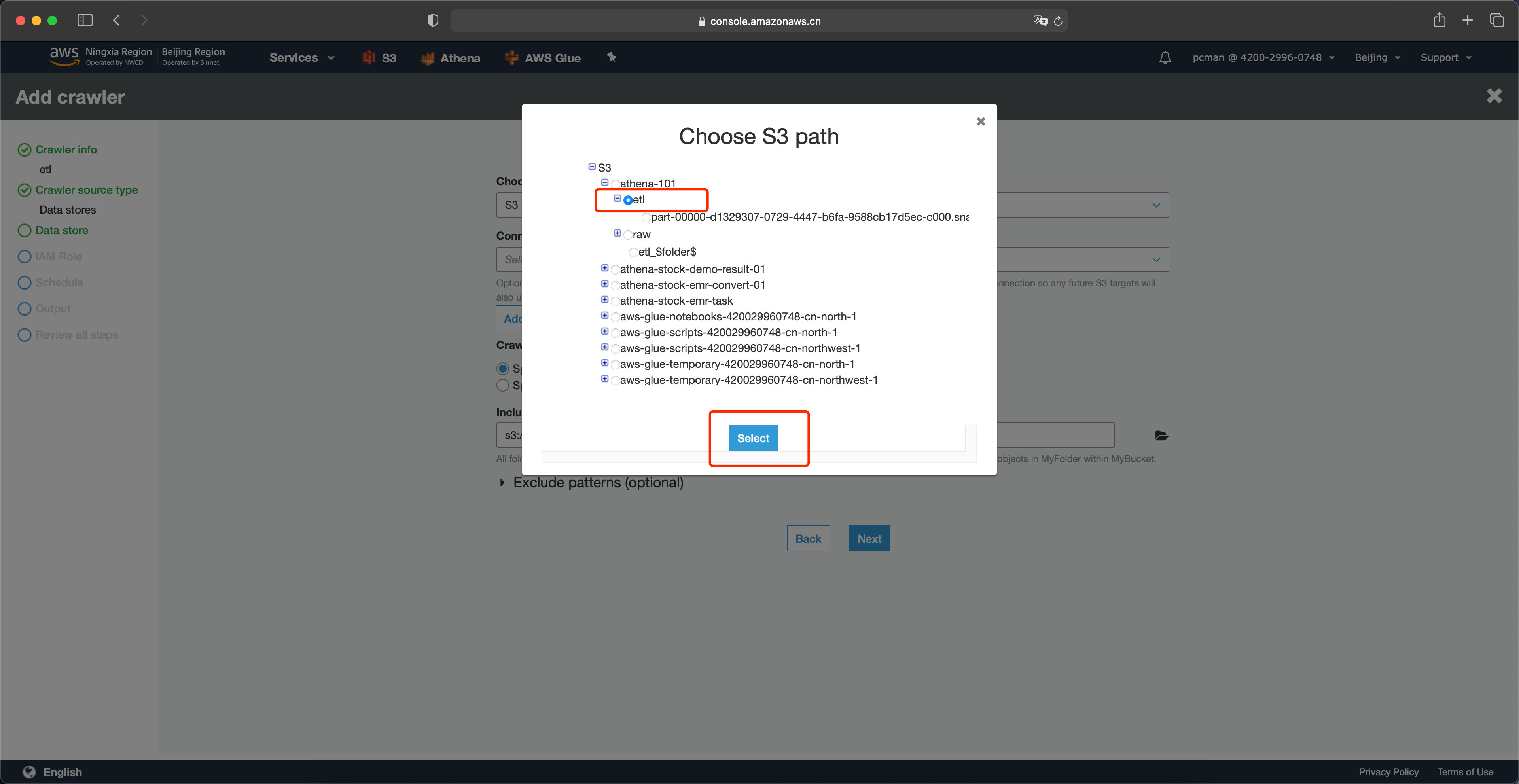
设置好路径之后,点击下一步。如下截图。
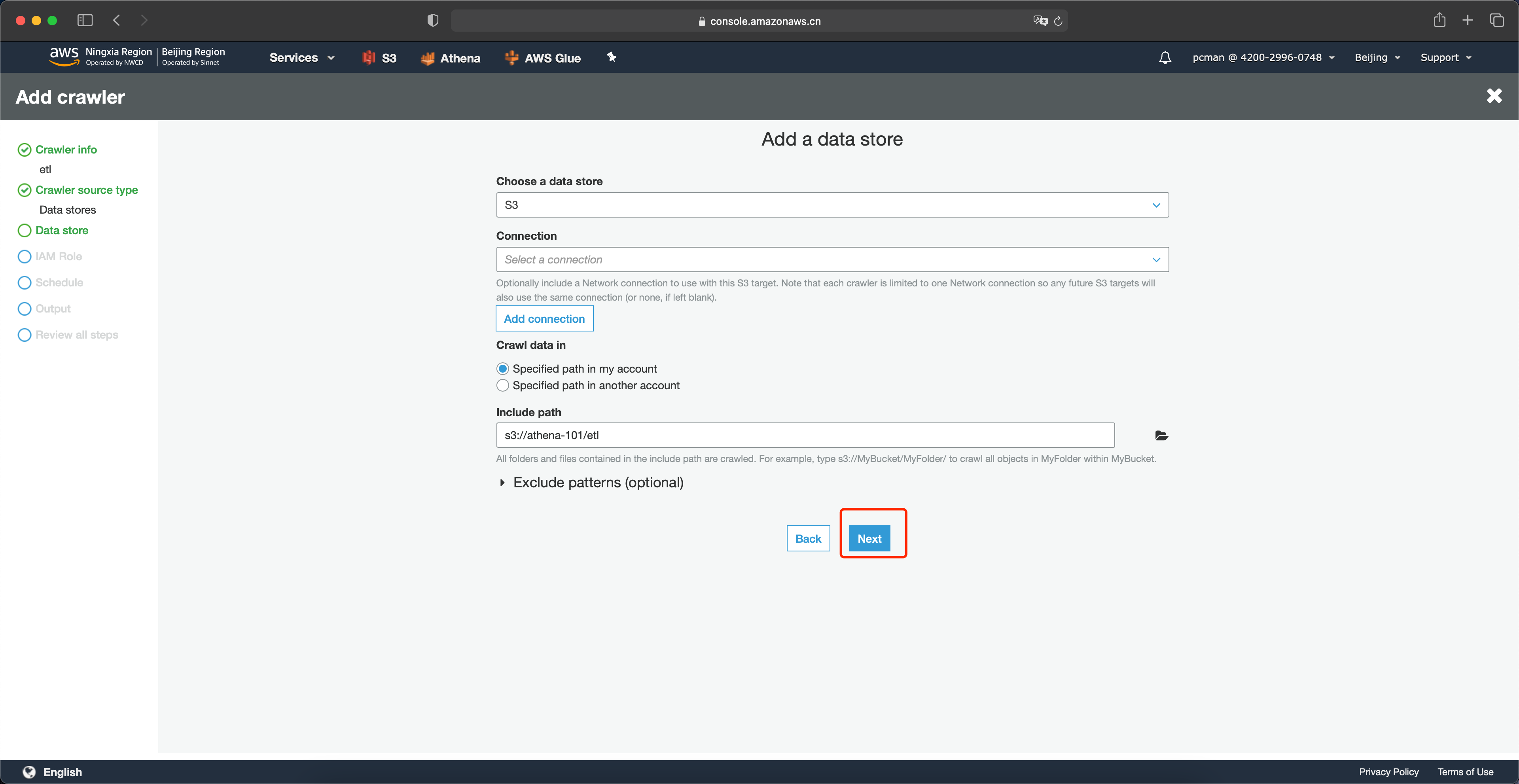
在下一个数据源位置,点击否,点击下一步。如下截图。
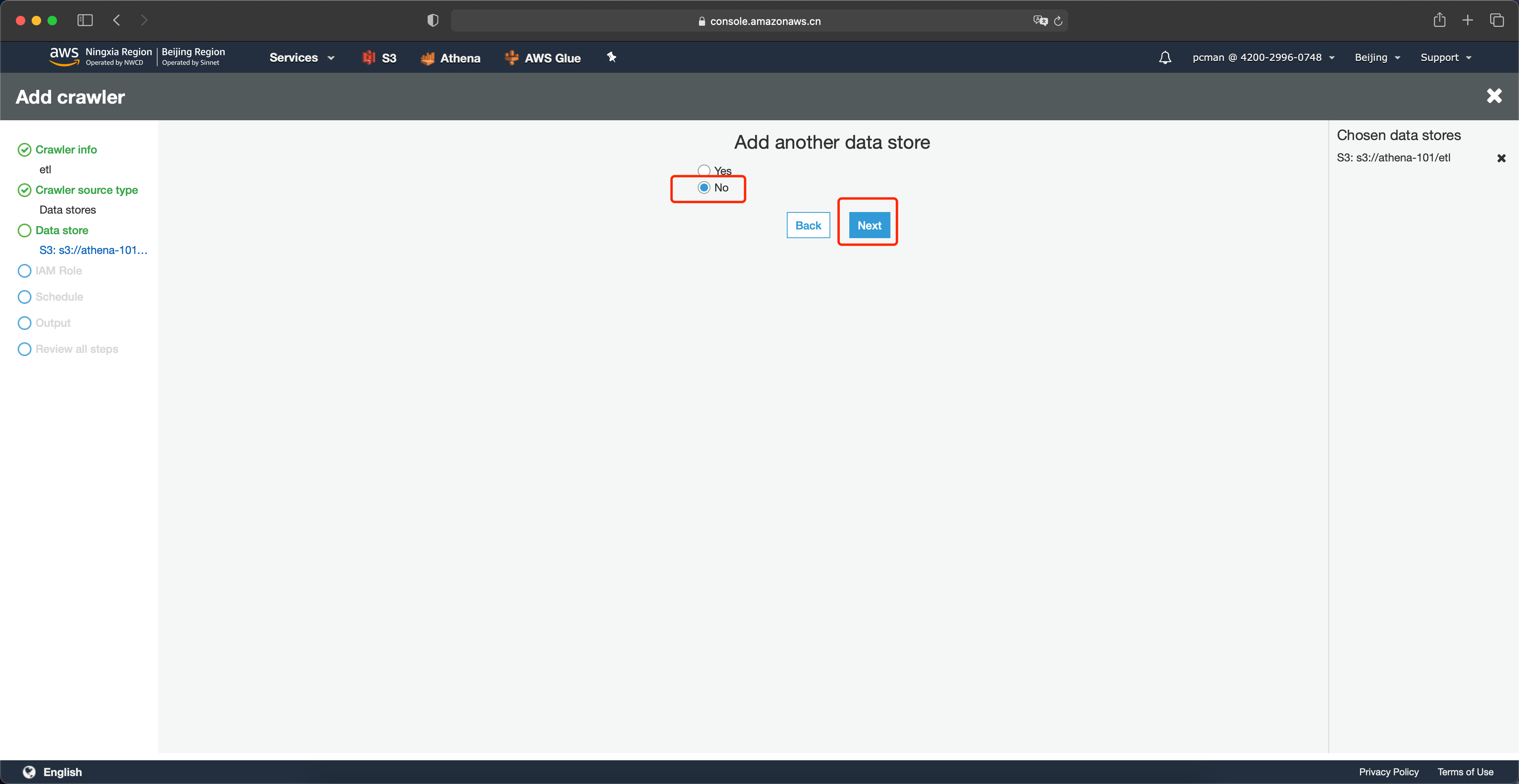
在角色配置页面,选择使用一个已经存在的IAM Role,从下拉框中选择实验第一步配置的角色,然后点击Next下一步继续。如下截图。
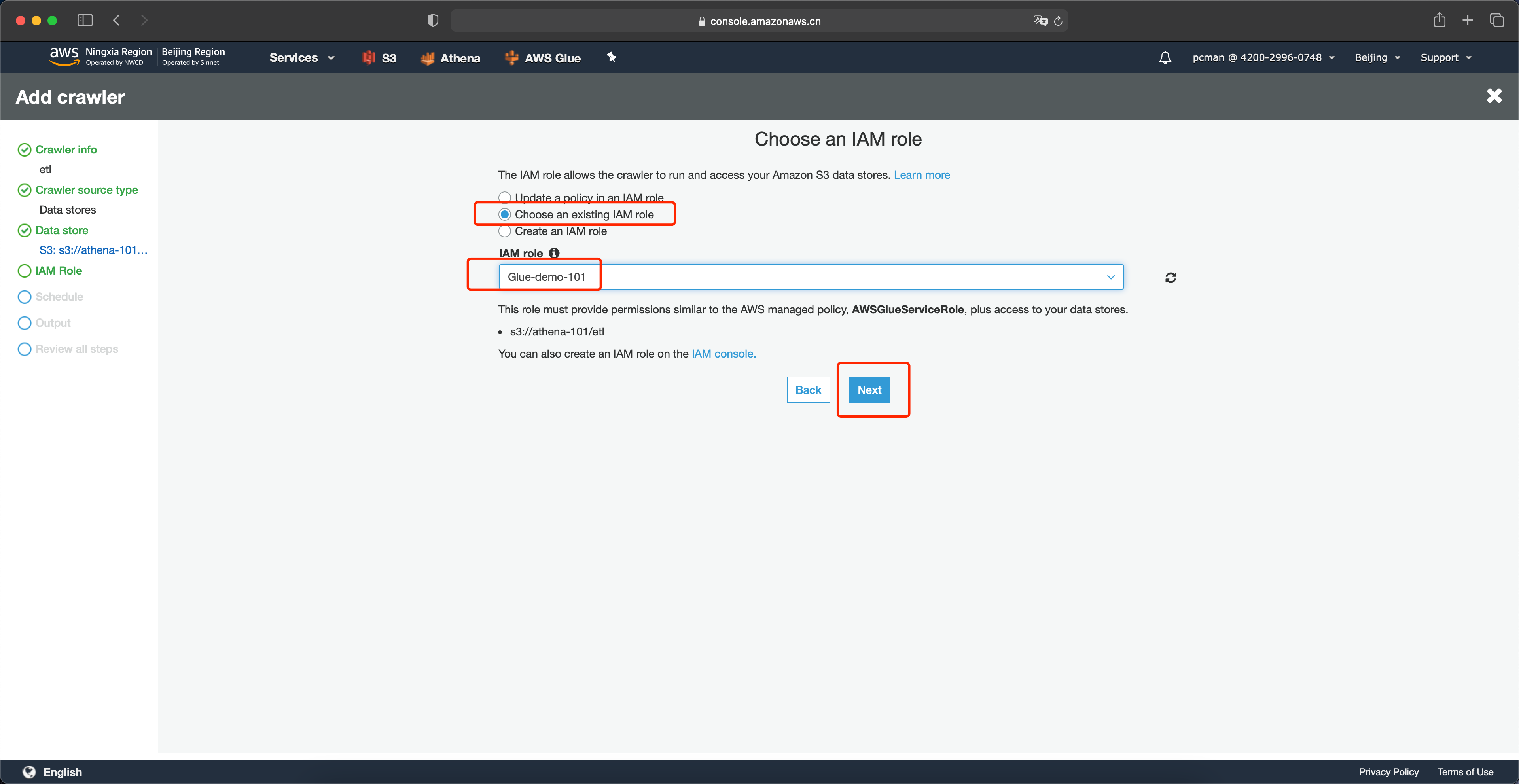
在频率位置选择按需运行,点击下一步继续。如下截图。
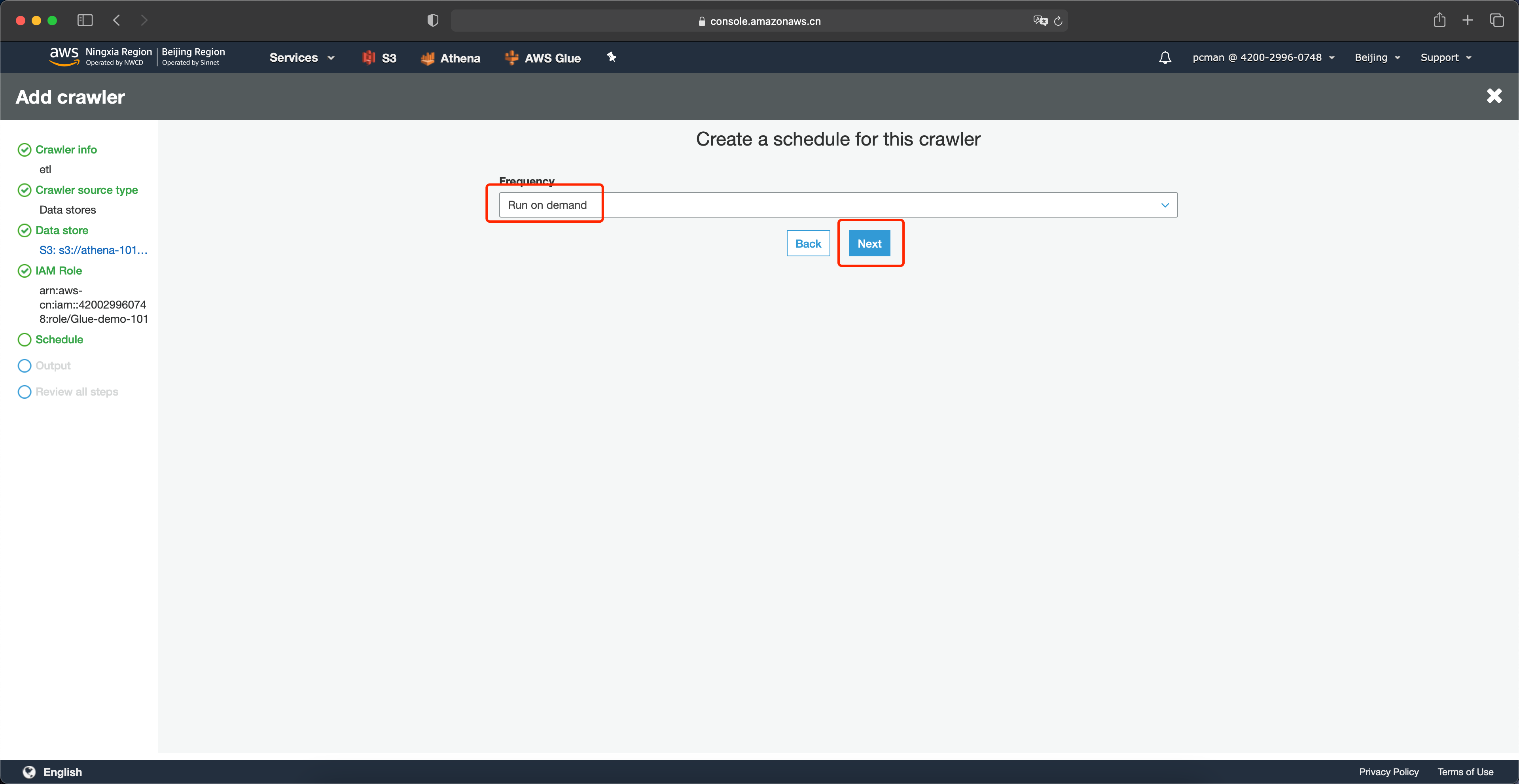
在输出配置界面,选择前文创建的数据库,跳过可选项的配置,点击下一步。如下截图。
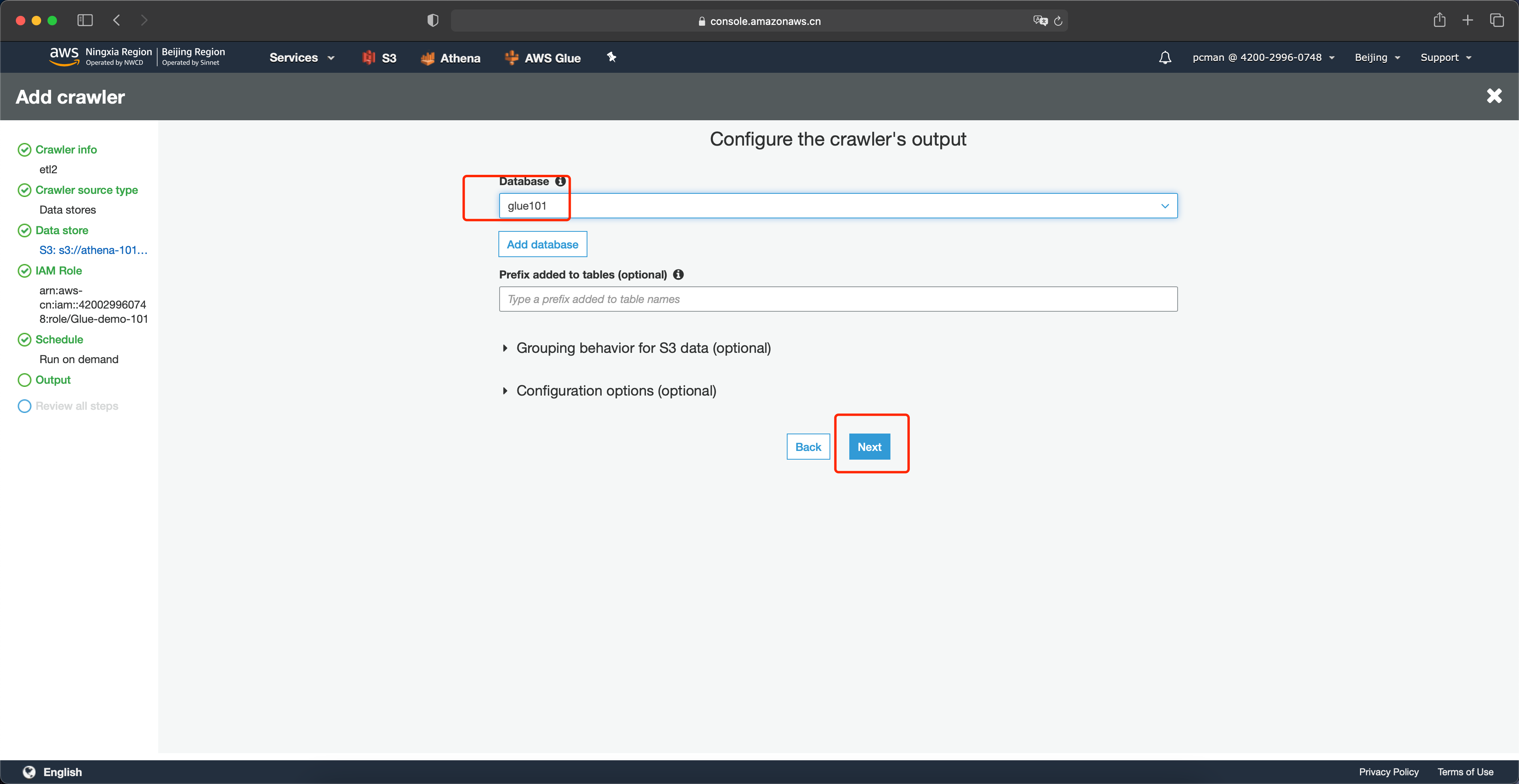
在配置向导最后一步,点击完成。如下截图。
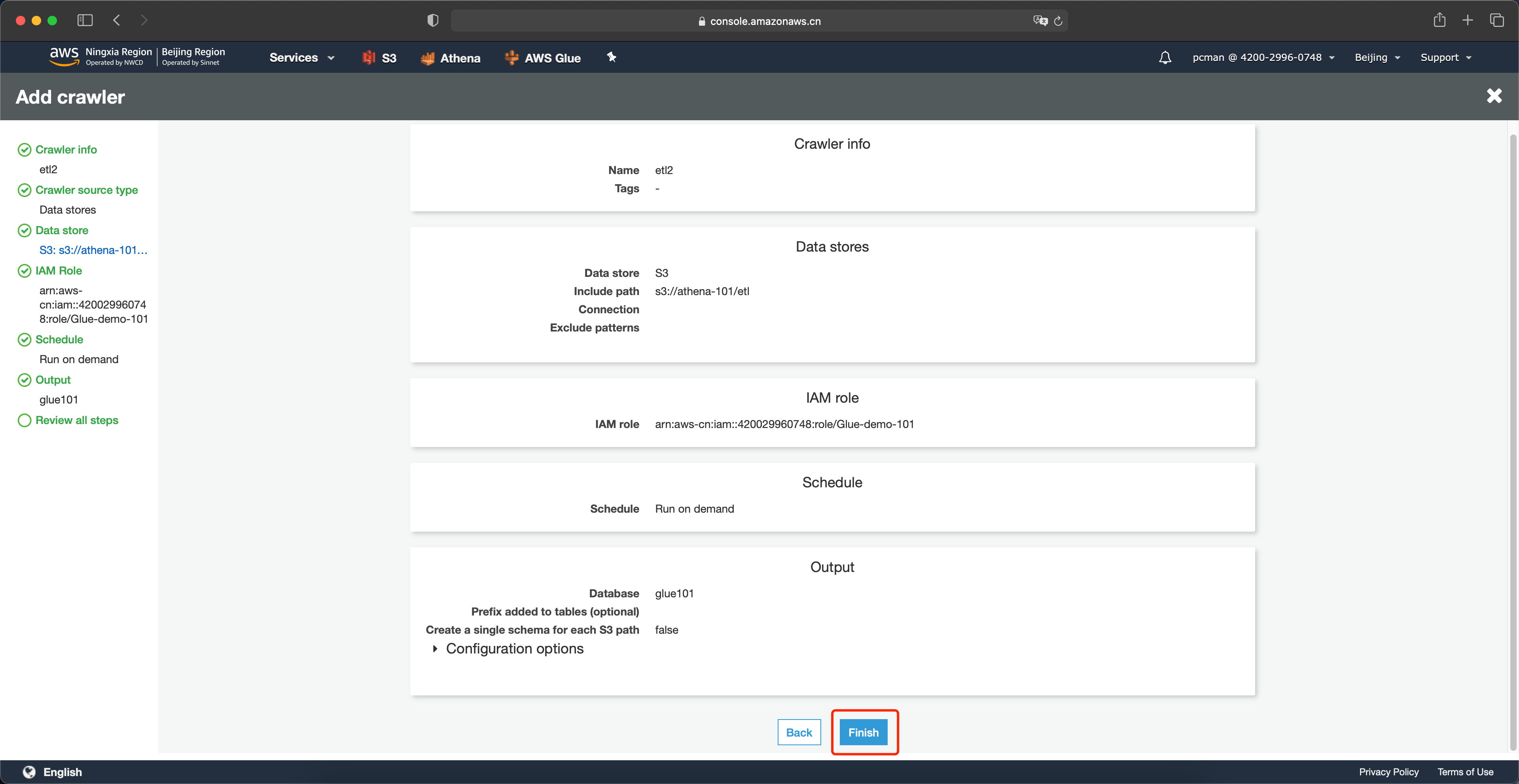
在新生成好的爬完程序列表中,点击启动按钮运行之。如下截图。
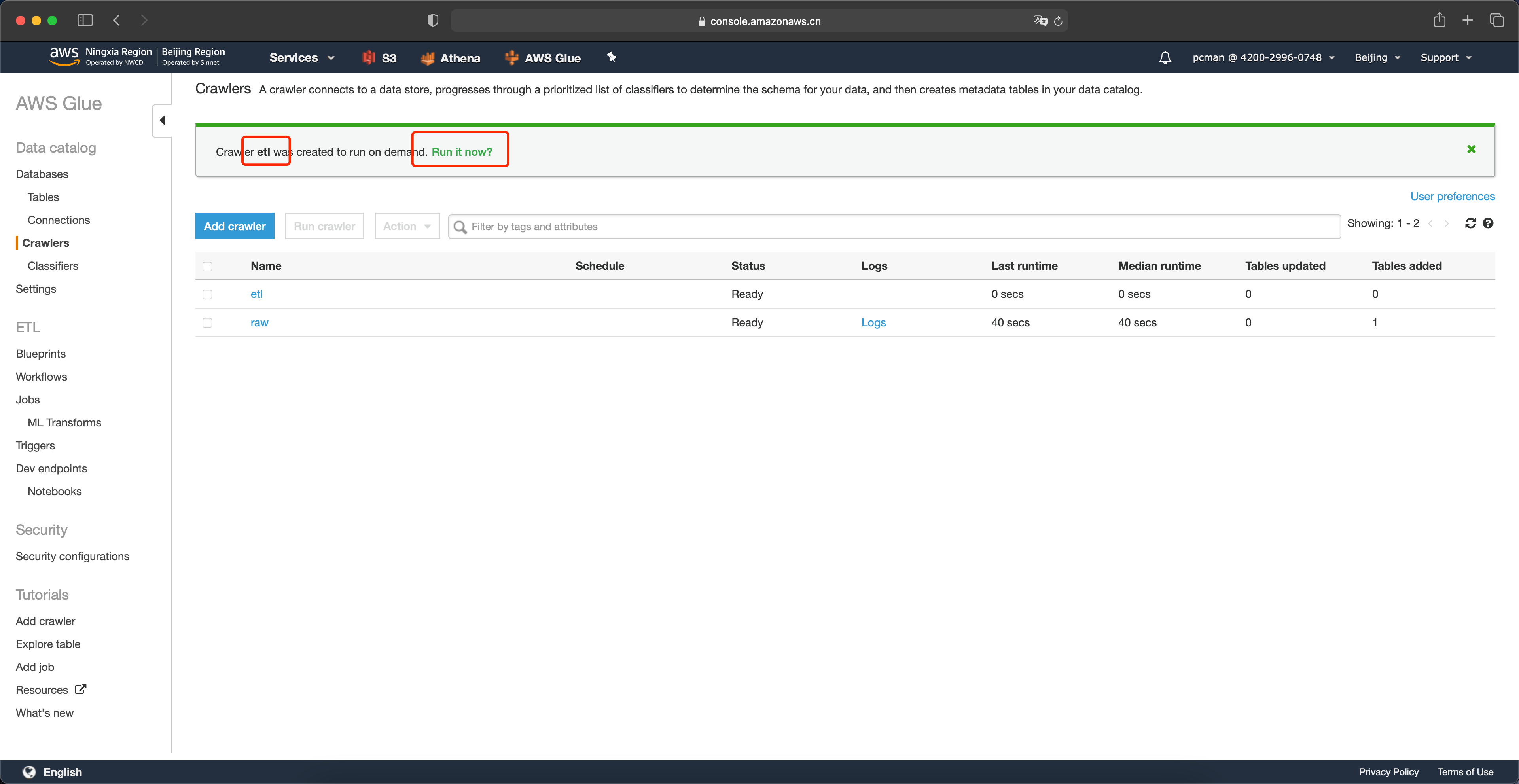
运行完成。此时Glue为转换后的数据生成了数据目录和表,可以进行Athena查询。
3、使用Athena进行查询
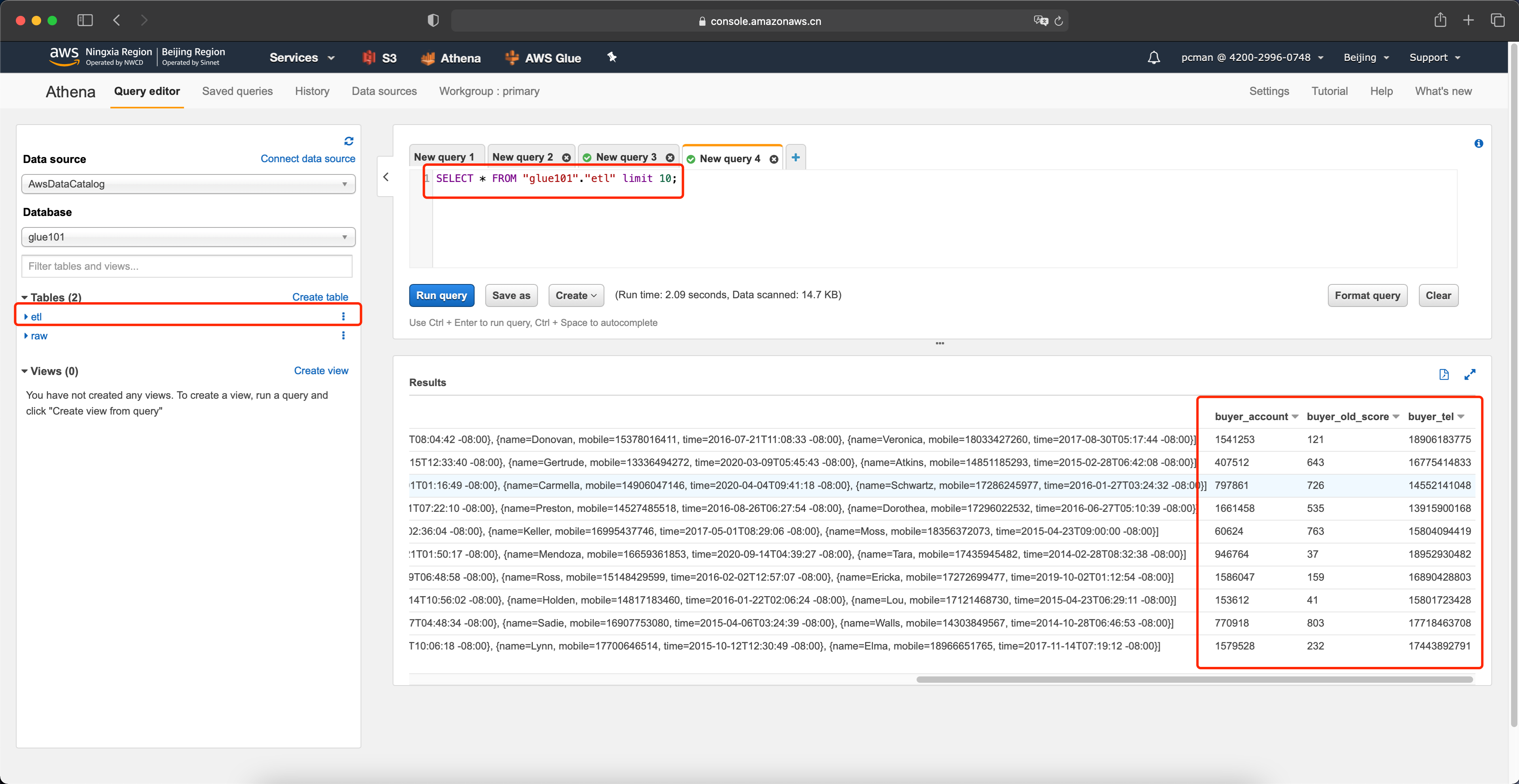
在Athena的上刷新表的名称,可以看到转换后的表etl。在代码部分,输入如下代码。
SELECT * FROM "glue101"."etl" limit 10;通过查询结果可以看到,原先是嵌套的三列Buyer信息被展平成为独立的列,方便查询时候降低扫描的数据量。如下截图。
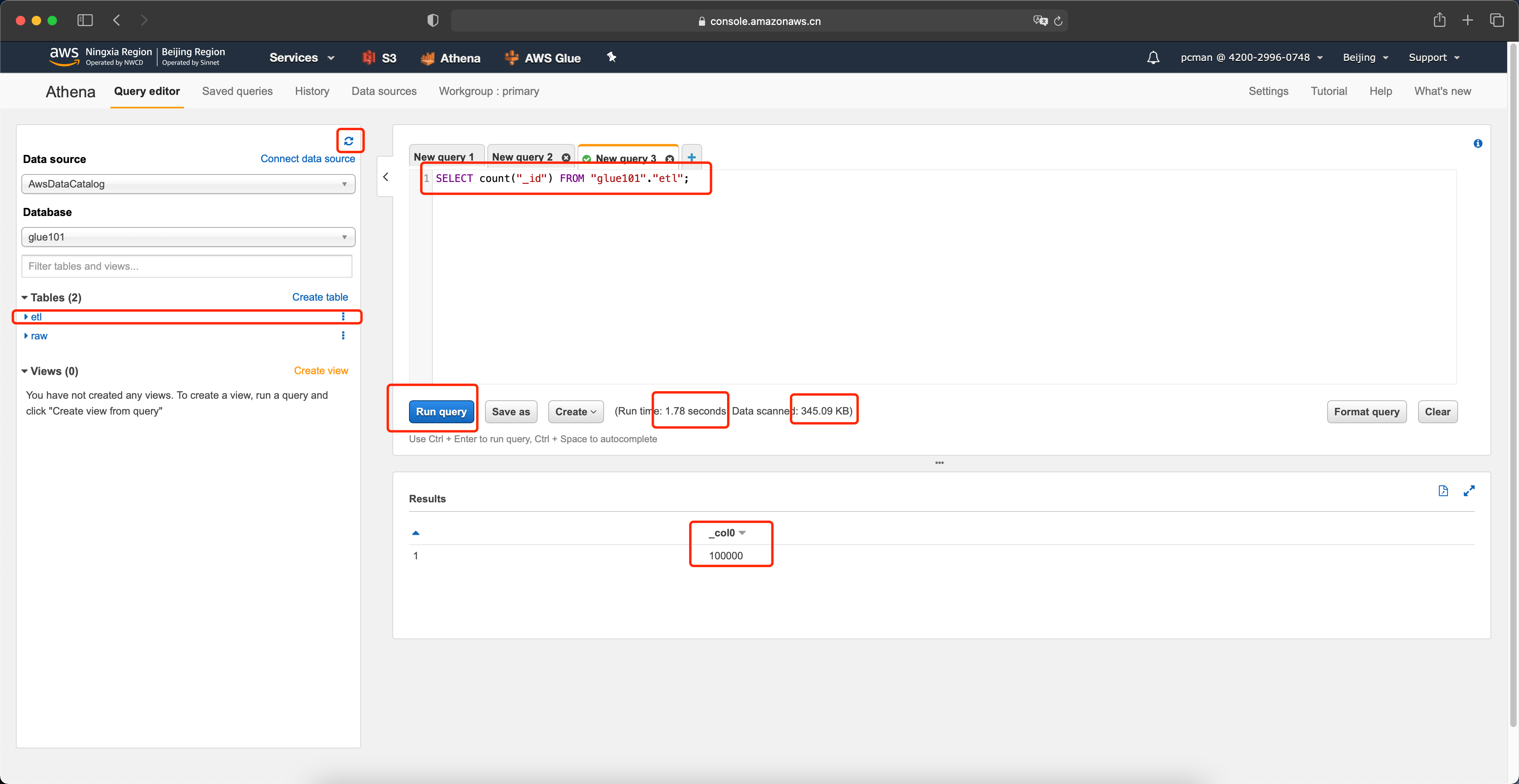
接下来测试整列遍历的场景,在代码部分,输入如下代码。
SELECT count("_id") FROM "glue101"."etl";运行后可看到,完成查询,耗时1.78秒,速度是之前的50%。扫描数据量是345KB,是之前扫描44MB的一百分之一。如下截图。
至此实验完成。
四、结论
通过实验可以看到,将原始数据从JSON格式转换为列格式,并附带嵌套文件展平能力,将显著节约查询需要扫描的数据量,并提升查询速度,让Athena服务的使用场景变得更加合理。