
注:2024年2月起,Kinesis Data Firehose也成为了独立产品Data Firehose。再加上之前成为独立产品的Managed Flink,Kinesis的三套件目前都成为了独立产品。
本文有关操作Demo请参考这个视频。本篇为具体技术配置过程。
一、背景和需求分析
1、Kinesis介绍
Kinesis简介From AWS官网:
Amazon Kinesis Data Firehose (KDF) 是将流数据加载到数据存储和分析工具的最简单方式。Kinesis Data Firehose是一项完全托管式服务,让您可以轻松地从数十万个来源中捕获、转换大量流数据,并将其加载到 Amazon S3、Amazon Redshift、Amazon OpenSearch Service、Kinesis Data Analytics、通用 HTTP 终端节点,以及 Datadog、New Relic、MongoDB 和 Splunk 等的服务提供商中,从而获得近乎实时的分析与见解。
2、Kinesis分区需求
测试Kinesis发送数据流时候,经常使用Kinesis控制台上的生成测试数据按钮,这个按钮将生成如下四个字段:
- sector:取值为 ENERGY、RETAIL、TECHNOLOGY、HEALTHCARE 中随机的一个
- ticker_symbol:股票代码,随机三位大写字母
- price:股票价格,浮点数
- change:变化值,浮点数
在默认情况下,即没有开启Kinesis的Dynamic Partitions功能时候,Kinesis会按照如下年、月、日、小时共4级目录在S3存储桶内生成Prefix(可视为子目录):
s3://bucket/year/month/day/hour/这样的四级目录结构的最后一层存储的是JSON格式的数据。为了查询数据,接下来需要配置Glue或者Athena创建数据目录和表,将年、月、日、小时的目录设置为分区键。此后发起查询时可直接指定要搜索的分区条件例如日期等于某一天。由此即可大大减小搜索范围,优化搜索速度和成本。
以上的使用逻辑为Kinesis默认设置。它满足了Kinesis数据流的基础功能要求,但是缺少时间戳、缺少自定义分区字段等配置。除了根据时间作为分区键之外,某些业务场景还需要以特定关键字作为分区键,例如上述4个字段中的Sector值可用作分区键,用于缩小每次查询的范围。当使用Sector作为分区键时候,Kinesis将数据保存到S3的目录如下。
s3://bucket/sector/Kinesis Data Firhose通过自定义分区功能支持以上需求。此外,为了进一步优化空间占用提升搜索效率,Kinesis还支持将落盘到S3的数据从JSON格式自动转换为列格式。这里优先推荐Apache Parquet格式,可节省数倍的磁盘存储空间,并提升搜索速度。
下文将分别进行两个自定义分区设置,第一个按年、月、日三级分区的规则,第二个按特定字段分区的规则。
3、S3数据湖、Glue、Athena对分区键符合Hive格式的要求的设置
是否Hive兼容从数据存储角度主要体现在S3存储桶的Prefix(目录)是否带有变量名。从后续分区管理的角度上,非Hive兼容模式需要执行的加载分区命令需要显式声明分区所在的路径,而兼容Hive的方式下,只需要简单执行msck命令即可。具体对比如下表。
| 对比 | 非Hive兼容 | Hive兼容 |
|---|---|---|
| 目录 | S3://bucket/2023/04/14/abc.json | s3://bucket/year=2023/month=04/day=14/abc.json |
| 新增分区 | ALTER TABLE kdfs301 ADD PARTITION (year=2023,month=04,day=05) location ‘s3://kdf-s3-01/2023/04/05/’。注:这里kdfs301为表的名字 | MSCK REPAIR TABLE kdfs301。注:这里kdfs301为表的名字 |
| Kinesis配置Prefix | !{partitionKeyFromQuery:year}/!{partitionKeyFromQuery:month}/!{partitionKeyFromQuery:day}/ | year=!{partitionKeyFromQuery:year}/month=!{partitionKeyFromQuery:month}/day=!{partitionKeyFromQuery:day}/ |
两种方式Kinesis都可以支持,因此从Kinesis本身配置角度并无功能性差别。本文后续按照兼容Hive的方式进行配置。
二、准备工作
1、创建S3原始数据存储桶和Athena查询结果存储桶。
在与Kinesis对应的Region内创建S3存储桶,创建S3存储桶的过程较为简单,本文不再展开讲解。此过程创建几个存储桶:
- kdf-s3-01:存放Kinesis流过来的数据(针对使用年、月、日作为分区键的场景1)
- kdf-s3-02:存放Kinesis流过来的数据(针对使用自定义字段作为分区键的场景2)
- athena-result:存放Athena查询结果的存储桶
创建S3存储桶过程中,所有参数都保持页面上默认的参数,即存储桶无须打开公开访问。
2、Athena准备工作之设置查询结果目录(如本AWS账号第一次使用Athena必须设置)
进入Athena服务,如果是本账号第一次启动Athena服务,还需要设置下Athena查询结果的存储桶。点击页面标签页Settings,点击右上角的Manage按钮设置查询结果存储桶。如下截图。
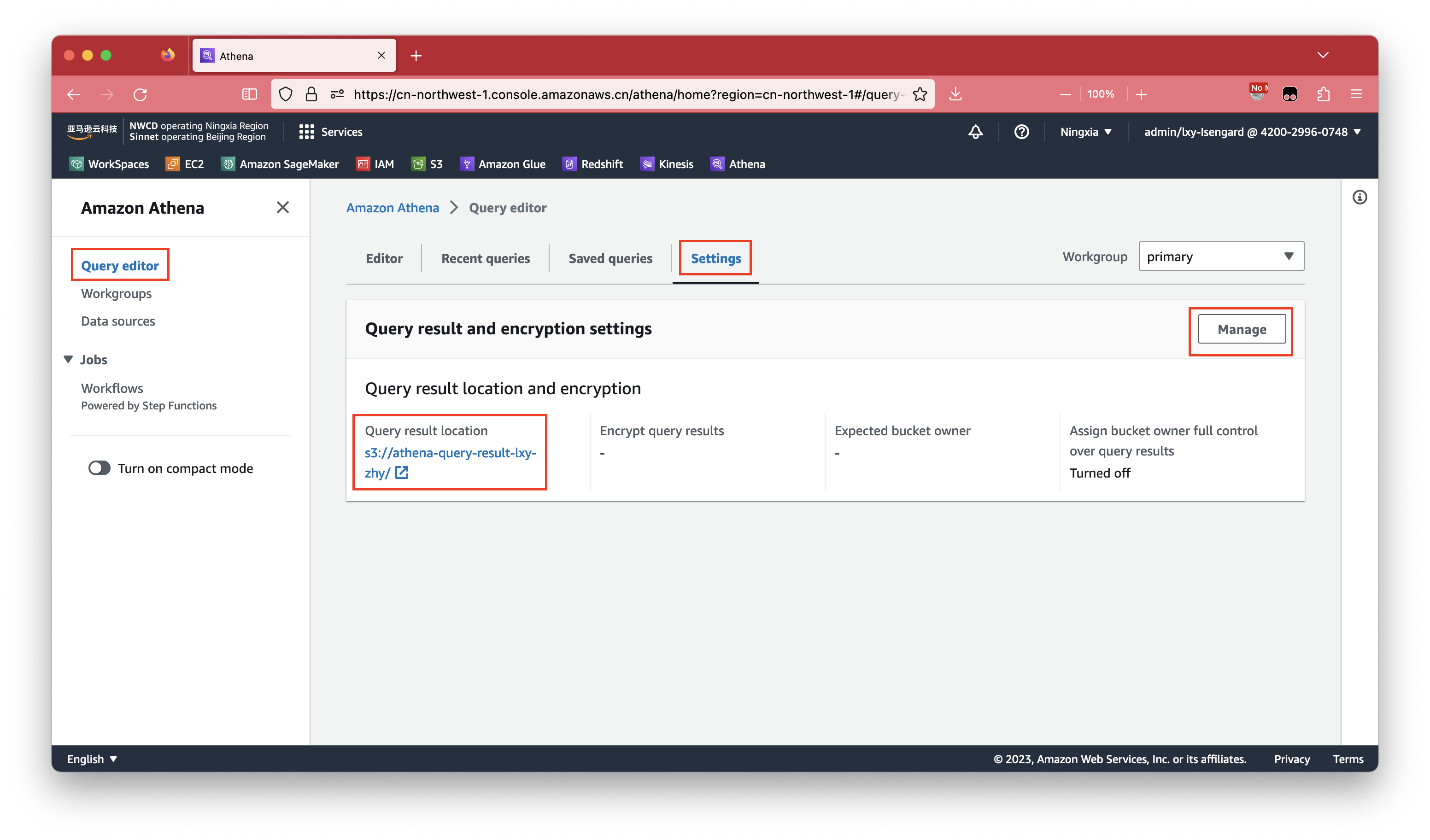
修改完毕后,点击保存按钮。如下截图。
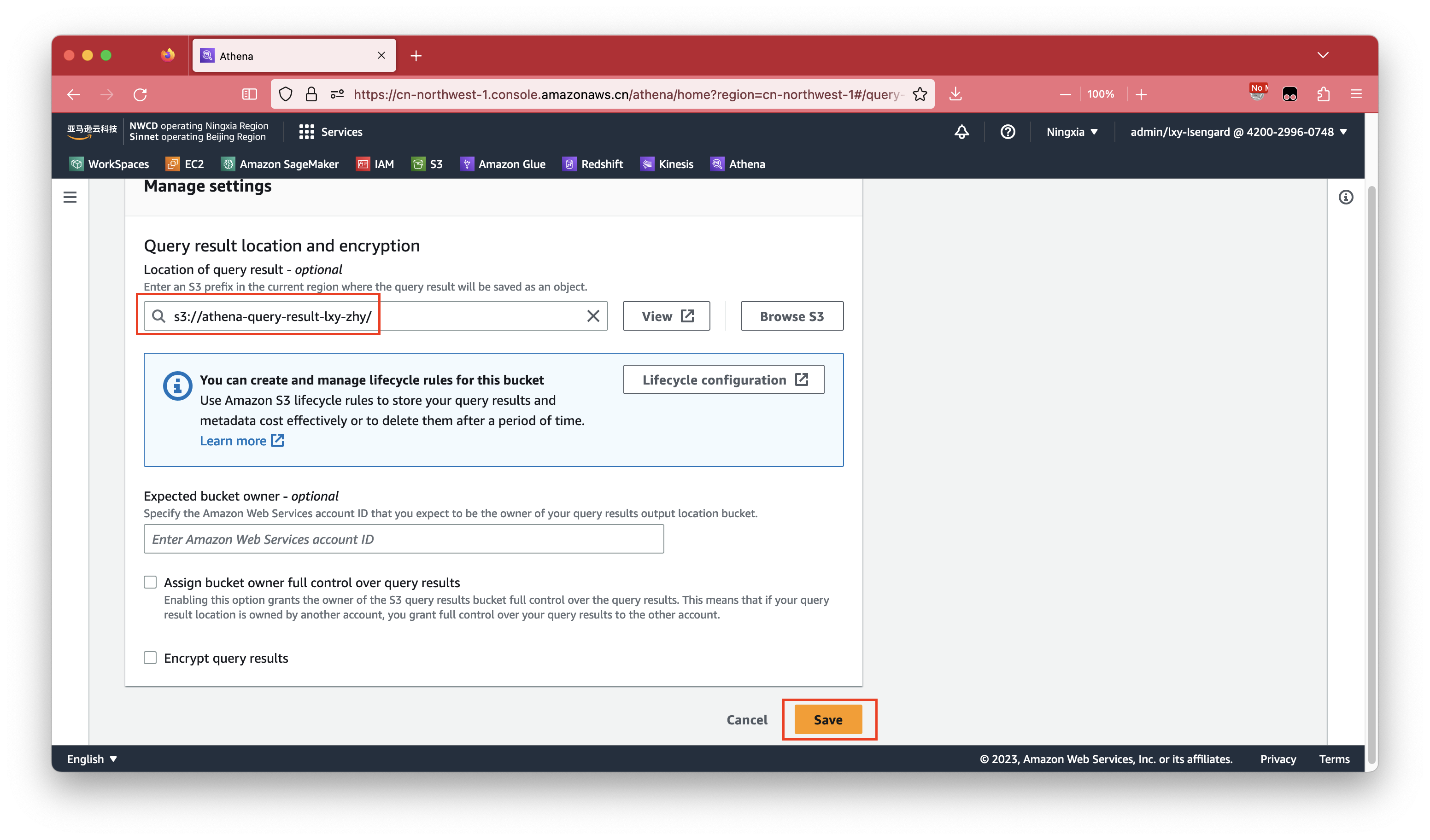
接下来就可以开始使用Athena了对数据发起查询了。
三、实验1-以年、月、日作为分区键并转换数据为Parquet格式
1、创建Glue表
在单独使用S3+Athena数据湖的过程中,通常我们使用Glue的爬虫(Crawlers)功能去自动识别S3存储桶的已知数据的目录结构(Prefix)、分区、数据格式等。这种场景适合现有数据已经保存在S3的场景。对于本文的场景,数据来源是Kinesis,在Kinesis被正确配置之前,S3存储桶内是空白的没有数据,因此Glue爬虫也就无法自动生成目录结构了。由此,我们使用Athena执行SQL去手工创建表结构。
在Athena中执行如下SQL语句,其中有两处需要替换成真实值。第一行的kdfs301请替换为Glue和Athena未来要使用的表的名字。倒数第四行的s3://kdf-s3-01/请替换成Kinesis保存数据的S3桶的名字。
在Athena界面中,选择数据库为default,在页面右侧空白处粘贴以上SQL代码,然后点击Run执行按钮。
CREATE EXTERNAL TABLE `kdfs301`(
`msgtime` timestamp COMMENT '',
`ticker_symbol` string COMMENT '',
`sector` string COMMENT '',
`change` float COMMENT '',
`price` float COMMENT '')
PARTITIONED BY (
`year` smallint COMMENT '',
`month` tinyint COMMENT '',
`day` tinyint COMMENT '')
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://kdf-s3-01/'
TBLPROPERTIES (
'classification'='parquet',
'compressionType'='none',
'typeOfData'='file')执行成功后,页面右下角会提示Query successful。另外,左侧的Tables表菜单下,也会出现刚才的创建的表结构了。如下截图。
如下截图。
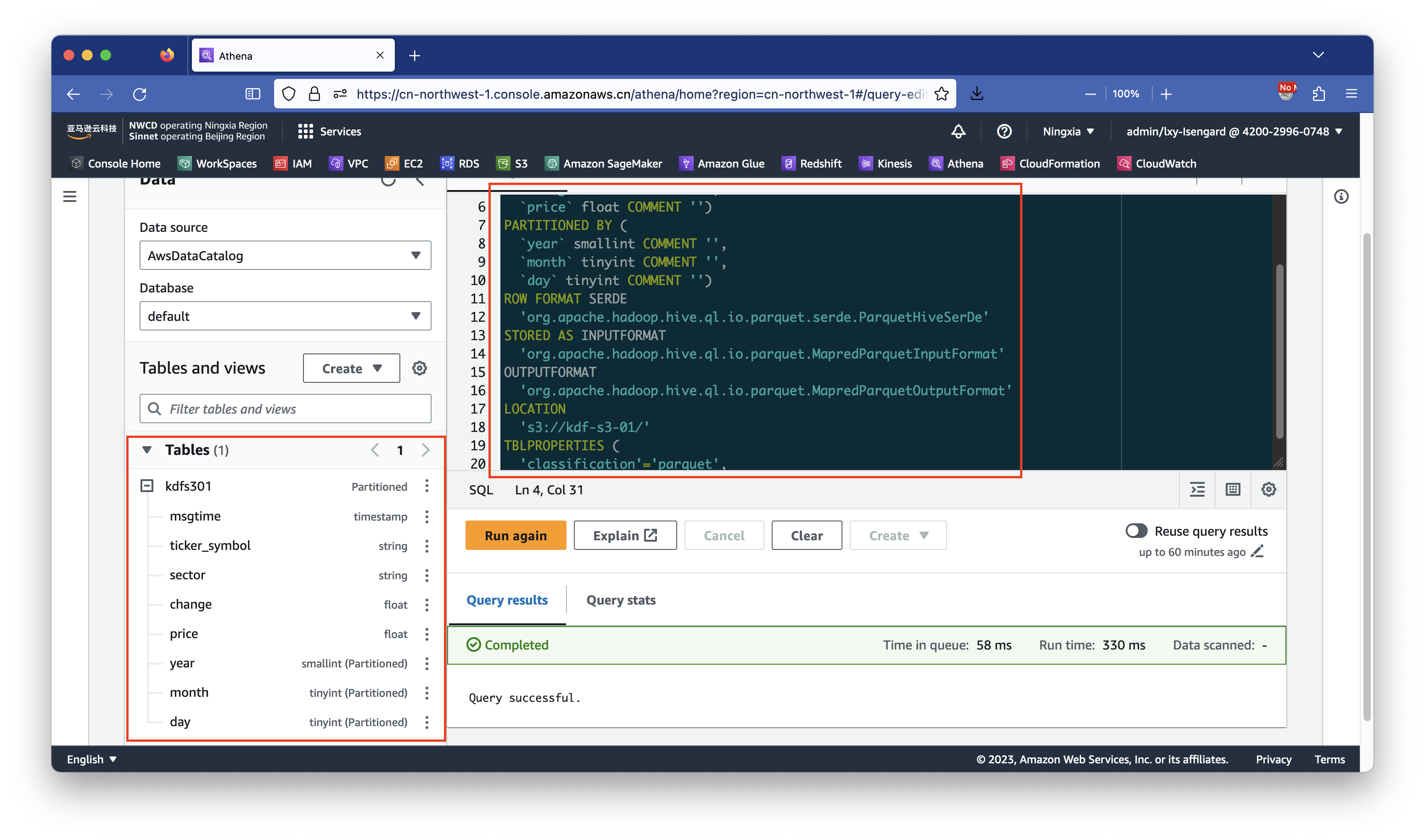
由此要发送到Kinesis的数据结构和Glue表结构准备工作完成。
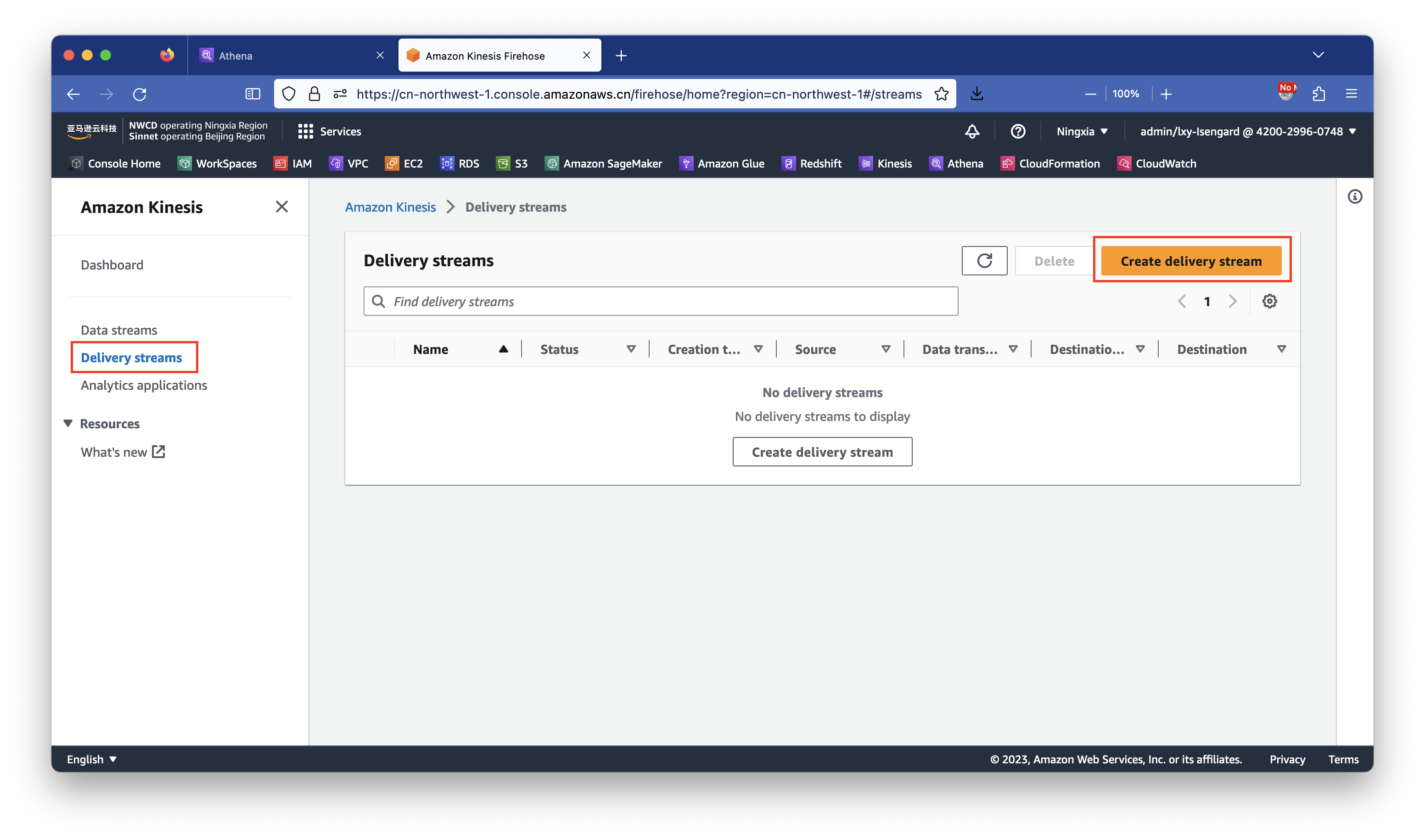
2、创建Kinesis Data Firehose
进入Kinesis服务,在左侧选中Data firehose,在右侧的点击右上角新建按钮。如下截图。
在创建向导的上方,选择输入来源Source是Direct PUT,在目标Destination选择Amazon S3,在Delivery stream name位置可填写自定义名字,这里使用PUT-S3-parquet-1用于和其他Stream区分开。后续代码中还要使用这个Stream name,请确认好自己的命名规则。填写好之后继续向下滚动页面,如下截图。
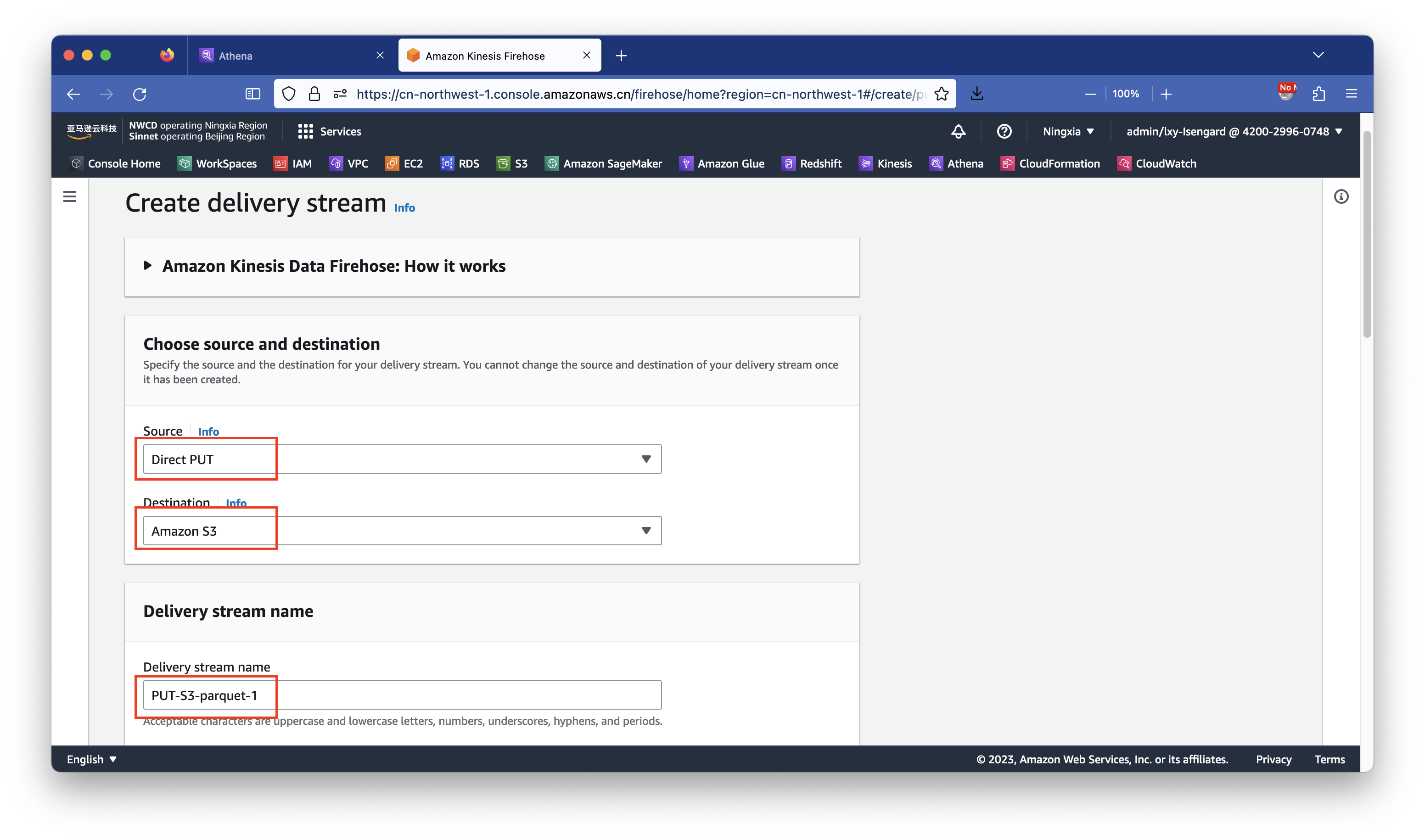
在页面中间位置,点击Enable record format conversion选项,打开数据转换。在Output format位置选择Apache parquet,在下方选择使用Glue的区域。如下截图。
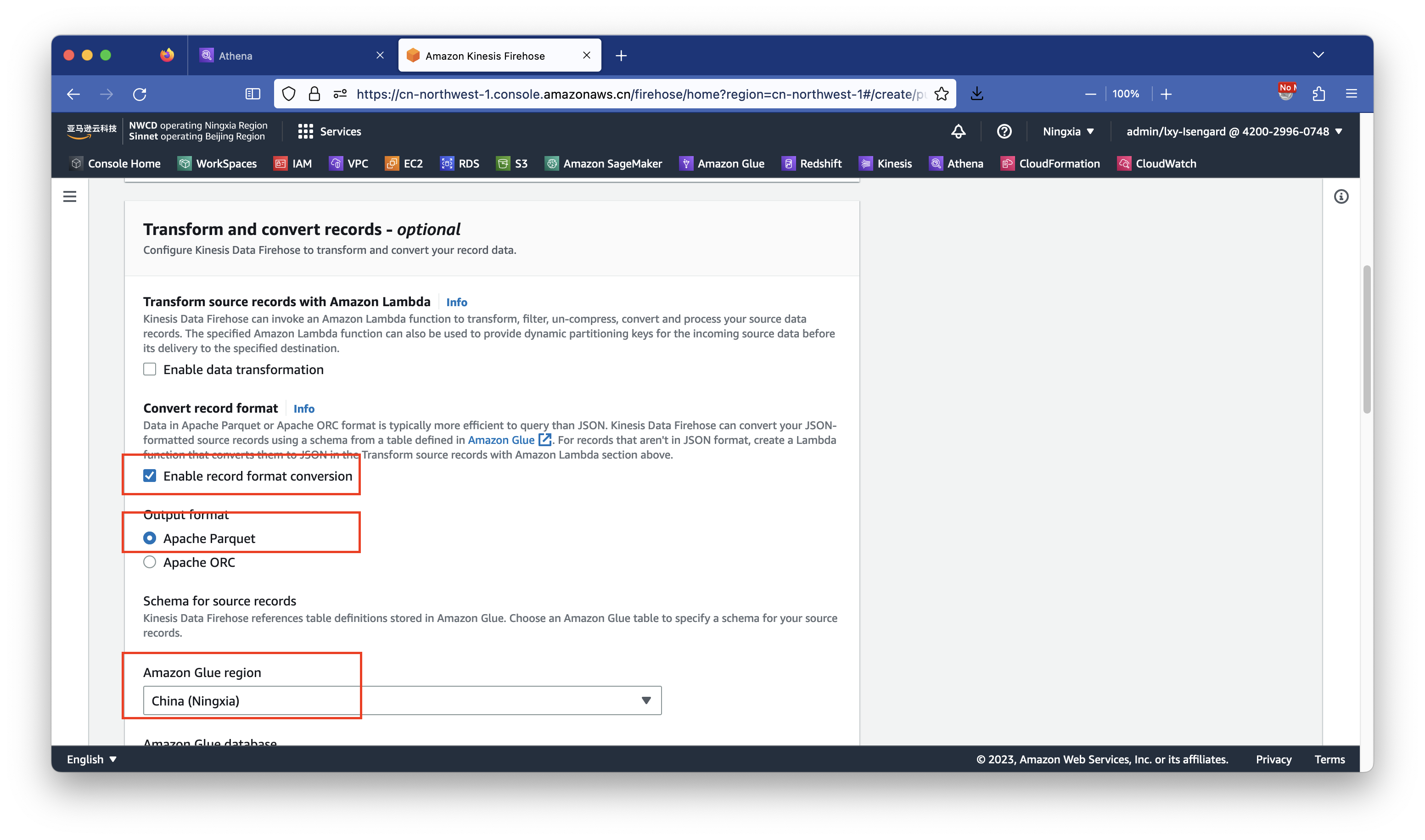
上一步选择好了Glue的区域。接下来选择对应的表和S3存储桶。
在数据库位置选择Glue默认的default数据库。然后点击浏览Browse按钮查看上一步在Athena上创建好的数据库。在选择了Glue中的现有表kdf-to-s3之后,页面会出现一段蓝色的提示,大致内容是本Glue表已经指定了S3存储桶名叫kdf-s3-01,因此后续配置要Glue数据落盘时候要使用Glue表定义的同一个存储桶。这样配置既可让Kinesis通过Glue完成自动的格式转换,又可以直接使用Athena查询结果。填写好之后继续向下滚动页面,如下截图。
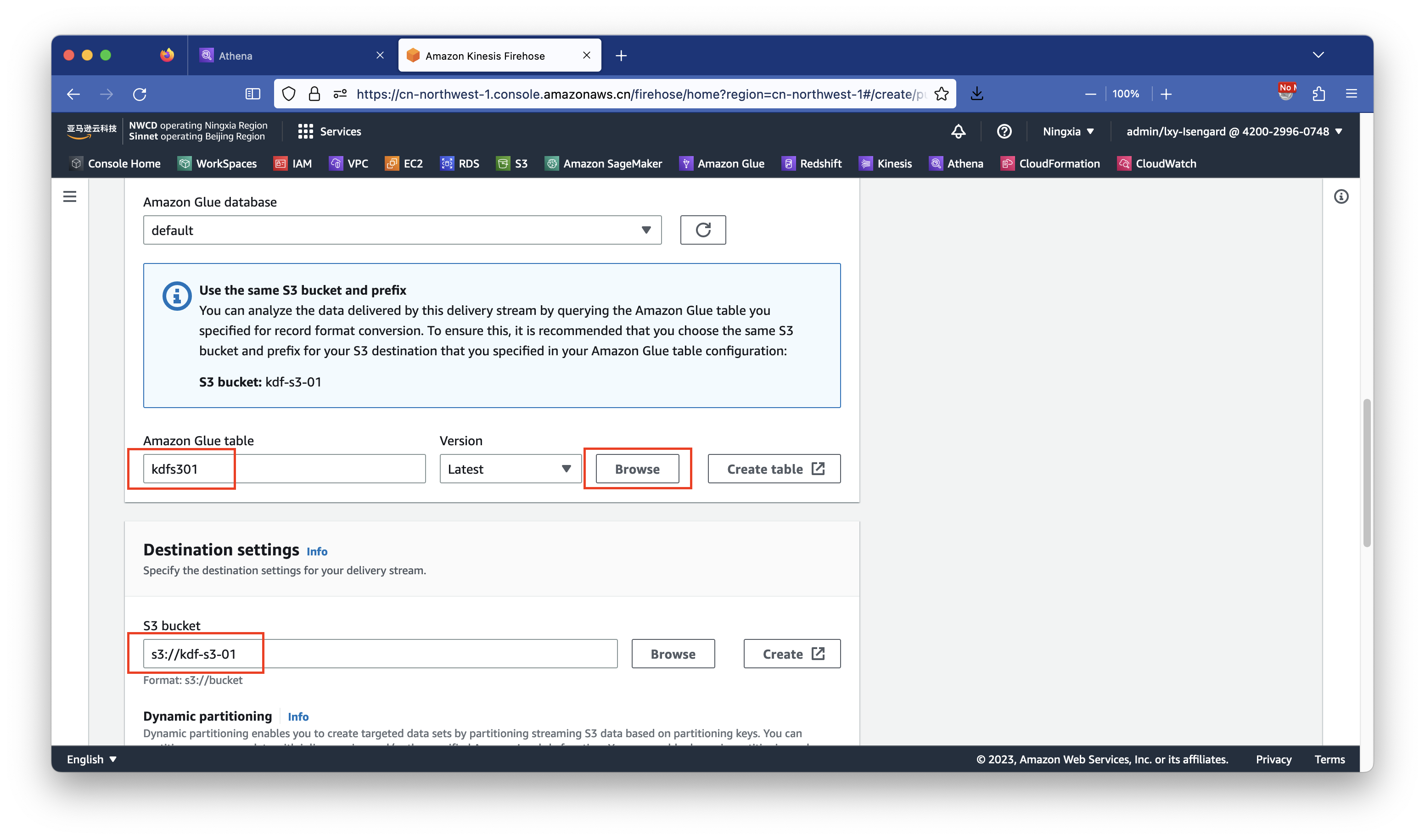
向下滚动页面,在存储桶名称位置,填写上文要求的kdf-to-s3。在Dynamic partitioning动态分区功能位置,选择Enable打开。注意这个选项只能在创建Kinesis时候修改,后续不能再修改,除非删除Kinesis重建一个新的。这个选项针对后续使用Athena数据查询时候降低查询成本、提升查询速度有重大影响。因此要打开这个功能。
接下来在Multi record deaggregation位置选择Not enabled。在New line delimiter选项位置选择not enabled。继续向下滚动页面。如下截图。
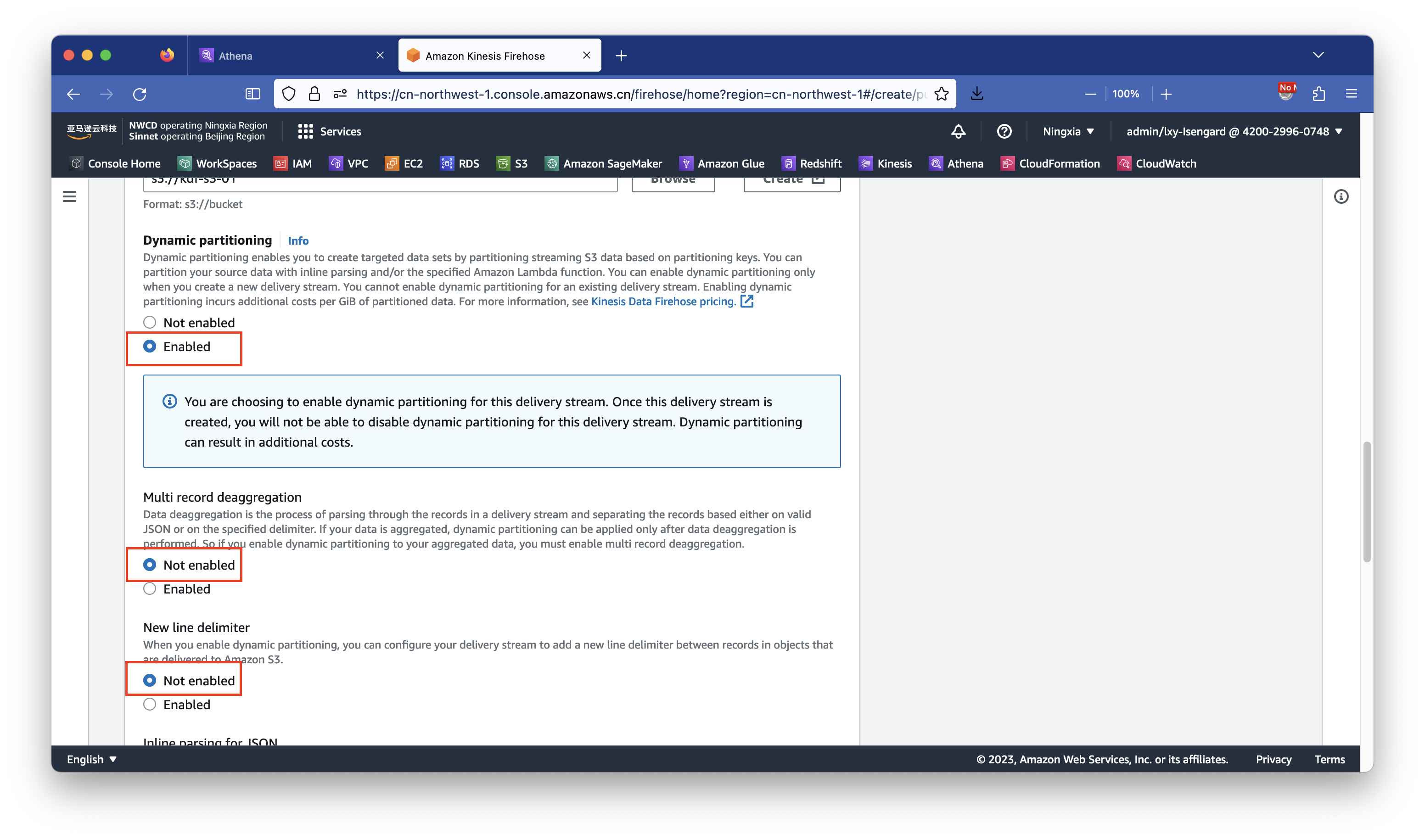
在Inline parsing for JSON位置选择Enabled,这是因为要打开动态分区,就需要识别JSON数据流里边的各字段名称,因此这里需要设置为Enable。
接下来在配置动态分区键值的位置,如果不会编写希望参考下配置参数写法,可点击Example record查看示例。本文事先准备好配置参数写法,注意参照前文用于生成数据的Python脚本,分区键必须与生成数据的脚本精确匹配。
- Key name:
year,JQ expression:.year - Key name:
month,JQ expression:.month - Key name:
day,JQ expression:.day
以上参数填写到下方的Key name和JQ expression表达式中。然后向下滚动页面。如下截图。
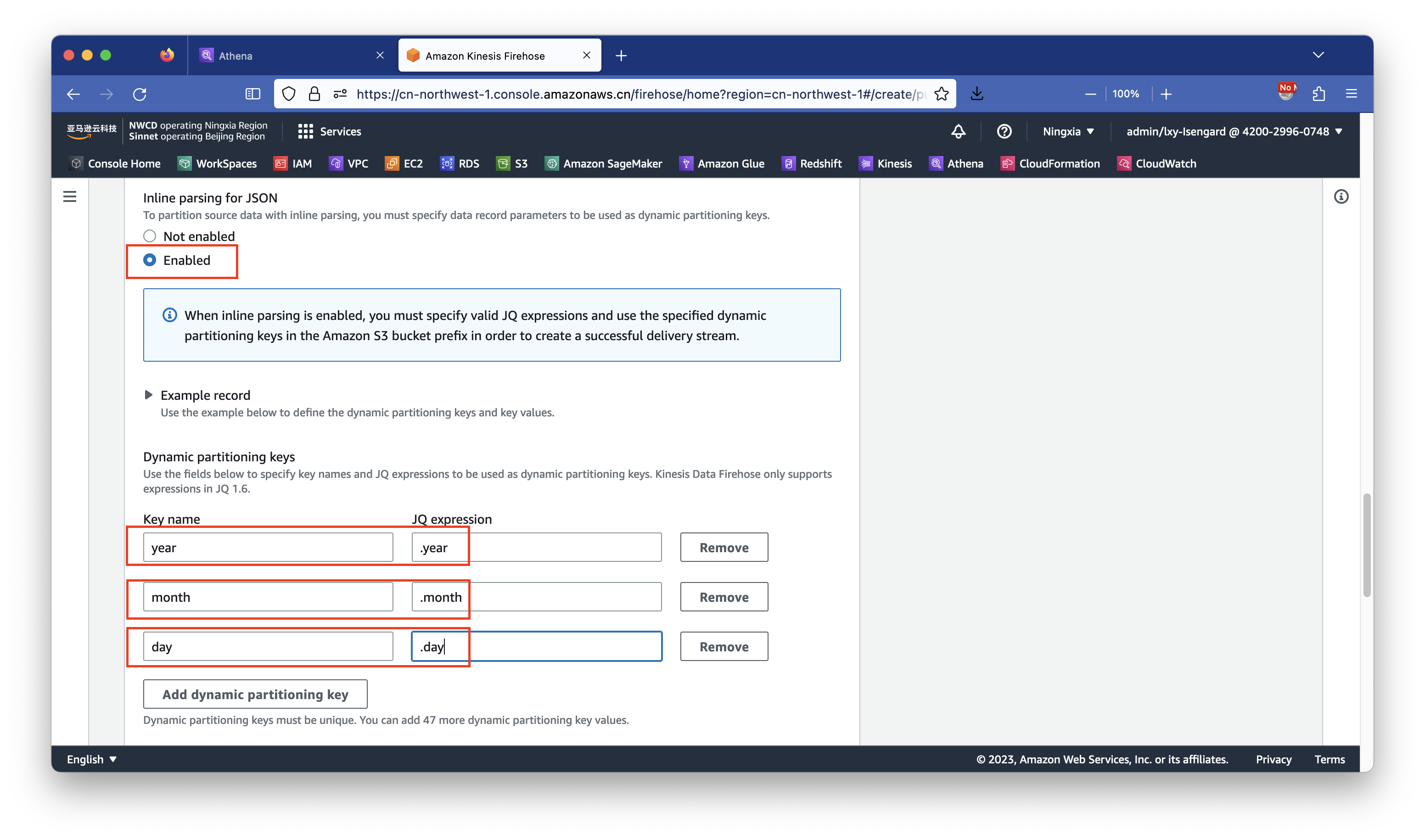
填写完毕分区键后,按下方的Apply dynamic partitioning keys按钮,即可自动在S3存储桶目录(prefix)规则的位置生成分区键作为目录的写法。前文已经介绍过,为了符合Hive规范更加便于维护,我们在这里手工增加year=、month=、day=的变量名。这样后续使用更简单易于分区管理。设置完毕后,在下一个对话框配置S3错误数据目录的地方输入error用于存放转换错误的原始数据,在下方的Retry duration位置输入3表示3秒重试时间。然后向下滚动页面。如下截图。
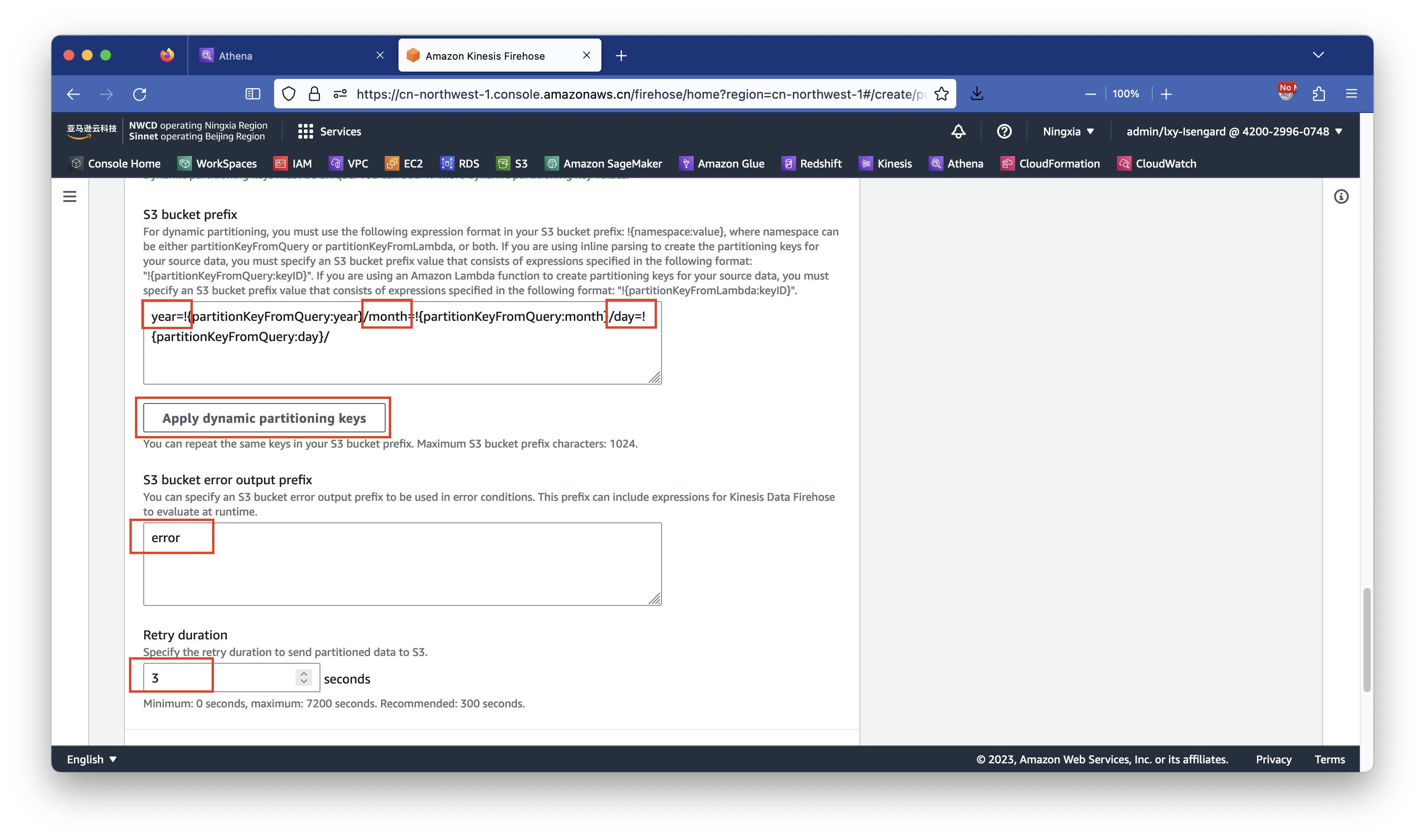
接下来配置数据落盘缓冲。点击Buffer hints, compression and encryption展开详细设置,在Buffer size位置保持默认的128MB不变,在Buffer interval位置输入60秒。然后向下滚动页面。如下截图。
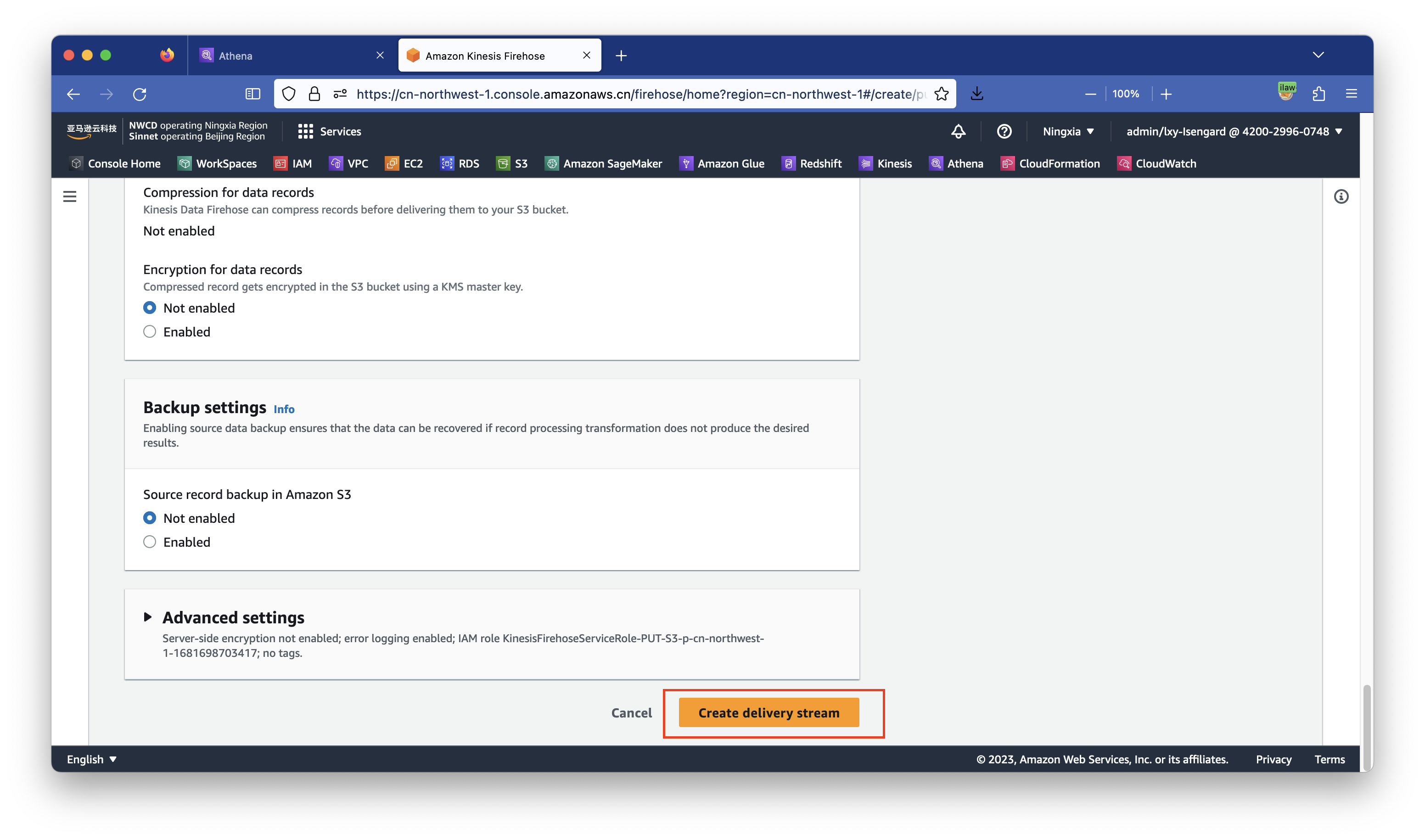
到此终于完成了Kinesis Data Firehose的所有配置,点击右下角创建按钮。如下截图。
创建过程需要3~5分钟才会变成可用。
3、生成测试数据并检查S3存储桶数据是否落盘
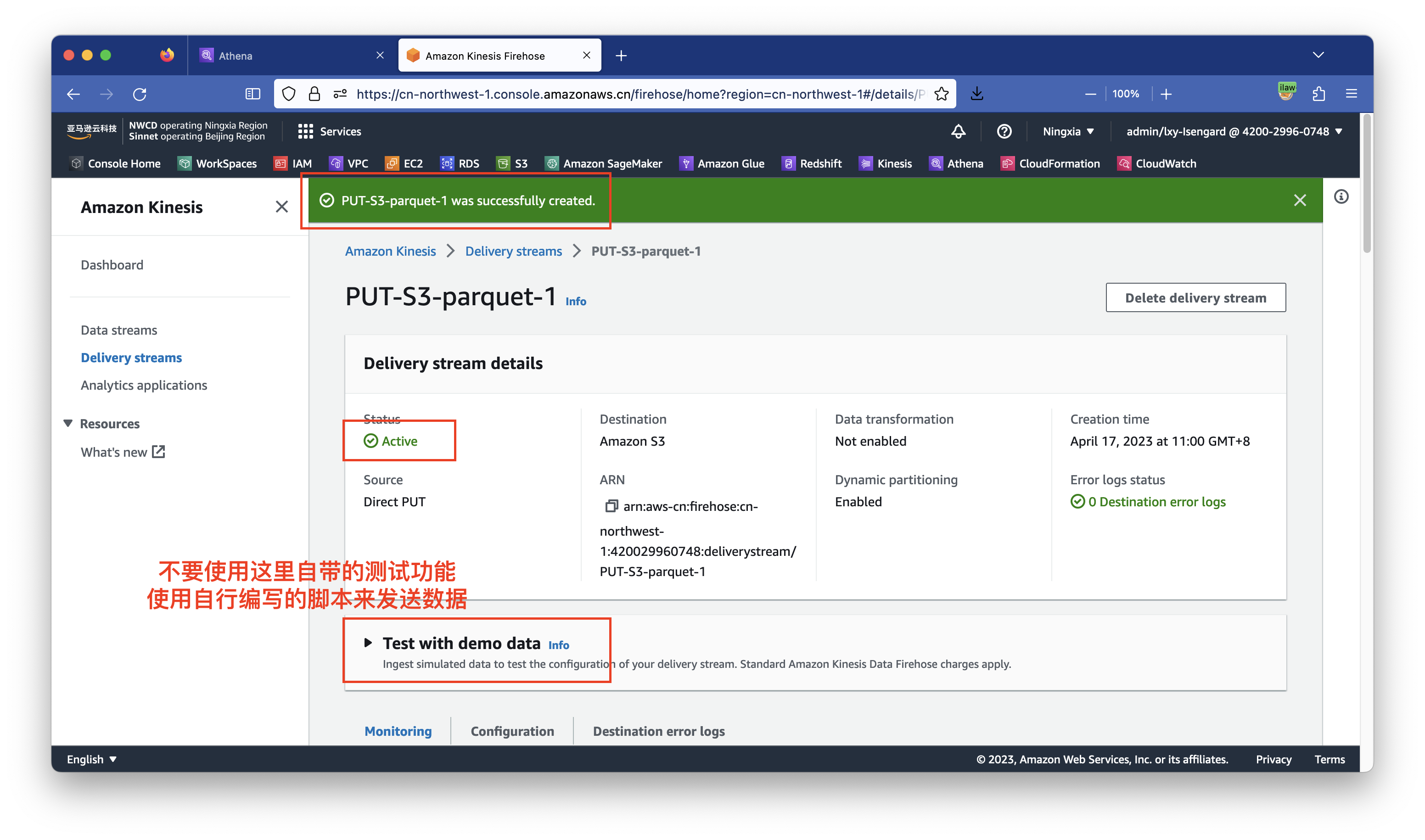
首先等待几分钟,确保Kinesis显示Status位置为绿色的Active。页面上有一个Test with demo data这里也不要使用,因为其数据缺少自定义分区字段。稍后使用自定义脚本生成数据测试。如下截图。
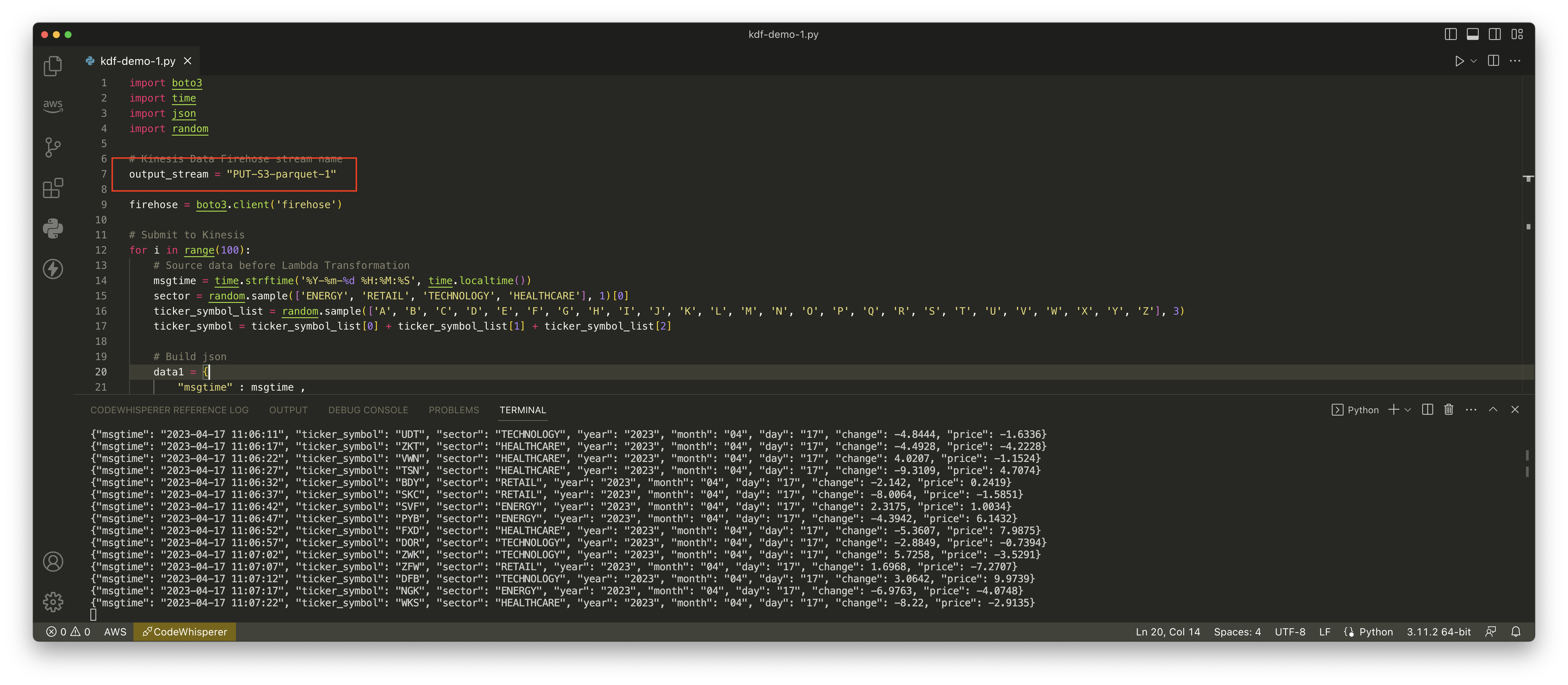
运行生成数据脚本前,需要在运行代码的环境上提前配置好Python、AWSCLI的密钥,设置好AWS区域。执行如下命令安装Boto3库。
pip3 install boto3将如下代码保存为kdf-demo.py。然后运行python3 kdf-demo.py执行之。本文两个不同分区键的实验都使用这个脚本生成数据。在Kinesis Data Firehose配置过程中会设置自定义分区键来声明S3保存目录和分区。
import boto3
import time
import json
import random
# Kinesis Data Firehose stream name
output_stream = "PUT-S3-parquet-1"
firehose = boto3.client('firehose')
# Submit to Kinesis
for i in range(100):
# Source data before Lambda Transformation
msgtime = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
sector = random.sample(['ENERGY', 'RETAIL', 'TECHNOLOGY', 'HEALTHCARE'], 1)[0]
ticker_symbol_list = random.sample(['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z'], 3)
ticker_symbol = ticker_symbol_list[0] + ticker_symbol_list[1] + ticker_symbol_list[2]
# Build json
data1 = {
"msgtime" : msgtime ,
"ticker_symbol" : ticker_symbol ,
"sector" : sector ,
"year" : time.strftime('%Y', time.localtime()) ,
"month" : time.strftime('%m', time.localtime()) ,
"day" : time.strftime('%d', time.localtime()) ,
"change" : round(random.uniform(-10, 10),4) ,
"price" : round(random.uniform(-10, 10),4)
}
msg = json.dumps(data1)
firehose.put_record(
DeliveryStreamName=output_stream,
Record={
'Data': msg
}
)
print(msg)
time.sleep(5)以上脚本中的output_stream需要替换为本文实际使用的Kinesis流的名字。
运行数据生成脚本,确认对应的Region,并确认Kinesis流的名称与配置的一致。可看到数据正常发送。如下截图。
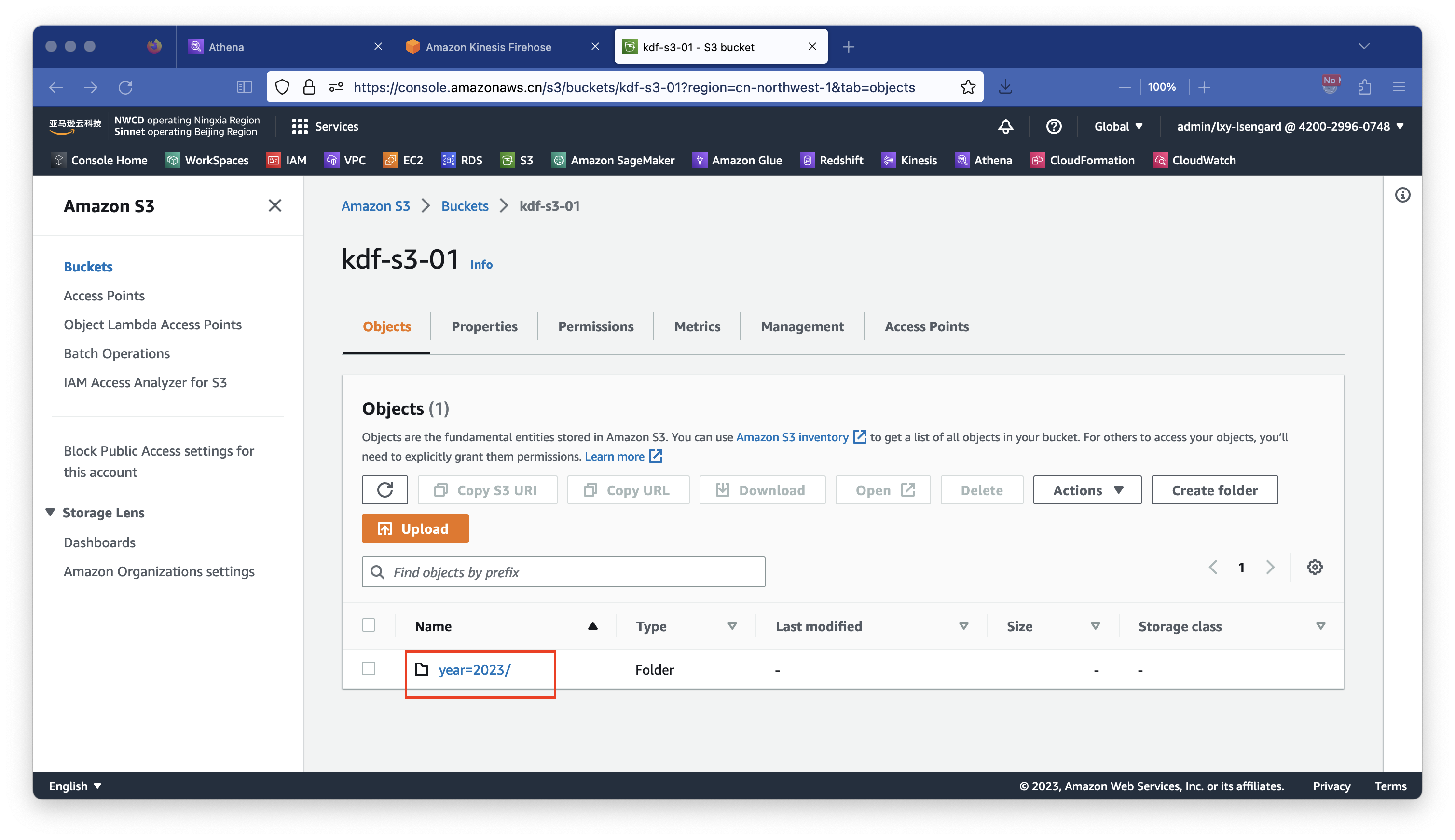
数据发送等待1~2分钟后,检查S3存储桶,可以看到其中的数据已经落盘。如下截图。
为了进一步确认S3存储桶的数据结构,这里可以使用AWSCLI的aws s3 ls --recursive命令,递归的查看本存储桶内所有子目录和数据。
aws s3 ls kdf-s3-01 --recursive <aws:zhy>
2023-04-17 11:07:58 1378 year=2023/month=04/day=17/PUT-S3-parquet-1-1-2023-04-17-03-05-21-d63ecfdf-c0bd-3227-8355-627e40acc8cb.parquet
2023-04-17 11:09:59 1067 year=2023/month=04/day=17/PUT-S3-parquet-1-1-2023-04-17-03-07-32-6a8fac69-e7c4-3727-a4cb-a83e7095478b.parquet
2023-04-17 11:11:02 1356 year=2023/month=04/day=17/PUT-S3-parquet-1-1-2023-04-17-03-08-33-65e76942-d56c-3b64-b9f6-018d503eefe0.parquet
2023-04-17 11:13:07 1067 year=2023/month=04/day=17/PUT-S3-parquet-1-1-2023-04-17-03-10-40-40d516cf-91b4-32f5-99c2-5e3c95c5c0e1.parquet
2023-04-17 11:14:08 1085 year=2023/month=04/day=17/PUT-S3-parquet-1-1-2023-04-17-03-11-40-7068021f-2c7a-391e-8906-59cbf3b2471c.parquet
2023-04-17 11:15:17 1063 year=2023/month=04/day=17/PUT-S3-parquet-1-1-2023-04-17-03-12-46-116ddc75-eba5-3222-862b-3a45938f949c.parquet执行结果如下截图。
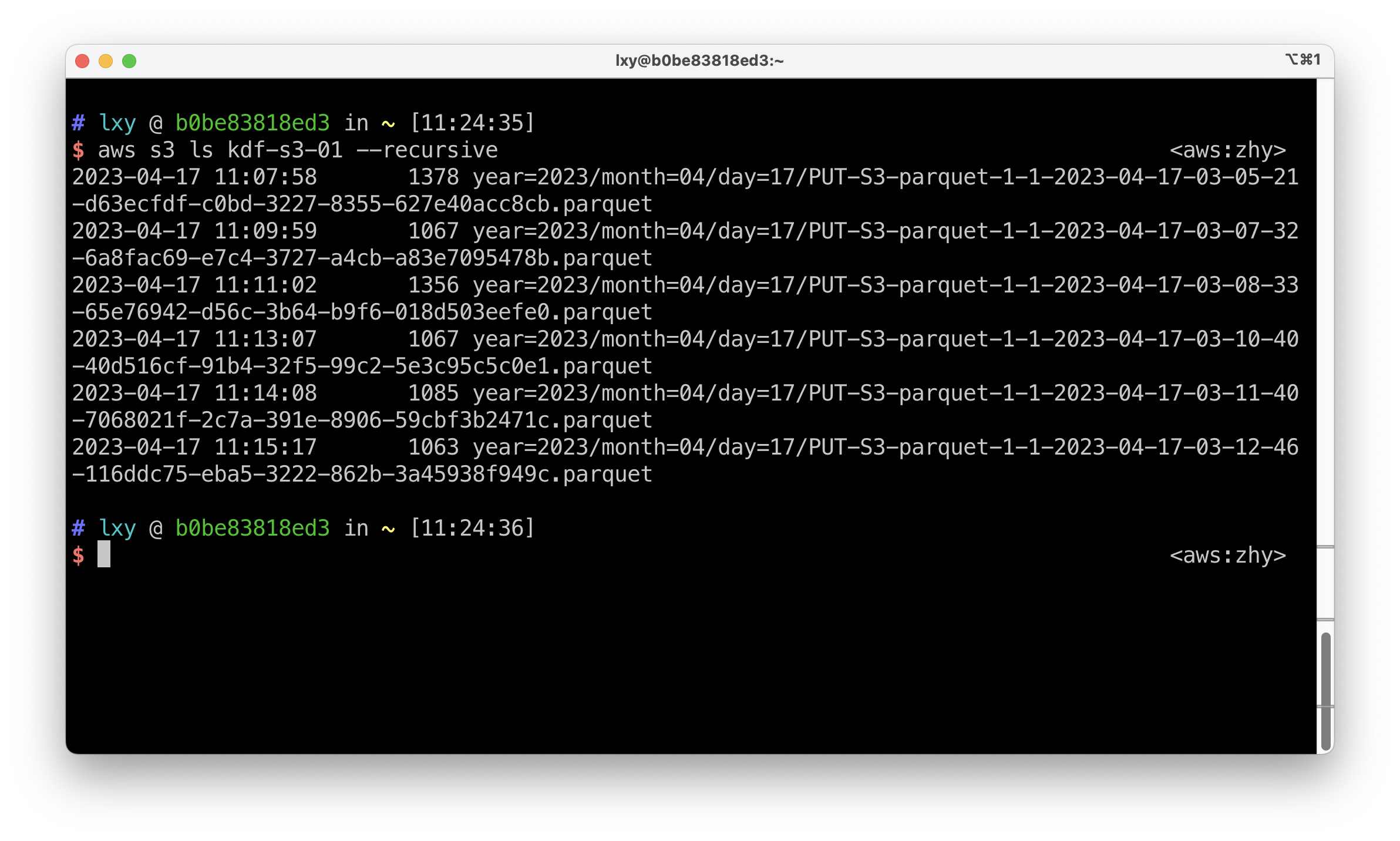
由此可看到,生成的数据分别是带有年、月、日三级目录结构作为分区键,符合预期。
4、使用Athena识别新的分区并查询数据
回到Athena界面上,选中之前创建的数据库。执行如下命令添加分区。如下截图。
MSCK REPAIR TABLE `kdfs301`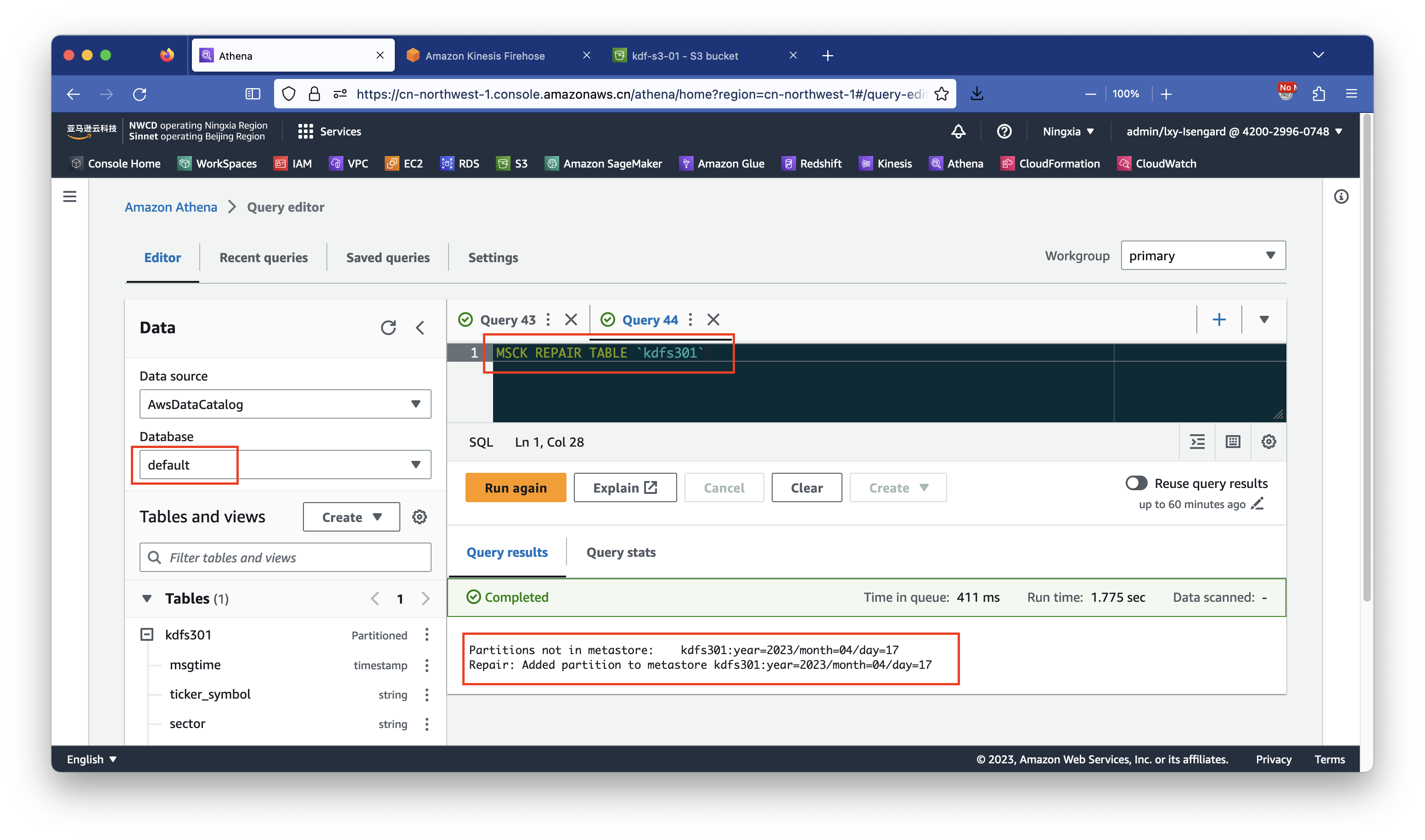
执行成功后返回结果如下:
Partitions not in metastore: kdfs301:year=2023/month=04/day=17
Repair: Added partition to metastore kdfs301:year=2023/month=04/day=17由此表示新的分区键已经被识别和加载,可以使用Athena查询了。
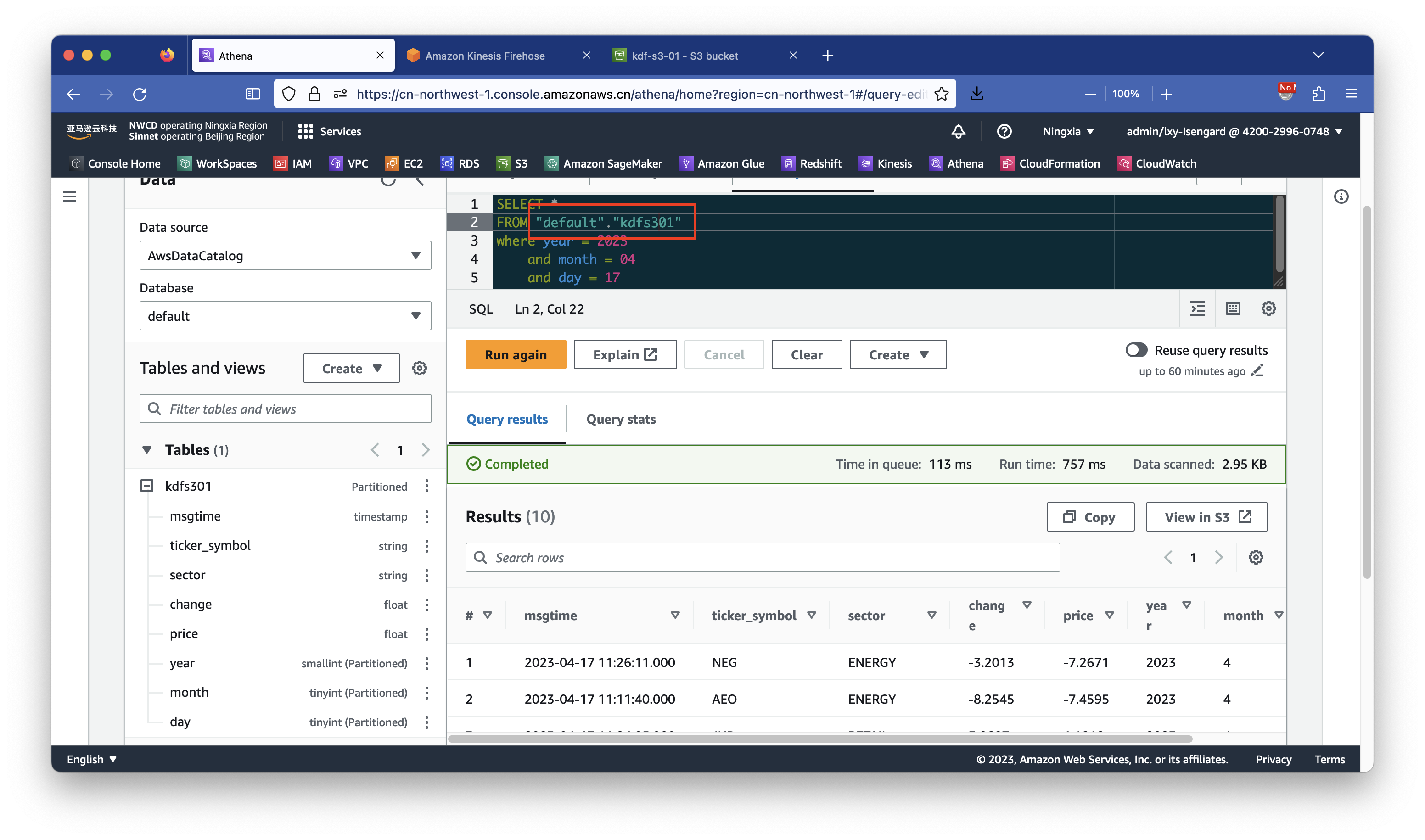
执行如下命令查询:
SELECT *
FROM "default"."kdfs301"
where year = 2023
and month = 04
and day = 04
limit 10;即可看到查询数据正常。如下截图。
5、查询数据注意事项
使用Athena查询时候需要注意,每次有新的分区被加入,都需要再次执行msck命令让Athena识别和加载新的分区。如果使用时间(年/月/日)作为分区键,那么可设置计划任务,每天自动执行一次加载新分区即可。在已经存在的分区内注入新的数据时候,是不需要再次执行msck命令的。
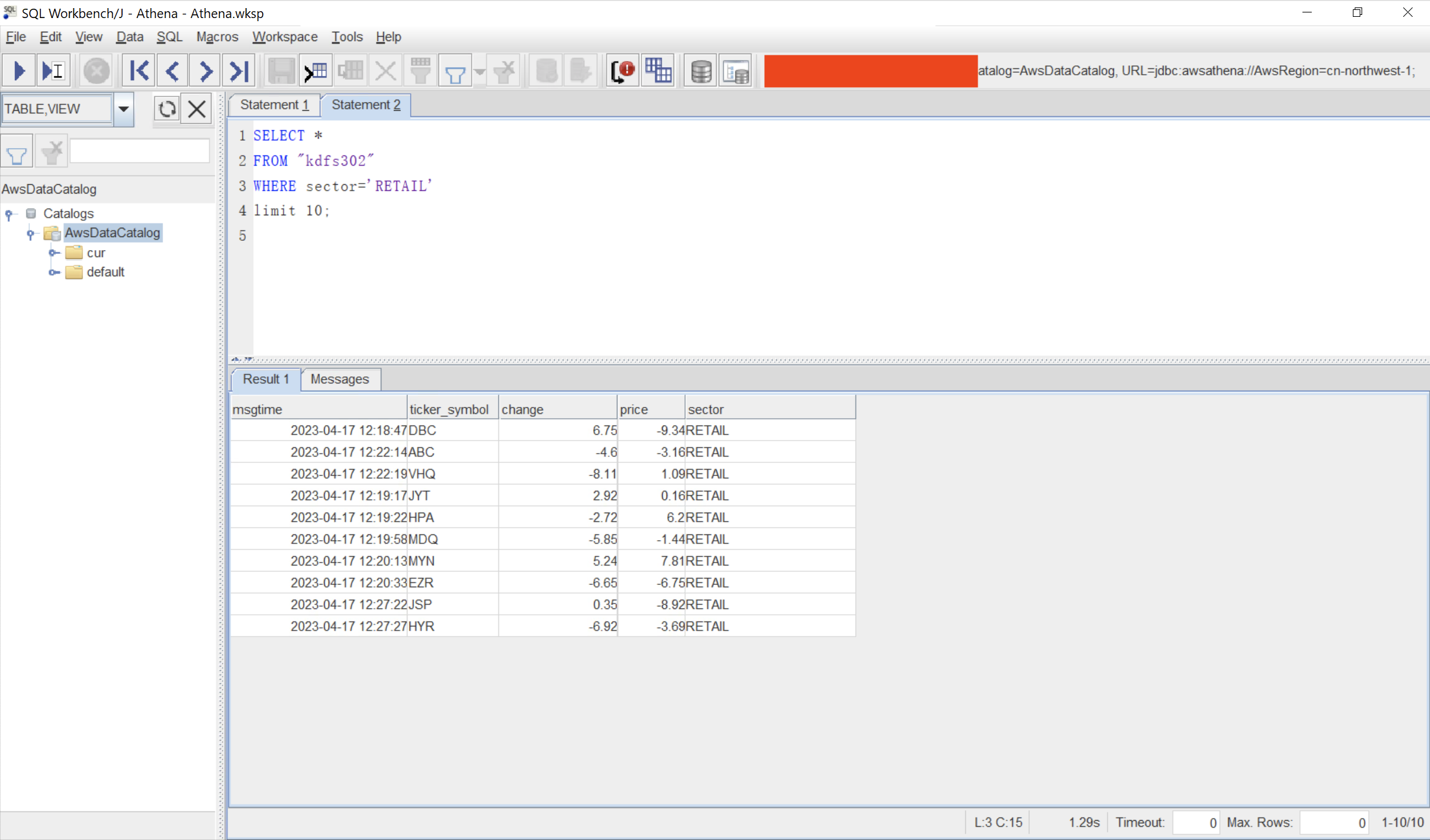
此外,Athena支持JDBC接口方式访问,通过在应用软件、SQL客户端上配置好Athena JDBC驱动,然后直接将上述SQL发送到云端,即可获得查询结果。有关JDBC配置请参考另外的文档。JDBC接口查询效果如下截图。
至此实验一完成。
四、实验2-使用某数据字段作为自定义分区键值
实验二是以上实验一的重复过程,只是使用了不同的自定义分区键。因此在Athena、Kinesis控制台界面上重复配置过程将不进行详细讲解,这里只给出实验二和实验一有区别的配置。
1、创建Glue表
在Athena中执行如下SQL语句,其中功能有两个部分需要替换成真实值。第一行的kdfs302请替换为Glue和Athena未来要使用的表的名字。倒数第四行的s3://kdf-s3-02/请替换成Kinesis保存数据的S3桶的名字。
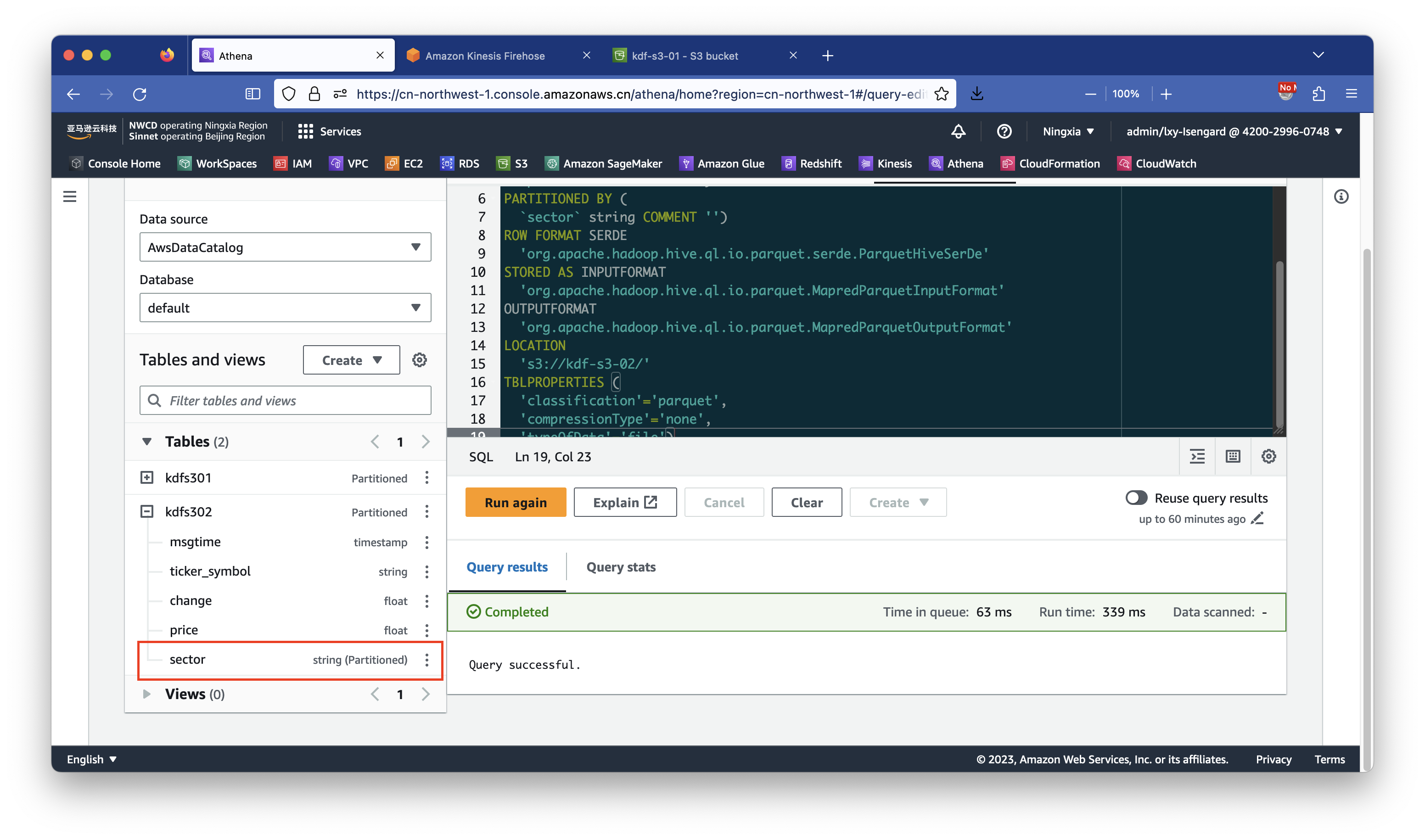
CREATE EXTERNAL TABLE `kdfs302`(
`msgtime` timestamp COMMENT '',
`ticker_symbol` string COMMENT '',
`change` float COMMENT '',
`price` float COMMENT '')
PARTITIONED BY (
`sector` string COMMENT '')
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://kdf-s3-02/'
TBLPROPERTIES (
'classification'='parquet',
'compressionType'='none',
'typeOfData'='file')创建完成后,可看到表的分区键是刚指定的sector。如下截图。
2、创建Kinesis Data Firehose
配置相同的步骤略过。
Kinesis流名称填写为PUT-S3-parquet-2,名字与前一个流区别开。
与使用年、月、日做分区键相比,使用sector做分区键时候,填写如下:
- Key name:
sector,JQ expression:.sector
以上参数填写到下方的Key name和JQ expression表达式中。然后向下滚动页面。如下截图。
在S3 bucket prefix的表达式位置填写为:sector=!{partitionKeyFromQuery:sector}/。
其他设置与前文相同。(注意落盘间隔时间也调整为60秒)
3、生成测试数据并检查S3存储桶数据是否落盘
实验二使用sector做分区键的脚本如下:
import boto3
import time
import json
import random
# Kinesis Data Firehose stream name
output_stream = "PUT-S3-parquet-2"
firehose = boto3.client('firehose')
# Submit to Kinesis
for i in range(1000):
# Source data before Lambda Transformation
msgtime = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
sector = random.sample(['ENERGY', 'RETAIL', 'TECHNOLOGY', 'HEALTHCARE'], 1)[0]
ticker_symbol_list = random.sample(['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z'], 3)
ticker_symbol = ticker_symbol_list[0] + ticker_symbol_list[1] + ticker_symbol_list[2]
# Build json
data1 = {
"msgtime" : msgtime ,
"ticker_symbol" : ticker_symbol ,
"sector" : sector ,
"change" : round(random.uniform(-10, 10),4) ,
"price" : round(random.uniform(-10, 10),4)
}
msg = json.dumps(data1)
firehose.put_record(
DeliveryStreamName=output_stream,
Record={
'Data': msg
}
)
print(msg)
time.sleep(5)运行这个脚本。在1~2分钟后,可以从S3存储桶内看到数据。
通过AWSCLI也可以查询到数据。
aws s3 ls kdf-s3-02 --recursive <aws:zhy>
2023-04-17 12:21:09 694 sector=ENERGY/PUT-S3-parquet-2-1-2023-04-17-04-18-42-e43dc0e0-e903-3e7d-bd33-4eba3db404dd.parquet
2023-04-17 12:21:09 878 sector=HEALTHCARE/PUT-S3-parquet-2-1-2023-04-17-04-18-32-6b1d6332-5bd5-3363-aa70-70587305e602.parquet
2023-04-17 12:21:08 740 sector=RETAIL/PUT-S3-parquet-2-1-2023-04-17-04-18-47-03c01a37-aef5-30d4-8fcc-5bf7379fc5b2.parquet
2023-04-17 12:21:09 694 sector=TECHNOLOGY/PUT-S3-parquet-2-1-2023-04-17-04-18-52-468f1e7d-babf-33ca-a62f-7d0686851c38.parquet4、使用Athena查询
步骤和方法与上文相同。先执行msck命令识别新的分区,然后查询。
MSCK REPAIR TABLE `kdfs302`如下截图。
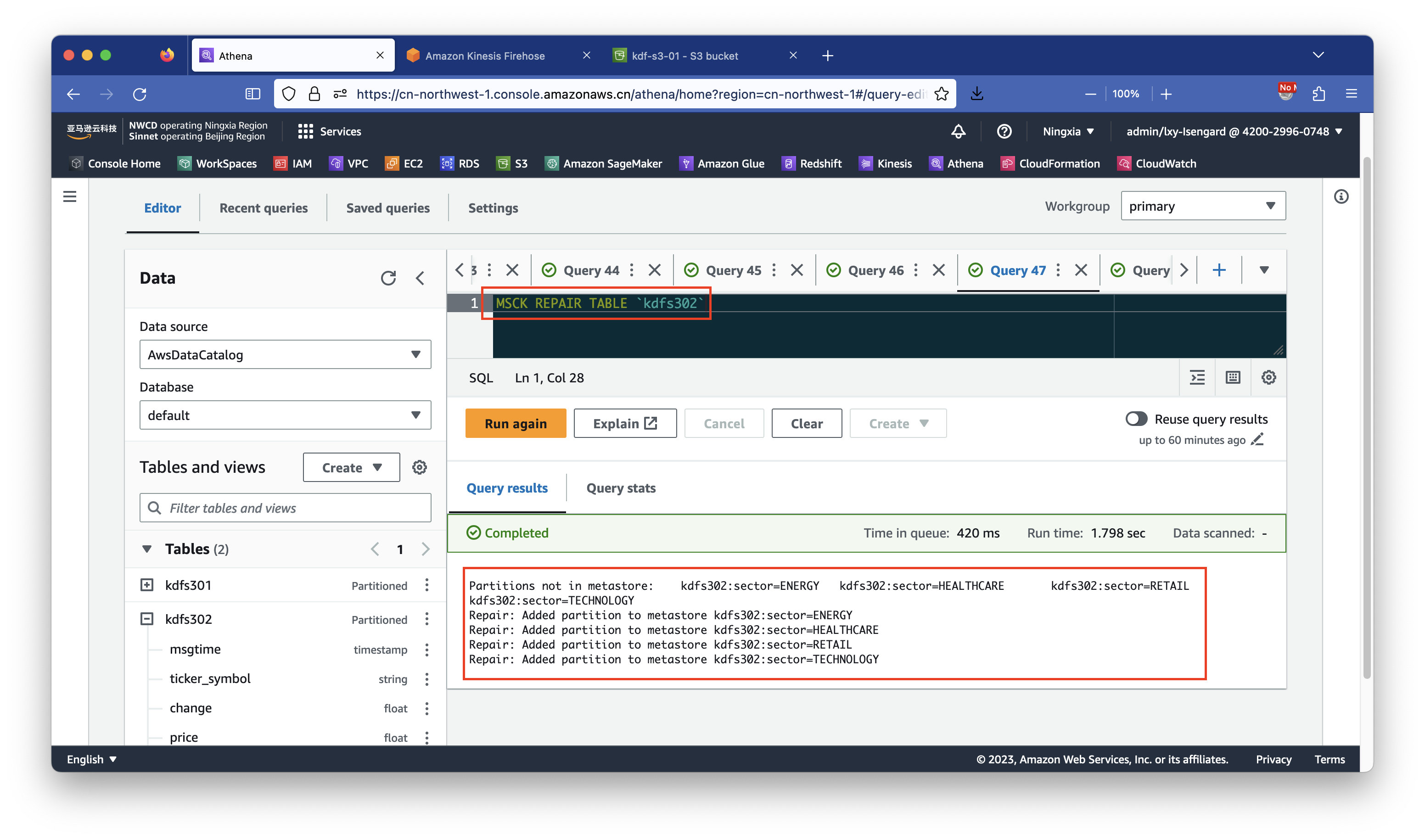
返回结果如下表示识别到了新的分区。
Partitions not in metastore: kdfs302:sector=ENERGY kdfs302:sector=HEALTHCARE kdfs302:sector=RETAIL kdfs302:sector=TECHNOLOGY
Repair: Added partition to metastore kdfs302:sector=ENERGY
Repair: Added partition to metastore kdfs302:sector=HEALTHCARE
Repair: Added partition to metastore kdfs302:sector=RETAIL
Repair: Added partition to metastore kdfs302:sector=TECHNOLOGY在Athena上执行如下SQL发起查询。
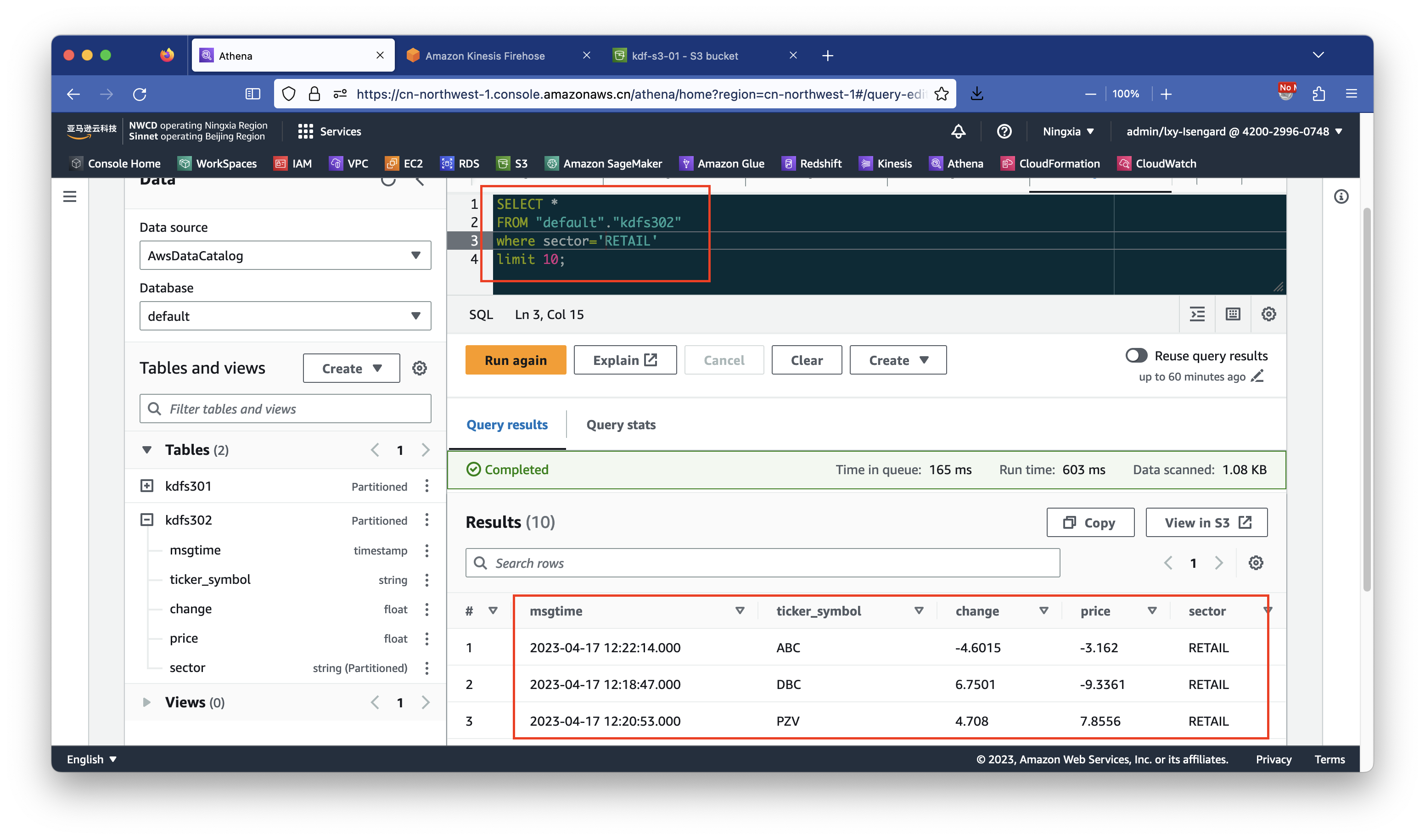
SELECT *
FROM "default"."kdfs302"
WHERE sector="RETAIL"
limit 10;查询成功。如下截图。
五、参考文档
Kinesis Data Firehose now supports dynamic partitioning to Amazon S3
Amazon Kinesis Data Firehose Immersion Day – Lab 3-1 – Partition streaming JSON data
Dynamic Partitioning in Kinesis Data Firehose
https://docs.aws.amazon.com/firehose/latest/dev/dynamic-partitioning.html
在 Athena 中对数据进行分区(Hive风格和非Hive风格)
https://docs.aws.amazon.com/zh_cn/athena/latest/ug/partitions.html
Athena JDBC接口配置
https://docs.aws.amazon.com/zh_cn/athena/latest/ug/connect-with-jdbc.html