使用Claude 3进行OCR文字识别将影印件PDF并转换为Markdown文本格式
通过Bedrock调用Claude 3模型实现PDF影印件OCR识别,将图片转换为Markdown文本。介绍依赖安装、代码实现和识别效果,探讨Prompt优化对识别准确度的影响。
一、背景
RAG+LLM Chatbot解决方案是AWS中国团队开发的大语言模型的RAG对话机器人,它是一个基于Serverless无服务器技术构建、使用LangChain框架的解决方案,用于快速搭建一套可用于生产环境的知识问答机器人。RAG+LLM Chatbot 支持向量模型 & 大语言模型的灵活配置插拔,设计上采用无服务器方式,无需EC2,前后端分离,可集成到即时通信工具(如飞书)。
在这套解决方案中,包含了一个摄取PDF进行OCR文字识别的工具,其代码可从Github上这里获取。本文介绍使用这个代码调用Claude3模型实现OCR识别。
二、执行OCR
1、样本准备
我们将AWS官网文档做个截图,然后将这个截图转换为PDF格式。此时在预览等PDF浏览软件中,可以看到本PDF是整体的截图。
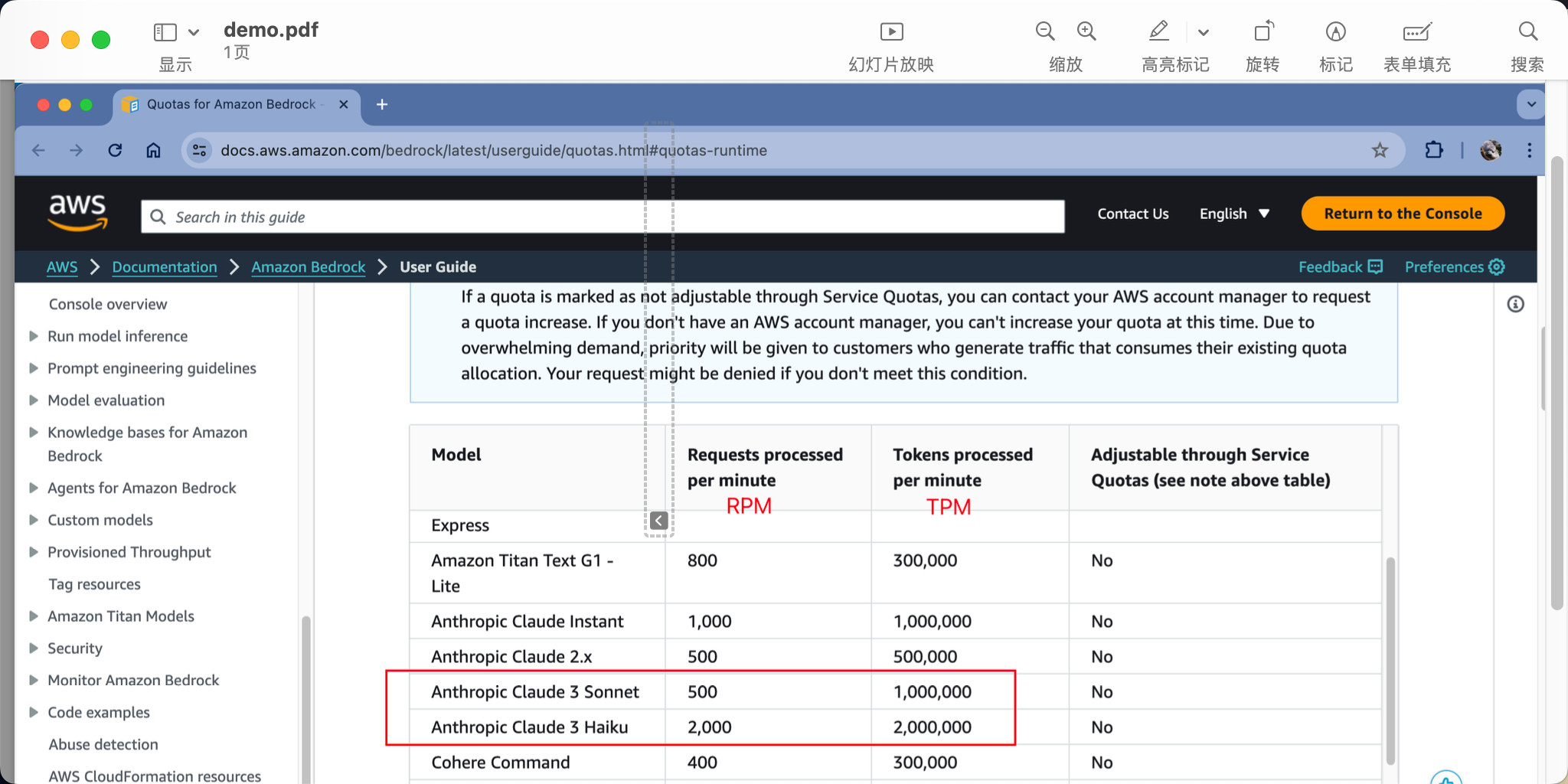
在当前目录下,创建子目录PDF(注意全大写)用于存放待识别的PDF。创建子目录output(注意全小写)用于保存输出之后的Markdown文本文件。
2、安装依赖库
为了完成OCR,需要安装名为pdf2image的Python库。
pip3 install pdf2image
此外,为了处理PDF信息,还需要安装poppler软件。在MacOS上可使用brew安装。在Linux上可使用apt或者yum安装。
brew install poppler
3、运行代码
安装依存库完毕后,将如下代码从Github上这里复制到本地,确保本地已经配置好了AWS的AKSK密钥,然后运行之。
import boto3
import base64
import io
import json
import os
import argparse
from tqdm import tqdm
from PIL import Image
from typing import Any, Dict, List, Optional, Mapping
from pdf2image import convert_from_path
def format_to_message(query:str, image_base64_list:List[str]=None, role:str = "user"):
if image_base64_list:
content = [{ "type": "image", "source": { "type": "base64", "media_type": "image/png", "data": image_base64 }} for image_base64 in image_base64_list ]
content.append({ "type": "text", "text": query })
return { "role": role, "content": content }
return {"role": role, "content": query }
def Image2base64(img_path):
image = Image.open(img_path)
buffer = io.BytesIO()
image.save(buffer, format="PNG")
image_data = buffer.getvalue()
base64_encoded_string = base64.b64encode(image_data).decode('utf-8')
return base64_encoded_string
def construct_multimodal_prompt(img_path):
prompt = """Please help me organize the content on the picture into text.
<requirements>
1. Based on the layout in the image, determine the output order. If there is no explicit order, convert the text part first, then the chart part.
2. Output in markdown format. Try your best to keep all the information(text, format, chart).
4. Pay attention to the formatting, keep the the quote and header level.
5. convert image to markdown picture tag, describe image in image name, for example ""
6. convert table into markdown table format
7. convert bar chart into bullets format, use Chart Title as Title, Category Label as bullet header, Value Labels as value, keep all category labels.
8. convert pie chart into bullets format, use Chart Title as Title, Category Label as bullet header, Value Labels as value, keep all category labels.
9. Be consistent with the original language in pictures.
</requirements>
put your output between <output> and </output>"""
base64_image = Image2base64(img_path)
message = format_to_message(prompt, [base64_image])
messages = [ message, { "role":"assistant", "content": "<output>"} ]
input_body = {}
input_body["anthropic_version"] = "bedrock-2023-05-31"
input_body["messages"] = messages
input_body["max_tokens"] = 4096
input_body["stop_sequences"] = ['</output>']
body = json.dumps(input_body)
return body
def convert2markdown(img_path):
md_result = ""
try:
request_body = construct_multimodal_prompt(img_path)
request_options = {
"body": request_body,
"modelId": 'anthropic.claude-3-sonnet-20240229-v1:0',
"accept": "application/json",
"contentType": "application/json",
}
response = boto3_bedrock.invoke_model(**request_options)
body = response.get('body').read().decode('utf-8')
body_dict = json.loads(body)
md_result = body_dict['content'][0].get("text")
except Exception as e:
print(f"failed to process {img_path}")
print(e)
return md_result
def pdf2image(input_dir, output_dir):
for root, dirs, files in os.walk(input_dir):
for file in files:
if not file.endswith('.pdf'):
print(f"skip {file}..")
continue
# 构造文件的完整路径
file_path = os.path.join(root, file)
path_without_ext, ext = os.path.splitext(file_path)
file_name = os.path.basename(path_without_ext)
if not os.path.exists(output_dir):
os.makedirs(output_dir)
folder_dest = f'{output_dir}/{file_name}'
if not os.path.exists(folder_dest):
os.makedirs(folder_dest)
images = convert_from_path(file_path, 300)
for idx, image in tqdm(enumerate(images)):
image_path = f'./{folder_dest}/page-{idx}.png'
image.save(image_path)
def image2markdown(input_dir, output_dir):
# 遍历目录及其子目录中的所有文件
files = os.listdir(input_dir)
for file in tqdm(files):
print(f"processsing {file}")
file_path = os.path.join(input_dir, file)
if os.path.isdir(file_path):
png_files = os.listdir(file_path)
for png_file in png_files:
png_path = os.path.join(file_path, png_file)
if png_path.endswith('.png'):
output_path = png_path.replace(input_dir, output_dir).replace('.png', '.md')
conent = convert2markdown(png_path)
output_sub_folder = file_path.replace(input_dir, output_dir)
if not os.path.exists(output_sub_folder):
os.makedirs(output_sub_folder)
with open(output_path, 'w') as file:
file.write(conent)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--input_path', type=str, default='./PDF', help='input path')
parser.add_argument('--output_path', type=str, default='./output', help='output path')
parser.add_argument('--region_name', type=str, default='us-west-2', help='aws region')
args = parser.parse_args()
pdf_path = args.input_path
output_path = args.output_path
region = args.region_name
image_path = f"{output_path}/images"
markdown_path = f"{output_path}/markdown"
boto3_bedrock = boto3.client(
service_name="bedrock-runtime",
region_name=region
)
pdf2image(pdf_path, image_path)
image2markdown(image_path, markdown_path)
运行文件。
/usr/local/bin/python3 /Users/lxy/Downloads/pdf2markdown_claude3.py --input_path=./PDF
返回结果如下:
1it [00:00, 2.35it/s]
0%| | 0/1 [00:00<?, ?it/s]processsing demo
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:11<00:00, 11.22s/it]
执行完毕,可看到在OUTPUT目录中生成了Markdown文件。
使用Markdown编辑器打开Markdown文件,并开启预览Preview查看效果,如下截图。
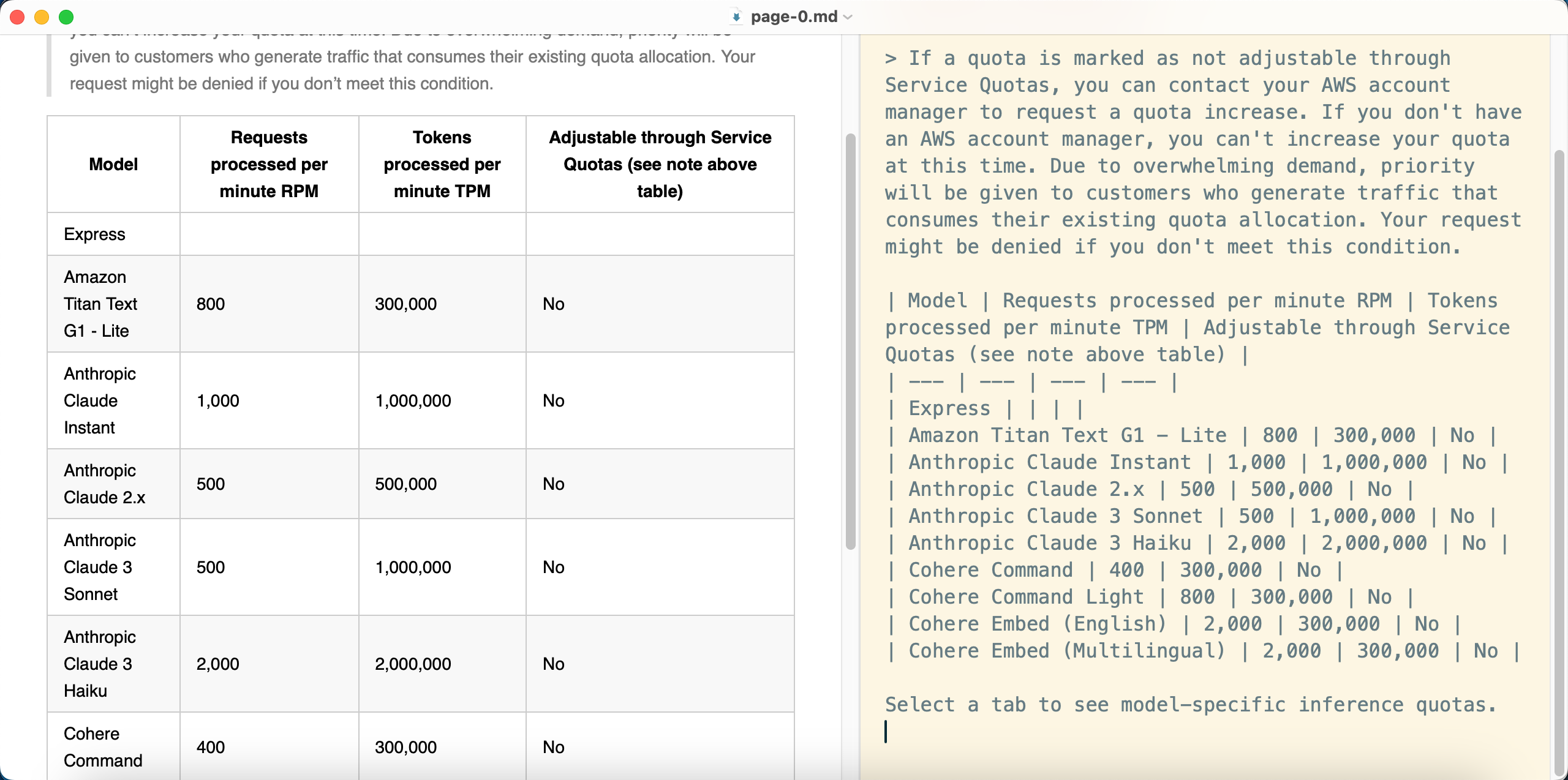
由此可看到,Claude 3模型成功识别了包含PDF影印件的文档中,右侧部分的文档关键字。但左侧的文档目录没有被OCR识别出来。这里需要进一步调整Prompt以识别左侧的菜单。
因此,使用大语言模型对图片做OCR是在技术上可行的,但不能保证100%准确,实际使用场景中需要根据特定输入格式调整Prompt,建议只用在有严格输入规范的场景以获得更好的效果。
三、参考文档
使用Claude3做OCR的Python示例代码
https://github.com/aws-samples/private-llm-qa-bot/blob/main/docpreprocess/pdf2markdownclaude3.py
RAG+LLM Chatbot 部署指南
https://upgt6k0dbo.feishu.cn/docx/GiLZd1glmo0l06xNRDmcr4P1nBf
基于Amazon Open Search+大语言模型的智能问答系统
https://catalog.us-east-1.prod.workshops.aws/workshops/158a2497-7cbe-4ba4-8bee-2307cb01c08a/zh-CN
最后修改于 2024-04-12