使用CloudTrail和Athena分析S3访问日志
本文介绍使用CloudTrail采集S3访问日志,通过Athena进行SQL查询分析。针对大量历史数据全表扫描导致成本高的问题,提出创建带分区键的Athena表方案,按Region和日期分区显著降低查询成本。
本文更新于2023年8月,新增了对于大量CloudTrail历史数据,需要实现创建分区键的说明。否则按照CloudTrail控制台推荐的默认的Athena建表语句进行查询,将是针对数个GB数据的全表扫描带来不必要的成本。按照本文新增章节,创建带有分区键的Athena表,即可显著降低查询成本。分区键推荐采用Region和日期的方式。
一、背景
S3存储桶的文件读写日志包括Server Access Log和CloudTrail两种方式。二者之间的差别可参考如下网址:
https://docs.aws.amazon.com/zh_cn/AmazonS3/latest/userguide/logging-with-S3.html
在官方上描述非常详细,可看到CloudTrail采集的信息更加丰富,因此本文将介绍使用CloudTrail做分析。如下截图。
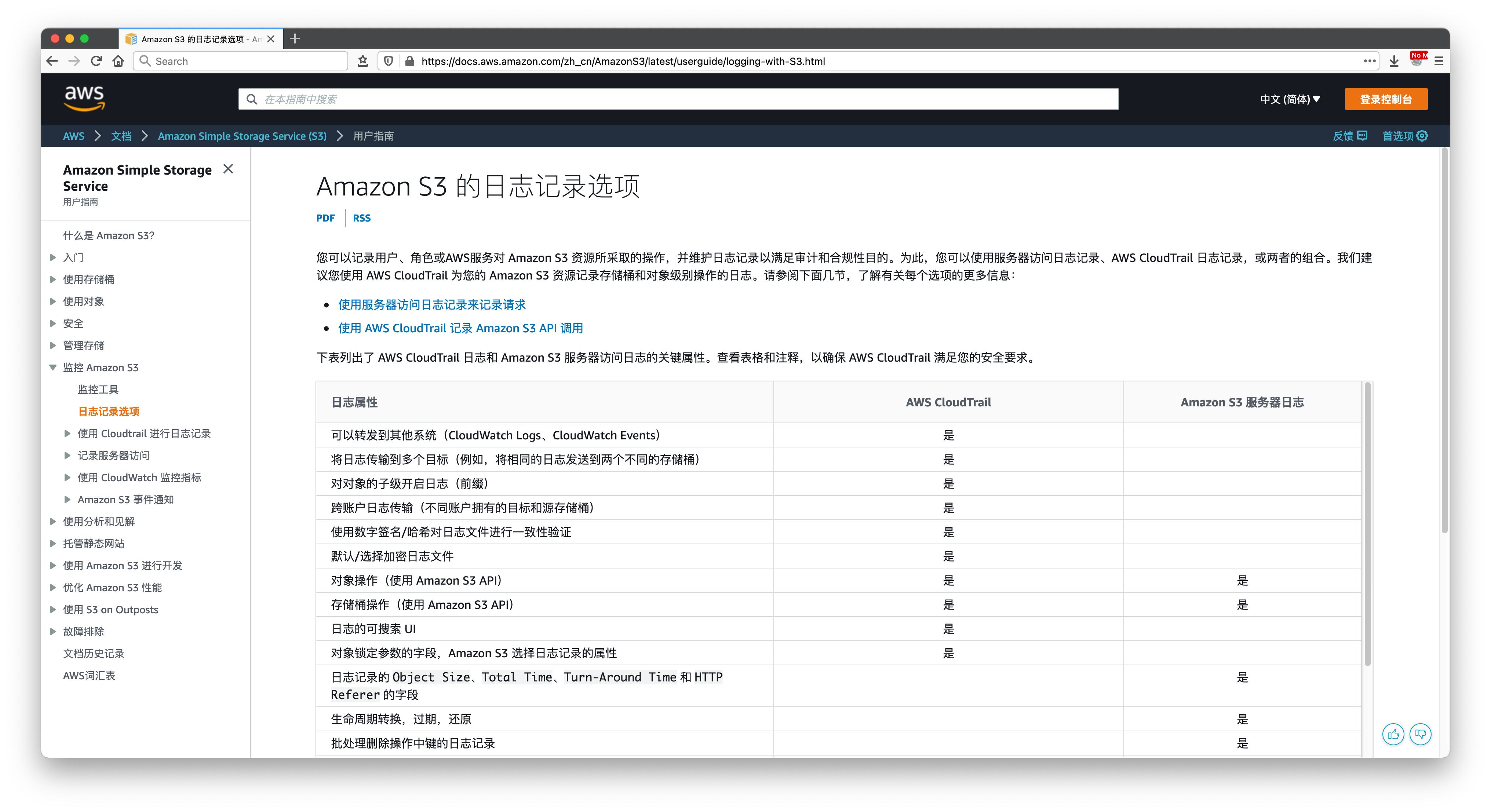
二、启用CloudTrail日志
CloudTrail日志可以从CloudTrail服务界面启动,也可以从S3存储桶界面跳转过去。本文截图描写从S3界面进入。
首先进入S3存储桶属性界面(第二个标签页)。如下截图。
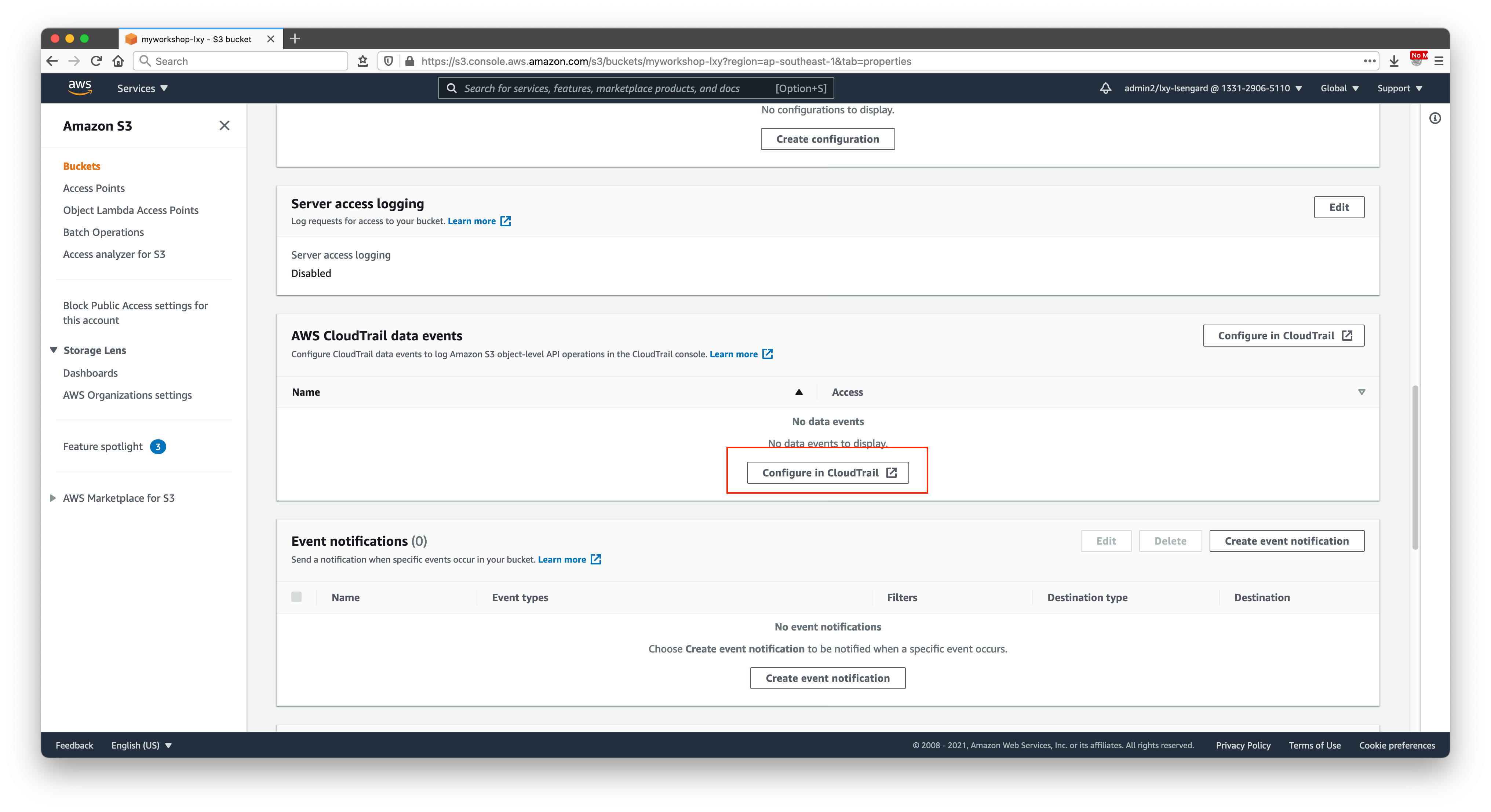
将页面向下滚动后,来到CloudTrail界面,点击配置CloudTrail即可跳转。如下截图。
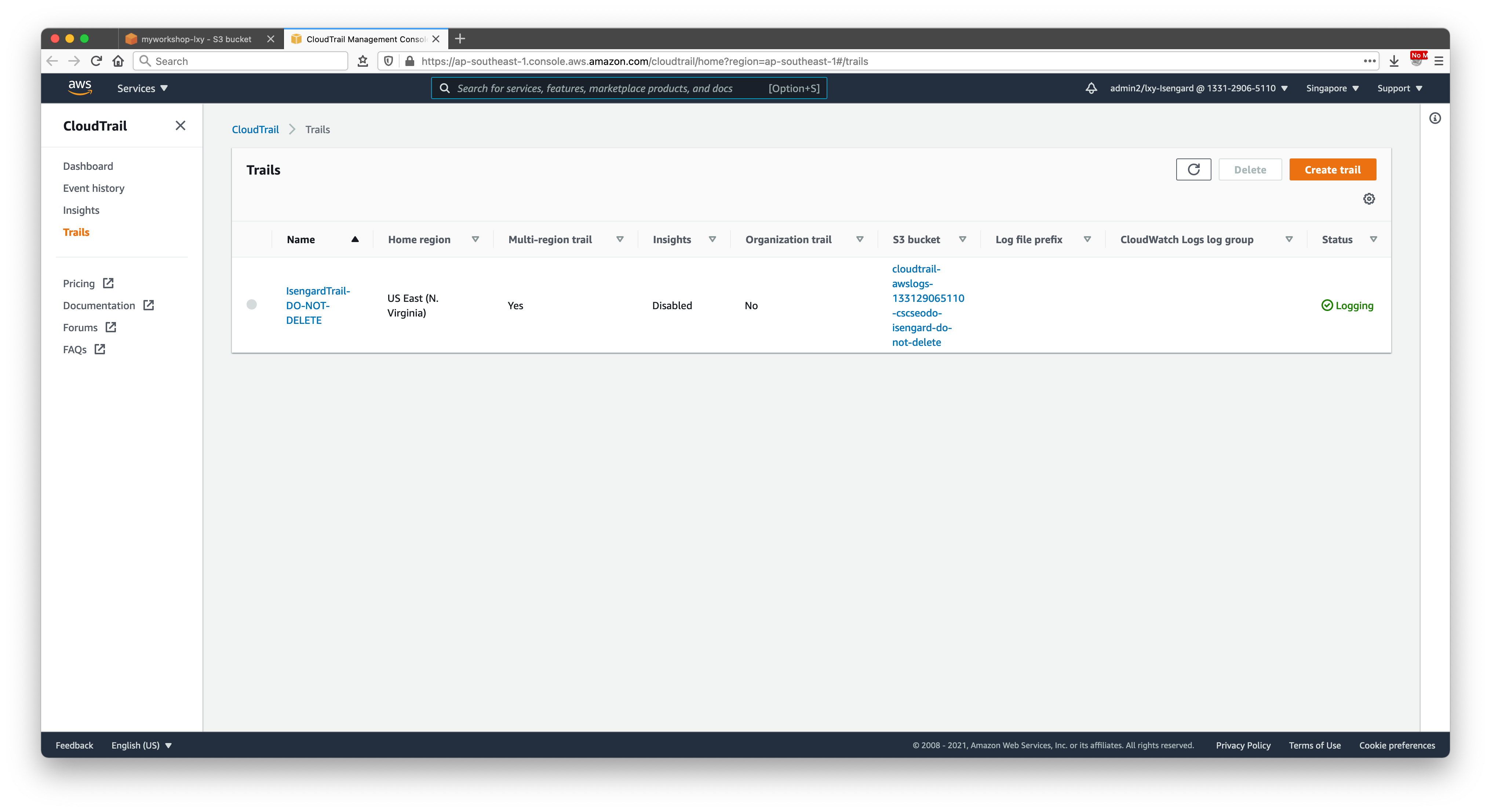
在CloudTrail界面,点击新建。如下截图。
在新建CloudTrail的界面上,输入名称,选择Create new S3 bucket,并使用自动生成的名称。新生成的日志将保存在这个存储桶内。此存储桶名字将包含AWS账户ID(12位数字),用以区分。如下截图。
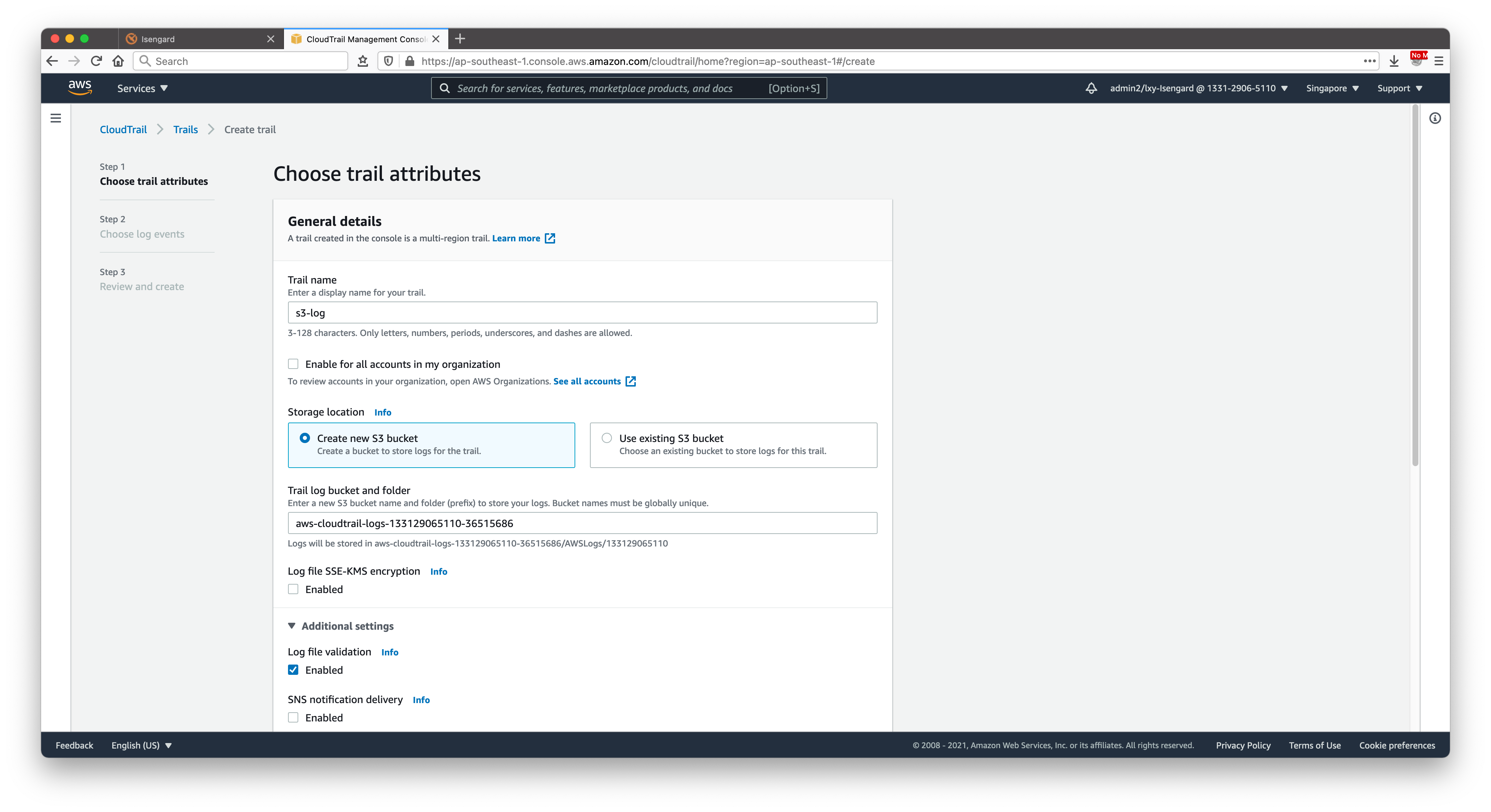
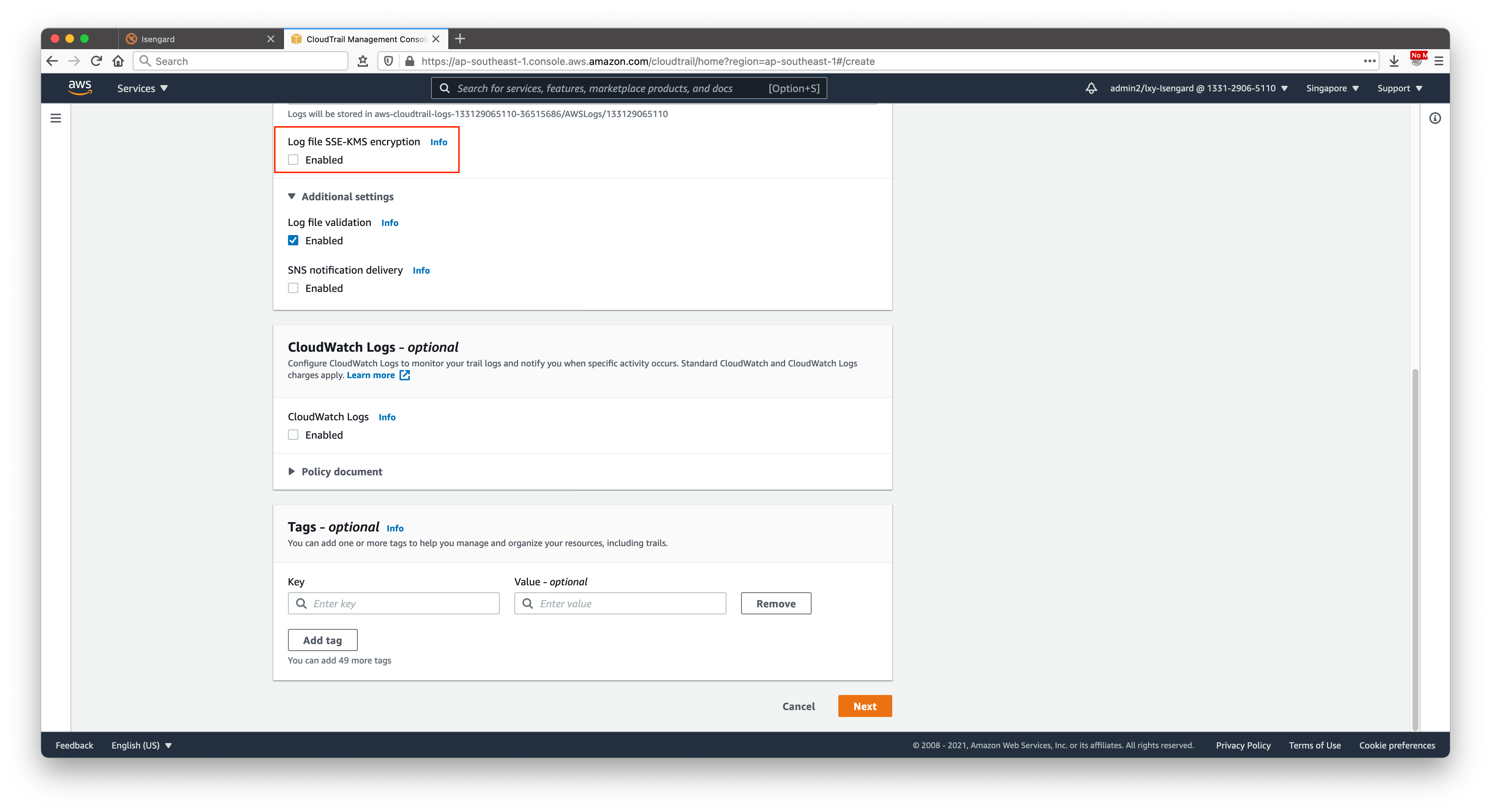
继续向下滚动屏幕。在加密位置,不要选中SSE-KMS加密。在CloudWatch Log位置不要启用,这样日志将仅保存到S3,不保存到CloudWatch。其他选项保持默认。如下截图。
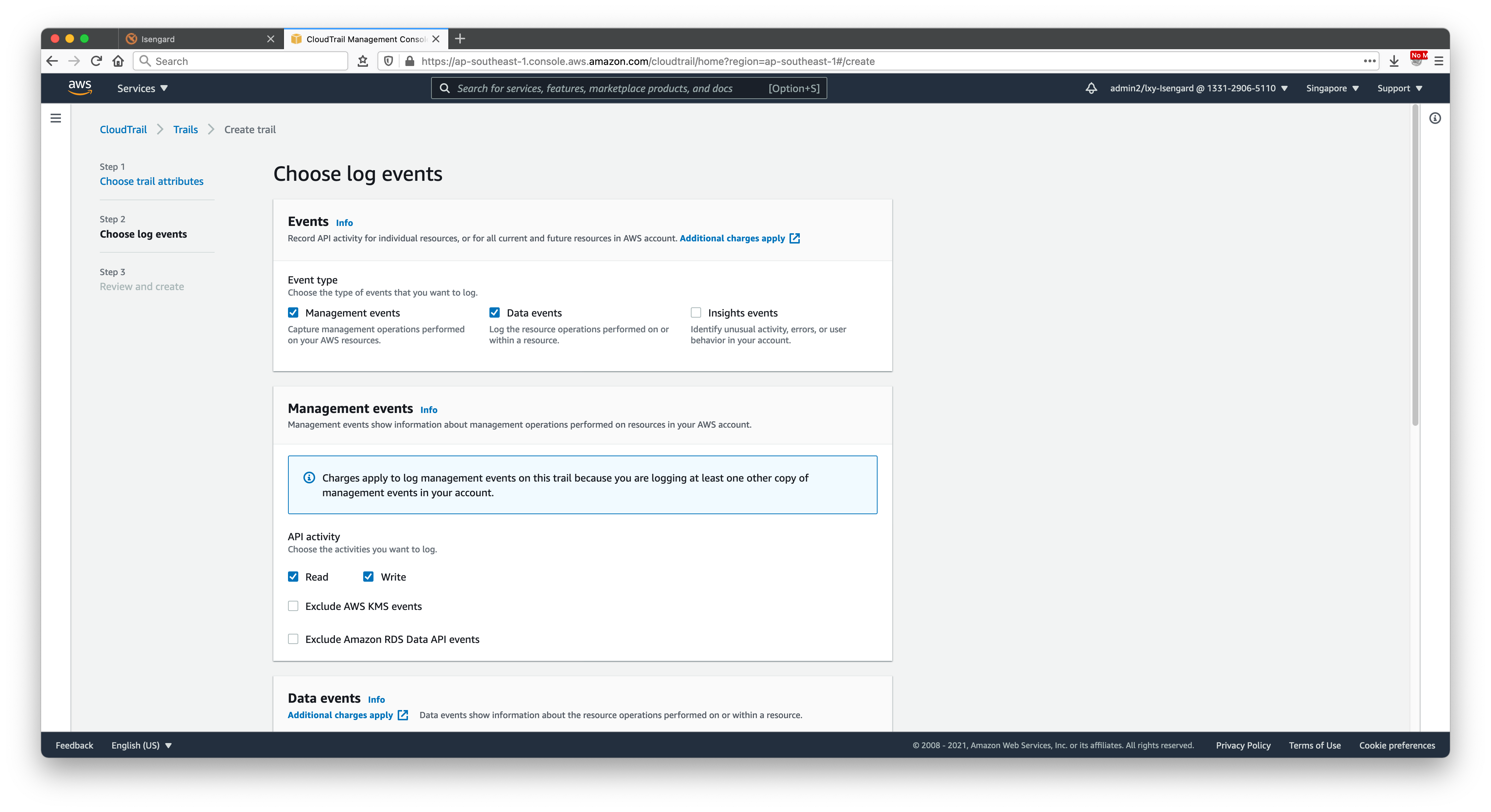
在向导第二步,选择Event Type事件类型是Management Event和Data events两个。其中第二个Data Event默认是不选中的,这里需要开启。其他选项保持默认不变。如下截图。
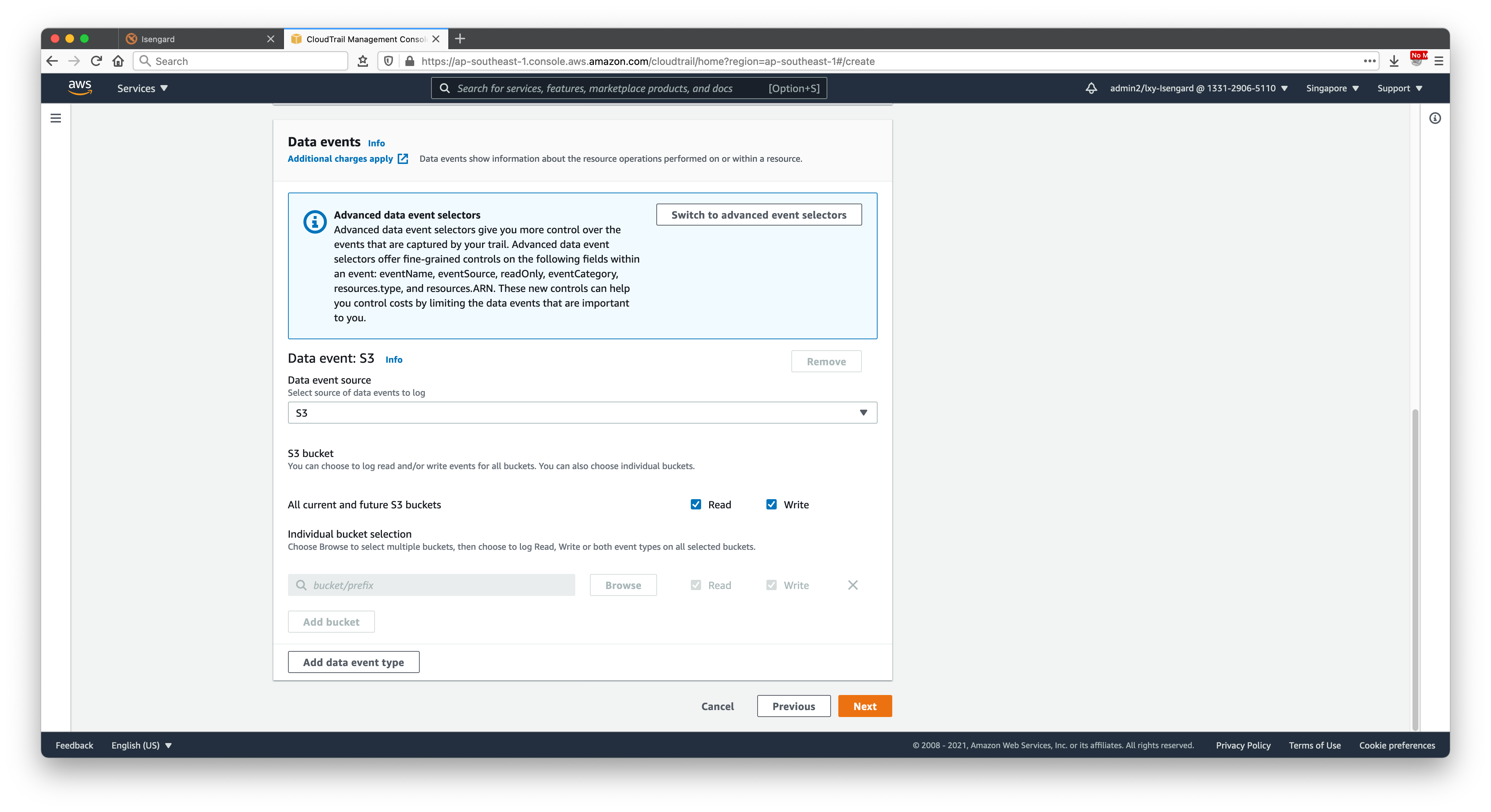
继续向下滚动页面。选项保持不变。点击右下角创建按钮。如下截图。
在向导的最后一步,无须修改任何设置,点击创建。如下截图。
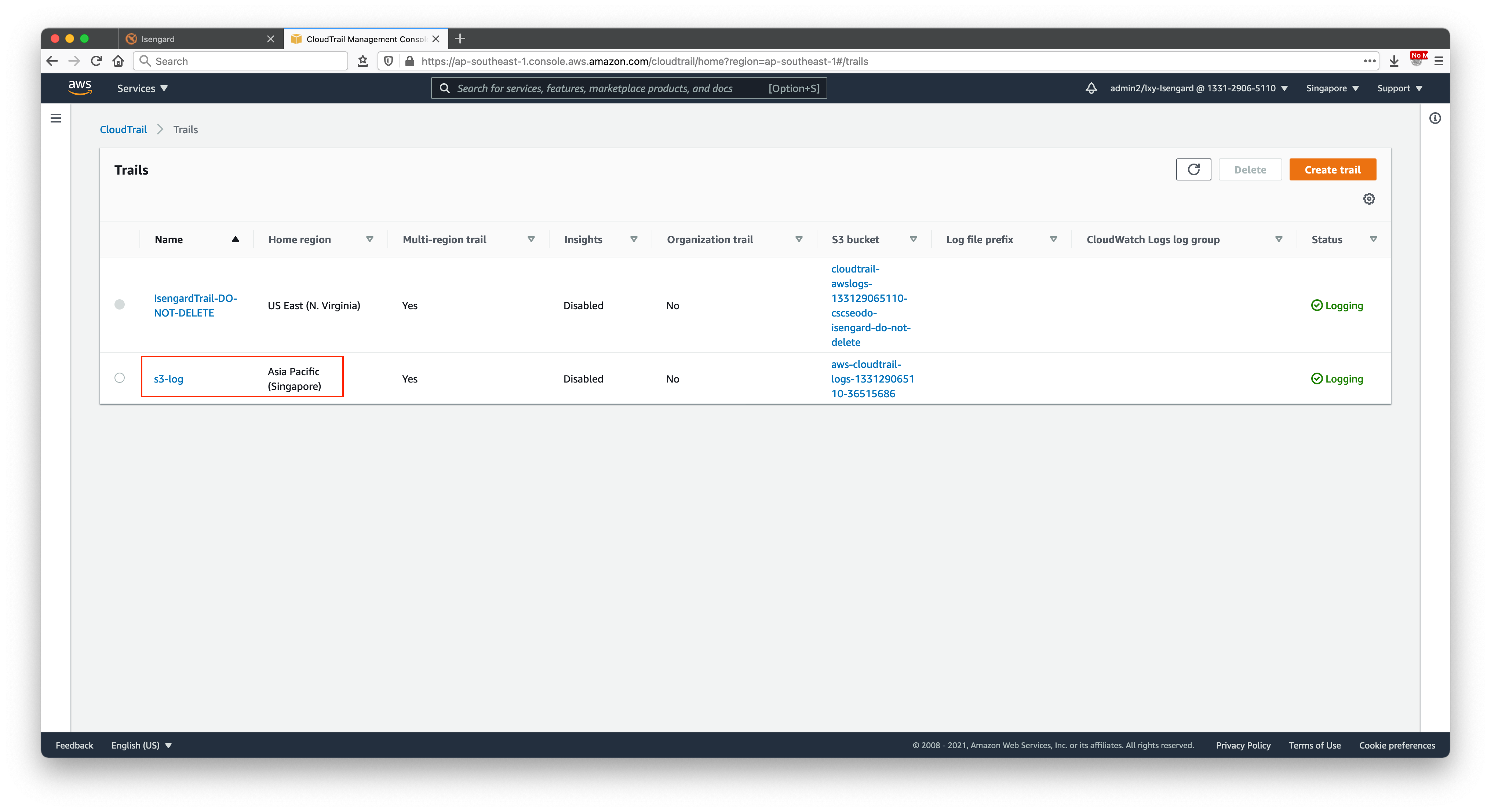
创建完毕,可以看到CloudTrail下多了一条记录。如下截图。
三、生成Athena表格并通过SQL查询日志
1、获取建表语句
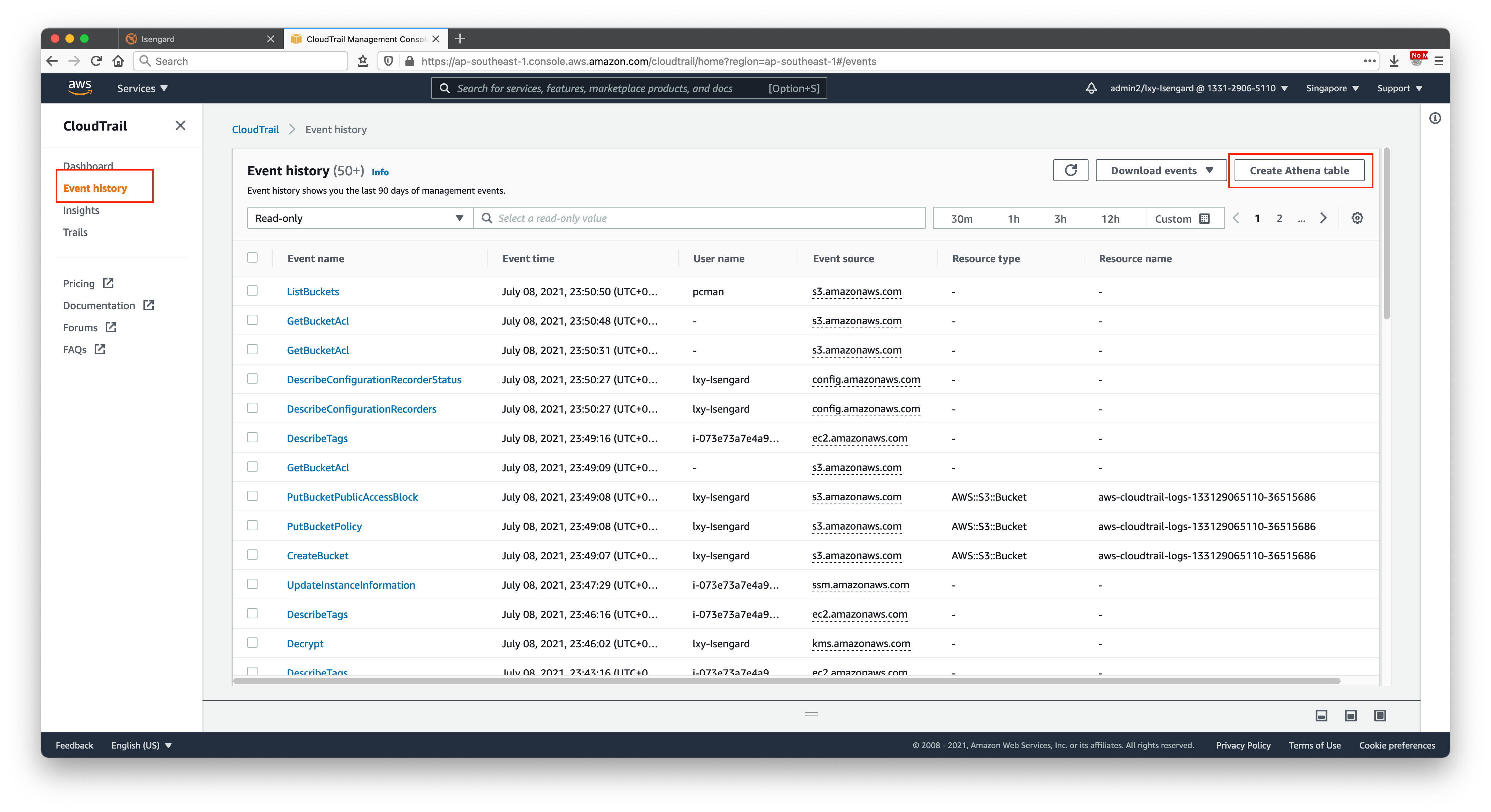
点击CloudTrail左侧的菜单折叠栏,展开菜单,点击第二项Event History,从中已经可以看到对S3的操作日志了。点击创建。
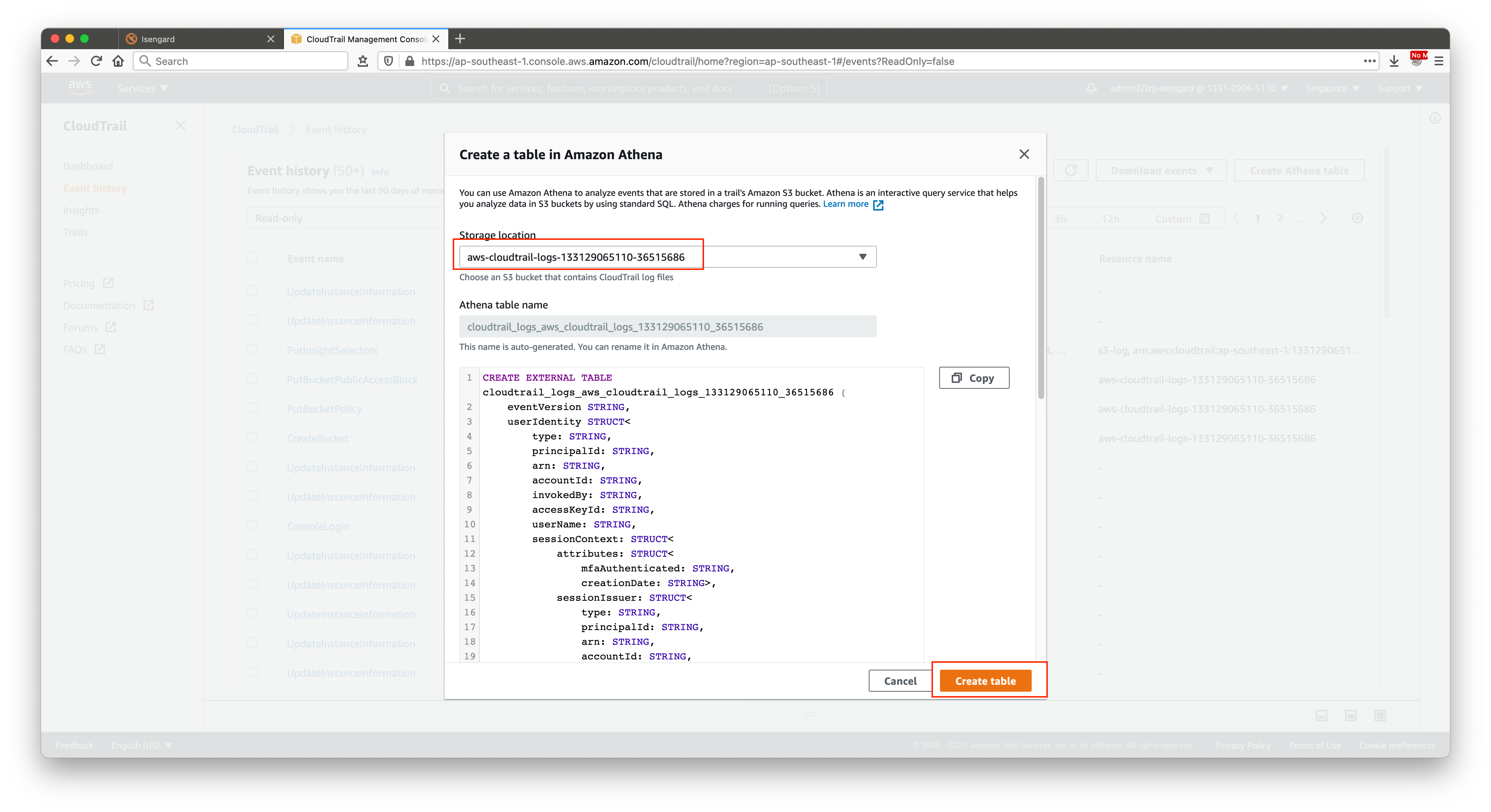
注意这里需要切换下CloudTrail的选项。系统默认可能有不只一条CloudTrail。这里注意挑选上一步配置CloudTrail的名字。同时确认所在的S3存储桶,这里如果点击创建按钮,就会自动创建Athena表。此时再点击下复制按钮,把创建表的语句复制下来。如下截图。
建表语句如下:
CREATE EXTERNAL TABLE cloudtrail_logs_aws_cloudtrail_logs_133129065110_36515686 (
eventVersion STRING,
userIdentity STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
invokedBy: STRING,
accessKeyId: STRING,
userName: STRING,
sessionContext: STRUCT<
attributes: STRUCT<
mfaAuthenticated: STRING,
creationDate: STRING>,
sessionIssuer: STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
username: STRING>,
ec2RoleDelivery: STRING,
webIdFederationData: MAP<STRING,STRING>>>,
eventTime STRING,
eventSource STRING,
eventName STRING,
awsRegion STRING,
sourceIpAddress STRING,
userAgent STRING,
errorCode STRING,
errorMessage STRING,
requestParameters STRING,
responseElements STRING,
additionalEventData STRING,
requestId STRING,
eventId STRING,
resources ARRAY<STRUCT<
arn: STRING,
accountId: STRING,
type: STRING>>,
eventType STRING,
apiVersion STRING,
readOnly STRING,
recipientAccountId STRING,
serviceEventDetails STRING,
sharedEventID STRING,
vpcEndpointId STRING,
tlsDetails STRUCT<
tlsVersion: STRING,
cipherSuite: STRING,
clientProvidedHostHeader: STRING>
)
COMMENT 'CloudTrail table for aws-cloudtrail-logs-133129065110-36515686 bucket'
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://aws-cloudtrail-logs-133129065110-36515686/AWSLogs/133129065110/CloudTrail/'
TBLPROPERTIES ('classification'='cloudtrail');
如果此时Athena提示无法创建表缺少权限,那么一般是由于本账户的Lake Formation对数据管理权限不足造成的,Lake Formation需要指定数据管理员的身份(IAM Role或IAM User)。制定完成后,Athena即可创建完毕。
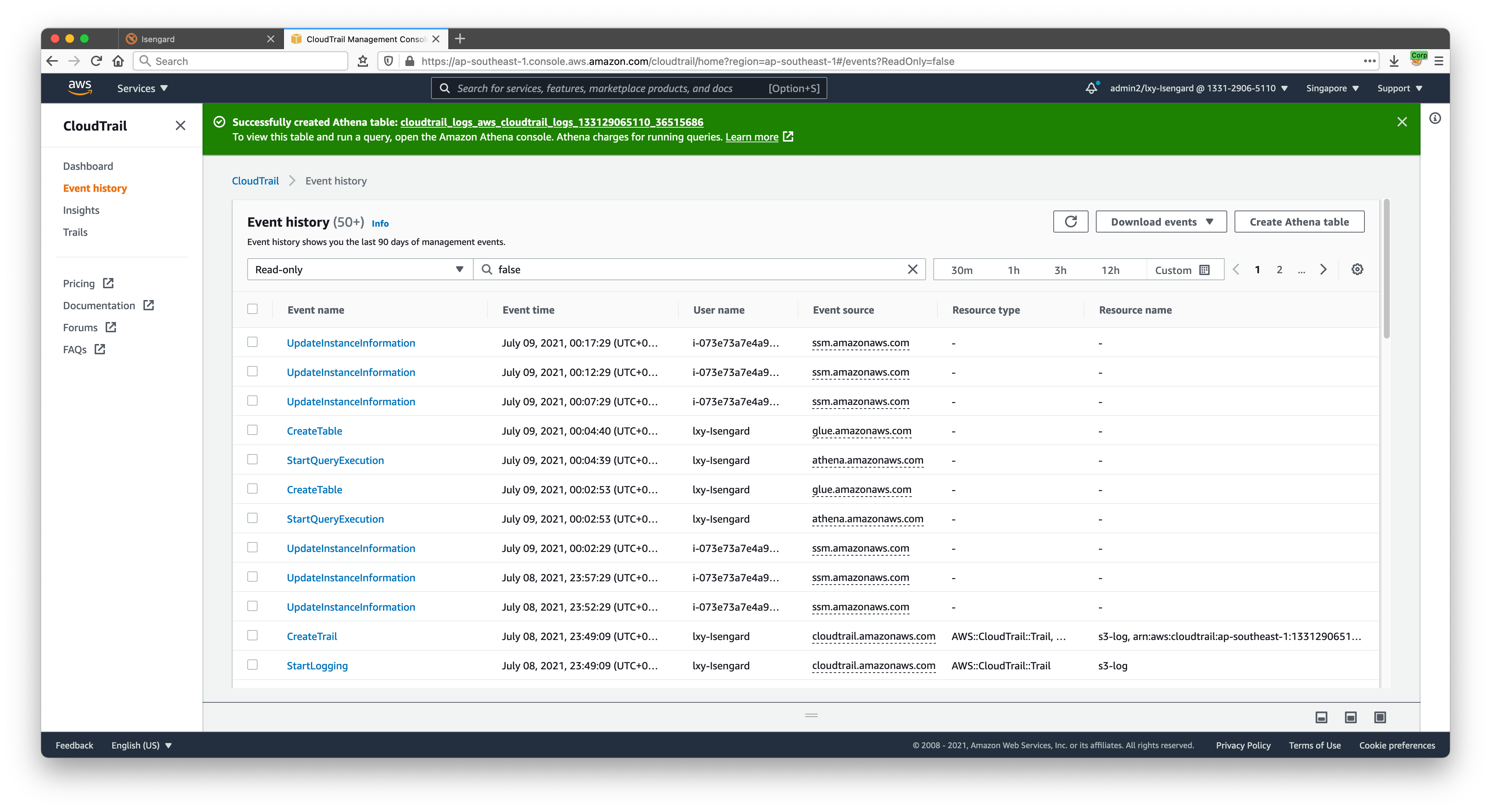
创建完毕后页面上方提示绿色的Athena创建完毕,获得名为cloudtrail_logs_aws_cloudtrail_logs_133129065110_36515686的Athena表一张。如下截图。
2、使用Athena查询日志
请注意:如果您的CloudTrail已经运行了很长时间,有数个GB的数据,请跳过本章节,那么查询会带来大量的Athena扫描数据成本。建议直接到下一个条件,使用带有分区键优化方式的Athena查询。
进入Athena服务,运行查询程序。
如果之前没有进入过Athena服务,那么第一次运行Athena时候,会提示需要设置一个Athena Outout bucket for querying result。此时,需要点击右上角的Setting进入设置,然后选择一个存储桶,保存Athena查询结果。如下截图。
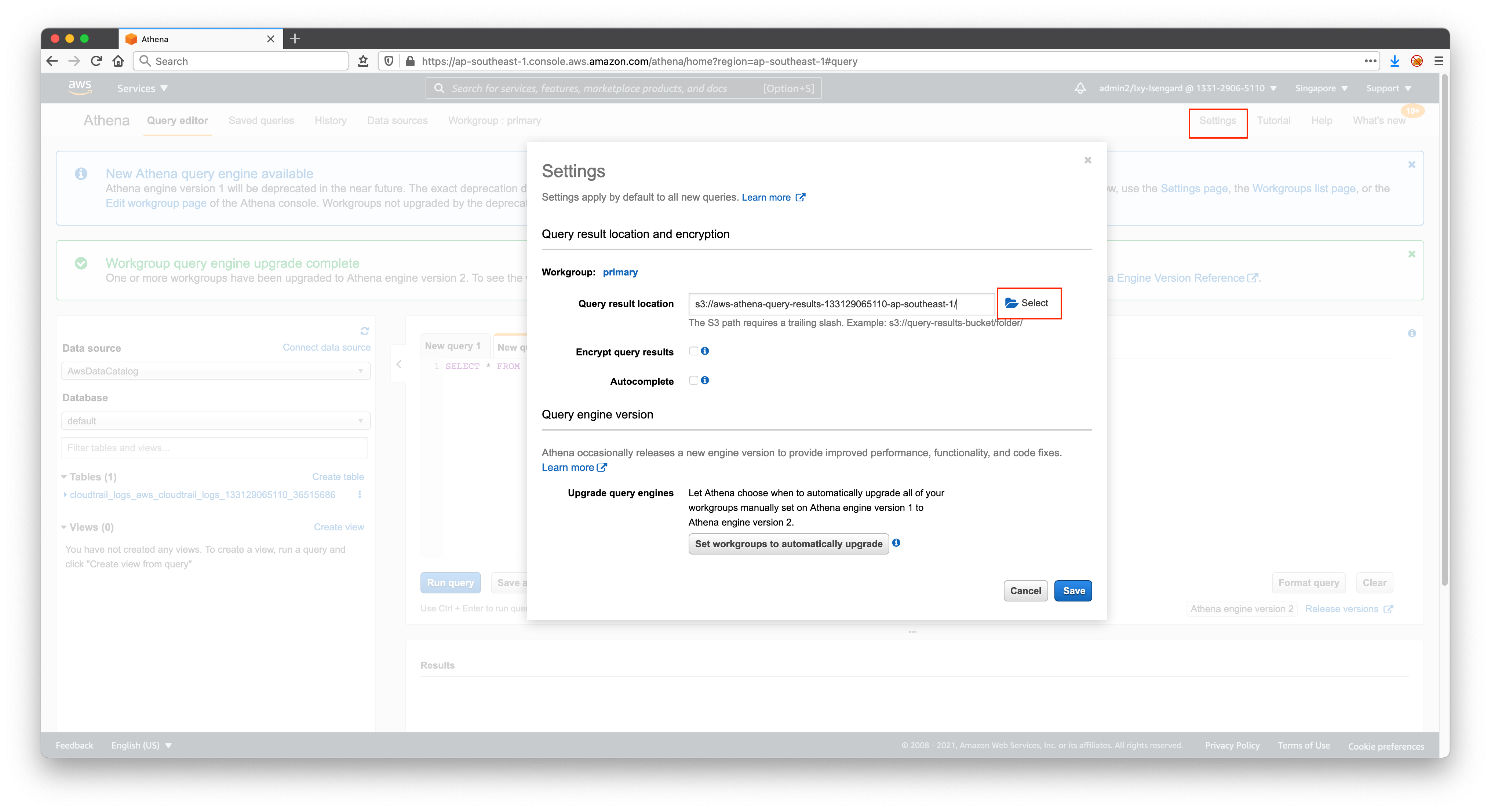
注意:Athena查询结果和Source不能放在同一个桶里,被查询的CloudTrail日志和Athena查询结果需要在不同的目录。
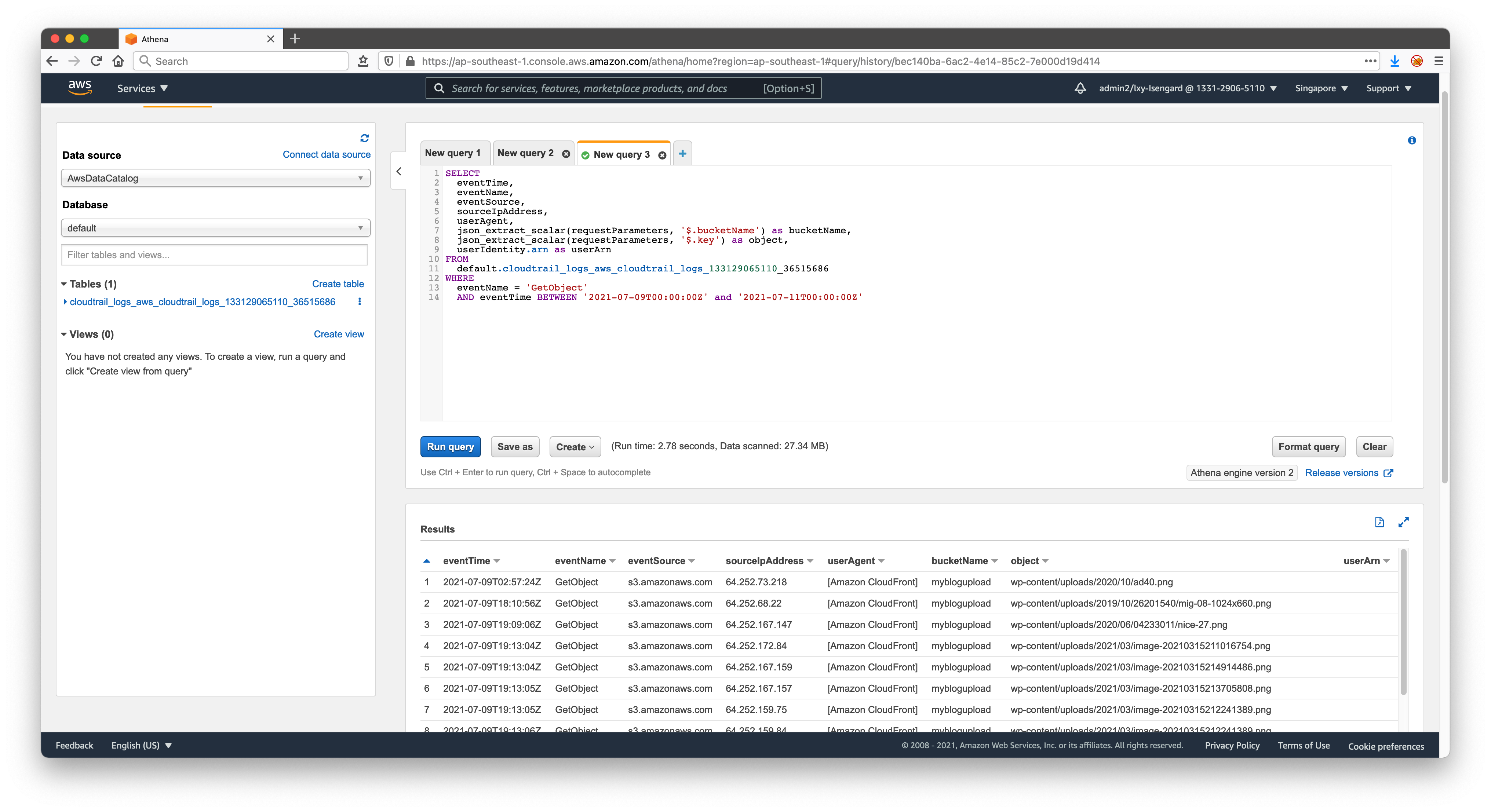
执行如下一段查询。请酌情替换from字段中的default数据库名和表名cloudtrail_logs_aws_cloudtrail_logs_133129065110_36515686,不同账号下生成的存储桶名称不一样。如果需要查询上传时间,请修改GetObject为PutObject
SELECT
eventTime,
eventName,
eventSource,
sourceIpAddress,
userAgent,
json_extract_scalar(requestParameters, '$.bucketName') as bucketName,
json_extract_scalar(requestParameters, '$.key') as object,
userIdentity.arn as userArn
FROM
default.cloudtrail_logs_aws_cloudtrail_logs_133129065110_36515686
WHERE
eventName = 'GetObject'
AND eventTime BETWEEN '2021-07-09T00:00:00Z' and '2021-07-11T00:00:00Z'
由此可以看到查询结果。如下截图。
至此配置完成。
以下章节为2023年8月新增,通过带有分区键的建表,优化查询成本。
四、重新建表指定分区键优化查询
1、为何要增加分区键
上一步介绍的是用CloudTrail默认建表语句创建的表。这里有个问题是默认的建表语句没有预留分区键,那么以后数据量大了,查询负担会很重。例如CloudTrail开启了一年积累数个GB的数据,没有分区键时候做一个普通查询,都会触发全表扫描扫描这几个GB的数据,这样的话Athena会产生不必要的查询费用,且查询速度非常慢。由此我们建议创建分区键。
重新建表不需要删除之前默认Athena语句创建的表,只需要换一个名字即可。Athena表本身没有费用Cost。产生费用的是储存在S3存储桶的CloudTrail日志占用的S3存储容量和S3请求次数本身,Athena不查询不收费。
2、建表语句
重新整理建表语句,新的表命名为newcloudtraillog,在代码中加入分区键。这里采用了region、year、month、date几个分区键,分别用于筛选如region和时间。因为日志存储的目录是分region的,所以分区键设置region是很有帮助的,不同region之间的查询一般是独立的。此外,根据数据量和查询需要,也可以调整分区键为月份。
CREATE EXTERNAL TABLE newcloudtraillog (
eventVersion STRING,
userIdentity STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
invokedBy: STRING,
accessKeyId: STRING,
userName: STRING,
sessionContext: STRUCT<
attributes: STRUCT<
mfaAuthenticated: STRING,
creationDate: STRING>,
sessionIssuer: STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
username: STRING>,
ec2RoleDelivery: STRING,
webIdFederationData: MAP<STRING,STRING>>>,
eventTime STRING,
eventSource STRING,
eventName STRING,
awsRegion STRING,
sourceIpAddress STRING,
userAgent STRING,
errorCode STRING,
errorMessage STRING,
requestParameters STRING,
responseElements STRING,
additionalEventData STRING,
requestId STRING,
eventId STRING,
resources ARRAY<STRUCT<
arn: STRING,
accountId: STRING,
type: STRING>>,
eventType STRING,
apiVersion STRING,
readOnly STRING,
recipientAccountId STRING,
serviceEventDetails STRING,
sharedEventID STRING,
vpcEndpointId STRING,
tlsDetails STRUCT<
tlsVersion: STRING,
cipherSuite: STRING,
clientProvidedHostHeader: STRING>
)
PARTITIONED BY (
`region` char(20),
`year` int,
`month` int,
`date` int
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://aws-cloudtrail-logs-133129065110-36515686/AWSLogs/133129065110/CloudTrail/'
TBLPROPERTIES ('classification'='cloudtrail');
3、加载分区
执行如下命令加载分区,这里指定区域和月份。
ALTER TABLE newcloudtraillog
ADD PARTITION (region = 'ap-southeast-1', year = 2023, month = 08, date = 24)
LOCATION 's3://aws-cloudtrail-logs-133129065110-36515686/AWSLogs/133129065110/CloudTrail/ap-southeast-1/2023/08/24';
执行如下确认分区添加成功。
show partitions newcloudtraillog;
返回结果如下表示创建分区成功。
region=ap-southeast-1/year=2023/month=08/date=24
4、运行查询
执行如下命令其中包含了分区键,相对上一个查询,调整了查询字段便于排错。
SELECT
eventTime,
eventName,
json_extract_scalar(requestParameters, '$.bucketName') as bucketName,
json_extract_scalar(requestParameters, '$.key') as object,
sourceIpAddress,
vpcendpointid as vpcEndpoint,
userIdentity.accesskeyid as accesskey,
userIdentity.arn as userArn,
userAgent,
eventSource
FROM
newcloudtraillog
WHERE
region = 'ap-southeast-1'
AND year = 2023
AND month = 08
AND date = 24
AND eventName = 'GetObject'
AND json_extract_scalar(requestParameters, '$.bucketName') = 's3idc'
LIMIT 10;
查询返回结果如下截图。
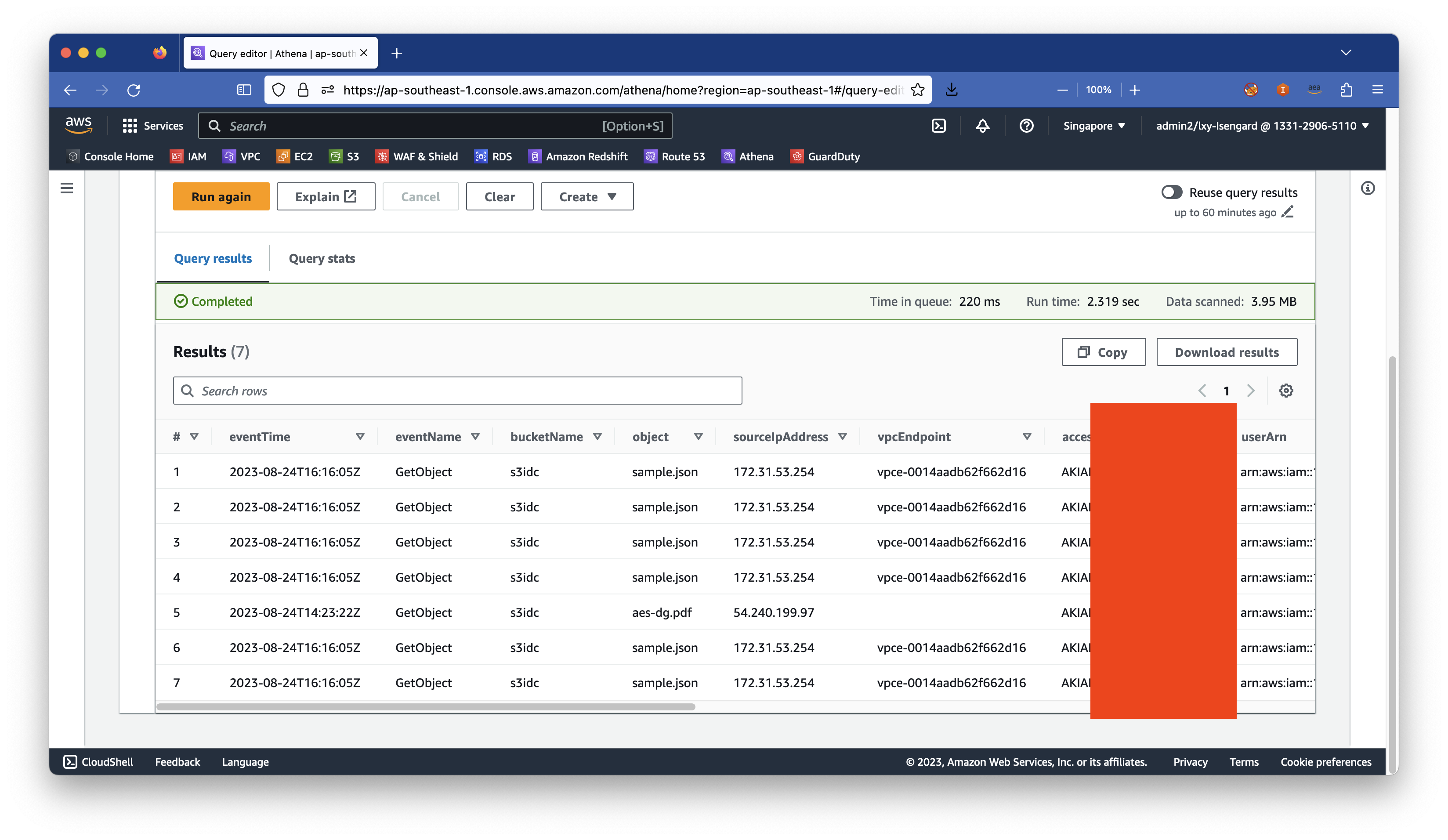
由此可以看到,本Athena查询扫描的数据量相对上一个实验就很少了,因此较低的成本更便于做分析。
五、参考文档
参考文档:
最后修改于 2021-07-12