使用Ollama在MacOS本机和AWS EC2 G系列机型上运行DeepSeek R1蒸馏模型
详细介绍如何使用Ollama框架在MacOS和AWS EC2上部署DeepSeek R1蒸馏模型,解决本地大模型部署复杂性,提供完整的安装、配置和API调用方案。
一、背景
1、什么是Ollama
Ollama是一个在本地运行大语言模型(LLM)的开源框架,提供了针对Windows、Linux、MacOS预先封装好的一系列模型,可一键方式在开发者本地(例如笔记本)运行大模型,大大简化了体验和开发的过程。Ollma将不同模型封装到自定义的容器架构内,并针对不同硬件架构做好了适配,可在包括Apple M1处理器在内的多种机型上运行。
2、关于Deekseek R1
DeepSeek是位于杭州的一家初创公司,其团队具有量化行业背景。DeepSeek据称拥有1万张A100级别的算力,并在2024年5月发布DeepSeek V2模型,2024年12月发布V3模型。DeepSeek模型是开源模型,通过Github这里可以获取。DeepSeek目前使用MIT协议,可免费用于商用。DeepSeek官方对V3版本的描述是:“DeepSeek-V3 为自研 MoE 模型,671B 参数,激活 37B,在 14.8T token 上进行了预训练。DeepSeek-V3 多项评测成绩超越了 Qwen2.5-72B 和 Llama-3.1-405B 等其他开源模型,并在性能上和世界顶尖的闭源模型 GPT-4o 以及 Claude-3.5-Sonnet 不分伯仲”。DeepSeek V3的论文在Github的这里。
由V3演进而来的是R1模型。DeepSeek官方的对R1版本的描述是:“DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版”。R1版本的论文在Github的这里。DeekSeek R1版本是660B参数的模型,同时官方通过 DeepSeek-R1 的输出,基于阿里千问Qwen和Meta(Facebook)的Llama蒸馏出了6个小模型,官方的评测显式基于Llama蒸馏的32B和70B模型在多项能力上实现了对标OpenAI o1-mini的效果。R1模型和所有蒸馏的模型也都遵循MIT协议,可免费用于商用。
通过Ollama部署DeepSeek支持纯CPU运行,也支持CPU和GPU混合运行(显存被加载到内存),但最高效率的还是在纯GPU和显存运行。当以纯CPU方式运行时,模型推理速度十分有限,可能仅有几个Token每秒,即便是单个对话任务也非常卡顿,这个性能不具备实际使用效果。因此建议使用纯GPU来运行,针对使用的GPU的显存大小来下载对应模型版本。
虽然DeepSeek的模型使用MIT协议可以自行部署,但部署R1模型需要数百GB显存,一般用户不具备条件部署完整版,此时可根据需要选择蒸馏版本。本文将演示最低成本的1.5b模型的部署。
二、在MacOS本机上运行1.5b模型
本文以使用M1处理器的MacBook Pro 13英寸机型为例,配备4个性能核心+4个效率核心(4P+4E)共计8个内核的CPU,以及8核心GPU,搭配16GB统一内存。
1、安装Ollama
从Ollama官网 https://ollama.com/ 下载对应的操作系统Windows、Linux或MacOS的安装包。
下载时候是ZIP格式,解压缩后是应用程序,双击运行。MacOS上会提示是否将这个程序移动到Application应用程序文件夹,这里点击确认。如下截图。
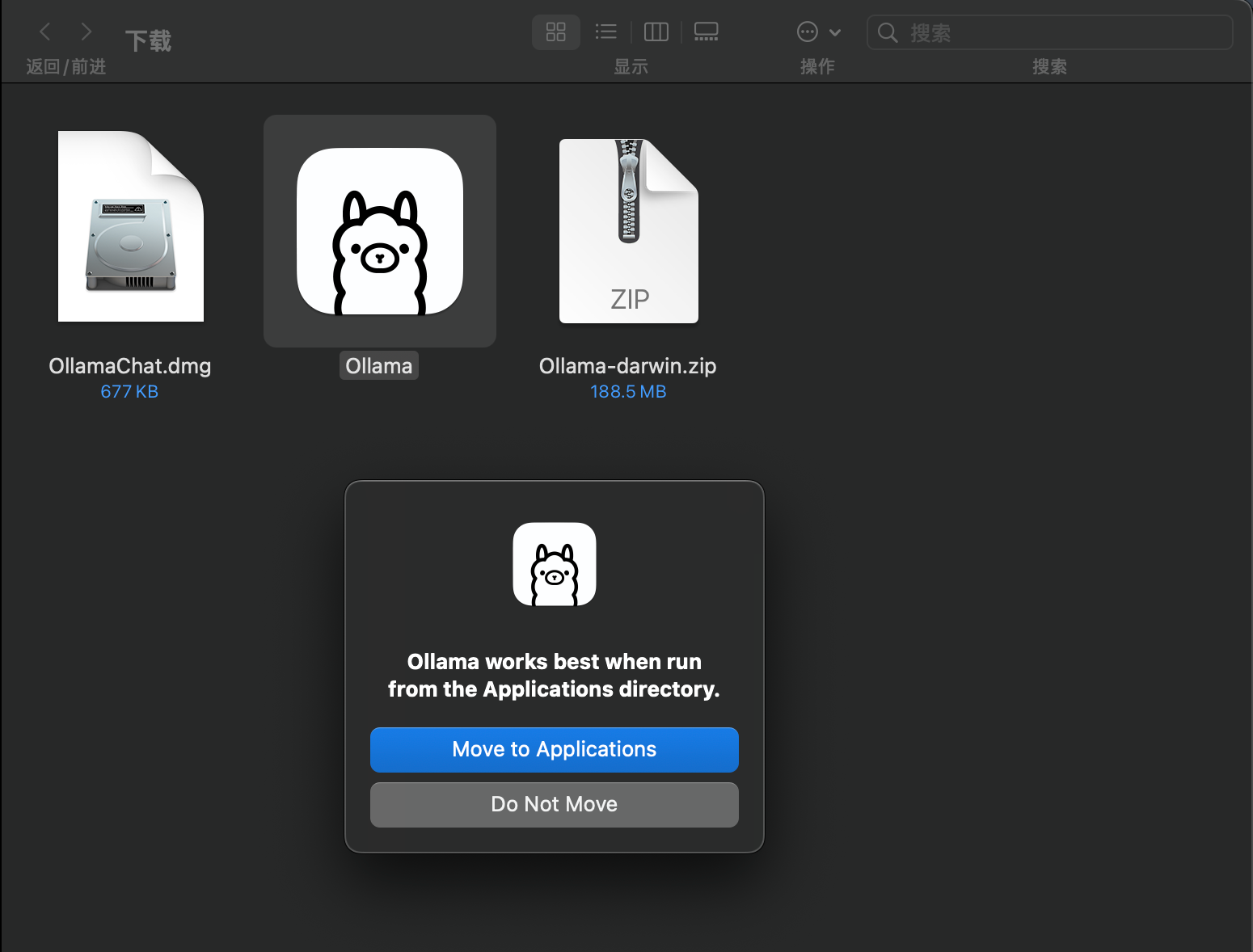
第一次运行Ollama,会提示是否要安装,点击确认。
在安装命令行位置点击安装即可。如下截图。

2、下载并启动DeepSeek R1
从Ollama官网这里的模型清单中,查找要在本地部署的模型。这里找到DeepSeek R1模型的蒸馏后的1.5b模型,可以看到在model介绍部分也显示其架构师基于Qwen2模型蒸馏而来。点击复制按钮,将部署命令复制下来。如下截图。
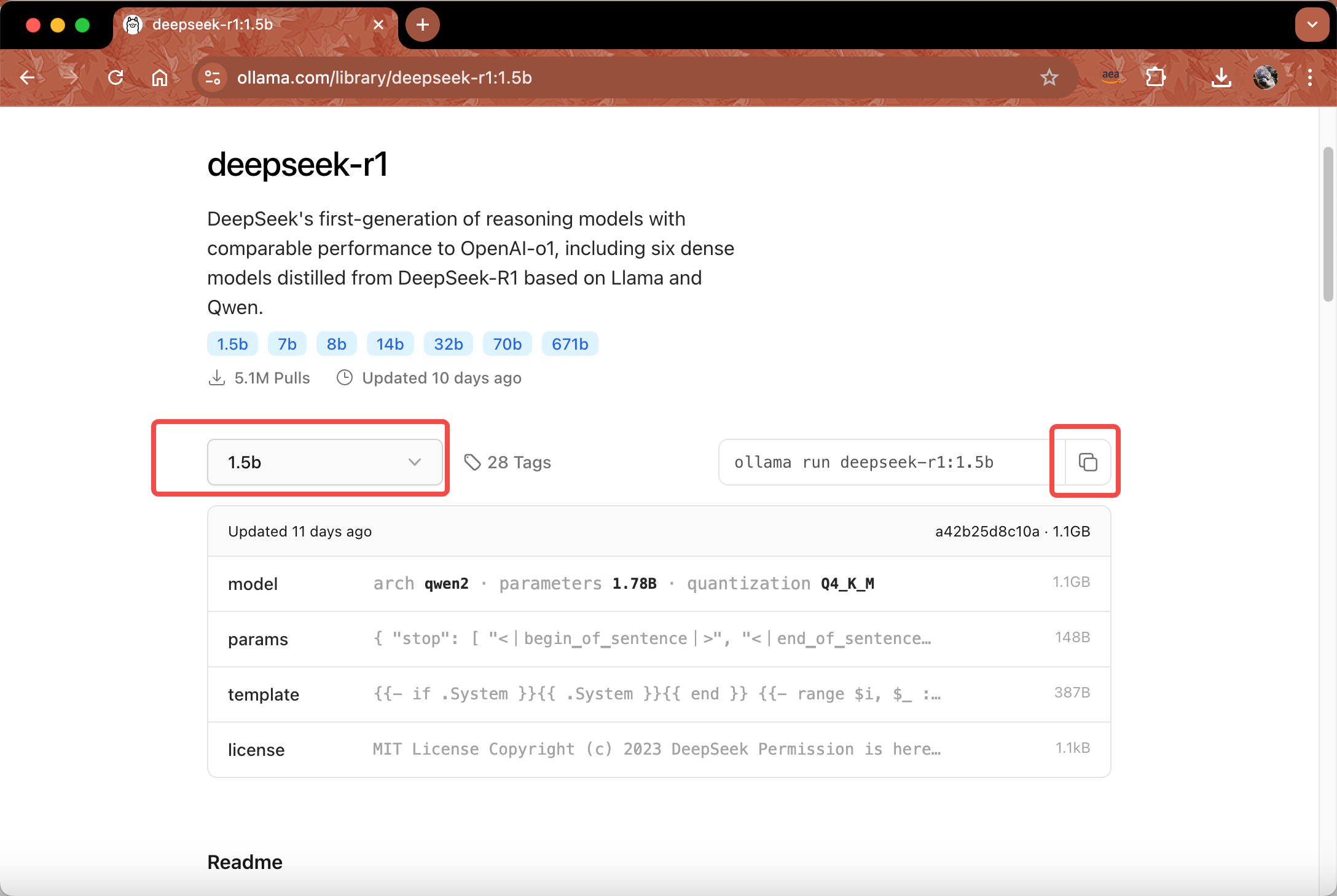
打开本机的终端,运行上一步复制下来的命令:
ollama run DeepSeek-r1:1.5b
现在可以看到ollama的命令行程序正在下载对应模型。根据网速不同,可能需要几分钟。如下截图。
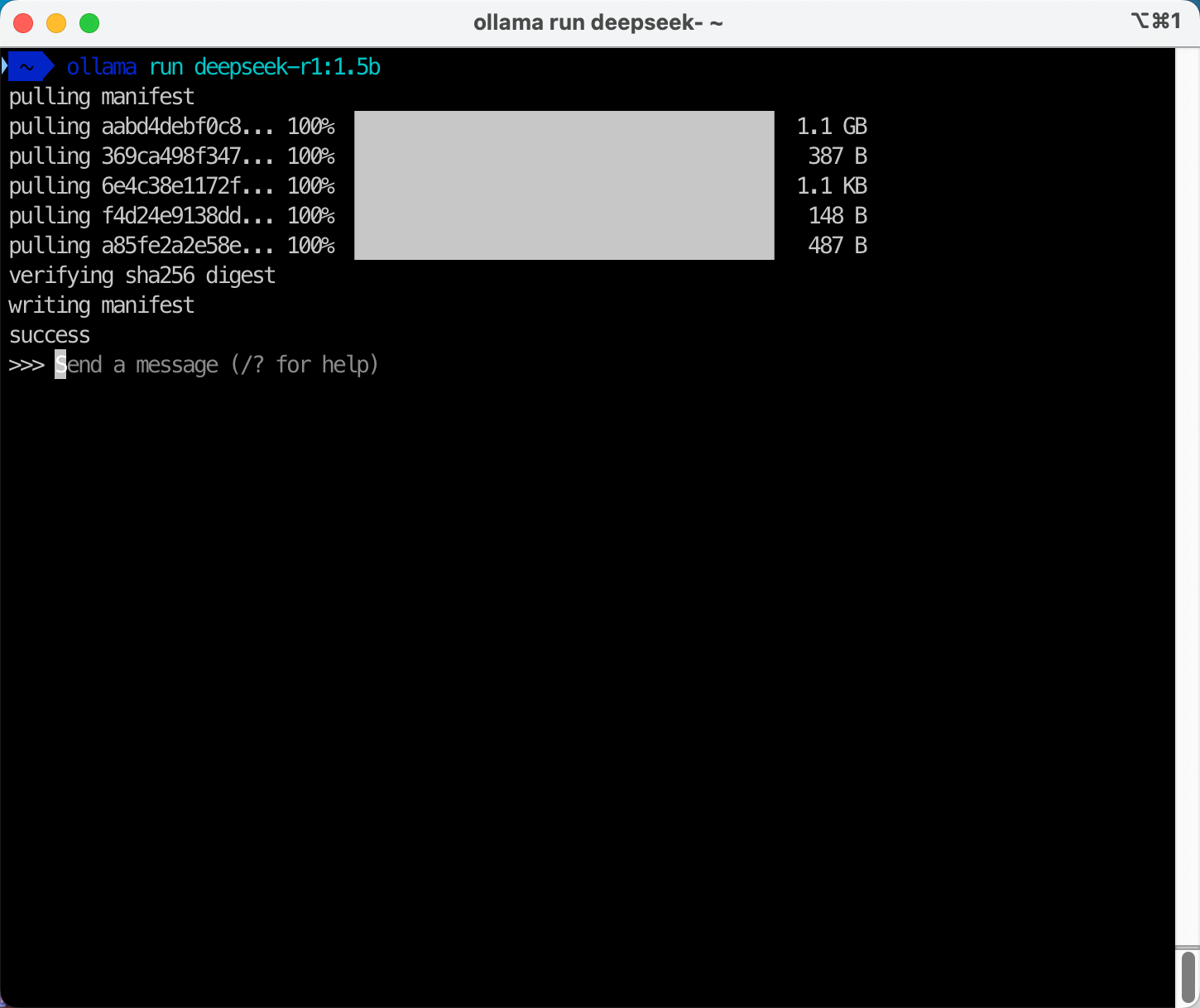
部署完毕后,出现Send a message (/? for help)提示符。已经就绪可直接输入Prompt提示词。如下截图。
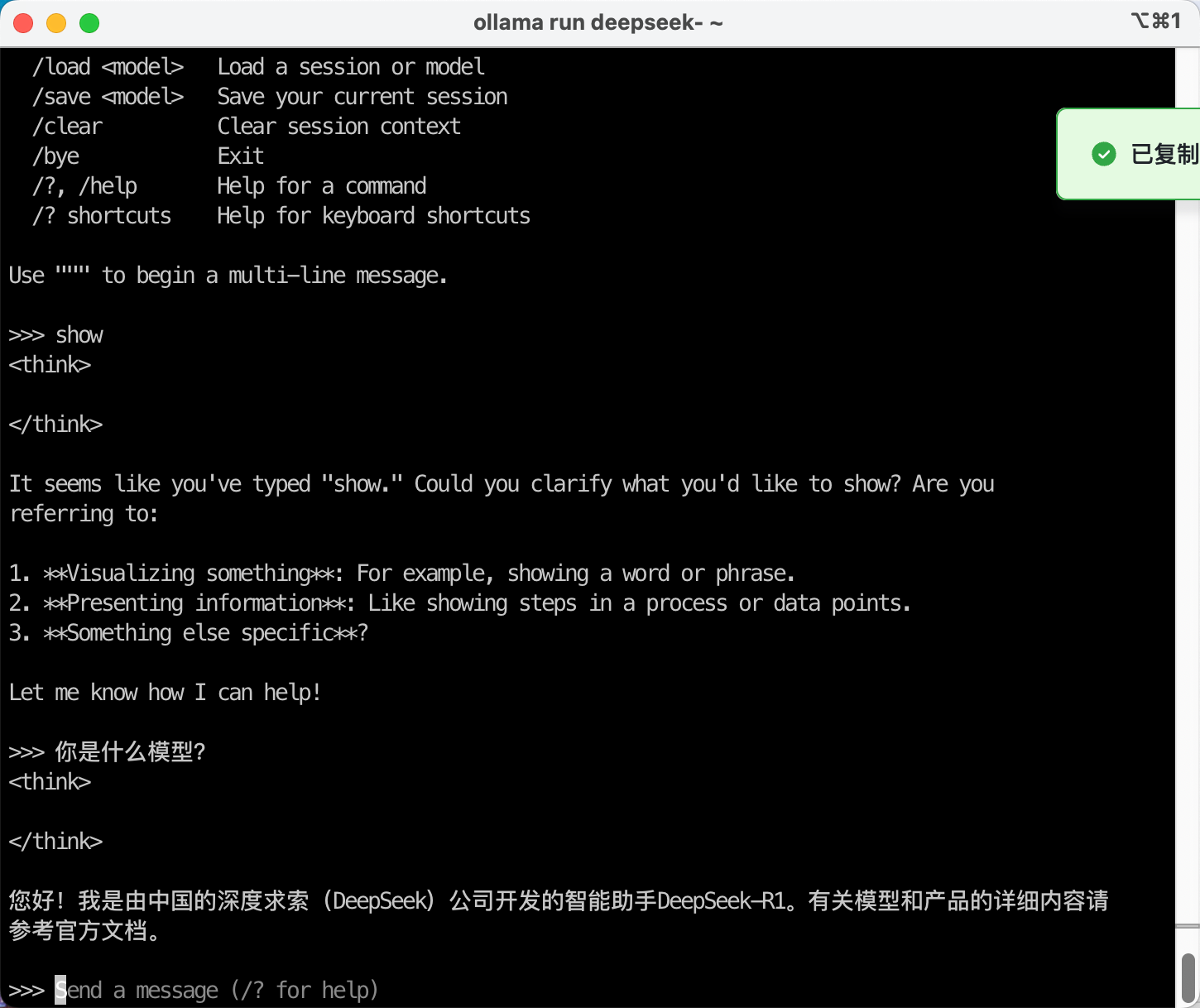
由此可看到在MacOS本机运行模型正常。
3、使用CURL通过API交互
注意,Ollama默认只监听本机地址,即127.0.0.1的本地地址,因此除本计算机之外的本地局域网的其他计算机是不能访问的。如果希望开放本地局域网访问,可以修改Ollama的配置文件,使其监听在0.0.0.0本机所有地址即可。此外还需要注意,默认的Ollama服务端口是没有身份认证的,如果要开放给本机127.0.0.1之外的地址,还需要注意访问安全。
本文的例子是针对本地请求的例子。
curl http://localhost:11434/api/generate -d '{"model": "deepseek-r1:1.5b", "prompt": "你是什么模型"}'
即可看到返回结果。注意,返回内容是Stream流式的,因此CURL会给出多条返回记录,每个记录一个文字或者一个单词。
4、使用本机C/S架构聊天客户端
Ollama有很多的开源客户端,这里选择名为OllamaChat的客户端。这个客户端也是开源的,可以从Github的这里获取。这里以MacOS版本为例。
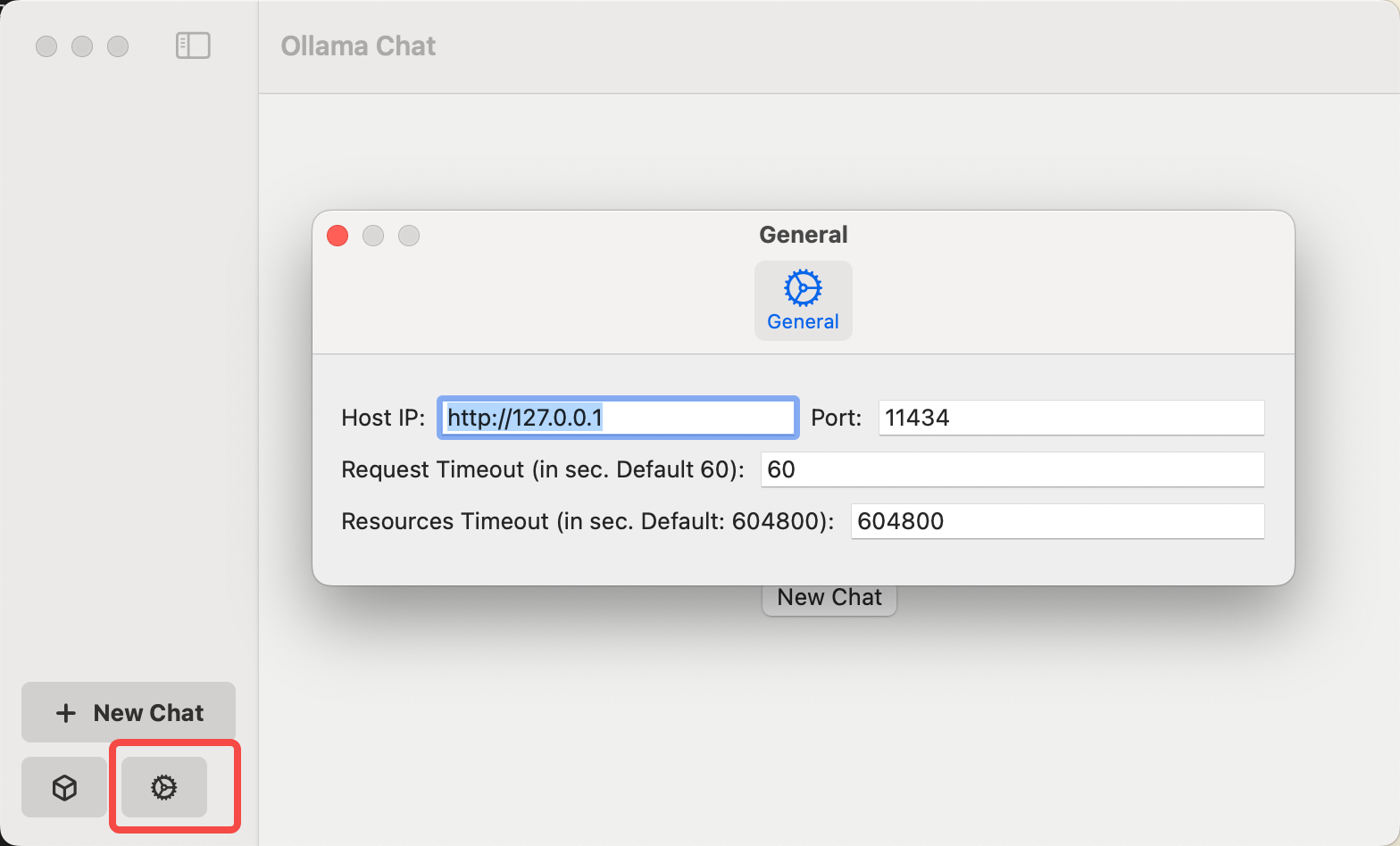
下载到本地后,解压缩即可直接运行。在主界面左下角的齿轮符号是进入配置界面。配置界面中可看到调用的API。默认的API端口不用修改,可直接使用。如下截图。
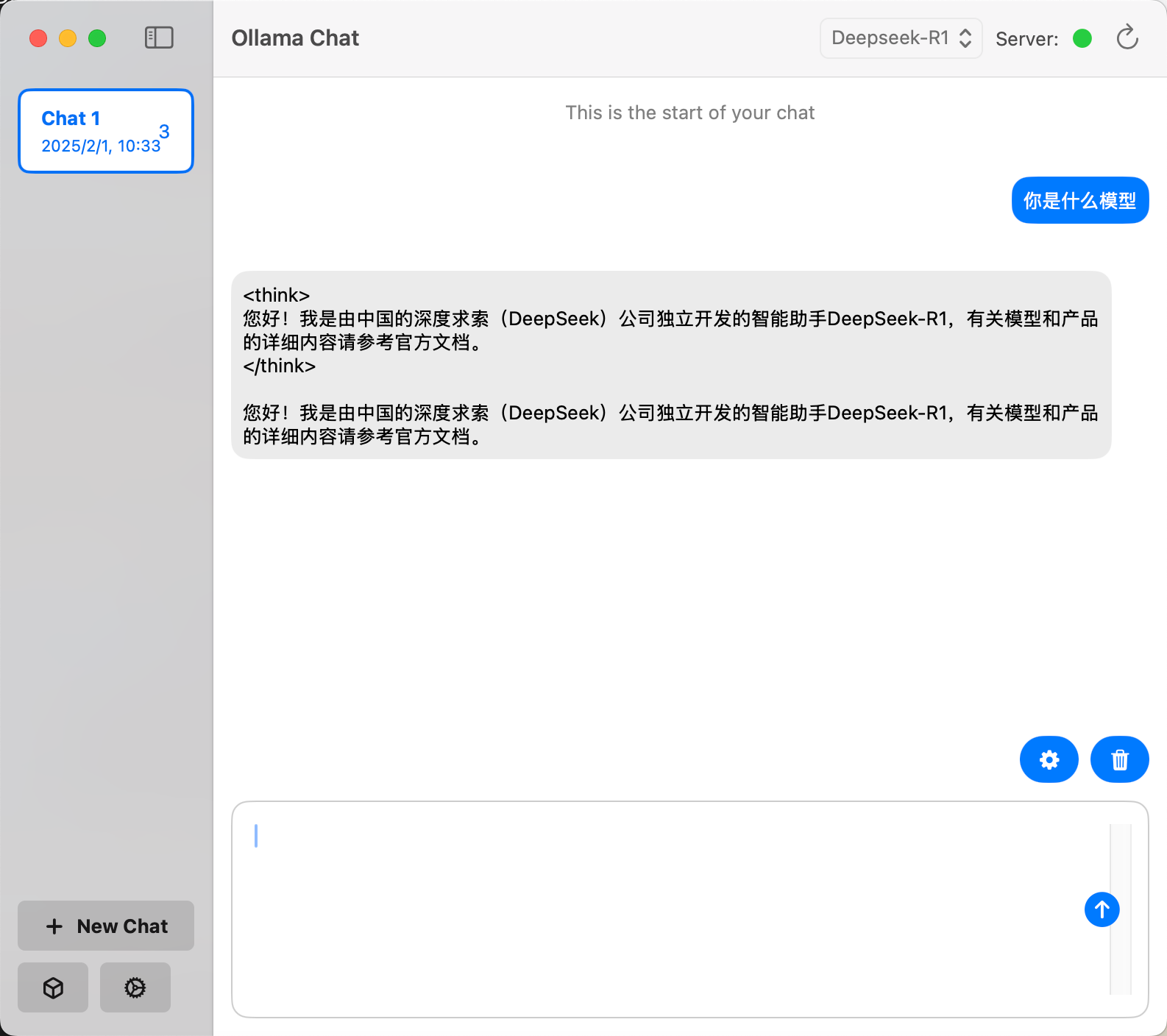
输入提示词可看到运行正常。如下截图。
5、启动和停止服务
由于推理容器一直会占用本机资源,因此在需要使用的时候,需要手工停止。如果当前还在Ollama的Shell下,可以按CTRL+C键,返回到命令行。如果不结束命令行,那么再次输入提示词时候,Ollama又会自动启动。
执行ollama ps命令查看正在运行的模型。返回结果如下:
NAME ID SIZE PROCESSOR UNTIL
deepseek-r1:1.5b a42b25d8c10a 2.1 GB 100% GPU 4 minutes from now
找到正在运行的模型ID,运行如下命令停止它。
ollama stop deepseek-r1:1.5b
如果要再次运行之前停止的模型,可首先执行ollama list命令查询本地可用的模型镜像。返回结果如下:
NAME ID SIZE MODIFIED
deepseek-r1:1.5b a42b25d8c10a 1.1 GB 4 days ago
可以看到本机有之前下载过的镜像,复制下来ID,然后执行如下命令启动:
ollama run deepseek-r1:1.5b
启动完成,出现Send a message (/? for help)提示符即可开始交互。
三、在云端GPU机型运行32b模型
刚才在MacOS本机部署的是R1蒸馏后的Qwen-1.5b模型,选择这个模型是考虑到Mac本地的运算能力和Mac的内存大小(Apple M1的内存叫统一内存,也是显存),因而选择1.5b模型。
如果在云端,可使用较大显存的机型,运行参数更大的模型。本文使用蒸馏后Qwen-32B模型,机型选择A10单卡有24GB显存的机型做推理,在AWS云上对应型号为G5/G6等机型。实际启动后占用约23GB显存,因此可以说是勉强能启动,如果是生产环境使用,建议更换为单卡48GB显存的EC2 G6e机型。
对应70b的从llama蒸馏而来的模型,可以选择使用Nvidia L40s显卡且单卡配备48GB显存的G6e机型。注意EC2 G6和G6e机型是不同的显卡,显存差一倍。
1、创建EC2
创建一台g5.2xlarge机型,其配置是8vCPU/32GB,一个A10 GPU/24GB显存。操作系统选择Ubuntu Server 24.04 LTS版本。
由于要从Ollama官方镜像下载模型,因此需要确保本机的EBS磁盘足够大(建议选100GB的gp3),并且确保本机能够访问互联网(可为本VPC增加NAT gateway)。
创建完毕。
2、安装Ollama并启动服务
执行如下命令安装ollama。
curl -fsSL https://ollama.com/install.sh | sh
这里拉取DeepSeek R1蒸馏后参数32B的Qwen-32b模型。
ollama run deepseek-r1:32b
等待一段时间后(注意保持网络不要中断),即可看到模型部署完毕。Ollama的shell控制台可以直接按CTRL+D键退出,不会影响后台模型的运行。
为了确认机型正确且模型被完全加载到显存中,可执行ollama ps命令。如果下方显示100% GPU则表示显存足够。如果显示50% CPU 50% GPU则表示显存不够,一部分模型只能通过系统内存加载,建议更换更大的机型。
deepseek-r1:70b 0c1615a8ca32 46 GB 100% GPU 4 minutes from now
3、在本EC2上使用Python代码流式对话(Stream)
在本EC2上安装依存性包。
sudo -i
apt install pipx
pipx install ollama --include-deps
pipx ensurepath
export PYTHONPATH=$PYTHONPATH:/root/.local/share/pipx/venvs/ollama/lib/python3.12/site-packages
在本EC2上编写如下代码,并保存为chat.py。
from ollama import chat
messages = [
{
'role': 'user',
'content': '你是什么模型?',
},
]
for part in chat('deepseek-r1:32b', messages=messages, stream=True):
print(part['message']['content'], end='', flush=True)
print()
需要注意以上代码的模型ID必须与执行ollma ps显示正在运行的模型的ID一致。运行这个脚本python3 chat.py测试,即可看到正常运行。
四、参考资料
Ollama支持的GPU型号
https://github.com/ollama/ollama/blob/main/docs/gpu.md
查询模型
https://ollama.com/library/DeepSeek-r1:1.5b
Ollama MacOS GUI
https://github.com/rijieli/OllamaChat
Ollama python example
https://github.com/ollama/ollama-python/blob/main/README.md
最后修改于 2025-02-01