使用SCT+DMS迁移MySQL
详解如何使用AWS SCT和DMS工具将自有MySQL迁移到RDS,解决自增属性、索引、二进制数据等迁移难题,实现全量+增量数据同步。
一、背景
本文介绍如何使用SCT+DMS将客户自有MySQL迁移到AWS RDS MySQL。
1、SCT+DMS简介
AWS有两个迁移工具,一个是基于C/S软件客户端架构的SCT,一个是基于WEB界面的DMS向导。在最佳实践中,SCT通常用于转换数据库架构,例如从Oracle转MySQL,从SQL Server转PostgreSQL等。DMS用于复制数据。
在本例中,源库和目标库,都是MySQL数据库。由于DMS存在一定局限性,以迁移数据为主,但是一些数据库结构不会被完全迁移,因此导致大量额外手工的工作量。本文描述了先使用SCT创建数据库schema,然后用DMS迁移数据的过程。
2、DMS的局限和SCT的必要性
SCT与DMS的配合如下。
- 主键自增属性不会被DMS迁移,需要逐个表对有自增ID的手工增补;而使用SCT则可以自动生成一个没有数据的Schema,是可以迁移自增属性到目标库的,然后再通过DMS导入数据;
- DMS只迁移主键的索引;其他列的索引将不会被DMS识别和复制;使用SCT可以完成迁移所有索引。
由此可以看出,将SCT和DMS配合使用,可以最小化工作量。
3、其他限制
此外,还有一定局限性是SCT也不能辅助解决的,主要的包括如下:
- 源库可以有MyISAM引擎的库,但迁移后目标库的引擎都是自动是InnoDB;
- Drop/rename table不会被DMS的CDC持续复制所迁移;
- 不能用Aurora MySQL的只读节点当作源库;
- ALTER TABLE时候将列插入特定位置不支持,复制之后永远插在最后一列;
- 当全量迁移进行中,如果把源库直接关机,那么DMS复制任务不会提示出错而是提示复制完成,最新数据就截止到停机的一刻。解决办法:重新启动整个迁移任务,或者对受影响的表格做reload data操作;
- 二进制数据LOB迁移默认只limit到32KB,因此如果源库有二进制内容,需要选择Full LOB模式,完全迁移二进制内容,且调整二进制复制时候分片大小,默认是64KB。
二、使用SCT迁移数据库schema
1、使用SCT生成评估报告
下载并安装SCT。下载地址点击这里 SCT for Windows 。下载JDBC 库文件,MySQL数据的在这里,点这里Oracle 11g和12c版本。
在一个可以同时访问源数据库和目标数据库的Windows节点上,安装SCT。
安装完毕后,从开始菜单中找到它,并启动。第一次启动时候,将会自动出现新建project向导,如果没出现,可以从如下菜单启动向导。如下截图。
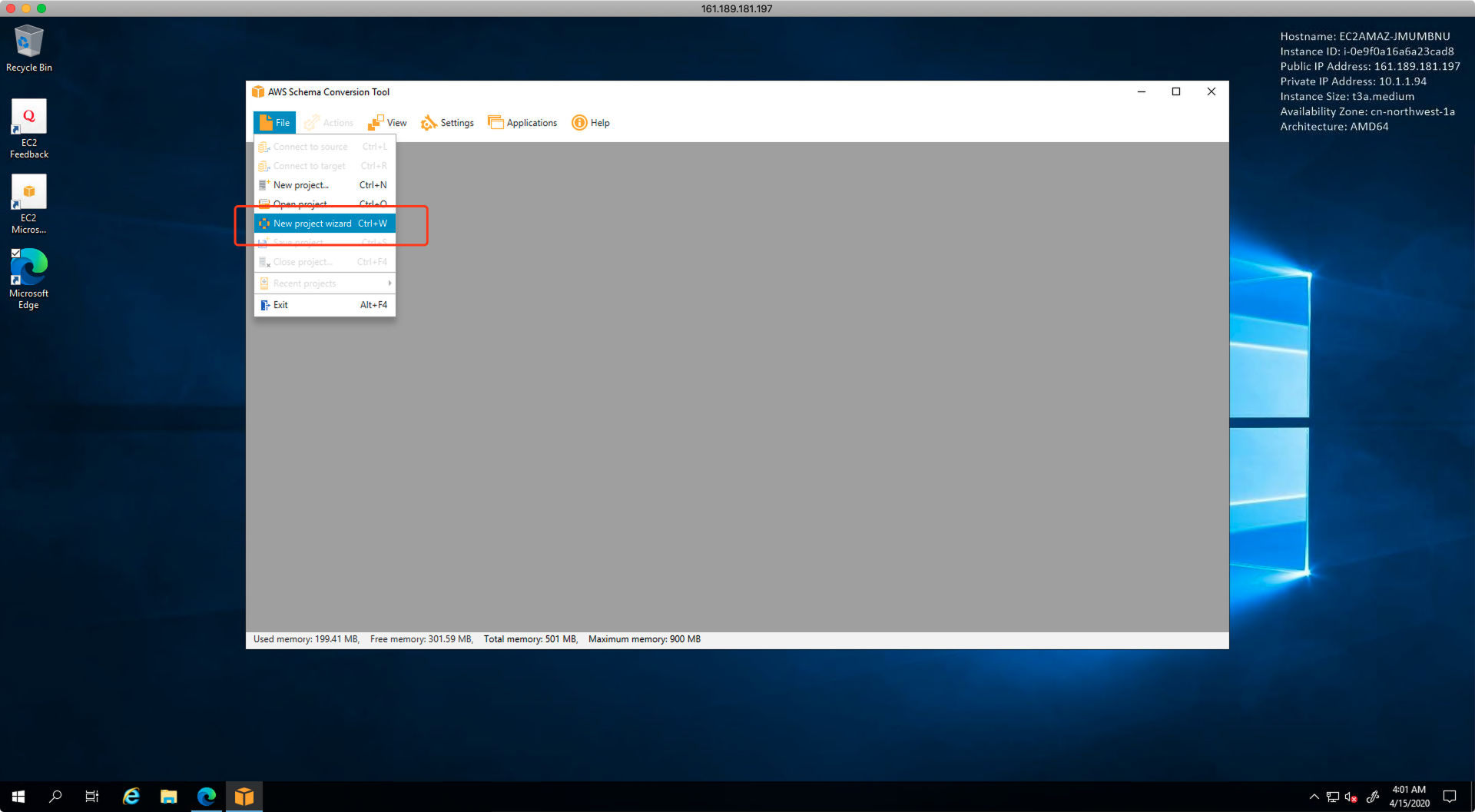
启动后选择数据库类型是OLTP,选择不更换数据库架构,源库和目标库一致都是MySQL,如下截图。
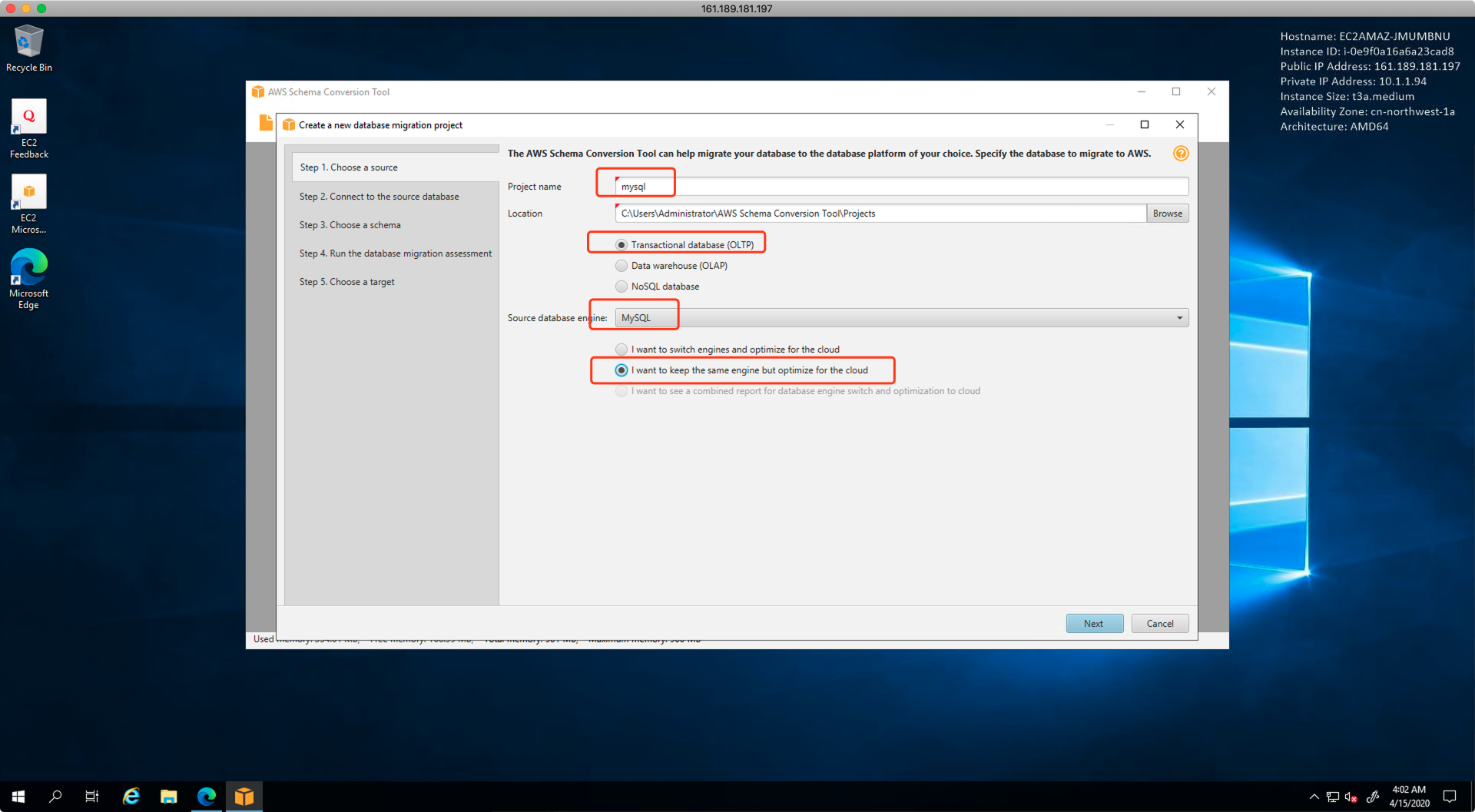
接下来填写MySQL源库信息,由于迁移要使用的权限较多,因此建议用root级别账号,允许SCT扫描整个MySQL所有数据库,包含系统库。最后一步选择JDBC文件所在路径。点击下一步继续。如下截图。
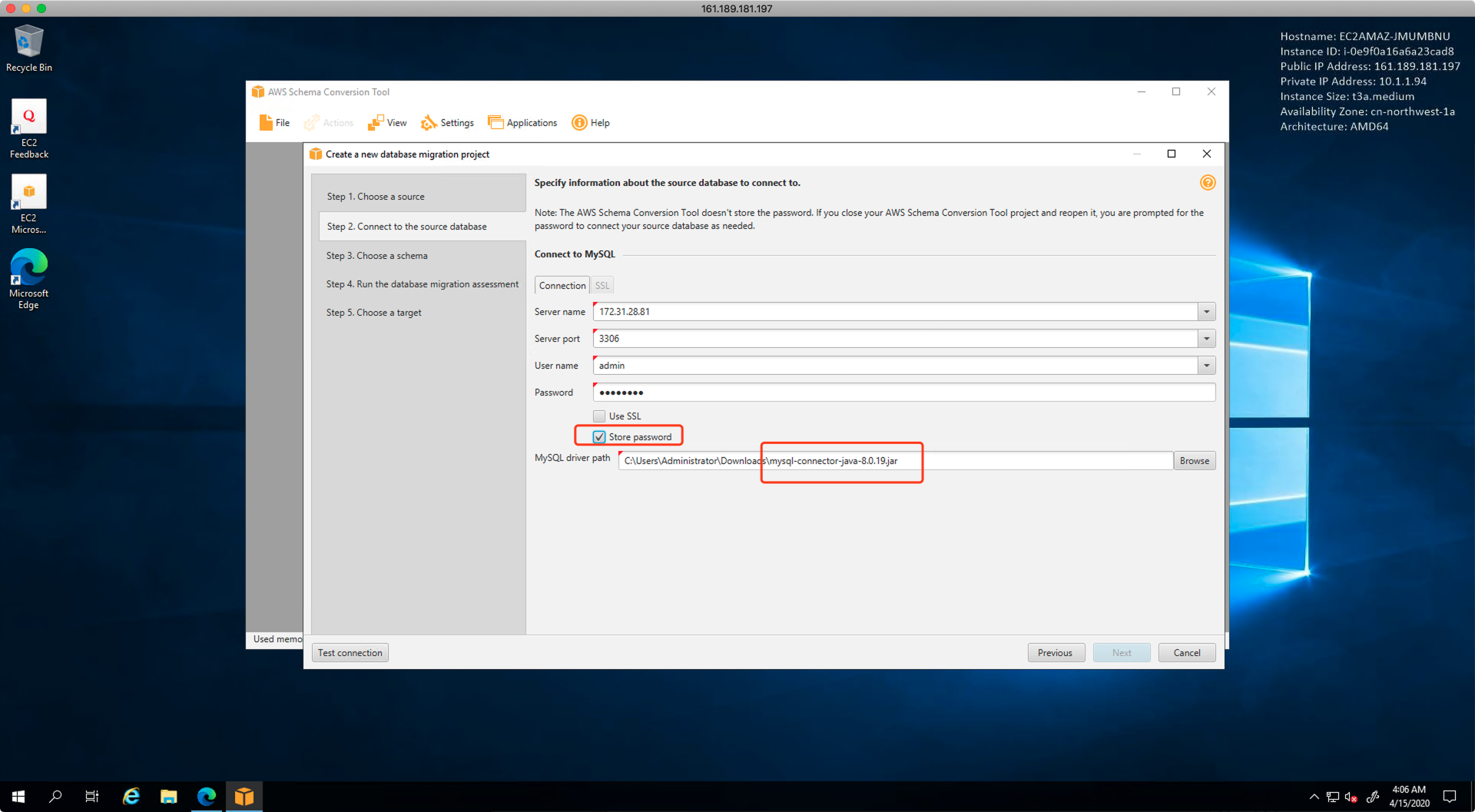
填写源数据库信息完成并建立连接成功后,SCT将提示要扫描哪一个数据库。这里选择应用使用的wordpress数据库。如下截图。
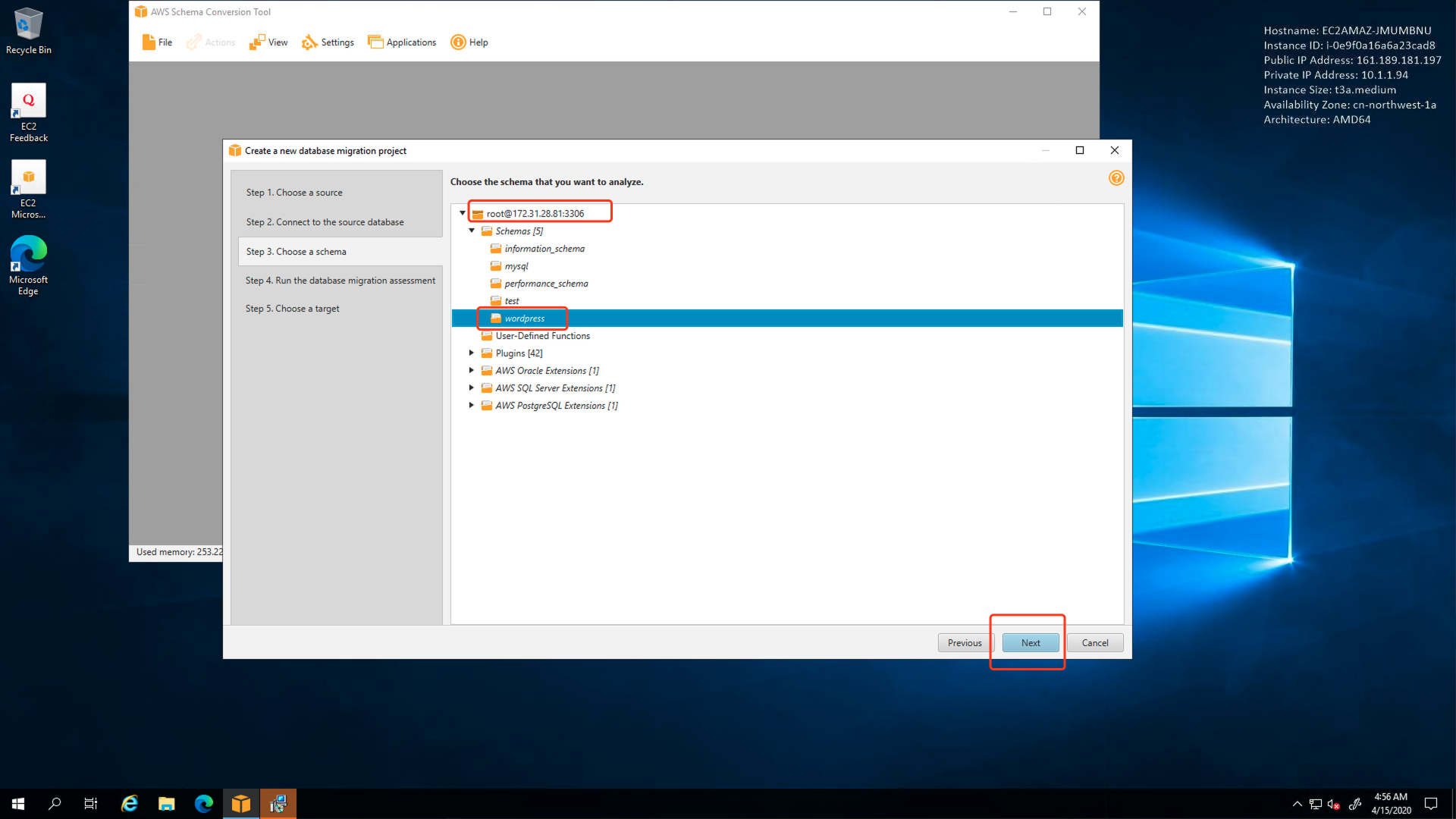
向导第四步是生成评估报告,可以点击右上角的下载,将评估报告下载到本地。如下截图。
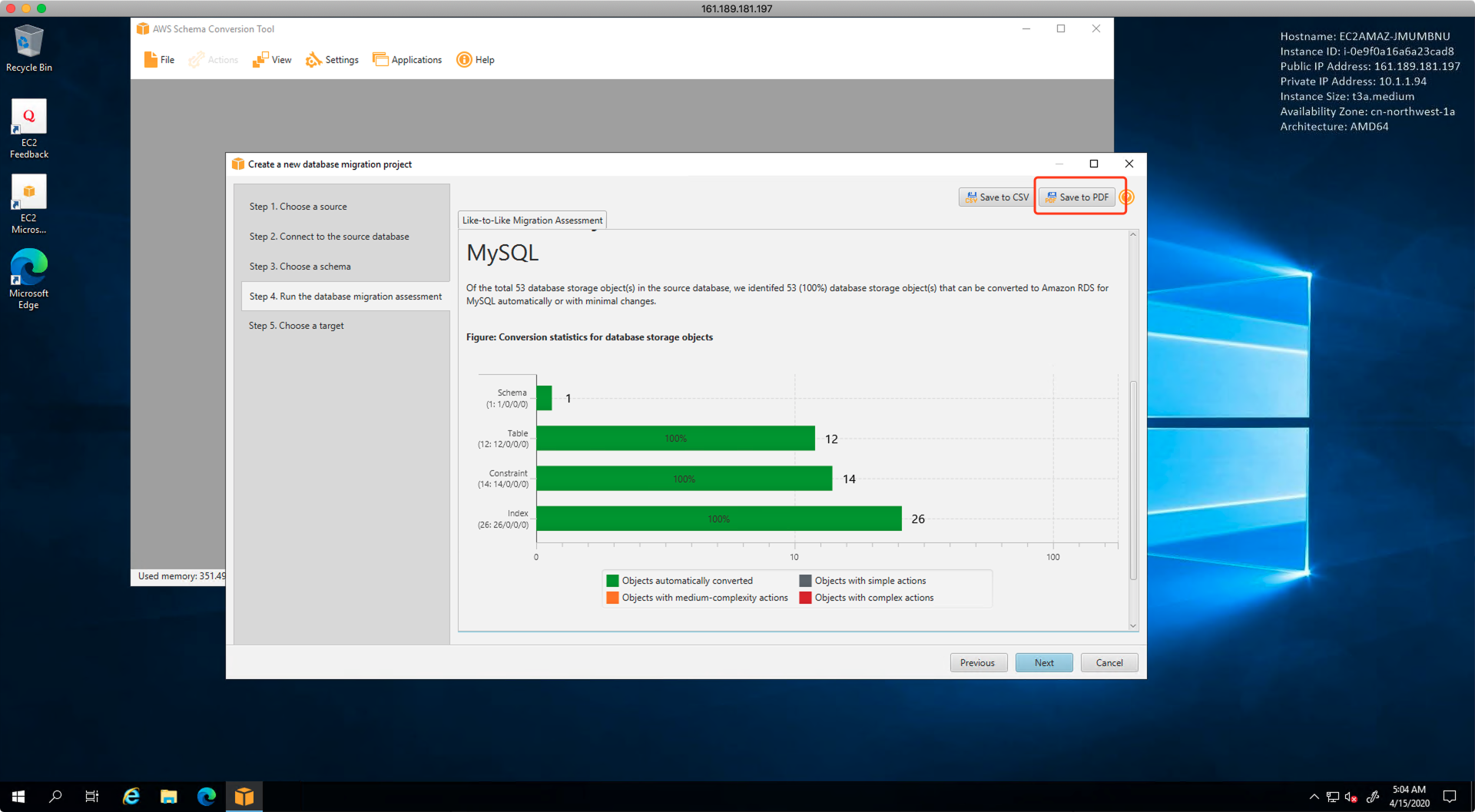
打开评估报告可以看到结论是,100%的数据可以被正常迁移。
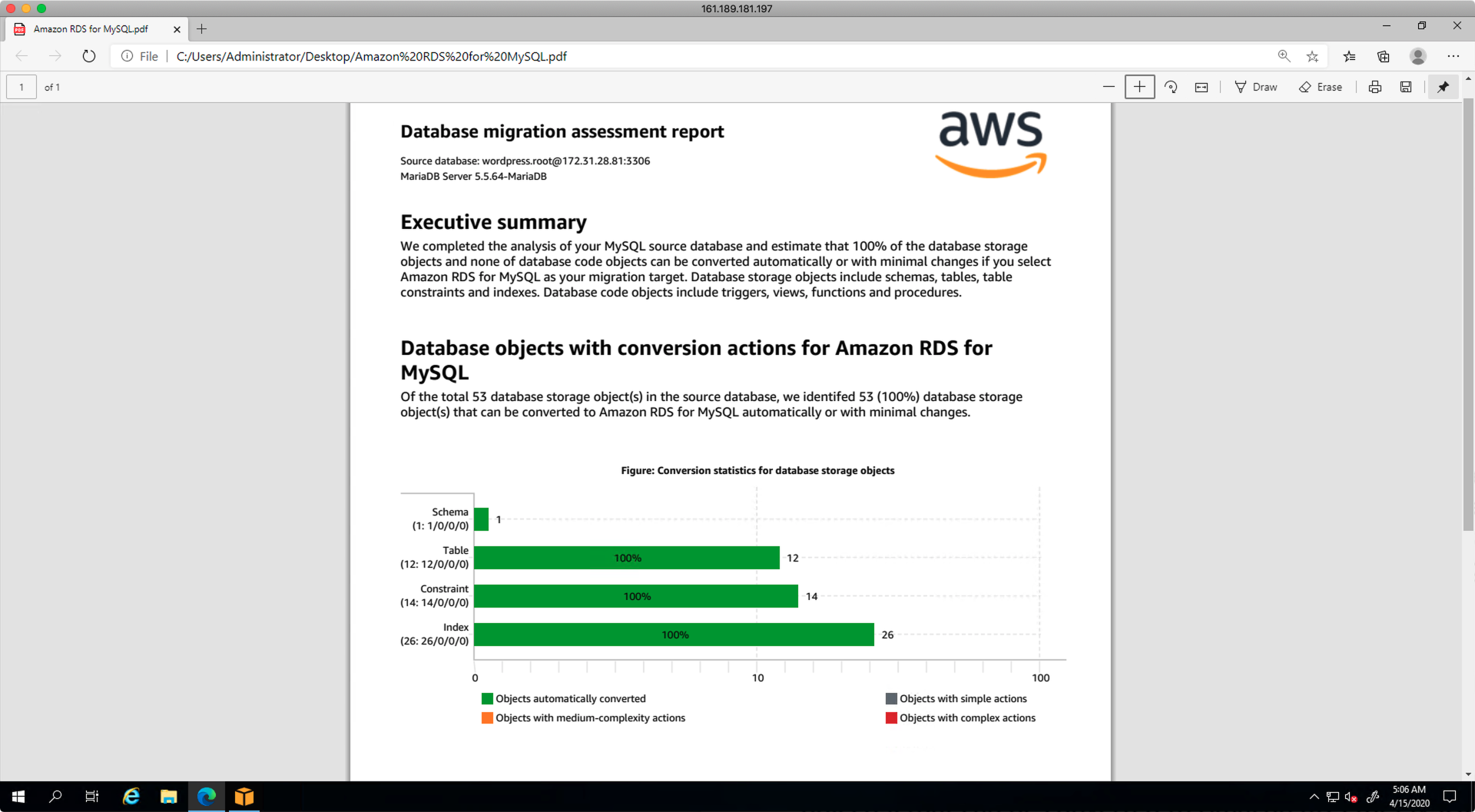
向导的最后一步,是填写上目标数据库的地址。点击测试按钮完成连接性测试,然后点击保存。如下截图。
点击另存为一个新的project名字和路径,完成对配置文件保存。
SCT工具主要是对数据库结构进行分析,生成兼容性报告,并对于需要转换数据库架构的场景下,负责schema转换。本例中,源库和目标库都是MySQL,不存在异构,但是使用SCT可以快速建立整个Schema,显著降低后续手工调整数据库的工作量。
2、使用SCT创建目标库Schema
在SCT界面上,左侧显示的是源库,右侧显示的是目标库。
点击鼠标,取消所有的库选中状态。
然后只选中要迁移的一个库,点击鼠标右键,选择“Convert Schema”,如下截图。
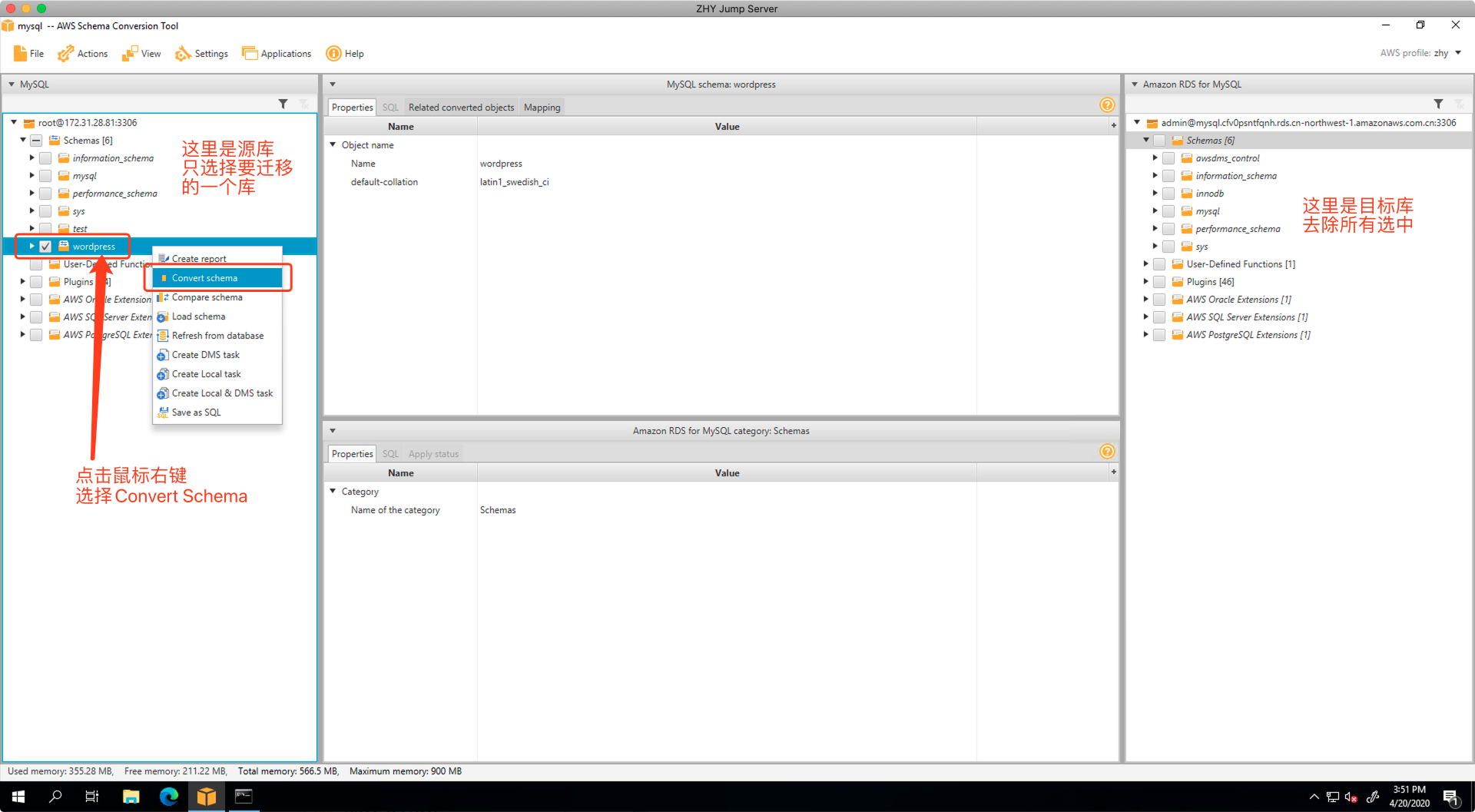
在弹出的对话框中,选择Yes,如下截图。
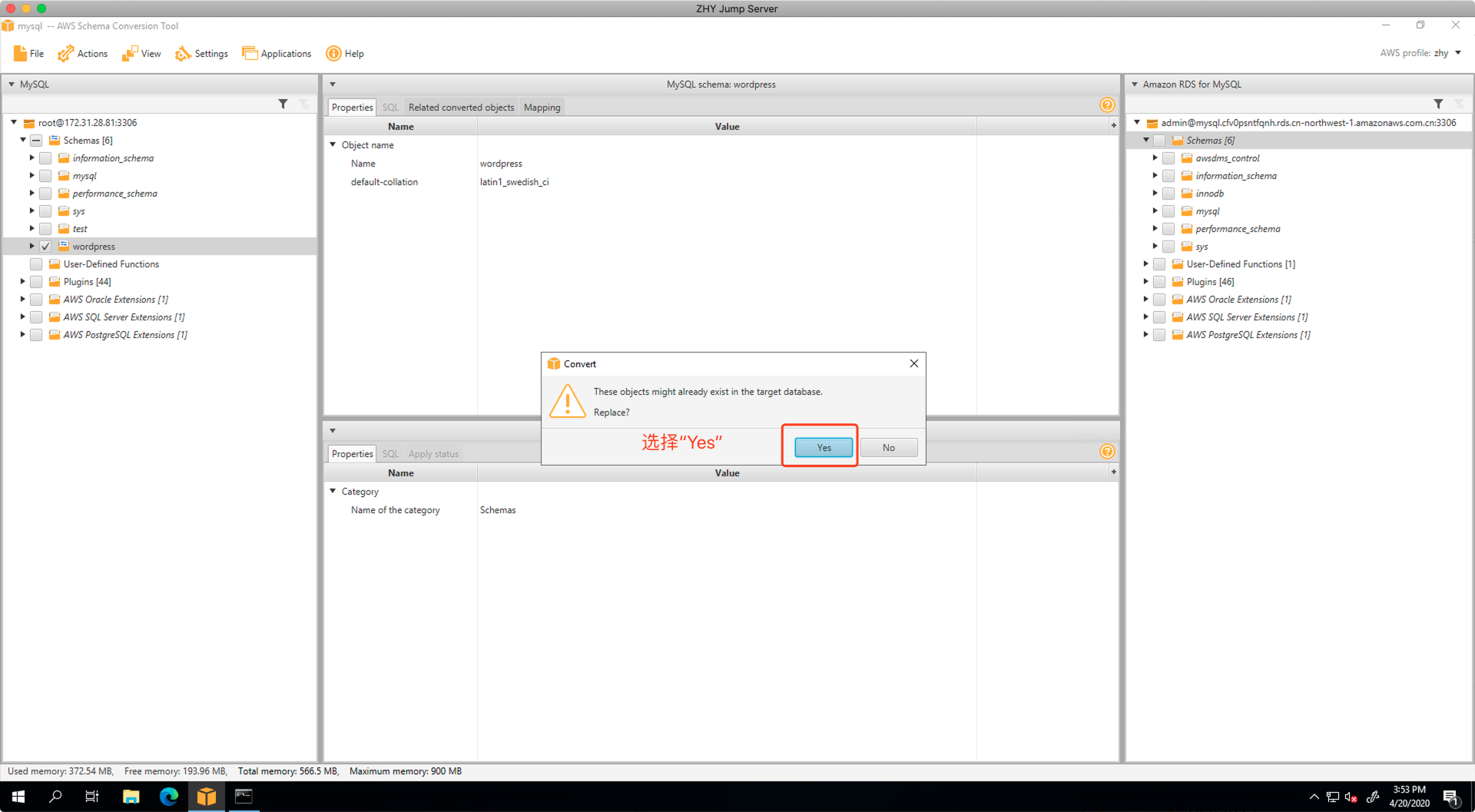
此时对右侧的目标库点击鼠标邮件,选择Apply to database,会将Schema应用到目标库上,完成表的创建。
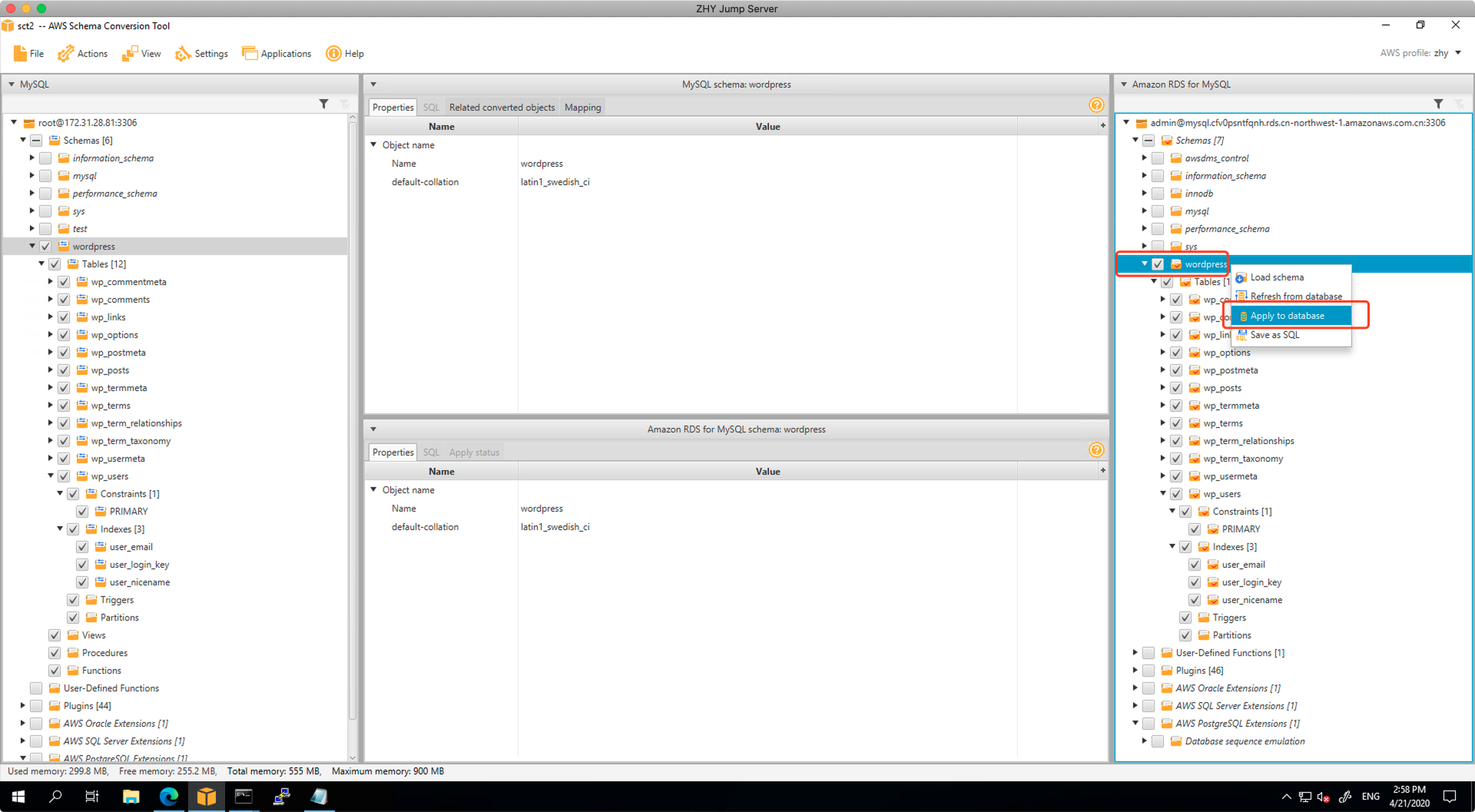
在弹出的对话框中,选择确认。
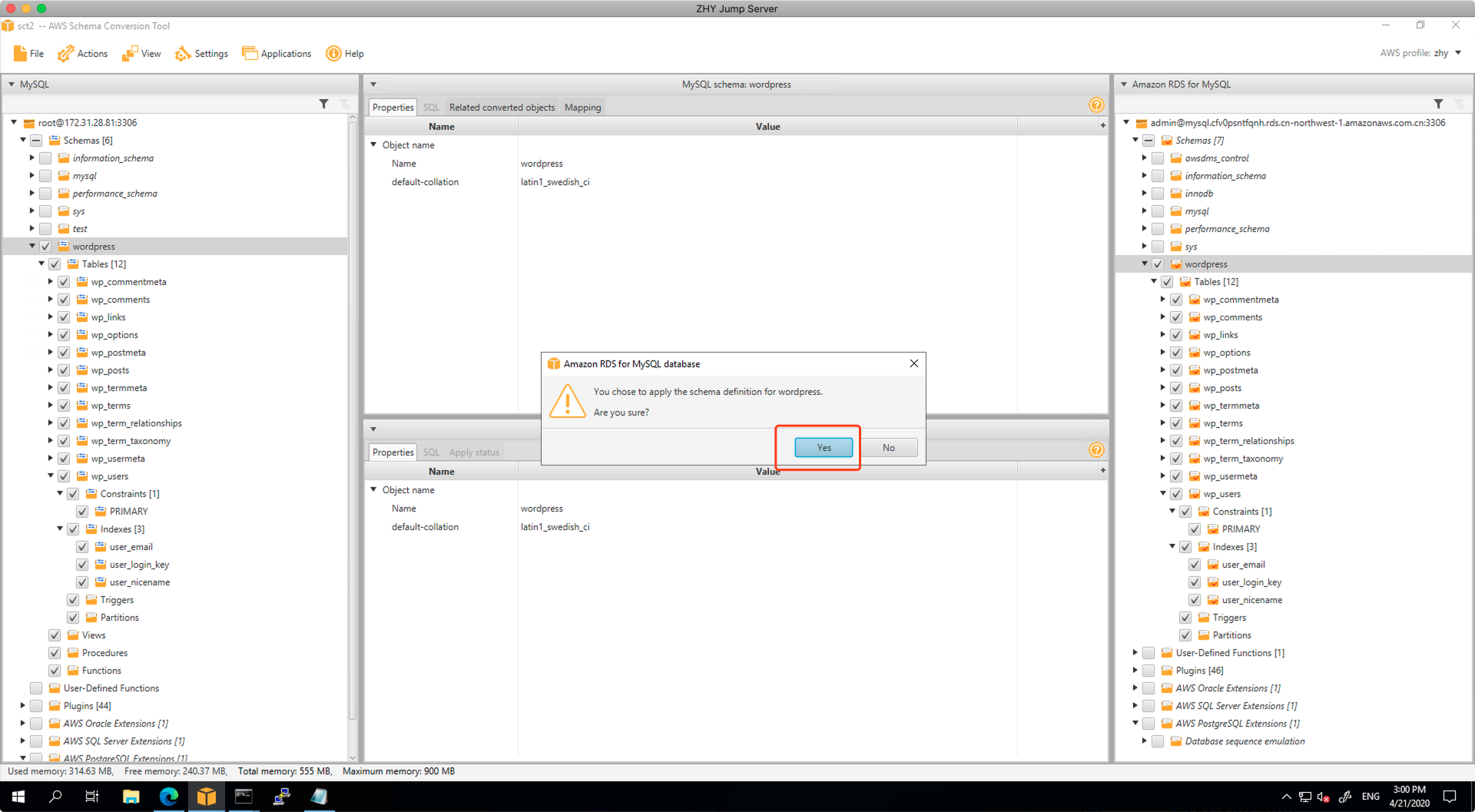
建立完毕后,展开菜单,可以看到目标库内的Index索引也正常建立。
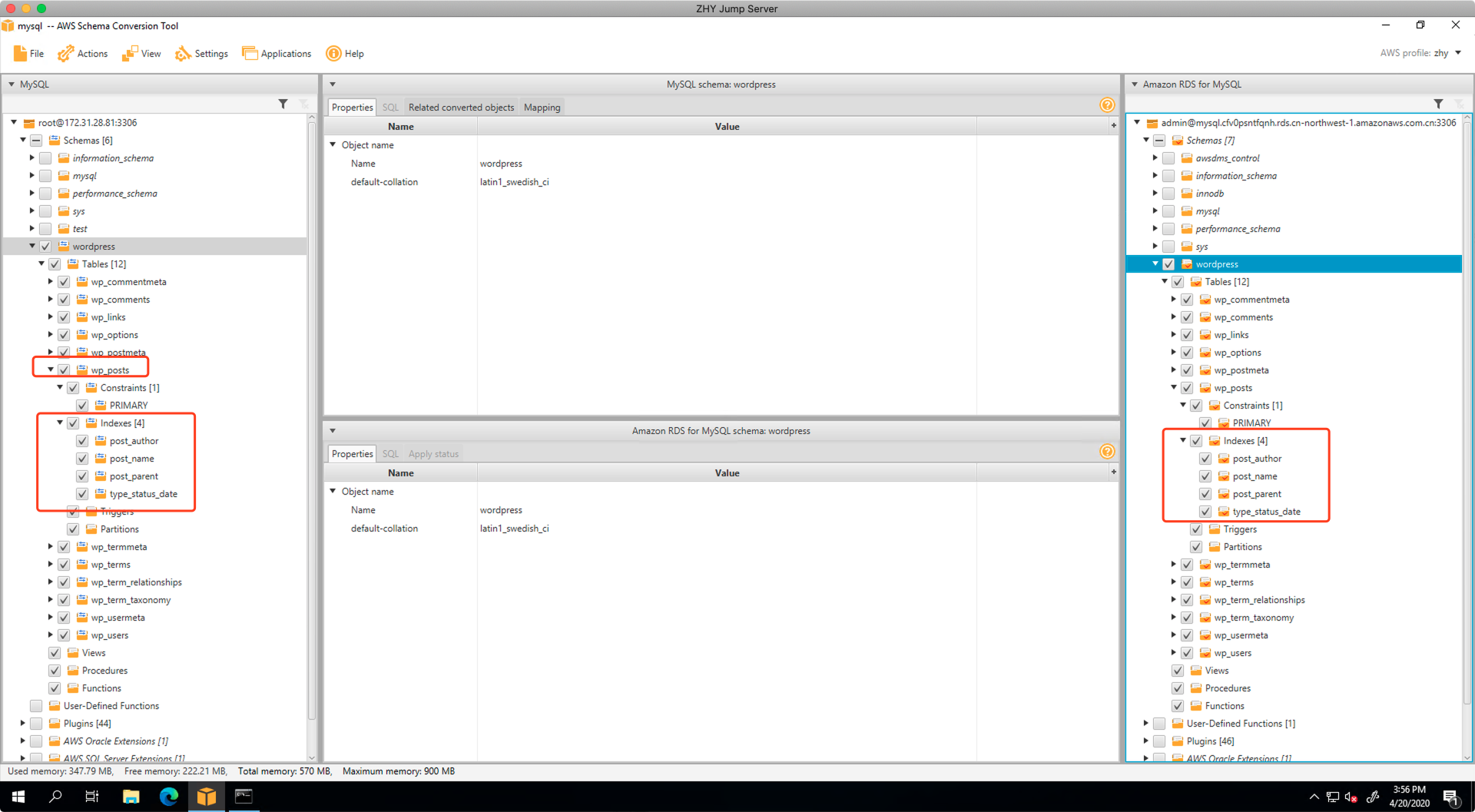
再更换一个表检查,可以发现目标库内的自增ID也已经迁移完成。
通过以上过程,可以看到使用SCT便利之处就是完整的将Schema迁移到了目标库,由此就省去了后续手工补充建立索引等一系列问题。
这一步的执行过程非常重要,如果SCT在转换中,源库和目标库都是MySQL是同构,但依然遇到了错误,不能正确建议Schema,那么应该停止下来,修正Schema,否则部分表可能确实,后续DMS填充数据可能会报错,造成整个表迁移失败。
后续不再使用SCT操作,将转回到DMS界面继续操作。
三、创建DMS复制实例
1、设置复制实例使用的网络
首先进入DMS服务,从清单中找到DMS,如下截图。
RDS复制实例需要工作在特定的subnet子网,才可以同时访问源站和目标站。点击左侧的子网组,然后点击右上角新建。如下截图。
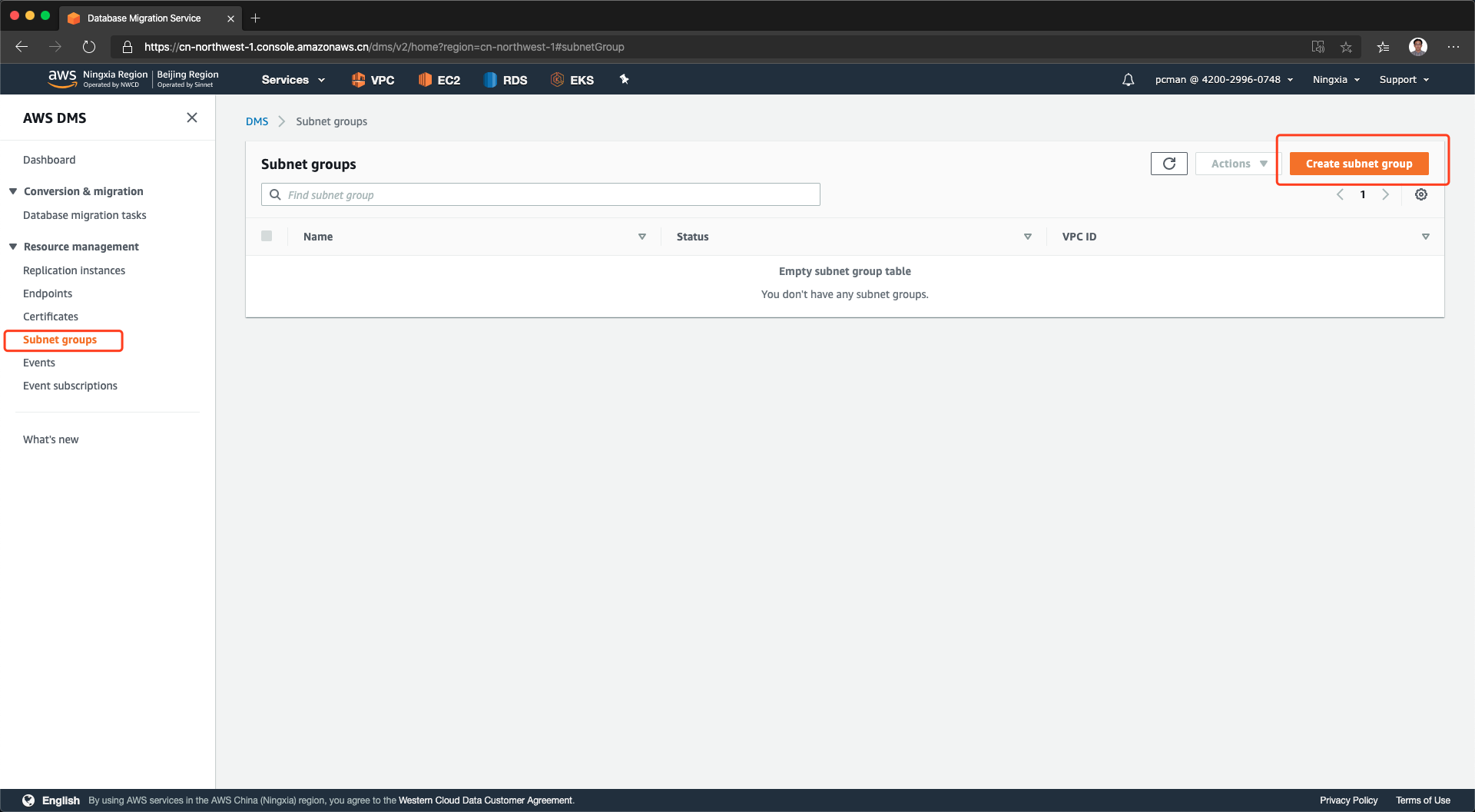
在新建子网组界面,输入自定义的子网组名称,输入描述。然后从VPC清单中选择应用所在的VPC,接下来继续选择正确的子网。本例中,选择VPC1Private1和2子网。这两个子网是本VPC内部署应用的内部子网,且也是未来运行RDS服务的子网,同时这个子网也具有去往私有数据中心IDC的路由表条目,可以访问IDC。如下截图。
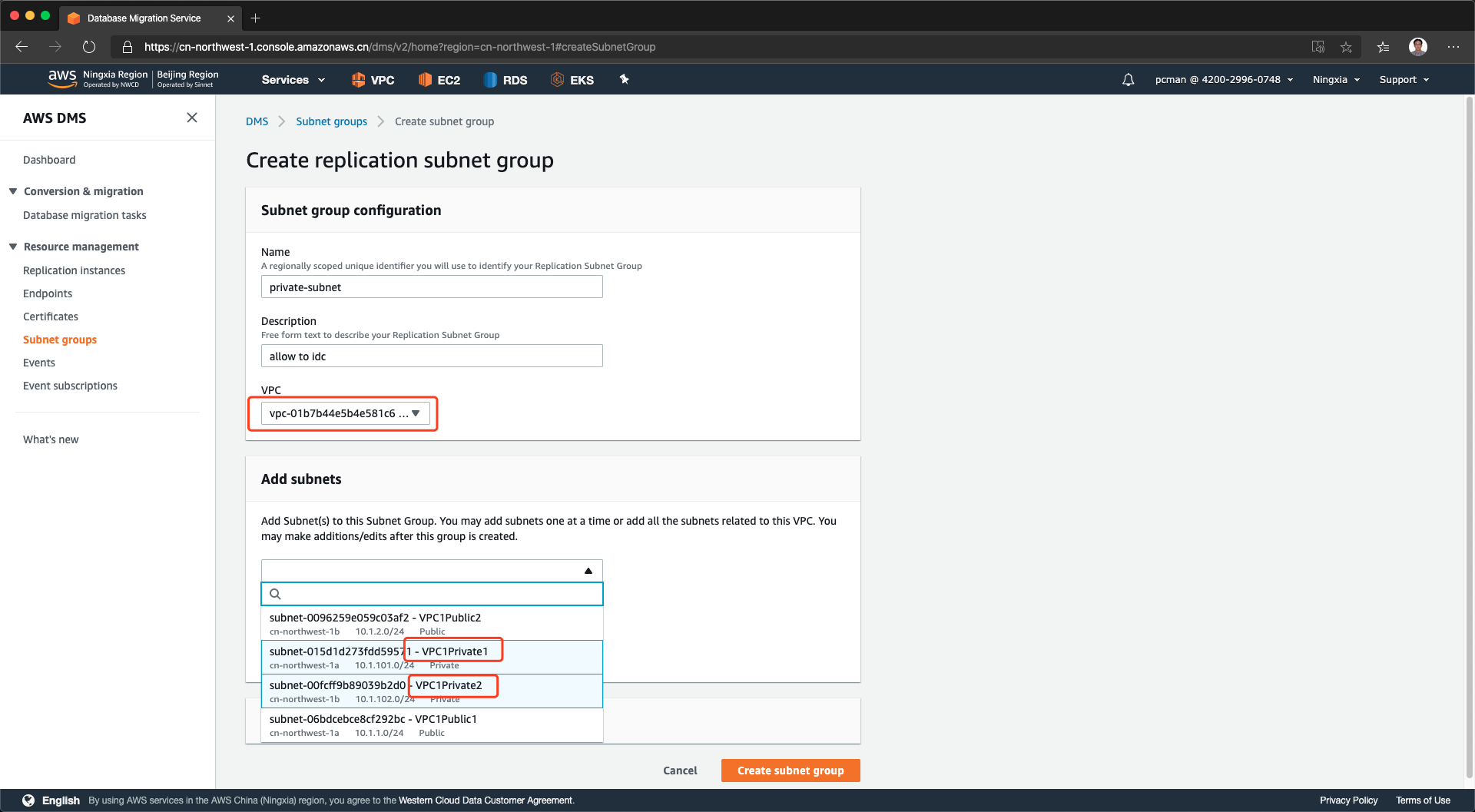
点击创建,编辑子网组成功。如下截图。
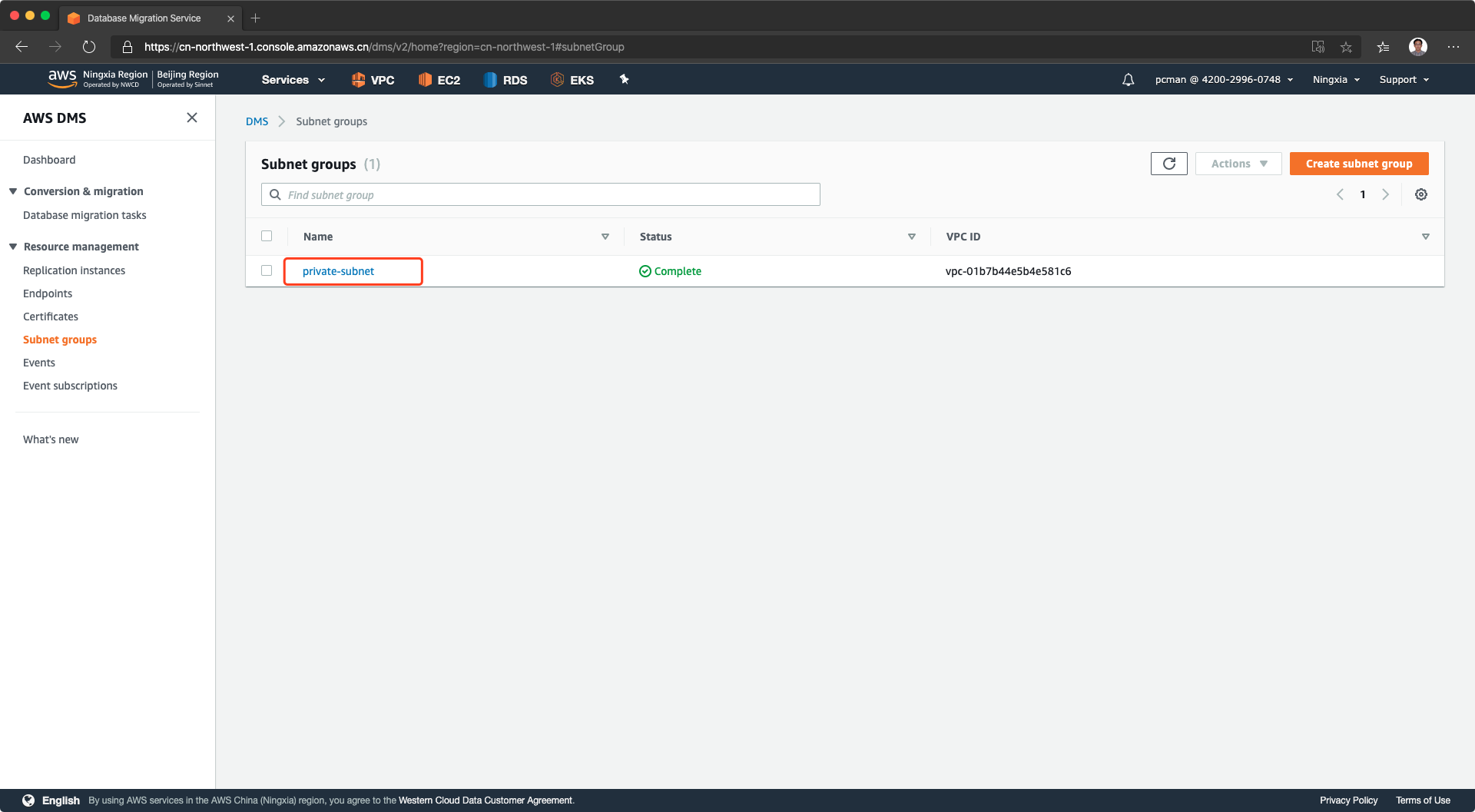
2、创建复制实例
从左侧菜单中,选择复制实例,然后点击右上角创建实例。如下截图。
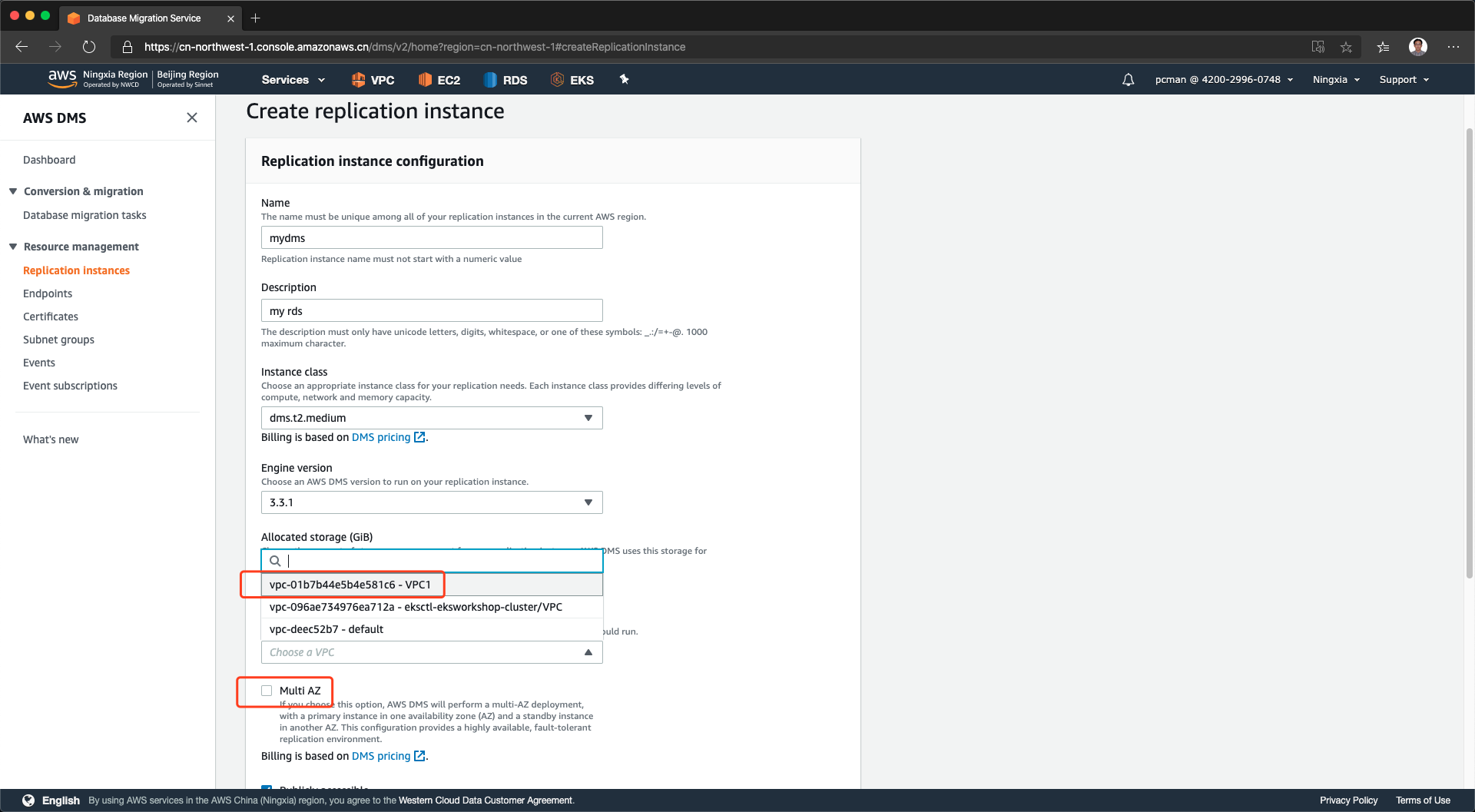
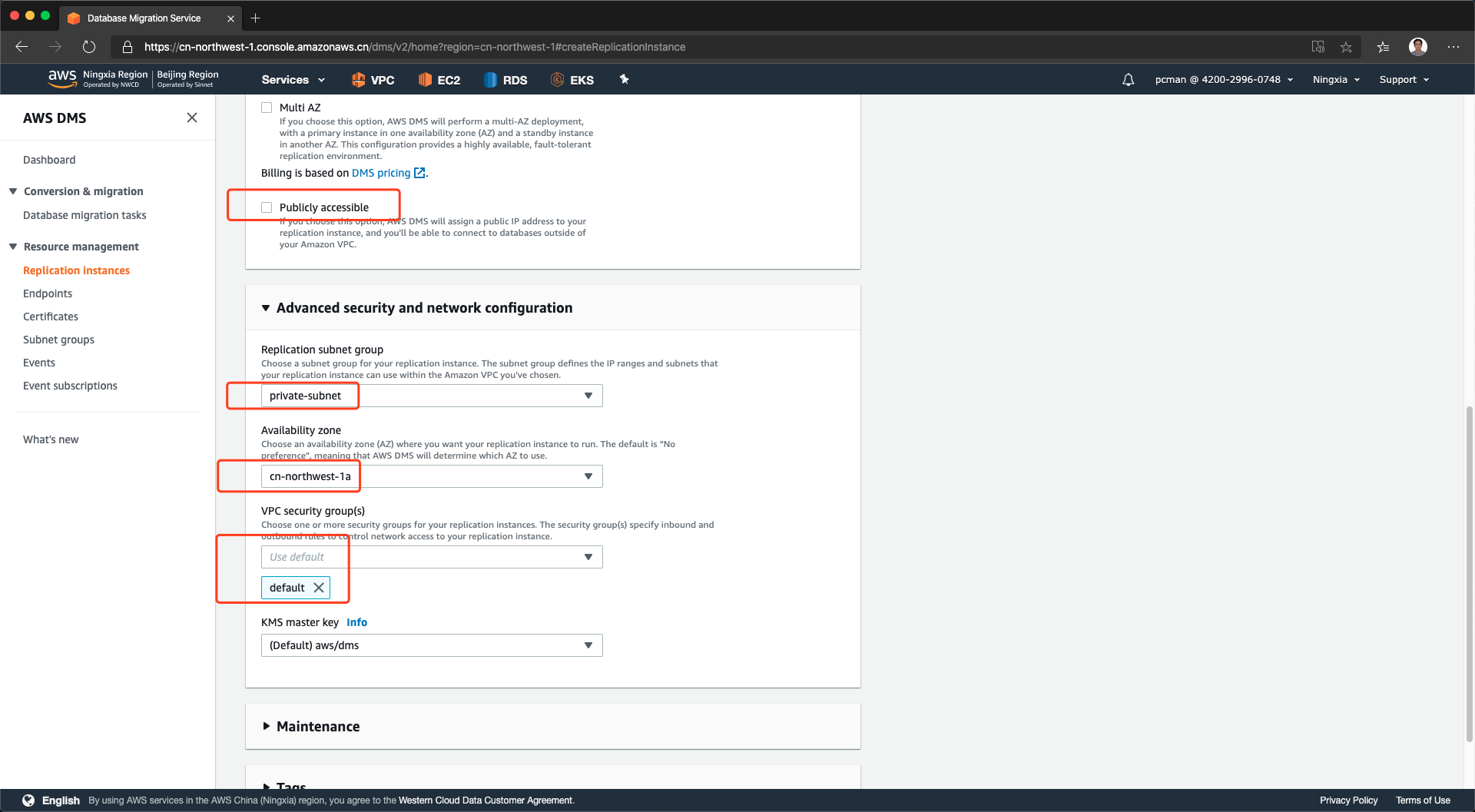
在创建复制实例的页面上,填写名称等通用信息。引擎版本选择3.3.1即可,引擎使用的虚拟机规格选择dms.t2.medium即足够满足复制要求。另外,在多AZ选项上,可以不打勾,单可用区复制即可。最后,选择合适的VPC,即上一个步骤穿件子网组的VPC。如下截图。
将页面向下滚动,继续配置。公开访问选项默认是选中的,这里我们取消选中。本例DMS是完全内网。展开高级网络设置,在子网组中,选择本文档上一个步骤配置的子网组,可用区选择与RDS写入节点相同的可用区,以提高性能。安全规则组选择默认即可,复制实例不需要外部登录,因此无需在给复制实例打开SSH等端口。选择完毕后,将页面滚动到最下方,点击创建。如下截图。
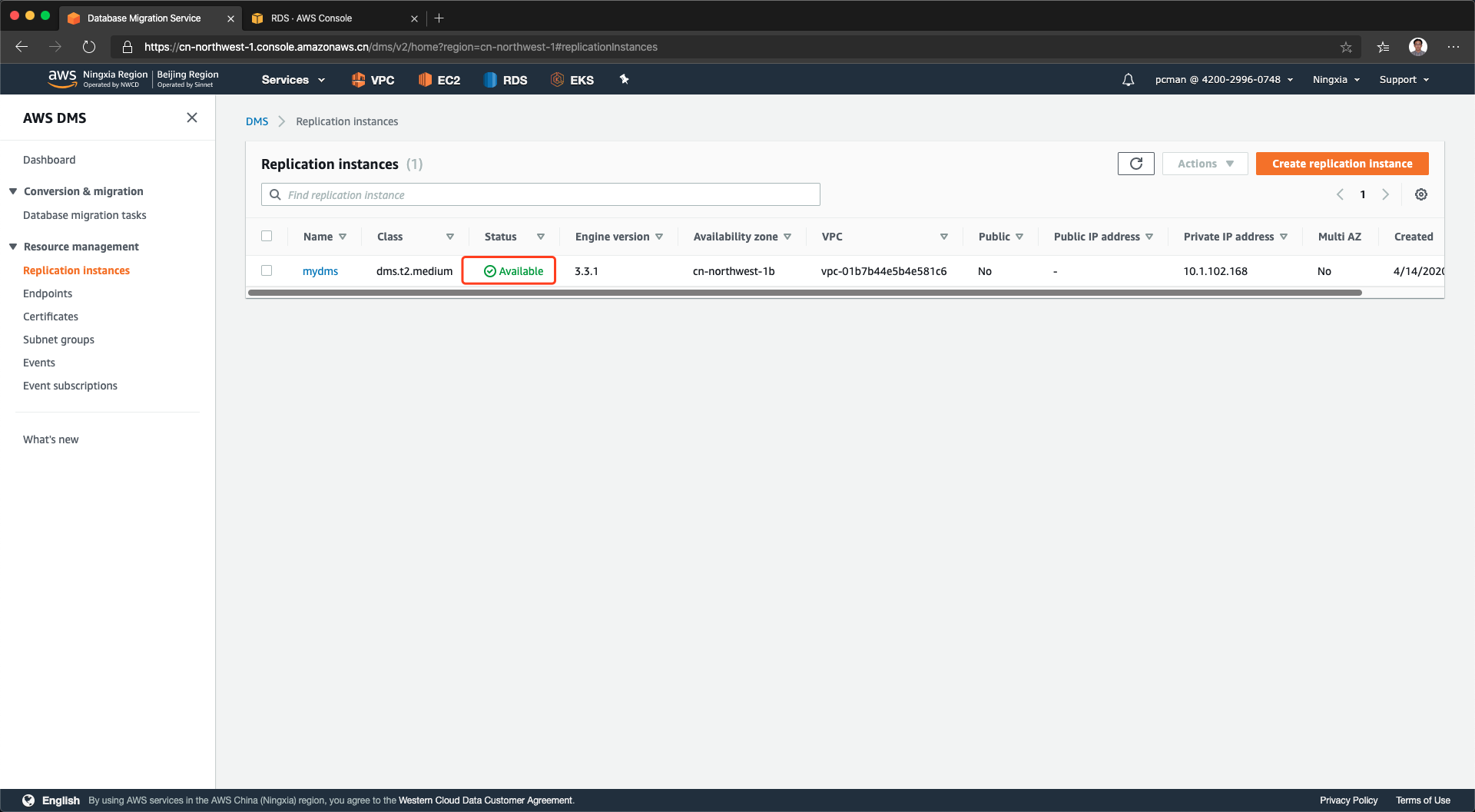
创建DMS复制实例完成,可以看到其状态是绿色。请注意其中的IP地址是DMS在私有子网中落地的IP地址,稍后在下一步将需要配置到源数据库中授予访问许可。如下截图。
3、验证复制实例网络连通性
验证网络连通性有两种方法:一是在DMS复制实例所在的相同子网内,创建一个EC2,然后从这个EC2上ping私有IDC中的源数据库,看能否ping通。方法二是将复制实例的安全组改为一个允许ping的安全组,然后从IDC上的源数据库所在服务器发起ping操作,ping这个复制实例。
验证网络联通将有利于后续步骤排查错误。大部分情况下DMS连接不上源库都是网络配置问题造成的。
四、DMS源库和目标库校验
1、配置源库
首先登录到源库MySQL上,为从DMS远程发起操作赋予授权。执行如下命令。
接下来进入DMS界面,从左侧点击Endpoints,点击右上角创建终端节点。如下截图。
在上方的类型中,选择Source Endpoint,表示当前录入的是源站的信息。不要选中RDS DB instance这个选项狂,在引擎类型下拉框里边选择MySQL,然后填写源数据库的IP、端口、账号、密码等信息。如下截图。
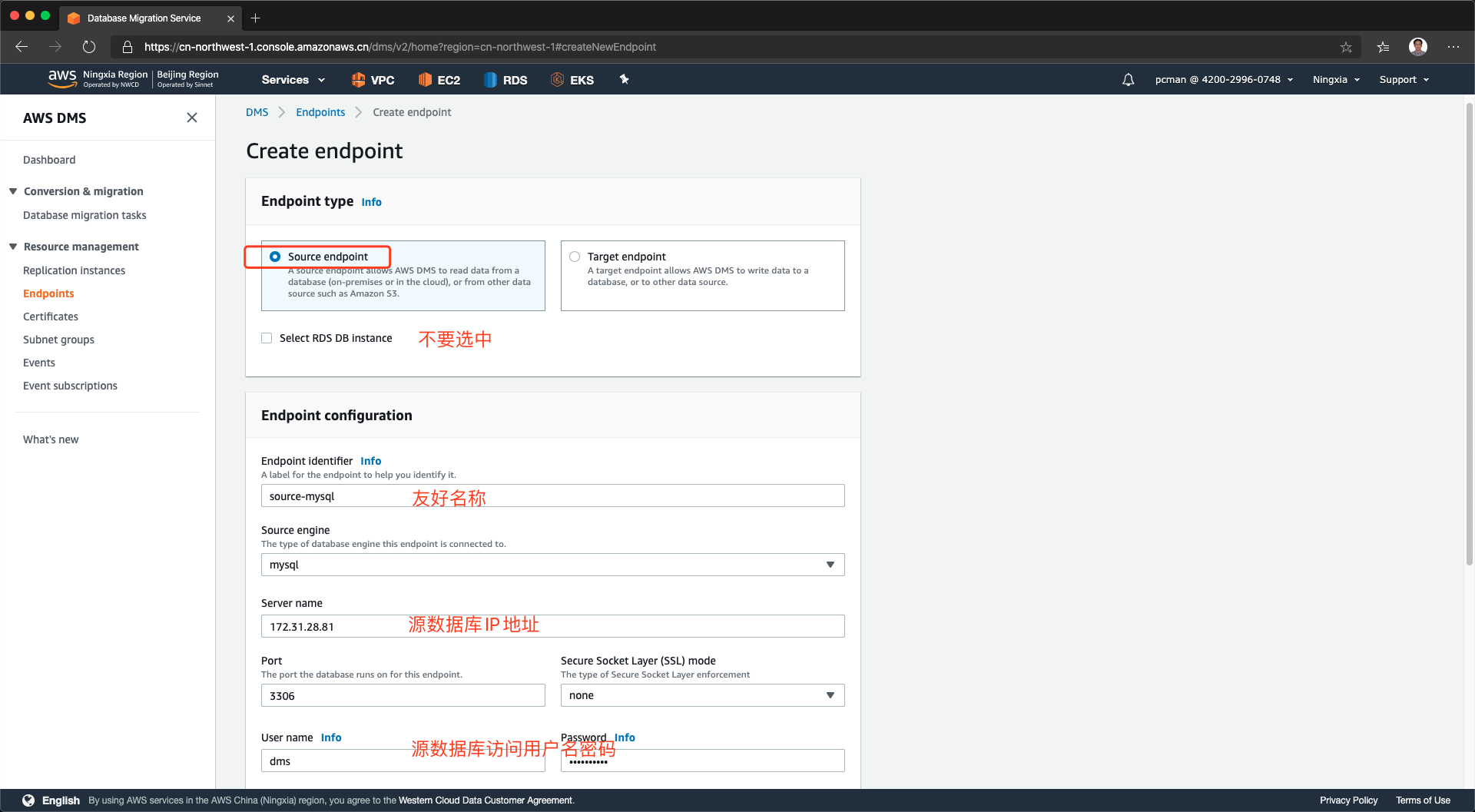
由于迁移过程需要较多权限,建议提供root账号,允许DMS访问系统库。并且需要注意,需要为DMS复制实例的IP地址赋予登录权限。测试环境下,可以将登录地址写为通配符“%”,生产环境下,请先查看复制实例页面上的IP地址,然后只对单个IP赋予登录权限。
将页面向下滚动。来到测试环节。从VPC下拉框中,选择第一步创建子网组的VPC,从中找到DMS复制实例的名字,选中之,然后点击发起测试。如下截图。
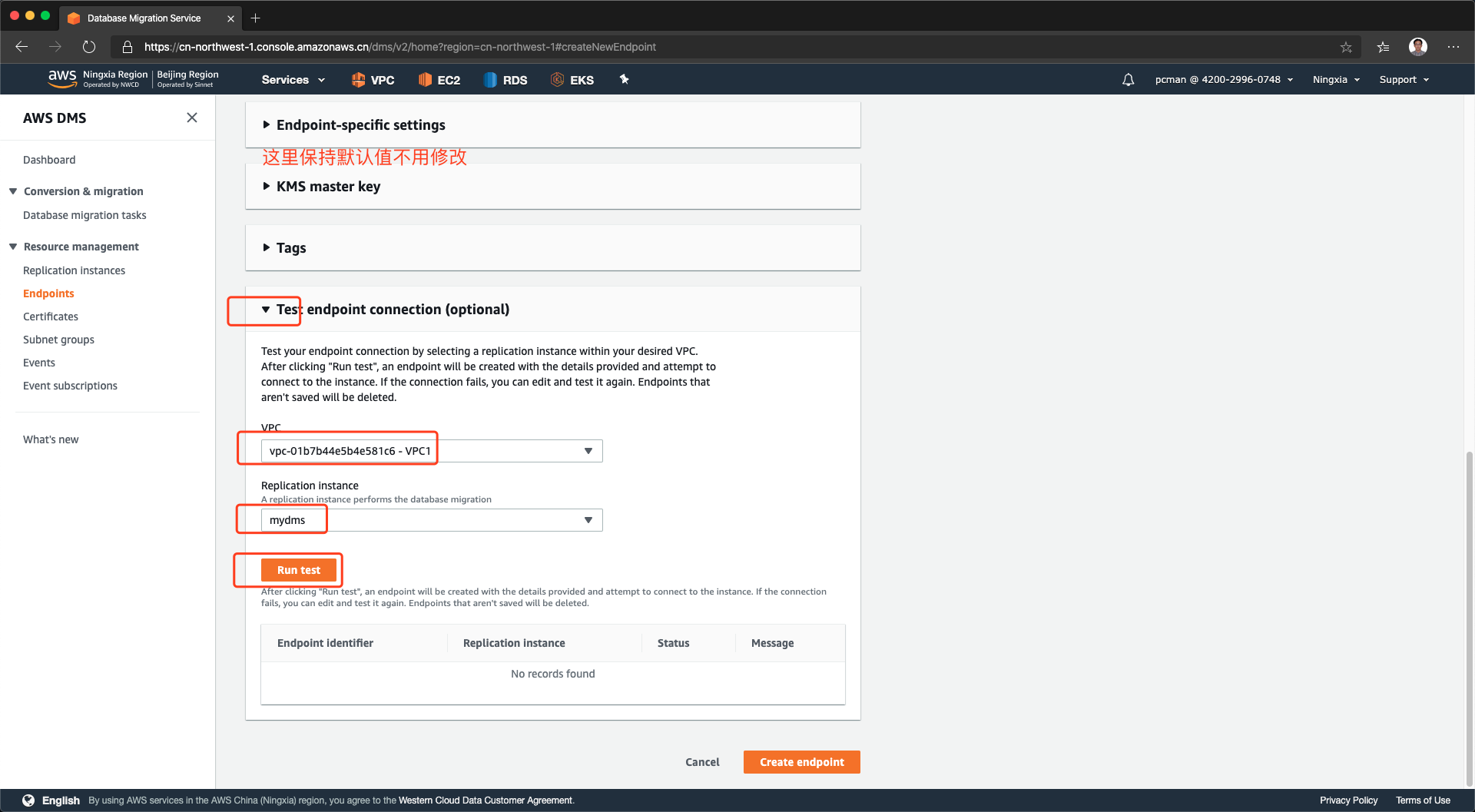
当测试后显示成功状态,就可以点击创建终端节点完成操作了。如下截图。
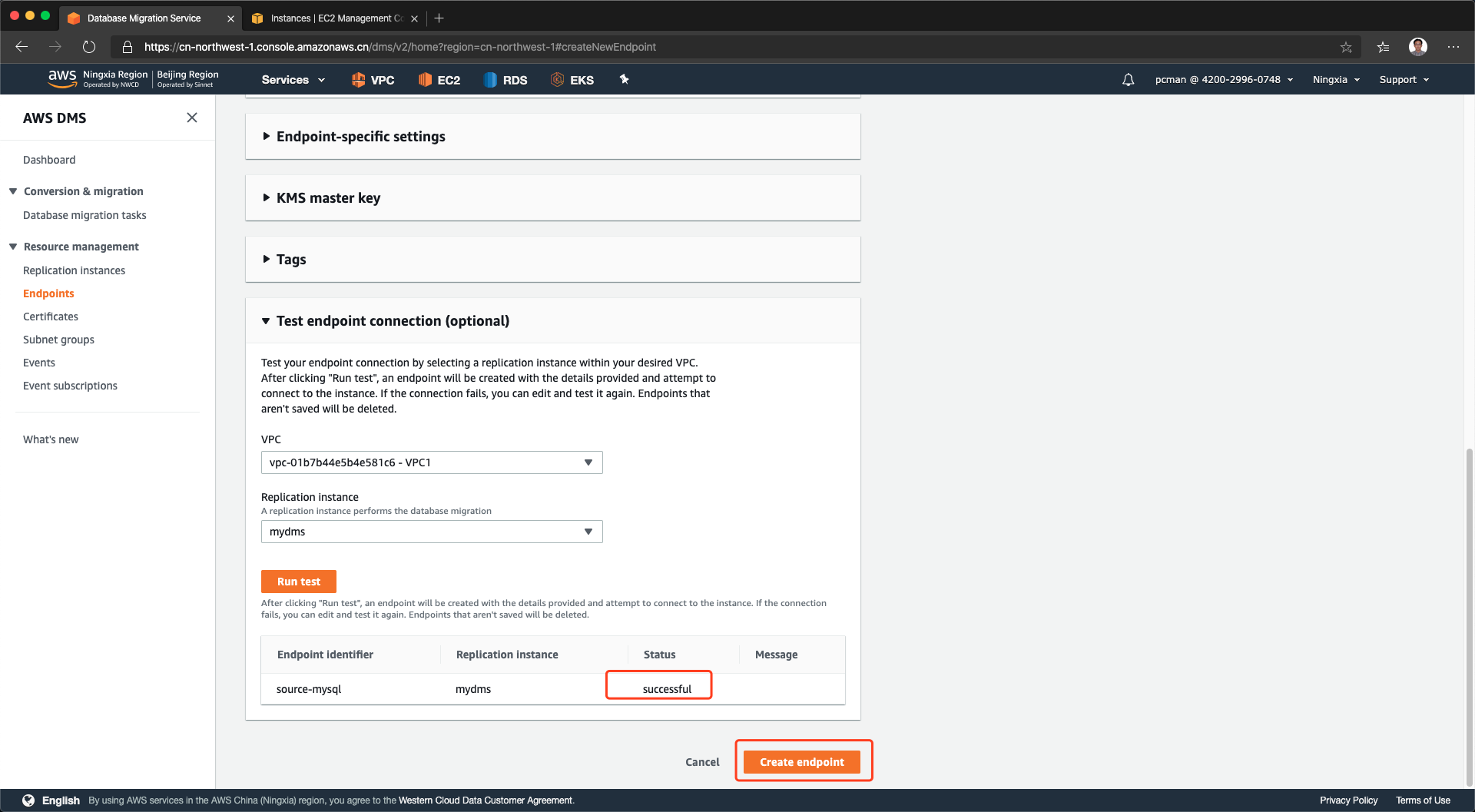
配置源数据库完成。如下截图。
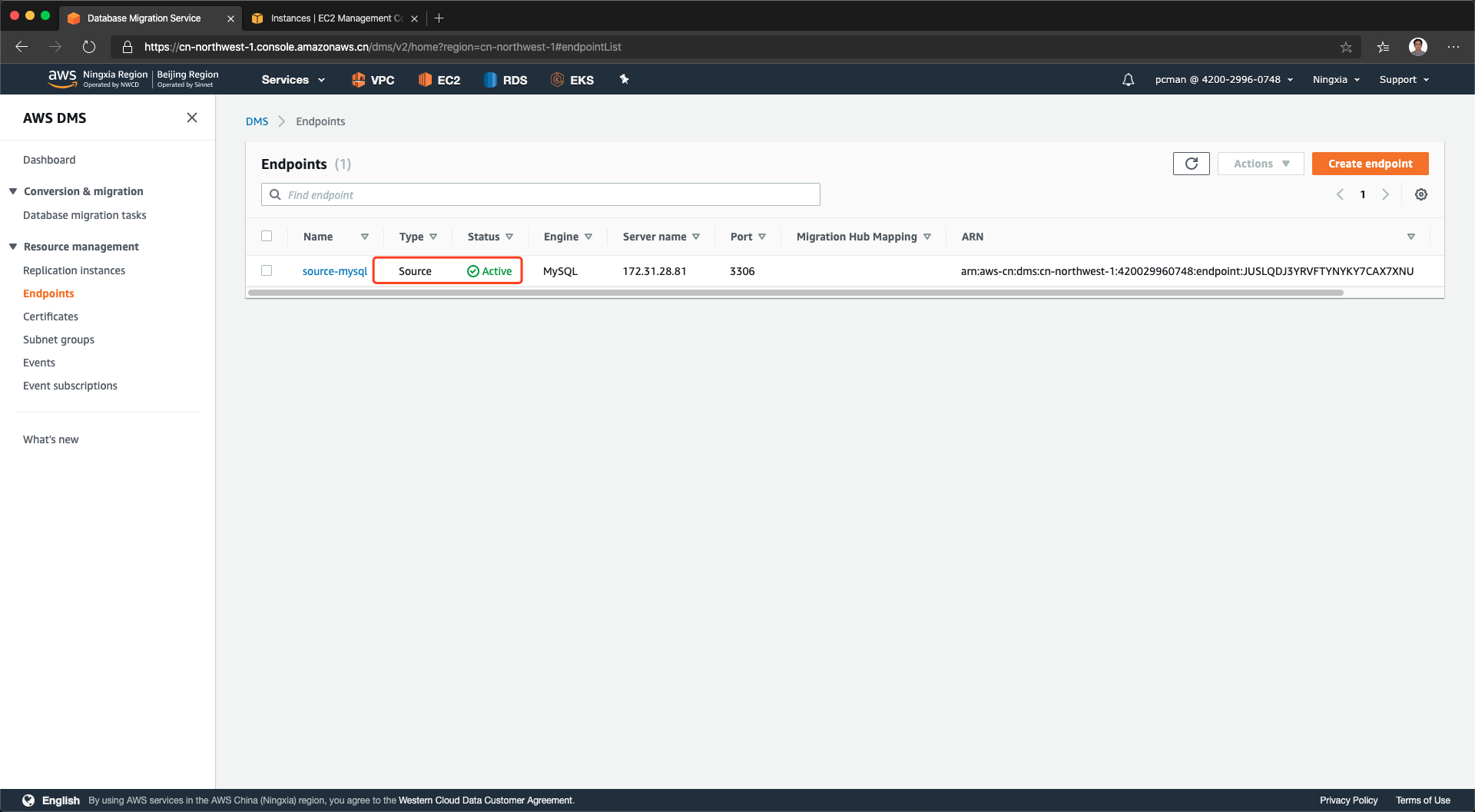
2、配置目标库
在终端节点界面,点击新创建终端节点,在第一项选择类型的时候,选择目标节点。然后,将类型选择为使用RDS DB实例。再从下拉框中选择RDS Instance。这样,RDS实例的有关信息,包括地址、端口、用户名都将自动带出,不用在人工填写了。需要注意的是,密码还需要手工输入。如下截图。
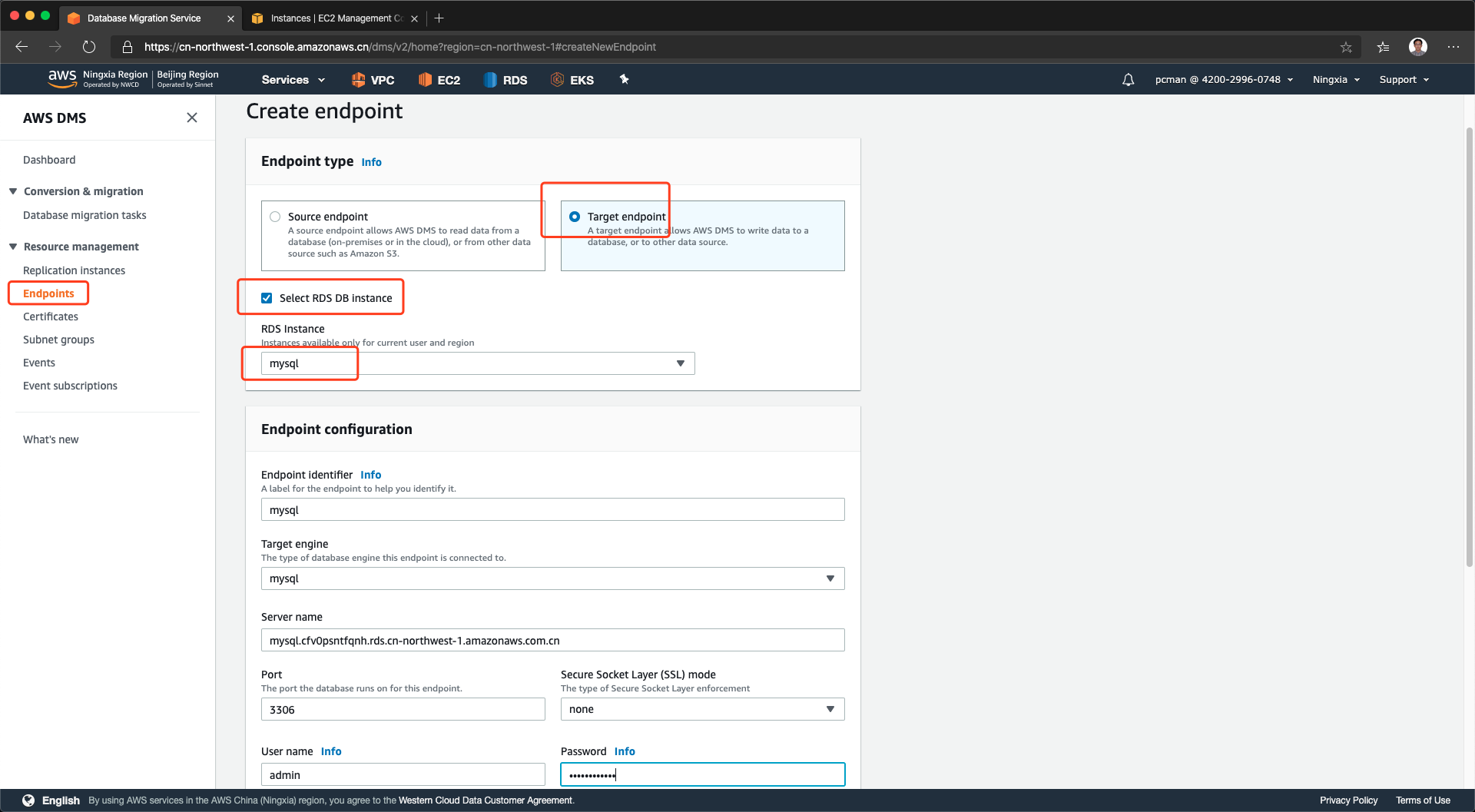
与设置源库的方法一样,填写密码后,也要发起连接测试。测试成功后,创建终端节点。如下截图。
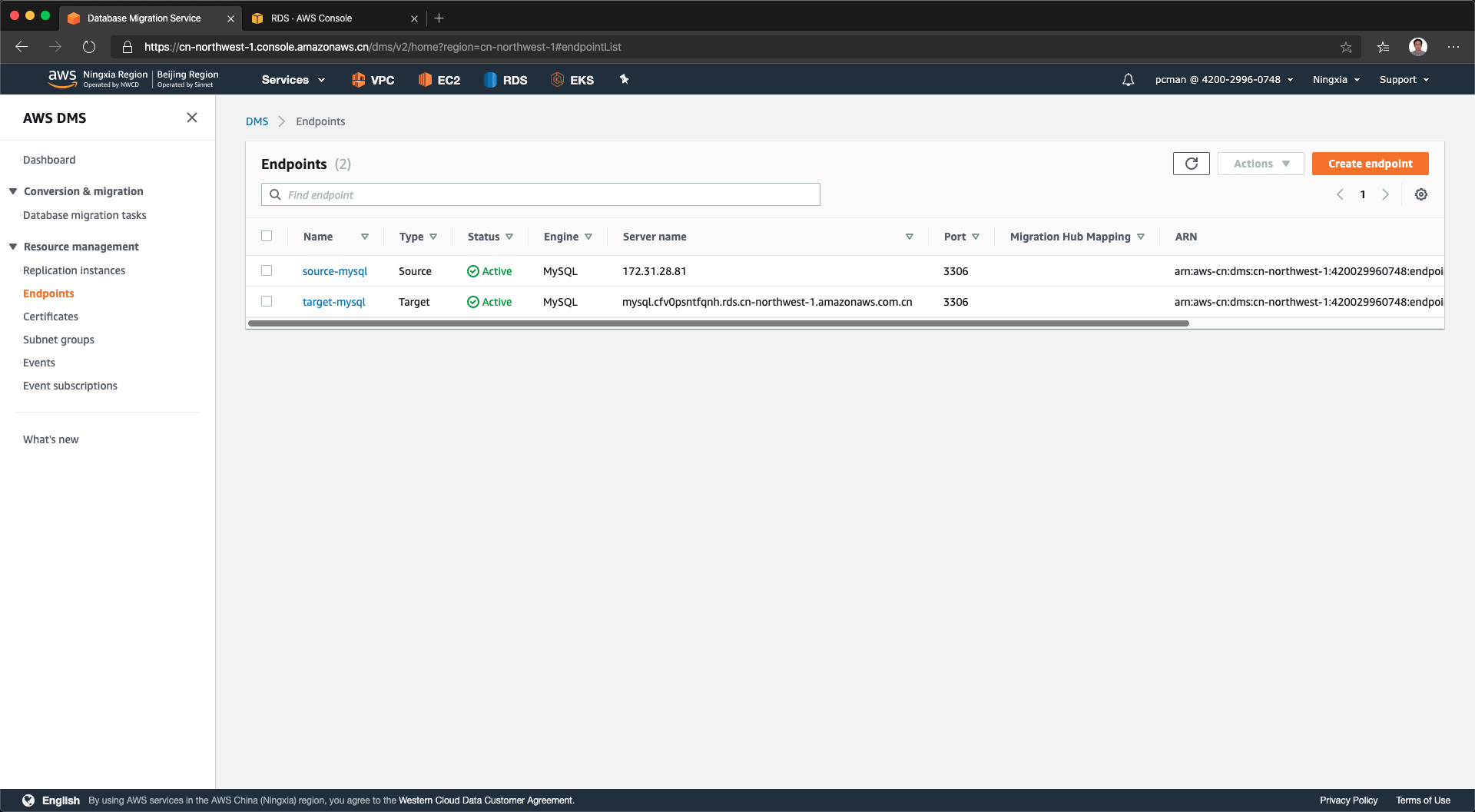
如果在测试过程中,遇到了错误,页面退出,其实系统依然会创建一条Endpoint记录,但是其状态就是测试未成功状态。这时候,需要点击本endpoint名字进入,进入到链接标签页,再次对其发起测试,直到状态显示成功,才是真正配置好。如下截图,
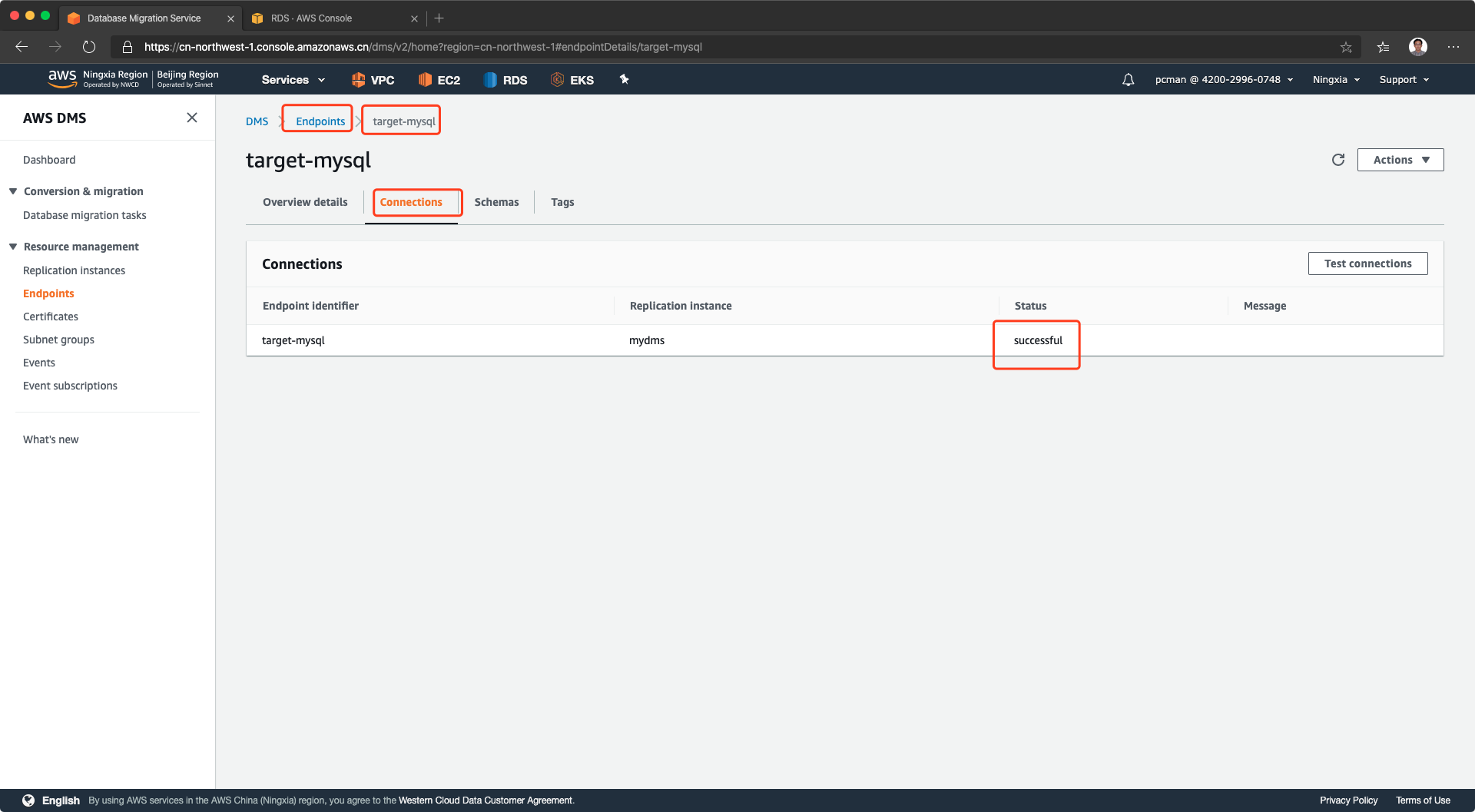
至此终端节点准备完成。
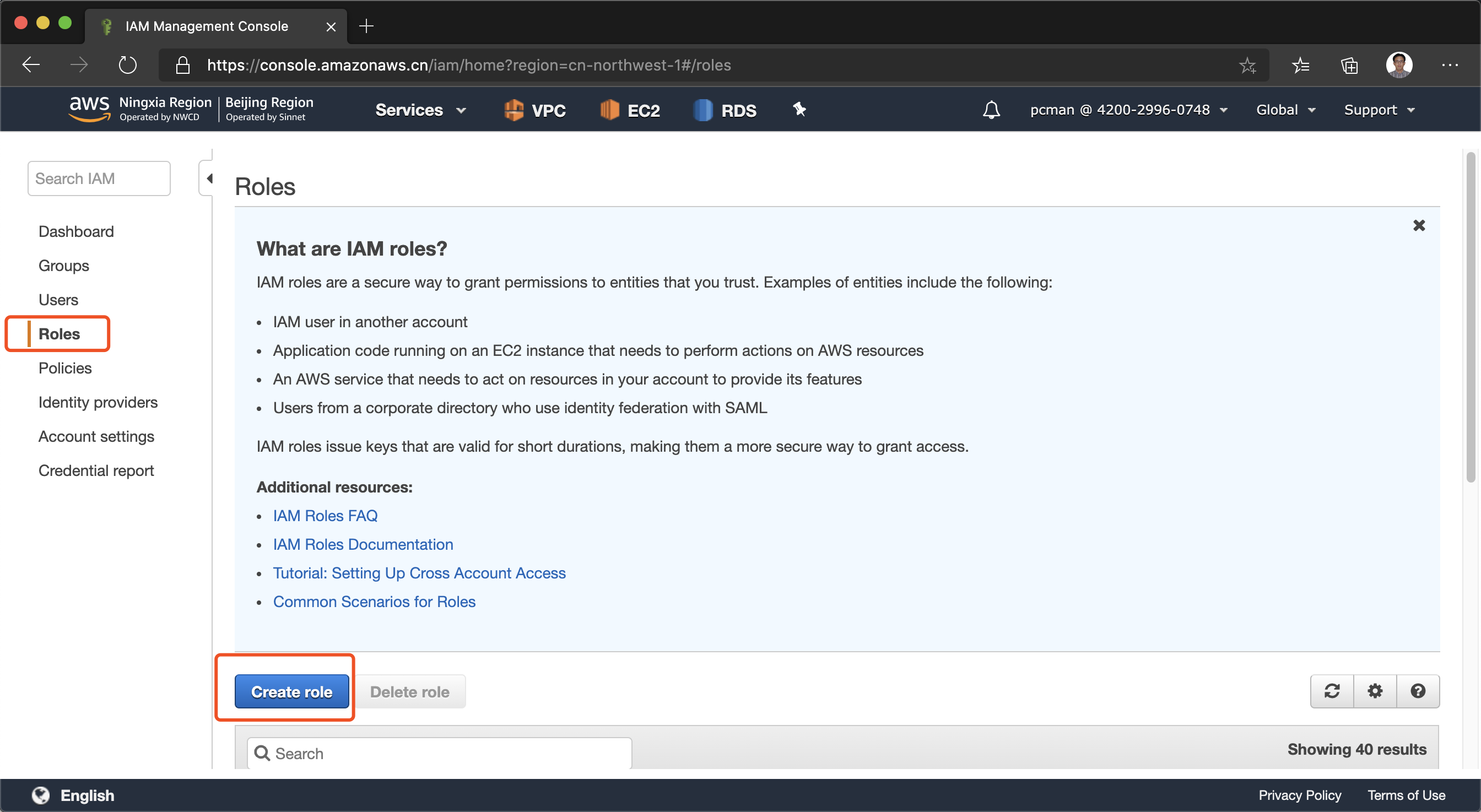
3、为Cloudwatch监控DMS日志设置IAM角色
Cloudwatch可以记录DMS执行日志,需要额外做IAM角色配置。进入IAM模块,点击角色,点击新建角色。如下截图。
在服务清单中,选择DMS,然后点击下一步。如下截图。
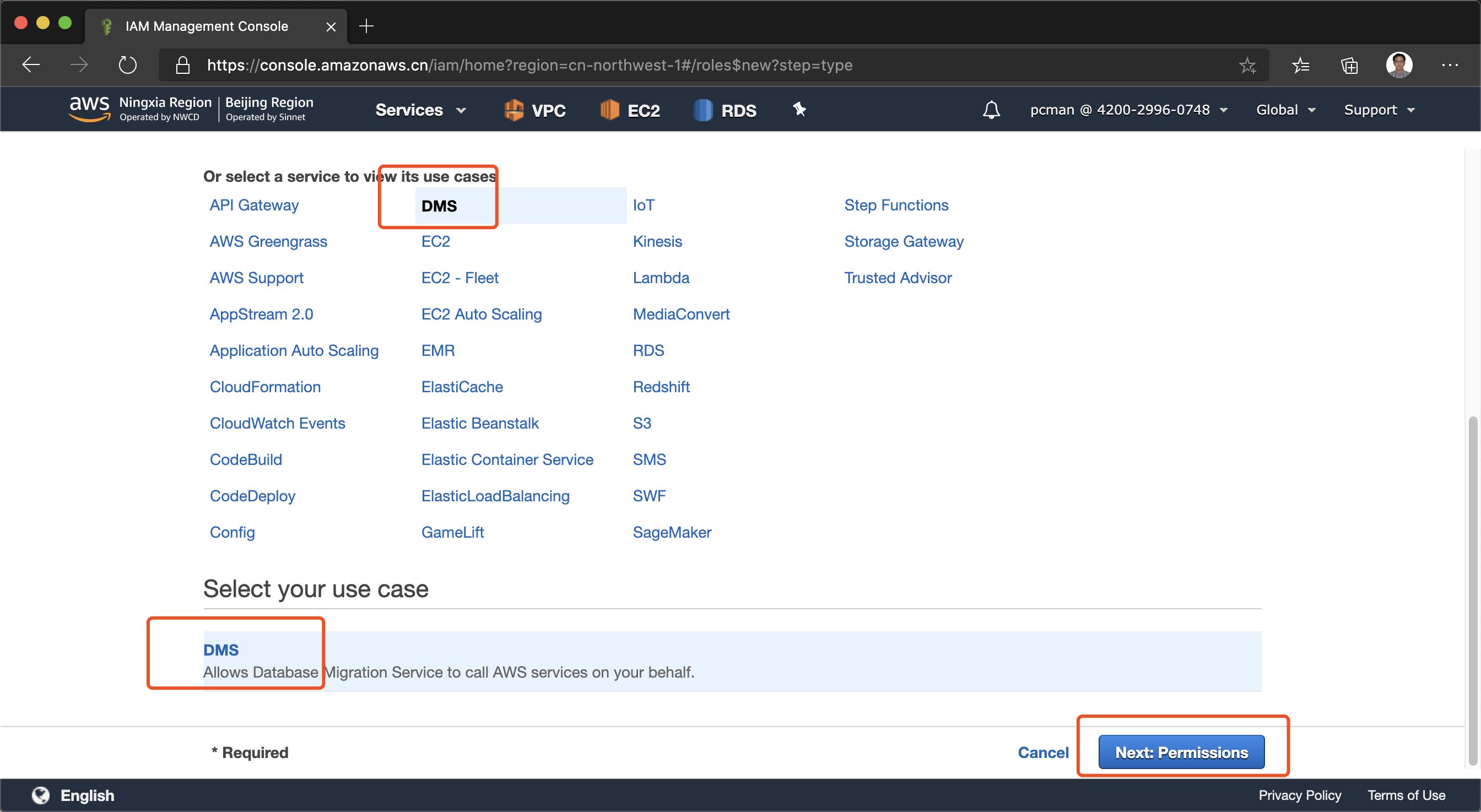
下一步在权限配置界面,输入框中输入“AmazonDMSCloudWatchLogsRole”,并从搜索结果中选中。然后点击下一步。如下截图。
在标签界面,点击下一步跳过。如下截图。
向导的最后一步,输入role的名字。这里必须使用“dms-cloudwatch-logs-role”,然后点击保存。如下截图。
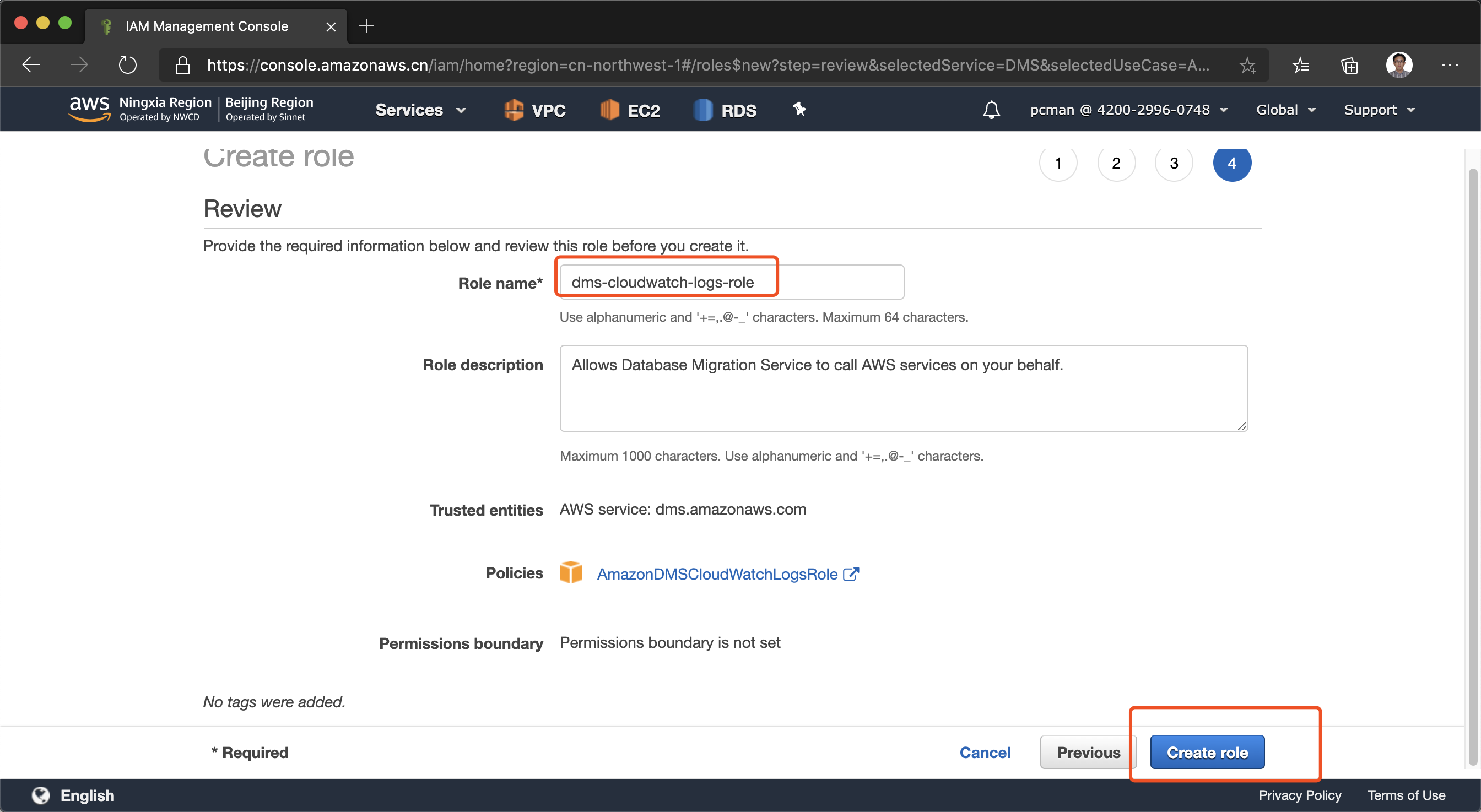
至此DMS需要的日志权限设置完成。
五、启动DMS迁移
1、对源库启用binlog支持
登录到源数据库上,编辑 /etc/my.cnf 文件,在[mysqld]的章节下加入如下的设置:
server_id=1
log-bin=/var/lib/mysql/binlog
binlog_format=ROW
expire_logs_days=1
binlog_checksum=NONE
binlog_row_image=FULL
保存退出后,重启服务。
以CentOS7为例,MySQL是Oracle官方binary的RPM安装,那么重启命令是:
systemctl restart mysql
重启完整后,登录到MySQL内,执行如下命令,确认下binlog加载成功。
show variables like 'log_%';
如果返回结果显示为log_bin的状态是ON,则表示binlog打开成功。
2、启动全量+增量迁移任务
进入DMS界面,选择“数据库迁移任务”,点击右上角新建。如下截图。
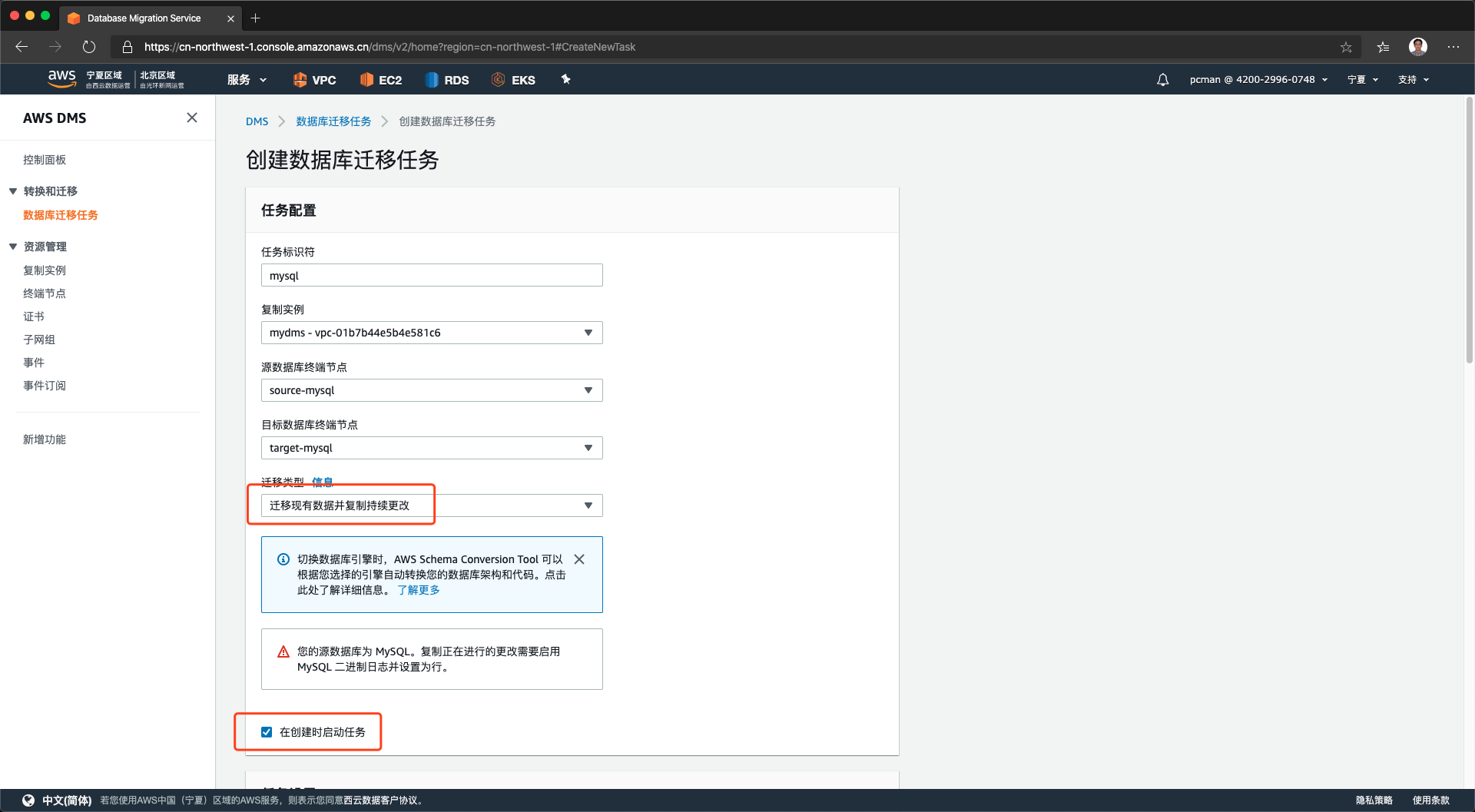
在向导界面上,输入向导名称,选择源数据库、目标数据库、迁移使用的复制实例,并选择迁移类型是“迁移现有数据并持续复制更改”。为便于对照,下图采用中文截图。
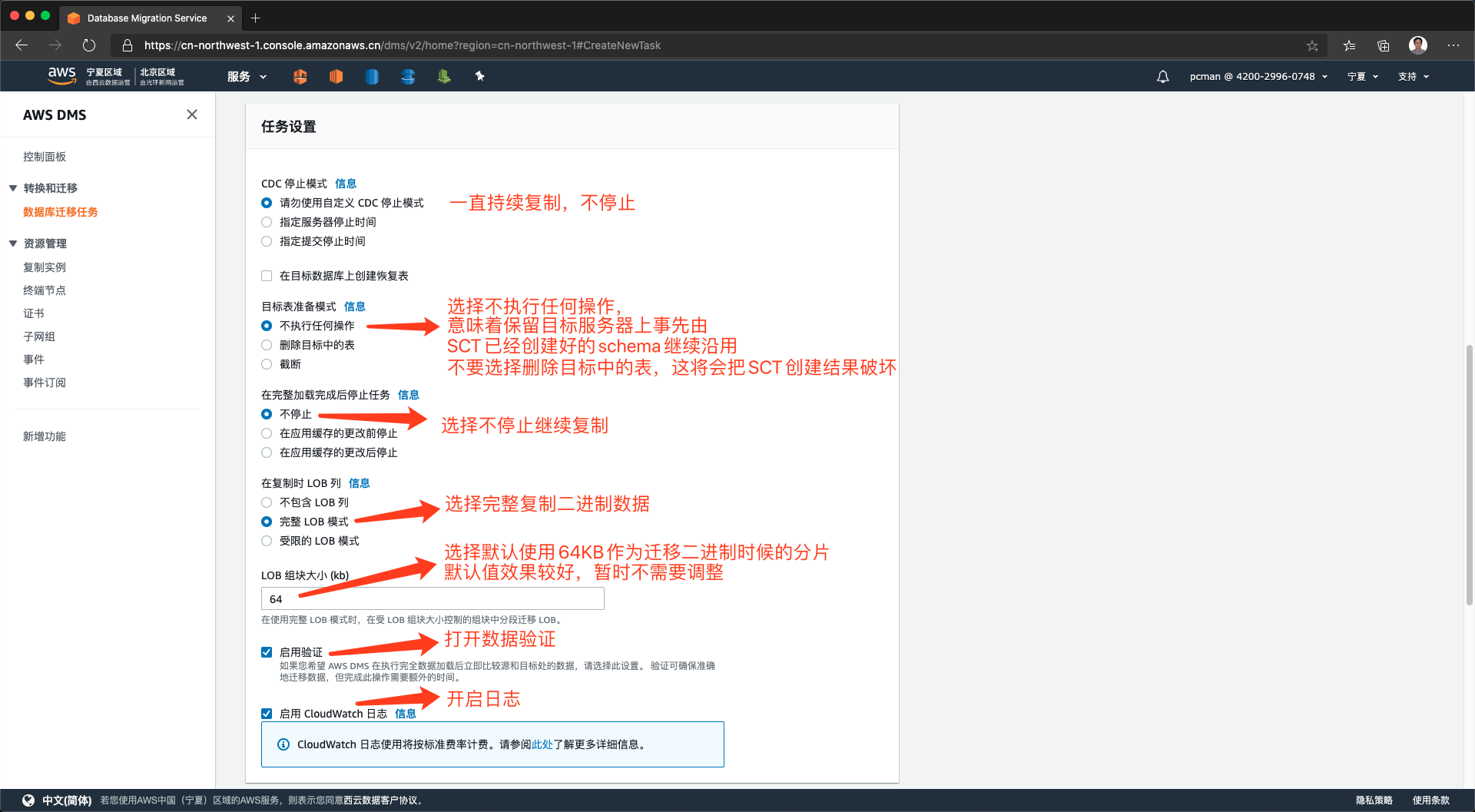
将页面向下滚动,继续配置设置。持续数据传输这里,选择不停机一致持续复制。目标表准备模式选择不执行任何操作,这样将沿用刚才SCT创建好的Schema。。在完整加载后选择不停止,继续持续复制。LOB大型二进制对象这里,选择完全复制,并将数据分片设置为64KB。再下方的选项“启用验证”和“CloudWatch日志”都选中。如下截图。
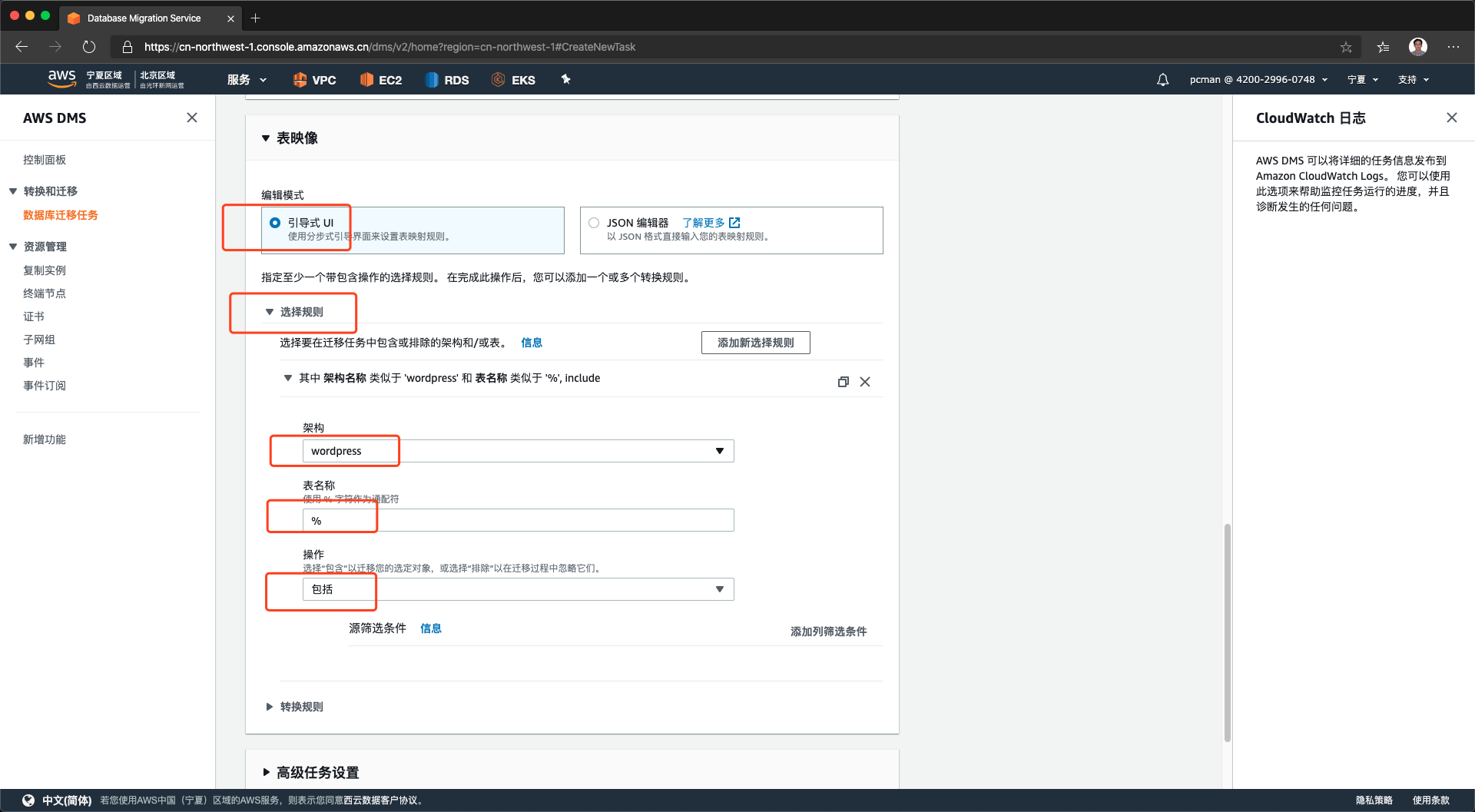
继续将页面向下滚动。在表映像部分,选择引导式UI,即向导方式。展开选择规则菜单,从架构选项下拉框中,选择出来要迁移的数据库。下方的表%表示通配符,在下方的操作“包括”是表示选中。如下截图。
将页面滚动到最下方,点击右下角的创建任务按钮。
创建完毕后,将获得一个新的迁移任务,显示正在创建,如下截图。
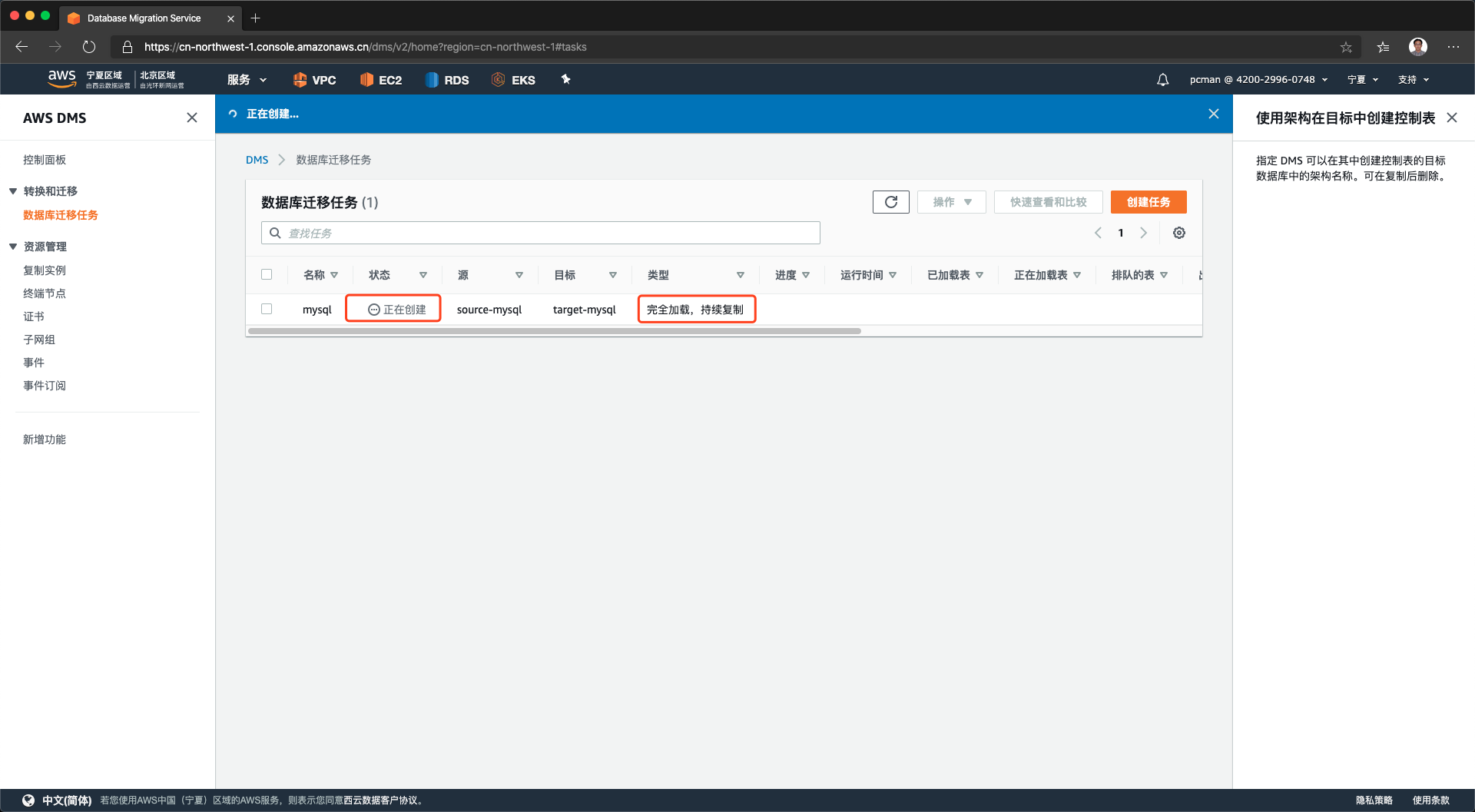
如果上述参数配置正常,创建完毕的任务将转入正在启动状态。如下截图。
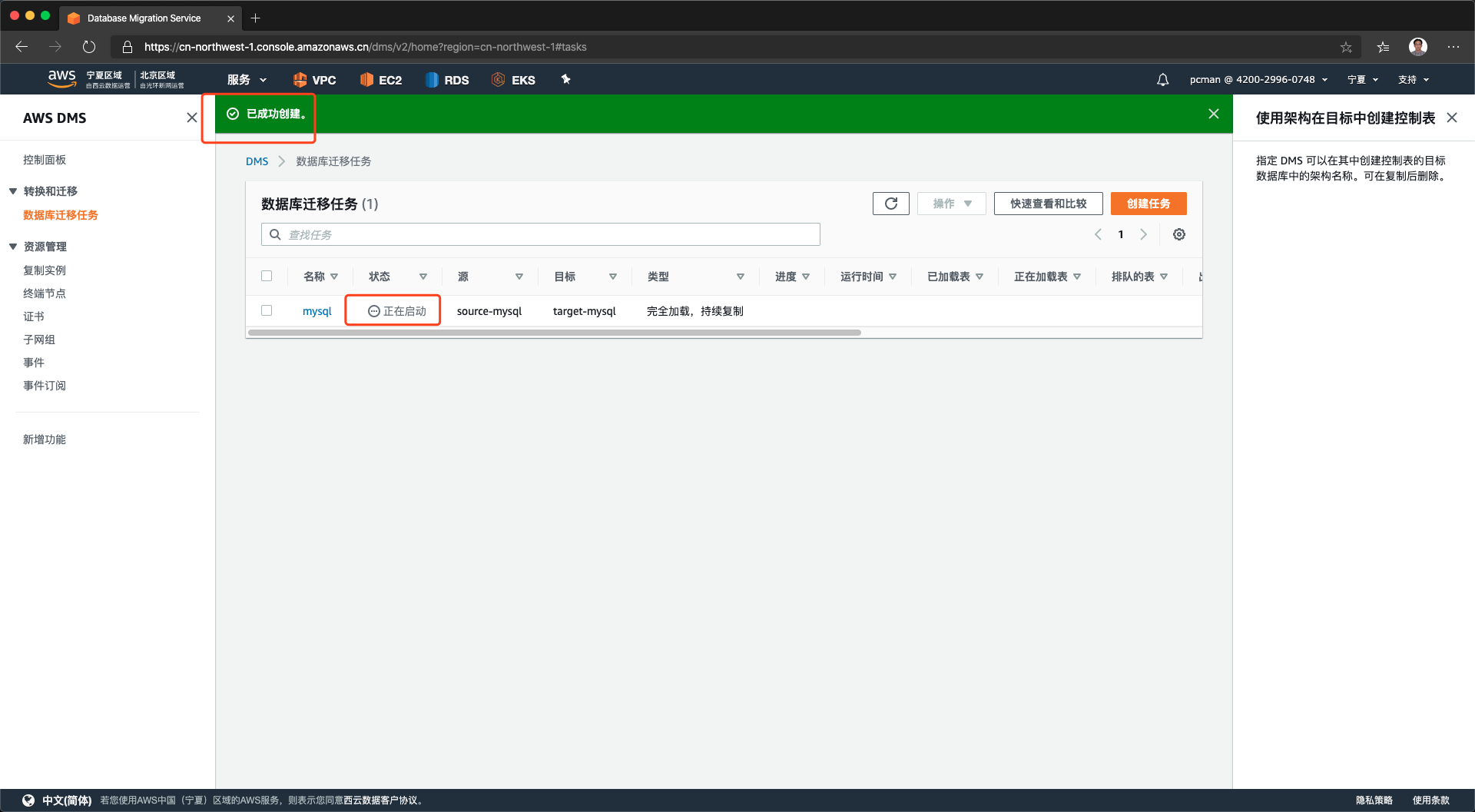
对一个状态是正在启动的库,点击名称可以查看其运行状态。
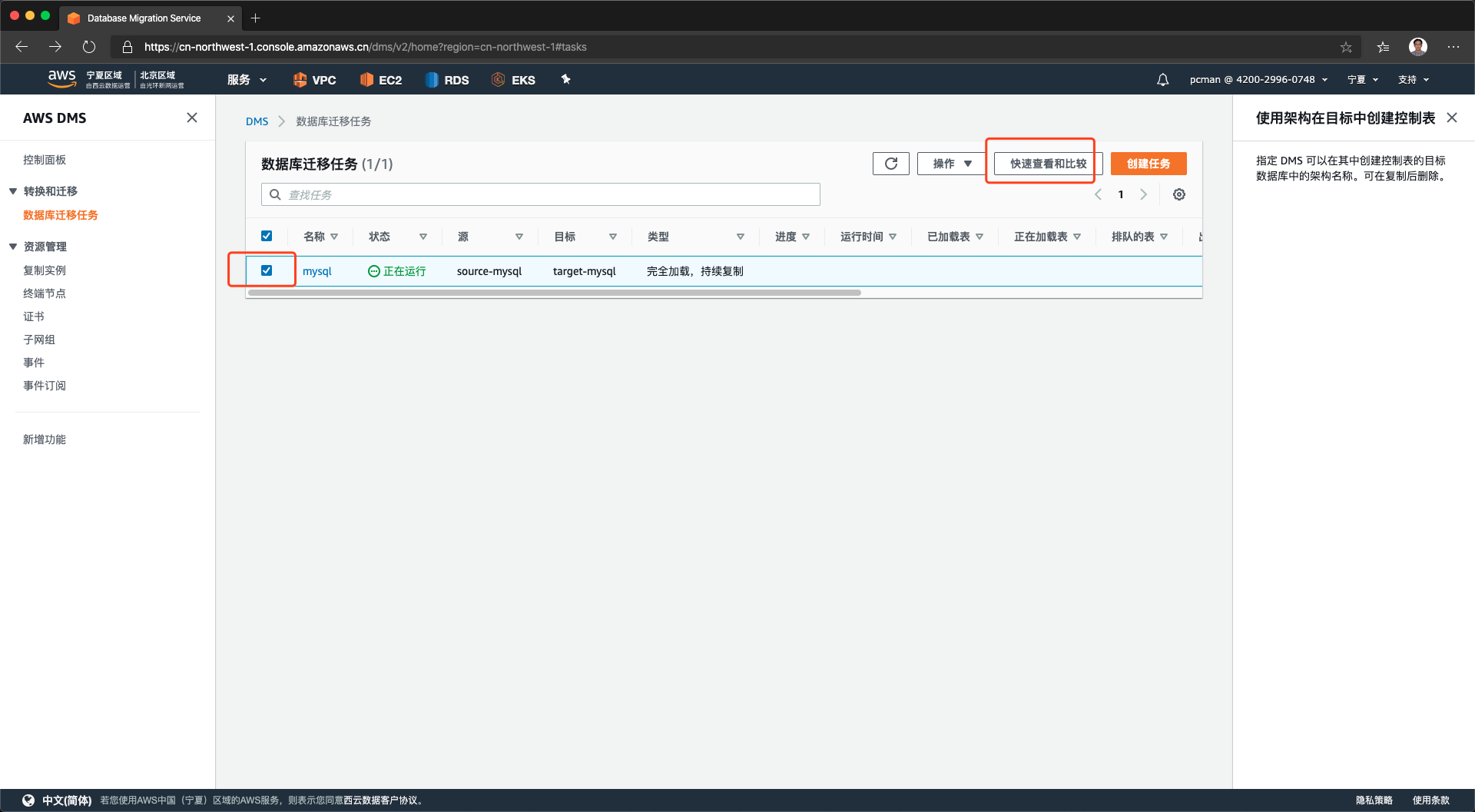
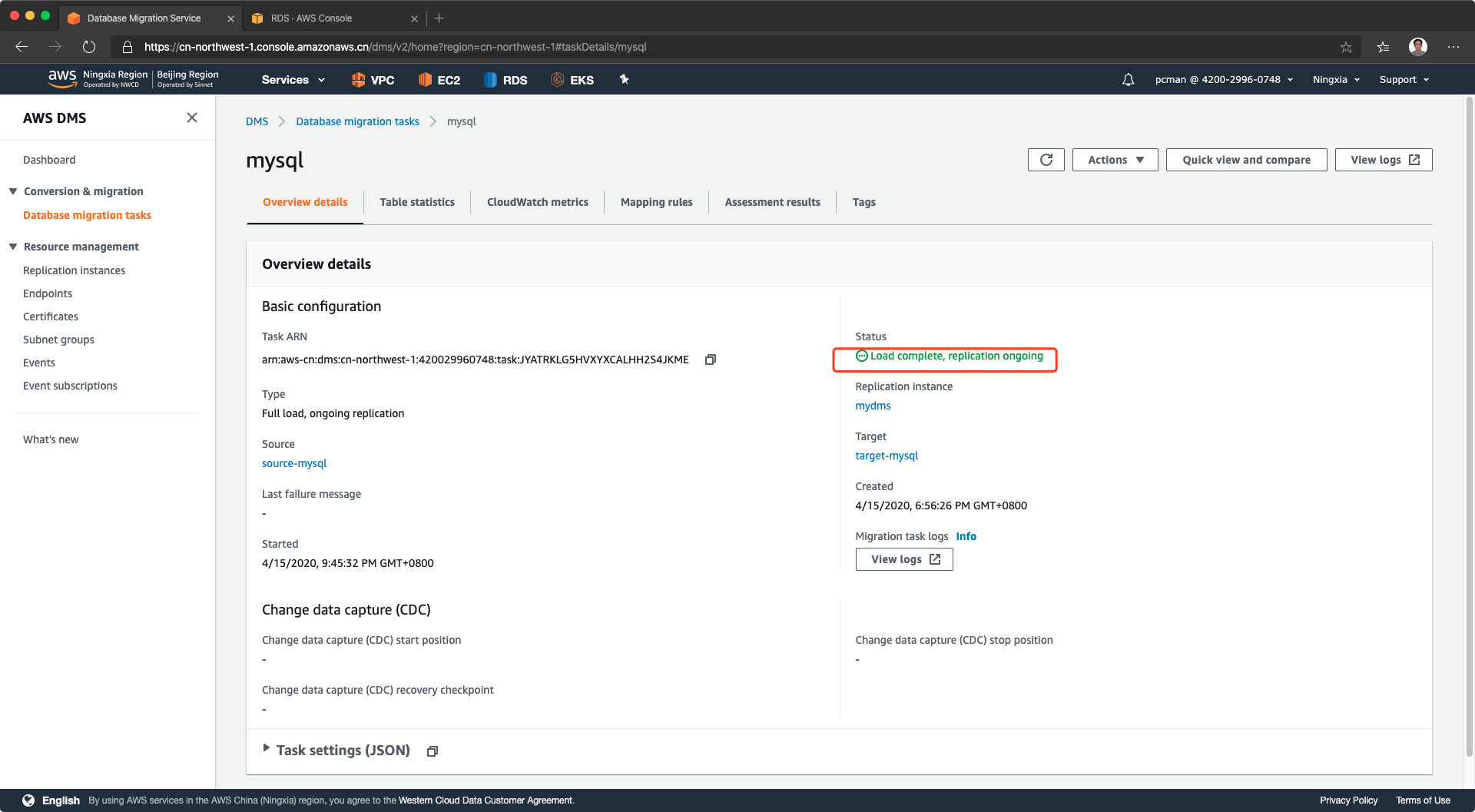
点击进入后,可以看到数据全量复制完成,正在保持增量同步状态。如下截图。
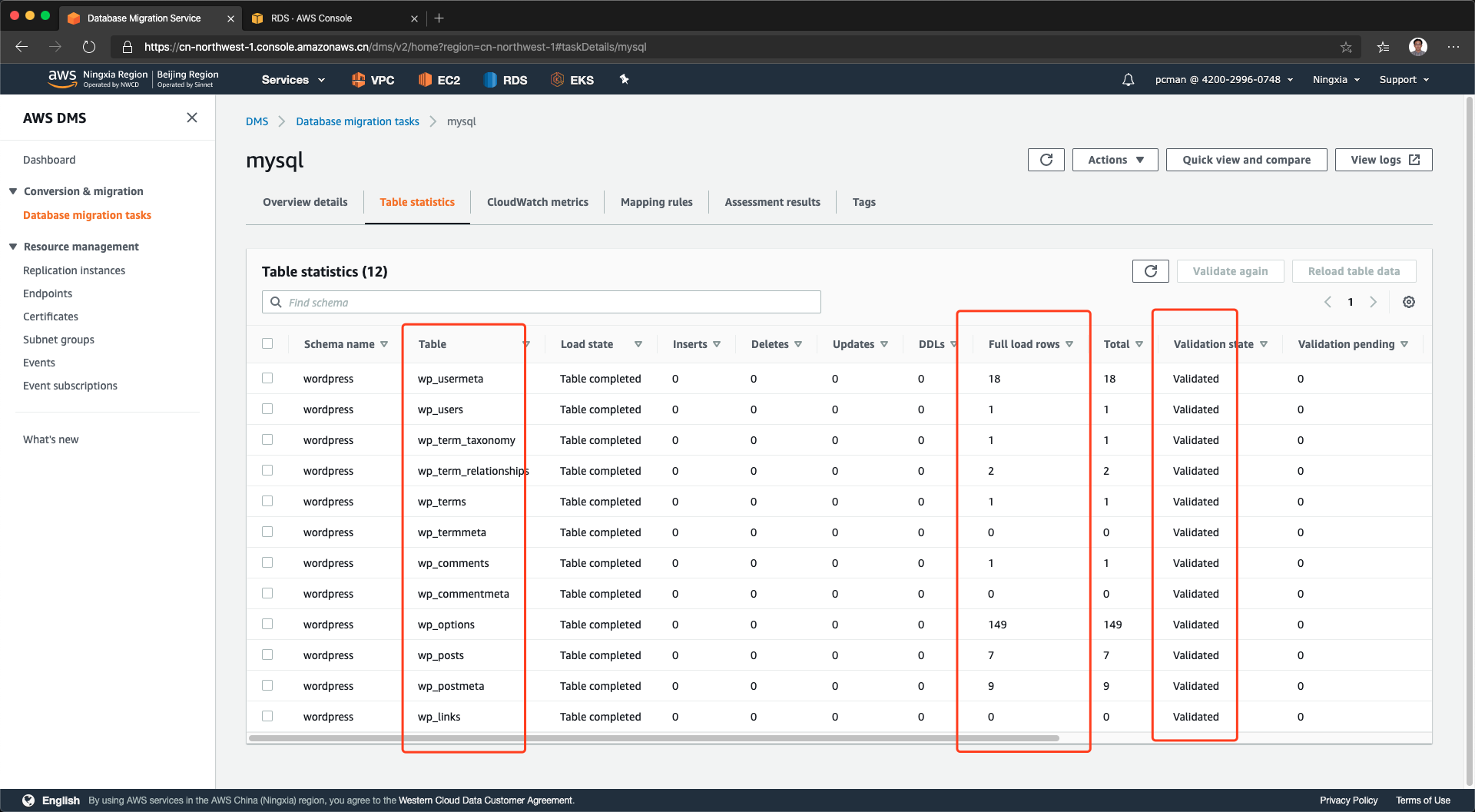
点击第二个标签页,可以看到本数据库的各表的数据量都已经完成同步。
3、测试CDC持续数据迁移
为了测试数据迁移效果,我们在云上环境部署了一个应用服务器,连接到迁移上云后的AWS上的RDS数据库。通过在云下IDC的业务系统上新增数据的办法,检查增量数据是否被同步传输过来。
首先在位于IDC的MySQL源数据库的应用程序上,写入新的条目。写入过程从应用程序的web界面发起。如下截图。
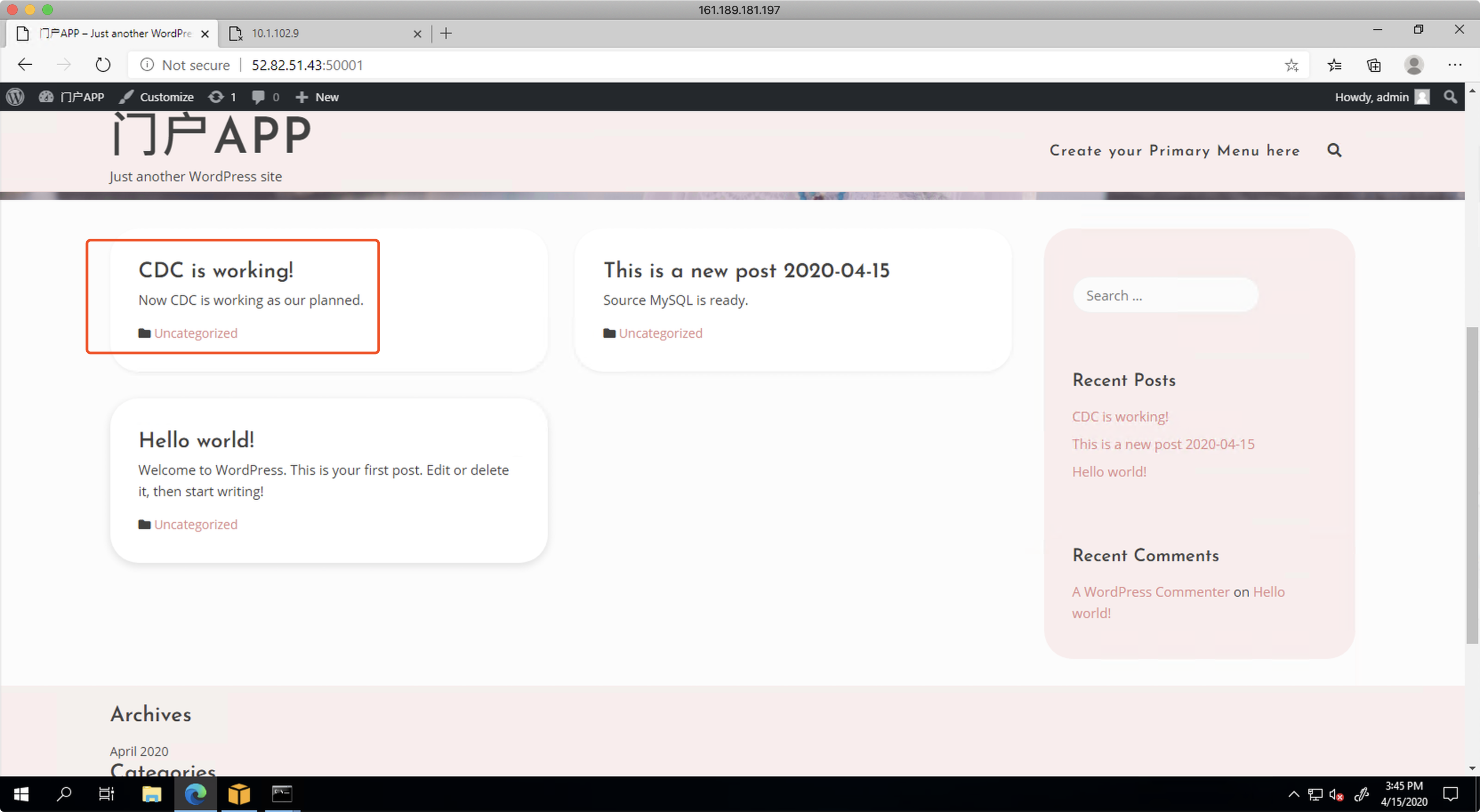
接下来,使用云上的EC2,通过SSH和MySQL客户端方式,连接到云上的RDS MySQL库,检查CDC是否将数据持续复制到位。检查后可发现数据正常写入数据库,源库和目标库内容相同。如下截图。
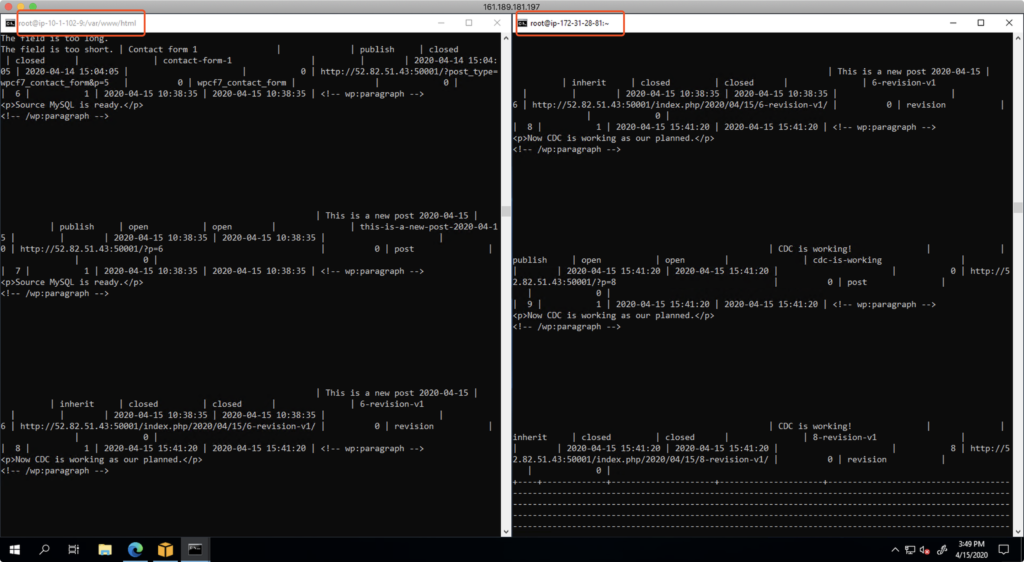
接下来返回DMS界面,点击正在进行持续数据复制的DMS任务,进入到复制状态中,各表的insert、update计数器都是已经不再是0,而是记录下来复制过来的更新后的数据了。可以将这个界面与刚完整全量复制时候的数据对比,当时尚未产生增量和技术。接下来可以进一步在源库发布新内容做更新,继续观察,可以看到计数器持续增长。表示持续数据复制正常。如下截图。
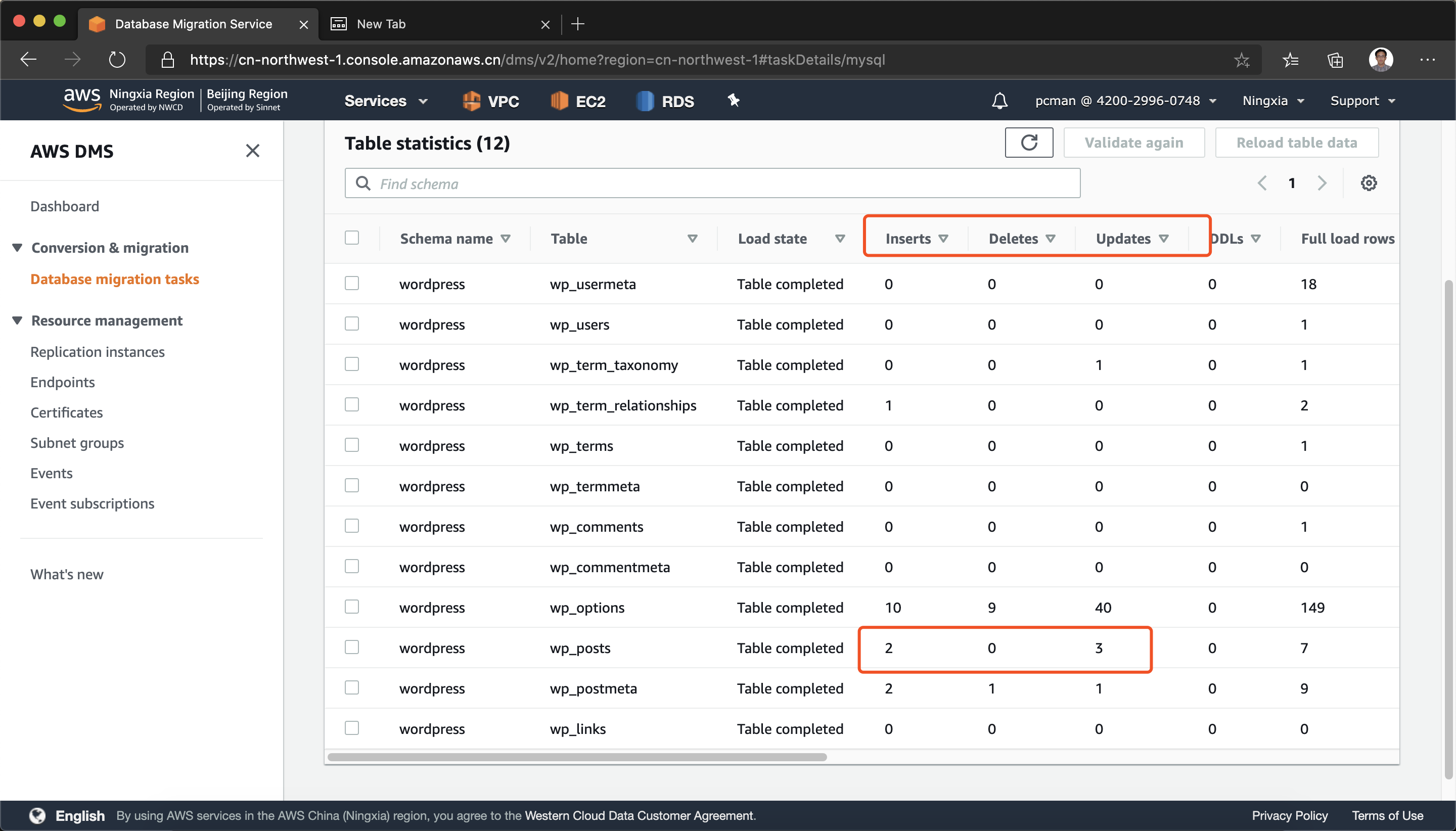
4、业务功能校验和数据一致性
在迁移完成后,需要发起业务业务测试。测试过程中需要注意的问题是数据一致性问题。
(1)DMS是单向复制不能反向同步
功能测试和数据完整性检查过程中,尽量不要对目标库发起修改操作。因为DMS是单向复制,只从源库复制到目标库。因此,对目标库的修改,不会反向同步给源库的。因此,对目标库的测试,建议首先确认功能测试,功能正常之后,关注数据完整性校验。
(2)非核心的数据表在测试中会发生数据不一致是正常情况
在校验数据完整性过程中,需要精确的确认核心数据表。这是因为当对目标库发起测试后,很多数据会跟随发生变化。举例来说,在云上平台做功能测试的时候,需要从应用层进行用户登录,测试应用对数据库的操作。此时,应用软件会向云上的目标库发生写一些操作,例如用户表的session信息、用户操作日志、最后登录时间等。这些操作虽然没有动核心数据,但依然导致云上目标库的部分表和线下IDC的源库有不一致。此时如果查看DMS的同步进度,可能对特定表格存在不一致,这是正常现象。建议关注在核心数据表格,忽略因为业务系统测试导致的新增数据变化。
(3)检查不一致的数据
在复制完成后的校验过程中,可能显示部分数据校验失败,其原因是在复制时候,源库和目标库可能发生了改变,因此造成两边不同步。这种现象对于又不断写入的生产库时候比较常见,或者是对目标库做大量功能测试的时候也会导致目标库数据变化发生不一致。
检查不一致的方法是,连接到目标库RDS,找到数据库awsdms_control,显示其中的表awsdms_validation_failures_v1,即可显示出来不一致的数据。如下查询结果。
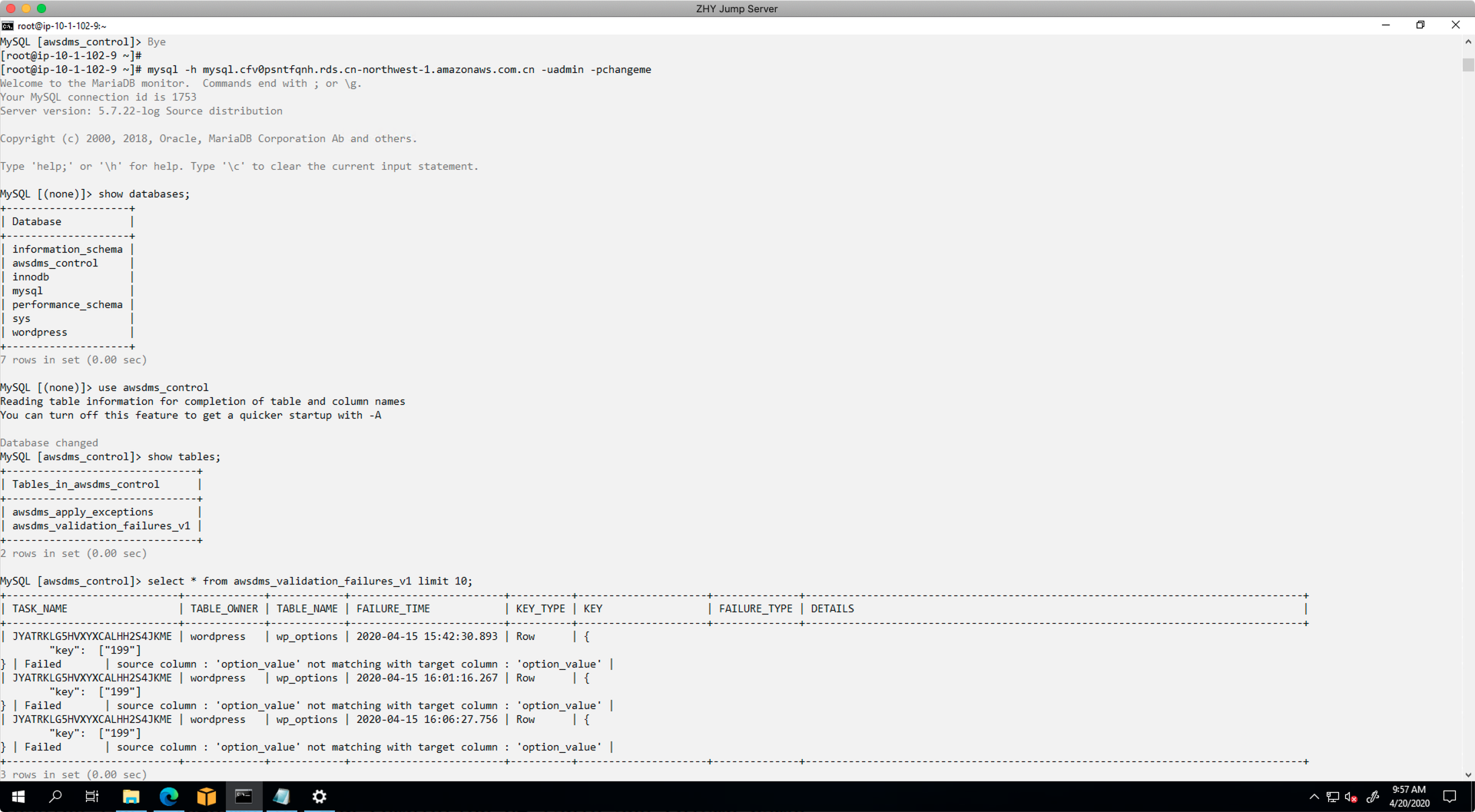
由此,可以通过人工方式,调查对应字段,确认不匹配的原因是否是生产库数据正常变更、还是对目标库功能测试导致数据变化等问题。
此外,还可以通过编程方式用代码批量获取和查询不一致的数据。
5、迁移完成切换入口
数据校验完整,则可以切换流量入口,并停止迁移复制任务。
至此整个DMS操作完成。
六、附录 - 手工修正
前文提到的SCT可以自动迁移数据库Schema,将SCT和DMS配合使用可以最小化迁移工作量。如果,一开始没有使用SCT迁移Schema,那么就需要通过如下步骤检查源数据库和目标库的差异,并且人为修正。
1、检查并添加自增字段
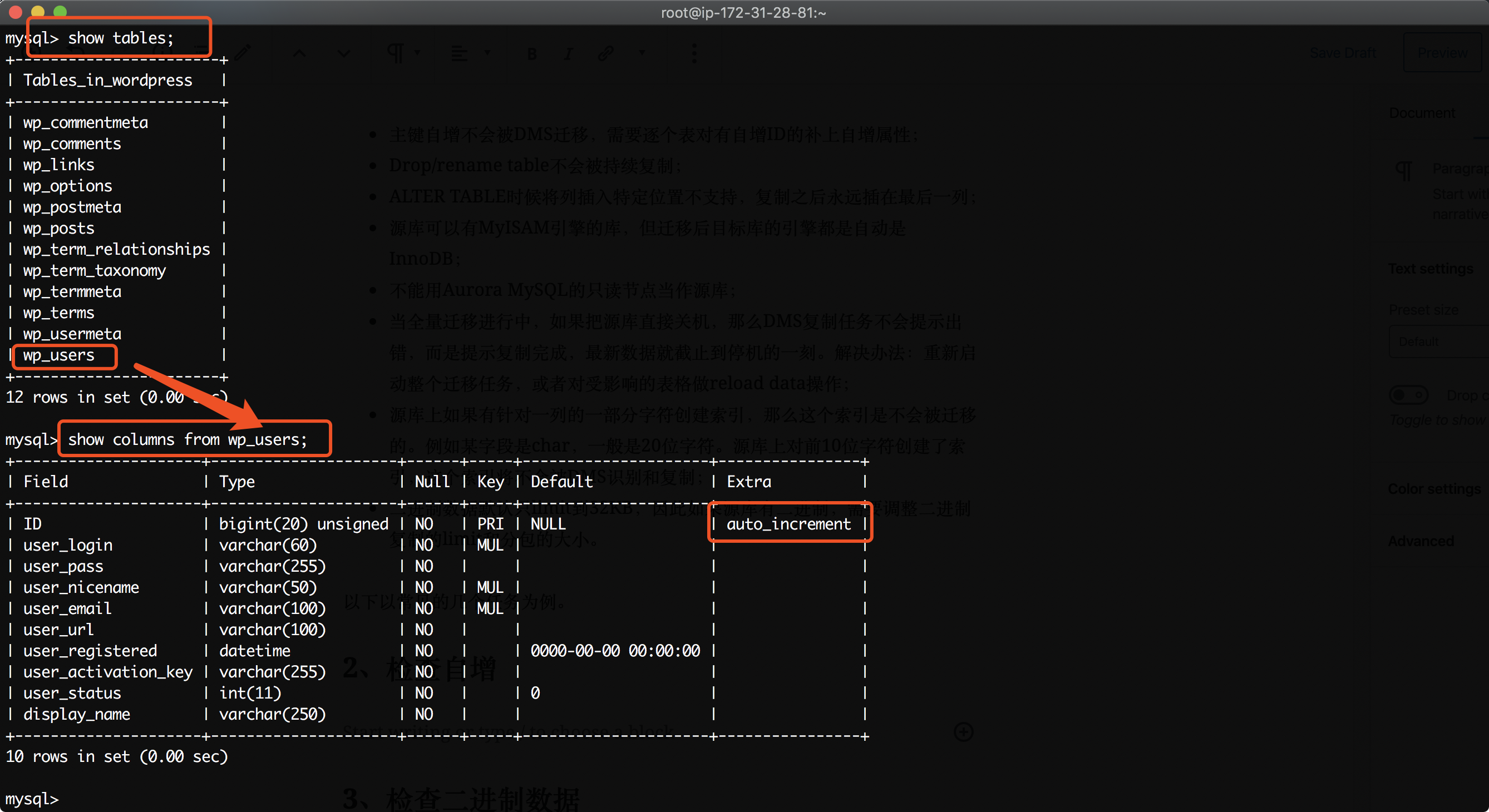
由于DMS迁移时候不会复制自增属性,因此需要人工检查所有表,并认为添加自增。登录到源库,以wordpress数据库为例,执行如下命令。
use wordpress;
show tables;
show columns from wp_users;
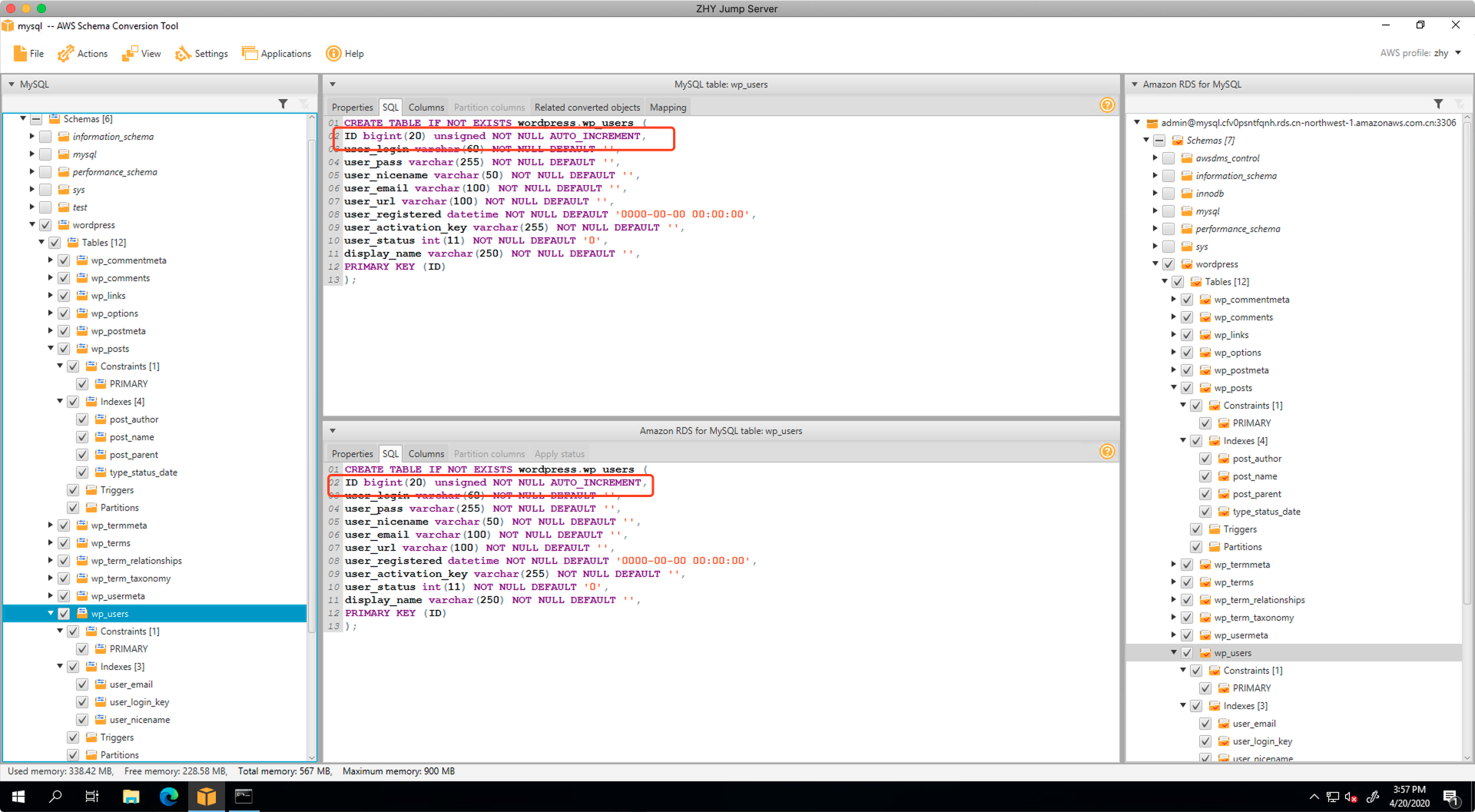
从查询结果中可以看到,ID是自增的。如下截图。
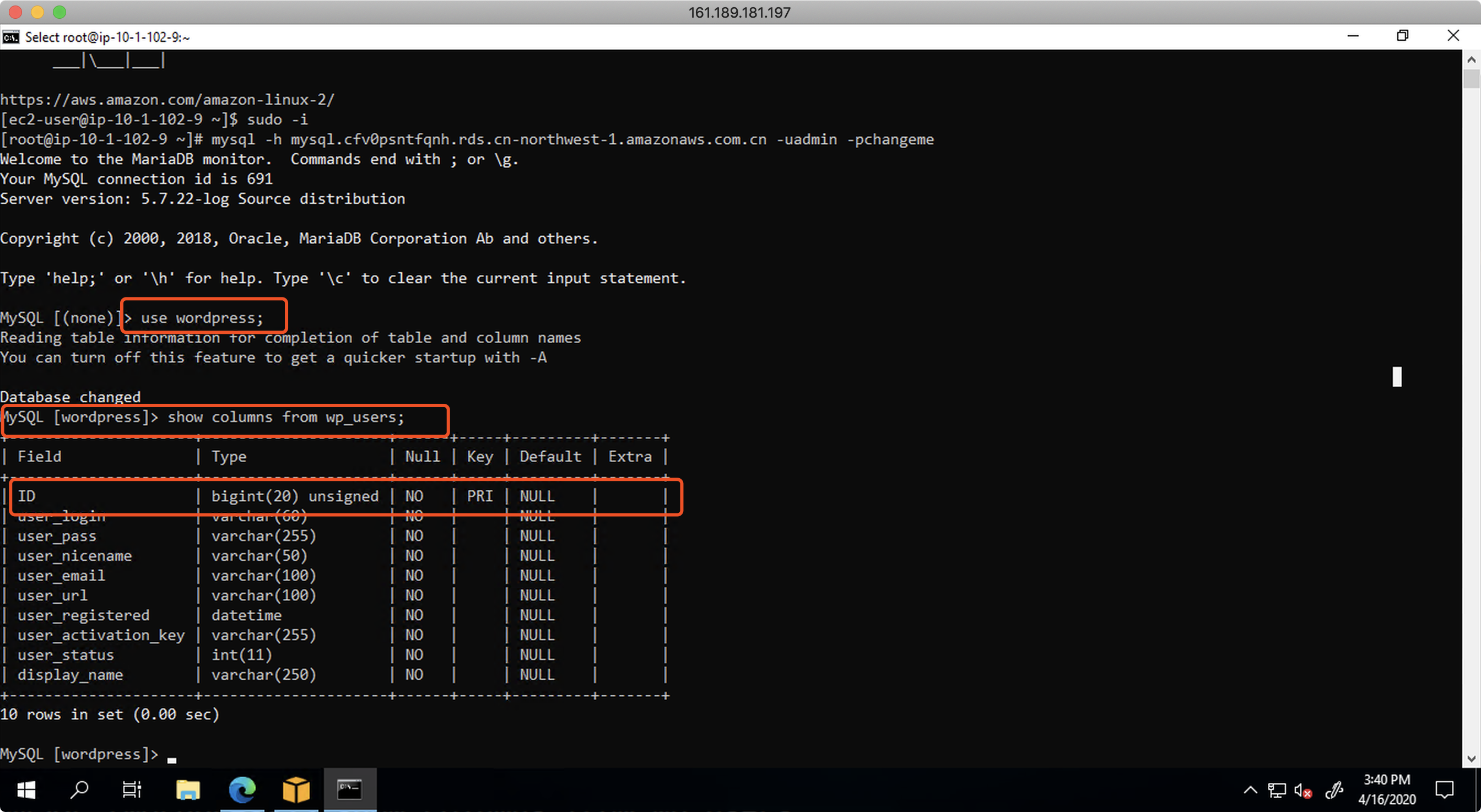
现在连接到目标库。执行相同的查询命令。可以发现ID列不具备自增属性。如下截图。
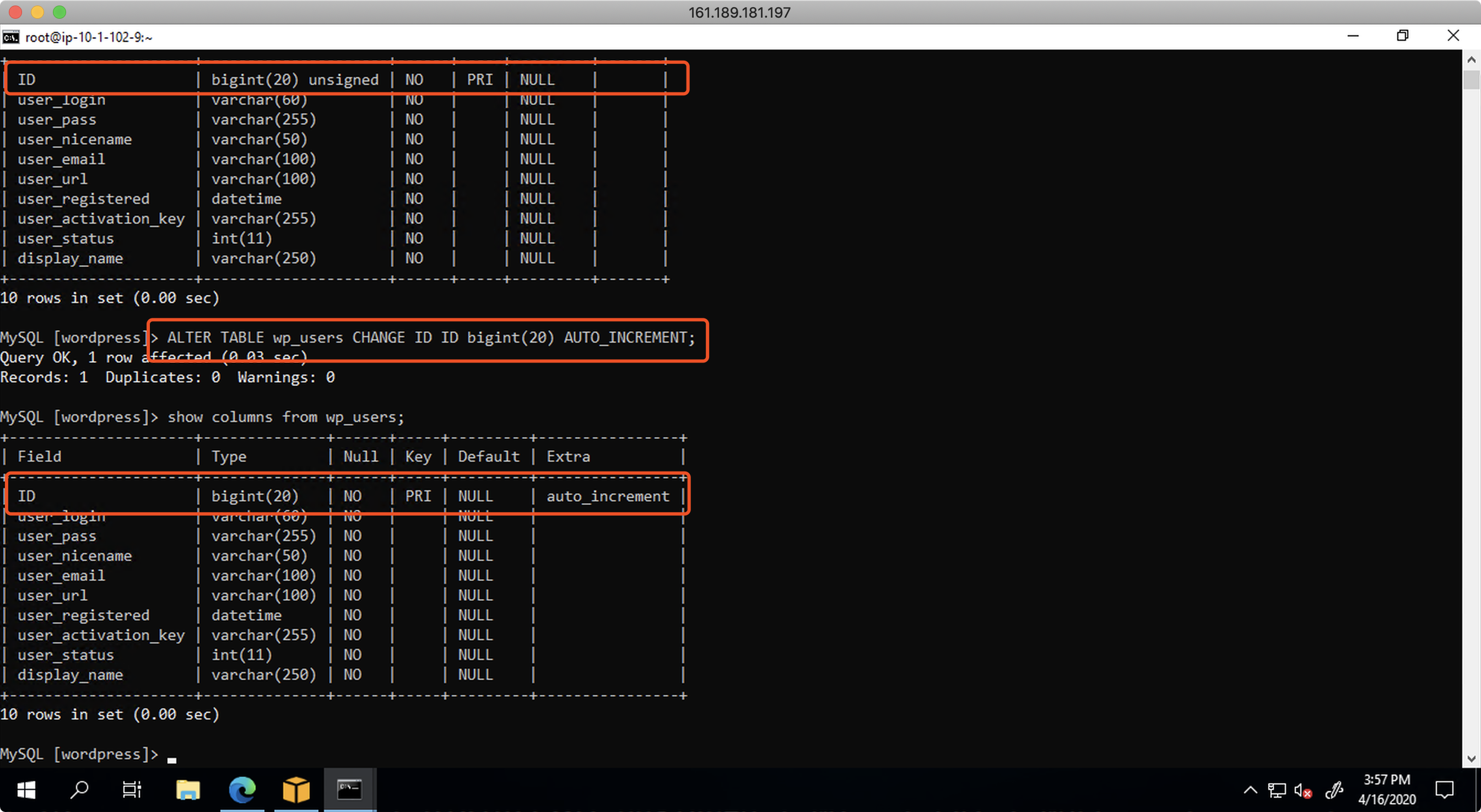
连接到目标库,在目标库上执行如下命令,增加自增ID。
ALTER TABLE wp_users CHANGE ID ID bigint(20) AUTO_INCREMENT;
执行后再次查询,可以发现目标库已经增加了自增属性了。如下截图。
至此对一个表增加自增完成。
接下来,需要逐个表检查,凡是源库上具有自增属性的,都要在目标库上手工补充。
2、检查二进制数据
某些应用系统,会将用户上传的文件例如图片直接以二进制的形式存在表中。这时候,会对迁移的性能造成较大影响。创建DMS任务的时候,需要人工设置LOB,即Large Object的限制,默认只对32KB以下的二进制进行迁移。
由此,我们需要排查源库的各表格,是否使用了二进制类型存放数据。排查方法还是显示各表格的所有列,检查类型是否包含二进制。命令如下。
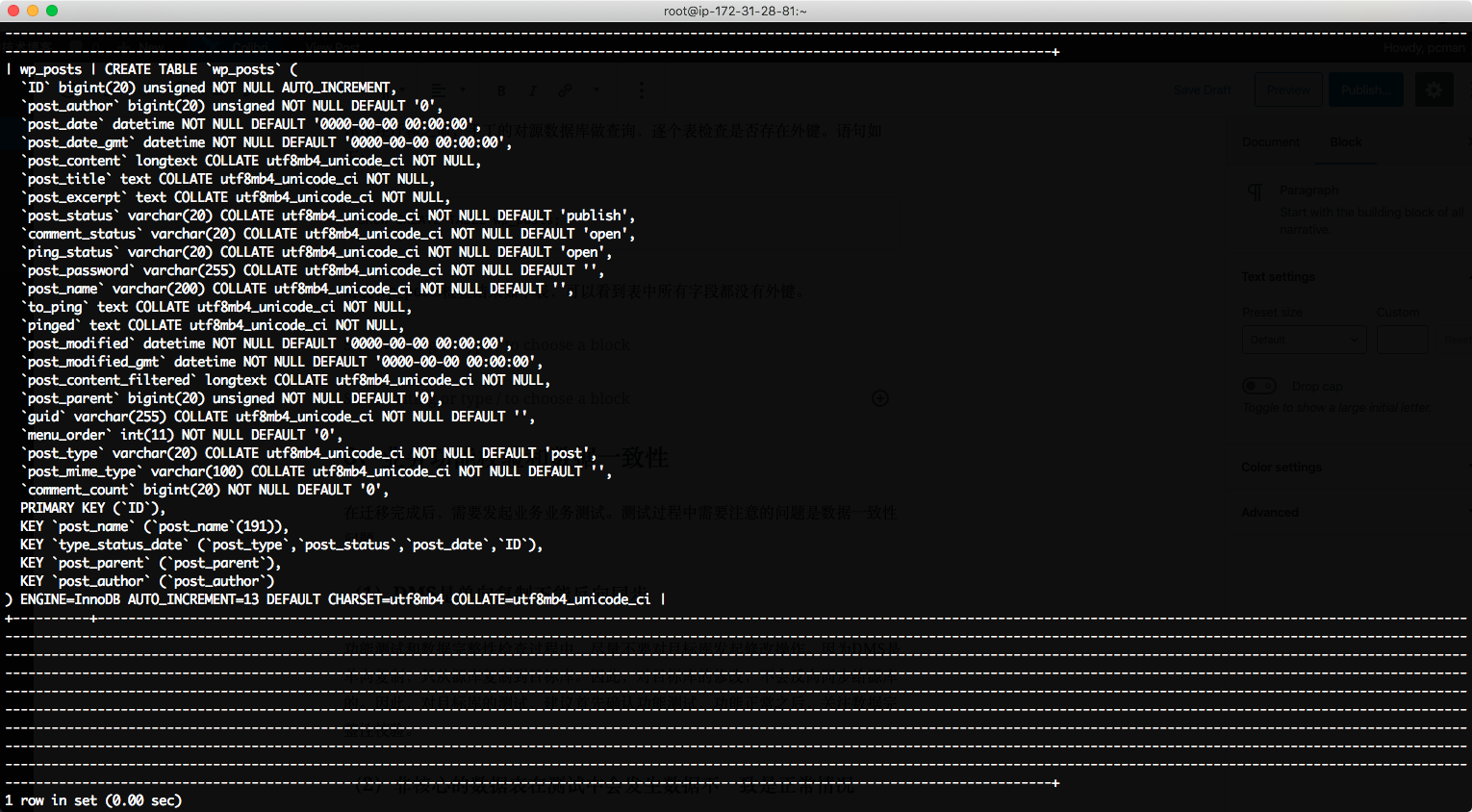
show columns from wp_posts;
检查结果如下。
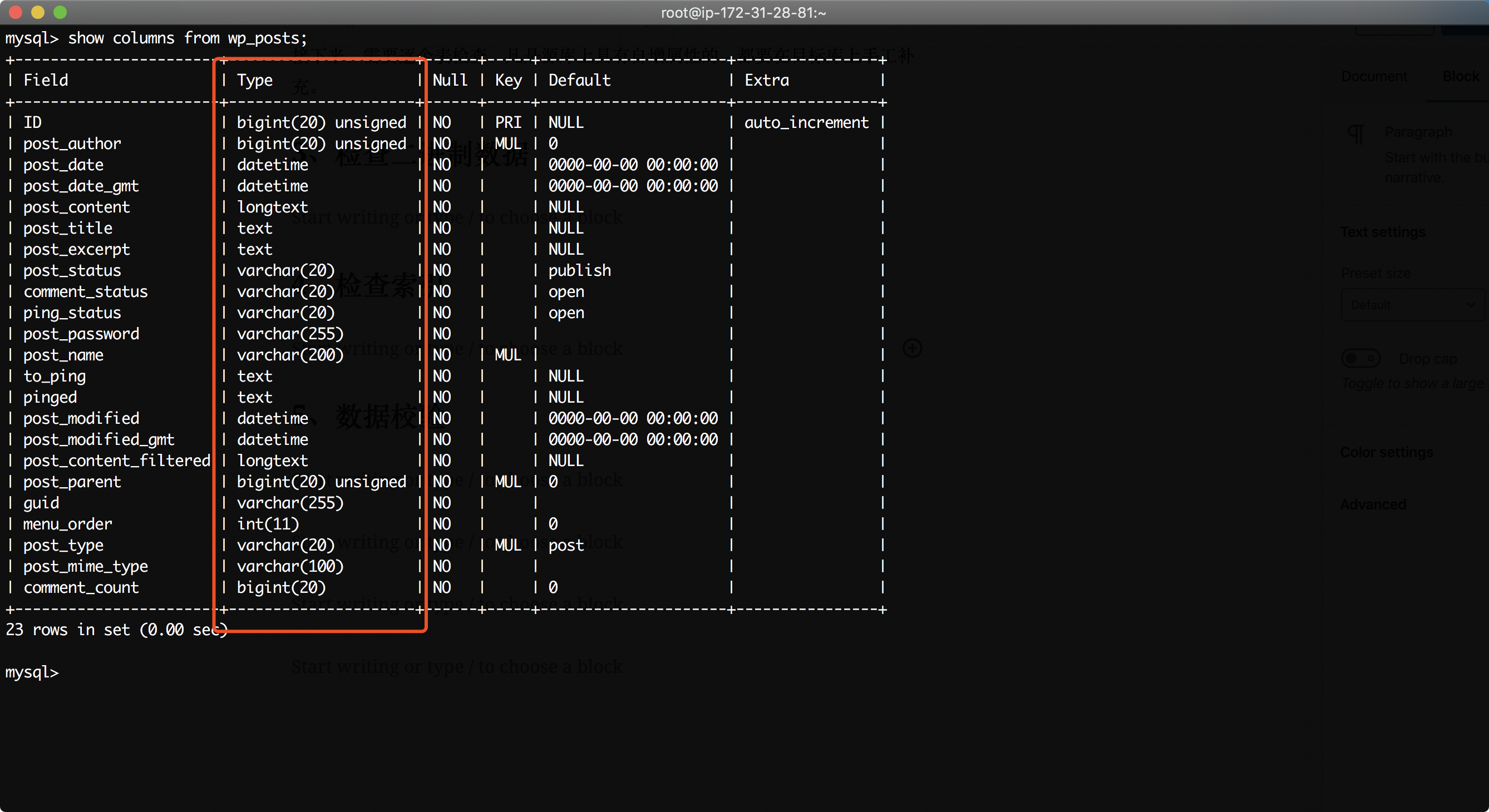
经过检查,在本表中,没有二进制类型。
由此,需要对源库中所有表逐一检查排除。
3、检查索引
DMS在迁移的时候,只会迁移一部分索引,因此需要逐个表检查索引,缺少的索引,需要手工创建补充。以本文编写的wordpress为例,对wp_users表显示索引,可以看到如下条目。源库的查询结果如下截图。
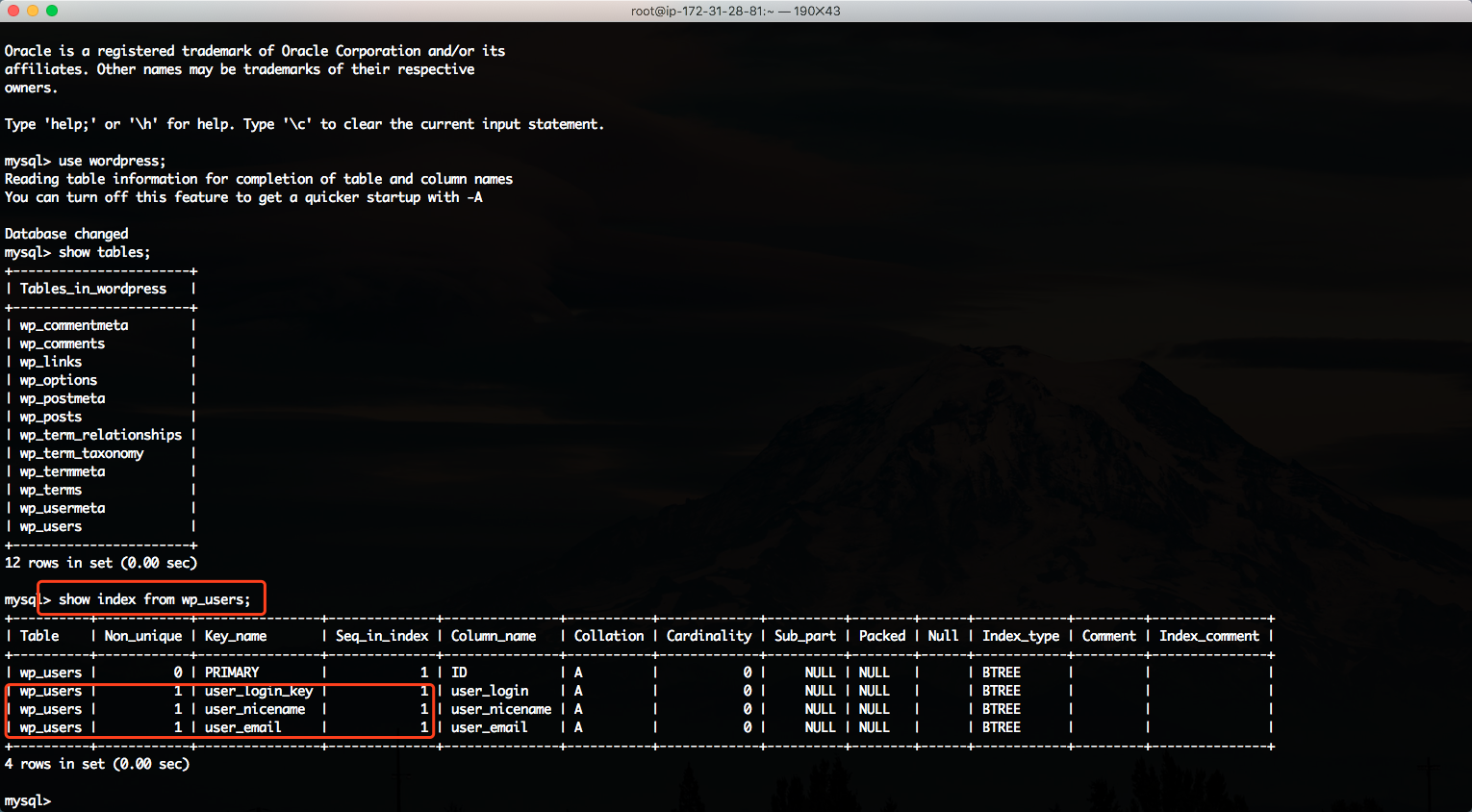
现在登录到目标库,在DMS启用CDC持续复制迁移任务,且持续复制一致处于运行状态的情况下,可以查询到wp_user表只有ID字段的一条索引。如下截图。
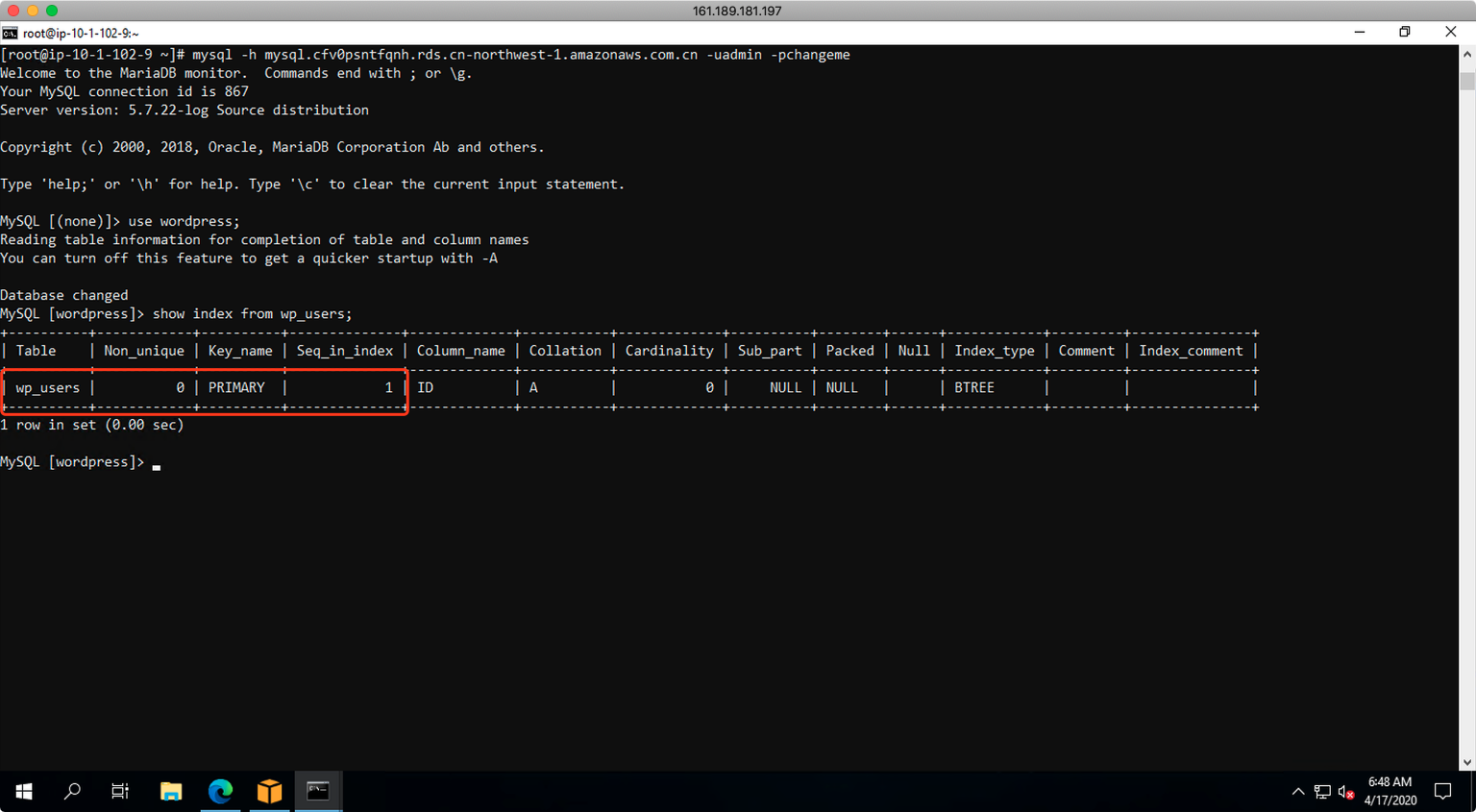
在本例中,增加确实的索引的步骤如下。
CREATE INDEX user_login_key ON wp_users (user_login);
CREATE INDEX user_nicename ON wp_users (user_nicename);
CREATE INDEX user_email ON wp_users (user_email);
添加索引完成后,查询目标库,可以看到索引和源库是一致的。如下截图。
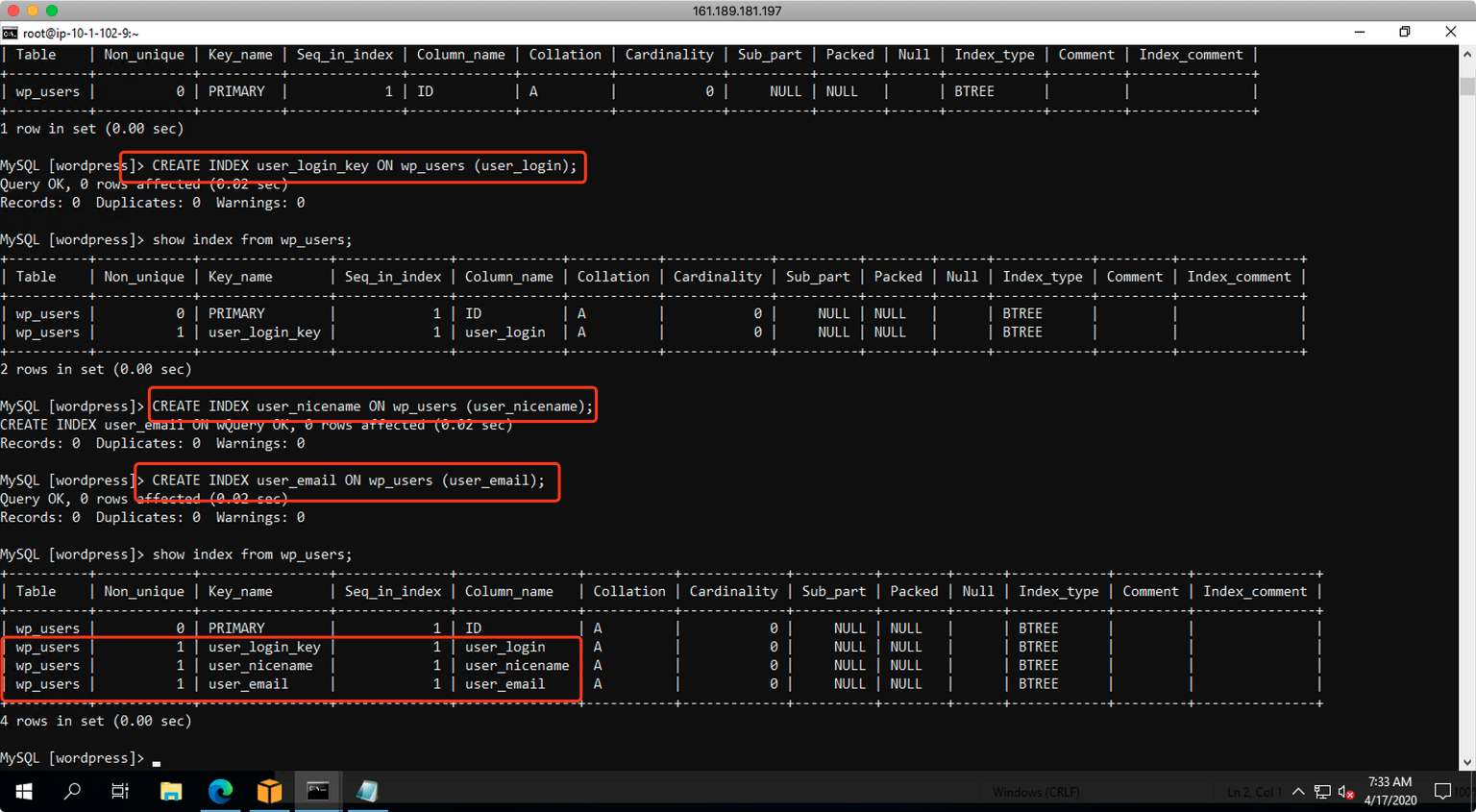
至此索引补充完成。
4、查询存储过程和函数
在源库上执行如下命令,查询所有存储过程和函数清单。
select name from mysql.proc where `type` = 'PROCEDURE';
select name from mysql.proc where `type` = 'FUNCTION';
例如查询结果如下截图:
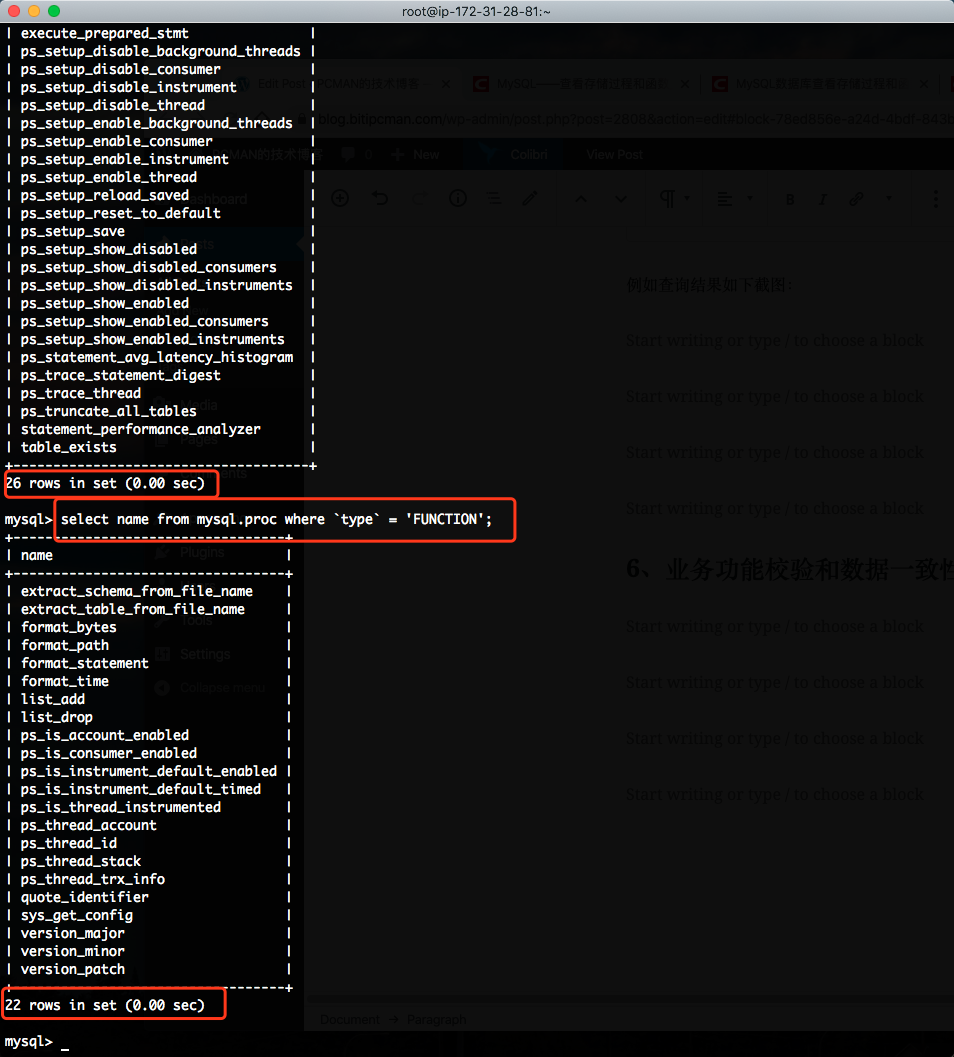
从以上查询结果中,可以看到所有的存储过程和函数都是系统内置的,用户应用程序并未创建自己的存储过程。由此不需要额外手工建立存储过程了。
请注意:AWS云上的RDS服务,自身有一系列专有的存储过程,以RDS名字开头。这一部分不是业务代码建立的存储过程,而是云上系统本身就自带的,这是正常的。检查存储过程,应与应用开发团队进行确认。
5、查询视图
登录到源库,执行如下命令检查视图。
show table status where comment='view';
如果没有逻辑视图,返回结果为0。
或者也可以通过查询所有表,然后检查commnet字段是否有视图标识来标注是否是视图。
show table status;
检查后如果没有视图,则迁移中不需要额外手工操作。
6、查询外键
外键是表之间的约束, DMS不会自动迁移外键,因此需要手工配置。
建议在迁移之前,手工的对源数据库做查询,逐个表检查是否存在外键。语句如下:
SHOW CREATE TABLE wp_posts;
对表wp_posts检查结果如下表,可以看到表中所有字段都没有查询到constraint外键的关键字,因此检查结果是没有外键。
全文完。
最后修改于 2020-04-17