在Bedrock上以导入自定义模型的方式部署DeepSeek R1模型蒸馏的Llama70b模型
详细讲解如何在AWS Bedrock上通过Custom Model Import功能部署DeepSeek R1蒸馏的Llama 70B模型,解决生产环境高可靠性和并发需求,包含模型下载、S3上传、导入配置、冷启动处理和费用分析。
注:由于Amazon Bedrock服务已经提供了完全托管的Serverless Bedrock模型,因此您无须再通过导入模型的方式运行DeepSeek R1模型了。如果您希望了解导入自定义模型的操作过程和方式,那么您可以继续阅读本篇。
本文基于亚马逊云开发者微信公众号这篇文章的内容编写,对相关服务增加了介绍,操作过程做了截图,并汇总了冷启动、费用等问题。有疑问请参考原文。
一、背景
在前一篇博客中介绍了使用Ollama在MacOS本机或者EC2 G系列实例上快速启动DeepSeek R1蒸馏后的1.5b模型/32b(均基于Qwen蒸馏而来)。在生产环境中,单机部署只能解决时效性要求不高的批量离线推理,对于在线的实时推理场景,单机部署是不能满足高可靠要求和并发要求的,一但单机遇到故障,整个应用就无法访问了。因此此时就需要在Bedrock上托管的方式部署。
Bedrock支持自定义模型导入功能。截至2025年1月Bedrock导入自定义模型仅支持Llama架构、不支持Qwen架构,因此导入DeepSeek R1模型蒸馏的一组模型时候,无法选择基于Qwen架构的32B参数的版本。可用的将是8B和70B参数的版本(基于Llama)。本文选择70B参数的版本,通过Custom Model Import功能在Bedrock上部署。
注:2025年11月更新:Bedrock Import Model功能已经支持Qwen2, Qwen2.5, Qwen2-VL, Qwen2.5-VL系列模型的导入。后续Qwen3版本的支持情况,以Bedrock官方文档为准。
二、下载模型文件到S3存储桶
注意:请确认下载的DeepSeek R1蒸馏的模型架构正确,截至2025年1月Bedrock仅支持Llama等架构的模型的导入,不支持Qwen架构的导入。如果下载了DeepSeek R1蒸馏的Qwen-7b模型,那么在发起导入任务之后,将会提示错误:Amazon bedrock does not support the architecture (qwen2) of the modelthat you are importing. Try again with one of the following supported architectures: [llama, mistral, t5, mixtral, gpt_bigcode, mllama, poolside]。
1、在海外区域创建用于下载模型文件EC2
下载文件可以在任意环境包括开发者本机、云上虚拟机、或者SageMaker Notebook中完成,如果之前有下载好的模型文件保存在别的AWS账号的存储桶内,也可以复制过来使用。如果之前未曾下载过,那么第一次获取模型文件需要从HuggingFace下载。
由于国内一些地区可能无法正常访问HuggingFace,或者可以访问但是网速很慢,无法满足几十GB的稳定下载需求,因此这里推荐在海外云端创建一个EC2用于下载模型文件。您也可以用SageMaker Notebook来完成,此时您需要注意Notebook的磁盘空间是否足够,或者在Notebook上挂载容量无限的EFS存储来存放模型文件。如果您在使用SageMaker Studio,那么其已经是自动挂载EFS了,无需担心磁盘空间不足。
本文以us-west-2俄勒冈区域为例,创建一个EC2,机型是t3.medium,规格为2vCPU/4GB,操作系统选择为Amazon Linux 2023最新版。磁盘选择为200GB的gp3规格,为了上传下载更快,可以将本机的EBS磁盘配置的吞吐从默认的125MB/s上调到1000MB/s。另外确认本机有外网访问权限。
创建完毕后,在本EC2上安装软件包。
yum install python3-pip -y
pip install huggingface_hub boto3
安装完成后,编写download.py文件,内容如下:
from huggingface_hub import snapshot_download
model_id = "deepseek-ai/DeepSeek-R1-Distill-Llama-70B"
local_dir = snapshot_download(repo_id=model_id, local_dir ="DeepSeek-R1-Distill-Llama-70B")
将上述文件保存为写download.py,然后执行python3 download.py即可下载模型。下载进行中。
LICENSE: 100%|████████████████████████████████████████████████████████████████████████████████| 1.06k/1.06k [00:00<00:00, 45.3kB/s]
README.md: 100%|███████████████████████████████████████████████████████████████████████████████| 19.0k/19.0k [00:00<00:00, 728kB/s]
config.json: 100%|████████████████████████████████████████████████████████████████████████████████| 879/879 [00:00<00:00, 47.8kB/s]
.gitattributes: 100%|█████████████████████████████████████████████████████████████████████████| 1.52k/1.52k [00:00<00:00, 33.4kB/s]
generation_config.json: 100%|█████████████████████████████████████████████████████████████████████| 181/181 [00:00<00:00, 13.9kB/s]
figures/benchmark.jpg: 100%|████████████████████████████████████████████████████████████████████| 777k/777k [00:00<00:00, 6.08MB/s]
Fetching 26 files: 4%|██▉ | 1/26 [00:00<00:12, 2.06it/s]
model-00004-of-000017.safetensors: 7%|███▋ | 577M/8.69G [00:15<04:10, 32.4MB/s]
model-00006-of-000017.safetensors: 7%|███▌ | 566M/8.69G [00:15<04:19, 31.4MB/s]
model-00002-of-000017.safetensors: 7%|███▊ | 608M/8.69G [00:15<04:09, 32.4MB/s]
model-00001-of-000017.safetensors: 7%|███▋ | 598M/8.95G [00:15<04:24, 31.6MB/s]
model-00008-of-000017.safetensors: 7%|███▋ | 587M/8.69G [00:15<04:04, 33.2MB/s]
model-00003-of-000017.safetensors: 38%|████████████████████▊ | 598M/1.58G [00:15<00:30, 31.7MB/s]
model-00007-of-000017.safetensors: 7%|███▋ | 566M/8.42G [00:15<03:52, 33.8MB/s]
model-00005-of-000017.safetensors: 7%|███▋ | 566M/8.42G [00:15<04:04, 32.2MB/s]
下载完毕后,本机将获得一系列文件,基于Llama蒸馏的70b参数的模型,文件体积大约132GB。
2、创建S3存储桶并上传
新创建一个S3存储桶,名称可取名为bedrock-custom-model-import-123456789012,后边的12位数字是自己的AWS账号,或者其他名称以进行区分。创建时候存储桶类型选择General purpose通用型即可,区域一定要与EC2区域对应,例如都在us-west-2俄勒冈区域。其他选项都保持默认值,本存储桶不需要对外公开访问。
创建存储桶完毕后,需要上传如下一组文件:
- 模型配置文件:config.json
- Tokenizer文件:一共有三个:tokenizer.json、tokenizer_config.json和 tokenizer.mode
- 模型权重文件:Model weights files in 上一步下载的体积巨大的、扩展名是
.safetensors的一系列文件
这些文件都在上一个步骤下载的目录中,不需要在额外补充了。
接下来来准备一个上传文件名为upload.py,内容如下:
import boto3
import os
s3_client = boto3.client('s3', region_name='us-west-2')
bucket_name = 'bedrock-custom-model-import-123456789012'
local_directory = 'DeepSeek-R1-Distill-Llama-70B'
for root, dirs, files in os.walk(local_directory):
for file in files:
local_path = os.path.join(root, file)
s3_key = os.path.relpath(local_path, local_directory)
s3_client.upload_file(local_path, bucket_name, s3_key)
将以上文件的存储桶名替换为实际的桶的名字,Region替换为实际的Region,并确保上一步下载的目录正确。接下来还需要确认本EC2有向S3上传文件的权限。可以采用的方式是1)在本机配置AWSCLI的密钥,2)在本机不设置密钥但是为EC2设置IAM Role,在IAM Role中附加允许写入S3的权限。
配置完毕后,执行python3 upload.py即可上传。70B模型总计大约132GB,上传到S3需要5-10分钟。
三、将模型导入到Bedrock
1、发起模型导入
进入对应区域的Bedrock服务,确认区域正确,点击左侧菜单的Imported models按钮。然后点击右侧的Import model导入按钮。如下截图。
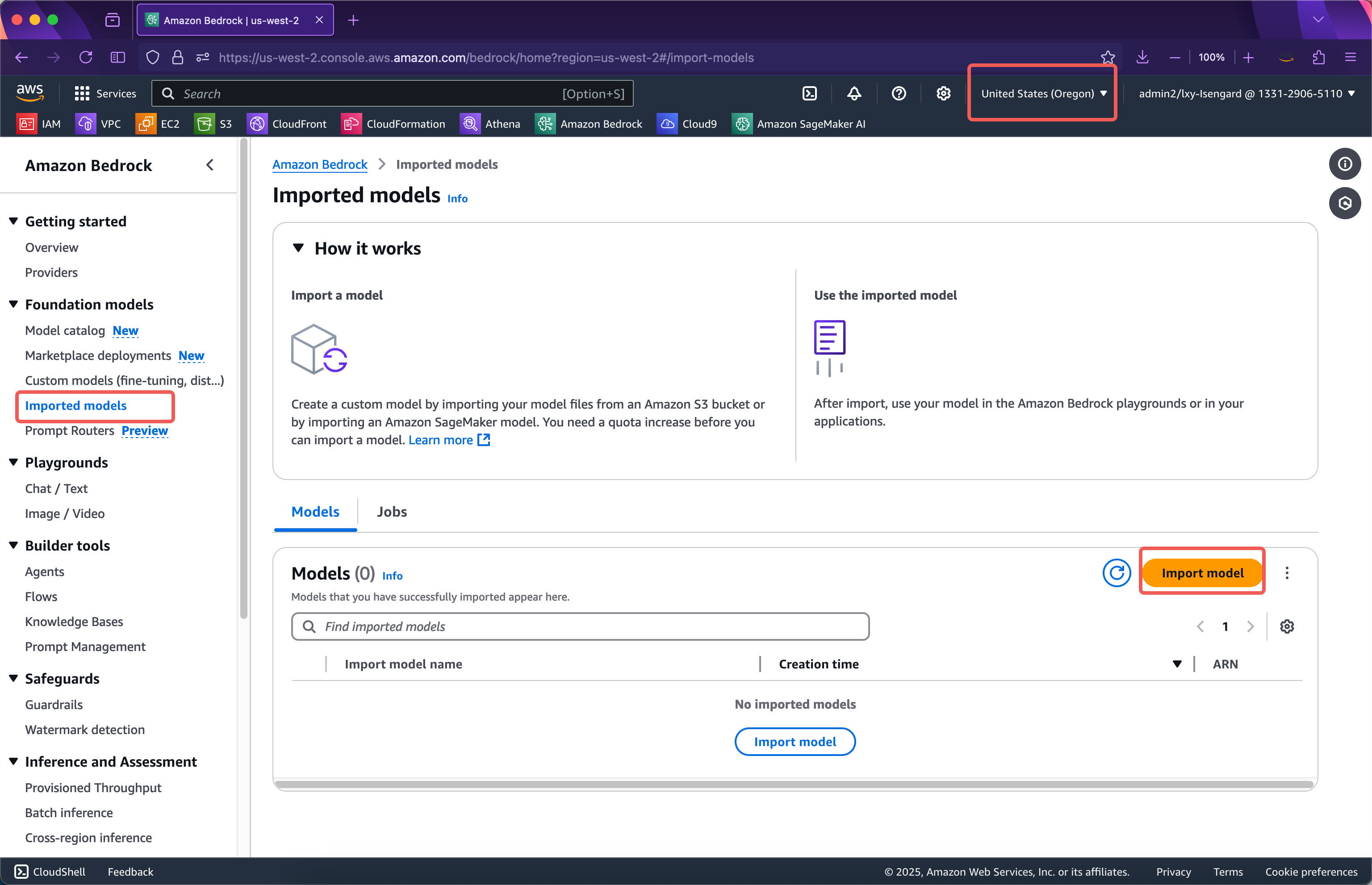
在导入向导的第一步,输入导入模型的名称,这里使用deepseek-r1-distilled-70b也就是它的版本号作为名称。接下来本页面的选项无需改动,继续向下滚动屏幕。如下截图。
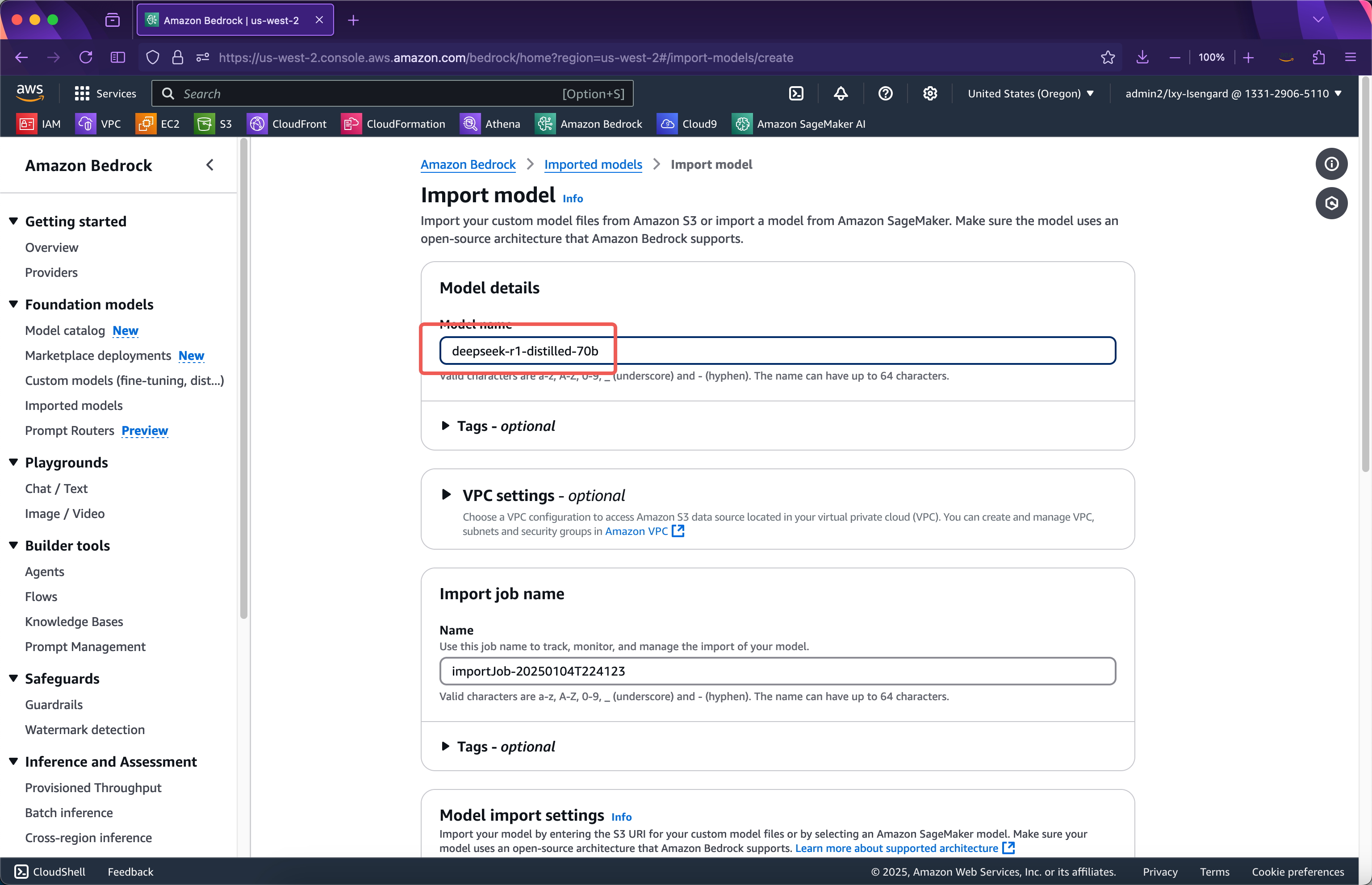
在模型导入设置位置,输入上一步模型上传的存储桶的名称。上一步的Python脚本会将模型文件上传到存储桶的根目录,因此这里直接填写存储桶名称即可。在下方,导入模型使用的服务角色位置,选择Create and use a new service role。这里不需要事先手工创建IAM Role了,导入模型向导会自动创建。接下来将页面滚动到最下方,点击导入模型按钮。如下截图。
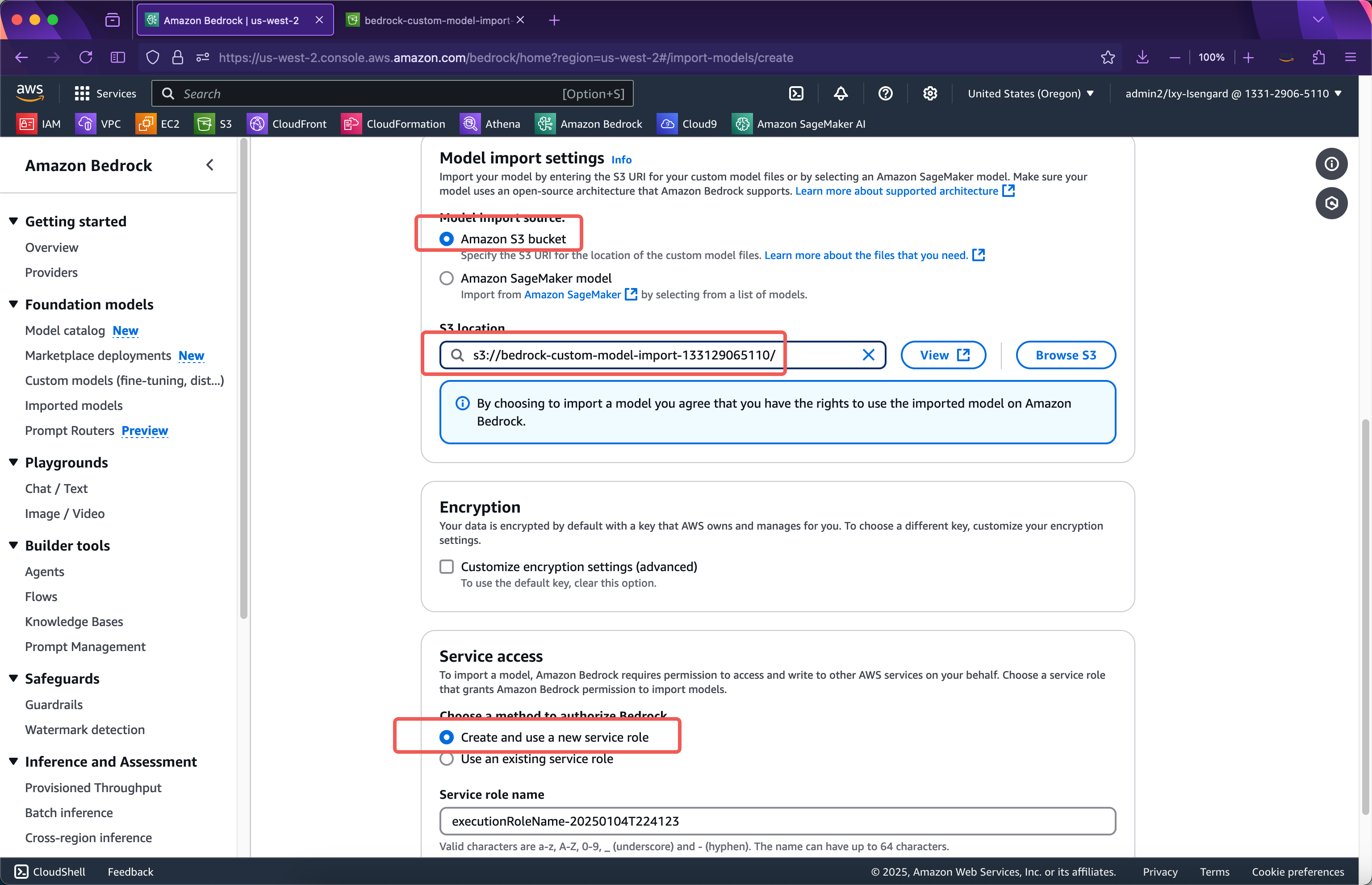
提交后向导自动会创建导入模型说需要的IAM Role,此时浏览器不能离开页面,等IAM Role创建完毕后,会自动提交模型导入任务,届时就转入后台,浏览器可离开当前页面。如下截图。
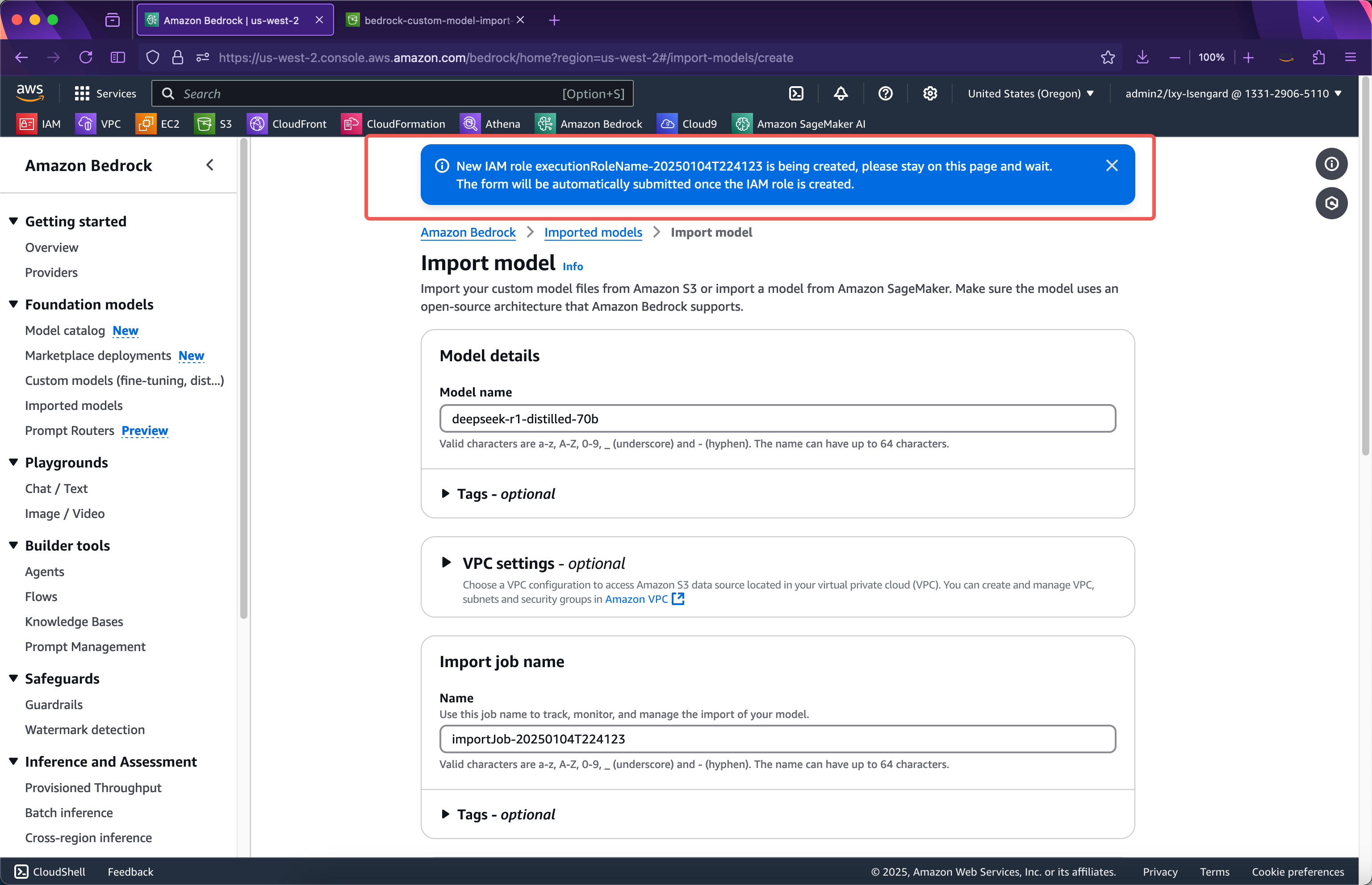
等待大约1分钟,IAM Role创建完成,网页自动跳转到模型导入任务进行中的界面,此时浏览器可以离开当前页面。整个模型导入过程,根据导入模型的大小,可能需要15~30分钟时,甚至更长。如下截图。
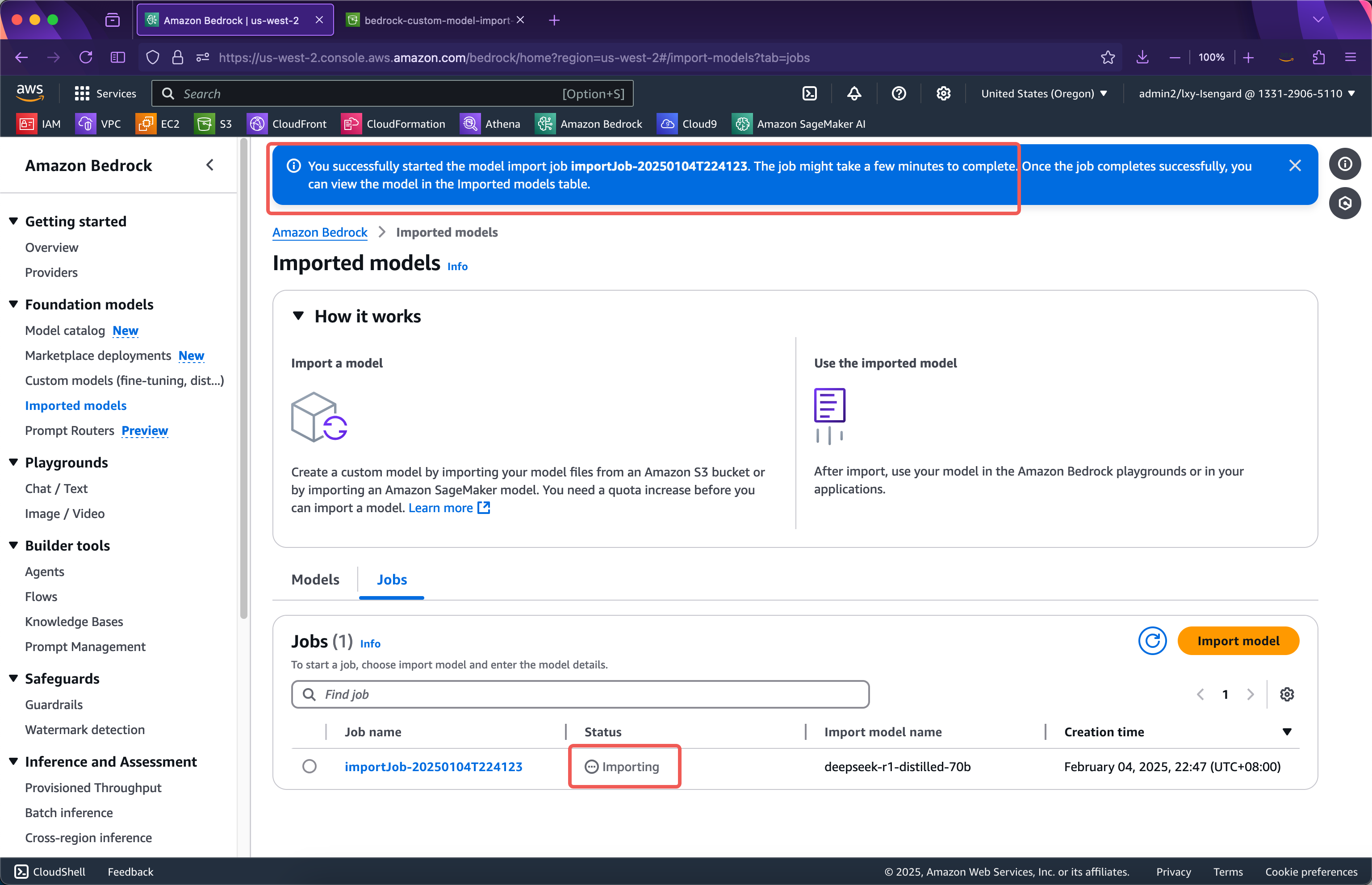
等待一段时间后,导入成功。如下截图。
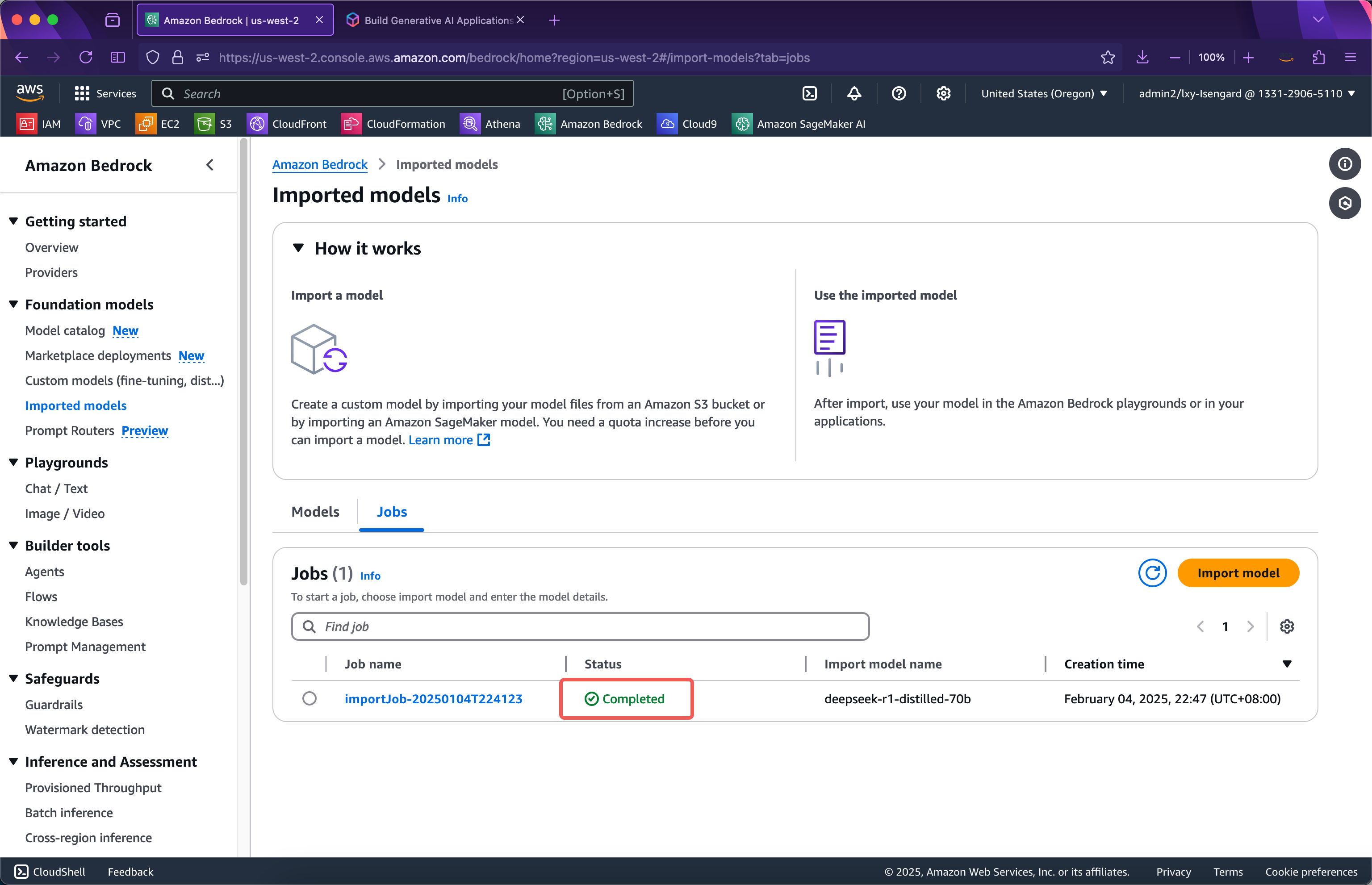
接下来发起测试。
2、从Bedrock控制台发起测试
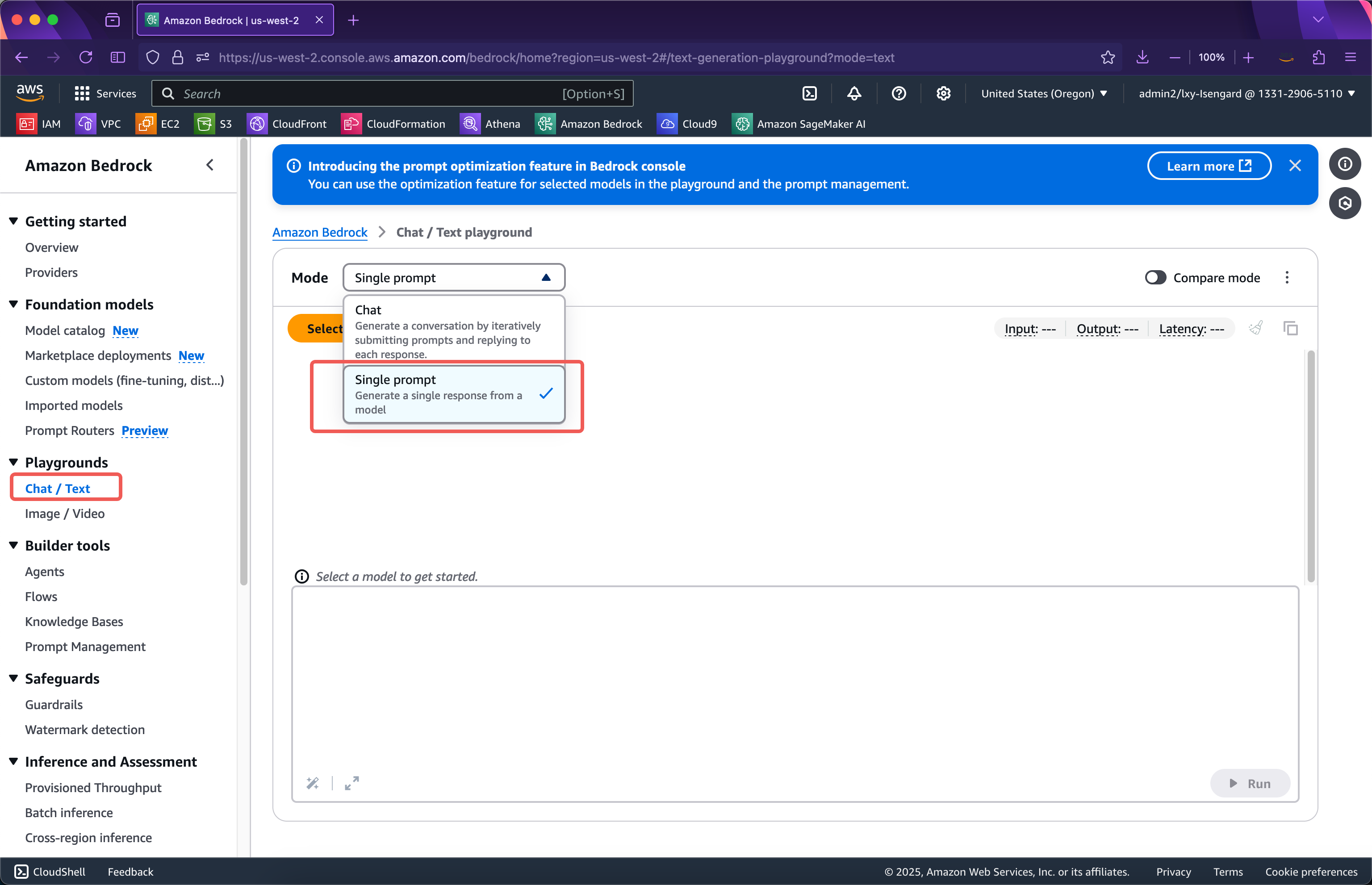
进入Bedrock服务,点击左侧Playgrounds菜单,从右侧的模式下拉框中,选择Single prompt。注意导入自定义模型后,在Bedrock控制台上,仅能在Single Prompt中看到自定义的模型。如下截图。
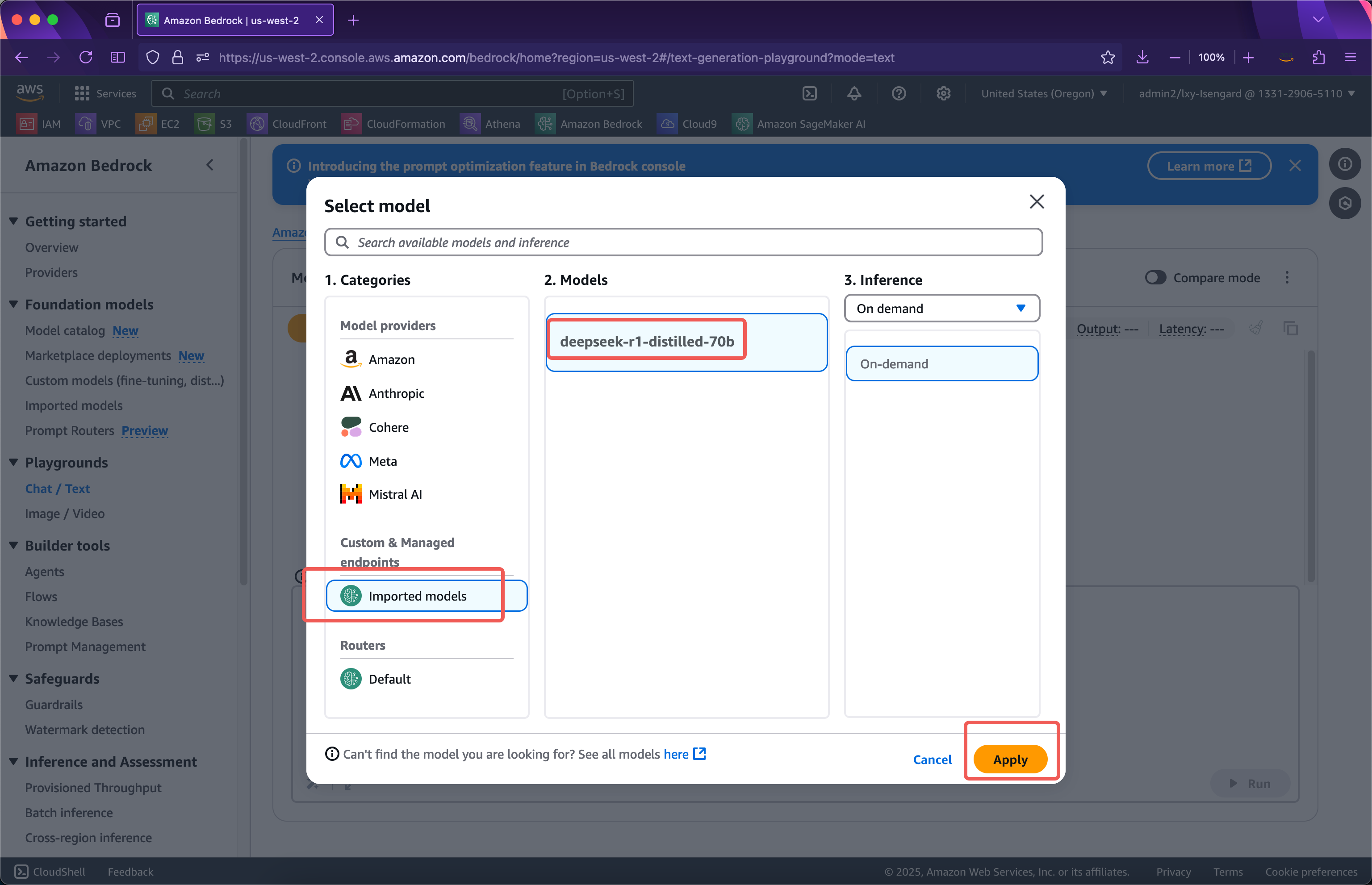
接下来在模型提供者清单中,可看到Custom & Managed endpoints下边就是自己导入的模型。点击Apply即可开始使用。如下截图。
需要注意的是,将自定义模型导入到Bedrock后,模型实质上并未启动,因此第一次调用模型时候,模型会被加载到GPU资源池中,这个过程存在一个数十秒的冷启动。当模型启动完毕后,后续调用即可无延迟直接输出。如果在一个5分钟窗口没有调用,模型占用的GPU资源将会被释放,再次调用模型时候还会遇到冷启动问题。
在控制台的Playgrounds上调用导入的自定义模型,提示词有特定写法,需要按照如下格式输入。
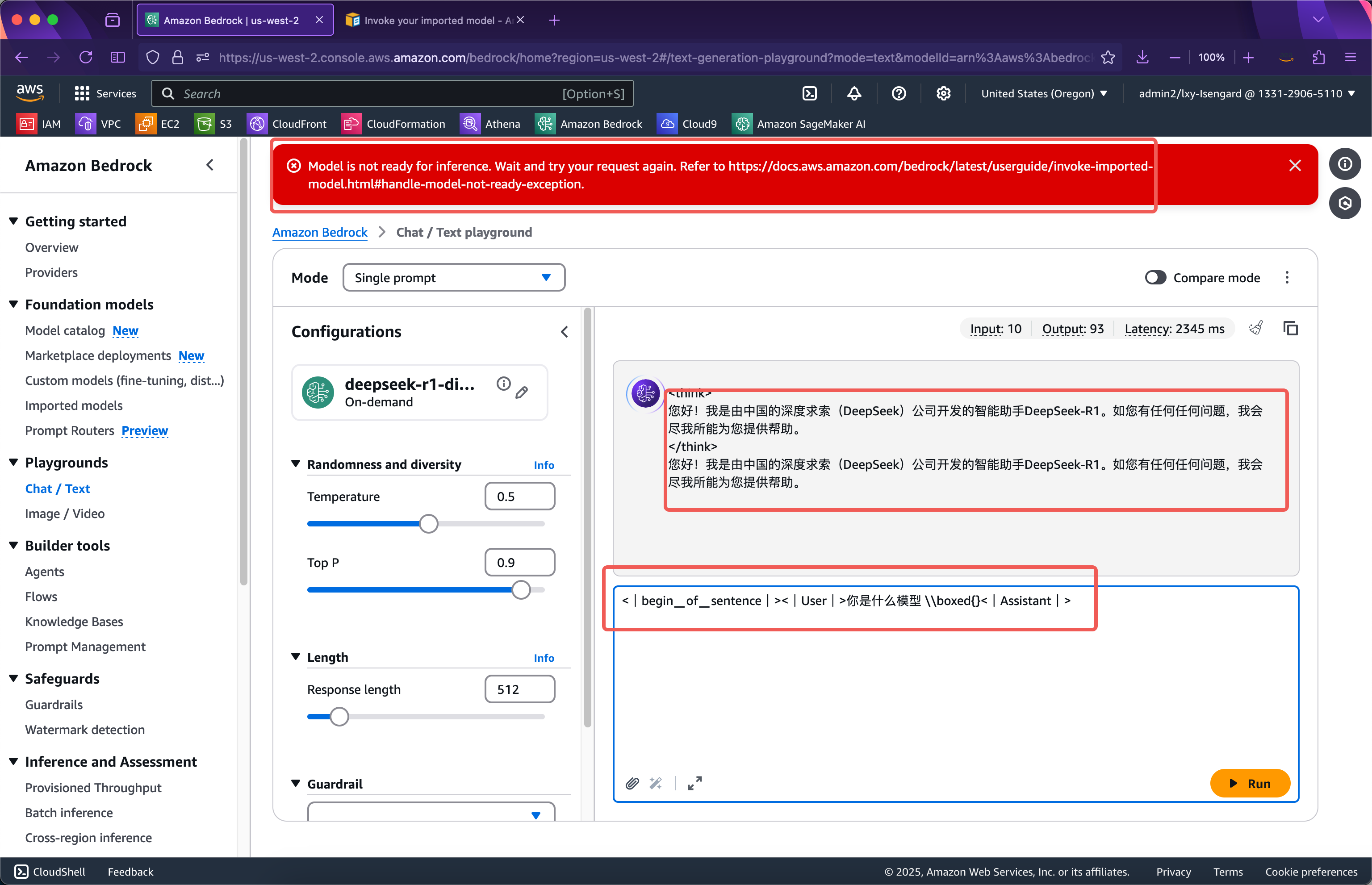
<|begin▁of▁sentence|><|User|> 你是什么模型|Assistant|>
输入后会看到页面上方红色提示框显示模型推理尚未就绪Model is not ready for inference。此时需要等待几十秒,再次提交即可看到模型运行正常。如下截图。
现在换一个比较复杂的需要思考(Thinking)的例子,输入如下一段Prompt,然后提交。如下截图。
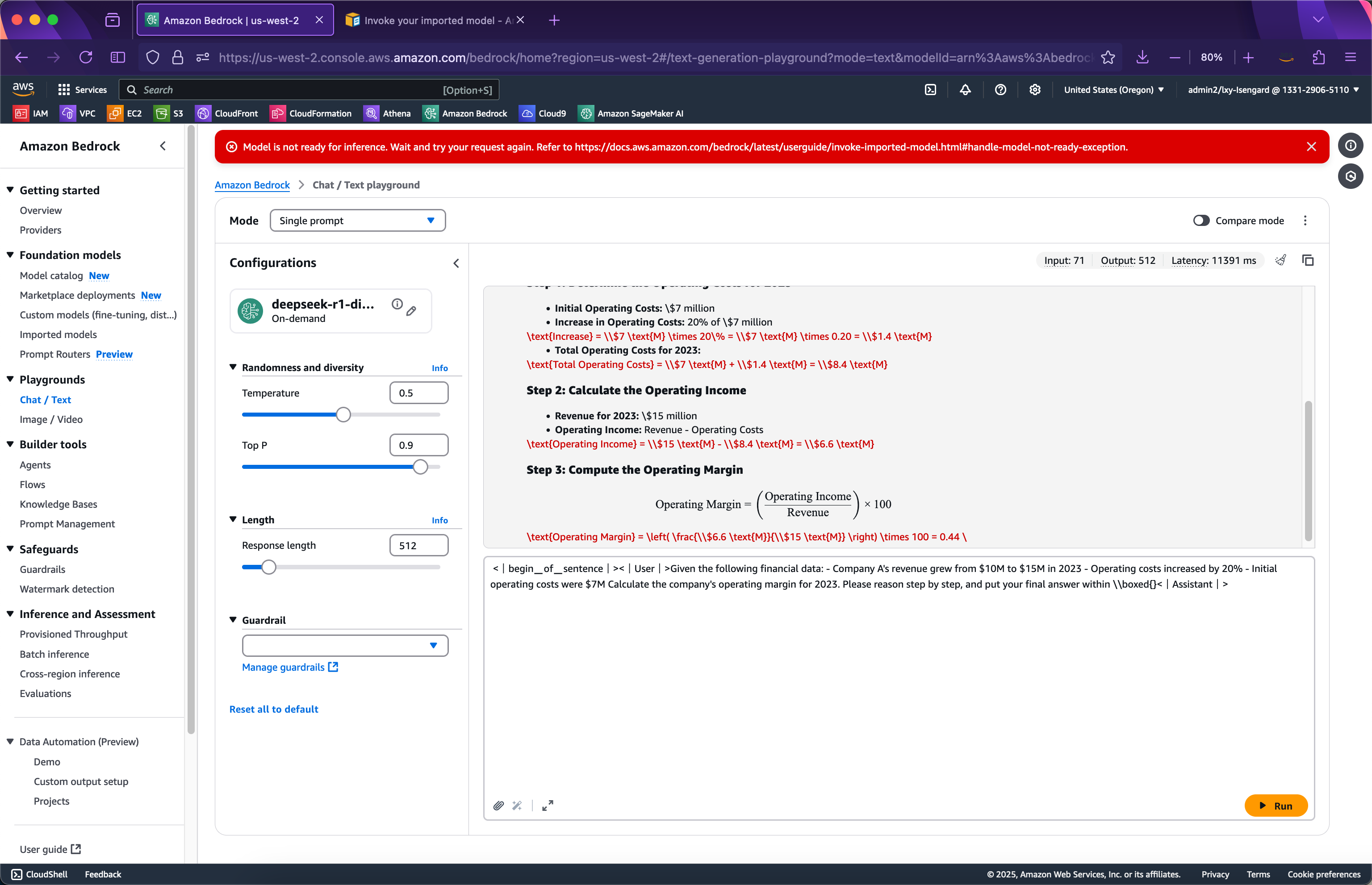
<|begin▁of▁sentence|><|User|>Given the following financial data: - Company A's revenue grew from $10M to $15M in 2023 - Operating costs increased by 20% - Initial operating costs were $7M Calculate the company's operating margin for 2023. Please reason step by step, and put your final answer within \\boxed{}<|Assistant|>
可以看到模型很好的完成了推理。
下边进行API调用。
3、从Bedrock API发起测试
通过Bedrock API调用之前,需要获取模型ID。模型ID也就是ARN字符串可以通过如下位置获取。如下截图。
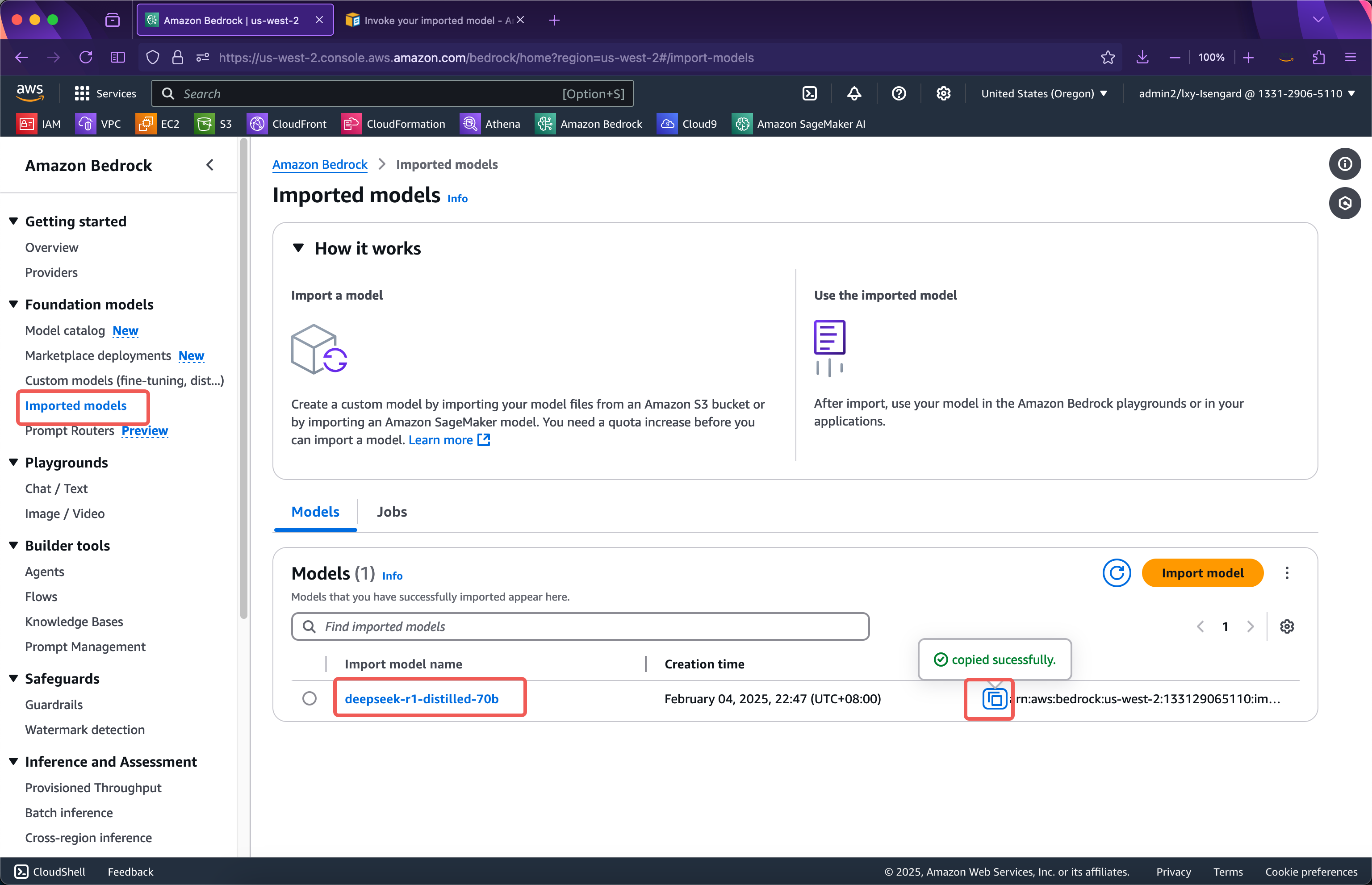
接下来准备如下一段Python代码:
import boto3
import json
client = boto3.client('bedrock-runtime', region_name='us-west-2')
model_id = 'arn:aws:bedrock:us-west-2:133129065110:imported-model/otk6ql88yk9i'
prompt = "你是什么模型"
response = client.invoke_model(
modelId=model_id,
body=json.dumps({'prompt': prompt}),
accept='application/json',
contentType='application/json'
)
result = json.loads(response['body'].read().decode('utf-8'))
print(result)
如果刚才Bedrock控制台上发起调用启动了模型,那么运行这段Python程序将没有冷启动时间,模型立刻即可调用。运行后返回结果如下:
{'generation': '?\n\n</think><think>\n\n</think>\n\n您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。', 'generation_token_count': 52, 'stop_reason': 'stop', 'prompt_token_count': 4}
由此自定义模型运行正常。
如果要让代码适应自定义模型的冷启动,可以加入异常处理。增加重试次数、异常处理后的代码如下。
import boto3
import json
from botocore.config import Config
config = Config(
retries={
'total_max_attempts': 10,
'mode': 'standard'
}
)
client = boto3.client('bedrock-runtime', region_name='us-west-2', config=config)
model_id = 'arn:aws:bedrock:us-west-2:133129065110:imported-model/otk6ql88yk9i'
prompt = "你是什么模型"
try:
response = client.invoke_model(
modelId=model_id,
body=json.dumps({'prompt': prompt}),
accept='application/json',
contentType='application/json'
)
result = json.loads(response['body'].read().decode('utf-8'))
print(result)
except Exception as e:
print(e)
print(e.__repr__())
运行这段Python代码,可看到不会提示模型未就绪,而是在遇到冷启动时候等待并重试。如果模型已经启动就绪,则后续访问没有延迟。
{'generation': '?\n\n\n您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。', 'generation_token_count': 47, 'stop_reason': 'stop', 'prompt_token_count': 4}
四、Bedrock导入自定义模型使用场景的费用说明
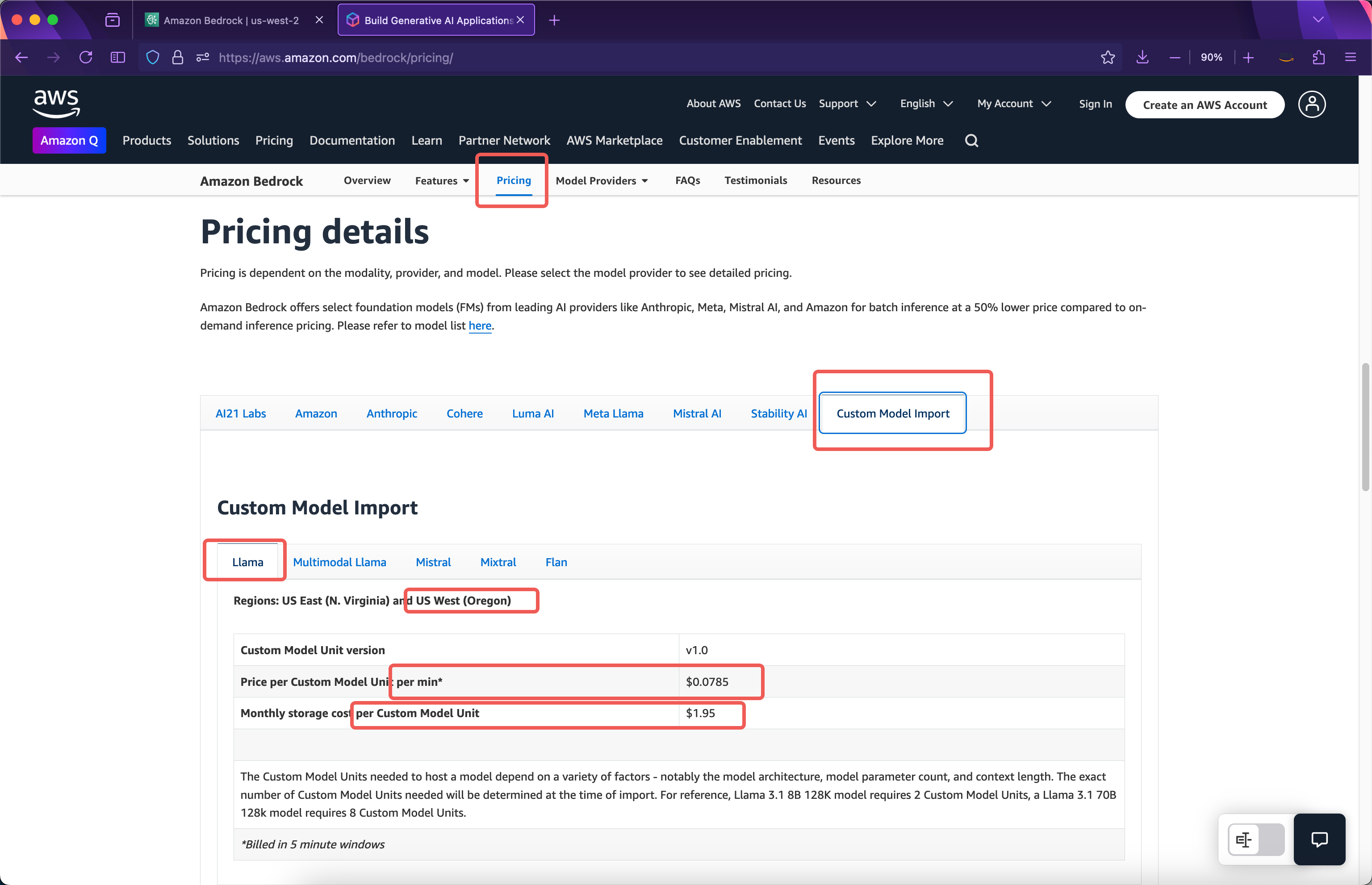
Bedrock导入自定义模型的收费方式是按照导入模型后运行副本所占用的计算资源来计费,而不是按照输入、输出的Token。在AWS官网上可看到如下的价格清单。如下截图。
1、模型存储费
官方介绍导入8b模型的时候会占用2个Custom Model Unit,如果导入了70b参数的模型会占用8个Custom Model Unit。所以以导入了deepseek-r1-distilled-70b模型为例,占用8个Custom Model Unit,因此其存储费用是$1.95 * 8 = $15.6一个月。
2、单个副本的计算资源费
导入自定义模型的计算时长按照5分钟为单位,5分钟后没有模型调用则自动释放计算资源,下次再调用模型时候存在一次冷启动加载时间。例如本文例子当模型导入完毕时候,导入过程不收费,模型未被调用,本月将收取存储费,但是计算时长不收费。导入模型后的第二天早上10:00对模型发起了首次调用,此时从10:00~10:05这个五分钟窗口,将按照占用8个Custom Model Unit收费,按照以上截图可看出,费用是$0.0785每分钟每模块 * 8个模块 * 5分钟 = $3.14。这就是运行本模型一个五分钟窗口的费用。
第一个五分钟窗口在10:05结束,模型会继续运行五分钟。在第二个五分钟窗口内如果没有模型调用,那么10:10模型就会释放资源,总计产生了2个5分钟窗口的费用。如果第二个五分钟窗口内又产生了模型调用,例如10:07分模型被调用那么第二个五分钟计费窗口被记录,接下来从10:10开始三个计费五分钟。假设从10:10~10:15这第三个五分钟没有用户访问了,那么以上总共运行了3个五分钟窗口,总计收费$3.14 * 3 = $9.42。按此逻辑,如果继续用调用,继续按5分钟窗口计费。
运行一段时间后,可以看到70b模型消耗8个计算单元,共计4个5分钟的周期,总计20分钟。这项开支在大约24小时后可以从本AWS账号的账单中看到。如下截图。
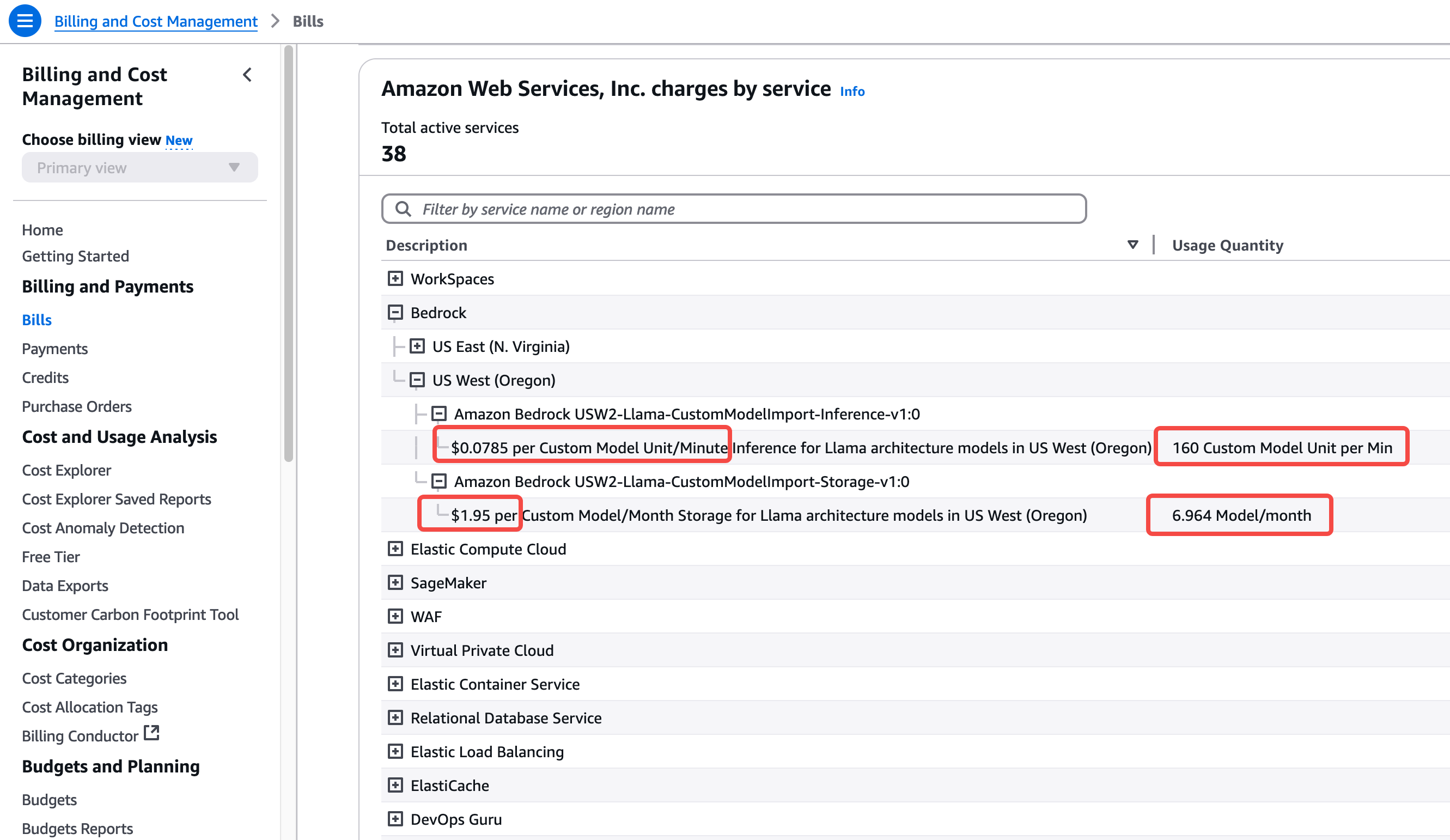
由此可以看到,如果导入deepseek-r1-distilled-70b模型后,假如7x24小时运行一整个月,总费用将是$0.0785每模块每分钟 * 8模块 * 60分钟 * 24小时 * 30天 = $27129.6(一个月费用)。这是由于70B参数的模型消耗数百GB显存需要运行在8个GPU卡的硬件上,因此如果全天运行一直有API调用那么费用将相对很高。
3、Bedrock弹性缩放和多副本
以上是模型导入后运行一个副本的情况。启动一个副本占用8个Custom Model Unit,此时8个Custom Model Unit的Token输入/输出不再额外计费。但是,启动一个副本也不是具有无限吞吐的,模型每个副本的最大吞吐量和并发限制取决于模型本身,这在特定参数大小的模型导入时候就被自动确定了。Bedrock默认是启动一个副本,针对大流量调用,Bedrock提供了自动缩放能力,如果吞吐量打满了一个副本所载的硬件资源,会自动扩展到第二个副本、第三个副本。当然,启动一个新的副本,又要多占用8个Custom Model Unit,并按分钟计费。目前,一个AWS账号的默认Quota值是3,也就是自定义模型后加并发,最多只能扩展到三个副本。需要更多的话请开support case申请提升limit。
4、关于费用和模型参数大小选择
由于DeepSeek模型具有思考能力,在很多场景下8B模型的版本就体现了良好的能力,因此本文部署70B参数的版本主要是展示Bedrock操作的全过程,实际业务使用中可尝试8B参数模型,以获得最佳成本和效果的平衡。
五、参考文档
[亚马逊云开发者官方微信号]高效部署DeepSeek-R1 Distill Llama模型
https://mp.weixin.qq.com/s/qLQqmJFQRoOCIn-7GOFiuA
亚马逊官方博客(英文)Deploy DeepSeek-R1 distilled Llama models with Amazon Bedrock Custom Model Import
Deploying DeepSeek R1 Model on Amazon Bedrock
https://github.com/manu-mishra/DeepSeekR1onAmazonBedrock
DeepSeek file downloads on Huggingface
https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-70B/tree/main
Bedrock的API进行异常处理解决导入自定义模型后的冷启动问题
最后修改于 2025-02-04