使用Bedrock批量推理Batch Inference处理Embedding任务
本文介绍Bedrock批量推理处理大规模图像Embedding任务的完整方案,涵盖权限配置、任务创建、进度监控和结果加载,解决海量数据处理的成本和效率问题。
一、批量推理场景
通常构建Agent应用、和模型对话的Bedrock InvokeModel API是实时同步调用,如果遇到体积较大任务,例如图像生成或者视频生成,还可能使用异步调用InvokeModelAsync。这两种调用本质上都是预期很快返回结果的,只是Async不是一直等待那里。如果有这样一种业务场景,有海量的数据需要被处理,可能是一般的文本推理、可能是图片理解、还可能是Embedding,业务场景会一个批次提交大量待处理的文件,并且没有时间期限的要求,等待几个小时才处理好是可以接受的。此时这种场景,就适合Bedrock Batch Inference。
由于没有时限要求,Bedrock会在相对不繁忙的时候进行推理,处理时间根据数据量大小从一小时到几小时,一般最长不超过24小时。因此可以看到,Batch Inference非常适合每天一次或者每天几次的定期加载数据任务,另外,Batch Inference的API计费只有普通实时API的一半左右,是节约成本的好手段。
二、Bedrock Batch Inference的运行原理和方案设计
1、原理
Bedrock Batch Inference通过JSONL格式定义要处理的任务。JSONL是JSON文件的合集,每行是一个JSON对象。每一行的JSON都定义了一个目标文件的推理任务,一次提交的清单需要大于100个目标文件才可以被Batch Inference所接受。要处理的原始数据存放在S3存储桶中,定义任务的JSONL文件需要和原始文件在同一个路径(Prefix/目录),否则API会报错。然后通过API提交任务。
一旦提交任务成功,Bedrock会分配唯一的任务ID,后续可追踪这个ID对应的任务状态。任务可能有以下多种状态:
- Submitted – 任务已提交到队列等待验证。
- Validating – 任务正在验证是否满足"格式和上传批量推理数据"中描述的要求。验证标准包括以下内容:
- IAM 服务角色有权访问包含文件的 Amazon S3 存储桶。
- 文件是 .jsonl 文件,每条记录都是格式正确的 JSON 对象。注意:验证不检查 modelInput 值是否与模型的请求体匹配。
- 文件满足文件大小和记录数量的要求。更多信息请参阅 Amazon Bedrock 配额。
- Scheduled – 任务已验证,现在在队列中。任务将在轮到它时自动启动。
- Expired – 任务已过期,因为任务已排期但在设置的超时时间内未开始。请提交新的任务请求。
- InProgress – 任务已开始。您可以开始在输出 S3 位置查看结果。
- Completed – 任务已成功完成。在输出 S3 位置查看输出文件。
- PartiallyCompleted – 任务已部分完成。并非所有记录都能在规定时间内处理。在输出 S3 位置查看输出文件。
- Failed – 任务失败。检查失败消息了解更多详情。如需进一步帮助,请联系支持中心。
- Stopped – 任务已被用户停止。
- Stopping – 任务正在被用户停止。
任务刚提交时第一个状态是Submitted,然后会进行校验和排期,这个过程相对较快,可能在数分钟后完成。当任务状态转到Scheduled之后,会等待较长的时间,根据任务量的大小,可能排期在10分钟~60分钟内,也可能排期在几小时后。通常不超过24小时。
任务无论成功和失败,都可以通过任务ID追踪,可看到整个JSONL对应所有对象的处理,这意味着一次提交大量文件时,单个文件可能失败而其他文件处理成功。此时需要追踪单个文件处理结果的正确性,确保没有遗漏。处理结果会保存在S3存储桶的output目录中,以JSONL格式返回。Bedrock Batch Inference处理任务在这里结束。
最后,如果所有文件都处理成功了还需要用户自己进行后处理。不管是文字生成、图像理解、还是Embedding,推理后的结果只是保存在JSONL文件中,它们还需要被逐条读取出来,然后加载到对应的数据库或者数据服务中,与相应的ID进行关联。这部分操作是用户业务代码负责的范围。本文使用的例子是Embedding的例子,它们会被加载到S3 Vector Bucket中。
2、本文演示代码的相关环境
定义如下资源用于后续演示代码的调用:
- 原始数据存储桶:nova-mme-demo-source-image,被处理的原始文件位于某个路径下
- 批任务处理清单存储桶:同上,定义任务的JSONL文件需要和原始文件在同一个路径下
- 批处理结果存储桶:nova-mme-demo-batch-result
- S3向量存储桶:my-nova-mme-demo-01
- S3向量存储桶的Index索引名称:my-image-index-02-lambda
编写四个脚本:
- 脚本 01_create_job.py 负责提交任务
- 脚本 02_monitor_job.py 负责查询任务状态
- 脚本 03_load_result_to_s3_vector_bucket.py 负责将推理完成的数据加载到S3向量存储桶
- 脚本 04_remove_completed_task.py 负责清理临时文件
此外,iam目录下的是调用Batch Inference所需要的权限和角色的配置。
现在开始构建。
三、创建批量推理所需要的权限和角色
1、批量推理的权限机制
现在讲解下Bedrock批量推理的权限机制。提交Bedrock批处理任务分成几个部分:
- 第一部分:遍历S3存储桶生成文件清单、调用Bedrock API创建批量推理任务的脚本;这个阶段需要用户具有读写S3权限、创建Bedrock批量推理任务的权限、以及PassRole传递角色的权限。
- 第二部分:Bedrock在排期后,会自动调用Bedrock API处理任务。这个阶段需要Bedrock Service Role具有读写S3权限、调用特定模型权限。
- 第三部分:Bedrock处理任务完成后,会将结果存储到S3存储桶中。这个阶段需要用户具有读写S3权限,以及读写S3 Vector Bucket存储桶权限。
综合以上信息,本着最小权限原则,这里需要为第二部分创建一个全新的Bedrock Service Role。然后,由于脚本都在客户端(本机)执行,所以第一部分和第三部分所需要的权限可以合并成一个策略。
这里需要特别注意的是,第一部分和第三部分任务,如果当前使用的IAM User的AKSK是管理员权限,则什么也不用做。如果不是管理员权限,那么就需要为第一部分和第三部分额外补充权限。此外,您可能在使用2025年Bedrock发布的单一API Key功能。单一API Key在背后对应的是一个唯一的IAM User,这个IAM User也需要额外增加PassRole权限。
下面分别操作。
2、创建Bedrock批量推理的服务角色
本文使用setup_service_role.sh脚本创建角色:
chmod +x iam/setup_service_role.sh
bash iam/setup_service_role.sh
这个脚本会创建IAM role。返回如下:
==========================================
Creating Bedrock Batch Inference Role
==========================================
Step 1: Creating trust policy...
Step 2: Creating IAM role: BedrockBatchInferenceRole
{
"Role": {
"Path": "/",
"RoleName": "BedrockBatchInferenceRole",
"RoleId": "ARXXXXXXXXXXXXXXXXXXX",
"Arn": "arn:aws:iam::133129065110:role/BedrockBatchInferenceRole",
"CreateDate": "2025-11-18T09:37:38+00:00",
"AssumeRolePolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "bedrock.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
}
}
✓ Role created successfully
Step 3: Attaching permissions policy...
✓ Permissions policy attached successfully
Step 4: Verifying role setup...
✓ Role ARN: arn:aws:iam::133129065110:role/BedrockBatchInferenceRole
==========================================
✓ Setup Complete!
==========================================
Role Name: BedrockBatchInferenceRole
Role ARN: arn:aws:iam::133129065110:role/BedrockBatchInferenceRole
由此创建IAM Role成功,记录下返回结果最后一行ARN,接下来提交任务脚本中要指定用这个Role。
3、为调用Bedrock的API Key增加PassRole权限
根据前文的介绍,如果您使用的不是AWS账户管理员权限的话,现在要给AWS的AKSK对应的IAM User增加权限。另外如果您使用的是Bedrock API Key,那么还需要给Bedrock API Key对应的用户增加权限。要确保这两个身份都具有权限。
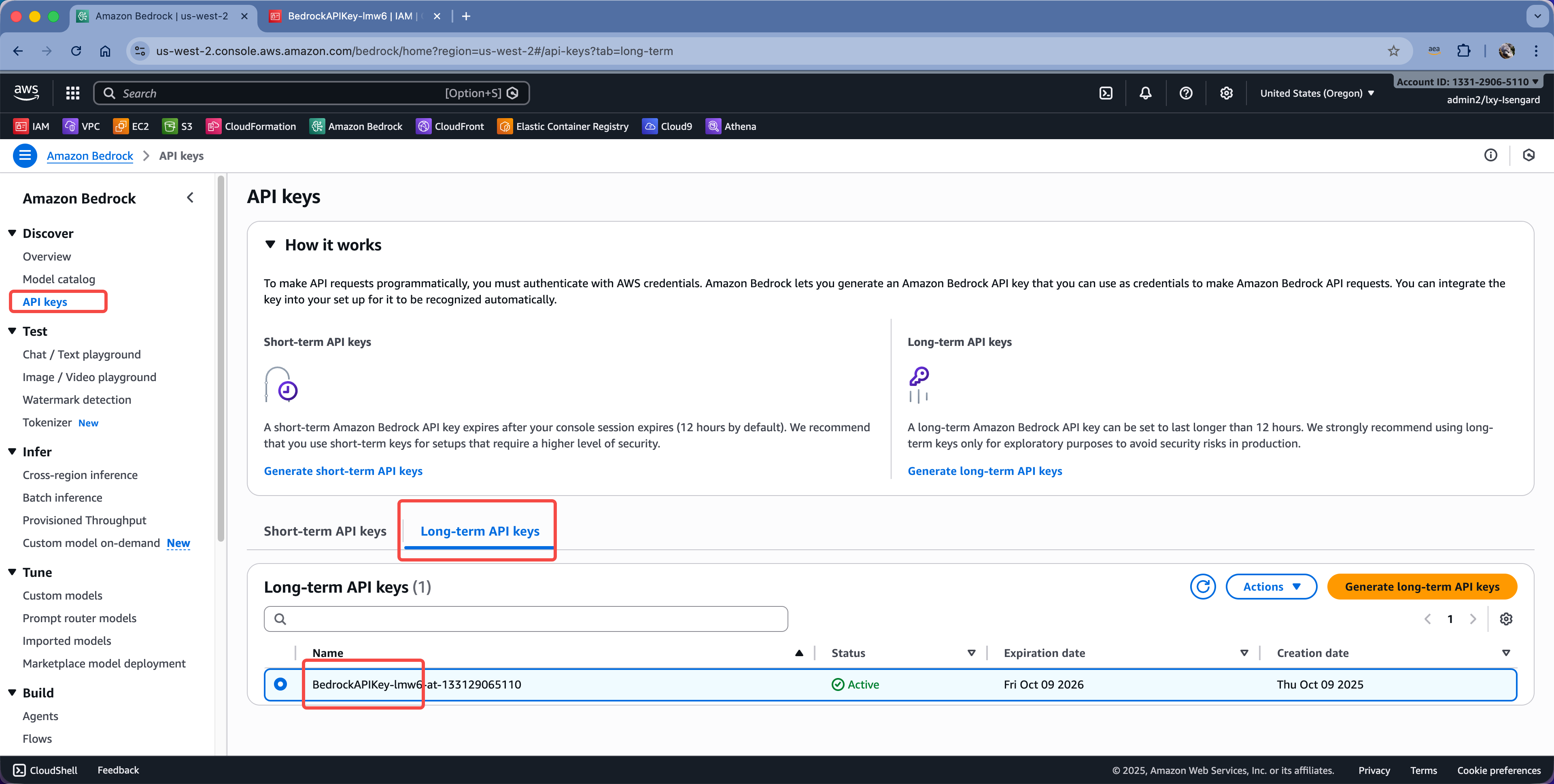
进入Bedrock服务控制台,找到API Key。这个Key的ID的前半部分,就是对应着AWS IAM user名称,如下截图。
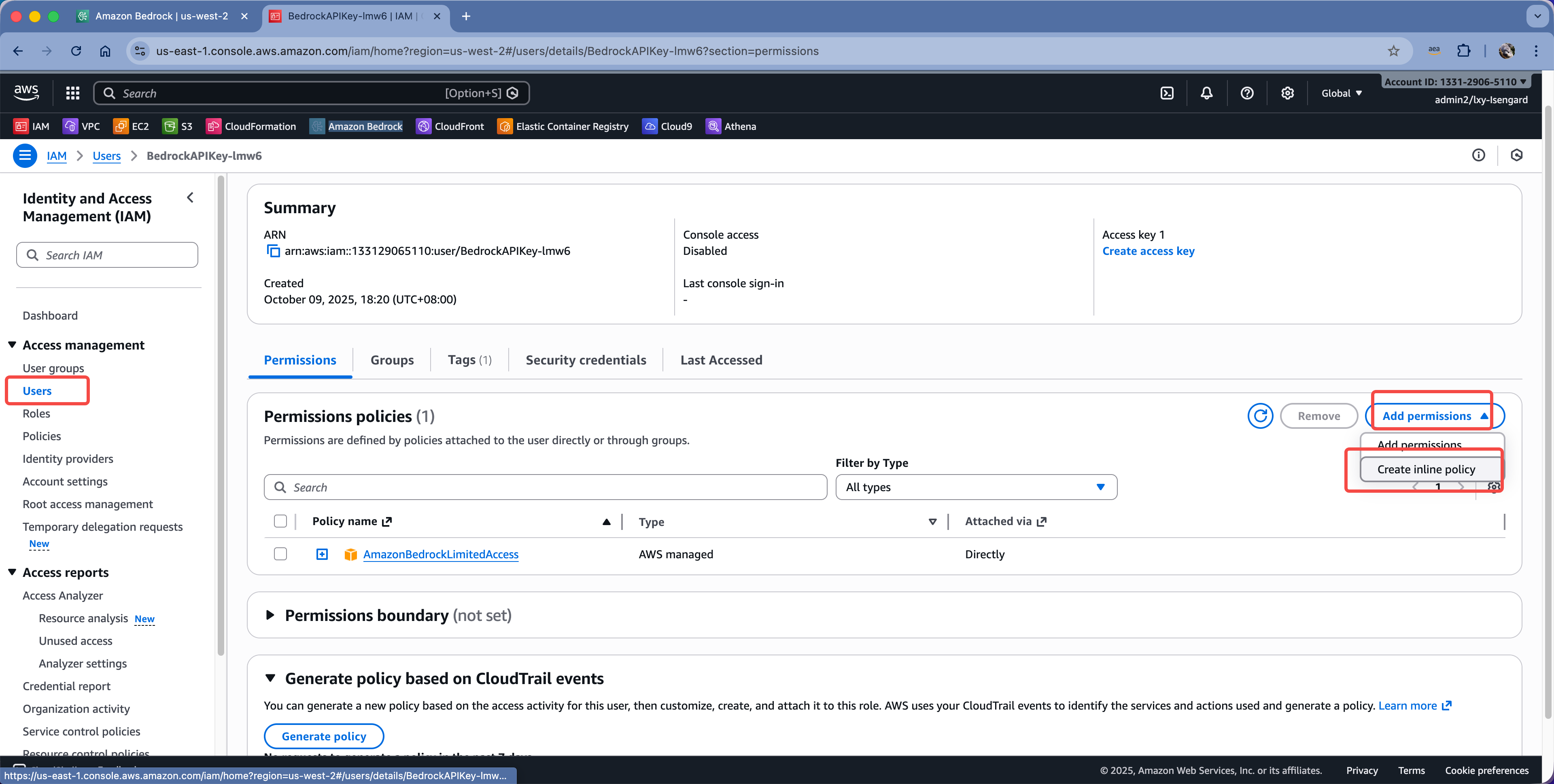
进入到这个用户对应的Policy,点击右侧的Add permissions按钮,点击Create inline policy。如下截图。
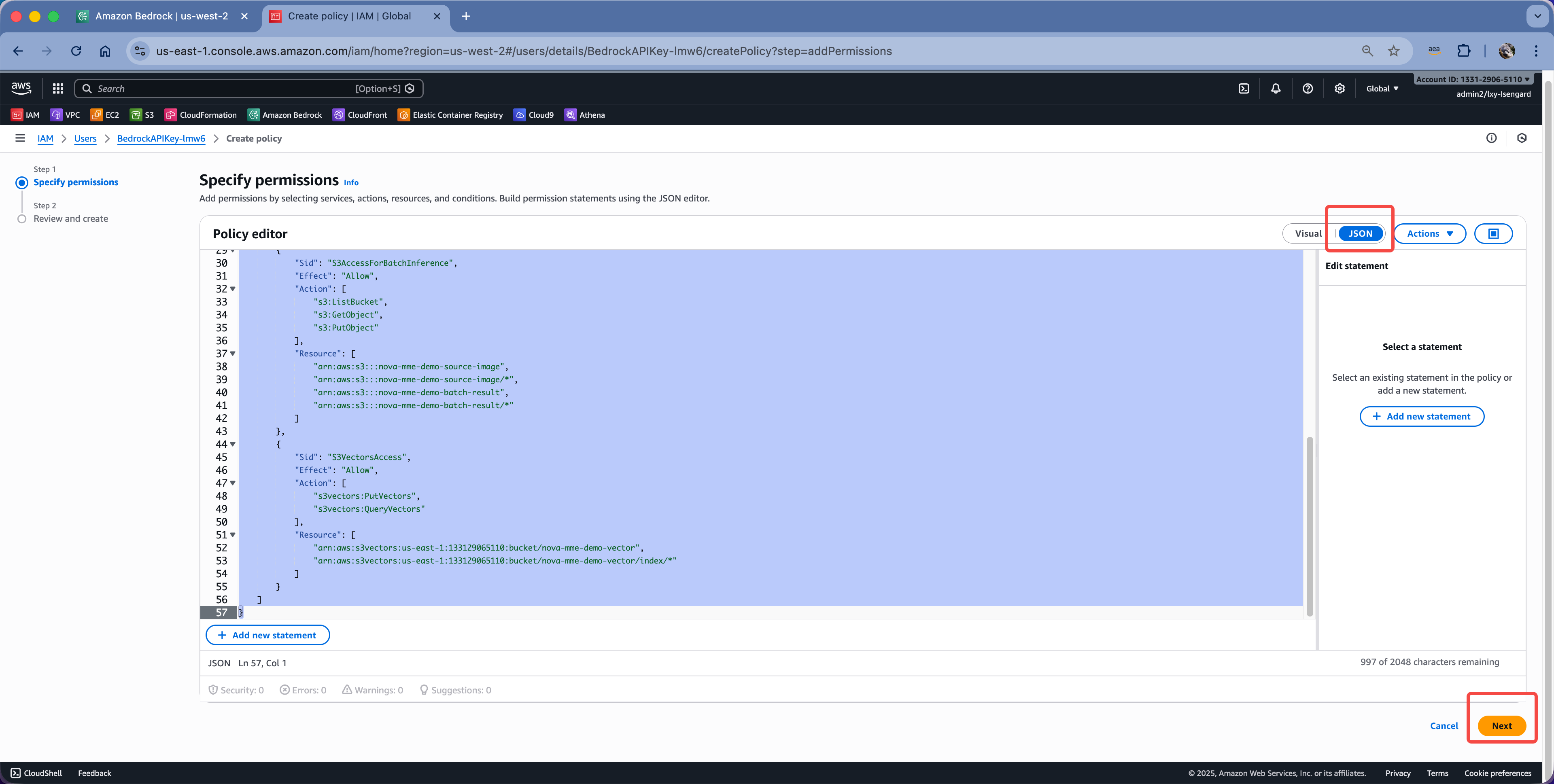
将策略编辑器切换到直接输入JSON模式,然后粘贴如下策略:
执行如下命令:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "BedrockBatchInferenceUserPermissions",
"Effect": "Allow",
"Action": [
"bedrock:CreateModelInvocationJob",
"bedrock:GetModelInvocationJob",
"bedrock:ListModelInvocationJobs",
"bedrock:StopModelInvocationJob"
],
"Resource": "*"
},
{
"Sid": "PassRoleToBedrockServiceRole",
"Effect": "Allow",
"Action": [
"iam:PassRole"
],
"Resource": "arn:aws:iam::133129065110:role/BedrockBatchInferenceRole",
"Condition": {
"StringEquals": {
"iam:PassedToService": "bedrock.amazonaws.com"
}
}
},
{
"Sid": "S3AccessForBatchInference",
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetObject",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::nova-mme-demo-source-image",
"arn:aws:s3:::nova-mme-demo-source-image/*",
"arn:aws:s3:::nova-mme-demo-batch-result",
"arn:aws:s3:::nova-mme-demo-batch-result/*"
]
},
{
"Sid": "S3VectorsAccess",
"Effect": "Allow",
"Action": [
"s3vectors:PutVectors",
"s3vectors:QueryVectors"
],
"Resource": [
"arn:aws:s3vectors:us-east-1:133129065110:bucket/nova-mme-demo-vector",
"arn:aws:s3vectors:us-east-1:133129065110:bucket/nova-mme-demo-vector/index/*"
]
}
]
}
粘贴完毕点击保存按钮。如下截图。
下一步还要求输入这个inline策略的名称,自选一个名称输入,然后点击创建。修改策略完成。
四、创建批量推理任务
执行脚本01_create_job.py,将数据提交到Bedrock的Batch Inference中。执行如下命令加载环境:
uv init .
uv venv
source .venv/bin/activate
uv run 01_create_job.py
这个程序会自动生成JSONL清单文件,里边的格式如下:
{"recordId": "IMG_4FD2E571", "modelInput": {"taskType": "SINGLE_EMBEDDING", "singleEmbeddingParams": {"embeddingPurpose": "GENERIC_INDEX", "embeddingDimension": 3072, "image": {"format": "jpeg", "source": {"s3Location": {"uri": "s3://nova-mme-demo-source-image/2024/01/s01.jpg", "bucketOwner": "133129065110"}}}}}}
在生成JSONL清单后,这个程序会将其上传到S3存储桶,注意这个必须是图片所在的原始存储桶的同一个目录下,不能是其他目录,否则处理任务会报错。上传完毕后提交任务给Bedrock。返回结果如下:
======================================================================
Bedrock Batch Inference - Create Job
======================================================================
Listing images from s3://nova-mme-demo-source-image/2024/ (including subdirectories)
✓ Found 641 images
Creating JSONL file: batch_input_20251121-002057.jsonl
✓ Created JSONL with 641 records
Cleaning up old JSONL files from s3://nova-mme-demo-source-image/2024/
Deleted: 2024/batch_input_20251120-225835.jsonl
✓ Cleaned up 1 old JSONL file(s)
Uploading JSONL to s3://nova-mme-demo-source-image/2024/batch_input_20251121-002057.jsonl
✓ Uploaded to s3://nova-mme-demo-source-image/2024/batch_input_20251121-002057.jsonl
Creating batch inference job: nova-mme-embedding-20251121-002057
Model: amazon.nova-2-multimodal-embeddings-v1:0
Input: s3://nova-mme-demo-source-image/2024/
Output: s3://nova-mme-demo-batch-result/output/
Role: arn:aws:iam::133129065110:role/BedrockBatchInferenceRole
✓ Batch job created successfully!
Job ID: x4zk6curm64m
Job ARN: arn:aws:bedrock:us-east-1:133129065110:model-invocation-job/x4zk6curm64m
Saving job information to batch_job_info.json
✓ Job information saved
======================================================================
✓ Batch Job Created Successfully!
======================================================================
Next steps:
1. Monitor job status: uv run 02_monitor_job.py
2. Load results to vector bucket: uv run 03_load_result_to_s3_vector_bucket.py
由此表示创建任务成功。注意在返回结果中有个Job ARN,请复制下来,后续查询任务时需要使用。
五、查看任务进度
执行脚本02_monitor_job.py,查看任务进度:
uv run 02_monitor_job.py
返回结果如下:
======================================================================
Bedrock Batch Inference - Monitor Job
======================================================================
Loaded job info from batch_job_info.json
Job ARN: arn:aws:bedrock:us-east-1:133129065110:model-invocation-job/x4zk6curm64m
======================================================================
Batch Inference Job Status
======================================================================
>>> STATUS: Validating <<<
Job Information:
Job Name: nova-mme-embedding-20251121-002057
Job ARN: arn:aws:bedrock:us-east-1:133129065110:model-invocation-job/x4zk6curm64m
Submit Time: 2025-11-20 16:21:00.456000+00:00
Last Modified: 2025-11-20 16:23:02.012000+00:00
Status: Waiting for processing to begin...
(Processing statistics will appear once job starts)
Output Location: s3://nova-mme-demo-batch-result/output/
======================================================================
Job is still running. Monitor until completion? (y/n): y
回答y的话,程序会每隔30秒刷新。
此外,通过AWS Bedrock控制台的图形界面,也可以看到异步任务已经提交。其状态会在上文介绍的状态之间切换。如下截图。
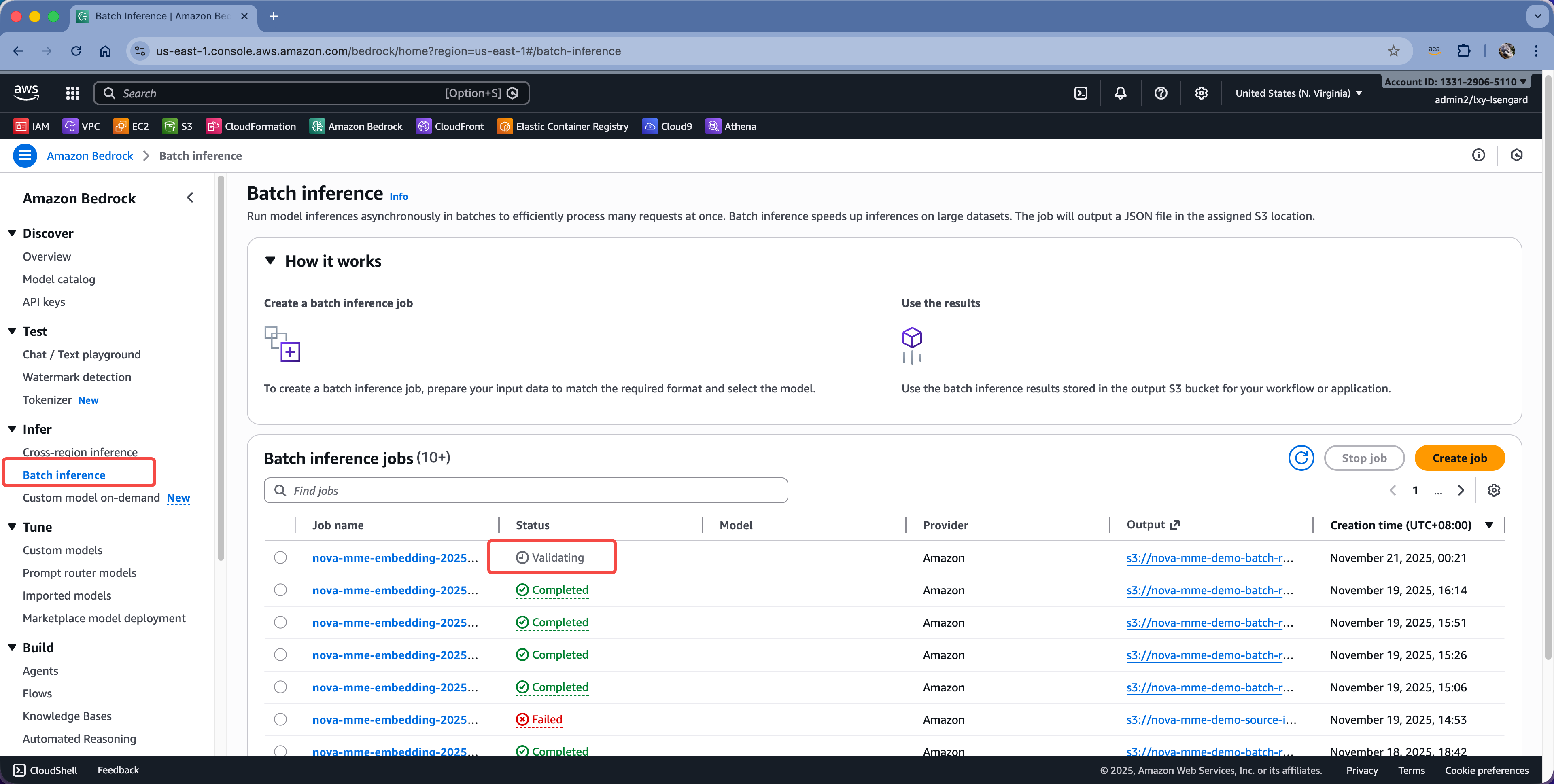
当显示为已计划的状态时,就表示通过了基本的权限校验,等待任务排期。如果数据集比较小的话,可能1小时即可处理完成,数据集比较大的话,可能需要12-24小时。
注意,如果是任务代码中的数据结构有问题,依然可能在处理时候出错。此时运行查看任务的结果,可以看到Successful和Error的文件计数。在存储结果的S3存储桶内,查看任务处理生成的JSONL文件,里边会提示错误原因。
六、查看结果并将结果加载到S3 Vector Bucket
以本文处理几百张图片的批量推理任务为例,大概等待30分钟,即可显示批量推理正在进行中。返回信息如下:
[Poll #27] 2025-11-21 00:36:44
======================================================================
Batch Inference Job Status
======================================================================
>>> STATUS: InProgress <<<
Job Information:
Job Name: nova-mme-embedding-20251121-002057
Job ARN: arn:aws:bedrock:us-east-1:133129065110:model-invocation-job/x4zk6curm64m
Submit Time: 2025-11-20 16:21:00.456000+00:00
Last Modified: 2025-11-20 16:36:39.822000+00:00
Processing Statistics:
Total Records: 641
Processed Records: 641
Success Records: 641
Error Records: 0
Input Tokens: 0
Output Tokens: 0
Progress: 100.0% (641/641)
Output Location: s3://nova-mme-demo-batch-result/output/
======================================================================
Next check in 30 seconds...
再等待一段时间,任务完成。
[Poll #29] 2025-11-21 00:37:47
======================================================================
Batch Inference Job Status
======================================================================
>>> STATUS: Completed <<<
Job Information:
Job Name: nova-mme-embedding-20251121-002057
Job ARN: arn:aws:bedrock:us-east-1:133129065110:model-invocation-job/x4zk6curm64m
Submit Time: 2025-11-20 16:21:00.456000+00:00
Last Modified: 2025-11-20 16:37:25.407000+00:00
Processing Statistics:
Total Records: 641
Processed Records: 641
Success Records: 641
Error Records: 0
Input Tokens: 0
Output Tokens: 0
Progress: 100.0% (641/641)
Output Location: s3://nova-mme-demo-batch-result/output/
======================================================================
Cleaning up input JSONL files...
(No JSONL files found to clean up)
✓ Job completed successfully!
Next step: uv run 03_load_result_to_s3_vector_bucket.py
现在结果存储桶内的Output目录内、以任务ID为子目录,会生成一个JSONL.out文件,在这个多行JSON文件中,每一行是一个图片对应的向量。接下来进行所谓的后处理过程,也就是把批量推理后的结果加载到对应的向量数据库中。写入过程会顺带设置metadata,在本文的例子中,使用图片在S3原始路径作为Metadata信息。您可以修改本文的脚本,将希望的字段写入metadata。
现在执行后处理脚本,运行03_load_result_to_s3_vector_bucket.py启动任务。
uv run 03_load_result_to_s3_vector_bucket.py
返回结果如下:
======================================================================
Bedrock Batch Inference - Load Results to Vector Bucket
======================================================================
Loaded job info from batch_job_info.json
Job Name: nova-mme-embedding-20251121-002057
Job ARN: arn:aws:bedrock:us-east-1:133129065110:model-invocation-job/x4zk6curm64m
Job ID: x4zk6curm64m
Batch Result Bucket: nova-mme-demo-batch-result
Listing output files from s3://nova-mme-demo-batch-result/output/x4zk6curm64m/
✓ Found 1 output files
Downloading output/x4zk6curm64m/batch_input_20251121-002057.jsonl.out...
Processing batch_input_20251121-002057.jsonl.out...
Processed 100 records...
Processed 200 records...
Processed 300 records...
Processed 400 records...
Processed 500 records...
Processed 600 records...
Inserting 641 vectors to S3 Vectors...
Vector Bucket: my-nova-mme-demo-01
Index Name: my-image-index-02-lambda
Batch Size: 100
Delay between batches: 0.5s (rate limiting)
✓ Batch 1: Inserted 100 vectors
✓ Batch 2: Inserted 100 vectors
✓ Batch 3: Inserted 100 vectors
✓ Batch 4: Inserted 100 vectors
✓ Batch 5: Inserted 100 vectors
✓ Batch 6: Inserted 100 vectors
✓ Batch 7: Inserted 41 vectors
✓ Total vectors inserted: 641
✓ Processed batch_input_20251121-002057.jsonl.out
Total: 641, Success: 641, Error: 0
======================================================================
Summary
======================================================================
Total Records Processed: 641
Successful: 641
Errors: 0
Vectors Inserted: 641
Vector Bucket: my-nova-mme-demo-01
Index Name: my-image-index-02-lambda
======================================================================
✓ Results loaded successfully!
You can now query the vector bucket.
加载数据到S3存储桶成功。
接下来运行04_remove_completed_task.py删除运行以上过程中本地生成的临时任务文件,以及云端S3原始数据存储桶内的JSONL文件清单。否则可能会导致重复处理。执行命令如下:
uv run 04_remove_completed_task.py
返回结果如下:
======================================================================
Bedrock Batch Inference - Remove Completed Task Files
======================================================================
Loaded job info from batch_job_info.json
Job Name: nova-mme-embedding-20251121-002057
Job ID: x4zk6curm64m
Removing local files...
✓ Deleted: batch_input_20251121-002057.jsonl
✓ Deleted: batch_job_info.json
Removing S3 JSONL files from s3://nova-mme-demo-source-image/2024/...
✓ Deleted: s3://nova-mme-demo-source-image/2024/batch_input_20251121-002057.jsonl
======================================================================
Cleanup Summary
======================================================================
Local files removed: 2
S3 JSONL files removed: 1
======================================================================
✓ Cleanup completed successfully!
Task files have been removed from local and S3.
删除成功。
现在即可对S3向量存储桶发起查询了。查询的过程使用Nova MME模型进行文搜图、图搜图,使用方法和演示代码在之前的文章中介绍过,这里不再展开。
七、参考文档
Bedrock batch inference 批量推理官方文档
https://docs.aws.amazon.com/bedrock/latest/userguide/batch-inference.html
最后修改于 2025-11-21