使用 AWS Network Firewall 检测带有 NAT 的出站流量
本文介绍了在 VGW + Site-to-Site VPN + BGP 模拟 DX 专线的基础上,为云上 VPC 新增 IGW 与 NAT Gateway,并通过 AWS Network Firewall 同时审查 IDC 与云端 VPC 之间的东西向流量、以及云端 VPC 去往互联网的南北向出站流量。文中给出 CloudFormation 一键部署的环境、采用「先 NFW 后 NAT」以保留真实源 IP 的路径设计,以及围绕默认 Drop Established 动作、流异常处理、闲置超时、7 层域名规则与 pass 兜底写法的配置实践。
使用 AWS Network Firewall 检测带有 NAT 的出站流量
本方案在 nfw-vgw-demo 的基础上 fork 而来。原有架构的架构中,已经搭建好的部分包括 VGW + Site-to-Site VPN + BGP 用于模拟 IDC 到云端的 DX 专线,NFW 负责检测 IDC 和云上 VPC 之间的流量。本方案在原有架构保留的基础上,为云端 VPC 增加了自己的 Internet Gateway 和 NAT Gateway,使云上 EC2 具备互联网出口,并且新增 NFW 对云上 VPC 去往互联网出站流量进行审查。
与原 nfw-vgw-demo 的差异:本方案的出站检查路由(南北向)由 CloudFormation 模板在创建时自动生效,创建完成后 NFW 立即开始扫描出站互联网流量,无须手工配置。模拟 IDC 到云上 VPC 的路由(东西向)则与原方案 CloudFormation 模版保持一致,即创建完毕后流量默认不经过 NFW 检测,需手工修改路由表将流量送往 NFW 才会检测流量。
全文技术术语缩写与原方案保持一致:
| 全称 | 简称 |
|---|---|
| Network Firewall | NFW |
| Internet Gateway | IGW |
| NAT Gateway | NAT |
| Transit Gateway | TGW |
| Direct Connect | DX |
| CloudFormation | CFN |
| Virtual Private Gateway | VGW |
| Border Gateway Protocol | BGP |
在云上创建好的资源名称使用如下简写:
| 全称 | 简称 |
|---|---|
| Availability Zone | az |
| Route Table | rt |
| Private | prv |
| Network Firewall | fw |
一、新增去往互联网的 NAT 时架构设计思路
1、是否需要多个 NFW 和 多个 Endpoint 的思考
首先定义流量方向:
- 东西向:水平方向,指 VPC 和 IDC 之间,或者多个 VPC 之间。本文特指 IDC 到 VPC。
- 南北向:垂直方向,指 VPC 去互联网,从互联网入 VPC。本文特指仅检查从 VPC 去互联网的出站流量。
本方案的南北向流量中,云上 VPC 目前没有从互联网入站的流量(没有 ELB,EC2 也没有 EIP),因此 NFW 只检测 EC2 主动发起、去往互联网方向的出站流量。在此情况下,东西向和南北向的检测可共用一套 NFW ,也就是一个创建一个统一的 NFW Profile,在 NFW Rule Group 部分,分别填写东西向和南北向需要的扫描规则即可,这些规则因为有不同的源/目标 IP 地址,因此规则之间不会冲突。
于此同时,因为检测的流量是从 VPC 去往互联网出站的,没有涉及到从互联网通过 ELB 入站的流量,因此每个 AZ 只需 1 个 NFW Endpoint 即可承载检测。当以后架构中增加了 ELB,并需要检测从互联网入站的流量,那么出于要保留 source IP 的要求,在每个 AZ 内就需要 2 个 Endpoint 来分别处理入站与出站。
2、流量通过 NFW 和 NAT 的顺序问题
出站流量经过 NAT 和 NFW,有两种串联顺序,二者的核心区别在于 NFW 看到的源 IP 不同。
(1) 先 NAT 后 NFW(NFW 在 NAT 与 IGW 之间)
流量路径为 EC2 → NAT → NFW → IGW。NAT 先做了 SNAT,把源地址换成了 NAT 的 EIP,因此 NFW 看到的所有出站流量源 IP 都是 NAT 的公网地址,无法区分是哪一台 EC2 发出的。这种顺序会丢失原始 source ip,不利于按业务子网或单机做策略与审计。
(2) 先 NFW 后 NAT(NFW 在 EC2 与 NAT 之间)
流量路径为 EC2 → NFW → NAT → IGW。NFW 先做检查然后流量才抵达 NAT 转换,此时 NFW 中看到的报文源地址仍是 EC2 的私网地址(10.87.114.x / 10.87.113.x),NFW 日志和规则都能看到真实的 source ip,可以基于业务子网精确制定策略。NAT 只在流量离开 NFW 之后才做 SNAT。
(3) 本方案的选择
本方案采用先 NFW 后 NAT。为保持可用区隔离,NAT 与 NFW Endpoint 均按 AZ 成对部署,AZ1 的业务流量只走 AZ1 的 NFW Endpoint 与 AZ1 的 NAT,AZ2 同理,避免跨 AZ 流量与额外费用。
3、本方案新增的资源
本方案在原项目 nfw-vgw-demo 的基础上新增以下资源(均为本 fork 新增,不影响原有 VGW/VPN/BGP 部分):
- 1 个 Internet Gateway:
Inspection IGW - 2 个 NAT 子网(公有):
NAT subnet AZ1=10.87.116.0/28,NAT subnet AZ2=10.87.116.16/28 - 2 个 NAT Gateway(各带 1 个 EIP):
NAT Gateway AZ1、NAT Gateway AZ2 - 2 张 NAT 子网路由表:
nat-rt-az1、nat-rt-az2
子网 CIDR 设计新增:
- 新增 NAT 子网(
10.87.116.0/28、10.87.116.16/28)。
4、路由表设计
以下资源缩写名称代表的含义,请参考本文片头的术语表。
(1) 出站方向路由(从 EC2 出站去互联网)
| 路由表 | 关联对象 | 目的 CIDR | 下一跳 | 说明 |
|---|---|---|---|---|
prv-rt-az1 |
业务子网 AZ1 | 0.0.0.0/0 |
NFW Endpoint AZ1 | 默认去互联网先送 NFW(本模板自动创建) |
prv-rt-az2 |
业务子网 AZ2 | 0.0.0.0/0 |
NFW Endpoint AZ2 | 同上 |
fw-rt-az1 |
防火墙子网 AZ1 | 0.0.0.0/0 |
NAT Gateway AZ1 | NFW 检查后送 NAT 做 SNAT |
fw-rt-az2 |
防火墙子网 AZ2 | 0.0.0.0/0 |
NAT Gateway AZ2 | 同上 |
nat-rt-az1 |
NAT 子网 AZ1 | 0.0.0.0/0 |
Inspection IGW | SNAT 后出公网 |
nat-rt-az2 |
NAT 子网 AZ2 | 0.0.0.0/0 |
Inspection IGW | 同上 |
(2) 出站后回包方向路由(从互联网返回 EC2 )
注意:这里的路由条目是上一步出站流量的回程包,并不是指通过 ELB 或者 EIP 从互联网访问 VPC 内资源的。请注意区分二者定义的区别。
出站后的流量回包报文到达 NAT 完成 D-SNAT 后,目的地址变回 EC2 的私网地址。NAT 子网路由表用一条比本地 10.87.0.0/16 更精确的 /24 路由,把回程流量引回 NFW Endpoint,确保来回都过防火墙:
| 路由表 | 目的 CIDR | 下一跳 | 说明 |
|---|---|---|---|
nat-rt-az1 |
10.87.114.0/24 |
NFW Endpoint AZ1 | 回程引回防火墙(更长掩码优先于 local) |
nat-rt-az2 |
10.87.113.0/24 |
NFW Endpoint AZ2 | 同上 |
NFW Endpoint 完成回程检查后,按防火墙子网路由表的 local 路由把报文直接送回业务子网的 EC2。
注意:在某些特定 NFW 部署方案时,经常需要配置一张所谓的“边缘绑定”路由表,在路由表绑定子网位置,选择边缘绑定,并选择本 VPC 的 IGW,它会负责特定流量的“劫持”和引导。在本方案下,并不需要这种特殊配置。因为 EC2 先经过 NFW 再经过 NAT,最后才通过 IGW。在本方案的 IGW看来,IGW 收到 NAT 发来的正常通信,无须为 IGW 配置边缘绑定的路由表。
(3) 完整流量路径
flowchart LR
EC2["EC2<br/>10.87.114.x"]
NFW["NFW Endpoint"]
NAT["NAT Gateway"]
IGW["IGW"]
NET(["Internet"])
%% 出站方向
EC2 -->|"prv-rt 0.0.0.0/0"| NFW
NFW -->|"fw-rt 0.0.0.0/0"| NAT
NAT -->|"nat-rt 0.0.0.0/0"| IGW
IGW --> NET
%% 回程方向
NET -.-> IGW
IGW -.->|"D-SNAT"| NAT
NAT -.->|"nat-rt 10.87.114.0/24"| NFW
NFW -.->|"fw-rt local"| EC2
linkStyle 0,1,2,3 stroke:#2e7d32,stroke-width:2px
linkStyle 4,5,6,7 stroke:#1565c0,stroke-width:2px在上图中,实线(绿色)为出站方向 EC2 → NFW → NAT → IGW → Internet。虚线(蓝色)为回程方向 Internet → IGW → NAT(de-SNAT) → NFW → EC2。来回都经过 NFW,保证有状态检测对称。
5、新增南北向检测与原有东西向流量检测不冲突的说明
原方案的 CloudFormation 拉起后,去往 IDC 方向(东西向)流量默认不经过 NFW,如果要检测需要手工调整路由表将流量送往 NFW。本方案的 CloudFormation 拉起后,也遵循这个原则,这与之前的模版行为保持一致。那么如何区分东西向流量还是南北向流量呢?是通过路由表中下一跳目标地址来确定。下一跳是 IDC 的 IP CIDR,则属于东西流量,写为 0.0.0.0/0 则表示去往互联网任意地址,属于南北向流量。
在 CloudFormation 启动完成后,在云上的 VPC 的防火墙子网与业务子网,与原方案一样开启了 VGW 路由传播。BGP 传播过来的 IDC 网段(10.0.0.0/16、10.132.66.0/24)掩码比 0.0.0.0/0 更精确,因此去 IDC 的东西向流量仍走 VGW,只有去互联网的默认流量才会命中本方案新增的 0.0.0.0/0 → NFW → NAT 路径。
6、设计小结
以上几个话题讨论完毕。到这里,我们已经有了完整路由表设计,现在使用 CloudFormation 构建新的环境。
二、使用 CFN 模板启动环境
1、获得模版
本方案使用的 CloudFormation 模板位于 Github 这里:https://github.com/aobao32/nfw-vgw-and-nat-demo/tree/main/cloudformation
该模板在原 nfw-vgw-demo 模板基础上 fork,新增了 IGW、NAT 子网、NAT Gateway、NAT 路由表,以及出站域名拦截规则,并自动写好出站检查路由。创建完成后即可直接验证 NFW 对出站流量的检测,无须手工配置路由。
2、创建前置条件
注意:必须有 EC2 KeyPair 存在,否则模版创建失败。
- 在目标区域已有一个 EC2 密钥对(
KeyPairName参数引用,用于 EC2 SSH,本方案登录主要用 SSM) - 账号默认 VPC、EIP 配额足够:本模板新建 2 个 VPC,新建 3 个 EIP,分别是 strongSwan 1 个 + NAT 2 个
- 登录 AWS 控制台的 IAM User 具备使用 CloudFormation 以及创建 VPC、NFW、NAT、IAM、Lambda、CloudWatch Logs 的权限
3、创建步骤
-
- 进入 CloudFormation 控制台,选择创建 Stack,上传模板
vpc-dual-az-vgw-vpn-bgp-nfw-nat-create.yaml
- 进入 CloudFormation 控制台,选择创建 Stack,上传模板
-
- 填写 Stack 名称,从本 AWS 账号现有的 EC2 密钥下拉框中,选择登录新创建 EC2 的
KeyPairName,其余参数可用默认值(其中 VPN 预共享密钥建议改为自定义密钥)
- 填写 Stack 名称,从本 AWS 账号现有的 EC2 密钥下拉框中,选择登录新创建 EC2 的
-
- 在权限确认页面勾选允许创建 IAM 资源,提交创建
-
- 等待约 20-30 分钟,Stack 状态变为
CREATE_COMPLETE
- 等待约 20-30 分钟,Stack 状态变为
也可使用 CLI 创建(也需要等待 20-30 分钟):
aws cloudformation create-stack \
--stack-name nfw-nat-demo \
--template-body file://cloudformation/vpc-dual-az-vgw-vpn-bgp-nfw-nat-create.yaml \
--parameters ParameterKey=KeyPairName,ParameterValue=<你的密钥对名称> \
--capabilities CAPABILITY_IAM
4、创建完成后的状态
- CloudFormation 显示 Stack 创建完成
- NFW 已创建并就绪,两个 AZ 的 NFW Endpoint 已生成
- 出站检查路由已由模板自动写入
prv-rt、fw-rt、nat-rt - NFW 策略采用严格顺序(STRICT_ORDER),规则优先级为:
- 优先级 1:
block-idc-http,丢弃 IDC → 云端业务子网 TCP/80(继承自原方案) - 优先级 2:
block-egress-domain,丢弃云端去往特定域名的 HTTP/HTTPS 出站(本方案新增,用于演示出站检测) - 优先级 100:
allow-all,放行其余流量(放行已建立的 TCP「客户端→服务器」方向、以及 UDP、ICMP)
- 优先级 1:
注意:CloudFormation 显示绿色后,VPN 隧道与 BGP 会话可能还需要再等 5-10 分钟才完全建立。出站互联网检测不依赖 VPN/BGP,可立即验证;IDC 东西向相关验证需等待 BGP 收敛。
三、验证 NFW 对出站流量的检测工作正常
1、登录 EC2 执行命令
云上业务 EC2 位于私有子网,通过 SSM Session Manager 登录(VPC 内已部署 SSM 接口终端节点,无须公网登录)。
-
- 进入 EC2 控制台,选择
Workload AZ1 (inspection)或Workload AZ2 (inspection)
- 进入 EC2 控制台,选择
-
- 点击
Connect→ 选择Session Manager标签页 → 连接
- 点击
登录后执行以下命令验证出站检测效果:
# 1) 访问被拦截的域名 google.com —— 预期返回失败/超时(匹配 block-egress-domain 规则)
curl -v --max-time 10 http://google.com
curl -v --max-time 10 https://google.com
# 2) 访问其他域名 —— 预期返回成功(匹配 allow-all 规则,经 NFW 检查后放行出网)
curl -v --max-time 10 https://aws.amazon.com
# 3) 查看本机出站公网 IP —— 返回的是 NAT Gateway 的 EIP,证明流量经过了 NAT
curl -s --max-time 10 https://checkip.amazonaws.com
预期结果:
- 访问
google.com的 HTTP 与 HTTPS 均被 NFW 丢弃(连接超时或被重置) - 访问其他域名正常返回,说明默认放行的出站流量经 NFW 检查后通过 NAT 出网
checkip返回的公网 IP 等于NatEIPAZ1Address/NatEIPAZ2Address(见 Stack 的 Outputs),证明出站路径确实是EC2 → NFW → NAT → IGW
2、查看 NFW 日志
进入 CloudWatch 控制台 → 日志 → 日志组,查看以下两个日志组(<stack-name> 为你的 Stack 名称):
/aws/network-firewall/<stack-name>/flow:所有连接的流日志,可看到出站连接的源(EC2 私网 IP)、目的、端口/aws/network-firewall/<stack-name>/alert:命中 alert/drop 规则的事件日志
查看 NFW 审查的日志:
- 在
flow日志中,出站连接的源地址应为业务 EC2 的私网地址(10.87.114.x/10.87.113.x),证明 NFW 在 NAT 之前就看到了真实 source ip - 在
alert日志中,应能看到访问google.com被丢弃的记录,event.alert字段包含Block egress ... to google.com - 可用 Logs Insights 进一步检索,例如按
event.alert.signature或源/目的 IP 过滤
完成以上验证,即可确认 NFW 正确检测并按策略拦截了云上 EC2 的出站互联网流量。
四、NFW 配置中的参数和规则设计讨论
本章节探讨下 NFW 使用过程中一些参数的选择和规则的设置。
1、NFW 的 Stateful 默认规则的选择
2026 年 6 月,AWS 调整了新创建的 Stateful 规则的默认动作,从过去默认的 Application drop established (bidirectional) 更换为 Application drop established (server-directed only)。由此提升了一些复杂规则场景下的健壮性和稳定性。
以一个 7 层过滤规则的场景为例,以前使用 Application Drop established(双向,bidirectional) 默认规则时候,当客户端和服务器端双方开始进入 TCP 的握手步骤时候,还没有传输 SNI 信息。由于不知道要访问的域名,此时 NFW 防火墙的 7 层域名过滤放行规则还没有生效。此时服务器向客户端发出一些典型的流量控制规则:
- TCP window updates(服务端通告窗口变化)
- TCP keep-alives(保活探测)
- TCP resets / RST(服务端主动断开)
遇到这些数据包时,由于后续包含 7 层访问请求的规则尚未被触发,NFW 会判定当前数据包是没有匹配到任何一条 PASS 规则,因此就会按照没有匹配的行为丢弃这些服务器流控包,导致用户访问过程出现偶发卡住、偶发中断、长连接掉线等行为。此时日志中看不到记录,因为此时还没有进入完整的 Stateful 规则处理,拦截这些流控包的不是 Stateful 匹配的 7 层域名规则,而是防火墙默认行为。因此,使用 Application drop established (server-directed only) 这个规则,可以很好的适配 7 层 URL 规则场景。
此外,选择 Drop established 也能满足放行服务器端发来的流控包的条件,但是在进行 7 层检测时候,如果遇到 SNI 和 Host 检测被触发之前服务器端发来的分段的 HTTP 请求,可能会被 NFW 丢弃。因此如果有 7 层检测规则,不建议使用 Drop established。
根据以上信息,本方案使用 Application drop established (server-directed only) 作为默认规则。
2、不完整包的处理规则
在 NFW 的策略(Policy)页面中,创建策略时候有个选项是:
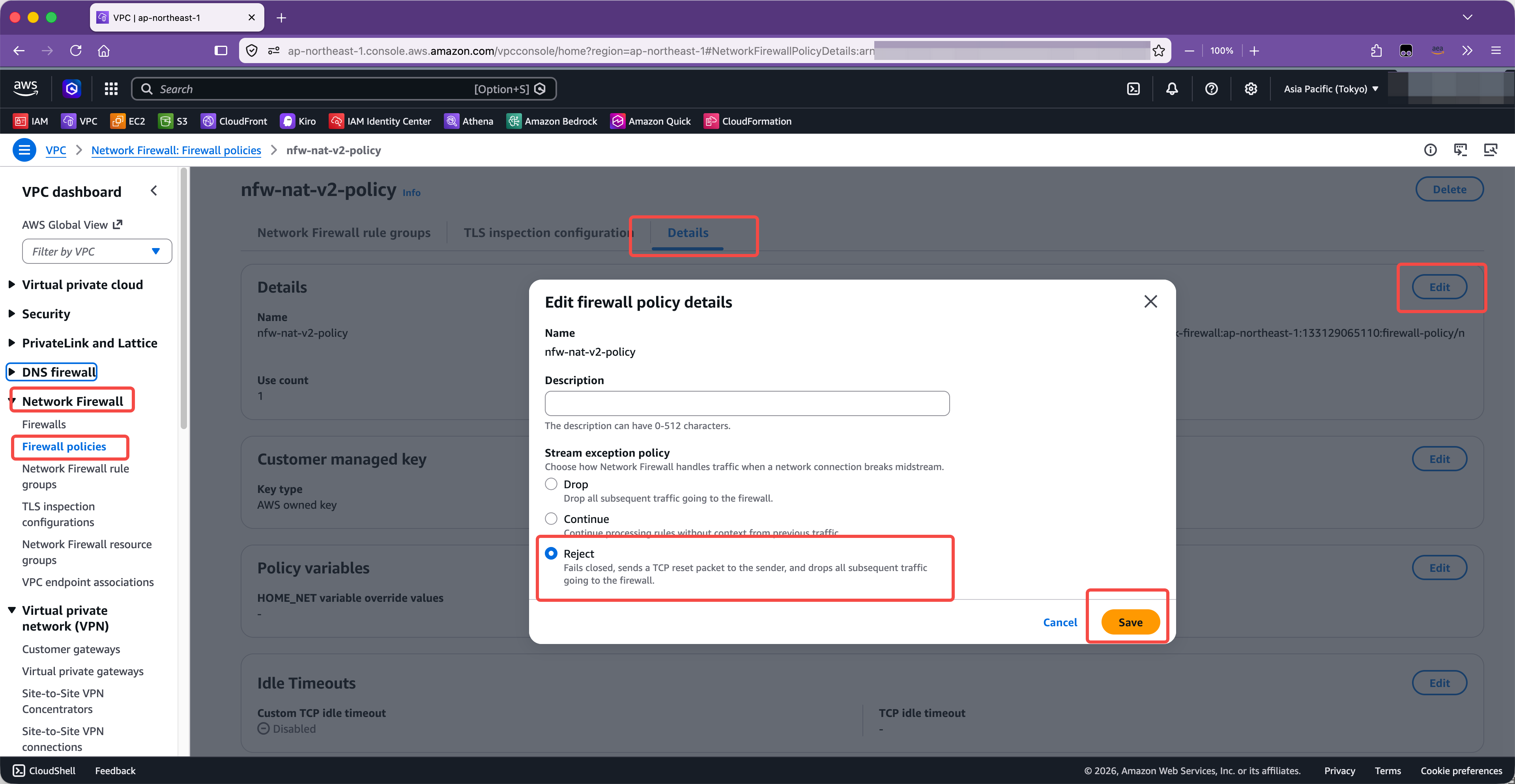
这里解释这个参数的作用。NFW 的有状态引擎(Suricata)会为每条 TCP/UDP 连接维护一个会话上下文(state/flow context),记录这条流从握手开始的协议识别结果、方向、应用层协议等信息,规则匹配很多时候依赖这个上下文。而 Stream exception policy 指当收到不完整的包或者现有流丢失或断裂时(midstream break),后续到达防火墙的报文该怎么处理。例如,当 NFW 引擎触发了 AZ 切换/自身容量缩放等导致连接中断,或者是流量来回双向路由不对等走了不同的路径,此时防火墙收到了不完整的包,此时针对后续继续发过来的流量,防火墙采取丢弃/放行/拒绝哪一种行为。
三个选项功能如下:
- 丢弃:防火墙丢弃不完整的流后续的包。这通常导致客户端不知情并卡住,直到客户端自己 timeout 才会重新传输
- 继续放行:可能会导致某些流量本该被拦截,但是继续通过了 NFW
- 拒绝:NFW 向客户端发出 TCP RST 包,客户端会立即收到重置,并重新建立连接,重新发送完整整个流完整的包
以上选项,默认是丢弃(Drop),建议修改为 Reject 拒绝,这样遇到类似场景,客户端会主动重新连接,不会影响连接质量。
3、闲置超时的配置修改
NFW 对于长连接的管理是需要特别注意,由于防火墙不可能维护无限数量的长连接,其引擎能处理的连接数有限,因此会自动关闭处于闲置状态的长连接。而应用软件在维护长连接时候,经常会隔一段时间发送 Keepalive 包,宣称自己的长连接并不是闲置的,以此要求 NFW 维护客户端和服务器之间的长连接。
默认 NFW 的闲置超时是350秒。如果应用层发送 Keepalive 包间隔比较长,例如每 10 分钟(600秒)才发送一次 Keepalive 包,那就会出现问题,还没等应用程序自己确认存活,NFW 就把连接判定为空闲而关闭了。这种情况下,如果客户端还继续发送包,就会被 NFW 引擎 Drop 掉。
针对长连接闲置超时,此时有两种处理办法:
- (1) 将应用程序或者客户端/服务器端操作系统发送 Keepalive 包的间隔调小,即调整到 350 秒以下,让双方频繁发送探活包,以维持长连接存活
- (2) 将 NFW 判定闲置超时的窗口从 350秒 调高,例如设置到1200秒。
针对第一种调整客户端的处理办法,MySQL/PostgreSQL 数据库连接池、SSH、WebSocket、HTTP 2.0、RPC调用等长连接,建议在应用层或者应用程序所在的 OS/容器层面开启 Keepalive,确保过一会能自动发送探活包。
针对第二种调整 NFW 闲置超时,方法如下。进入 NFW 的策略编辑菜单,切换到最后一个标签页,详细信息,其中可找到超时设置。如下截图。
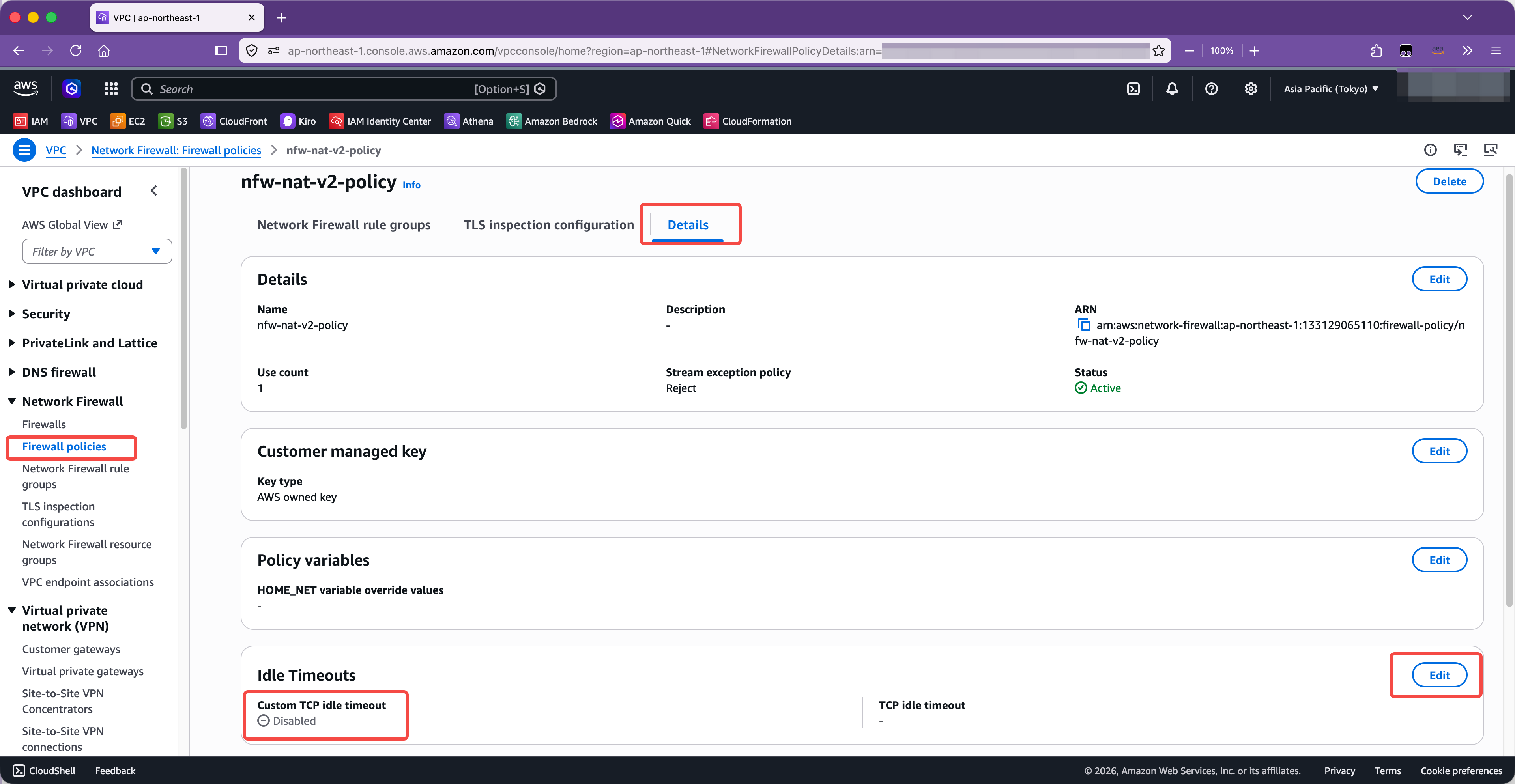
修改为1200秒。如下截图。
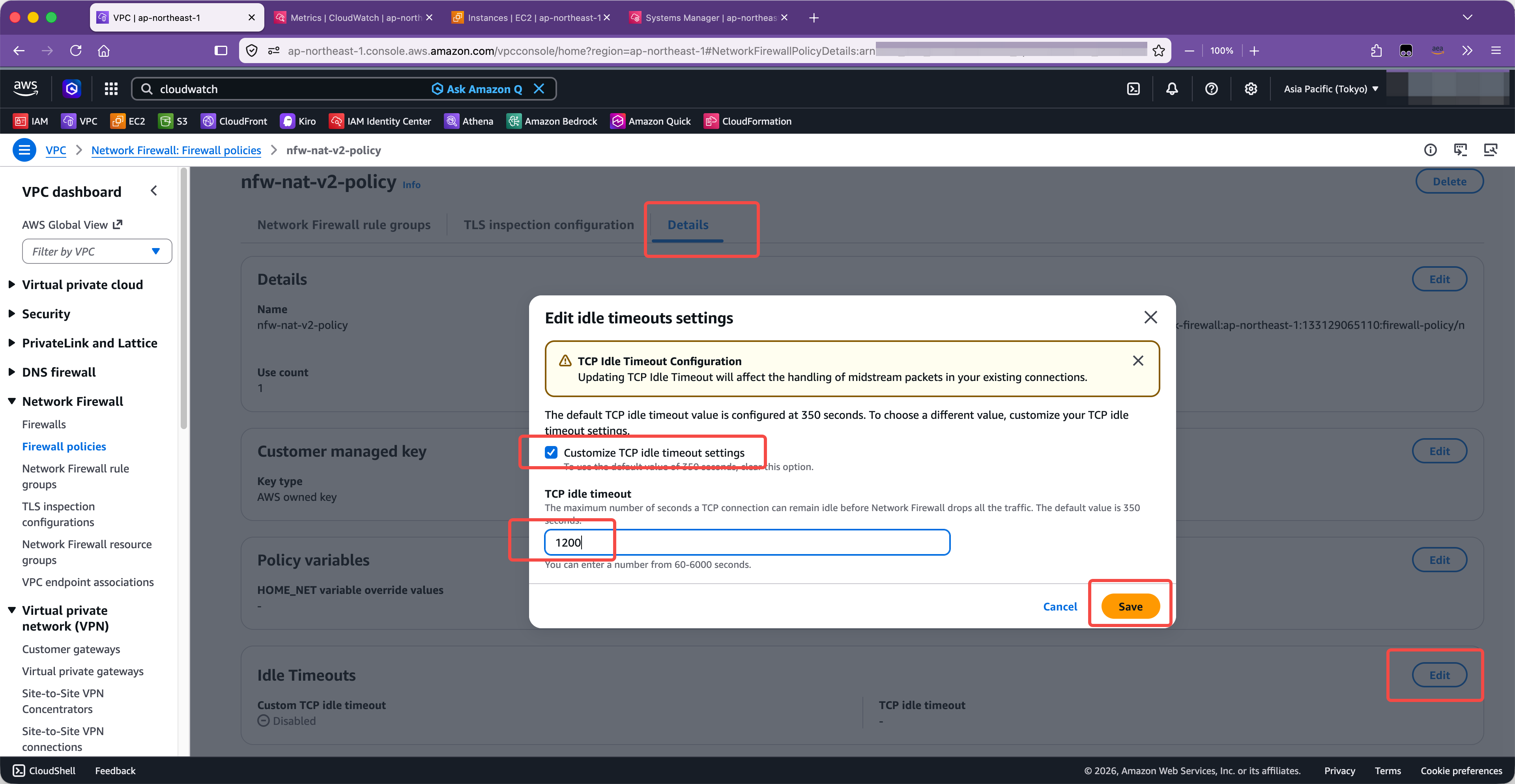
保存后,需要等待几分钟时间,NFW 规则才会生效。
4、检测 7 层域名时的规则写法
在 strict order 模式下做黑名单方式的域名拦截,兜底对其他所有域名都放行规则的写法是关键。
(1) 本方案的规则写法
优先级 1 : drop tcp [IDC] any -> [云端子网] 80 (4层规则的端口拦截)
优先级 2 : drop http/tls ... content:"google.com" (7层规则域名拦截)
优先级 100 : pass tcp any any -> any any (flow:established,to_server; ...)
pass udp any any -> any any
pass icmp any any -> any any
策略默认动作: aws:drop_established_app_layer_to_server
以上规则可以看到,放行的写法是带有额外参数的,如果只写简单 pass,那么过滤域名的检测规则就会失效。
(2) 为什么不是简单 pass_all 而是 pass 后必须加 flow:established,to_server 参数
而 Suricata 对 pass 的语义是:流中任一个包命中 pass,整条流后续包直接放行、不再过规则。如果优先级 100 写成 pass ip any any,那么针对被拦截域名的访问流量就会出现如下场景:
- 客户端发来 SYN 包,优先级 1 的 4 层规则没匹配上,继续下一条规则
- SYN 包只有 4 层信息是不含 7 层请求域名信息的,因此优先级为 2 的规则虽然想过滤域名,但现在检测不到,继续下一条规则
- 优先级 100 的兜底规则命中并触发整流放行
由此可以看到,一旦写了整体 pass 的规则,整个流都放行了,这个流后面的带 Host 的 HTTP GET 包根本进不了规则引擎,优先级为 2 的域名过滤黑名单规则的 drop 操作永远不会被匹配。
当给 pass 加上 flow:established,to_server 参数后,整体放行规则只发生在「连接已建立 + 客户端→服务器」的应用层数据包上才匹配,而不是从像刚才那样 SYN 开始就完全放行。此时域名 drop(优先级 2)和兜底 pass(优先级 100)是在同一个检查序列上,优先级小的先生效,由此触发了拦截才真正生效。
注意:端口规则 block-idc-http 不受影响,因为这个规则是 4 层协议,和优先级 2 的 7 层协议不在一个维度。因此无论放行规则的参数怎么写,4 层规则都有效。
(3) 针对 7 层拦截规则、不含域名的 SYN 握手包 NFW 怎么处理
上一个小节讲述到 SYN 规则不含 7 层信息,那么 SYN 是如何被 NFW 处理的呢?当一个 SYN 包没有匹配到任何 4 层规则的时候,NFW 使用策略默认 aws:drop_established_app_layer_to_server 来判断这个包是否放行。
本章节的第一个小节探讨这个默认规则的设置。这个规则是应用层感知的,即先放行3层、4层握手和服务器返回方向,然后仅丢弃「已建立的连接中客户端→服务器方向」没有被规则 pass 放行的包,同时这个默认规则还对分段 TLS ClientHello / HTTP 请求做重组判定。因此选这个默认策略,即可在尚未收到 7 层请求的 SNI、HTTP Host 信息之前,先放行这几个包,再根据整个流后续的包决定是否放行或拦截。由此就不会触发整个流被直接放行或者整个流被完全丢弃的场景了。
以上几个章节是对 NFW 规则配置的一些详细探讨。
五、清理环境
在实验结束后,需要清除实验环境。进入 CloudFormation 服务,直接删除 CloudFormation Stack 即可。模板内置的 Lambda 自定义资源会在删除前自动清理指向 NFW Endpoint 的路由,可避免「related VPC endpoint(s) still exist in route table(s)」导致防火墙删除失败。
六、参考文档
带有 Internet Gateway 和 NAT Gateway 的 NFW 架构
组合 Ingress 与 Egress 检测时的源 IP 可见性
使用 NAT Gateway 与 Network Firewall 实现集中式 IPv4 出站
2026年6月起 NFW 调整新创建的 Stateful 规则的默认动作
Managing evaluation order for Suricata compatible rules in AWS Network Firewall
最后修改于 2026-06-29