通过 NFW 的 Flow 日志观察长连接的 Idle Timeout 闲置超时并通过修改操作系统的 Keepalive 设置维持长连接
本文介绍了 AWS Network Firewall(NFW)对长连接闲置超时(Idle Timeout)的处理机制,并给出排查与解决方案。通过实际搭建 SSH 长连接测试环境,验证了 NFW 默认 350 秒的闲置超时如何导致连接被静默切断,并演示了如何通过 CloudWatch Flow 日志(控制台查询、AWS CLI 脚本、CloudShell 三种方式)定位闲置超时事件。解决方案部分从调整 NFW 超时参数、修改应用程序(以 SSH 为例)配置文件、调整操作系统 SO_KEEPALIVE 三个层面展开,并整理了 SSH、MySQL、PostgreSQL、Redis、NFS、gRPC 六种常见服务对 Keepalive 的支持情况对比表,供实际排查参考。
通过 NFW 的 Flow 日志观察长连接的 Idle Timeout 闲置超时并通过修改操作系统的 Keepalive 设置维持长连接
一、背景
在之前的两篇博客中,分别是介绍了:
- 使用 NFW 审查 IDC 和云上 VPC 之间的流量(使用 Site-to-site VPN + BGP + VGW 模拟 Direct Connect)
- 使用 NFW 审查 VPC 去往互联网出站方向的流量(使用 NAT Gateway )
这两篇博客,都提供了 CloudFormation 模版,可用于一键拉起实验环境。
在第二篇博客中,还介绍了调整 NFW 长连接超时参数,并且在 CloudFormation 模版中,默认 Idle Timeout 被设置为 1230 秒。本篇稍微展开介绍 NFW 闲置超时的问题。
二、NFW 长连接问题参数设置
NFW 对于长连接的管理是需要特别注意,由于防火墙不可能维护无限数量的长连接,其引擎能处理的连接数有限,因此会自动关闭处于闲置状态的长连接。而应用软件在维护长连接时候,经常会隔一段时间发送 Keepalive 包,宣称自己的长连接并不是闲置的,以此要求 NFW 维护客户端和服务器之间的长连接。
默认 NFW 的闲置超时是 350 秒。如果应用层发送 Keepalive 包间隔比较长,例如每 10 分钟(600 秒)才发送一次 Keepalive 包,那就会出现问题,还没等应用程序自己确认存活,NFW 就把连接判定为空闲而关闭了。这种情况下,如果客户端还继续发送包,就会被 NFW 引擎 Drop 掉。
本文接下来将实际验证 NFW 的闲置超时。
三、以 SSH 远程连接来验证 NFW 闲置超时
以之前【这篇博客】为例,使用这篇博客提供的 CloudFormation 把环境拉起,完成流量通过路由表引导到 NFW,确保流量经过 NFW。然后将 NFW 的 Idle Timeout 从本 CloudFormation 默认的 1200+ 秒调整为 60 秒,便于快速实验。
1、为 IDC 和云上 VPC 之间的流量启用 NFW
在 CloudFormation 模版启动后,模拟 IDC 的 EC2 和云上 VPC 的 EC2 之间的流量是不经过 NFW 的,还需要修改路由表,使得流量被引导通过 NFW。修改方法可以参考之前的【这篇博客】内的路由表配置章节。
2、确认 NFW 启用了 Flow、Alert 两种日志
在 CloudFormation 模版启动后,默认已经开启了 NFW 的 Flow、Alert 两种日志。这里可以进行下二次确认。
进入 VPC 服务,从左侧菜单找到 Network Firewall,进入第一个子菜单 Firewalls,点击右侧的防火墙名称进入,然后在第一个标签页 Firewall details 防火墙详情的位置,向下滚动屏幕。如下截图。
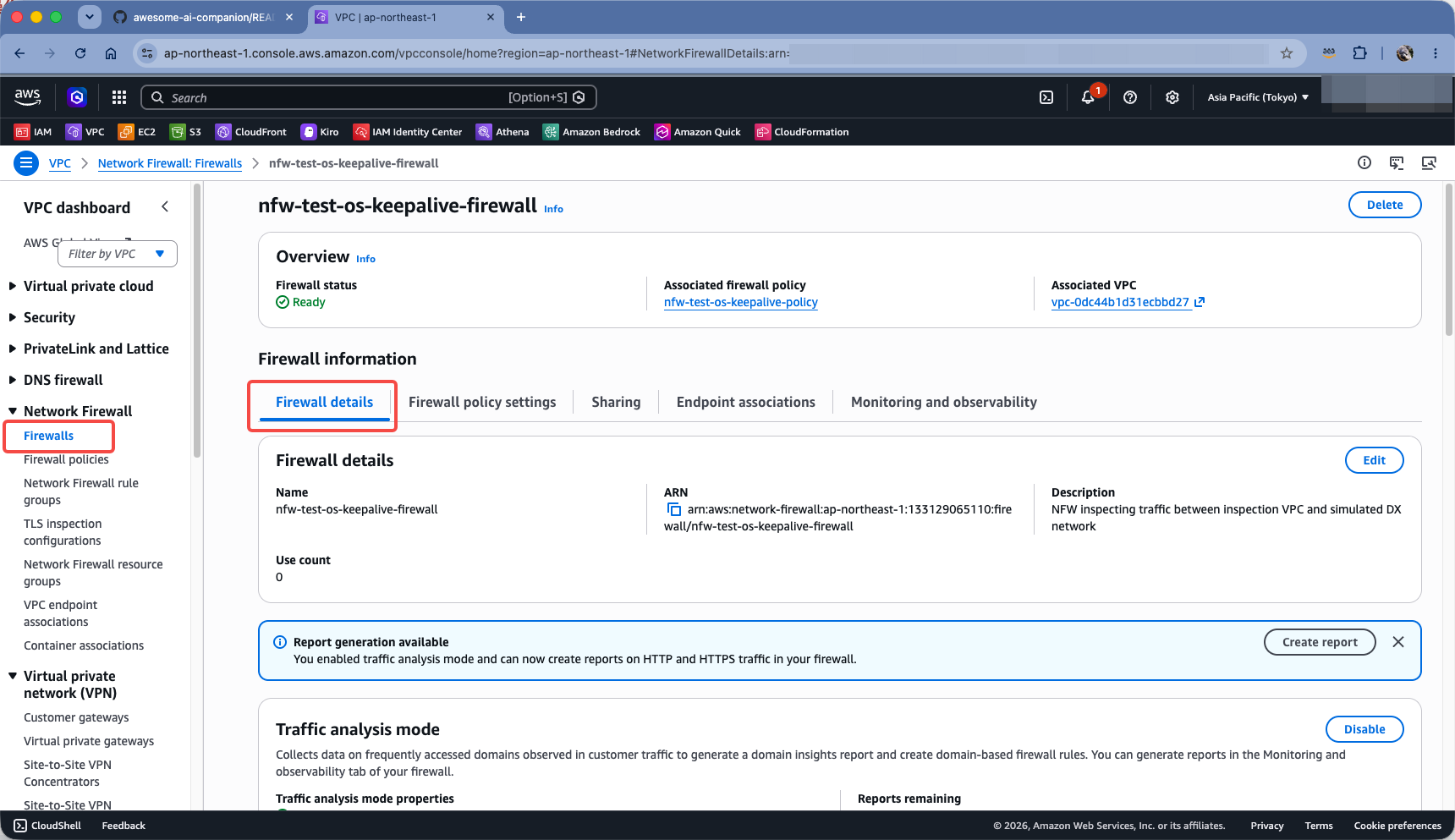
页面向下滚动 2~3 个屏幕后,可看到日志配置。如果 CloudFormation 创建后不曾修改,那么这里已经是开启状态。记录下日志组 Log Groups 的名称。如下截图。
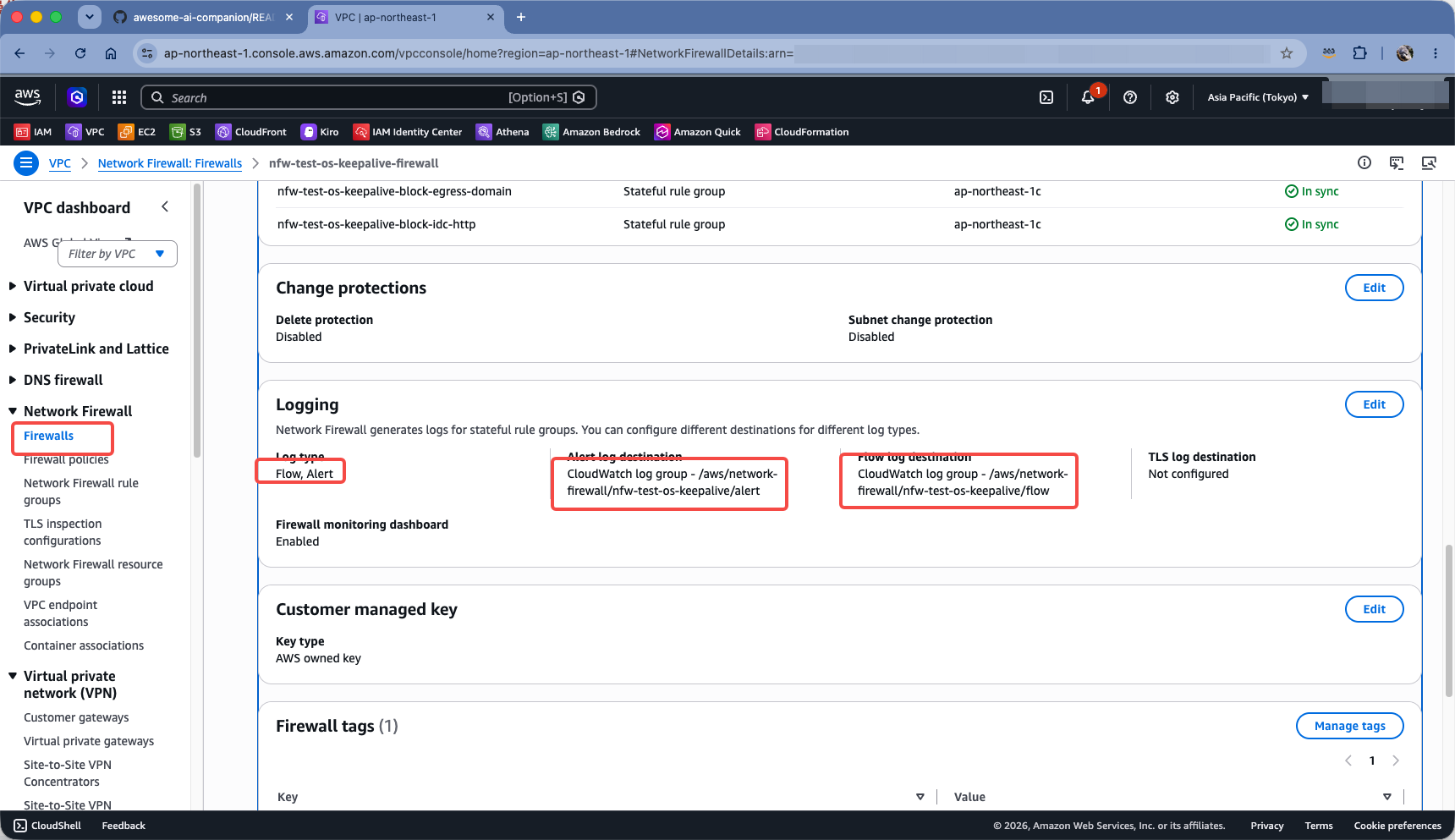
进入 CloudWatch 服务,点击左侧的 Logs 日志菜单,从中找到 Log Management 日志管理菜单,在 Log groups 日志组的搜索过滤框中,输入上一步查询到的日志组名称,即可看到。如下截图。
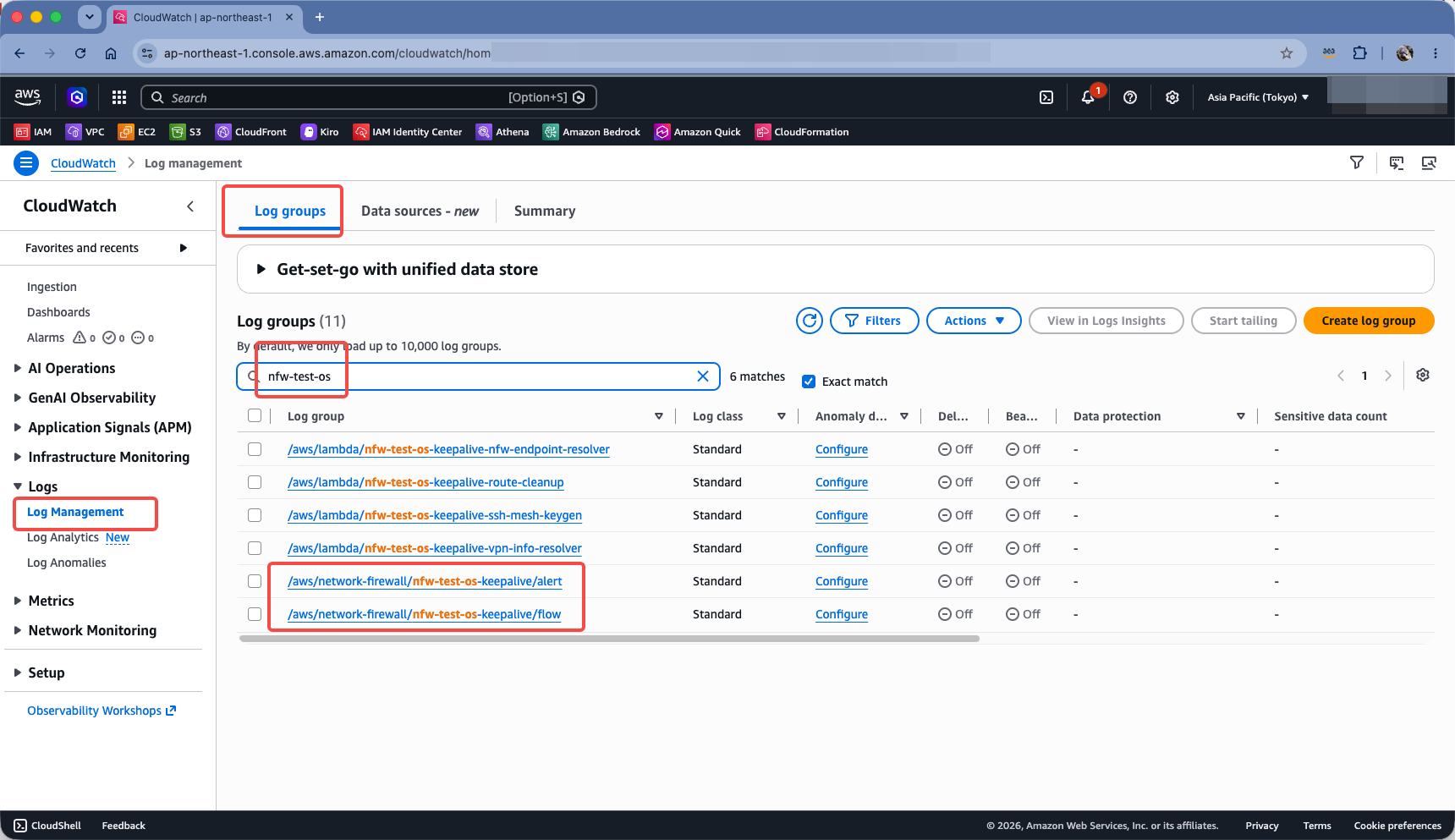
确认日志打开后,现在来模拟连接超时。
3、模拟一个 SSH 访问并闲置 60 秒后触发 Idle Timeout
从云上 VPC 环境的 EC2 用 SSH 登录模拟 IDC 的 EC2。
SSH 登录成功后,等待数秒后,查看 CloudWatch LogGroup 中 NFW 的 Flow 日志,可以看到 SSH 建立成功的记录。
离开 SSH 登录成功的窗口,确保闲置 60 秒以上(在多等几秒确保采样时间),再去 SSH 窗口内,按回车键或者输入命令,可看到 SSH 卡死,按回车也没有反应。如果您等待足够长的时间,等客户端自己多次重试(自动地按照指数退避逐渐增大重试间隔),数分钟后才会收到 client_loop: send disconnect: Broken pipe 的报错信息。
四、NFW 的 Idle Timeout 闲置超时的日志分析
注意:需要确认 NFW 已经启动了 Flow 日志。
1、Idle Timeout 发生时候在 CloudWatch 的 LogGroups 中看到的原始日志
在上一步闲置了 60 秒导致 SSH 卡死的时候,记录下发生的时间,然后进入 CloudWatch LogGroup 中 NFW 的 Flow 日志,查看这个时间范围内的日志,观察可找到类似如下信息:
{
"firewall_name": "nfw-test-os-keepalive-firewall",
"availability_zone": "ap-northeast-1a",
"event_timestamp": "1783175697",
"event": {
"tcp": {
"tcp_flags": "1a",
"syn": true,
"psh": true,
"ack": true
},
"app_proto": "ssh",
"src_ip": "10.87.114.52",
"src_port": 45096,
"netflow": {
"pkts": 154,
"bytes": 17367,
"start": "2026-07-04T14:33:51.321717+0000",
"end": "2026-07-04T14:33:55.871232+0000",
"age": 4,
"min_ttl": 63,
"max_ttl": 63,
"state": "established",
"reason": "timeout",
"alerted": false,
"tx_cnt": 1
},
"event_type": "netflow",
"flow_id": 2226192497599167,
"dest_ip": "10.132.66.200",
"proto": "TCP",
"dest_port": 22,
"timestamp": "2026-07-04T14:34:57.468453+0000"
}
}
以上日志中,关键字段的解读如下:
| 字段 | 值 | 含义 |
|---|---|---|
| tcp.tcp_flags | “1a” (十六进制) | “1a” = 0x02(SYN) + 0x08(PSH) + 0x10(ACK) = 26。RST 位是 0x04,没置位 |
| tcp.rst | 字段缺失 | 若曾出现 RST 应为 true。缺失=false |
| netflow.reason | “timeout” | flow 关闭原因是 idle age-out。不是 “reset”,也不是 “stream_exception” |
| netflow.state | “established” | flow 关闭时的最终 TCP 状态。没有变成 “closed” |
| netflow.alerted | false | Suricata 引擎规则:整条 flow 期间没有触发过任何 stateful rule alert |
2、NFW 处理 Idle Timeout 闲置超时的行为特征
通过以上信息可以获得结论:
- NFW 关闭长连接时候,直接从
established状态关闭,不会进入Closed状态 - NFW 处理 Idle Timeout,是直接回收连接资源,不属于异常流量
stream_exception的包,因此不会触发 RST - NFW 管理连接时候,不会在 Alert 日志中记录,只在 Flow 日志中从长连接发起方向,记录到
"reason": "timeout"的信息,反向不会记录 timeout 信息 - 对已经被回收的长连接,后续两端如果继续发包,NFW 直接丢弃,不属于异常流量
stream_exception的包,不会再补发 RST,同时 Alert 日志中也不会记录
3、从 NFW 的 Flow 日志中批量检索触发了 Idle Timeout 闲置超时的长连接信息
从以上分析闲置超时的日志格式,可以进一步推导出通过日志查找长连接失效的办法,就是搜索 Flow 日志,查找关键字 "reason": "timeout" 的信息。查看方法有两种,一种是通过 AWS 控制台的 CloudWatch 服务界面来执行,另一种是通过 AWS CLI 来执行。
(1) 使用 AWS CloudWatch 控制台上 Log Analytics 的方法
进入 AWS 控制台,进入 CloudWatch 服务,在左侧菜单中,找到 Log Analytics,然后在右侧的 Data sources 检索框中选择 NFW 的 Log Groups 的名字,最后在查询框输入如下代码:
fields event.src_ip as src_ip,
event.src_port as src_port,
event.dest_ip as dst_ip,
event.dest_port as dst_port,
event.app_proto as app,
event.netflow.age as active_age,
event.netflow.pkts as pkts,
event.netflow.bytes as bytes,
event.netflow.start as flow_start,
event.netflow.end as flow_end,
event.timestamp as flow_gc_ts
| filter event.netflow.reason = "timeout"
and event.proto = "TCP"
and event.netflow.state = "established"
| parse flow_start /(?<sh>\d\d):(?<sm>\d\d):(?<ss>\d\d\.\d+)/
| parse flow_end /(?<eh>\d\d):(?<em>\d\d):(?<es>\d\d\.\d+)/
| parse flow_gc_ts /(?<gh>\d\d):(?<gm>\d\d):(?<gs>\d\d\.\d+)/
| fields (gh * 3600 + gm * 60 + gs) - (sh * 3600 + sm * 60 + ss) as total_life,
(gh * 3600 + gm * 60 + gs) - (eh * 3600 + em * 60 + es) as idle_duration
| display total_life, active_age, idle_duration, pkts, bytes, app,
src_ip, src_port, dst_ip, dst_port, flow_start, flow_gc_ts
| sort total_life desc
| limit 20
查询结果如下截图。
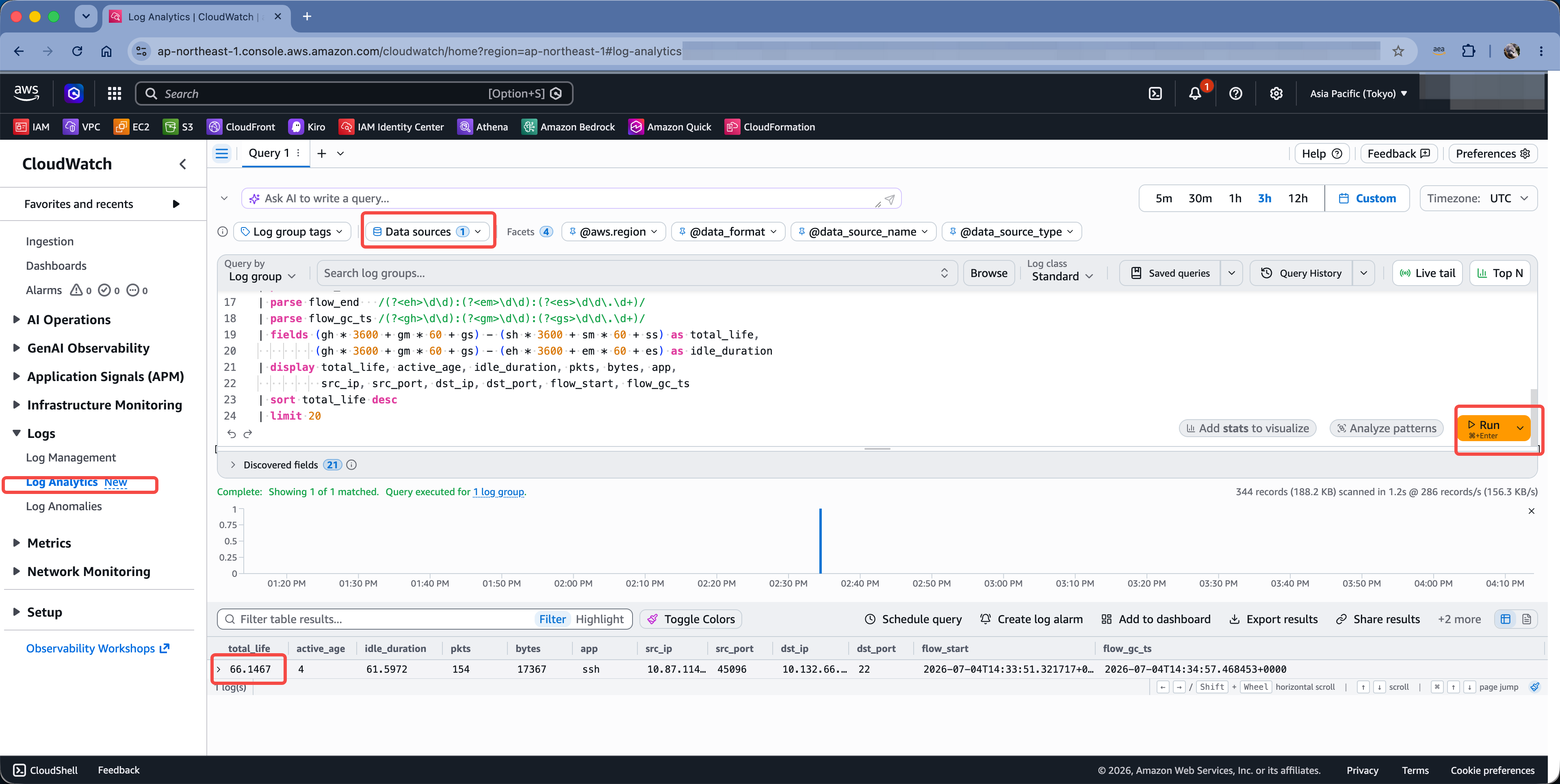
由此就可以查询到近期发生闲置超时的长连接。以上截图中可看到查询时间窗口内有一个闲置超时发生的记录。
(2) 使用 AWS CLI 脚本(运行环境有 AKSK 密钥)
通过 AWS CLI 运行脚本,要求运行环境本机有挂载于 IAM User 下的 AKSK 密钥,才有权限调用 AWS CloudWatch 服务的 API。
从 GitHub 的这里获取脚本:https://github.com/aobao32/nfw-vgw-and-nat-demo/tree/main/ide-timeout-log-analyze
此脚本有几个环境变量可以设置:
- NFW_REGION
- NFW_LOG_GROUP
- NFW_WINDOW_HOURS
- NFW_TOP_N
这些环境变量可以在脚本开头修改,也可以在 shell 上以环境变量方式传入。保存后赋予脚本可执行权限。
执行脚本:
./nfw-idle-report.sh
返回结果如下:
region: ap-northeast-1
log-group: /aws/network-firewall/nfw-test-os-keepalive/flow
window: past 24h
top-N: 20
被 NFW idle timeout 静默切断的 TCP 长连接: 1 条
====================================================================================================================================================
Top 20 明细,按 total_life 排序 (连接从建立到被 NFW 闲置切断的持续时长):
====================================================================================================================================================
total_life active_age idle_duration pkts bytes app src -> dst start evt_ts
66.1s 4.0s 61.6s 154 17367 ssh 10.87.114.52:45096 -> 10.132.66.200:22 2026-07-04T14:33:51 2026-07-04T14:34:57
字段说明:
total_life = 连接总持续时长 (从 flow 建立、到处于活跃、到闲置下来被 NFW 切断, 即 active_age + idle_duration)
active_age = 闲置下来之前,本 flow 的活跃期 (进入闲置前最后一个包的时间 - 第一个包的时间)
idle_duration = 最后一个包 到 NFW 切断的闲置时长 (≈ NFW 配置的 idle_duration 设置 + NFW 采样延迟)
由此即可找到日志中发生了 Idle Timeout 的长连接。
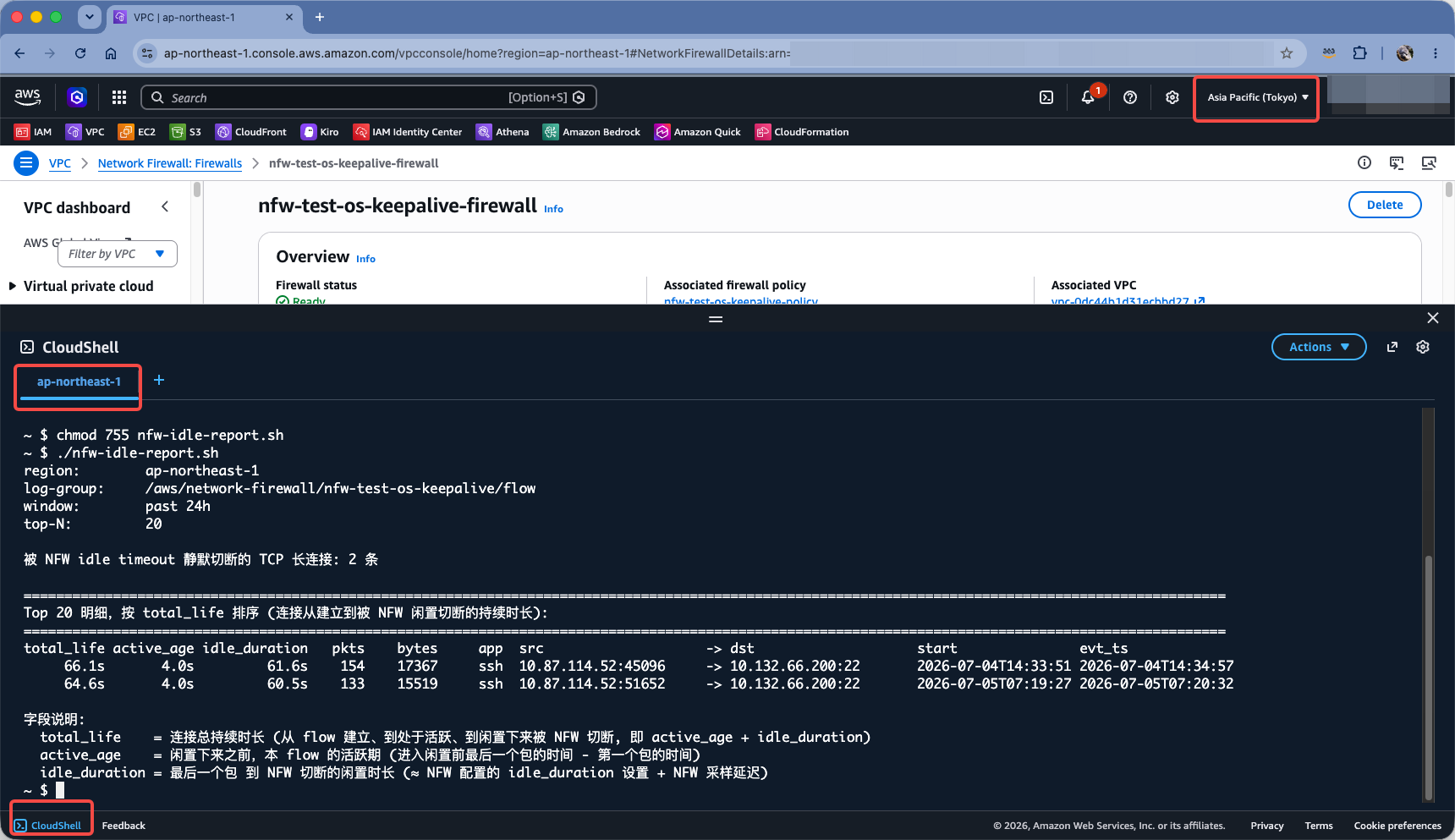
(3) 没有 AKSK 密钥时候直接在 AWS 控制台的 CloudShell 中查询
上一个查询方法,使用 AWS CLI 需要运行环境具备 AKSK 密钥。如果不具备此条件,没有 AKSK 密钥,那么还可以在 AWS 控制台的 CloudShell 网页界面中执行查询。
进入 AWS 控制台,进入 VPC 服务,确认当前 Region 是 NFW 所在 Region,点击页面左下角的 CloudShell,即可打开云上的网页版的终端,并且已经预置了当前操作者的 IAM 权限。当前登录 AWS 控制台的 IAM User 只要有查询 CloudWatch 日志的权限,那么这个 Shell 中的命令也可以查询到。
执行如下命令,下载脚本,添加可执行权限。
wget https://raw.githubusercontent.com/aobao32/nfw-vgw-and-nat-demo/refs/heads/main/ide-timeout-log-analyze/nfw-idle-report.sh
chmod 755 nfw-idle-report.sh
在开始执行之前,还需要编辑下脚本开头的几个设置,包括 Region、CloudWatch Log Groups、查询时间范围、查询条目数等。编辑完毕后,执行如下命令查询:
./nfw-idle-report.sh
查询结果如下截图。
五、解决长连接闲置超时
1、修改长连接双方的配置、或修改 NFW 配置
NFW 默认的长连接超时仅 350 秒,窗口很短,虽然本实验的 CloudFormation 模版创建 NFW 放大到了 1230 秒,但对于很多应用依然不够,还是会因闲置超时而被断开。那么此时有两种处理办法:
- (1) 将 NFW 判定闲置超时的窗口从 350 秒调高,例如设置到 1200 秒,不够可进一步调整到 3000 秒,最大 6000 秒。需要注意,调整 NFW 闲置超时可以显著缓解,但不能 100% 解决所有场景下的闲置超时。要 100% 解决,还需要调整长连接双方的 Keepalive 参数
- (2) 将应用程序或者客户端/服务器端操作系统发送 Keepalive 包的间隔调小,使其低于 NFW 的闲置超时时限,让双方频繁发送探活包,以维持长连接存活
下文分别介绍。
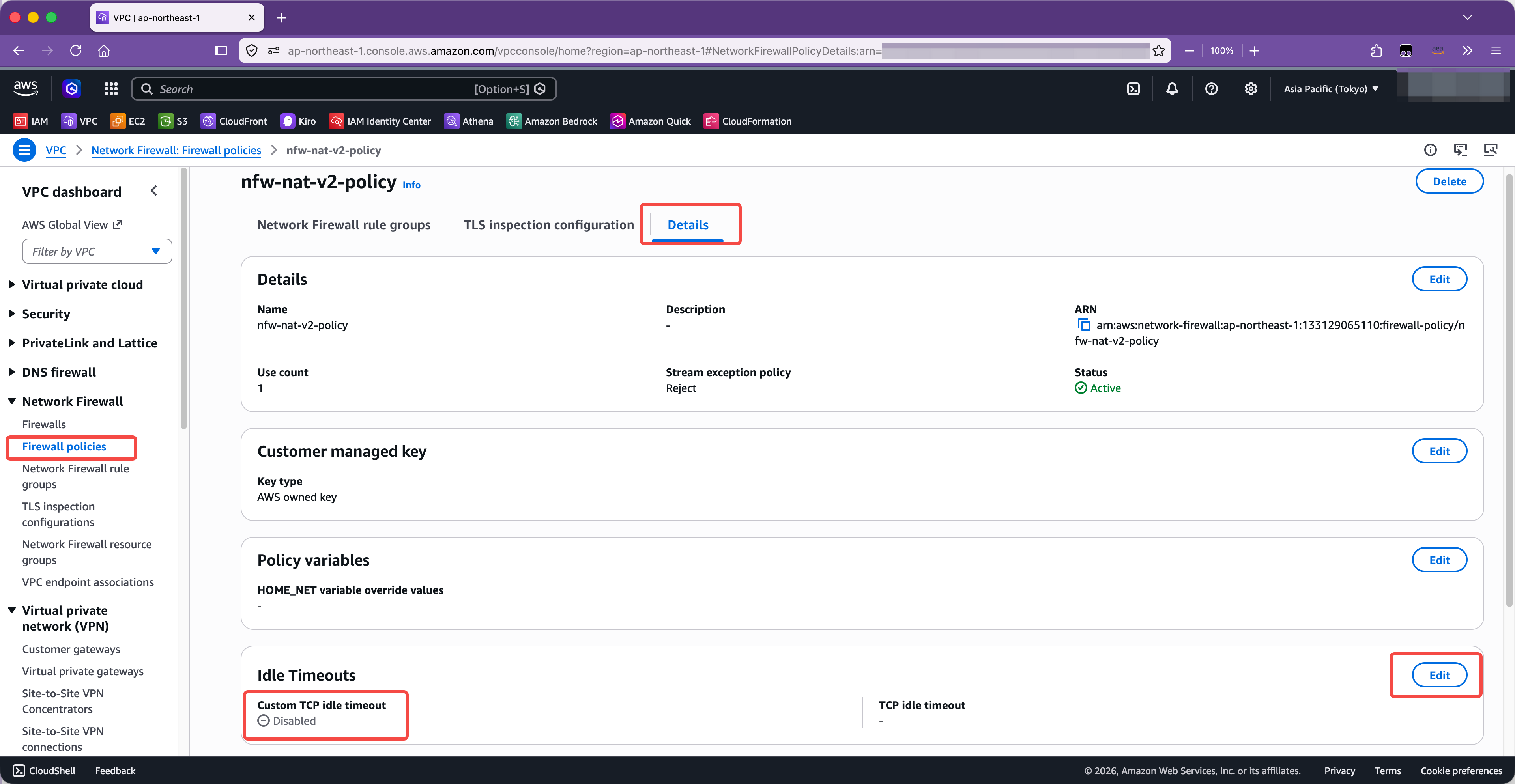
2、调整 NFW 的闲置超时判定时间
调整 NFW 闲置超时,方法如下。进入 NFW 的策略编辑菜单,切换到最后一个标签页,详细信息,其中可找到超时设置。如下截图。
修改为 1200 秒。如下截图。
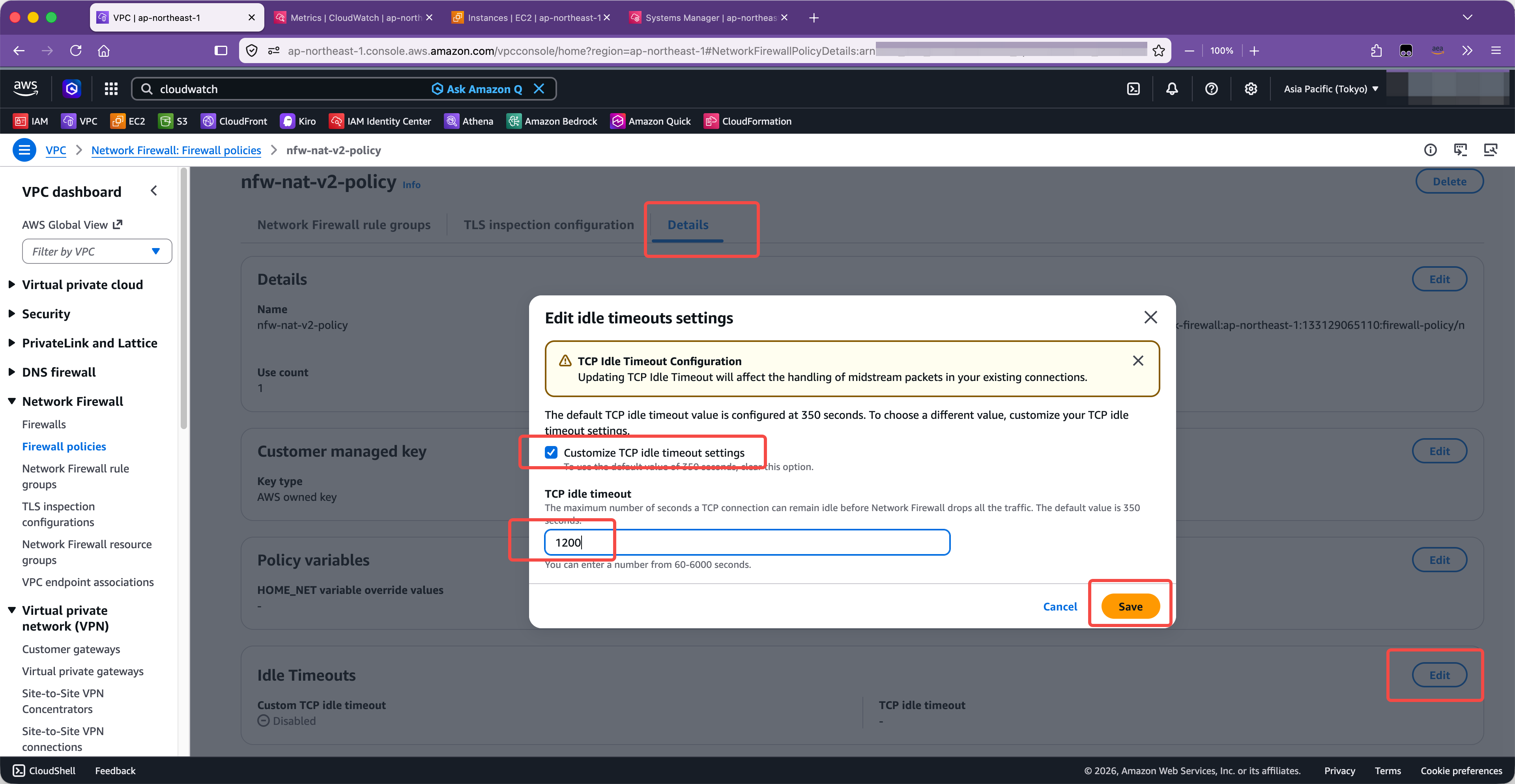
保存后,需要等待几分钟时间,NFW 规则才会生效。
3、调整应用程序客户端/服务器端配置文件中的 Keepalive 设置
除了调整 NFW 的处理办法可获得一定缓解之外,彻底解决闲置超时问题,需要在应用程序上做调整。针对不同应用软件,MySQL/PostgreSQL 数据库连接池、SSH、WebSocket、HTTP 2.0、RPC 调用等长连接,调整方法各不相同,请参考相应软件的文档。
下文以 SSH 为例,SSH 的 Keepalive 分为客户端和服务器端两处配置,两者互相独立,可以只改一侧,也可以两侧都改。
(1) SSH 客户端配置文件
SSH 客户端的配置文件路径是 ~/.ssh/config(仅对当前用户生效)或 /etc/ssh/ssh_config(对本机所有用户生效)。涉及的参数有两个:
ServerAliveInterval:客户端向服务器端发送 Keepalive 探活请求的间隔秒数,默认值是0,表示不发送ServerAliveCountMax:连续发送多少次探活请求都没有收到服务器端响应后,判定连接已经失效并主动断开,默认值是3
编辑 ~/.ssh/config,加入如下配置(如果需要对所有远程主机生效,可以用 Host * 匹配,也可以针对某个具体主机单独配置):
Host *
ServerAliveInterval 45
ServerAliveCountMax 3
以上表示客户端每隔 45 秒(需要小于 NFW 设置的 Idle Timeout)向服务器端发送一次探活请求,连续 3 次(即 135 秒)没有收到响应后主动断开连接。
(2) 服务器端配置文件
SSH 服务器端的配置文件路径是 /etc/ssh/sshd_config。涉及的参数同样有两个:
ClientAliveInterval:服务器端向客户端发送 Keepalive 探活请求的间隔秒数,默认值是0,表示不发送ClientAliveCountMax:连续发送多少次探活请求都没有收到客户端响应后,判定连接已经失效并主动断开,默认值是3
编辑 /etc/ssh/sshd_config,加入或修改如下配置:
ClientAliveInterval 45
ClientAliveCountMax 3
以上表示服务器端每隔 45 秒(需要小于 NFW 设置的 Idle Timeout)向客户端发送一次探活请求,连续 3 次(即 135 秒)没有收到响应后主动断开连接。
服务器端修改配置文件后,需要重启 sshd 服务才能生效:
sudo systemctl restart sshd
配置完毕后,重复之前章节的 SSH 登录并闲置试验,登录成功后什么都不要做,等待超过一次 ServerAliveInterval/ClientAliveInterval 的间隔后,观察 SSH 连接是否仍然活跃,即可验证配置是否生效。
需要注意:客户端和服务器端只要有一侧正确配置了 Keepalive 并生效,就足以让流量定期通过 NFW,防止被判定为闲置连接。两侧都配置属于双重保障,并非强制要求同时修改。
4、调整长连接双方的操作系统 Keepalive 设置
除了在应用系统本身配置 Keepalive 之外,一些应用系统的服务器端会直接调用操作系统 OS 层面的网络层接口,由操作系统负责 Keepalive 维持连接。因此也可以在通信双方的 OS/容器层面开启 Keepalive。
以上文测试的 SSH 连接为例,在不修改 SSH 服务双方的情况下,SSH 客户端默认 ServerAliveInterval = 0,服务器端 ClientAliveInterval = 0,这表示 SSH 的客户端和服务器端都不会定时发送 Keepalive。此时,Linux 操作系统默认是 7200 秒,如果开启了 Linux OS 层面的 Keepalive,Linux 系统会在 7200 秒后才发送第一次 Keepalive 包。由于 NFW 配置范围最小 60 秒、最大 6000 秒,明显小于 Keepalive 包发送间隔,因此 NFW 就判定长连接为闲置,然后中断连接了。如果将 Linux 默认设置修改得更小,那么即可实现操作系统发送 Keepalive 保证连接活跃。
以修改操作系统配置为例,在客户端和服务器端两边的操作系统上,修改 /etc/sysctl.conf,加入如下配置:
net.ipv4.tcp_keepalive_time = 45 # 需要小于 NFW 设置的 Idle Timeout
net.ipv4.tcp_keepalive_intvl = 30 # 需要小于 NFW 设置的 Idle Timeout
以上表示当连接空闲下来没有数据传输时候,等待 45 秒发送第一个 Keepalive 包,然后每隔 30 秒重复发送 Keepalive 包。注意:真实的操作系统环境一般不需要设置得这么小,因为上文为了更快获得长连接闲置效果,将 NFW 的闲置超时调整为了 60 秒,这是为了更快地完成测试。在正常环境中,确保这两个间隔都小于 NFW 配置的空闲超时即可。
配置完毕后,重新加载系统参数,无须重启。
sudo sysctl -p
现在,重复之前章节的 SSH 登录并闲置试验,登录成功后什么都不要做,等待数个 60 秒后(确认 NFW 配置的闲置超时是 60 秒),再看 SSH 连接是否还在正常活跃,即可验证。
需要注意的是:不是所有应用软件都支持使用操作系统的
SO_KEEPALIVE机制,由操作系统来维护Keepalive包。在某些特殊场景下,应用程序和服务器端配置自身不支持设置 Keepalive、且应用程序的 SDK 在构建底层网络接口时候没有采用操作系统内置的SO_KEEPALIVE机制,这个时候会出现在操作系统层面开启 Keepalive 也不生效的情况。这种情况相对少见。如果遇到这种场景,请首先调大 NFW 的超时时间,例如调整到 6000 秒,然后在应用层每隔一定间隔发出一个最小消耗的空查询,从应用层执行没有业务意义但是又不消耗系统资源的查询,即可保证一定间隔有流量通过 NFW,NFW 就会判定不是闲置的从而维持连接。
5、常见服务和协议支持 Keepalive 配置情况说明
不同应用软件对 Keepalive 的支持程度不一致,有的协议自身就带有心跳机制,有的则完全依赖操作系统的 SO_KEEPALIVE。下表整理了 SSH、MySQL、PostgreSQL、Redis、NFS、gRPC 六种常见服务/协议的支持情况,供实际配置时参考。
| 组件 | 是否有应用层原生心跳机制 | OS 层 SO_KEEPALIVE 是否默认开启 | 说明 |
|---|---|---|---|
| SSH | 有。协议层 SSH_MSG_GLOBAL_REQUEST(keepalive@openssh.com),通过 ServerAliveInterval(客户端)/ClientAliveInterval(服务器端)配置 |
客户端默认开启(TCPKeepAlive yes),服务器端 sshd 同样默认 TCPKeepAlive yes |
两种机制彼此独立,互不依赖,可同时启用做双重保障 |
| MySQL | 协议本身没有心跳帧,只能靠客户端主动调用 mysql_ping(),或连接池(如 HikariCP keepaliveTime)周期性发一次真实查询模拟 |
取决于驱动:Connector/J 默认 tcpKeepAlive=true;Node.js mysql2 需显式设置 enableKeepAlive,历史上还出现过设置被忽略的 bug;C API libmysqlclient 没有找到官方独立的 keepalive 开关文档 |
驱动层差异很大,使用前必须查具体驱动文档确认,不能一概而论 |
| PostgreSQL | 协议本身没有独立心跳帧,但 libpq 驱动把 SO_KEEPALIVE 开关和参数直接暴露为连接字符串参数 |
客户端 keepalives 参数默认值是 1(开启),keepalives_idle/interval/count 默认 0,即沿用 OS 默认值(Linux 通常 7200 秒) |
本质是驱动帮你调用 setsockopt,是 OS 层机制的一层封装,不是独立于 TCP 的应用层协议 |
| Redis | 无应用层心跳协议,PING/PONG 命令存在但主要用于客户端主动探活或哨兵健康检查,不是自动定期心跳 |
服务器端 tcp-keepalive 参数自 Redis 3.2 起默认值是 300(秒),即默认开启,Redis 通过这个配置直接调用 SO_KEEPALIVE |
服务器端默认已经打开,是少数"开箱即用"的例子;但很多客户端库(如早期 ioredis)默认关闭,需要单独确认 |
| NFS | NFSv4/4.1 有状态租约机制(lease),客户端需要定期发 RENEW 或 SEQUENCE 操作续租,但这是维护协议状态而非专门为防 NAT/防火墙断连设计的心跳;NFSv3 完全没有这类机制 |
Linux 内核 NFS 客户端(net/sunrpc/xprtsock.c)在建连时会调用 sock_set_keepalive(),并跟随 NFS 的 RPC 超时参数联动设置 keepidle/keepintvl/keepcnt,属于内核默认开启 |
现代 Linux 内核 NFS 客户端默认开(该 keepalive 补丁在 RHEL 6.9 附近引入),老版本内核需要手工确认;服务器端行为因实现而异 |
| gRPC | 有,基于 HTTP/2 PING frame 的应用层心跳,参数为 GRPC_ARG_KEEPALIVE_TIME_MS 等 |
不涉及/不依赖,走的是纯应用层机制 | 客户端默认 KEEPALIVE_TIME_MS 是 INT_MAX(相当于禁用),服务器端默认 2 小时;且客户端默认 PERMIT_WITHOUT_CALLS=false,意味着没有活跃 RPC 时默认不发心跳,必须显式配置才生效 |
除以上列表之外的客户端,需要 case-by-case 查询官方文档确认 Keepalive 开启方法。
六、小结
本文介绍了 AWS Network Firewall(NFW)对长连接闲置超时(Idle Timeout)的处理机制,并给出排查与解决方案。通过实际搭建 SSH 长连接测试环境,验证了 NFW 默认 350 秒的闲置超时如何导致连接被静默切断,并演示了如何通过 CloudWatch Flow 日志(控制台查询、AWS CLI 脚本、CloudShell 三种方式)定位闲置超时事件。解决方案部分从调整 NFW 超时参数、修改应用程序(以 SSH 为例)配置文件、调整操作系统 SO_KEEPALIVE 三个层面展开,并整理了 SSH、MySQL、PostgreSQL、Redis、NFS、gRPC 六种常见服务对 Keepalive 的支持情况对比表,供实际排查参考。
最后修改于 2026-07-05