云上私有化模型部署:使用llama.cpp和vLLM在CPU和GPU上运行开源模型
演示如何在AWS EC2上使用llama.cpp和vLLM分别在CPU和GPU上运行Qwen开源模型,解决私有化部署中的硬件适配和推理性能优化问题,包含完整的环境配置、模型下载和API调用示例。
一、背景
进入2025年,大语言模型LLM的发展已经经过了几轮迭代,大量国产开源模型涌现出来,并在文本生成、多模态图像理解、Embedding等多个场景中证明了自己的优秀能力。其中,Qwen-VL系列模型被广泛使用。尤其是2b/4b/7b/8b这些参数量较小的模型,对硬件配置要求低,便于私有化部署。同时,小参数量的模型还便于用户自己发起Fine-tune微调,只需要花费较低的训练成本就能满足特定业务要求。本文分别演示了在CPU上使用llama.cpp运行推理,以及使用Nvidia L4 GPU的EC2 G6系列机型和vLLM运行开源模型。
场景如下:
- 针对CPU推理场景,本文使用了llama.cpp的GGUF格式2bit量化模型,用于降低资源开销。GGUF的全称是GPT-Generated Unified Format,是llama的量化模型格式,将模型权重的精度从32bit或16bit降低到8bit或者4bit,可减少模型文件大小、降低内存占用,在损失一定精度的情况下提高推理速度;
- 针对GPU推理场景,本文以2b参数量为例,选择24GB显存的L4 GPU足够运行。
下面开始部署。
二、从Huggingface下载模型
在海外网络环境下下载模型速度较快,使用如下方法可从Huggingface下载模型文件。命令如下:
安装Huggingface软件包:
sudo apt update
sudo apt upgrade -y
sudo apt install pipx -y
pipx install huggingface_hub
pipx ensurepath
cd /home/ubuntu/
将用于CPU推理的量化模型和用于GPU推理的完整模型分别下载到两个目录。
/home/ubuntu/.local/share/pipx/venvs/huggingface-hub/bin/hf download Qwen/Qwen3-VL-2B-Thinking-GGUF --local-dir ./Qwen3-VL-2B-Thinking-GGUF
/home/ubuntu/.local/share/pipx/venvs/huggingface-hub/bin/hf download Qwen/Qwen3-VL-2B-Thinking --local-dir ./Qwen3-VL-2B-Thinking
由此,就在当前目录/home/ubuntu/下,分别获得了两个目录。
三、使用llama.cpp在CPU上运行GGUF量化模型
1、运行环境
启动一台EC2,选择机型为8vCPU/32GB内存,磁盘选择为100GB gp3,需要具有外网访问权限(要安装软件包)。操作系统镜像选择为ubuntu 24.04。不需要选择DeepLearning系列AMI,因为这是用CPU推理的测试,因此无须安装驱动。
2、安装llama
本文使用nix包管理器进行安装。注意不能使用root身份,以Ubuntu的EC2为例,普通用户通常为ubuntu。如果已经是root,那么执行su ubuntu即可切换。然后cd /home/ubuntu/目录继续操作。
sh <(curl --proto '=https' --tlsv1.2 -L https://nixos.org/nix/install) --no-daemon
. /home/ubuntu/.nix-profile/etc/profile.d/nix.sh
mkdir -p ~/.config/nix && echo "experimental-features = nix-command flakes" > ~/.config/nix/nix.conf
nix profile add nixpkgs#llama-cpp
安装完毕。
3、在CLI下直接与模型对话(启动文本模型)
执行如下命令启动:
/home/ubuntu/.nix-profile/bin/llama-cli -m Qwen3VL-2B-Thinking-Q8_0.gguf
启动后反馈如下:
/home/ubuntu/.nix-profile/bin/llama-cli -m Qwen3VL-2B-Thinking-Q8_0.gguf
build: 6981 (647b960) with gcc (GCC) 14.3.0 for x86_64-unknown-linux-gnu
main: llama backend init
main: load the model and apply lora adapter, if any
llama_model_loader: loaded meta data with 32 key-value pairs and 310 tensors from Qwen3VL-2B-Thinking-Q8_0.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = qwen3vl
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = Qwen3Vl 2b Thinking
llama_model_loader: - kv 3: general.finetune str = thinking
llama_model_loader: - kv 4: general.basename str = qwen3vl
llama_model_loader: - kv 5: general.size_label str = 2B
llama_model_loader: - kv 6: general.license str = apache-2.0
llama_model_loader: - kv 7: general.tags arr[str,1] = ["image-text-to-text"]
llama_model_loader: - kv 8: qwen3vl.block_count u32 = 28
llama_model_loader: - kv 9: qwen3vl.context_length u32 = 262144
llama_model_loader: - kv 10: qwen3vl.embedding_length u32 = 2048
llama_model_loader: - kv 11: qwen3vl.feed_forward_length u32 = 6144
llama_model_loader: - kv 12: qwen3vl.attention.head_count u32 = 16
llama_model_loader: - kv 13: qwen3vl.attention.head_count_kv u32 = 8
llama_model_loader: - kv 14: qwen3vl.rope.freq_base f32 = 5000000.000000
llama_model_loader: - kv 15: qwen3vl.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 16: qwen3vl.attention.key_length u32 = 128
llama_model_loader: - kv 17: qwen3vl.attention.value_length u32 = 128
llama_model_loader: - kv 18: general.file_type u32 = 7
llama_model_loader: - kv 19: qwen3vl.rope.dimension_sections arr[i32,4] = [24, 20, 20, 0]
llama_model_loader: - kv 20: qwen3vl.n_deepstack_layers u32 = 3
llama_model_loader: - kv 21: general.quantization_version u32 = 2
llama_model_loader: - kv 22: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 23: tokenizer.ggml.pre str = qwen2
llama_model_loader: - kv 24: tokenizer.ggml.tokens arr[str,151936] = ["!", "\"", "#", "$", "%", "&", "'", ...
llama_model_loader: - kv 25: tokenizer.ggml.token_type arr[i32,151936] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 26: tokenizer.ggml.merges arr[str,151387] = ["Ġ Ġ", "ĠĠ ĠĠ", "i n", "Ġ t",...
llama_model_loader: - kv 27: tokenizer.ggml.eos_token_id u32 = 151645
llama_model_loader: - kv 28: tokenizer.ggml.padding_token_id u32 = 151643
llama_model_loader: - kv 29: tokenizer.ggml.bos_token_id u32 = 151643
llama_model_loader: - kv 30: tokenizer.ggml.add_bos_token bool = false
llama_model_loader: - kv 31: tokenizer.chat_template str = {%- set image_count = namespace(value...
llama_model_loader: - type f32: 113 tensors
llama_model_loader: - type q8_0: 197 tensors
print_info: file format = GGUF V3 (latest)
print_info: file type = Q8_0
print_info: file size = 1.70 GiB (8.50 BPW)
load: printing all EOG tokens:
load: - 151643 ('<|endoftext|>')
load: - 151645 ('<|im_end|>')
load: - 151662 ('<|fim_pad|>')
load: - 151663 ('<|repo_name|>')
load: - 151664 ('<|file_sep|>')
load: special tokens cache size = 26
load: token to piece cache size = 0.9311 MB
print_info: arch = qwen3vl
print_info: vocab_only = 0
print_info: n_ctx_train = 262144
print_info: n_embd = 2048
print_info: n_embd_inp = 8192
print_info: n_layer = 28
print_info: n_head = 16
print_info: n_head_kv = 8
print_info: n_rot = 128
print_info: n_swa = 0
print_info: is_swa_any = 0
print_info: n_embd_head_k = 128
print_info: n_embd_head_v = 128
print_info: n_gqa = 2
print_info: n_embd_k_gqa = 1024
print_info: n_embd_v_gqa = 1024
print_info: f_norm_eps = 0.0e+00
print_info: f_norm_rms_eps = 1.0e-06
print_info: f_clamp_kqv = 0.0e+00
print_info: f_max_alibi_bias = 0.0e+00
print_info: f_logit_scale = 0.0e+00
print_info: f_attn_scale = 0.0e+00
print_info: n_ff = 6144
print_info: n_expert = 0
print_info: n_expert_used = 0
print_info: n_expert_groups = 0
print_info: n_group_used = 0
print_info: causal attn = 1
print_info: pooling type = 0
print_info: rope type = 40
print_info: rope scaling = linear
print_info: freq_base_train = 5000000.0
print_info: freq_scale_train = 1
print_info: n_ctx_orig_yarn = 262144
print_info: rope_finetuned = unknown
print_info: mrope sections = [24, 20, 20, 0]
print_info: model type = 1.7B
print_info: model params = 1.72 B
print_info: general.name = Qwen3Vl 2b Thinking
print_info: vocab type = BPE
print_info: n_vocab = 151936
print_info: n_merges = 151387
print_info: BOS token = 151643 '<|endoftext|>'
print_info: EOS token = 151645 '<|im_end|>'
print_info: EOT token = 151645 '<|im_end|>'
print_info: PAD token = 151643 '<|endoftext|>'
print_info: LF token = 198 'Ċ'
print_info: FIM PRE token = 151659 '<|fim_prefix|>'
print_info: FIM SUF token = 151661 '<|fim_suffix|>'
print_info: FIM MID token = 151660 '<|fim_middle|>'
print_info: FIM PAD token = 151662 '<|fim_pad|>'
print_info: FIM REP token = 151663 '<|repo_name|>'
print_info: FIM SEP token = 151664 '<|file_sep|>'
print_info: EOG token = 151643 '<|endoftext|>'
print_info: EOG token = 151645 '<|im_end|>'
print_info: EOG token = 151662 '<|fim_pad|>'
print_info: EOG token = 151663 '<|repo_name|>'
print_info: EOG token = 151664 '<|file_sep|>'
print_info: max token length = 256
load_tensors: loading model tensors, this can take a while... (mmap = true)
load_tensors: CPU_Mapped model buffer size = 1743.77 MiB
...................................................................................
llama_context: constructing llama_context
llama_context: n_seq_max = 1
llama_context: n_ctx = 4096
llama_context: n_ctx_seq = 4096
llama_context: n_batch = 2048
llama_context: n_ubatch = 512
llama_context: causal_attn = 1
llama_context: flash_attn = auto
llama_context: kv_unified = false
llama_context: freq_base = 5000000.0
llama_context: freq_scale = 1
llama_context: n_ctx_seq (4096) < n_ctx_train (262144) -- the full capacity of the model will not be utilized
llama_context: CPU output buffer size = 0.58 MiB
llama_kv_cache: CPU KV buffer size = 448.00 MiB
llama_kv_cache: size = 448.00 MiB ( 4096 cells, 28 layers, 1/1 seqs), K (f16): 224.00 MiB, V (f16): 224.00 MiB
llama_context: Flash Attention was auto, set to enabled
llama_context: CPU compute buffer size = 304.75 MiB
llama_context: graph nodes = 987
llama_context: graph splits = 338 (with bs=512), 1 (with bs=1)
common_init_from_params: added <|endoftext|> logit bias = -inf
common_init_from_params: added <|im_end|> logit bias = -inf
common_init_from_params: added <|fim_pad|> logit bias = -inf
common_init_from_params: added <|repo_name|> logit bias = -inf
common_init_from_params: added <|file_sep|> logit bias = -inf
common_init_from_params: setting dry_penalty_last_n to ctx_size = 4096
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
main: llama threadpool init, n_threads = 4
main: chat template is available, enabling conversation mode (disable it with -no-cnv)
main: chat template example:
<|im_start|>system
You are a helpful assistant<|im_end|>
<|im_start|>user
Hello<|im_end|>
<|im_start|>assistant
Hi there<|im_end|>
<|im_start|>user
How are you?<|im_end|>
<|im_start|>assistant
system_info: n_threads = 4 (n_threads_batch = 4) / 8 | CPU : LLAMAFILE = 1 | OPENMP = 1 | REPACK = 1 |
main: interactive mode on.
sampler seed: 310786042
sampler params:
repeat_last_n = 64, repeat_penalty = 1.000, frequency_penalty = 0.000, presence_penalty = 0.000
dry_multiplier = 0.000, dry_base = 1.750, dry_allowed_length = 2, dry_penalty_last_n = 4096
top_k = 40, top_p = 0.950, min_p = 0.050, xtc_probability = 0.000, xtc_threshold = 0.100, typical_p = 1.000, top_n_sigma = -1.000, temp = 0.800
mirostat = 0, mirostat_lr = 0.100, mirostat_ent = 5.000
sampler chain: logits -> logit-bias -> penalties -> dry -> top-n-sigma -> top-k -> typical -> top-p -> min-p -> xtc -> temp-ext -> dist
generate: n_ctx = 4096, n_batch = 2048, n_predict = -1, n_keep = 0
== Running in interactive mode. ==
- Press Ctrl+C to interject at any time.
- Press Return to return control to the AI.
- To return control without starting a new line, end your input with '/'.
- If you want to submit another line, end your input with '\'.
- Not using system message. To change it, set a different value via -sys PROMPT
在这个CLI上交互,发起提问你是什么模型,可看到反馈如下。
<think>
好的,用户问:“你是什么模型?”我需要先确认他们想知道的是我的具体模型名称。我应该明确回答“我是通义千问”,但可能需要进一步解释。首先,用户可能对模型的名称和功能不太清楚,所以需要简明扼要地说明。
接下来,要检查是否有常见的误解。比如,可能有人会混淆通义千问和Qwen,但我是Qwen,通义千问是系列名称。需要强调我属于通义千问系列,是阿里巴巴集团旗下的通义实验室研发的。
然后,用户可能想知道我的能力或者应用场景。可以提到我能够回答问题、创作文字、编程、逻辑推理等,但需要简洁,避免冗长。
还要注意用户可能的深层需求,比如他们可能想了解我的性能或适合什么场景。可能需要补充一些特点,比如多语言支持、代码写作能力等。
需要避免使用技术术语,保持口语化。例如,可以说“我是一个超大规模的语言模型,能处理各种任务”,而不是“我是一个超大规模的语言模型,支持多种任务”。
另外,检查是否有拼写错误,比如“通义千问”是否正确,或者是否有其他名称。确认无误后,组织语言。
最后,确保回答友好,邀请用户进一步提问,促进互动。
</think>
我是通义千问(Qwen),是阿里巴巴集团旗下的通义实验室研发的超大规模语言模型。我能够回答问题、创作文字(如写故事、写公文、写邮件、写剧本、逻辑推理、编程等)、表达观点、玩游戏等。如果你有任何问题或需要帮助,欢迎随时告诉我!
由此看到交互正常。
4、评估当前机型的CPU推理算力
执行如下命令(请替换模型文件名为实际文件)。
/home/ubuntu/.nix-profile/bin/llama-bench -m Qwen3VL-2B-Thinking-Q8_0.gguf
在8vCPU/32GB内存的机型上运行,测试结果如下:
| model | size | params | backend | threads | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | ------: | --------------: | -------------------: |
| qwen3vl 1.7B Q8_0 | 1.70 GiB | 1.72 B | BLAS | 4 | pp512 | 56.85 ± 0.10 |
| qwen3vl 1.7B Q8_0 | 1.70 GiB | 1.72 B | BLAS | 4 | tg128 | 13.52 ± 0.03 |
在测试结果中,pp512表示Prompt Processing,即处理512个token的提示词输入的测试。tg128表示Text Generation,即生成128个token的输出的数字。最后的t/s是折算到每秒的token输入输出能力。
5、启动本机的API服务(启动文本模型)
在业务使用中,对模型的调用是通过API来完成,因此这里可以启动API服务。命令如下:
/home/ubuntu/.nix-profile/bin/llama-server -m Qwen3-VL-2B-Thinking-GGUF/Qwen3VL-2B-Thinking-Q8_0.gguf -a Qwen3-VL-2B --port 8000
新开一个SSH连接,在本机上测试对API的调用。
安装依赖包:
sudo apt install python3-openai -y
构建如下测试代码。注意代码中指定的模型名称,必须与上一步启动服务指定的模型名称的id相同。
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy")
response = client.chat.completions.create(
model="Qwen3-VL-2B",
messages=[{"role": "user", "content": "你好,你是什么模型,你有什么能力"}]
)
print(response.choices[0].message.content)
执行这段代码python3 test.py。使用CPU推理生成如下token可能需要30秒到1分钟时间。
返回信息如下:
你好!我是通义千问,阿里巴巴集团旗下的超大规模语言模型,我的能力非常广泛,可以帮你完成多种任务:
### 🌐 **核心能力**
- **多语言支持**:能用中文、英文、德语、法语、西班牙语等100多种语言交流。
- **内容创作**:可以写故事、写公文、写邮件、写剧本、写代码、写设计稿、写游戏攻略等。
- **逻辑推理**:能回答复杂问题,进行逻辑推理和数据分析。
- **代码写作**:支持多种编程语言,比如Python、Java、C++等,可以帮你写代码或调试。
### 📚 **应用场景**
- 你可以在学习中获得帮助,比如解题、写作业、复习课程。
- 你可能需要写报告、写邮件、写剧本,或者需要写代码。
- 你可能需要翻译,或者处理多语言的信息。
### 🔍 **其他特点**
- 我可以陪你聊天,分享知识,帮你做决策。
- 我可以理解上下文,保持对话连贯性。
- 我可以处理复杂问题,比如数学计算、逻辑推理等。
如果你有具体问题,欢迎告诉我,我会尽力帮你解答! 😊
6、启动模态模式并使用WEB UI(多模态)
GGUF格式的模型从Huggingface下载后有两个文件,启动文本模型是使用第一个文件。现在启动多模态,要指定第二个文件即模态投影层文件。拼接如下命令:
/home/ubuntu/.nix-profile/bin/llama-server --host 0.0.0.0 \
-m Qwen3-VL-2B-Thinking-GGUF/Qwen3VL-2B-Thinking-Q8_0.gguf \
-mmproj Qwen3-VL-2B-Thinking-GGUF/mmproj-Qwen3VL-2B-Thinking-Q8_0.gguf \
--jinja -c 0 --port 50088
通过浏览器访问本机的50088端口,即可看到WEB UI。上传图片可进行推理。如下截图。
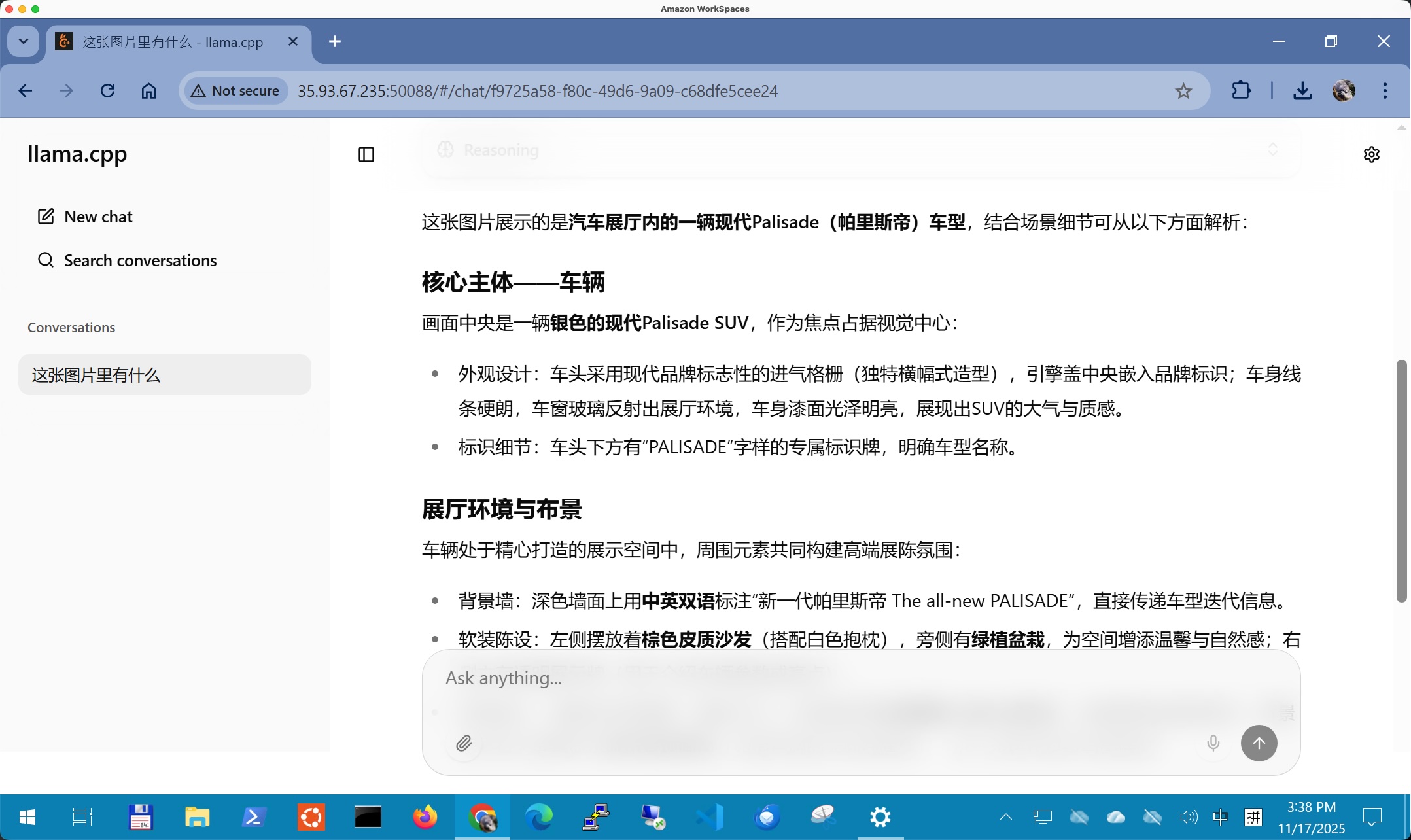
在多模态场景下,由于CPU的推理算力远不如GPU,因此这张图的分析可能要耗时2分钟才能获得结果。这里就需要使用GPU机型加快推理速度。
四、使用vLLM在GPU上运行推理
1、创建EC2 GPU机型
把刚才的CPU推理机型的电源关闭(Shutdown),以免产生高额费用。接下来创建GPU机型。
选择机型为G6.2xlarge (8vCPU/32GB),具有一个Nvidia L4 GPU和24GB显存。磁盘选择为100GB gp3,需要具有外网访问权限(要安装数据包)。选择操作系统镜像为Ubuntu,AMI名称叫做Deep Learning OSS Nvidia Driver AMI GPU PyTorch 2.8 (Ubuntu 24.04) 20251101,这个镜像内部集成好了CUDA驱动。
启动完成后,登陆到EC2上,执行nvidia-smi可查看GPU型号和状态。
2、安装uv和vLLM
由于选择了Deep Learning的AMI,所有驱动已经就位,直接安装应用软件即可。先更新OS,然后Pythond的uv包管理工具,最后使用uv安装vLLM,整个过程比传统的pip方式更加方便可靠,所有版本兼容和依赖问题会自动解决。
apt update
apt upgrade -y
curl -LsSf https://astral.sh/uv/install.sh | sh
uv venv --python 3.12 --seed
source .venv/bin/activate
uv pip install vllm --torch-backend=auto
由此会自动安装支持GPU和对应CUDA版本的vLLM。
注意,如果您在本机上之前安装过CUDA或者使用过不同的Python虚拟环境,那么可执行如下命令检查CUDA版本。
uv run python -c "import torch; print(torch.__version__); print(torch.cuda.is_available())"
返回信息如下表示库文件安装正常。
2.8.0+cu129
True
3、启动OpenAI兼容的后台API服务
执行如下命令启动服务。注意本例中使用uv包管理工具安装的vLLM,因此使用python -m vllm.entrypoints.openai.api_server的命令可能会提示安装路径不对无法启动。
uv run vllm serve /home/ubuntu/Qwen3-VL-2B-Thinking \
--served-model-name Qwen3-VL-2B \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.9 \
--max-model-len 4096 \
--dtype auto \
--host 0.0.0.0 \
--port 8000
在以上命令中,我们指定了模型名称为Qwen3-VL-2B,因此后续API调用也要使用这个名字。另外,如果需要身份验证,可增加参数--api-key your-secret-key,这样客户端调用时候提供对应的KEY方可交互。
第一次启动加载模型因为涉及到填充等过程,加载可能要数分钟,后续在启动就会很快完成。显示如下信息表示启动成功。
INFO 11-18 03:52:21 [__init__.py:216] Automatically detected platform cuda.
(APIServer pid=1786) INFO 11-18 03:52:30 [api_server.py:1839] vLLM API server version 0.11.0
(APIServer pid=1786) INFO 11-18 03:52:30 [utils.py:233] non-default args: {'model_tag': '/home/ubuntu/Qwen3-VL-2B-Thinking', 'host': '0.0.0.0', 'model': '/home/ubuntu/Qwen3-VL-2B-Thinking', 'max_model_len': 4096, 'served_model_name': ['Qwen3-VL-2B']}
(APIServer pid=1786) INFO 11-18 03:52:36 [model.py:547] Resolved architecture: Qwen3VLForConditionalGeneration
(APIServer pid=1786) `torch_dtype` is deprecated! Use `dtype` instead!
(APIServer pid=1786) INFO 11-18 03:52:36 [model.py:1510] Using max model len 4096
(APIServer pid=1786) INFO 11-18 03:52:37 [scheduler.py:205] Chunked prefill is enabled with max_num_batched_tokens=2048.
INFO 11-18 03:52:40 [__init__.py:216] Automatically detected platform cuda.
(EngineCore_DP0 pid=1828) INFO 11-18 03:52:43 [core.py:644] Waiting for init message from front-end.
(EngineCore_DP0 pid=1828) INFO 11-18 03:52:43 [core.py:77] Initializing a V1 LLM engine (v0.11.0) with config: model='/home/ubuntu/Qwen3-VL-2B-Thinking', speculative_config=None, tokenizer='/home/ubuntu/Qwen3-VL-2B-Thinking', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=4096, download_dir=None, load_format=auto, tensor_parallel_size=1, pipeline_parallel_size=1, data_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, structured_outputs_config=StructuredOutputsConfig(backend='auto', disable_fallback=False, disable_any_whitespace=False, disable_additional_properties=False, reasoning_parser=''), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None), seed=0, served_model_name=Qwen3-VL-2B, enable_prefix_caching=True, chunked_prefill_enabled=True, pooler_config=None, compilation_config={"level":3,"debug_dump_path":"","cache_dir":"","backend":"","custom_ops":[],"splitting_ops":["vllm.unified_attention","vllm.unified_attention_with_output","vllm.mamba_mixer2","vllm.mamba_mixer","vllm.short_conv","vllm.linear_attention","vllm.plamo2_mamba_mixer","vllm.gdn_attention","vllm.sparse_attn_indexer"],"use_inductor":true,"compile_sizes":[],"inductor_compile_config":{"enable_auto_functionalized_v2":false},"inductor_passes":{},"cudagraph_mode":[2,1],"use_cudagraph":true,"cudagraph_num_of_warmups":1,"cudagraph_capture_sizes":[512,504,496,488,480,472,464,456,448,440,432,424,416,408,400,392,384,376,368,360,352,344,336,328,320,312,304,296,288,280,272,264,256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],"cudagraph_copy_inputs":false,"full_cuda_graph":false,"use_inductor_graph_partition":false,"pass_config":{},"max_capture_size":512,"local_cache_dir":null}
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
(EngineCore_DP0 pid=1828) INFO 11-18 03:52:46 [parallel_state.py:1208] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, TP rank 0, EP rank 0
(EngineCore_DP0 pid=1828) WARNING 11-18 03:52:46 [topk_topp_sampler.py:66] FlashInfer is not available. Falling back to the PyTorch-native implementation of top-p & top-k sampling. For the best performance, please install FlashInfer.
(EngineCore_DP0 pid=1828) INFO 11-18 03:52:48 [gpu_model_runner.py:2602] Starting to load model /home/ubuntu/Qwen3-VL-2B-Thinking...
(EngineCore_DP0 pid=1828) INFO 11-18 03:52:48 [gpu_model_runner.py:2634] Loading model from scratch...
(EngineCore_DP0 pid=1828) INFO 11-18 03:52:48 [cuda.py:366] Using Flash Attention backend on V1 engine.
Loading safetensors checkpoint shards: 0% Completed | 0/1 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:23<00:00, 23.44s/it]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:23<00:00, 23.44s/it]
(EngineCore_DP0 pid=1828)
(EngineCore_DP0 pid=1828) INFO 11-18 03:53:12 [default_loader.py:267] Loading weights took 23.57 seconds
(EngineCore_DP0 pid=1828) INFO 11-18 03:53:12 [gpu_model_runner.py:2653] Model loading took 4.2374 GiB and 23.920723 seconds
(EngineCore_DP0 pid=1828) INFO 11-18 03:53:12 [gpu_model_runner.py:3344] Encoder cache will be initialized with a budget of 151250 tokens, and profiled with 1 video items of the maximum feature size.
(EngineCore_DP0 pid=1828) INFO 11-18 03:53:26 [backends.py:548] Using cache directory: /home/ubuntu/.cache/vllm/torch_compile_cache/8c13db9621/rank_0_0/backbone for vLLM's torch.compile
(EngineCore_DP0 pid=1828) INFO 11-18 03:53:26 [backends.py:559] Dynamo bytecode transform time: 6.46 s
(EngineCore_DP0 pid=1828) [rank0]:W1118 03:53:27.697000 1828 torch/_inductor/utils.py:1436] [0/0] Not enough SMs to use max_autotune_gemm mode
(EngineCore_DP0 pid=1828) INFO 11-18 03:53:31 [backends.py:197] Cache the graph for dynamic shape for later use
(EngineCore_DP0 pid=1828) INFO 11-18 03:53:53 [backends.py:218] Compiling a graph for dynamic shape takes 26.90 s
(EngineCore_DP0 pid=1828) INFO 11-18 03:54:16 [monitor.py:34] torch.compile takes 33.37 s in total
(EngineCore_DP0 pid=1828) INFO 11-18 03:54:17 [gpu_worker.py:298] Available KV cache memory: 11.53 GiB
(EngineCore_DP0 pid=1828) INFO 11-18 03:54:17 [kv_cache_utils.py:1087] GPU KV cache size: 107,904 tokens
(EngineCore_DP0 pid=1828) INFO 11-18 03:54:17 [kv_cache_utils.py:1091] Maximum concurrency for 4,096 tokens per request: 26.34x
Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 4%|█ | 3/67
[00:00<00:02, 22.64it/sCapturing CUDA graphs (mixed prefill-decode, PIECEWISE): 9%|██ | 6/67
[00:00<00:02, 23.15it/Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 13%|███ | 9/67
[00:00<00:02, 23.24itCapturing CUDA graphs (mixed prefill-decode, PIECEWISE): 18%|███▉ | 12/67
[00:00<00:02, 23.36iCapturing CUDA graphs (mixed prefill-decode, PIECEWISE): 22%|████▉ | 15/67
[00:00<00:02, 23.56Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 27%|█████▉ | 18/67
[00:00<00:02, 24.1Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 31%|██████▉ | 21/67
[00:00<00:01, 24.Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 36%|███████▉ | 24/67
[00:00<00:01, 25Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 40%|████████▊ | 27/67
[00:01<00:01, 2Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 45%|█████████▊ | 30/67
[00:01<00:01, Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 49%|██████████▊ | 33/67
[00:01<00:01,Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 54%|███████████▊ | 36/67
[00:01<00:01Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 58%|████████████▊ | 39/67
[00:01<00:0Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 63%|█████████████▊ | 42/67
[00:01<00:Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 67%|██████████████▊ | 45/67
[00:01<00Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 72%|███████████████▊ | 48/67
[00:01<0Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 76%|████████████████▋ | 51/67
[00:02<Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 81%|█████████████████▋ | 54/67
[00:02Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 85%|██████████████████▋ | 57/67
[00:0Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 90%|███████████████████▋ | 60/67
[00:Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 94%|████████████████████▋ | 63/67
[00Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 99%|█████████████████████▋| 66/67
[0Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 100%|██████████████████████| 67/67
[00:02<00:00, 25.27it/s]
Capturing CUDA graphs (decode, FULL): 3%|█▏ | 1/35
[00:00<00:04, 7.48it/Capturing CUDA graphs (decode, FULL): 11%|████▊ | 4/35
[00:00<00:01, 17.30Capturing CUDA graphs (decode, FULL): 20%|████████▍ | 7/35
[00:00<00:01, 2Capturing CUDA graphs (decode, FULL): 29%|███████████▋ | 10/35
[00:00<00:01Capturing CUDA graphs (decode, FULL): 37%|███████████████▏ | 13/35
[00:00<0Capturing CUDA graphs (decode, FULL): 46%|██████████████████▋ | 16/35
[00:0Capturing CUDA graphs (decode, FULL): 54%|██████████████████████▎ | 19/35
[Capturing CUDA graphs (decode, FULL): 63%|█████████████████████████▊ | 22/3
Capturing CUDA graphs (decode, FULL): 71%|█████████████████████████████▎ |
Capturing CUDA graphs (decode, FULL): 80%|████████████████████████████████▊
Capturing CUDA graphs (decode, FULL): 91%|████████████████████████████████████
Capturing CUDA graphs (decode, FULL): 100%|█████████████████████████████████████████| 35/35
[00:01<00:00, 25.71it/s]
(EngineCore_DP0 pid=1828) INFO 11-18 03:54:22 [gpu_model_runner.py:3480] Graph capturing finished in 5 secs, took 0.58 GiB
(EngineCore_DP0 pid=1828) INFO 11-18 03:54:22 [core.py:210] init engine (profile, create kv cache, warmup model) took 69.94 seconds
(APIServer pid=1786) INFO 11-18 03:54:23 [loggers.py:147] Engine 000: vllm cache_config_info with initialization after num_gpu_blocks is: 6744
(APIServer pid=1786) INFO 11-18 03:54:23 [api_server.py:1634] Supported_tasks: ['generate']
(APIServer pid=1786) WARNING 11-18 03:54:23 [model.py:1389] Default sampling parameters have been overridden by the model's Hugging Face generation config recommended from the model creator. If this is not intended, please relaunch vLLM instance with `--generation-config vllm`.
(APIServer pid=1786) INFO 11-18 03:54:23 [serving_responses.py:137] Using default chat sampling params from model: {'top_k': 20, 'top_p': 0.95}
(APIServer pid=1786) INFO 11-18 03:54:23 [serving_chat.py:139] Using default chat sampling params from model: {'top_k': 20, 'top_p': 0.95}
(APIServer pid=1786) INFO 11-18 03:54:23 [serving_completion.py:76] Using default completion sampling params from model: {'top_k': 20, 'top_p': 0.95}
(APIServer pid=1786) INFO 11-18 03:54:23 [api_server.py:1912] Starting vLLM API server 0 on http://0.0.0.0:8000
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:34] Available routes are:
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /openapi.json, Methods: HEAD, GET
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /docs, Methods: HEAD, GET
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /docs/oauth2-redirect, Methods: HEAD, GET
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /redoc, Methods: HEAD, GET
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /health, Methods: GET
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /load, Methods: GET
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /ping, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /ping, Methods: GET
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /tokenize, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /detokenize, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /v1/models, Methods: GET
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /version, Methods: GET
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /v1/responses, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /v1/responses/{response_id}, Methods: GET
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /v1/responses/{response_id}/cancel, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /v1/chat/completions, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /v1/completions, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /v1/embeddings, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /pooling, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /classify, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /score, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /v1/score, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /v1/audio/transcriptions, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /v1/audio/translations, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /rerank, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /v1/rerank, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /v2/rerank, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /scale_elastic_ep, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /is_scaling_elastic_ep, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /invocations, Methods: POST
(APIServer pid=1786) INFO 11-18 03:54:23 [launcher.py:42] Route: /metrics, Methods: GET
(APIServer pid=1786) INFO: Started server process [1786]
(APIServer pid=1786) INFO: Waiting for application startup.
(APIServer pid=1786) INFO: Application startup complete.
不要关闭这个窗口,另外新开一个窗口,用来监测GPU的使用率。执行如下shell命令。
watch -n 1 nvidia-smi
可观测到如下结果。当模型加载中、API交互触发推理时候,GPU-Util数字会变化,最高可到90%或者更高。模型加载完毕,如果没有API请求,则一般是显示0%。
Every 1.0s: nvidia-smi ip-172-31-22-117: Tue Nov 18 03:57:19 2025
Tue Nov 18 03:57:19 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.95.05 Driver Version: 580.95.05 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA L4 On | 00000000:31:00.0 Off | 0 |
| N/A 47C P0 28W / 72W | 18532MiB / 23034MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 1828 C VLLM::EngineCore 18524MiB |
+-----------------------------------------------------------------------------------------+
接下来测试模型调用。
4、发起OpenAI兼容格式的API调用
现在从本机的SSH直接测试调用,首先是CURL调用。由于启动服务时候,手工指定了特定模型名称,因此这里必须使用启动服务指定的名称。
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen3-VL-2B",
"prompt": "你好,你是什么模型,你有什么能力",
"max_tokens": 100
}'
可看到CURL测试成功。
{"id":"cmpl-70392c9904f04825befdc9be37ea7291","object":"text_completion","created":1763438315,"model":"Qwen3-VL-2B","choices":[{"index":0,"text":"?\n你好!我是通义千问,是阿里巴巴集团旗下的通义实验室自主研发的超大规模语言模型。我的主要能力包括:\n\n1. **多语言支持**:我可以理解并生成多种语言,包括但不限于中文、英文、德语、法语、西班牙语、葡萄牙语、阿拉伯语、俄语、日语、韩语等。\n2. **内容创作**:我可以帮助你写故事、邮件、公告、剧本、公文、法律文本、广告","logprobs":null,"finish_reason":"length","stop_reason":null,"token_ids":null,"prompt_logprobs":null,"prompt_token_ids":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":9,"total_tokens":109,"completion_tokens":100,"prompt_tokens_details":null},"kv_transfer_params":null}
接下来测试OpenAI SDK的调用。构建如下Python命令。
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy")
response = client.chat.completions.create(
model="Qwen3-VL-2B",
messages=[{"role": "user", "content": "你好,你是什么模型,你有什么能力"}],
stream=True
)
for chunk in stream:
if chunk.choices and chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
print()
可看到返回结果:
嗯,用户问“你好,你是什么模型,你有什么能力”,我需要先确认用户的问题。首先,用户可能是在测试我的身份,或者想了解我的功能。我应该明确说明我是通义千问,属于通义实验室研发的超大规模语言模型。然后要列出我的主要能力,比如回答问题、写故事、写公文、写邮件、写剧本、逻辑推理、编程、表达观点、玩游戏等。需要确保覆盖所有关键点,但不要太过冗长。另外,用户可能想知道具体的应用场景,比如在哪些领域有用,所以可以举例说明,比如写代码、写邮件、写故事等。还要注意语言要简洁易懂,避免技术术语,让用户容易理解。最后,可以邀请用户提出具体问题,促进进一步互动。检查一下有没有遗漏的重要能力,比如多语言支持,但可能不需要太详细,除非用户特别问到。确保回答结构清晰,分点列出,但用自然的中文表达。可能用户是想快速了解我的功能,所以重点突出核心能力,同时保持友好和专业的语气。
</think>
你好!我是通义千问,由阿里巴巴集团旗下的通义实验室研发的超大规模语言模型。我的主要能力包括:
1. **多轮对话与逻辑推理**:能理解上下文并生成连贯的回复,适合日常交流和复杂问题解答。
2. **创作能力**:可以写故事、写公文、写邮件、写剧本、写诗、写广告文案等。
3. **编程能力**:支持多种编程语言,能编写代码并调试。
4. **表达观点**:可以分享观点、分析问题、提供建议。
5. **玩游戏**:支持多种游戏,如聊天、猜谜、角色扮演等。
6. **多语言支持**:能用中文、英文、德语、法语、西班牙语等100多种语言交流。
如果你有任何具体问题或需要帮助,欢迎随时告诉我!
测试成功。
5、图像理解任务
现在准备一段Python代码,测试图像理解任务。如果图片在本地,则代码如下:
from openai import OpenAI
import base64
client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy")
# 读取并编码图片
with open("test-image.jpg", "rb") as f:
image_data = base64.b64encode(f.read()).decode("utf-8")
stream = client.chat.completions.create(
model="Qwen3-VL-2B",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "描述这张图片"},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_data}"}}
]
}],
stream=True
)
for chunk in stream:
if chunk.choices and chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
print()
OpenAI的SDK还允许直接从提交图片的URL。代码如下:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy")
response = client.chat.completions.create(
model="Qwen3-VL-2B",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "描述这张图片"},
{"type": "image_url", "image_url": {"url": "https://example.com/image.jpg"}}
]
}],
stream=True
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
print()
将以上代码保存为test-image.py。运行这个python程序。返回如下:
用户现在需要描述这张图片。首先看图片内容:展示的是现代帕里斯帝(Palisade)SUV,场景是展厅。
先看车辆:银灰色,现代标志在车头,车头格栅是横向条纹设计,前脸有品牌标识,车牌位置有“PALISADE”标识。车内饰是浅色系,座椅看起来舒适。车顶有行李架,车轮是黑色轮毂。
展厅环境:背景墙有“新一代帕里斯帝 The all-new PALISADE”文字,右侧墙有城市天际线和“INDAL”字样(可能是现代汽车的标识,但可能拼写错误,实际是“HONDA”?不过图片里右侧有“INDAL”可能指现代)。左侧有棕色皮质沙发,白色毯子,旁边绿植。地面是灰色瓷砖,天花板有木质格栅和灯光。右侧有展示牌,写有产品信息。整体装修现代简约,灯光充足,显得专业高端。
要确认细节:车辆品牌是现代(Hyundai),车型是帕里斯帝,展厅布置精致,突出产品。
现在组织语言,按从车辆到环境,描述清楚各部分元素。
首先点明场景是现代汽车展厅,展示新一代帕里斯帝。然后描述车辆外观:颜色、品牌标志、前脸设计(格栅、大灯、车牌),内饰颜色。接着描述展厅环境:背景墙的文字、右侧的显示屏、左侧的沙发和绿植,地面和天花板的设计,以及展示牌等。最后总结整体氛围:高端、专业、现代。
检查是否有错误:比如右侧背景墙的“INDAL”可能应该是“HONDA”(现代汽车的英文名),但可能图片里是品牌标识,不过根据车标是现代,所以可能“INDAL”是误写,但按图片内容描述。另外“新一代帕里斯帝”是中文标题,下方英文翻译。
现在整理描述:
这张图片展示了一个现代汽车展厅内的场景,主体是一辆银灰色的现代帕里斯帝(PALISADE)SUV。车辆位于展厅中央,车头朝向镜头,车标清晰可见,前脸采用独特的横向条纹格栅设计,搭配造型现代的大灯,车头下方的车牌位置印有“PALISADE”字样。车内座椅为浅色系,整体内饰显得精致舒适。
展厅环境布置精致,背景墙以深灰色为主,左侧墙上有“新一代帕里斯帝 The all-new PALISADE”的中文与英文标识,右侧墙面则展示着城市天际线的背景图,墙上有“INDAL”字样(可能是品牌标识的展示)。展厅左侧区域摆放着棕色皮质沙发和白色毯子,旁边还有一盆绿植,增添自然气息。地面采用灰色瓷砖铺设,天花板采用木质格栅结构并搭配嵌入式灯光,营造出科技感与现代感兼具的氛围。车辆前方放置了一块白色展示牌,上面印有产品信息。整体空间设计简约大气,灯光柔和,突出产品展示的专业性和高端感。
</think>
这张图片展示了**现代汽车展厅内**的一款**帕里斯帝(PALISADE)SUV**,整体场景精致专业,凸显高端汽车展示的氛围。
### 车辆细节
- **外观**:车身为银灰色,车头中央是现代(Hyundai)品牌标志,前脸采用**横向条纹格栅**设计,搭配极具科技感的**大灯**(灯组线条流畅,造型锐利)。车头下方的车牌位置印有“PALISADE”字样,强化车型标识。
- **内饰**:车内座椅为浅色系,材质看起来舒适且精致,整体内饰风格简约大气,契合现代SUV的豪华定位。
- **细节**:车顶配备行李架,轮毂为黑色设计,车身线条流畅且富有力量感。
### 展厅环境
- **背景墙**:左侧墙面印有“新一代帕里斯帝 The all-new PALISADE”字样(中英对照),右侧墙面展示城市天际线背景图,画面中隐约可见“INDAL”字样(可能是品牌标识或宣传元素)。
- **空间布置**:展厅地面为**灰色瓷砖**,天花板采用**木质格栅**与嵌入式灯光搭配,营造出科技感与现代感兼具的氛围。
- **附加元素**:展厅左侧区域摆放着**棕色皮质沙发**和白色毯子,旁边还有绿植点缀,增添温馨感;车辆前方放置一块**白色展示牌**,用于介绍车型信息。
整体来看,展厅通过灯光、布局与细节设计,突出帕里斯帝作为**新一代豪华SUV**的高端定位,传递出专业、现代且舒适的购物体验。
至此模型工作正常。
五、参考文档
Qwen’s Collections on Huggingface
https://huggingface.co/collections/Qwen/qwen3-vl
llama.cpp
https://github.com/ggml-org/llama.cpp
VLLM
https://github.com/vllm-project/vllm
最后修改于 2025-11-18