一、背景
Redshift默认会创建名为dev的数据库,在其中又包含名为public的schema,然后用户在其中创建表和视图。如果希望在同一个Redshift集群内同时创建多个数据库,并且进行跨数据库访问,那么可参照本文的方法。
注:本功能仅支持RA3机型,老的dc2/ds2机型上不支持。
Continue reading “Redshift 跨库查询使用方法”本站是个人兴趣学习笔记而非AWS官方博客,如用于商业生产环境请自行判断风险、谨慎把握

Redshift默认会创建名为dev的数据库,在其中又包含名为public的schema,然后用户在其中创建表和视图。如果希望在同一个Redshift集群内同时创建多个数据库,并且进行跨数据库访问,那么可参照本文的方法。
注:本功能仅支持RA3机型,老的dc2/ds2机型上不支持。
Continue reading “Redshift 跨库查询使用方法”注:2024年2月起,Kinesis Data Firehose也成为了独立产品Data Firehose。再加上之前成为独立产品的Managed Flink,Kinesis的三套件目前都成为了独立产品。
之前很多同学觉得Kinesis比较复杂,这里做一系列入门实验,方便快速采纳服务。点击每个标题后的连接跳转到对应文档。
典型的Kinesis数据流如下图。
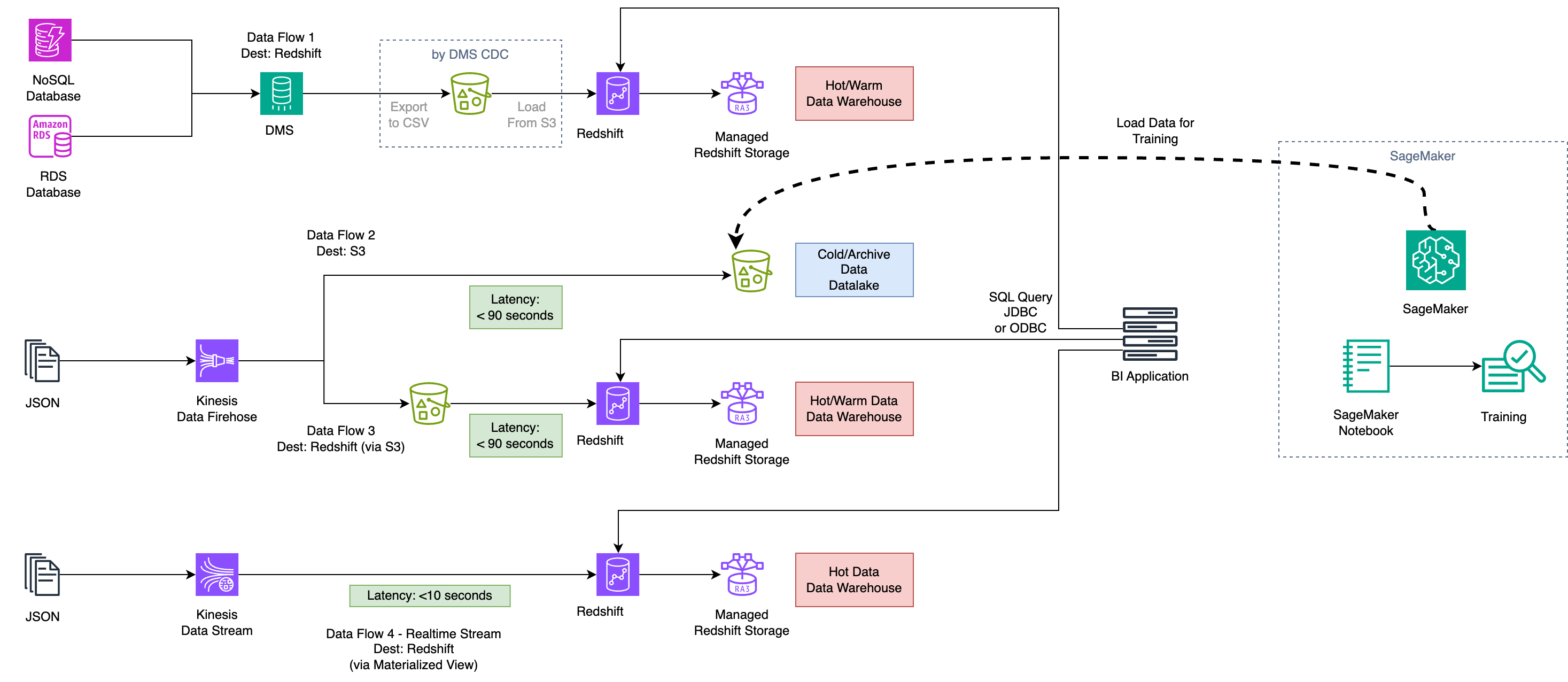
使用Kinesis Data Firehose将数据导入S3数据湖,设置分区键,并转换为Parquet列格式。通过Athena可以极低的开销做低频查询。本方案成本低效果好,对现有系统不侵入,可作为现有大数据分析手段的补充。点击跳转:文档,视频。
使用Kinesis Data Firehose将原始数据以GZIP压缩方式在S3落盘,并按照60秒的间隔自动加载到数Redshift数据仓库。Redshift为MPP架构分布式数仓,支持通过JDBC方式调用,满足BI系统多并发的高频查询要求。点击跳转:文档。
使用Kinesis Data Stream将原始数据放在Kinesis流中,可使用多种消费方式包括KDA(托管Flink)、Redshift等方式消费。本方案采用Redshift的物化视图方式对Kinesis数据流进行消费,并通过自动刷新物化视图实现秒级的延迟。Redshift可满足BI系统多并发的高频查询要求。点击跳转:文档。
注:2024年2月起,Kinesis Data Firehose也成为了独立产品Data Firehose。再加上之前成为独立产品的Managed Flink,Kinesis的三套件目前都成为了独立产品。
Redshift实时数据摄取功能是面向需要实时数据分析客户、对报表低延迟要求极高的客户的最佳选择之一。与使用Data Firehose相比,延迟从1分钟到1分半提升到秒级。
Continue reading “Redshift Realtime Ingress 实时数据摄入之Kinesis Data Stream方案”注:2024年2月起,Kinesis Data Firehose也成为了独立产品Data Firehose。再加上之前成为独立产品的Managed Flink,Kinesis的三套件目前都成为了独立产品。
Kinesis作为AWS流式数据服务的核心产品,支持多种数据服务作为投递对象。通过Kinesis Data Firehose将数据持久化落盘到S3并自动加载到Redshift数据仓库,可实现最低一分钟的分析间隔,且无需额外配置脚本或计划任务用于加载和数据转换。
本文通过自定义脚本生成测试数据,并加载到Redshift。
Continue reading “Kinesis Data Firehose 准实时写入数据到Redshift方案”注:2024年2月起,Kinesis Data Firehose也成为了独立产品Data Firehose。再加上之前成为独立产品的Managed Flink,Kinesis的三套件目前都成为了独立产品。
本文有关操作Demo请参考这个视频。本篇为具体技术配置过程。
Kinesis简介From AWS官网:
Amazon Kinesis Data Firehose (KDF) 是将流数据加载到数据存储和分析工具的最简单方式。Kinesis Data Firehose是一项完全托管式服务,让您可以轻松地从数十万个来源中捕获、转换大量流数据,并将其加载到 Amazon S3、Amazon Redshift、Amazon OpenSearch Service、Kinesis Data Analytics、通用 HTTP 终端节点,以及 Datadog、New Relic、MongoDB 和 Splunk 等的服务提供商中,从而获得近乎实时的分析与见解。
测试Kinesis发送数据流时候,经常使用Kinesis控制台上的生成测试数据按钮,这个按钮将生成如下四个字段:
Continue reading “Kinesis Data Firehose 写入S3动态分区并转换为Parquet格式”对象式存储S3是用于存储海量文件的,当文件达到百万、千万、上亿的时候,S3可正常响应查询、写入的请求,而普通OS上的文件系统在这个数量级必须引入目录散列,并且伴随着性能下降,且如果是虚拟机本地盘还可能出现inodes使用满的情况。这种场景下,S3对象存储针对海量文件是非常友好的。因此使用S3是很有必要的。
S3也有不方便的地方,例如统计文件大小。传统的文件系统方式是做遍历后求和。那么S3上数百万个文件做一次遍历,开销极其巨大,而且产生了巨大的读取费用(List也算读取,参考S3收费文档)。由此,S3有个功能是S3 Inventory,即每天一次生成文件清单,并可通过Athena做进一步查询文件名称和大小。此外,还可以通过S3 Storage Lens查看各存储桶的总数据量和类型。
Continue reading “使用Python Boto3从CloudWatch获取S3存储桶大小的Metric值”关于S3 Storage Lens功能介绍如下。
Continue reading “Python boto3 API调用Storage Lens配置”录屏仅登陆,无创建/配置/迁移等。
在一份账单中占比最大的部分可能就是EC2,EC2部分也包含了诸如EKS集群使用的node节点等用量。在部分机型是On-demand按需运行,部分机型是有多个RI预留时候,账单可能显示的比较复杂,晦涩难懂。那么如何解读账单中体现的EC2用量呢?本文以某个场景为例进行分析和解读。在开始解读账单之前,首先要看下RI预留实例的计费逻辑。
Continue reading “如何读懂一份AWS账单的EC2预留实例匹配关系”