Redshift Realtime Ingress 实时数据摄入之Kinesis Data Stream方案
介绍如何通过Kinesis Data Stream实现Redshift实时数据摄入,相比Firehose方案延迟从分钟级降低到秒级,包含完整的配置步骤和测试数据生成方案。
注:2024年2月起,Kinesis Data Firehose也成为了独立产品Data Firehose。再加上之前成为独立产品的Managed Flink,Kinesis的三套件目前都成为了独立产品。
一、背景
Redshift实时数据摄取功能是面向需要实时数据分析客户、对报表低延迟要求极高的客户的最佳选择之一。与使用Data Firehose相比,延迟从1分钟到1分半提升到秒级。
官网介绍如下:
以前,将数据从 Amazon Kinesis 等串流服务加载到 Amazon Redshift 涉及多个步骤。这包括将串流连接到 Amazon Kinesis Data Firehose,以及等待 Kinesis Data Firehose 在 Amazon S3 中存储数据,以不同长度的缓冲区间隔使用各种大小的批处理。然后 Kinesis Data Firehose 会启动 COPY 命令,以将数据从 Amazon S3 加载到 Redshift 中的表。
如今,Redshift流式摄取不再在 Amazon S3 中暂存数据,而是直接以低延迟、高速度的方式将串流数据从 Amazon Kinesis Data Streams 和 Amazon Managed Streaming for Apache Kafka 摄取到 Amazon Redshift 实体化视图中。因此,它减少了访问数据所需的时间并降低了存储成本。您可以为 Amazon Redshift 集群或 Amazon Redshift Serverless 配置串流摄取并使用 SQL 语句创建实体化视图,如在 Amazon Redshift 中创建实体化视图中所述。然后借助实体化视图刷新,每秒可以摄取数百兆字节的数据。从而快速访问快速刷新的外部数据。
二、准备工作
1、创建Redshift使用的IAM Policy
新建如下一个IAM Policy,取名为RedshiftRealtimeStreaming。
在Resource这一行的IAM_ROLE位置的arn:aws:iam:用户12位账户ID,填写时候请注意,如果是中国区则ARN的第二段是aws-cn,如果是海外区域,则填写为aws。如下为Policy规则。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ReadStream",
"Effect": "Allow",
"Action": [
"kinesis:DescribeStreamSummary",
"kinesis:GetShardIterator",
"kinesis:GetRecords",
"kinesis:DescribeStream"
],
"Resource": "arn:aws-cn:kinesis:*:0123456789:stream/*"
},
{
"Sid": "ListStream",
"Effect": "Allow",
"Action": [
"kinesis:ListStreams",
"kinesis:ListShards"
],
"Resource": "*"
}
]
}
创建IAM Policy完毕。
2、创建创建Redshift使用的IAM Role
在IAM界面上,点击创建角色的按钮。如下截图。选择要创建的角色类型是Redshift,并点击下一步继续。如下截图。
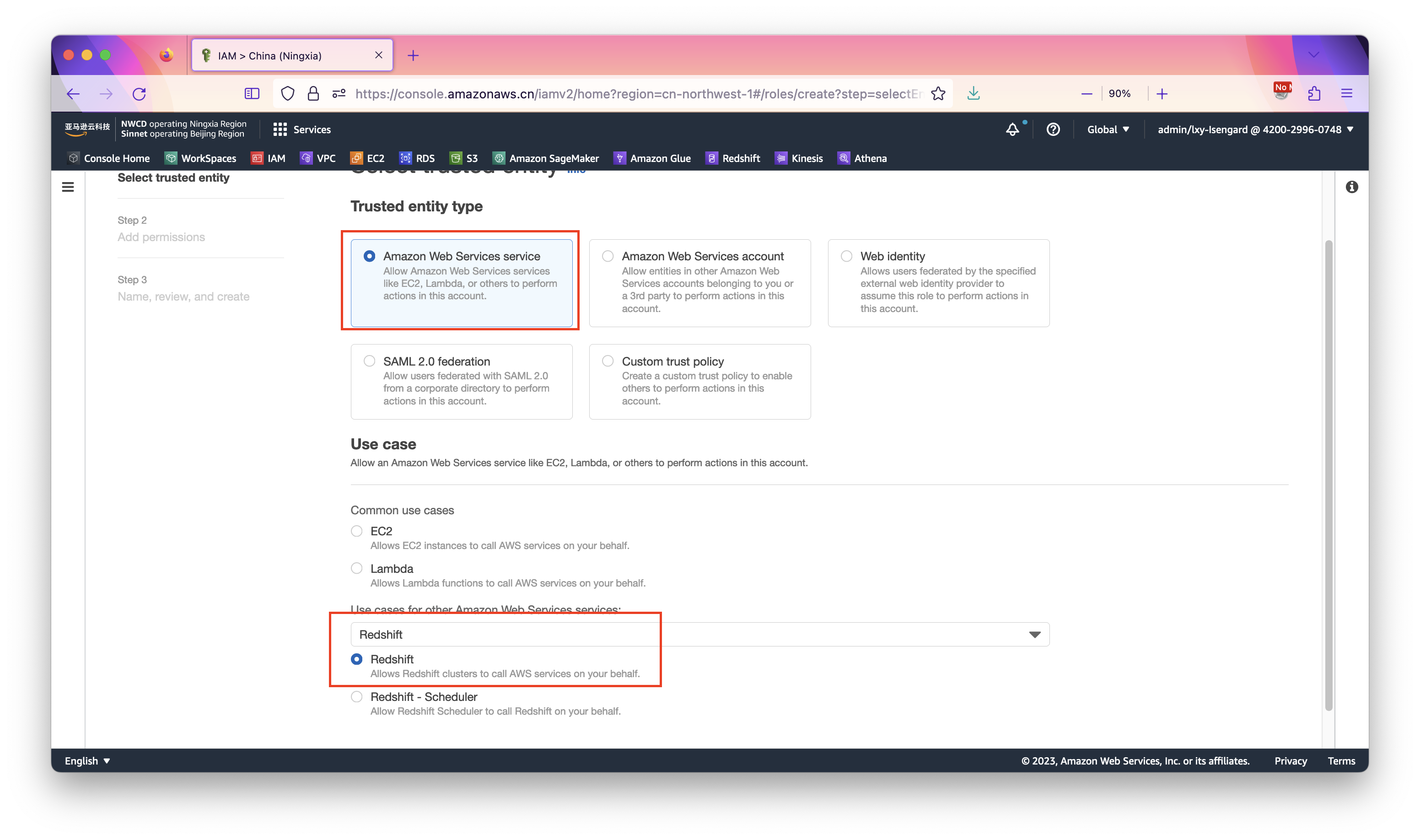
在创建IAM Role向导中,选中上一步创建的RedshiftRealtimeStreaming策略,然后点击下一步。
在设置IAM Role名字的界面上,输入Redshift_KDS_Role作为名称。
本页面上其他默认设置不需要调整,不管是海外区域还是中国区,都使用相同的设置。如下截图。
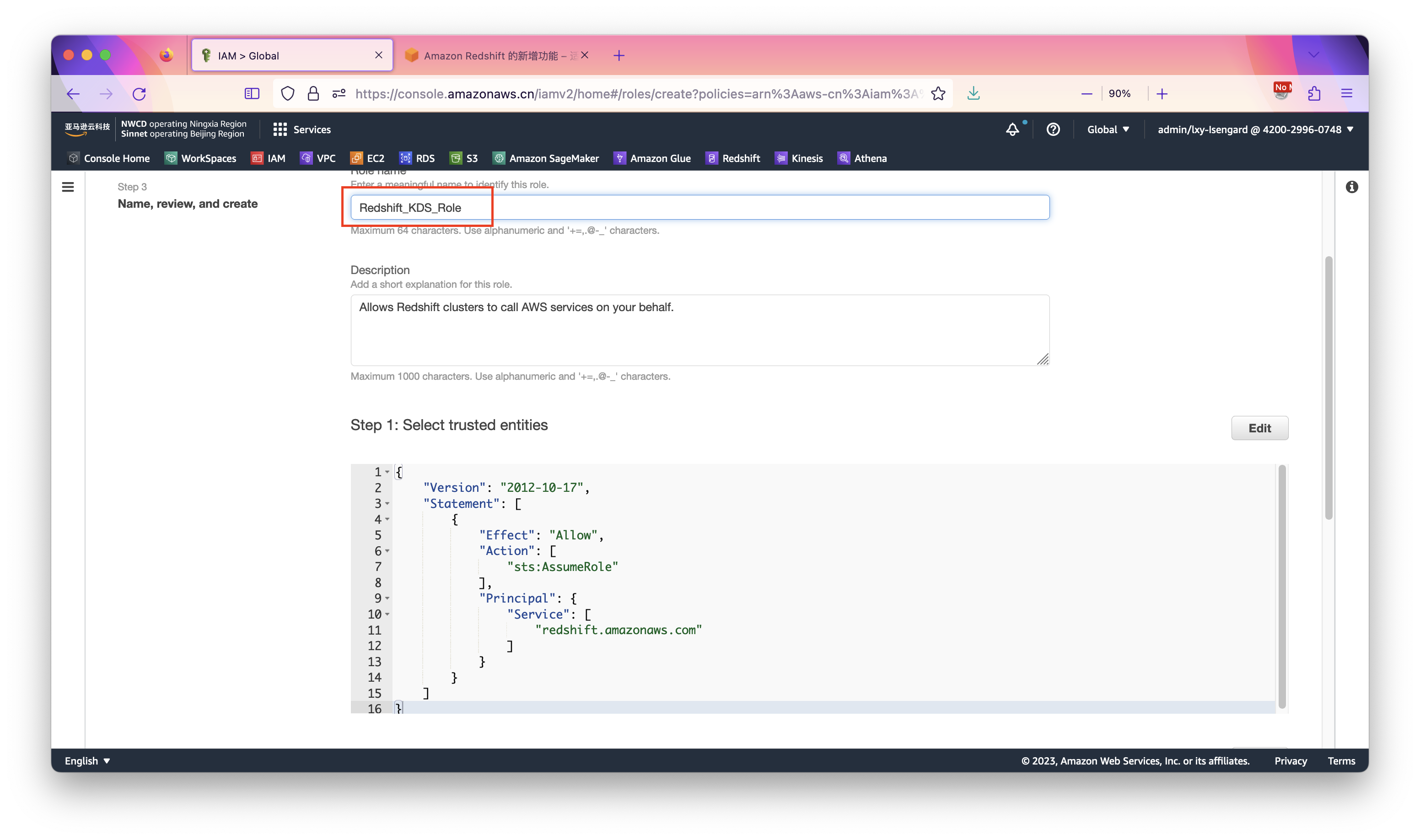
最后点击右下角创建按钮,创建IAM Role完成。
3、创建Redshift需要的EIP
由于Kinesis是在互联网上运行的服务,默认是通过互联网写入Redshift,因此需要为Redshift配置一个EIP用于接受流量,并为Redshift配置安全规则组允许来自Kinesis地址范围的写入。本文按照最简单的配置通过互联网写入,并通过安全规则组和IP地址限制确保Redshift的安全。如果希望Redshift从VPC内部网络访问,请参考这篇文档设置Kinesis的VPC Endpoint。
进入EC2界面,点击左侧的Elastic IPs按钮,点击右侧上的申请新的EIP按钮,获得一个新的EIP。如下截图。
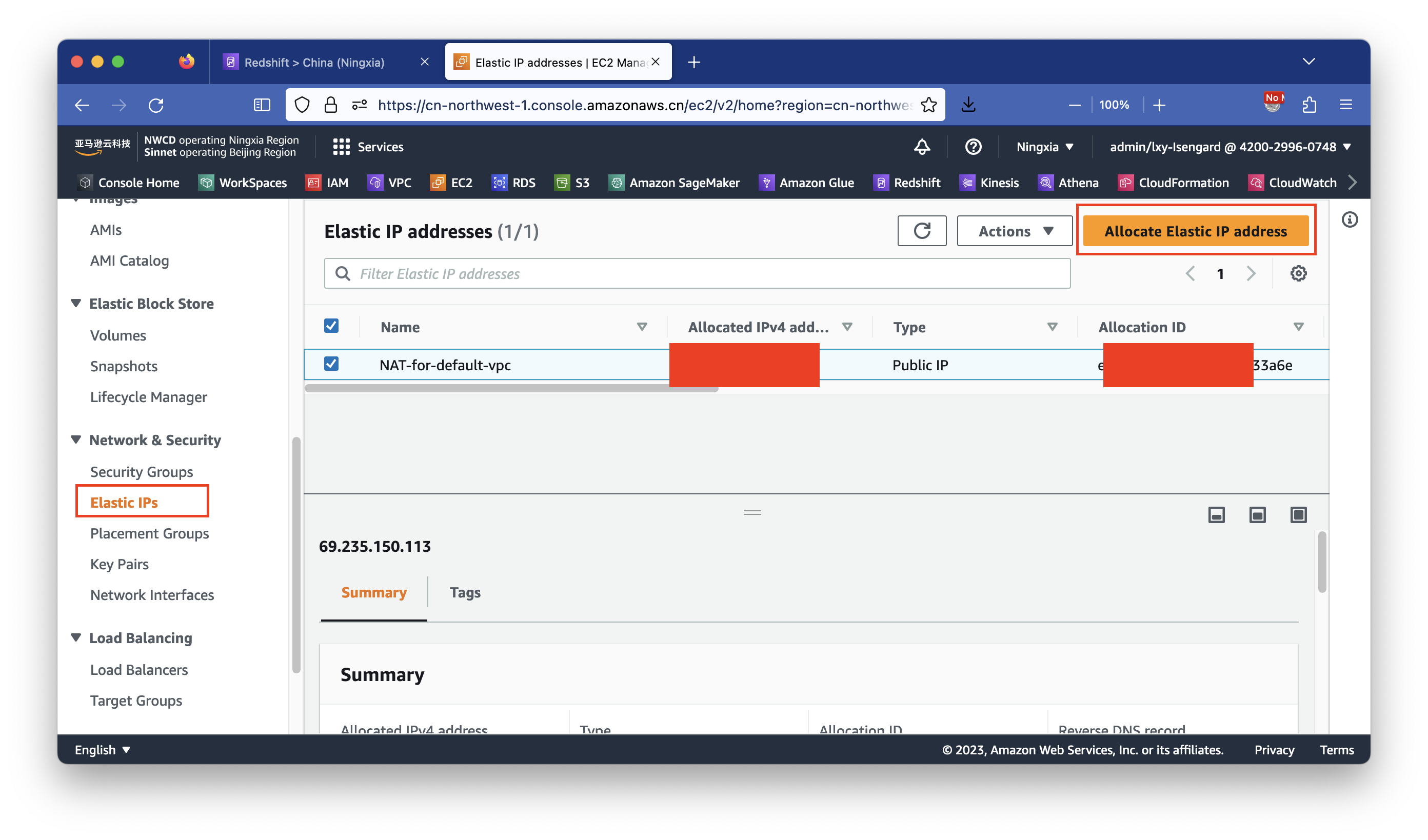
配置完成获得EIP一个。
4、创建Redshift需要的安全规则组
进入VPC服务,找到安全规则组,创建一个Redshift专用的新的安全规则组。
Redshift从Kinesis Data Stream摄取实时数据流不需要额外对外暴露Redshift端口。在入栈方向,将5432端口开放给要通过JDBC调用的应用地址即可。在出栈方向,设置为允许去往0.0.0.0/0所有方向。具体设置过程请参考相关文档,不再截图描述。
备注:Redshift从Kinesis Data Stream摄取实时数据流与Kinesis Data Firehose搭配Redshift的网络要求不同。Kinesis Data Firehose因为要主动触发Redshift加载按照1分钟间隔加载数据,因此还需要额外的开放5432入栈端口允许来自Kinesis Data Firehose连接Redshift。而本文的实时摄取是基于Kinesis Data Stream服务,由Redshift的物化视图主动去加载Kinesis数据。因此不需要在额外配置入栈端口了。
5、创建Redshift集群
创建Redshift的过程可简化操作快速创建,这里不再逐页截图,只说明重要的信息:
- Redshift集群名称可任意设置
- 类型选择为
Production生产 Node type机型:如果是做实验,可选择为1台ra3.xplus,最大支持4TB存储;如果是生产环境,可选择2台ra3.4xlarge,每台最大支持32TB存储,2台构成集群总计64TBSample data加载样例数据位置不需要选择- 正常设置用户名和密码
在设置Redshift使用的IAM Role的位置,点击Associate IAM roles。如下截图。
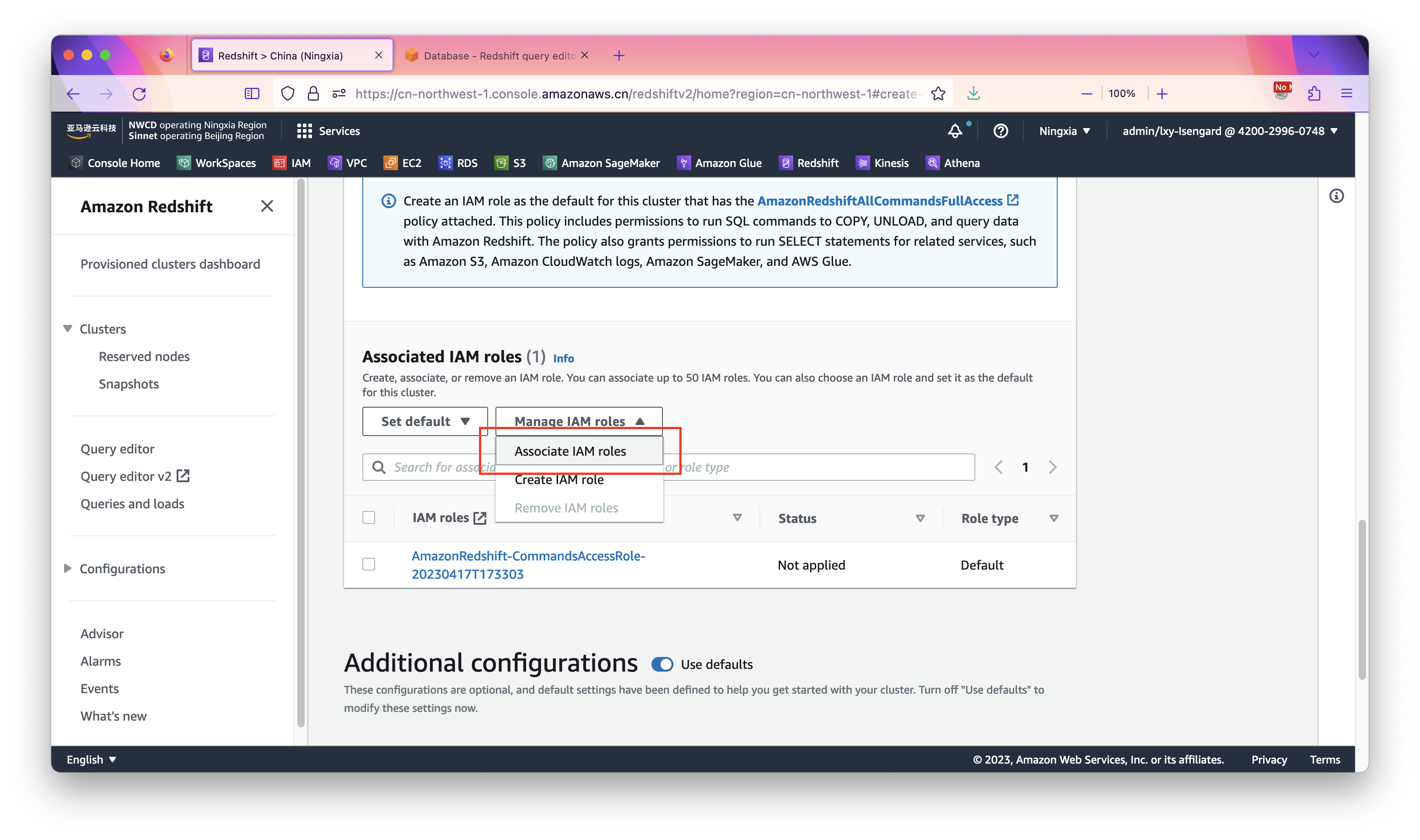
在IAM roles清单中选择上一步新建的IAM Role。如下截图。
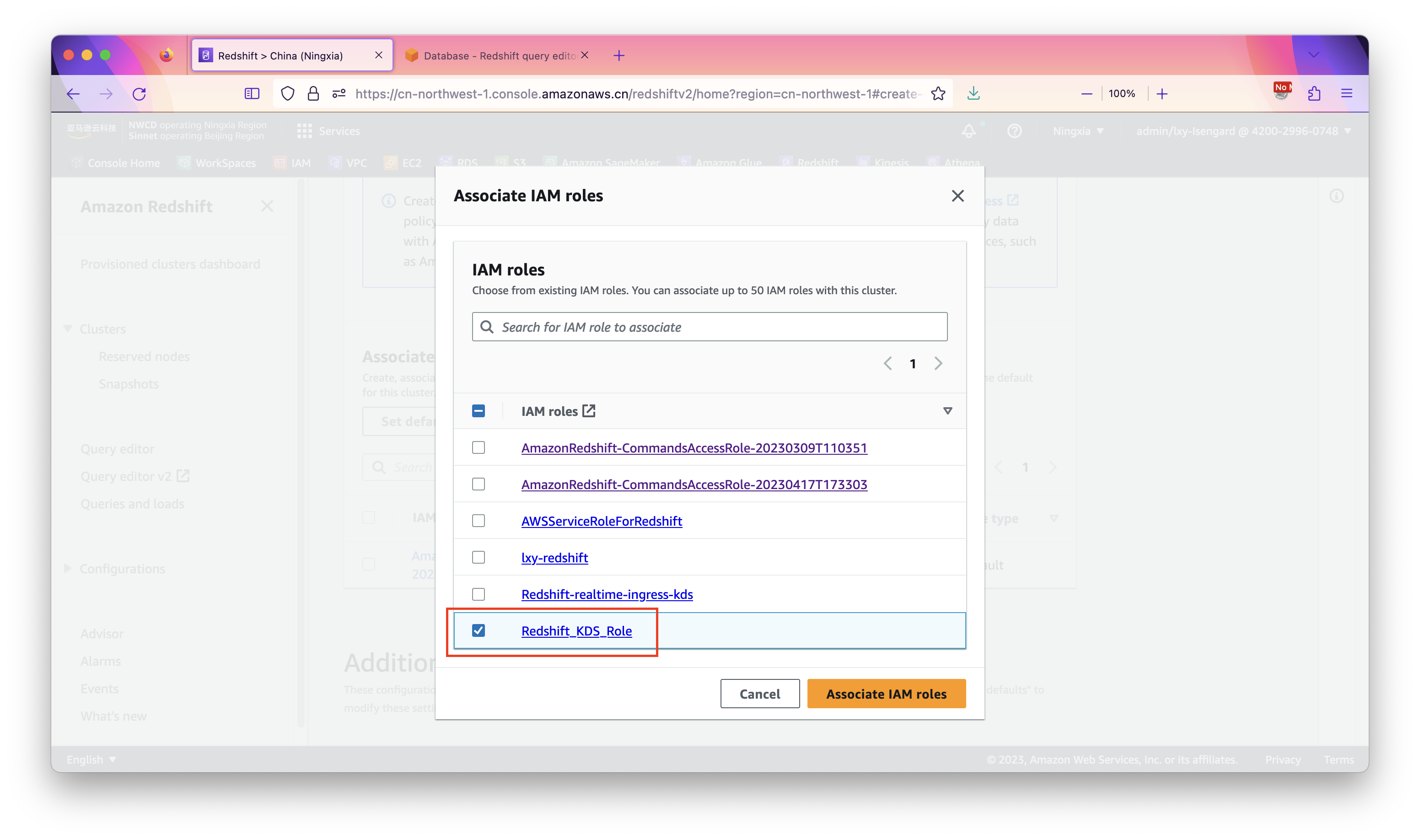
选中后效果如下,界面返回到创建向导。如下截图。
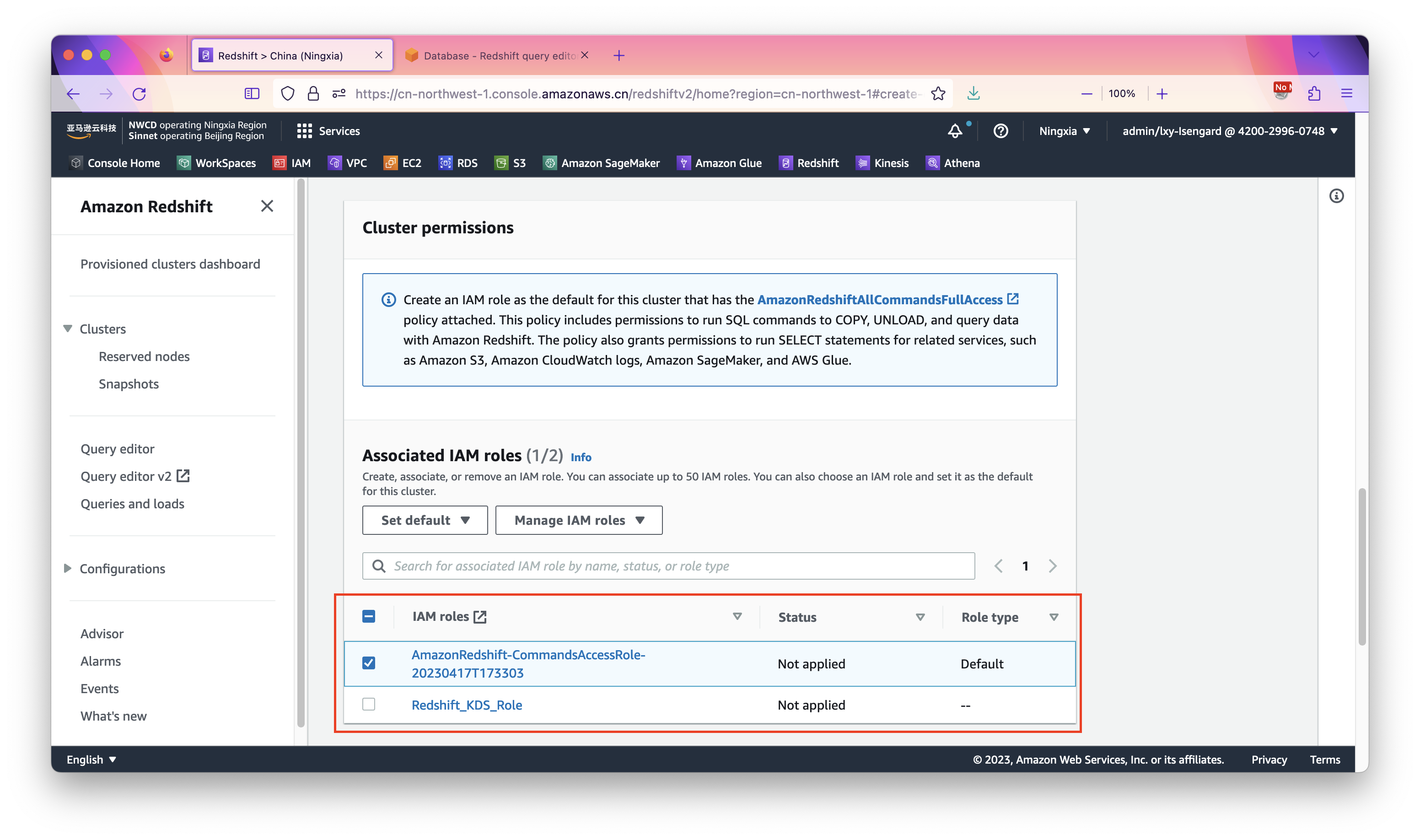
点击下方的高级设置,调整网络配置。
在安全规则组位置,选择前文配置的安全规则组。在Enhanced VPN routing位置选择Turn off,因为默认配置从互联网访问+安全规则组限制来源范围更简单。在Publicly accessible位置,选择Turn on。最后在页面下方的EIP位置,选择上一步创建的EIP。如下截图。
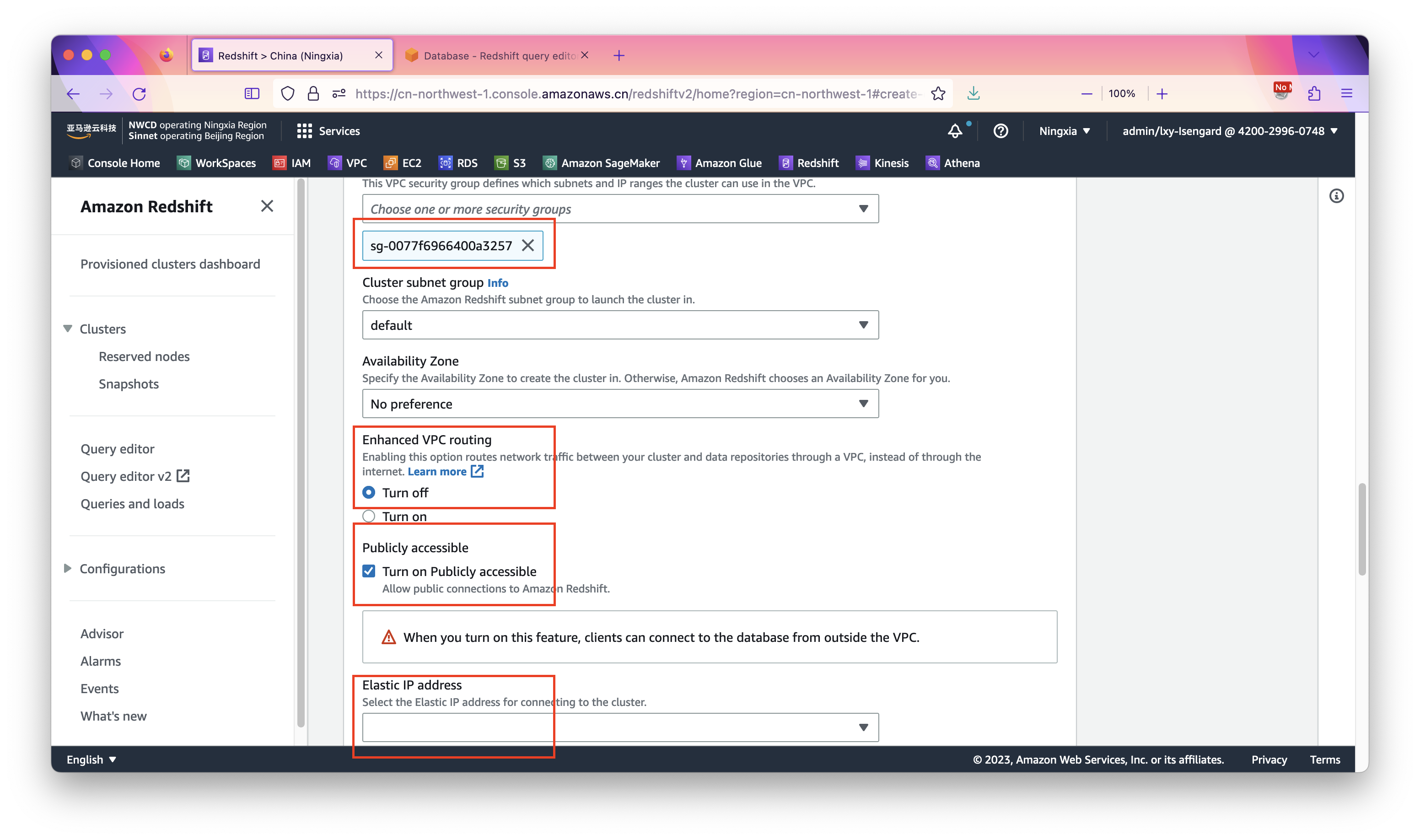
后续其他Redshift集群参数保持默认,点击创建完成。
三、创建Kinesis Data Steam流
进入Kinesis控制台的Dashboard,点机创建Kinesis Data Stream按钮。如下截图。
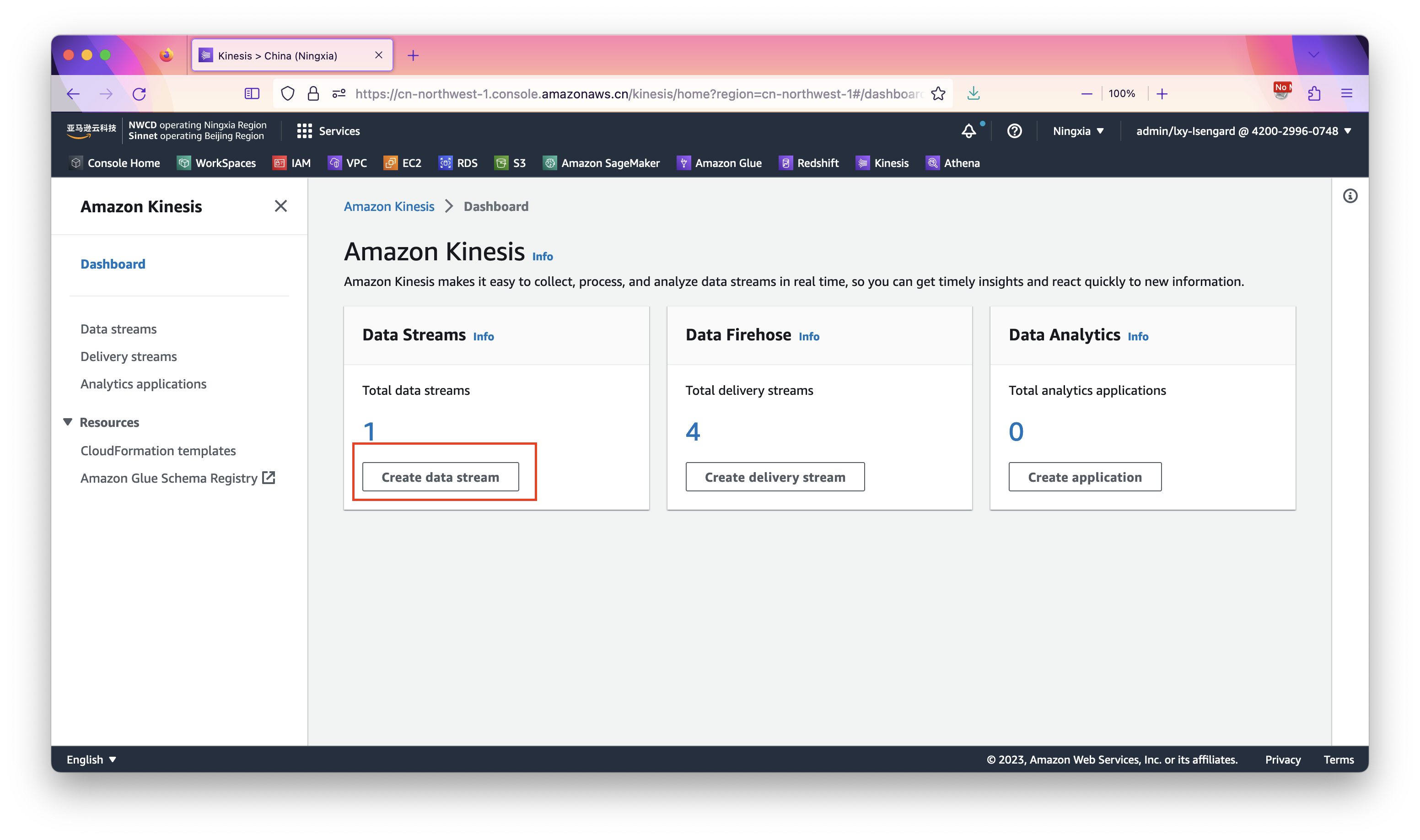
在创建向导中摄入名字,取名为kds-to-redshift,然后选择模式为On-demand。其他选项保持默认,点击右下角创建按钮完成。
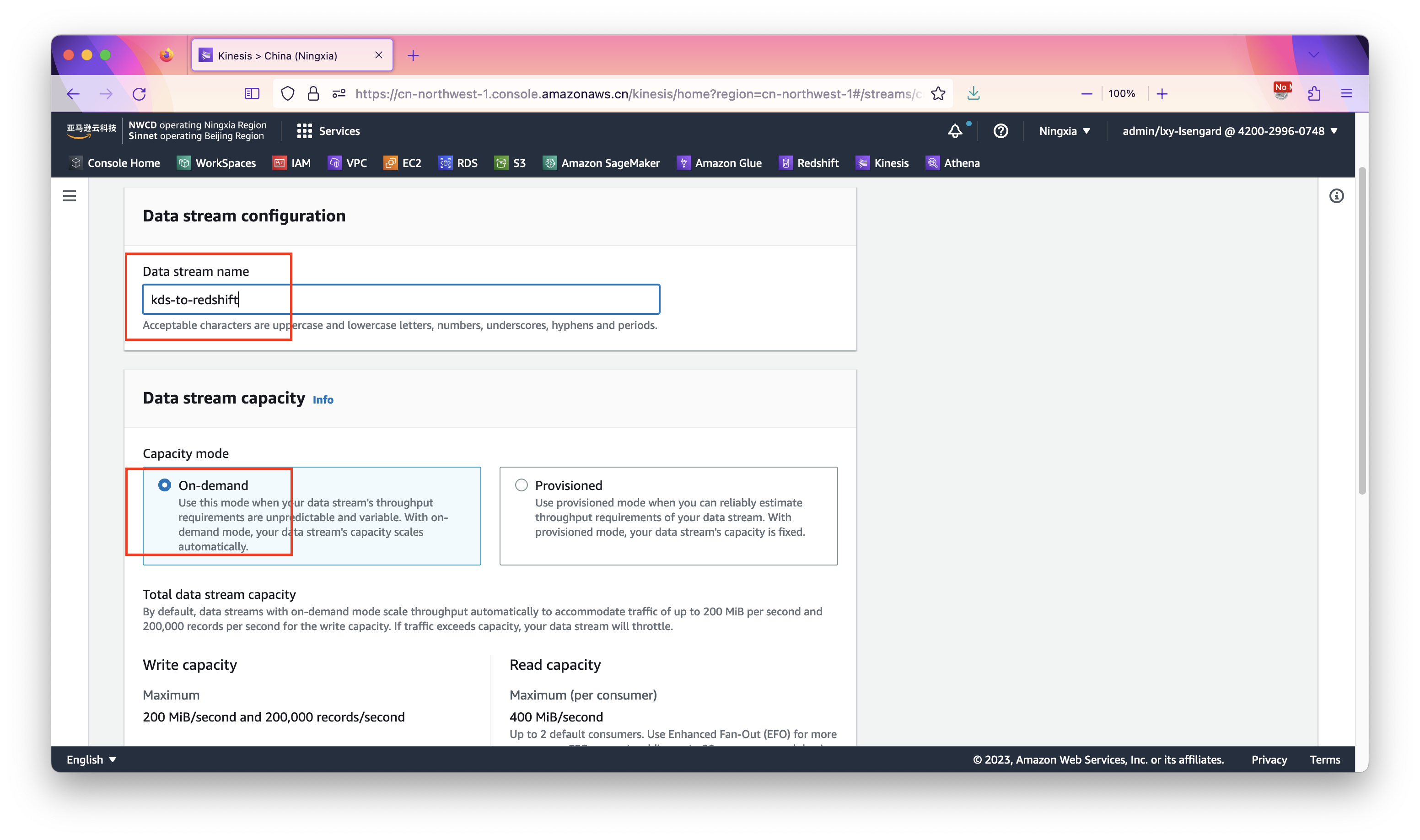
创建Kinesis Data Stream完成。
四、Redshift物化视图配置
1、创建Schema
进入已经创建好的Redshift集群的Query Editor V2,创建Schema。以下命令中,Schema取名叫做stream01,可根据需要修改。
在IAM_ROLE位置的arn:aws:iam:用户12位账户ID这里请注意,如果是中国区,ARN的第二段是aws-cn,如果是海外区域,则填写为aws。
例如亚马逊云科技中国区:
CREATE EXTERNAL SCHEMA stream01
FROM KINESIS
IAM_ROLE 'arn:aws-cn:iam::420029960748:role/service-role/AmazonRedshift-CommandsAccessRole-20230417T173303';
例如AWS海外区域:
CREATE EXTERNAL SCHEMA stream01
FROM KINESIS
IAM_ROLE 'arn:aws:iam::420029960748:role/service-role/AmazonRedshift-CommandsAccessRole-20230417T173303';
执行成功后效果页面返回如下。
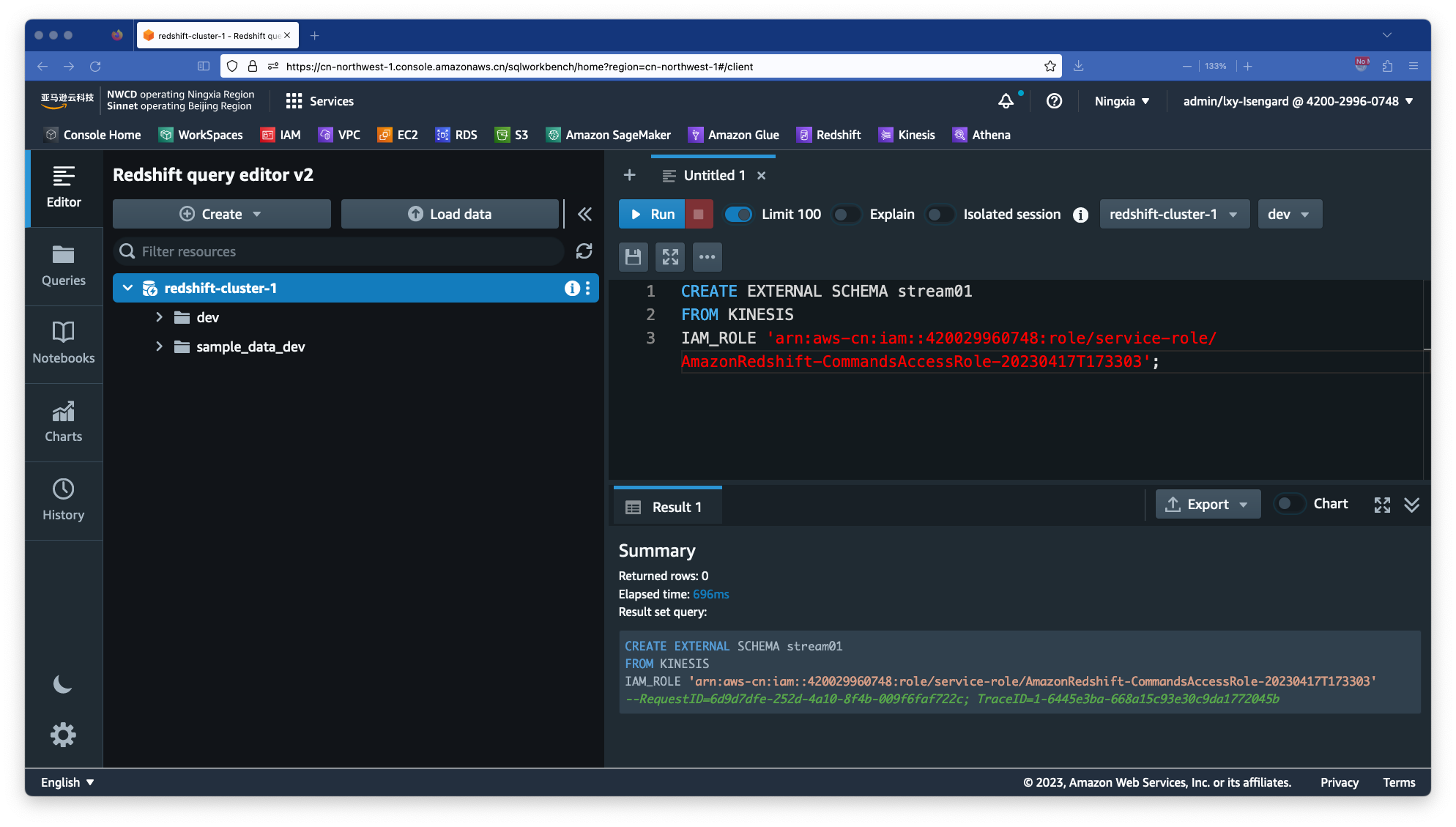
在这一步完成后,Redshift Query Editor V2右侧已经可以在Redshift菜单下看到新的Schema名叫Stream01,展开后也可以看到里边的表结构。
2、创建物化视图
在创建物化视图时候,可根据业务要求,对数据流发送过来的JSON放置到Redshift的一列中,以后查询的时候获取本列返回整个JSON。也可以将Kinesis Data Stream流中的JSON文件展平,直接对号入座到Redshift列。这两种采用哪一种方式,主要取决于流上的JSON数据格式和字段是否经常变化。如果经常变化,请选择方式一,将整个JSON放入一列。如果JSON数据是结构化、不变化,且为了查询方便,则可以采取方式二,将JSON展平,数据对号入座到各列。本文采用方式二。
在Redshift上执行以下SQL创建物化视图。其中stream_data_extract是Redshift上要使用的物化视图的名字,JSON_EXTRACT_PATH_TEXT后边的数据是来自Kinesis流的数据,stream01是一开始前一步创建Schema的名字,kds-to-redshift是前一步创建Kinesis Data Stream时候流的名字。
CREATE MATERIALIZED VIEW stream_data_extract AUTO REFRESH YES AS
SELECT approximate_arrival_timestamp,
partition_key,
shard_id,
sequence_number,
refresh_time,
JSON_EXTRACT_PATH_TEXT(FROM_VARBYTE(kinesis_data, 'utf-8'),'msgtime')::CHARACTER(32) as msgtime,
JSON_EXTRACT_PATH_TEXT(FROM_VARBYTE(kinesis_data, 'utf-8'),'ticker_symbol')::VARCHAR(8) as ticker_symbol,
JSON_EXTRACT_PATH_TEXT(FROM_VARBYTE(kinesis_data, 'utf-8'),'sector')::VARCHAR(16) as sector,
JSON_EXTRACT_PATH_TEXT(FROM_VARBYTE(kinesis_data, 'utf-8'),'change')::float as change,
JSON_EXTRACT_PATH_TEXT(FROM_VARBYTE(kinesis_data, 'utf-8'),'price')::float as price
FROM stream01."kds-to-redshift";
操作成功后,返回结果如下截图。
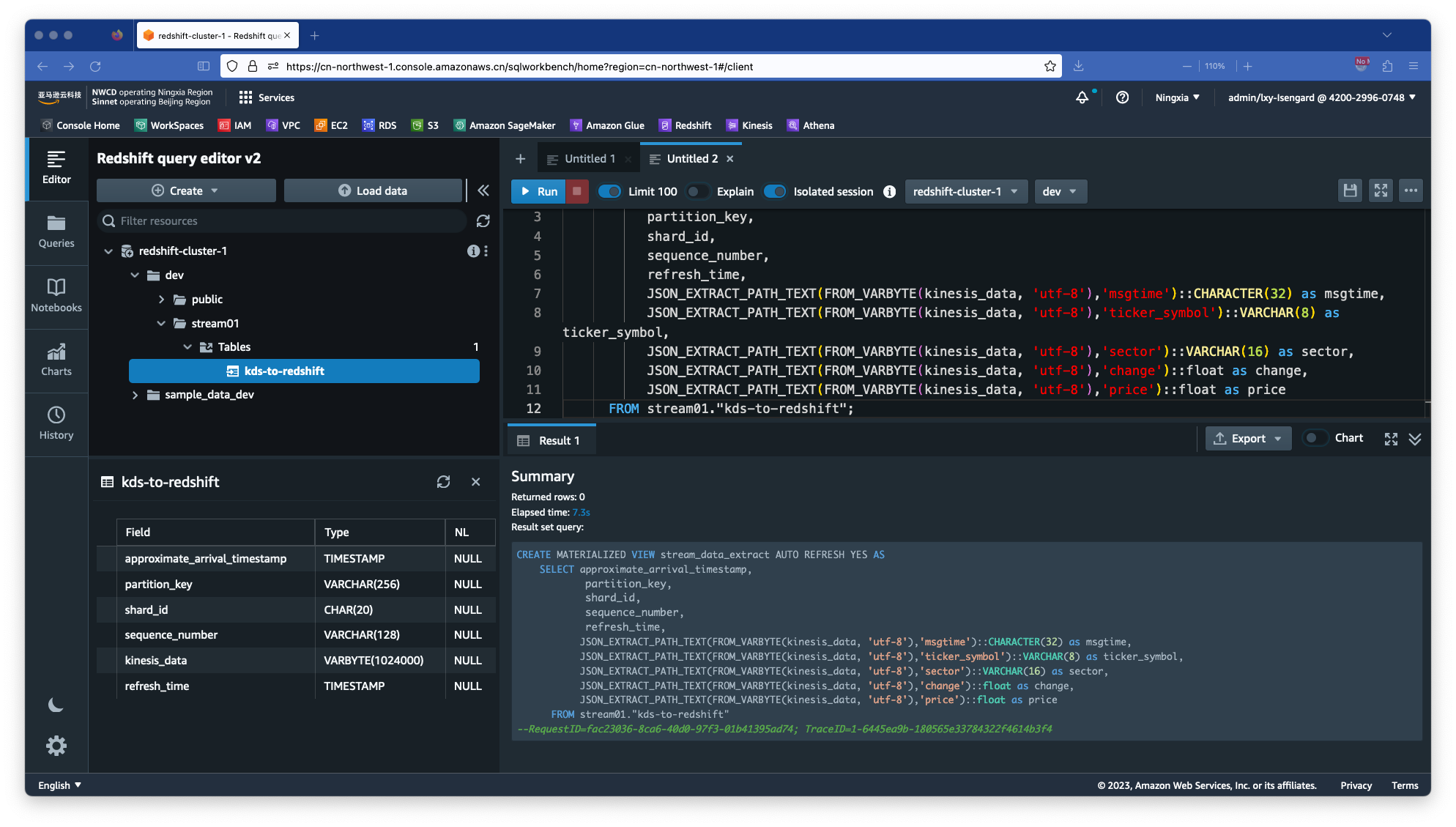
创建完毕后,即可在Redshift默认的Schema名叫Public下的View视图菜单中,看到新创建的stream_data_extract物化视图。接下来模拟数据流。
五、生成测试数据
本文使用如下Python脚本模拟。
import boto3
from botocore.config import Config
import time
import json
import random
# Kinesis Data Firehose stream name
output_stream = "kds-to-redshift"
kinesis_client = boto3.client('kinesis', config=Config(region_name='cn-northwest-1'))
# Submit to Kinesis
for i in range(1000):
# Source data before Lambda Transformation
msgtime = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
sector = random.sample(['ENERGY', 'RETAIL', 'TECHNOLOGY', 'HEALTHCARE'], 1)[0]
ticker_symbol_list = random.sample(['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z'], 3)
ticker_symbol = ticker_symbol_list[0] + ticker_symbol_list[1] + ticker_symbol_list[2]
# Build json
data1 = {
"msgtime" : msgtime ,
"ticker_symbol" : ticker_symbol ,
"sector" : sector ,
"change" : round(random.uniform(-10, 10),4) ,
"price" : round(random.uniform(-10, 10),4)
}
msg = json.dumps(data1)
kinesis_client.put_record(
StreamName = output_stream ,
Data= msg ,
PartitionKey = sector
)
print(msg)
time.sleep(5)
运行生成数据脚本前,需要在运行代码的环境上提前配置好Python、AWSCLI的密钥,设置好AWS区域。执行如下命令安装Boto3库。
pip3 install boto3
设置完毕后,运行以上Python脚本,开始生成测试数据。如下截图。
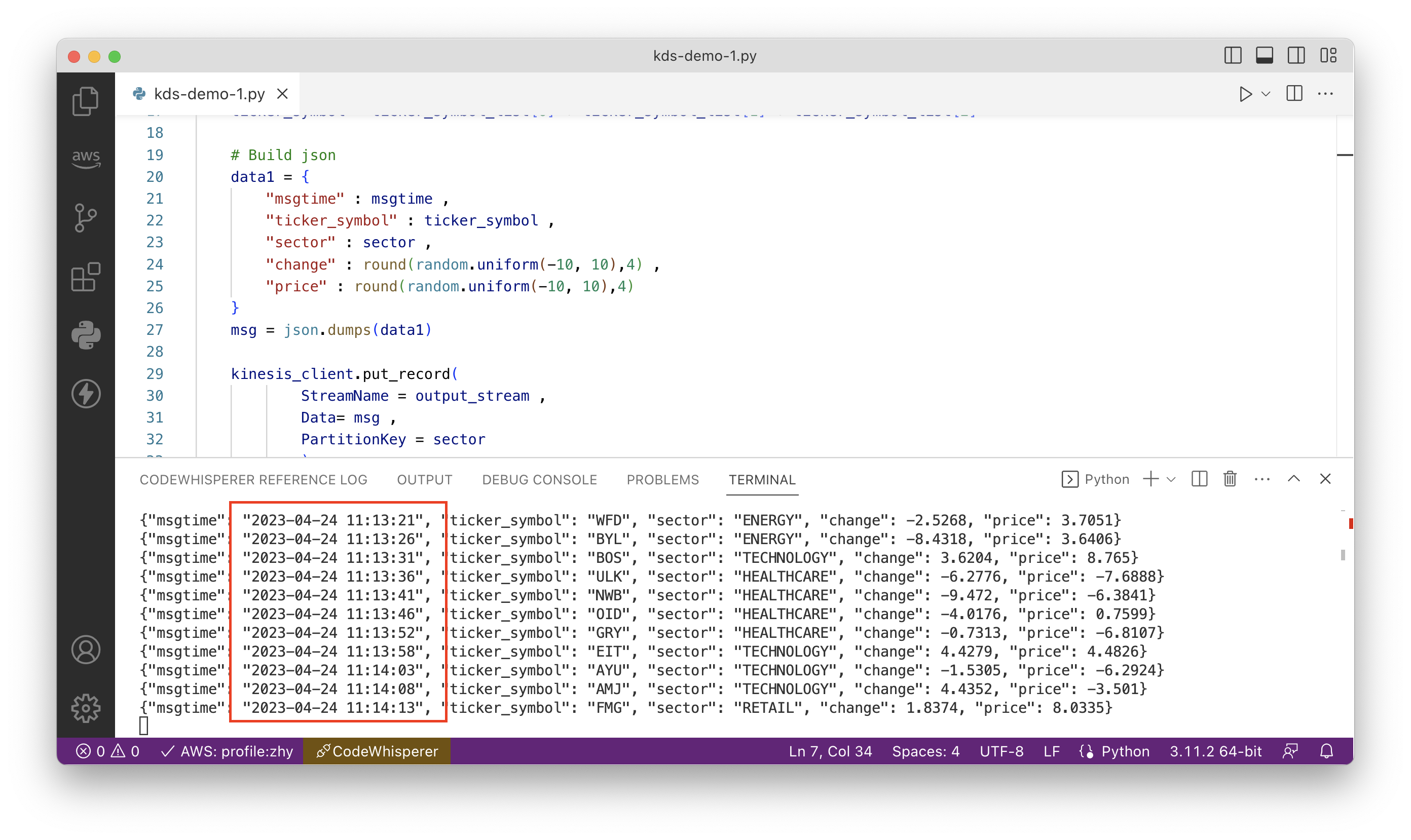
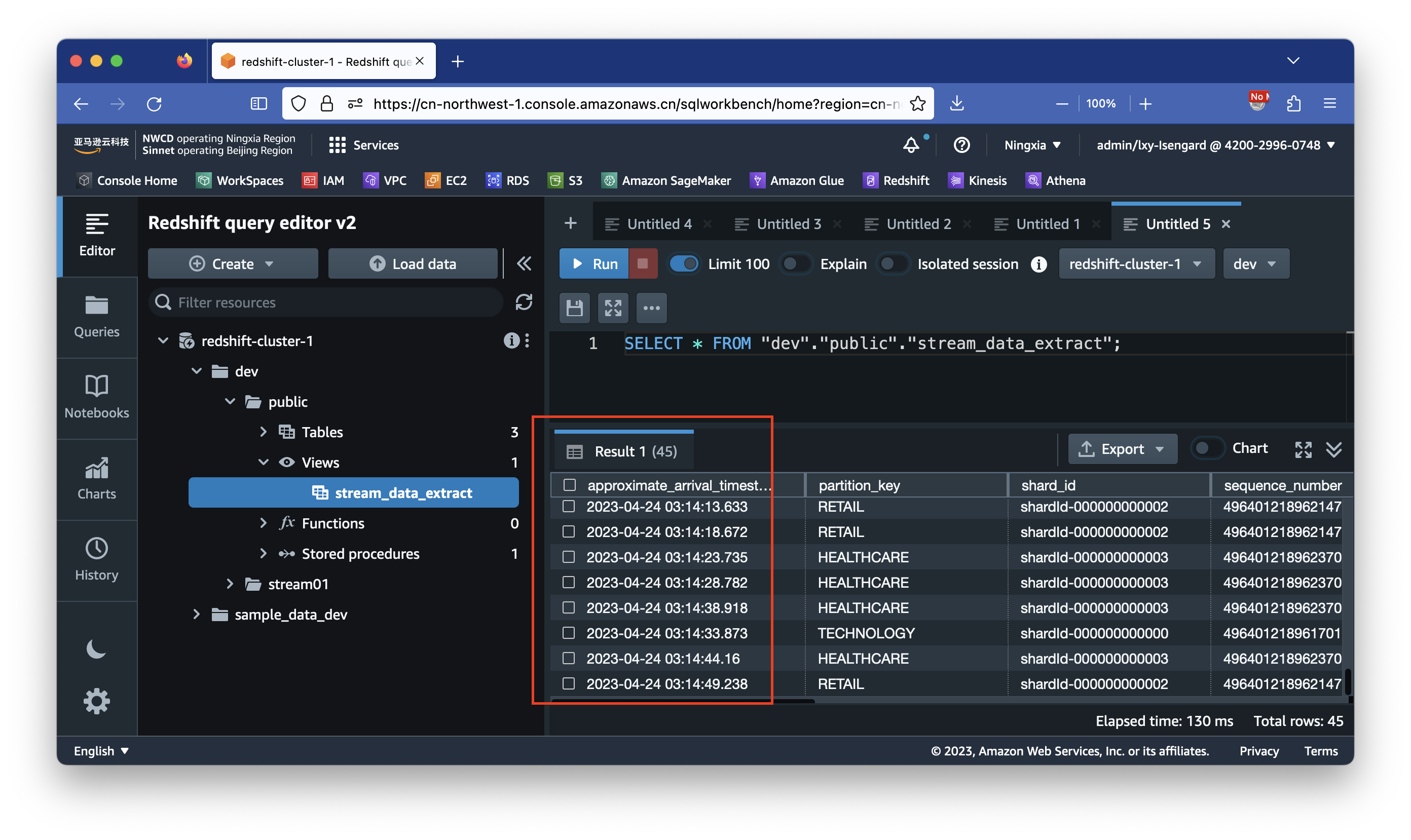
接下来切换到Redshift Query Editor V2界面上。对刚才创建的物化视图做查询,可看到时间戳,可看到里边查询结果已经生成对应的数据。
查询命令如下:
SELECT * FROM "dev"."public"."stream_data_extract" order by approximate_arrival_timestamp desc limit 10;
注意Kinesis发送给Redshift的数据的时间戳是UTC标准时间,和北京时间差8个小时。可看到这部分数据生成的就是刚才Python脚本生成的数据。如下截图。
为了查询磁盘空间占用,可执行如下命令。请替换其中的mv_tbl__stream_data_extract__0为Redshift上看到的表的名字。
select stv_tbl_perm.name as table, count(*) as mb
from stv_blocklist, stv_tbl_perm
where stv_blocklist.tbl = stv_tbl_perm.id
and stv_blocklist.slice = stv_tbl_perm.slice
and stv_tbl_perm.name = 'mv_tbl__stream_data_extract__0'
group by stv_tbl_perm.name
order by 1 asc;
即可查看当前物化视图占用的磁盘空间。
至此Kinesis到Redshift的Realtime Ingress流式注入配置完成。
六、参考文档
Amazon Redshift 的新增功能 – 适用于 Kinesis Data Streams 的流式摄取和适用于 Apache Kafka 的托管流式处理正式推出
开始使用 Amazon Kinesis Data Streams 串流摄取
最后修改于 2023-04-25