Amazon Bedrock上的Anthropic Claude开箱及Converse API使用
详解如何在Amazon Bedrock上使用Claude模型,涵盖权限申请、IAM配置、Converse API调用、图像文档处理等完整实现方案
本文更新了Converse API的使用,从原来的invoke_model的API更换为Converse API。
本文介绍了Amazon Bedrock服务的初始化,如何开始使用Claude模型,并讲解了最新的Converse API的使用,实现文本生成、图像理解、文档理解、流式输出等场景。
一、背景
Amazon Bedrock是托管的大模型服务,可通过API调用来自多家公司的基础模型(Foundation Model, 以下简称FM),包括AI21 Labs、Anthropic、Cohere、Meta、Stability AI以及Amazon等。使用Amazon Bedrock可通过模型微调(Fine-tune)和检索增强生成(Retrieval Augmented Generation,以下简称RAG)等技术实现更好的检索效果。由于Amazon Bedrock是无服务器的,因此您无需管理EC2虚拟机、GPU等基础设施,可使用多种开发语言从应用程序中调用,使用场景包括文本生成、文本摘要、图像生成、对话、虚拟助手、知识库、向量转换等。
在大模型的选择上,除了大家熟知的Meta(Facebook)的Llama等模型之外,Bedrock提供了来自Anthropic的Claude模型。在模型版本选择上,Claude的版本对应如下:
- Opus :最强的数学能力,但是慢,且贵。
- Sonnet:速度、能力、成本的均衡。
- Haiku:最便宜的成本,也具备多模态识别图像的能力,适合大量数据处理
下边开始介绍使用。
二、申请模型访问权限并在AWS控制台上使用
注:以下操作以具备AWS账号AdministratorAccess的账号来操作。
1、确认联系信息为海外地址
申请Bedrock服务中的Claude大模型要求必须有AWS海外账户。根据Claude模型的EULA用户协议,使用Claude模型的公司需要是海外实体。因此这里申请时候,账户的联系信息登记的支付信息(Billing Address)等信息都应为海外地址,不能是中国大陆地址也不能是香港地址。如果之前注册账号的时候,使用了中国大陆地址注册或使用香港地址,则可以在账户信息页面编辑修改,使用公司的海外营业机构地址。比如改为贵公司在新加坡的门店、当地员工所在办公地址。
此处修改还涉及不同国家税费的问题,请咨询为您服务的客户经理和商务人员。
从右上角进入自己账户的Billing and Cost Managment界面。
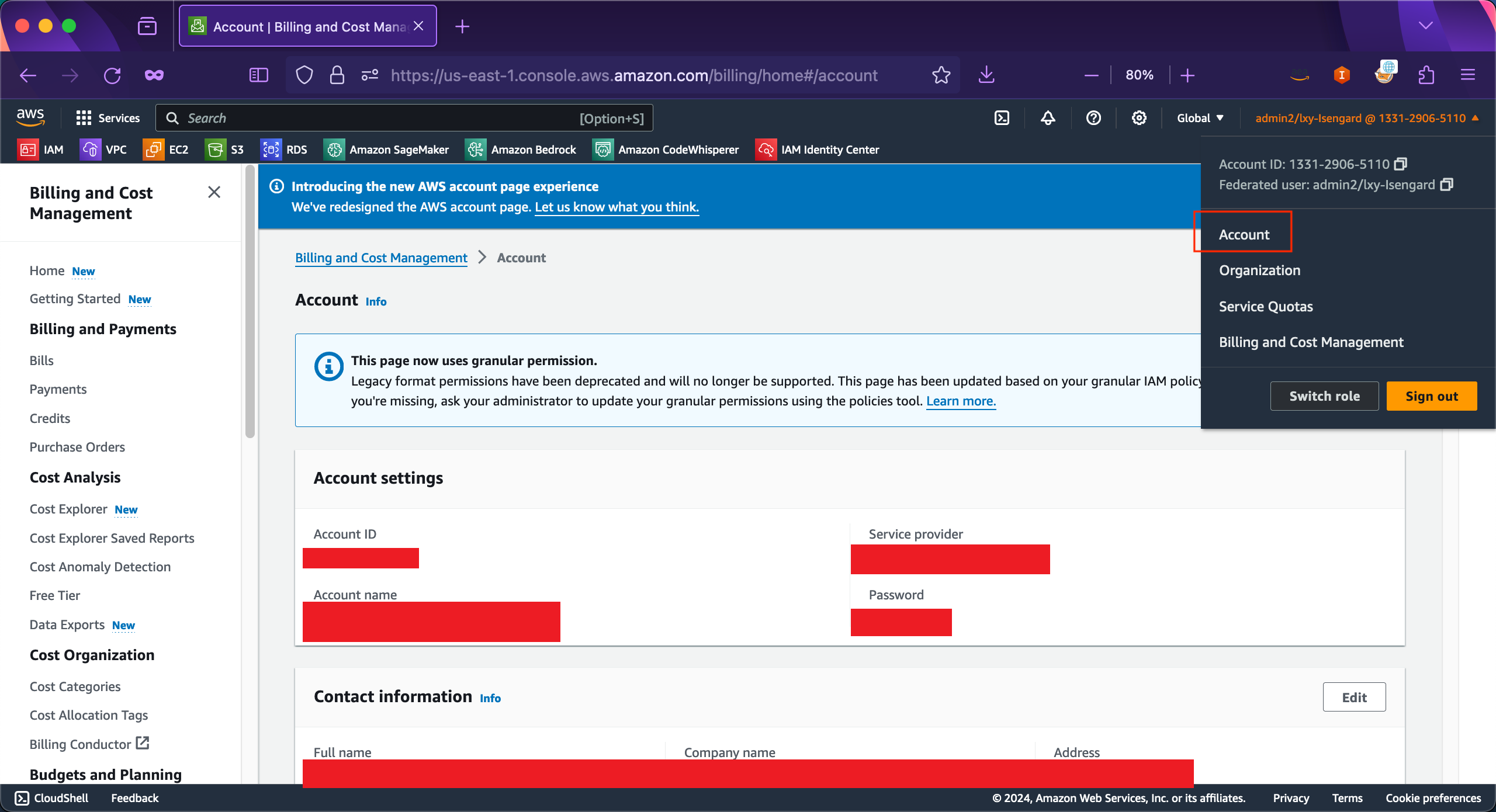
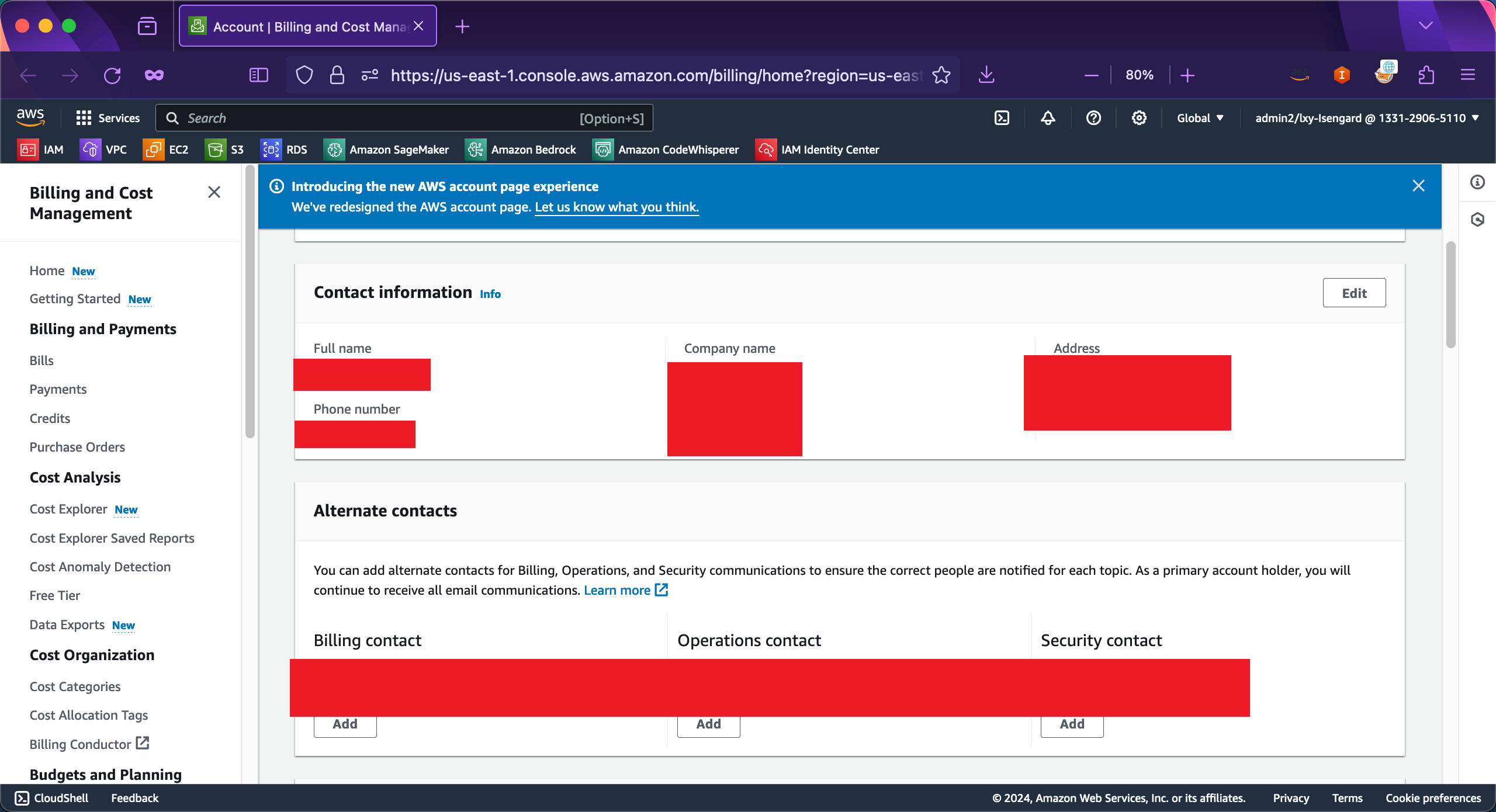
向下移动页面中,找到联系信息,编辑他们,确保使用海外分支机构的地址和联系人。
2、申请模型权限
切换要操作的Region到特定区域,例如本文为us-west-2美西2俄勒冈区域。
接下来进入Bedrock服务界面,可看到其中的模型如果还没申请,状态就是Available to request。点击右上角的Model access按钮,点击右侧的Manage model access按钮发起申请。
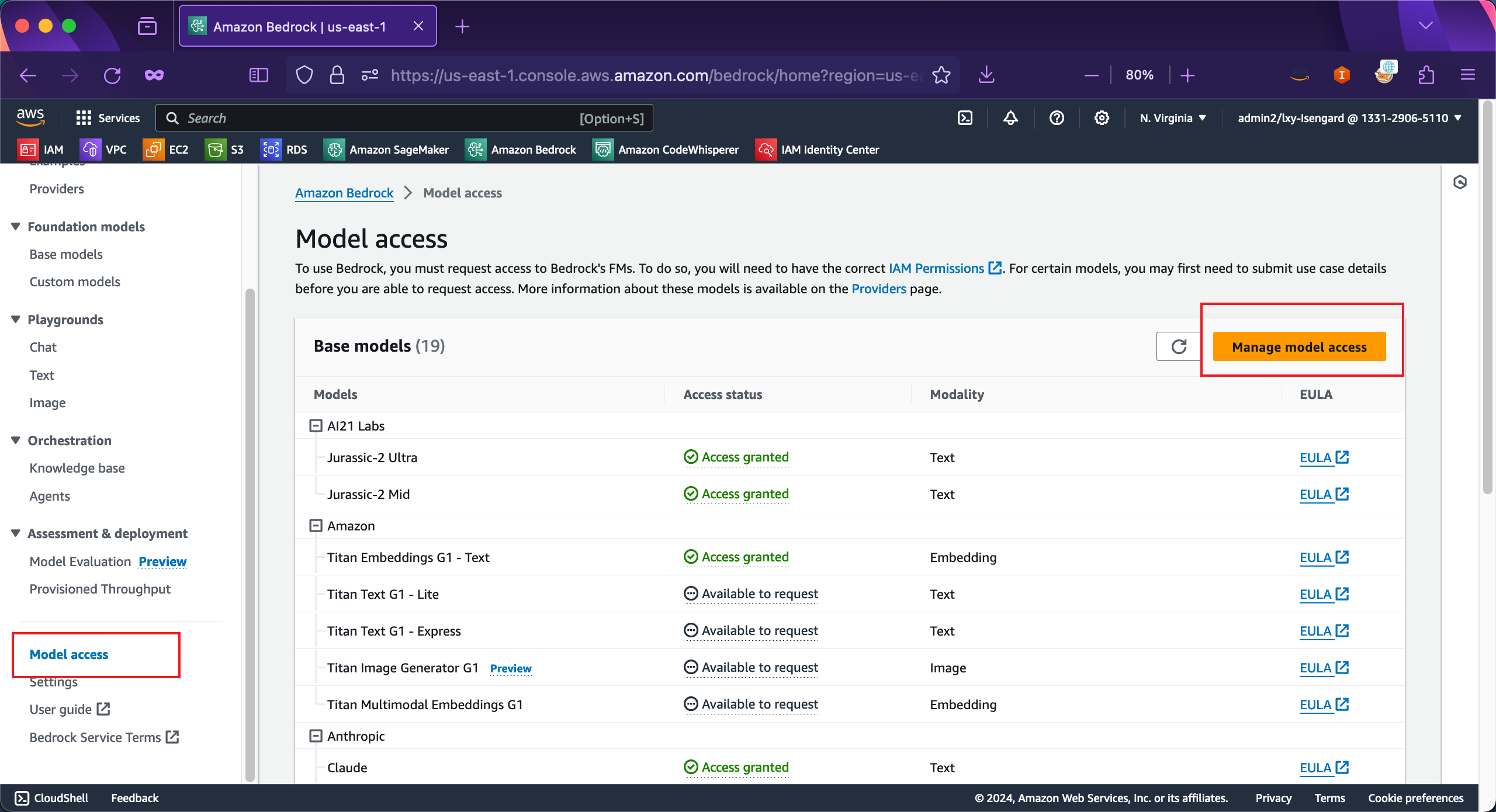
推荐申请的模型包括:
- Claude系列版本
- Titan系列版本(用于向量和RAG处理)
申请时候要填写的表单格式如下截图。
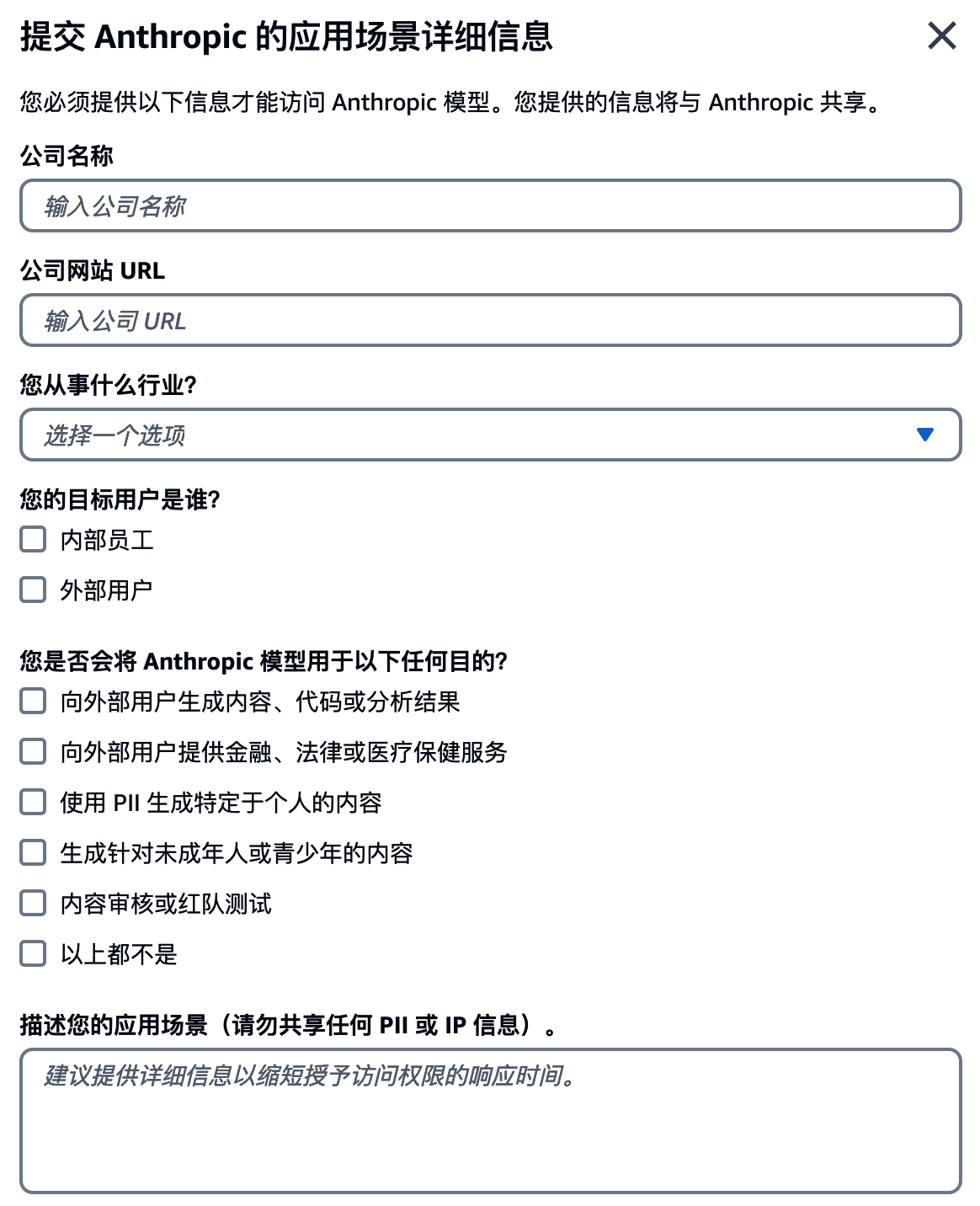
填写以上用户场景信息。通过审核可能需要几分钟时间。然后即可看到如下模型的状态变为已授权。如下截图。

获得模型许可授权后,可以通过左侧的Playgrounds菜单,进入图形界面测试。点击Select model选择模型。如下截图。
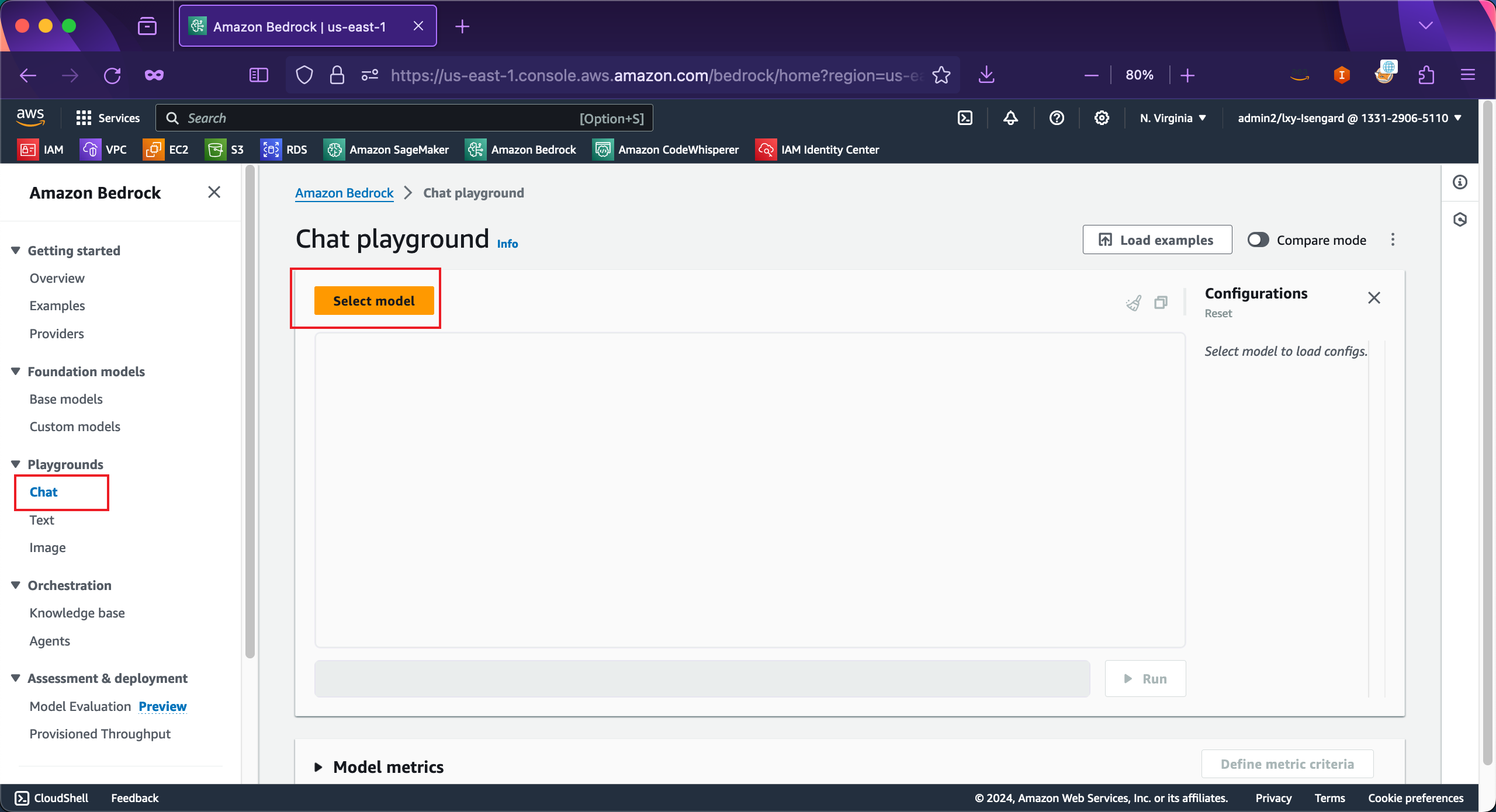
在选择模型的清单中,点击Anthropic公司,选择Claude 3 Sonnet或者Claude V2.1,最大允许传入Context是200K的。点击Apply,即可在界面上发起交互。如下截图。

现在可以在控制台上使用了!
3、新模型申请权限的说明
需要注意的是,如果您以前只是申请过Claude2模型的权限,那么Claude3模型发布后,您需要重新给Claude3模型申请权限,才可以继续使用。如果您之前申请了Claude 3 Sonnet模型,那么当新的Claude 3 Haiku模型发布后,是需要重新申请权限的。而同一个名称的模型,如果只是尾号小版本迭代,是不需要重新申请的。
三、配置IAM和AKSK通过代码访问Bedrock API
Bedrock与OpenAI的ChatGPT调用认证方式不同。ChatGPT因为是独立的SaaS服务,其身份认证只依靠HTTPS的Header。Bedrock是属于整个AWS体系中的一个服务,因此其有着标准的Access Key/Secret Key的认证方式。此外,还需要匹配的IAM Policy才可以调用。下面进行配置。
强烈建议不同的使用者创建不同的用户名,然后各自创建不同的AKSK,这样便于区分账单。如果所有的用户、不同业务场景都使用同一个AKSK,那么无法区分各自使用量。
1、创建API调用需要的IAM Policy
注意:配置的最小权限仅是调用Bedrock和Claude模型所需要的权限。如果您要使用Bedrock知识库,那么还涉及S3存储桶、OpenSearch向量数据库等服务,这时候建议您赋予Bedrock-FullAccess权限,调试更简单。调试后再适当缩减权限。
进入IAM服务,点击左侧Policy策略菜单,点击右上角创建策略按钮。
在向导第一步,策略编辑器位置,不使用可视化模式,而是点击JSON按钮,直接粘贴策略。如下截图。

策略如下:
{
"Version": "2012-10-17",
"Statement": {
"Sid": "bedrock",
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream"
],
"Resource": "arn:aws:bedrock:*::foundation-model/*"
}
}
点击下一步继续,在策略名称位置,输入名称bedrock-runtime,记住这个名称,稍后将会使用。如下截图。

创建策略完成。
2、创建API所属的IAM用户并绑定IAM Policy
进入IAM服务,点击左侧菜单Users用户,点击右上角新建User按钮。如下截图。
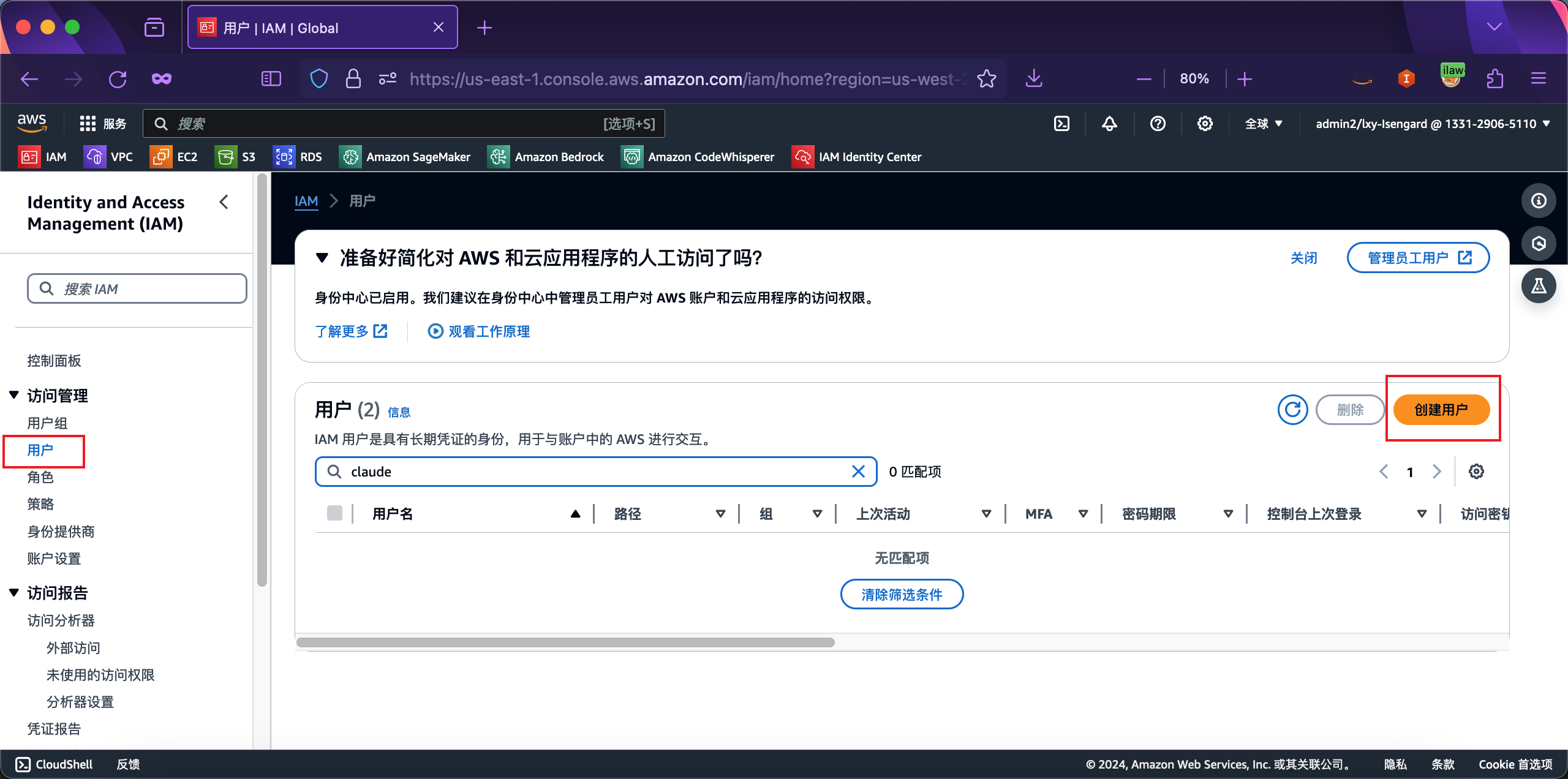
在新建用户的向导中,为用户起名叫做bedrock-runtime,不需要选中向用户提供 AWS 管理控制台的访问权限,因为是API调用,不需要登录AWS控制台,所以不需要给这个权限。然后点击下一步继续,。如下截图。

在设置权限界面,点击右侧直接附加策略按钮,然后在下方权限策略的搜索框中,输入上一步创建的Policy名叫bedrock-runtime,下方即可过滤出来。选中这个策略,点击下一步继续。如下截图。
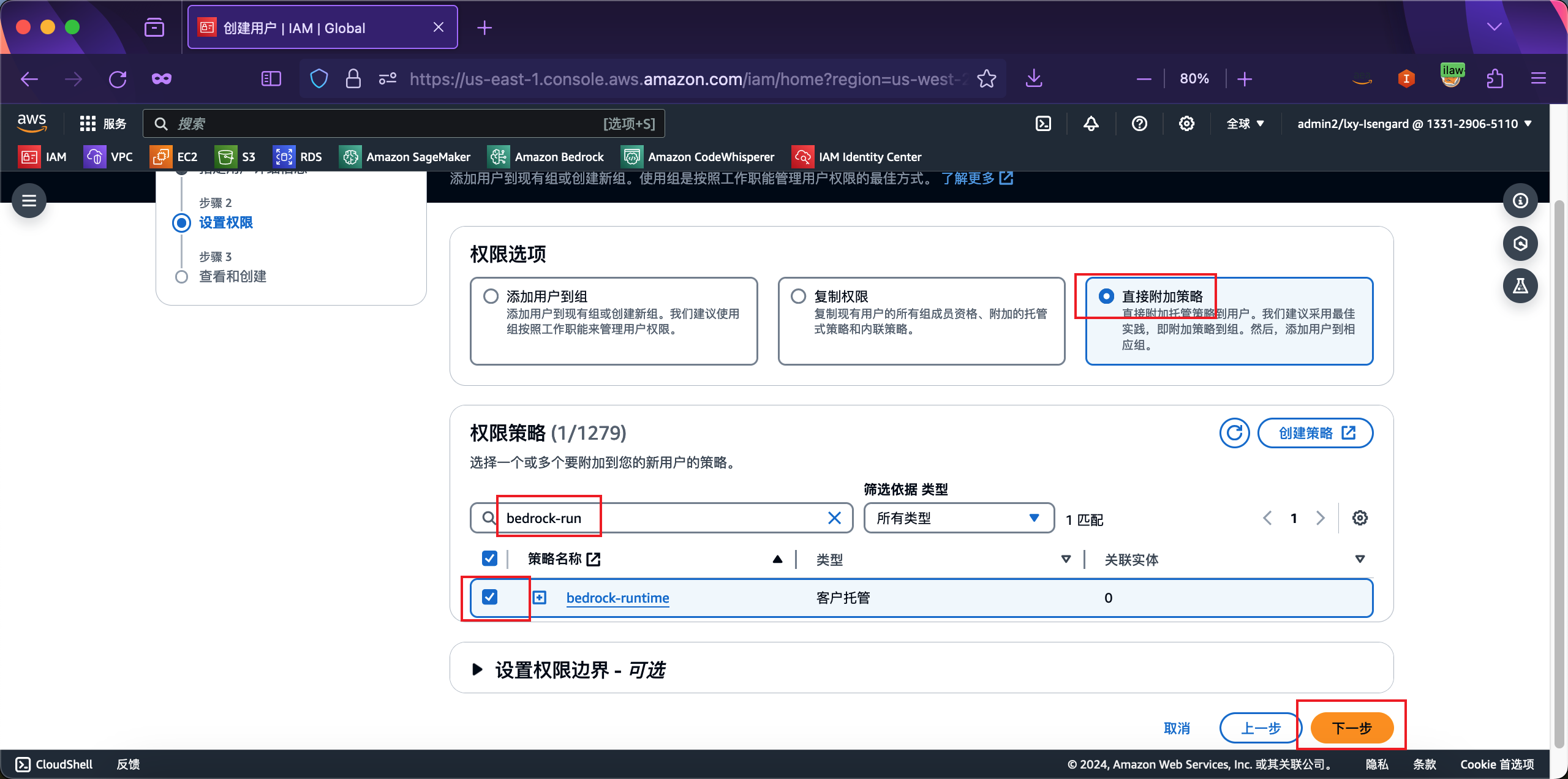
创建用户完成。
3、为使用者创建AKSK
接下来为用户创建AKSK密钥。从IAM用户中,找到刚才的用户,点击安全凭证标签页。如下截图。

在安全凭证标签页中,将页面向下移动,来到创建访问密钥部分。点击创建访问密钥。如下截图。
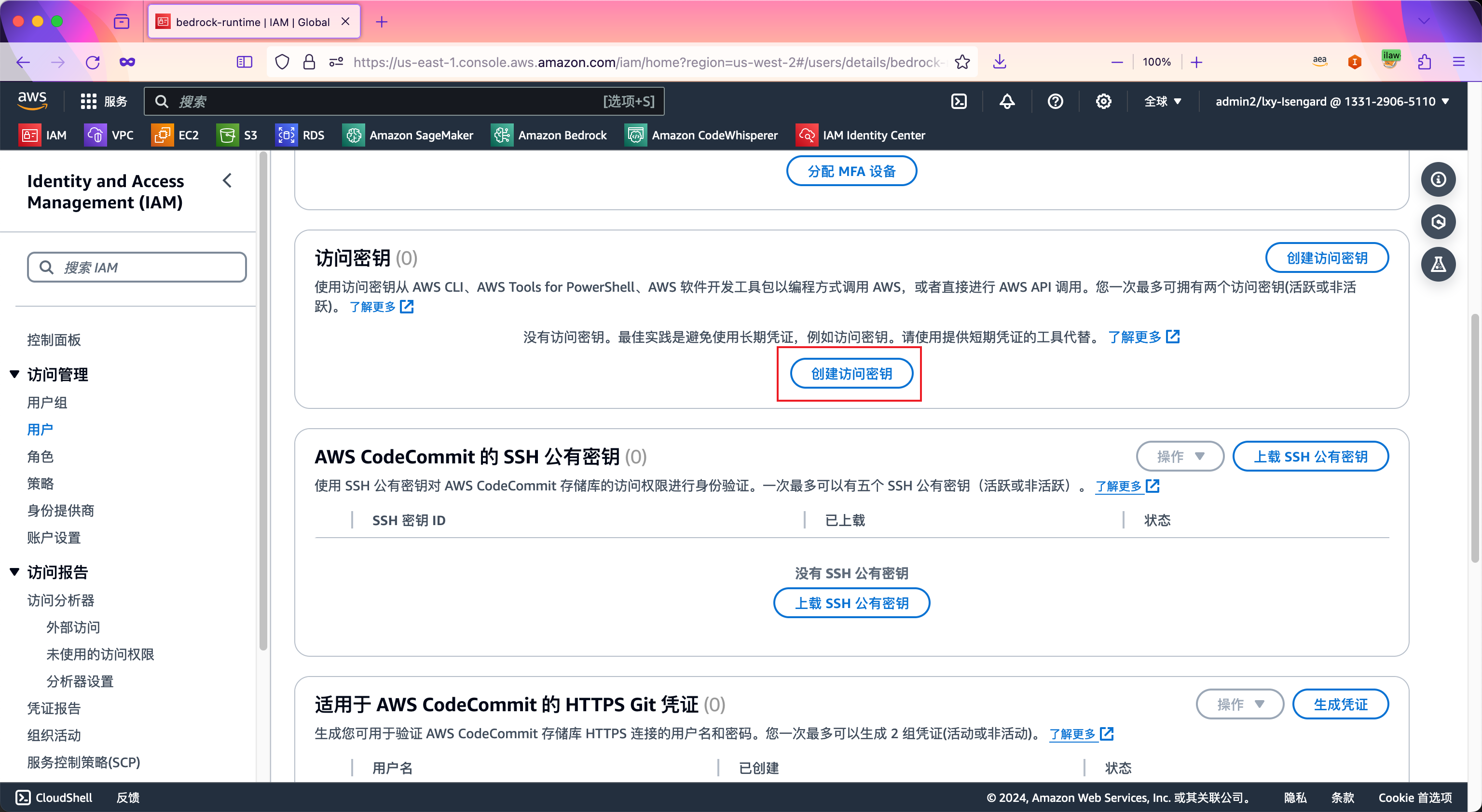
选择使用场景是命令行界面(CLI),并点击下方的确认,我理解上述建议,并希望继续创建访问密钥。然后点击右下角的下一步按钮。如下截图。

输入密钥的标签,例如取名bedrock-runtime。点击右下角的创建访问密钥按钮。如下截图。

创建密钥完成。请注意,密钥只显示一次,如果没有复制下来,或者没有下载CSV文件,则密钥不再显示,只能重新生成一个新的密钥。如下截图。
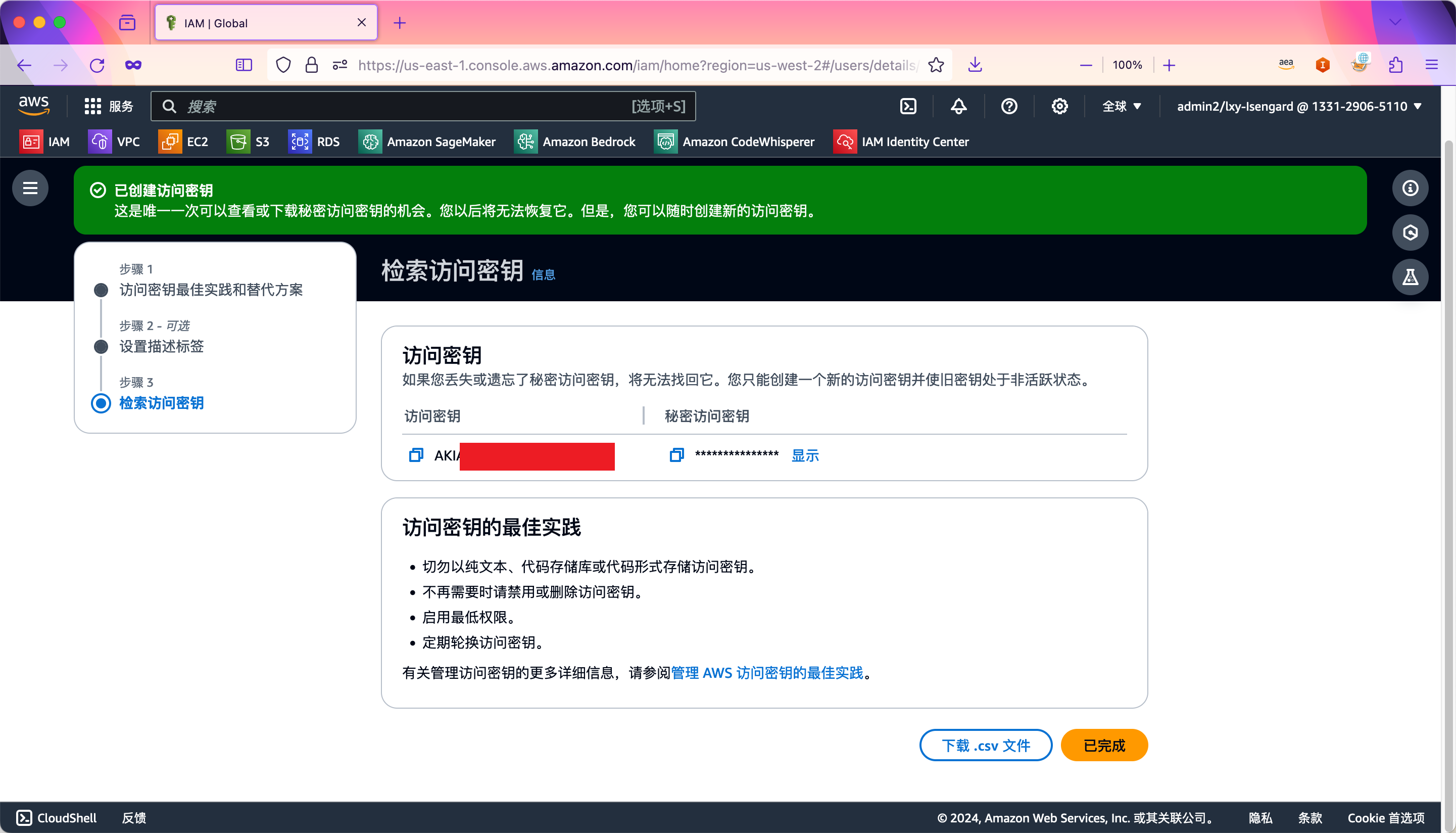
点击已完成按钮完成密钥创建。
四、准备通过API调用Bedrock服务和Claude模型所需要的AKSK
调用Bedrock使用的Access Key/Secret Key是与调用其他AWS服务的认证通用的,因此其配置过程可通过安装AWSCLI进行快速配置,也可以手工配置让各种编程语言的SDK识别到这个Key。
从安全角度考虑,不推荐在代码中硬编码写入密钥,推荐将密钥配置在本机的home目录下。
1、通过AWSCLI安装配置密钥(可选)
下载AWSCLI,并安装。
安装后运行aws configure,依次输入Access Key,Secret Key,调用的Region(本次实验为us-west-2),最后一步默认输出格式,填写JSON即可。
2、手工配置Access Key/Secret Key
如果上一步通过AWSCLI配置好了密钥,那么本步骤可以跳过。
(1) Linux系统
Linux系统放置AKSK到Home目录下特定位置
创建~/.aws/credentials文件,内容如下:
[default]
aws_access_key_id = YOUR_ACCESS_KEY
aws_secret_access_key = YOUR_SECRET_KEY
创建~/.aws/config文件,请注意使用特定的Region,例如文本前边步骤申请Model Access时候,选择的是us-west-2区域。内容如下:
[default]
region=us-west-2
保存退出。
(2) Windows系统
创建C:\Users\%USERNAME%\.aws\credentials文件。其中%USERNAME%是当前Windows使用的用户名,另外.aws目录是开头带有一个圆点表示隐藏目录。内容如下:
[default]
aws_access_key_id = YOUR_ACCESS_KEY
aws_secret_access_key = YOUR_SECRET_KEY
创建C:\Users\%USERNAME%\.aws\config文件。其中%USERNAME%是当前Windows使用的用户名,另外.aws目录是开头带有一个圆点表示隐藏目录。请注意使用特定的Region,例如文本前边步骤申请Model Access时候,选择的是us-west-2区域。内容如下:
[default]
region=us-west-2
保存退出。
3、如果没有配置AKSK时候在代码中写入密钥的方式
如果没有按照上述过程配置的home目录下的密钥,那么可以在代码中硬编码写入密钥,只是这种方式存在安全隐患,不推荐使用。代码中硬编码写入密钥的方法如下:
session = boto3.Session(
aws_access_key_id="xxxxxxxxxxxxxxx",
aws_secret_access_key="xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
region_name="us-west-2"
)
这种方法是有安全隐患的,因为代码会被上传到Git(包括公司私有Git),会造成密钥可见,因此不推荐。
4、安装对应语言的SDK(以Python为例)
pip install boto3 json
5、确认可用的模型ID
在配置好AWSCLI后,执行如下命令:
aws bedrock list-foundation-models --region=us-west-2 --by-provider anthropic --query "modelSummaries[*].modelId"
即可返回所有Claude模型。例如返回结果如下:
[
"anthropic.claude-instant-v1:2:100k",
"anthropic.claude-instant-v1",
"anthropic.claude-v2:0:18k",
"anthropic.claude-v2:0:100k",
"anthropic.claude-v2:1:18k",
"anthropic.claude-v2:1:200k",
"anthropic.claude-v2:1",
"anthropic.claude-v2",
"anthropic.claude-3-sonnet-20240229-v1:0:28k",
"anthropic.claude-3-sonnet-20240229-v1:0:200k",
"anthropic.claude-3-sonnet-20240229-v1:0",
"anthropic.claude-3-haiku-20240307-v1:0:48k",
"anthropic.claude-3-haiku-20240307-v1:0:200k",
"anthropic.claude-3-haiku-20240307-v1:0",
"anthropic.claude-3-opus-20240229-v1:0:12k",
"anthropic.claude-3-opus-20240229-v1:0:28k",
"anthropic.claude-3-opus-20240229-v1:0:200k",
"anthropic.claude-3-opus-20240229-v1:0",
"anthropic.claude-3-5-sonnet-20240620-v1:0:18k",
"anthropic.claude-3-5-sonnet-20240620-v1:0:51k",
"anthropic.claude-3-5-sonnet-20240620-v1:0:200k",
"anthropic.claude-3-5-sonnet-20240620-v1:0"
]
接下来继续了解模型调用API并编写测试代码。
五、了解Claude模型的几种调用方式并编写代码调用API
1、直接调用Claude官方API和调用Bedrock API之间的区别
Claude模型的开发者Anthropic官方提供了SaaS方式的模型服务,使用者需要在Anthropic的官网https://console.anthropic.com/上注册,然后使用Anthropic官方API调用(当然账单也是付给Anthropic和AWS无关)。Python代码样例如下:
# 使用Anthropic官方的Claude模型的SDK的Python代码样例
import anthropic
from anthropic import HUMAN_PROMPT, AI_PROMPT
anthropic.Anthropic().completions.create(
model="claude-2.1",
max_tokens_to_sample=1024,
prompt=f"{HUMAN_PROMPT} Hello, Claude{AI_PROMPT}",
)
运行以上代码的前提是为Python安装Anthropic的库,执行pip install -U anthropic即可安装。以上代码可以看出,程序与AWS服务不发生任何关系,API调用是直接发送给Anthropic官方的Endpoint进行调用。在直接调用Anthropic这种使用场景下,除了安装anthropic的依赖库,也可以直接构建POST请求的方式来提交访问,详情可参考Anthropic官网文档。
在Amazon Bedrock上运行Claude模型有很多优势,您可以结合AWS的多种产品,包括Bedrock知识库、Bedrock Agent,可借助向量数据库、S3数据湖、Lambda函数计算、API Gateway应用网关等构建完整的应用体系。本文介绍的是在Amazon Bedrock服务上使用Anthropic的Claude模型。
Amazon Bedrock提供了多种大模型服务,Claude只是其中一种模型。因此,Bedrock的API是进行了封装,包括身份认证、模型请求等都通过Amazon Bedrock进行发送,程序代码调用的Endpoint也是AWS的Endpoint,因此程序代码上的调用方法也和直接Claude有区别。下文会介绍多个例子。
使用Bedrock的前提是安装包含Bedrock的AWS SDK的最新版。以Python为例,执行pip install -U boto3,需要确保boto3版本大于1.28.59。通过Bedrock调用时候,程序与Anthropic官方不发生任何关系,API调用是直接发送给Amazon Bedrock的Endpoint进行调用,且身份认证也是通过AWS,即通过Access Key/Secret Key来认证。除了使用AWS SDK之外,还可以直接构建HTTPS请求以POST方式提交给Amazon Bedrock终端节点,这种访问方式的文档请参考这里。直接构建POST请求的方式属于底层调用,相对麻烦,因此不推荐,首选使用AWS SDK的方式。除了Python之外,其他主要开发语言都可以加载对应的SDK后调用Bedrock。
本文后续所有文档都以调用Bedrock为例,不再描述使用Claude官方API。
2、单次消息模式和Stream流式模式
普通的单次消息模式,发送一个较长的Prompt和素材提交给大模型,大模型再返回一段较长的生成式内容,可能需要数秒钟。在单次消息模式下,程序需要等待Bedrock和Claude返回完整消息后,才进行后续处理,如果返回的信息有成百上千字(输出Token多),那么等待时间给用户的反馈非常不好。
降低模型响应时间的一个办法是使用Stream模式。在Stream模式下,大模型在生成很长内容的时候随时返回,Stream模式将使得程序随时能显示出来。这样从用户交互的角度,不需要等待很长时间才一下子看到全部对话,而是生成一行返回一行,用户感受到大模型仿佛是人类一样逐渐的说出来,从交互体验上非常友好。Stream的原理是SSE(Server-Sent Events),详情可参考这里。
单次消息和Stream模式是两个API,在Claude3上分别叫做InvokeModel(API文档在这里)和InvokeModelWithResponseStream(API文档在这里)。另外,当使用Bedrock最新Converse API之后,单次消息模式和Stream模式也分别对应着两个API,他们是Converse API和ConverseStream API。
本文后续以最新的Converse API为例进行介绍。
3、从Claude2的Text Completion切换到Claude3的改变与PE部分的变化
本小节针对已经在使用Claude2的用户,切换到Claude3时候要做的调整。
Claude2模型是2023年发布的,Claude3在2024年初发布,二者在API调用上所有差别。Claude2支持旧的API Text Completion(文档在这里),也支持新的API Messages(文档在这里)。而Claude3只使用新的Message。因此从Claude2切换到Claude3时候,需要对代码进行进行一定的改动。
Claude2的使用Text Completion时候提交的prompt格式如下:
prompt = "\n\nHuman: Hello there\n\nAssistant: Hi, I'm Claude. How can I help?\n\nHuman: Can you explain Glycolysis to me?\n\nAssistant:"
Claude3的使用Message的API时候提交的prompt格式如下:
messages = [
{"role": "user", "content": "Hello there."},
{"role": "assistant", "content": "Hi, I'm Claude. How can I help?"},
{"role": "user", "content": "Can you explain Glycolysis to me?"},
]
由此可以看到,其API构成稍微有些差别。您需要使用message API来调用Claude 3(包括Opus、Sonnet和Haiku)。
在Prompt Enginering方面,Claude2因为输入的整个Prompt都是Text文本,因此需要通过标记\n\nHuman和\n\nAssistant的方式来表明哪些是人类的输入和哪些是大语言模型的。在Claude3模型的调用中,改用Message API后,是以JSON的方式来输入。其中又使用role标签且值是user来表示这部分信息是人类的输入,由此就不需要再加上\n\nHuman标签了。
除此了Message API的区别之外,大部分Claude2使用的Prompt编写方式在Claude3上继续可用。
4、从Bedrock的invoke_model API升级到Converse API的优势
Bedrock在2024年5月推出了全新的Converse API,新闻发布稿在这里。使用Converse API的优势如下:
- 多种模型构建的JSON格式完全统一
- 将模型参数独立放入inferenceConfig字段进行调用
- Bedrock输出格式严格遵循JSON便于处理
- 多轮对话代入历史对话时格式标准化所需要的代码更简单
- 上传图片时候不需要base64编码
- 更简单的stream流式代码的编写
- 支持多种格式的文档上传(pdf | csv | doc | docx | xls | xlsx | html | txt | md)且不需要base64编码
5、Claude 3的Converse API调用Python代码样例
注:以下代码使用新的Converse API。
import boto3
import json
region_name = 'us-west-2'
#model_id = "anthropic.claude-3-sonnet-20240229-v1:0"
model_id = 'anthropic.claude-3-haiku-20240307-v1:0'
message_text = "Write an email from Bob, Customer Service Manager, to the customer \"John Doe\" who provided negative feedback on the service provided by our customer support engineer"
system_prompt = [
{ "text": "Please respond to all requests in the style of a pirate." }
]
session = boto3.Session(region_name= region_name)
bedrock = session.client(service_name="bedrock-runtime")
message_list = []
initial_message = {
"role": "user",
"content": [
{ "text": message_text }
],
}
message_list.append(initial_message)
response = bedrock.converse(
modelId = model_id,
system = system_prompt ,
messages = message_list ,
inferenceConfig={
"maxTokens": 2000,
"temperature": 0
},
)
'''
# get entire json from reponse
response_message = response['output']['message']
print(json.dumps(response_message, indent=4))
'''
# Only get content from response
response_message = response['output']['message']['content'][0]['text']
print(response_message)
# Print token usage
print("\n\n--- Token usage ---")
print("Usage:", json.dumps(response['usage'], indent=4))
执行后,等待数秒会看到完整输出,即按照Prompt要求,模型以客户服务经理Bob的身份写给客户John Doe的关于差评的一封道歉信。
5、Claude 3的ConverseStream API调用Python代码样例
以下例子是使用ConverseStream API进行流式输出的Python代码例子。
import boto3
import json
region_name = 'us-west-2'
#model_id = "anthropic.claude-3-sonnet-20240229-v1:0"
model_id = 'anthropic.claude-3-haiku-20240307-v1:0'
message_text = "Write an email from Bob, Customer Service Manager, to the customer \"John Doe\" who provided negative feedback on the service provided by our customer support engineer"
system_prompt = [
{ "text": "Please respond to all requests in the style of a pirate." }
]
session = boto3.Session(region_name= region_name)
bedrock = session.client(service_name="bedrock-runtime")
message_list = []
initial_message = {
"role": "user",
"content": [
{ "text": message_text }
],
}
message_list.append(initial_message)
response = bedrock.converse_stream(
modelId = model_id,
system = system_prompt ,
messages = message_list ,
inferenceConfig={
"maxTokens": 2000,
"temperature": 0
},
)
stream = response.get('stream')
if stream:
for event in stream:
# print start role
#if 'messageStart' in event:
# print(f"\nRole: {event['messageStart']['role']}")
if 'contentBlockDelta' in event:
print(event['contentBlockDelta']['delta']['text'], end="")
# print stop reason
#if 'messageStop' in event:
# print(f"\nStop reason: {event['messageStop']['stopReason']}")
# print meta data/token usage
if 'metadata' in event:
metadata = event['metadata']
if 'usage' in metadata:
print("\nToken usage")
print(f"Input tokens: {metadata['usage']['inputTokens']}")
print(
f":Output tokens: {metadata['usage']['outputTokens']}")
print(f":Total tokens: {metadata['usage']['totalTokens']}")
if 'metrics' in event['metadata']:
print(
f"Latency: {metadata['metrics']['latencyMs']} milliseconds")
在这段流式输出的最后,也打印了token usage,即本次对话的token的使用量。如果不需要这部分输出,可以注释掉代码即可。
6、Claude 3的Converse API传入图片的代码示例
Claude是多模态大模型,支持输入图片可理解其中的内容。这里准备一个example.jpg作为测试图像。在新的converse API下,不需要再进行base64编码了,直接传入图片即可(本文使用绝对路径的方式)。代码如下:
import boto3
import json
region_name = 'us-west-2'
#model_id = "anthropic.claude-3-sonnet-20240229-v1:0"
model_id = 'anthropic.claude-3-haiku-20240307-v1:0'
system_prompt = [
{ "text": "Please respond to all requests in Chinese" }
]
file_name = "/Users/zhangsan/Documents/Demo/Bedrock/Claude3-converse_api/meow.png"
with open(file_name, "rb") as image_file:
image_bytes = image_file.read()
session = boto3.Session(region_name= region_name)
bedrock = session.client(service_name="bedrock-runtime")
message_list = []
initial_message = {
"role": "user",
"content": [
{ "text": "This is image 1:" },
{
"image": {
"format": "png",
"source": {
"bytes": image_bytes #no base64 encoding required!
}
}
},
{ "text": "Please describe the image." }
],
}
message_list.append(initial_message)
response = bedrock.converse_stream(
modelId = model_id,
system = system_prompt ,
messages = message_list ,
inferenceConfig={
"maxTokens": 2000,
"temperature": 0
},
)
stream = response.get('stream')
if stream:
for event in stream:
# print start role
#if 'messageStart' in event:
# print(f"\nRole: {event['messageStart']['role']}")
if 'contentBlockDelta' in event:
print(event['contentBlockDelta']['delta']['text'], end="")
# print stop reason
#if 'messageStop' in event:
# print(f"\nStop reason: {event['messageStop']['stopReason']}")
# print meta data/token usage
if 'metadata' in event:
metadata = event['metadata']
if 'usage' in metadata:
print("\nToken usage")
print(f"Input tokens: {metadata['usage']['inputTokens']}")
print(
f":Output tokens: {metadata['usage']['outputTokens']}")
print(f":Total tokens: {metadata['usage']['totalTokens']}")
if 'metrics' in event['metadata']:
print(
f"Latency: {metadata['metrics']['latencyMs']} milliseconds")
返回结果如下:
这张图片显示了一只正在睡觉的猫咪。这只猫咪的毛发呈现出灰色调,看起来非常柔软。它的眼睛紧闭,表情安详,似乎正在进入深度睡眠状态。整个画面以深蓝色为主调,营造出一种宁静祥和的氛围。这只猫咪看起来非常舒适和放松,让人感受到它正在享受一段安稳的睡眠时光。
7、Converse API传入文档示例
Bedrock上的Claude现在支持传入文档了,格式包括pdf|csv|doc|docx|xls|xlsx|html|txt|md。与图像一样,使用AWS SDK调用时候是不需要做base64编码的,直接把文件发过去即可。这里还需要注意SDK版本,建议升级到最新版本。
在开发者本机执行如下命令升级:
python3 -m pip install --upgrade pip
pip3 install boto3 --upgrade
准备一个里边是文本的PDF文档(不是照片影印件)的,例如Amazon的2024Q2的财报AMZN-Q2-2024-Earnings-Release,这个财报可以从官网这里下载。将这个提交给Claude并提问这个PDF中有关财务数据。
import boto3
import json
region_name = 'us-west-2'
#model_id = "anthropic.claude-3-sonnet-20240229-v1:0"
model_id = 'anthropic.claude-3-haiku-20240307-v1:0'
system_prompt = [
{ "text": "You are professional financial investigator, a report in PDF format is send to you. Please check a few questions in Chinese, and respond to all requests in Chinese" }
]
file_name = "/Users/lxy/AWS/MyWorkshop/Bedrock/Bedrock Getting-started/Claude3-converse_api/AMZN-Q2-2024-Earnings-Release.pdf"
with open(file_name, "rb") as image_file:
image_bytes = image_file.read()
session = boto3.Session(region_name= region_name)
bedrock = session.client(service_name="bedrock-runtime")
message_list = []
initial_message = {
"role": "user",
"content": [
{ "text": "This is image 1:" },
{
"document": {
"format": "pdf",
"name": "Q2 report",
"source": {
"bytes": image_bytes #no base64 encoding required!
}
}
},
{ "text": "根据财报,请回答一系列问题,回答问题时候按顺序。问题1,Amazon营收比2024 Q1如何,营收比2023 Q2如何。问题2,利润率比2024 Q1如何,利润率比2023年Q2如何。问题3,各业务板块中,盈利最大来自哪一个业务板块,其利润率数据是多少。问题4,各业务板块中,亏损最大的是哪一个板块,利润率百分比是多少。问题5,财报中是否披露了AWS的市场战略有率。问题6,本期财报中是否披露了汽车和自动驾驶相关投资信息,投资金额是多少。问题7,本期财报中是否披露了人工智能、大语言模型投资,是否包含对Anthropic公司投资的信息。" }
],
}
message_list.append(initial_message)
response = bedrock.converse_stream(
modelId = model_id,
system = system_prompt ,
messages = message_list ,
inferenceConfig={
"maxTokens": 2000,
"temperature": 0
},
)
stream = response.get('stream')
if stream:
for event in stream:
# print start role
#if 'messageStart' in event:
# print(f"\nRole: {event['messageStart']['role']}")
if 'contentBlockDelta' in event:
print(event['contentBlockDelta']['delta']['text'], end="")
# print stop reason
#if 'messageStop' in event:
# print(f"\nStop reason: {event['messageStop']['stopReason']}")
# print meta data/token usage
if 'metadata' in event:
metadata = event['metadata']
if 'usage' in metadata:
print("\nToken usage")
print(f"Input tokens: {metadata['usage']['inputTokens']}")
print(
f":Output tokens: {metadata['usage']['outputTokens']}")
print(f":Total tokens: {metadata['usage']['totalTokens']}")
if 'metrics' in event['metadata']:
print(
f"Latency: {metadata['metrics']['latencyMs']} milliseconds")
由此即可获得财报的分析数据。
六、Claude Prompt Engineering 调优
请参考这篇。
七、参考文档
Use converse API(包含本文/图像/文档以及流式等说明)
https://docs.aws.amazon.com/bedrock/latest/userguide/conversation-inference.html
Python Sample
Java Sample
NodeJS Sample
最后修改于 2024-01-30