通过分析Bedrock日志来获取不同应用各自调用成本
解决多应用共享Bedrock账单无法分账的难题,通过启用日志记录和Athena SQL查询,实现按IAM用户、模型、时间维度的成本分析。
在Athena查询语句SQL中,更新了Claude 3 Sonnect 3.5的价格(基于美西)。
本文已更新使用Athena Partition Projection功能,无须再手工管理数据分区。
一、背景
1、挑战
Amazon Bedrock提供多了多种基础模型的Model as a Service的调用能力,用户通过API调用Bedrock并指定要交互的模型,如Claude3的不同版本,即可获得模型返回结果。当属于多个团队、多个Workload的不同应用程序,分别调用Bedrock API时候,在AWS的账单中将仅包含从API传入的Token和生成的Token总数,但是没有提供按用户分账的功能。由此,需要一种方式能够帮助用户区分多个应用系统各自调用API的成本。
2、可能的实现方式
目前实现这个功能需求的几种方式有:
| 方案 | 实现场景 | 优点 | 缺点 |
|---|---|---|---|
| 1 | 为多个部门和应用系统划分多个AWS账号,且分割到不同Region,由此会单独生成账单 | 开发团队、运维团队都不需要调整代码 | 需要申请多个账号并在多个Region间分配应用 |
| 2 | 在应用层记录每个Bedrock API Request请求输入和返回的Token | 最准确的API请求计数 | 开发团队需要调整代码 |
| 3 | 使用Bedrock Proxy/Bedrock Access Gateway方案,封装API接口 | 兼容OpenAI的单密钥调用规范 | 二次封装API性能有影响且需要额外部署,且如果已经按照IAM User的AKSK和Bedrock API完成了应用开发,还需要修改API集成方式 |
| 4 | 通过Tag分账 | 与其他云服务器使用Tag分账的方式一致 | 截止2024年5月12日Bedrock官方尚未支持这一功能,此功能将在近期提供 |
| 5 | 开启Bedrock API日志功能记录请求者和模型,并通过分析日志来获取各自调用者的成本 | 无需应用程序和开发者做改动 | 需要自行编写简单SQL完成对日志的检索,日志建议使用S3保存日志用于降低成本 |
本文选择的是方案5。
Amazon Bedrock提供给了日志功能,日志可以记录完成的请求输入内容。为了分析不同应用的调用成本,这里可以不记录详细请求的内容,只要求Bedrock在日志中记录调用者身份(AKSK密钥属于哪一个ARN)、消耗的Token、调用时间等。由此即可满足统计成本的最低要求,也无需担心数据隐私。然后,编写一系列Athena查询SQL,通过Athena的控制台图形界面、或者JDBC接口提交查询,即可获得希望的成本分析结果。
3、前提、准备和注意事项
用此方法的几个注意事项:
- 不同应用的Bedrock API调用应通过不同的IAM User对应的AKSK进行,这样才可以通过IAM User的名称来区分调用费用,如果多个应用混用一个IAM User生成的AKSK,则无法区分
- Bedrock日志写入到S3数据湖比写入到Cloudwatch更便宜,因此本方案选择S3数据湖
- Bedrock日志默认是写到本Region的S3存储桶,因此如果有多个区域在使用Bedrock服务,则需要在每个Region分别配置
- 使用者应具有Athena操作经验,如果在本Region打开了Lake Formation功能,则需要为S3数据湖提供相应的权限
- 为了优化使用量大时候的日志查询速度和Athena检索成本,本文选择按照年/月/日的三级目录进行分区(Partition),这样查询数据时候,可仅检索指定日期,即可最小化查询成本,避免一个简单的小查询就触发全桶遍历
- 尽量避免过往日志的全桶扫描
二、开启Bedrock日志
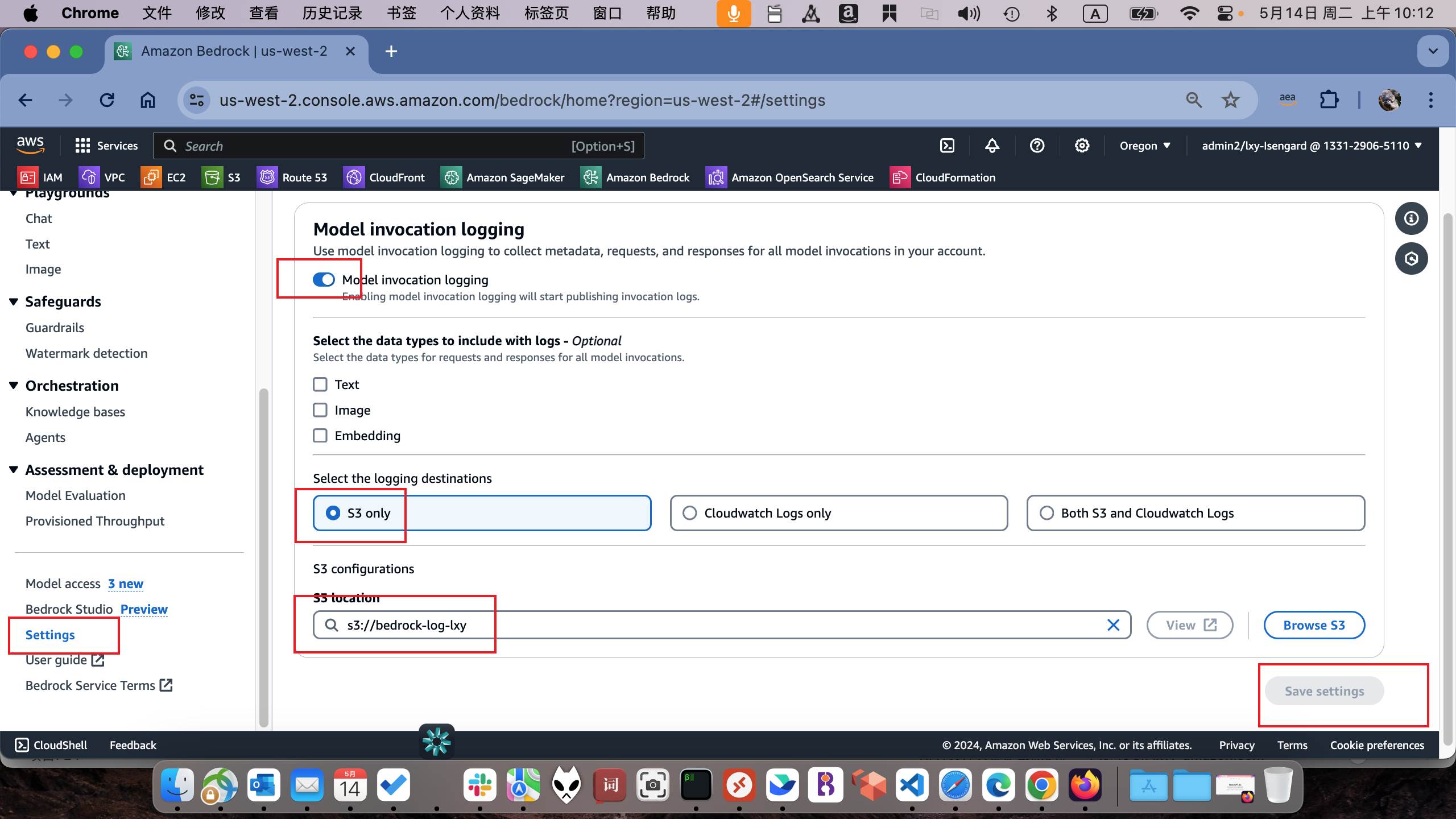
进入Bedrock服务。找到左下角的Settings按钮,在右侧界面Model invocation logging下方,打开记录日志的按钮。在下方可选的日志内容这里,不要选中Text、Image、Embedding三个选项。不选中则意味着日志不会记录提交的内容。然后继续选择Bedrock日志保存位置是在S3上,且输入提前创建好的空的S3存储桶。最后点击右下角继续。如下截图。
开启日志完成后,通过API去发起调用,日志会在几分钟内投递到S3上。进入S3存储桶,查看其目录结构如下。
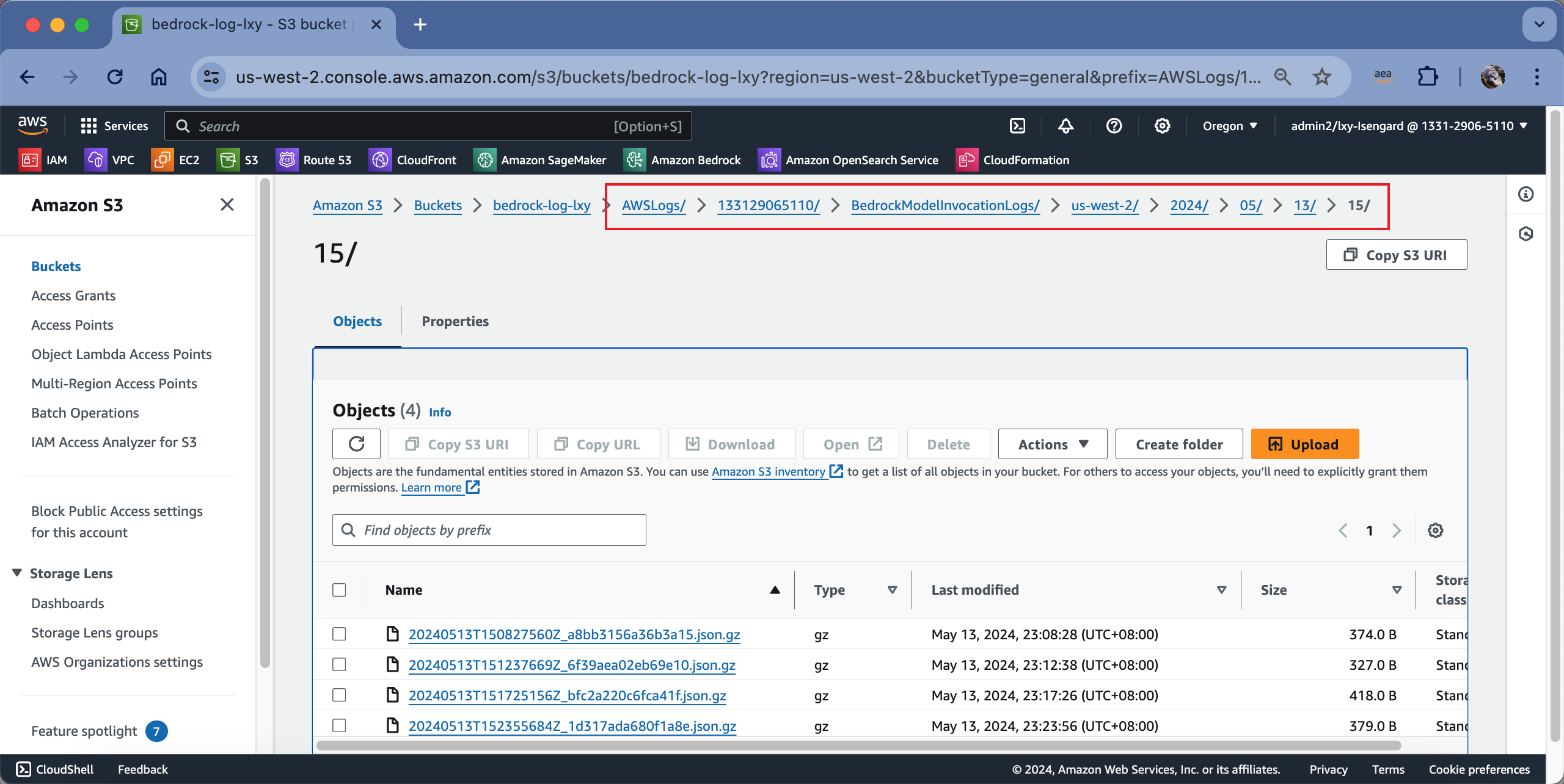
使用AWSCLI查询S3存储桶,也可以看到其完成目录如下。
aws s3 ls s3://bedrock-log-lxy/AWSLogs/133129065110/BedrockModelInvocationLogs/us-west-2/2024/05/13/15/
2024-05-13 23:08:28 374 20240513T150827560Z_a8bb3156a36b3a15.json.gz
2024-05-13 23:12:38 327 20240513T151237669Z_6f39aea02eb69e10.json.gz
2024-05-13 23:17:26 418 20240513T151725156Z_bfc2a220c6fca41f.json.gz
2024-05-13 23:23:56 379 20240513T152355684Z_1d317ada680f1a8e.json.gz
现在将其中一个日志下载到本地,解压缩,并查看其格式。如下截图。
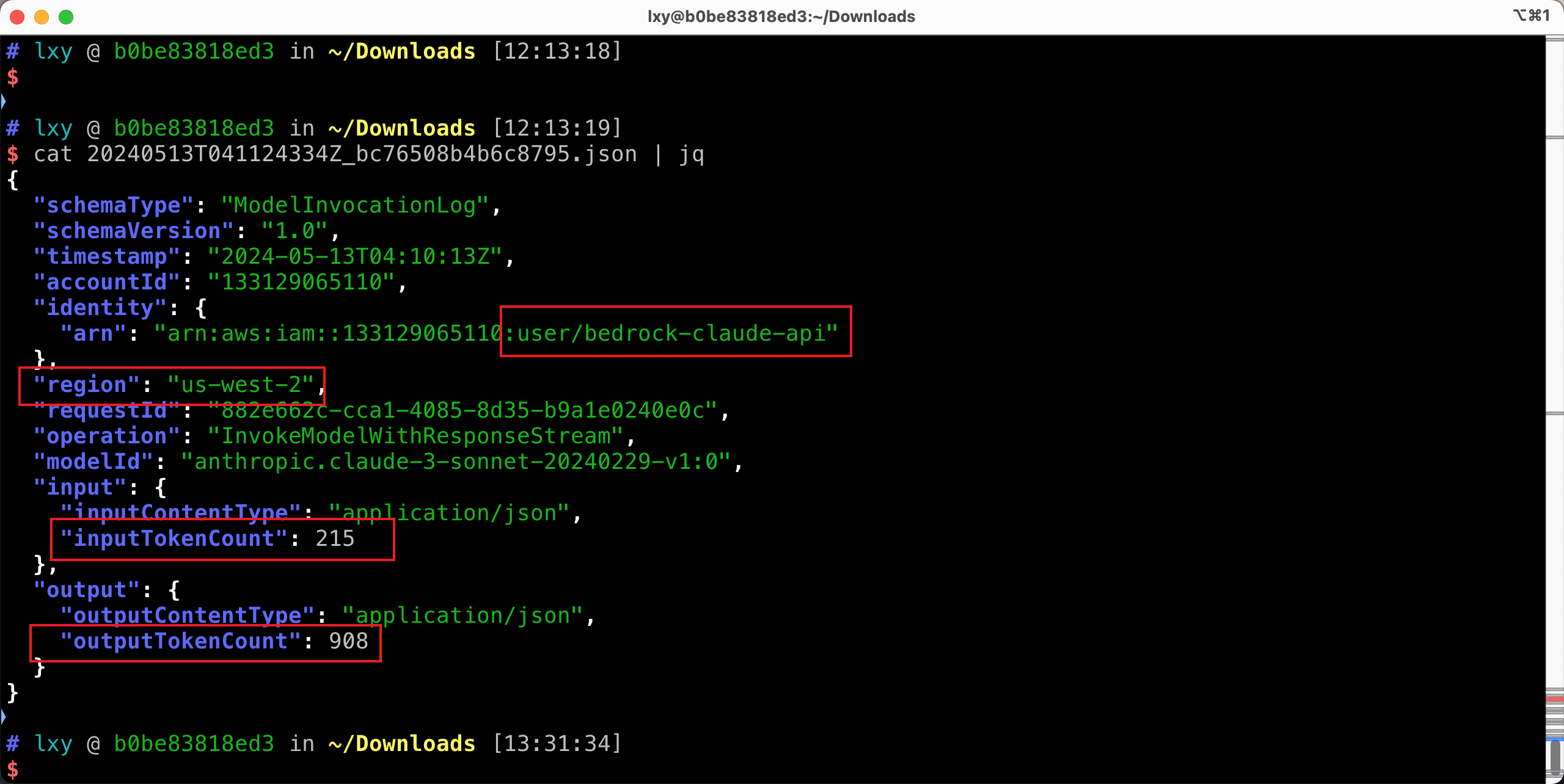
通过以上日志格式可以看出,分析账单需要的调用者身份是在ARN中,区域、模型名称、Input和Output的token数都具备,因此就可以分析各应用的成本了。
三、使用Athena服务分析成本
1、创建带有分区且开启了Partition Projection的Athena表
进入Bedrock和日志所在Region的Athena服务。在左侧选择默认的Data source是AwsDataCatalog,选择数据库是Default,然后在右侧Query窗口输入如下内容。本文按照用年、月、日做Partition Projection的方式来配置,因此无须执行MSCK加载分区,也无无须手工运行ALTER TABLE加载分区。
在以下脚本中,请替换您的数据表名、S3存储桶名(有两处)。
CREATE EXTERNAL TABLE `bedrock_partitioned`(
`schematype` string,
`schemaversion` string,
`timestamp` timestamp,
`accountid` string,
`identity` struct<arn:string>,
`region` string,
`requestid` string,
`operation` string,
`modelid` string,
`input` struct<inputcontenttype:string,inputbodyjson:struct<anthropic_version:string,max_tokens:int,top_p:double,temperature:double,messages:array<struct<role:string,content:string>>,system:string>,inputtokencount:int>,
`output` struct<outputcontenttype:string,outputbodyjson:struct<id:string,type:string,role:string,content:array<struct<type:string,text:string>>,model:string,stop_reason:string,stop_sequence:string,usage:struct<input_tokens:int,output_tokens:int>>,outputtokencount:int>
)
PARTITIONED BY (
day STRING
)
ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'paths'='accountId,identity,input,modelId,operation,output,region,requestId,schemaType,schemaVersion,timestamp')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://bedrock-log-lxy/AWSLogs/133129065110/BedrockModelInvocationLogs/us-west-2/'
TBLPROPERTIES (
'classification'='json',
'compressionType'='gzip',
"projection.enabled" = "true",
"projection.day.type" = "date",
"projection.day.format" = "yyyy/MM/dd",
"projection.day.range" = "2024/05/01,NOW",
"projection.day.interval" = "1",
"projection.day.interval.unit" = "DAYS",
"storage.location.template" = "s3://bedrock-log-lxy/AWSLogs/133129065110/BedrockModelInvocationLogs/us-west-2/${day}/"
)
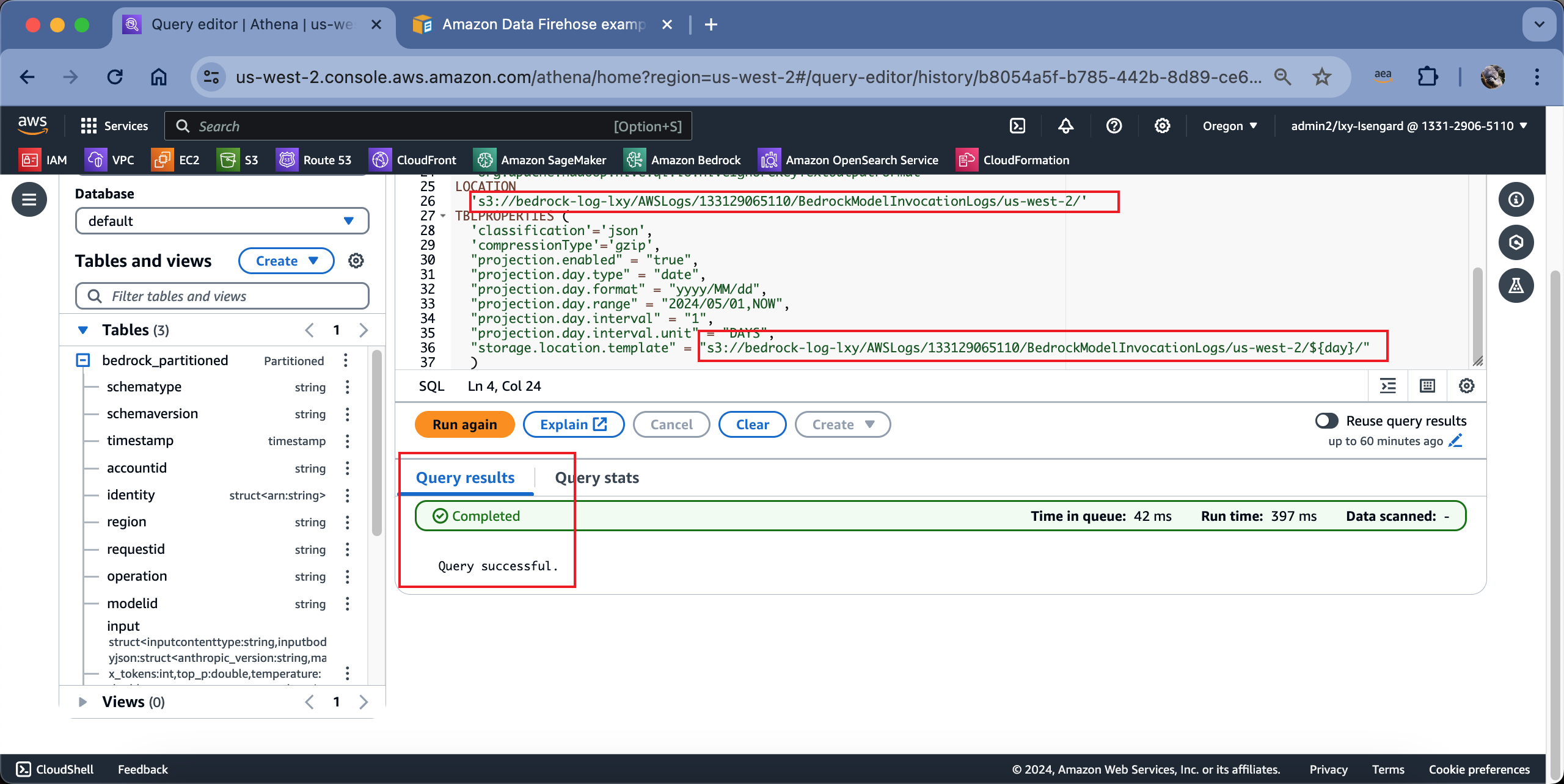
执行这段SQL。执行成功的话,左下角会在表中显示新创建好的表结构。如下截图。
2、查询本月各模型总量**(按月,按模型视角,不拆分用户,不拆分到天)**
Amazon Bedrock各模型价格如官网,单位均为1000 Token。如下截图。
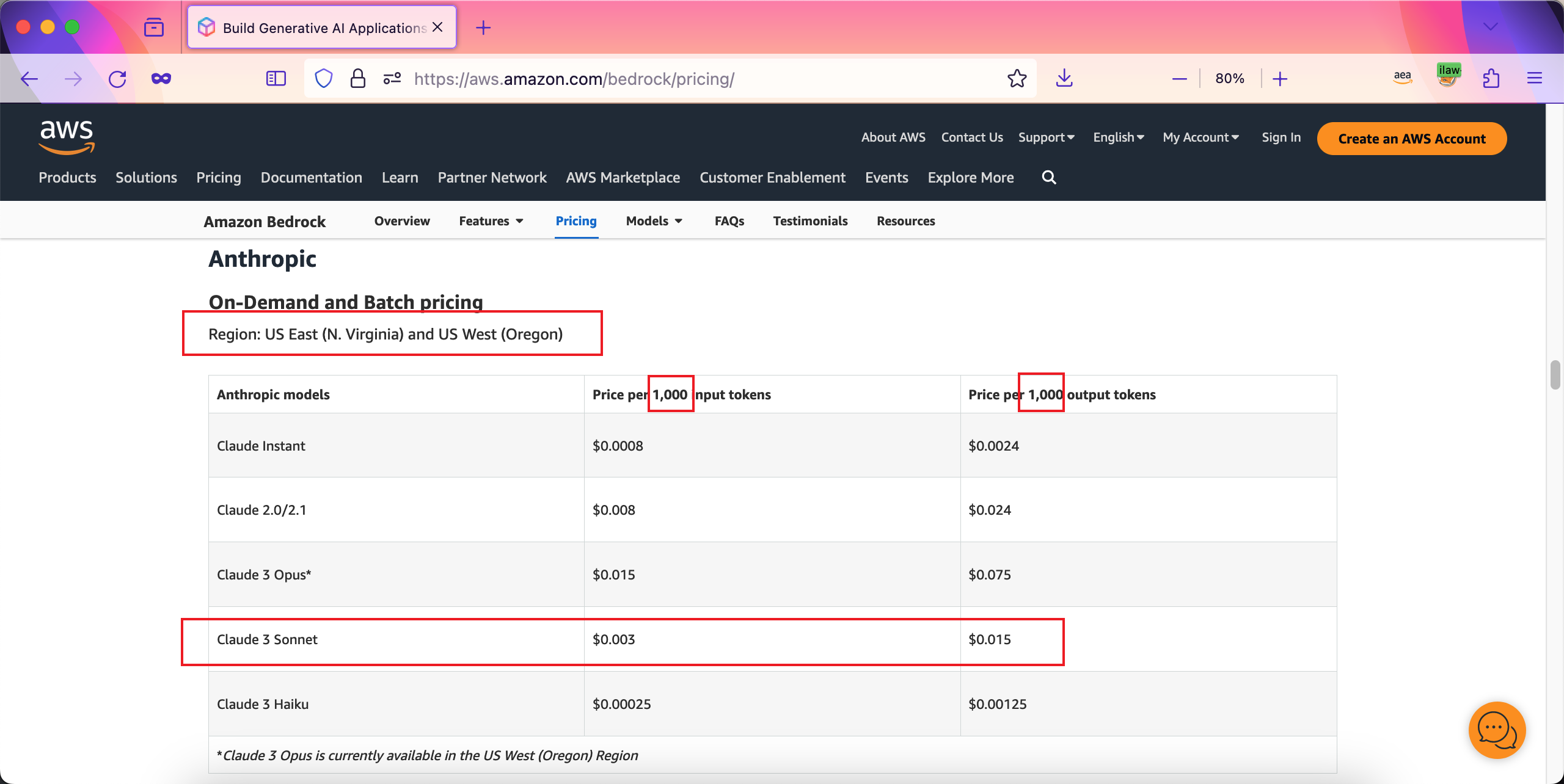
为了方便计算,下文中的SQL按照模型ID,分别乘以单价,即可分别根据不同模型计算出用量价格。
编写如下SQL查询本月的总量,按Region和模型ID汇总(因为价格不一样)。
-- 查看本月所有、按模型ID汇总(因为单价不一样)--
-- 以下价格based on us-west-2 美西2俄勒冈区域 --
-- 以下数据已经除以1000,将报价表默认的1K token报价折算为1 token报价 --
select
YEAR(timestamp) as year,
MONTH(timestamp) as month,
modelId as model_id,
region as region,
sum(input.inputtokencount) as total_input_token,
sum(CAST(input.inputtokencount*CASE
WHEN modelId LIKE 'anthropic.claude-3-5-sonnet-20240620-v1:0' THEN 0.000003
WHEN modelId LIKE 'anthropic.claude-3-sonnet-20240229-v1:0' THEN 0.000003
WHEN modelId LIKE 'anthropic.claude-3-haiku-20240307-v1:0' THEN 0.00000025
WHEN modelId LIKE 'anthropic.claude-3-opus-20240229-v1:0' THEN 0.000015
WHEN modelId LIKE 'mistral.mistral-large-2407-v1:0' THEN 0.000003
WHEN modelId LIKE 'meta.llama3-1-405b-instruct-v1:0' THEN 0.00000532
END AS DECIMAL(10,4))) AS input_price_USD,
sum(output.outputtokencount) as total_output_token,
sum(CAST(output.outputtokencount*CASE
WHEN modelId LIKE 'anthropic.claude-3-5-sonnet-20240620-v1:0' THEN 0.000015
WHEN modelId LIKE 'anthropic.claude-3-sonnet-20240229-v1:0' THEN 0.000015
WHEN modelId LIKE 'anthropic.claude-3-haiku-20240307-v1:0' THEN 0.00000125
WHEN modelId LIKE 'anthropic.claude-3-opus-20240229-v1:0' THEN 0.000075
WHEN modelId LIKE 'mistral.mistral-large-2407-v1:0' THEN 0.000009
WHEN modelId LIKE 'meta.llama3-1-405b-instruct-v1:0' THEN 0.000016
END AS DECIMAL(10,4))) AS output_price_USD
from "bedrock_partitioned"
where day > '2024/06/01' and day < '2024/12/31'
group by YEAR(timestamp),MONTH(timestamp),modelId,region
order by month
返回结果如下截图。
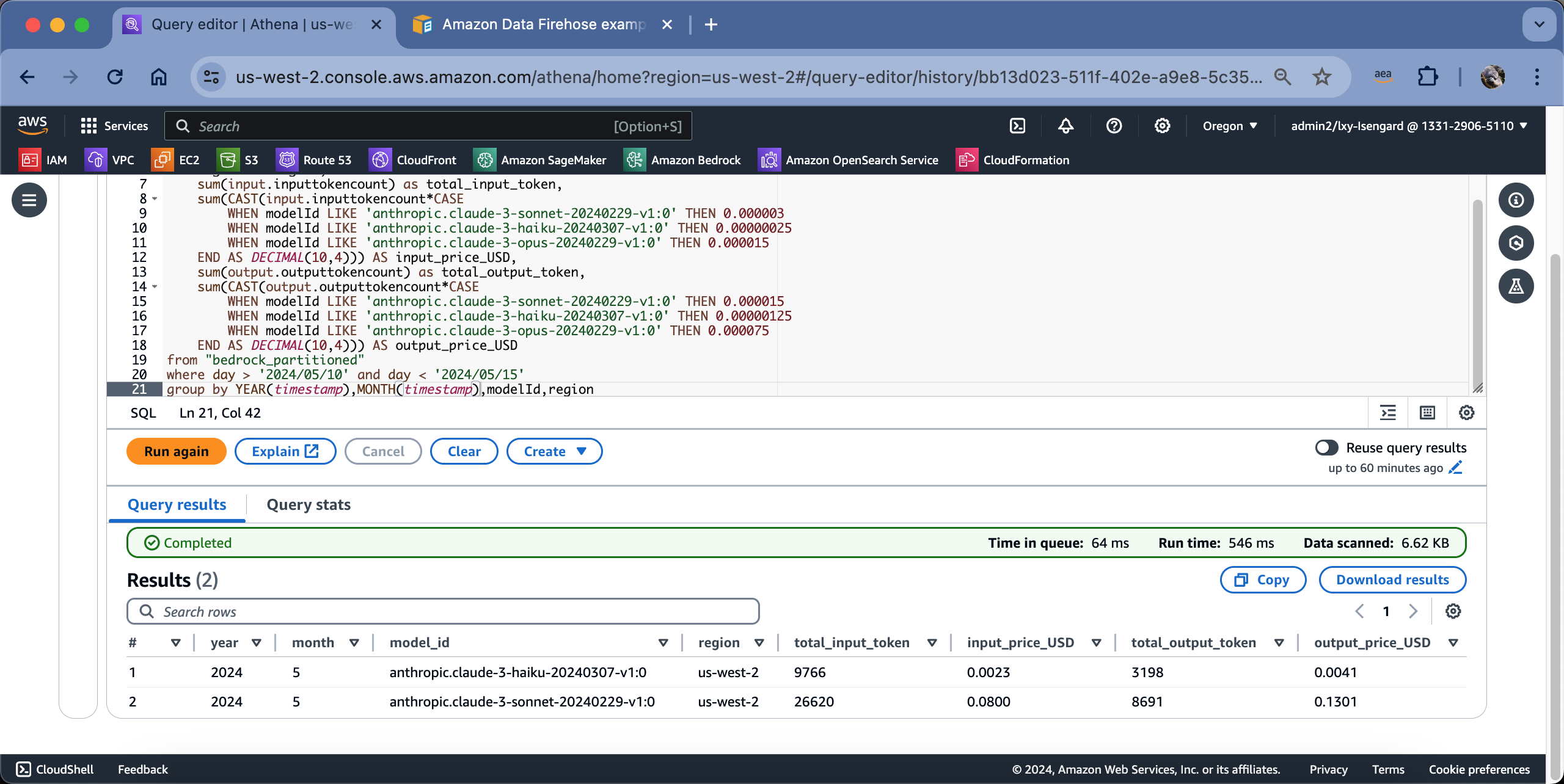
由此即可获得在本Region、本月、各模型的用量(不拆分用户)。
3、查询各模型按用户查询、按天用量的详表
编写如下SQL查询本月总量,按不同调用者的ARN(也就是IAM User)、Region和模型ID汇总。
-- 按模型、按天详表 --
-- 以下价格based on us-west-2 美西2俄勒冈区域 --
-- 以下数据已经除以1000,将报价表默认的1K token报价折算为1 token报价 --
select
YEAR(timestamp) as year,
MONTH(timestamp) as month,
DAY(timestamp) as day,
modelId as model_id,
region as region,
sum(input.inputtokencount) as total_input_token,
sum(CAST(input.inputtokencount*CASE
WHEN modelId LIKE 'anthropic.claude-3-5-sonnet-20240620-v1:0' THEN 0.000003
WHEN modelId LIKE 'anthropic.claude-3-sonnet-20240229-v1:0' THEN 0.000003
WHEN modelId LIKE 'anthropic.claude-3-haiku-20240307-v1:0' THEN 0.00000025
WHEN modelId LIKE 'anthropic.claude-3-opus-20240229-v1:0' THEN 0.000015
WHEN modelId LIKE 'mistral.mistral-large-2407-v1:0' THEN 0.000003
WHEN modelId LIKE 'meta.llama3-1-405b-instruct-v1:0' THEN 0.00000532
END AS DECIMAL(10,4))) AS input_price_USD,
sum(output.outputtokencount) as total_output_token,
sum(CAST(output.outputtokencount*CASE
WHEN modelId LIKE 'anthropic.claude-3-5-sonnet-20240620-v1:0' THEN 0.000015
WHEN modelId LIKE 'anthropic.claude-3-sonnet-20240229-v1:0' THEN 0.000015
WHEN modelId LIKE 'anthropic.claude-3-haiku-20240307-v1:0' THEN 0.00000125
WHEN modelId LIKE 'anthropic.claude-3-opus-20240229-v1:0' THEN 0.000075
WHEN modelId LIKE 'mistral.mistral-large-2407-v1:0' THEN 0.000009
WHEN modelId LIKE 'meta.llama3-1-405b-instruct-v1:0' THEN 0.000016
END AS DECIMAL(10,4))) AS output_price_USD,
identity.arn as iam_user
from "bedrock_partitioned"
where day >= '2024/06/01' and day <= '2024/12/31'
group by YEAR(timestamp),MONTH(timestamp),DAY(timestamp),identity.arn,modelId,region
order by month,DAY(timestamp);
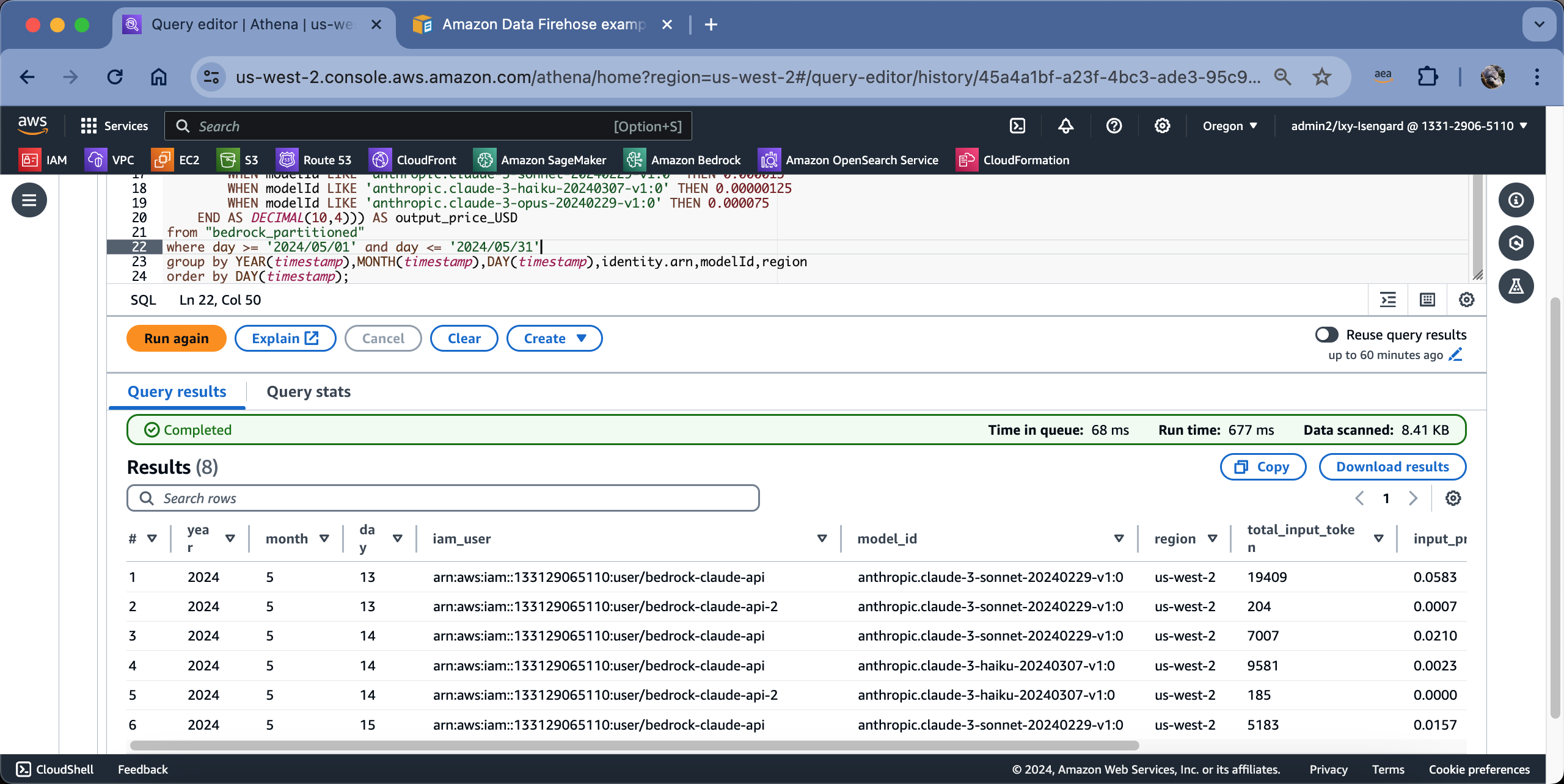
执行结果如下截图。
4、按用户汇总本月账单**(含所有模型,不拆分到天)**
执行如下SQL,按用户汇总每个用户本月账单(不区分模型)。
-- 按用户汇总,含所有模型,不拆分 --
-- 以下价格based on us-west-2 美西2俄勒冈区域 --
-- 以下数据已经除以1000,将报价表默认的1K token报价折算为1 token报价 --
SELECT
year,
month,
iam_user,
sum(input_price_USD) + sum(output_price_USD) as total_USD
FROM (
select
YEAR(timestamp) as year,
MONTH(timestamp) as month,
DAY(timestamp) as day,
identity.arn as iam_user,
modelId as model_id,
region as region,
sum(input.inputtokencount) as total_input_token,
sum(CAST(input.inputtokencount*CASE
WHEN modelId LIKE 'anthropic.claude-3-5-sonnet-20240620-v1:0' THEN 0.000003
WHEN modelId LIKE 'anthropic.claude-3-sonnet-20240229-v1:0' THEN 0.000003
WHEN modelId LIKE 'anthropic.claude-3-haiku-20240307-v1:0' THEN 0.00000025
WHEN modelId LIKE 'anthropic.claude-3-opus-20240229-v1:0' THEN 0.000015
WHEN modelId LIKE 'mistral.mistral-large-2407-v1:0' THEN 0.000003
WHEN modelId LIKE 'meta.llama3-1-405b-instruct-v1:0' THEN 0.00000532
END AS DECIMAL(10,4))) AS input_price_USD,
sum(output.outputtokencount) as total_output_token,
sum(CAST(output.outputtokencount*CASE
WHEN modelId LIKE 'anthropic.claude-3-5-sonnet-20240620-v1:0' THEN 0.000015
WHEN modelId LIKE 'anthropic.claude-3-sonnet-20240229-v1:0' THEN 0.000015
WHEN modelId LIKE 'anthropic.claude-3-haiku-20240307-v1:0' THEN 0.00000125
WHEN modelId LIKE 'anthropic.claude-3-opus-20240229-v1:0' THEN 0.000075
WHEN modelId LIKE 'mistral.mistral-large-2407-v1:0' THEN 0.000009
WHEN modelId LIKE 'meta.llama3-1-405b-instruct-v1:0' THEN 0.000016
END AS DECIMAL(10,4))) AS output_price_USD
from "bedrock_partitioned"
where day >= '2024/06/01' and day <= '2024/12/31'
group by YEAR(timestamp),MONTH(timestamp),DAY(timestamp),identity.arn,modelId,region
order by DAY(timestamp)
)
group by year,month,iam_user
order by year,month,iam_user;
执行结果如下截图。
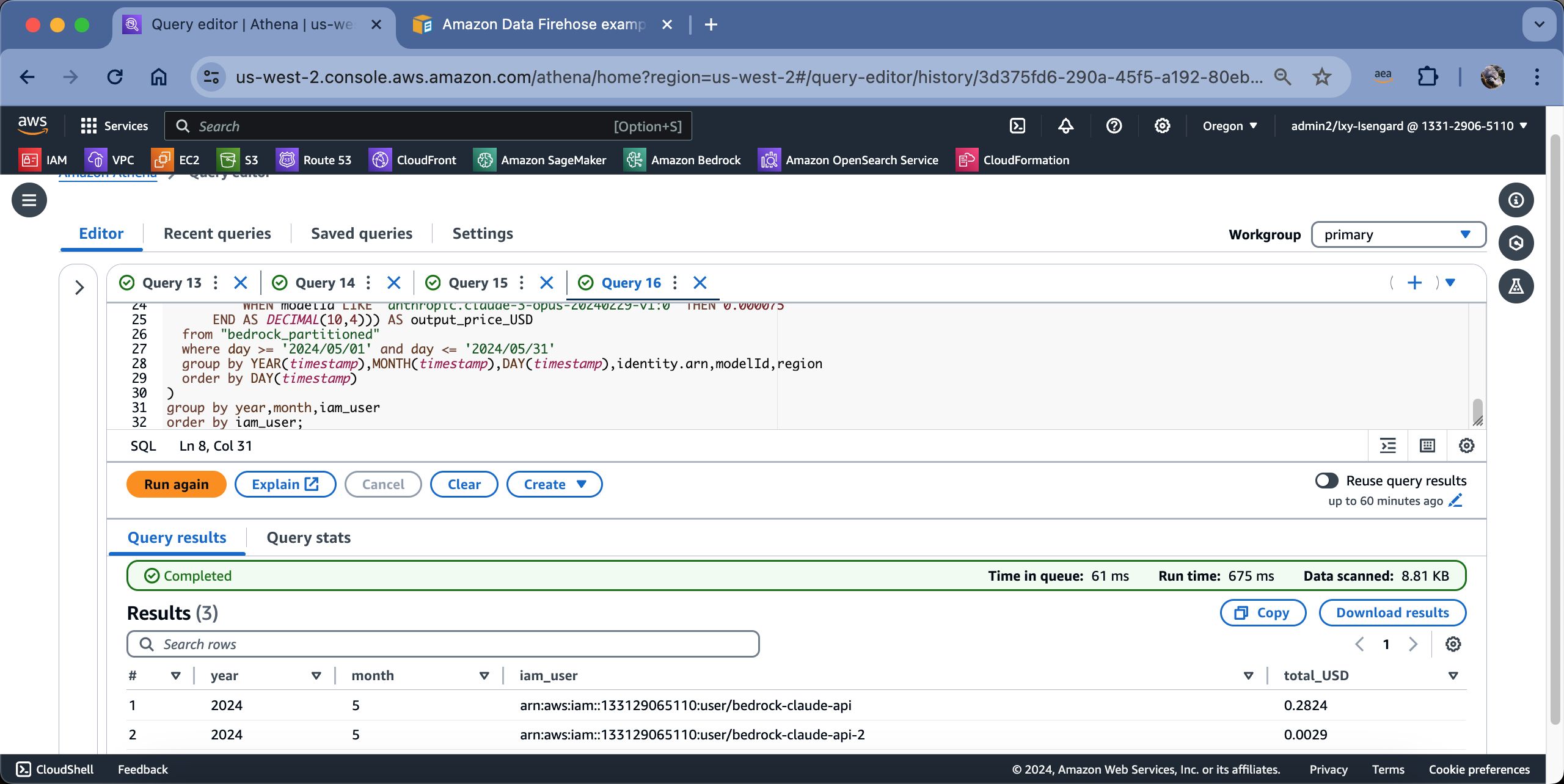
即可看到查询结果是基于用户名分组,每个用户下使用的多种模型的成本已经求和。
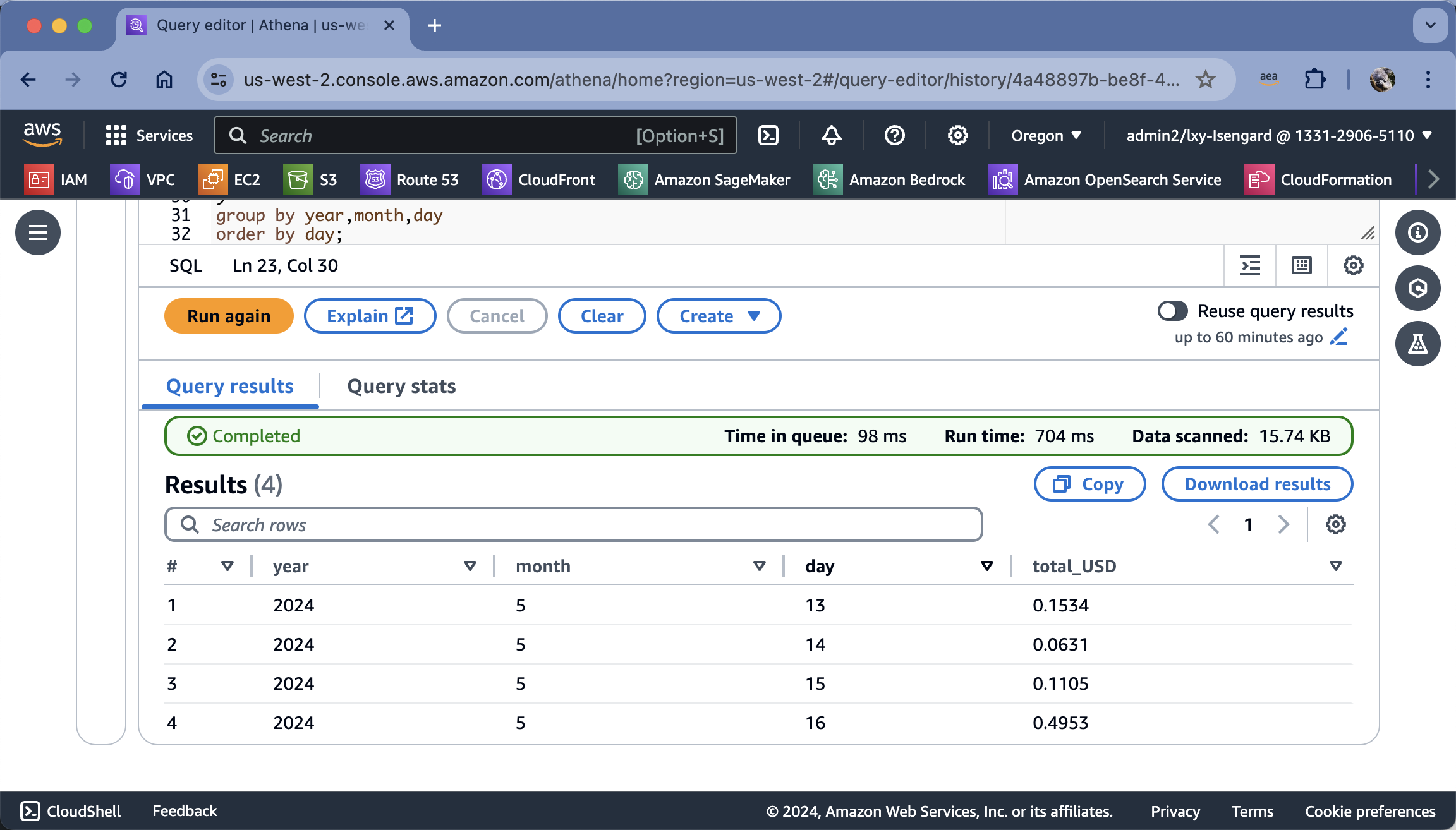
5、汇总本月每天账单(不拆分模型、不拆分用户)
执行如下代码。
-- 按用户汇总每天的费用,含所有模型,不拆分 --
-- 以下价格based on us-west-2 美西2俄勒冈区域 --
-- 以下数据已经除以1000,将报价表默认的1K token报价折算为1 token报价 --
SELECT
year,
month,
day,
sum(input_price_USD) + sum(output_price_USD) as total_USD
FROM (
select
YEAR(timestamp) as year,
MONTH(timestamp) as month,
DAY(timestamp) as day,
identity.arn as iam_user,
modelId as model_id,
region as region,
sum(input.inputtokencount) as total_input_token,
sum(CAST(input.inputtokencount*CASE
WHEN modelId LIKE 'anthropic.claude-3-5-sonnet-20240620-v1:0' THEN 0.000003
WHEN modelId LIKE 'anthropic.claude-3-sonnet-20240229-v1:0' THEN 0.000003
WHEN modelId LIKE 'anthropic.claude-3-haiku-20240307-v1:0' THEN 0.00000025
WHEN modelId LIKE 'anthropic.claude-3-opus-20240229-v1:0' THEN 0.000015
WHEN modelId LIKE 'mistral.mistral-large-2407-v1:0' THEN 0.000003
WHEN modelId LIKE 'meta.llama3-1-405b-instruct-v1:0' THEN 0.00000532
END AS DECIMAL(10,4))) AS input_price_USD,
sum(output.outputtokencount) as total_output_token,
sum(CAST(output.outputtokencount*CASE
WHEN modelId LIKE 'anthropic.claude-3-5-sonnet-20240620-v1:0' THEN 0.000015
WHEN modelId LIKE 'anthropic.claude-3-sonnet-20240229-v1:0' THEN 0.000015
WHEN modelId LIKE 'anthropic.claude-3-haiku-20240307-v1:0' THEN 0.00000125
WHEN modelId LIKE 'anthropic.claude-3-opus-20240229-v1:0' THEN 0.000075
WHEN modelId LIKE 'mistral.mistral-large-2407-v1:0' THEN 0.000009
WHEN modelId LIKE 'meta.llama3-1-405b-instruct-v1:0' THEN 0.000016
END AS DECIMAL(10,4))) AS output_price_USD
from "bedrock_partitioned"
where day >= '2024/05/01' and day <= '2024/05/31'
group by YEAR(timestamp),MONTH(timestamp),DAY(timestamp),identity.arn,modelId,region
order by DAY(timestamp)
)
group by year,month,day
order by year,month,day;
查询结果如下截图,可按本月的每日列出总账单(不拆分用户、不拆分模型)。
四、参考文档
Bedrock日志配置
https://docs.aws.amazon.com/bedrock/latest/userguide/model-invocation-logging.html
Athena扫描S3收费
https://aws.amazon.com/athena/pricing/?nc=sn&loc=3
Athena分区开启Partition Projection的说明
https://docs.aws.amazon.com/athena/latest/ug/partition-projection.html
最后修改于 2024-05-14