EMR 101 Workshop 中文版(上篇)
本文介绍EMR 101工作坊上篇,涵盖VPC/IAM环境准备、EMR Studio配置、创建Spark集群等,通过实践解决大数据处理中的集群配置和任务提交问题
因篇幅所限和单次实验时间所限,本文拆成上下两篇且只包含Spark/Hive/Presto。HBase、Iceberg、Hudi等将另外编写。
一、实验介绍
本实验将运行多个EMR集群,体验EMR、EMR Studio Notebook,以及Spark、Hive、Presto等多种服务的交互和操作。
本实验建议在AWS海外区域的美西2俄勒冈(us-west-2, Oregon)区域进行,也可以在新加坡等区域执行。
本实验可以在用户自有AWS账号内进行,也可以使用培训讲师提供的实验专用账号(有效期48小时)来进行。本实验步骤多\选项多,部分选项如果遗漏或者配置错误将导致实验不成功,请务必仔细操作。
二、环境准备
1、VPC和IAM准备
注:本步骤大约需要15分钟。
本实验使用CloudFormation模版拉起一个实验环境,预先配置了VPC、IAM策略、Security Group安全组等。这样做的好处:
- 如果您是使用当前AWS账号,那么本CloudFormation模版拉起全新实验环境包含VPC、IAM策略、角色,这对您的AWS账号内已经存在的应用没有影响;您也可以随时删除;
- 如果您使用的是实验专用全新的AWS账号(有效期48小时),那么本很多环境没有初始化配置,因此使用CloudFormation模版创建拉起实验环境将大大简化您上手的过程。
从这里下载CloudFormation模版。注:本模版因为包含IAM角色,因此目前只适用于AWS全球区域,不适合中国区域。如果希望在中国区域适用,那么需要修改IAM策略中ARN部分的的aws为aws-cn。
进入AWS控制台,从服务清单中查找CloudFormation服务,也可以从上方搜索框输入CloudFormation关键字,然后点击进入。如下截图。
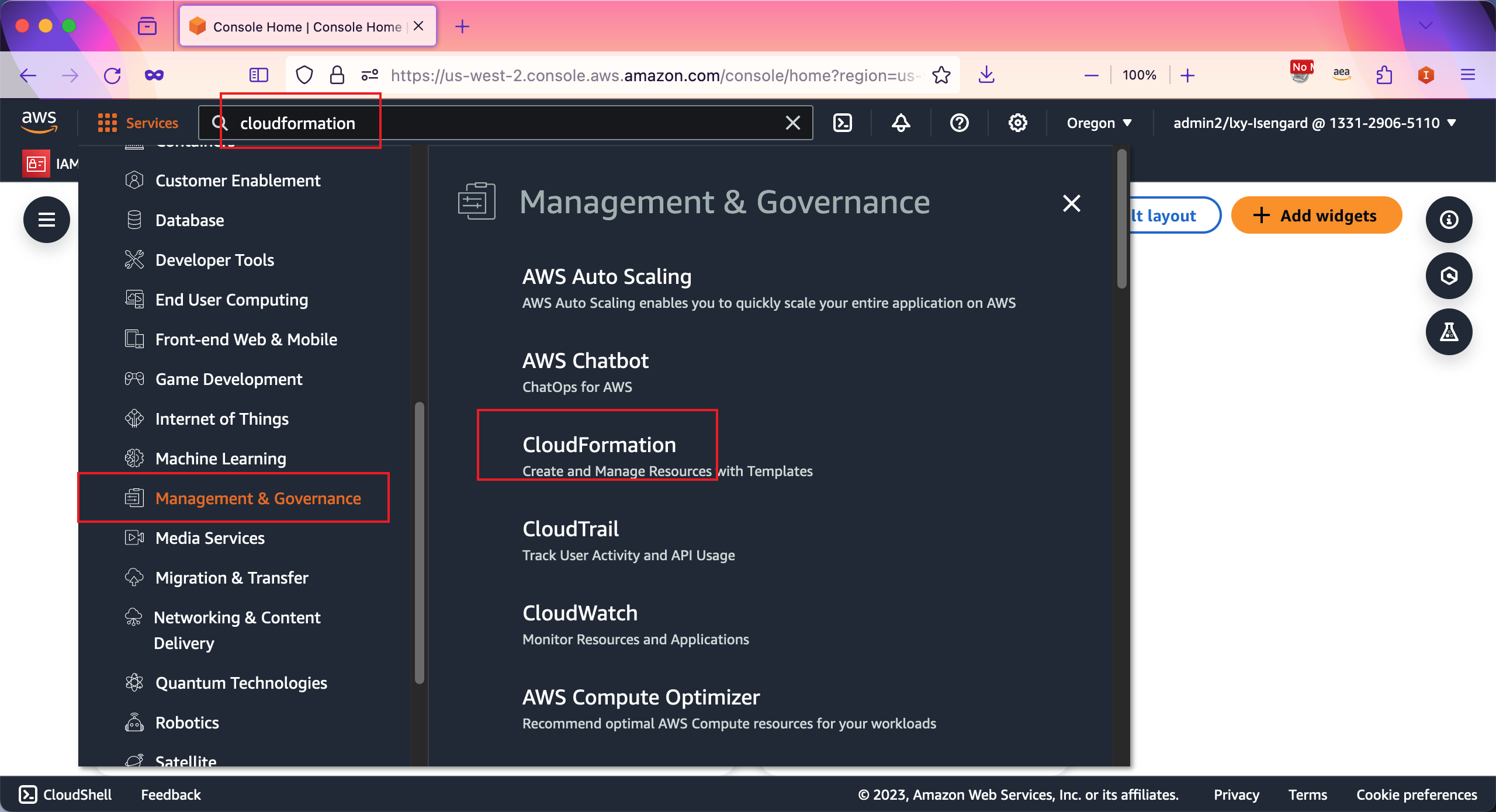
点击右上角的Create stack创建新的堆栈,选择第一项With new resources(Standard)。如下截图。
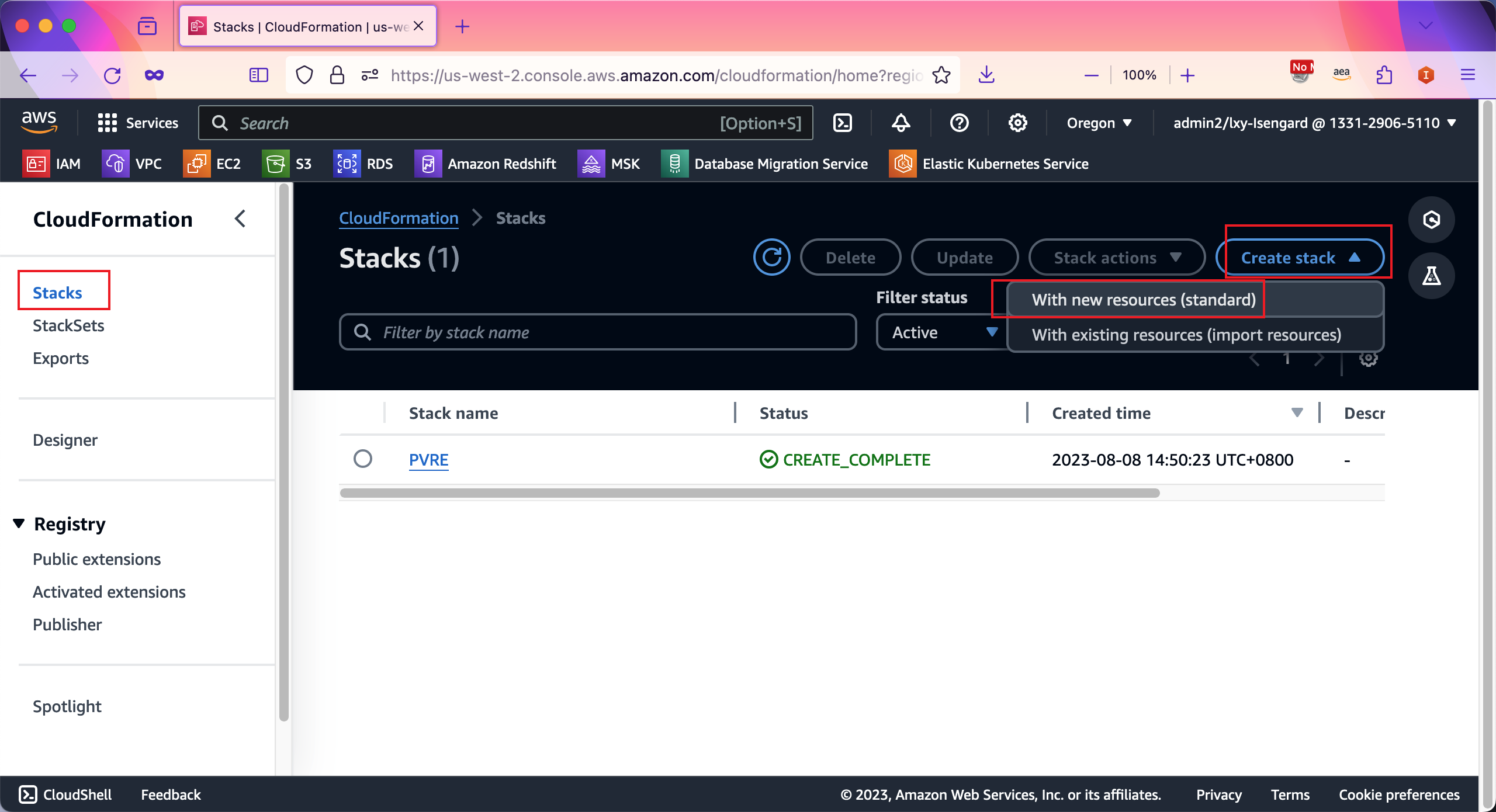
在创建向导中,选择Template is ready模版已经就绪,在下方选择Upload a template file上传模版,然后点击上传按钮浏览上传。如下截图。
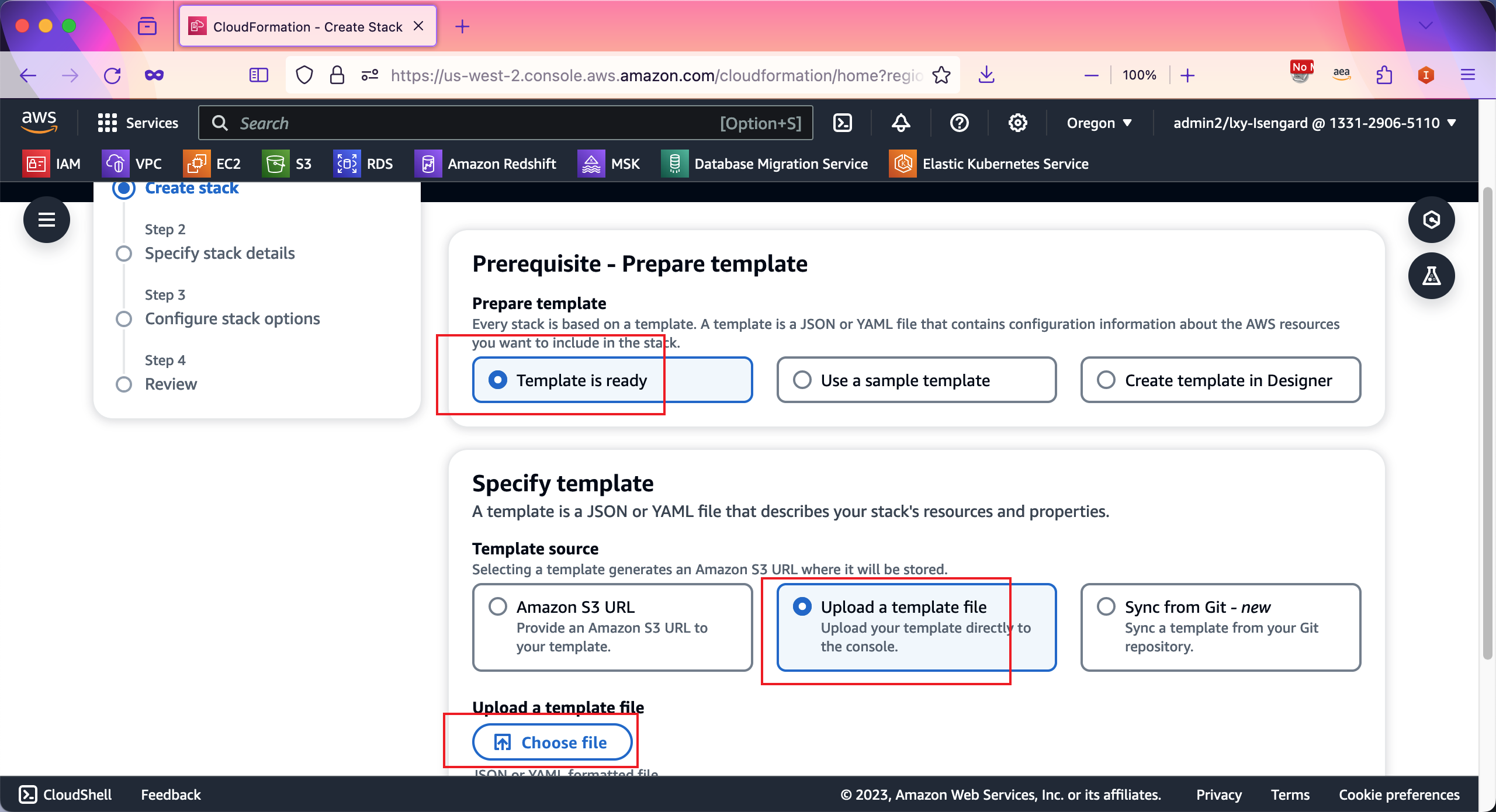
上传成功后,可识别出来文件名和上传后的一次性临时网址。点击右下角的Next按钮继续。如下截图。
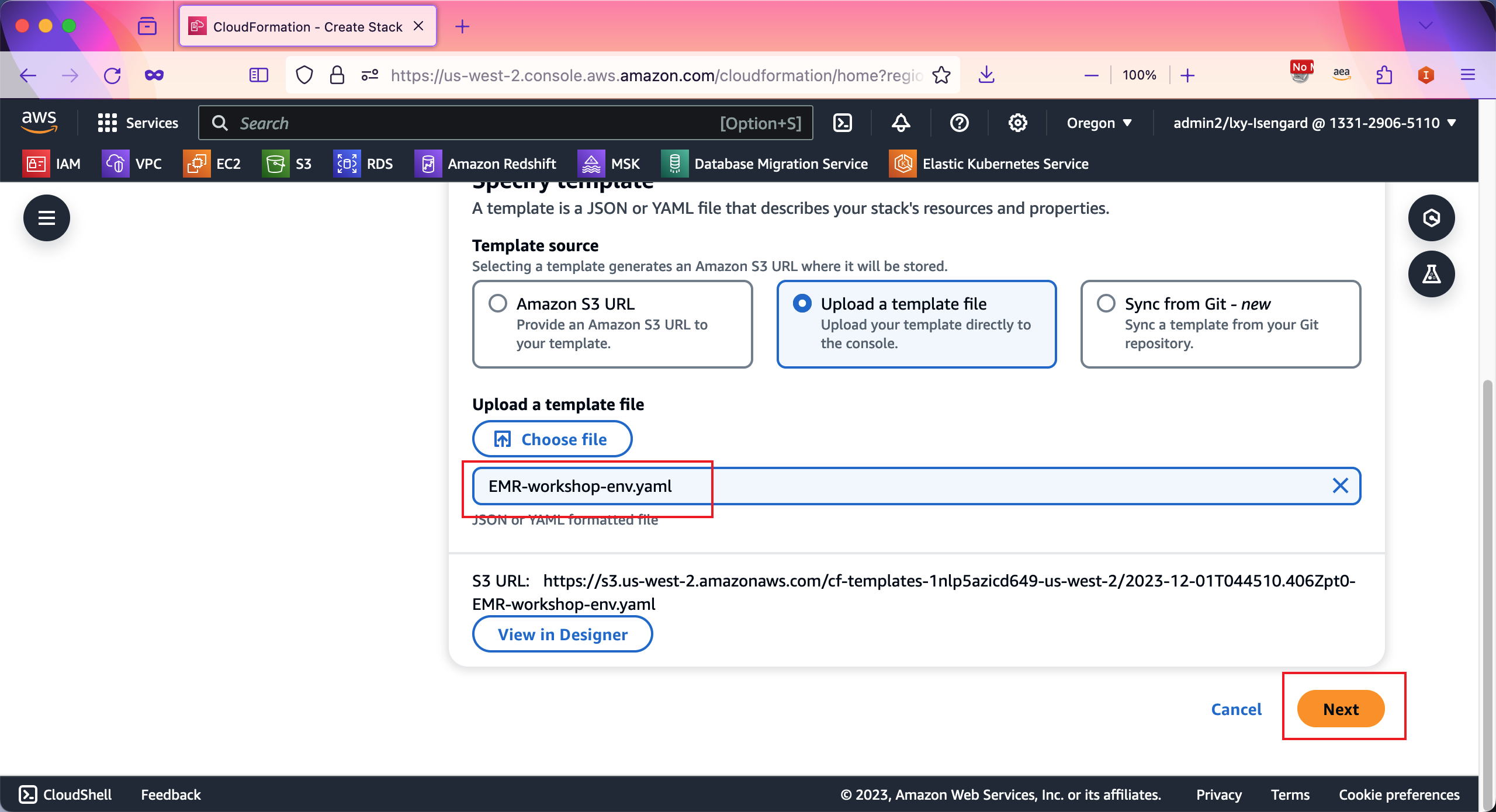
在模版名称位置,输入emr-workshop-env作为模版名称。点击右下角的Next按钮继续。如下截图。
在本页面跳过所有选项,点击右下角的Next按钮继续。如下截图。
选中页面上的允许CloudFormation创建IAM 资源的对话框,然后点击右下角的Submit按钮完成创建。如下截图。
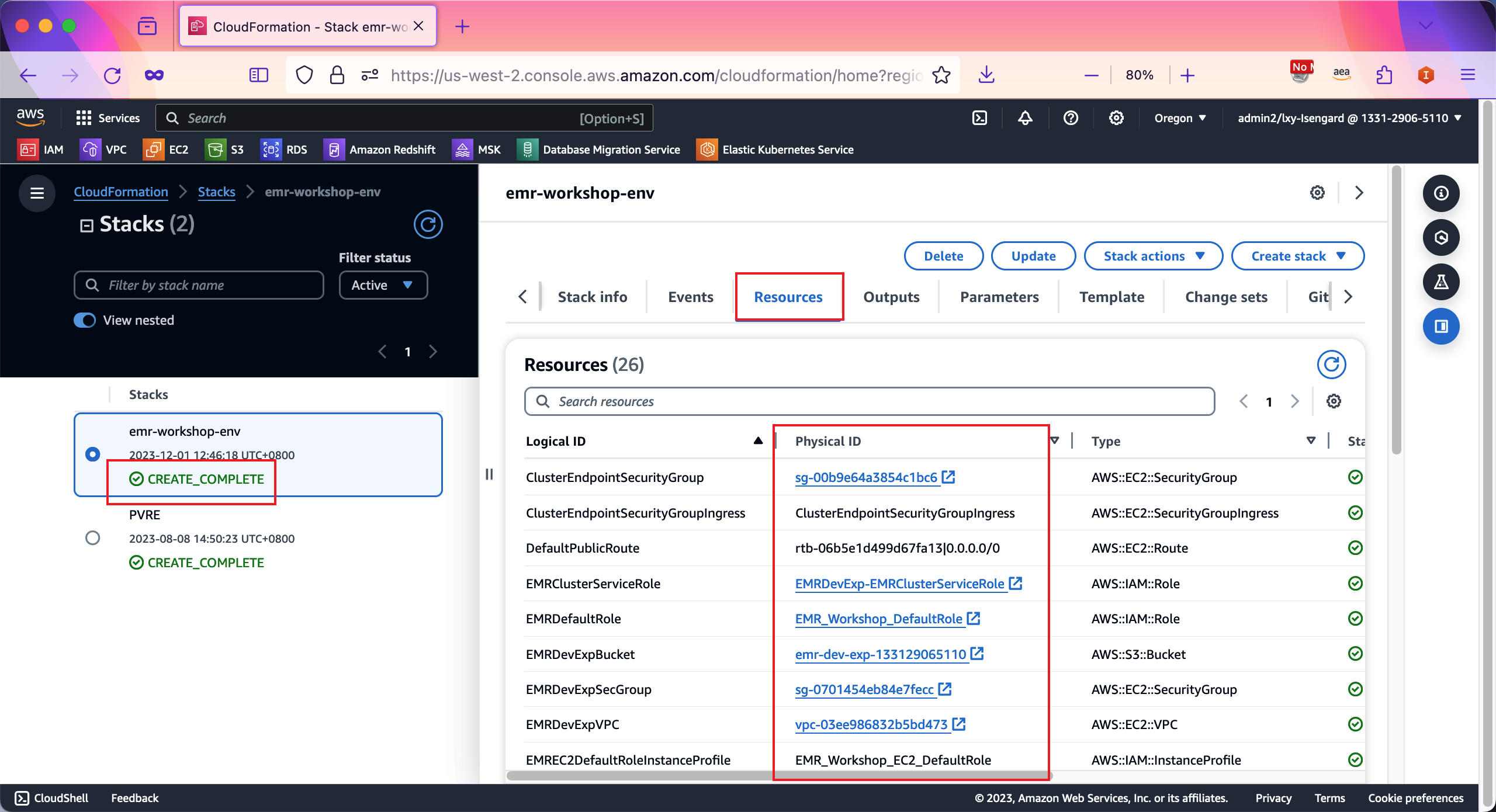
在CloudFormation界面中,左侧第一个菜单Stack堆栈下,可以看到刚才创建的emr-workshop-env这个模版。点击Resource资源标签页,就可以看到这个模版自动创建的VPC、安全组、IAM角色等。自动创建出来的这些资源,将用于下一步的动手实验。如下截图。
等待5分钟左右,VPC和IAM环境准备完毕。
2、EMR Studio和Notebook准备
注:本步骤大约需要10分钟。
在使用EMR得过程中,除了通过AWS EMR控制台下发Step任务、EC2远程SSH登录Root节点两种常见的任务之外,还可以使用EMR Studio的Notebook来进行数据访问操作任务。EMR Studio和Notebook提供了图形化的集成,里边也提供了数个ETL任务Sample可以学习借鉴。
在上一步的CloudFormation创建完毕后,即可创建EMR Studio。进入EMR服务控制台,在左下角的EMR Studio下边,找到Studios菜单,点击右上角的Create Studios,开始创建。如下截图。
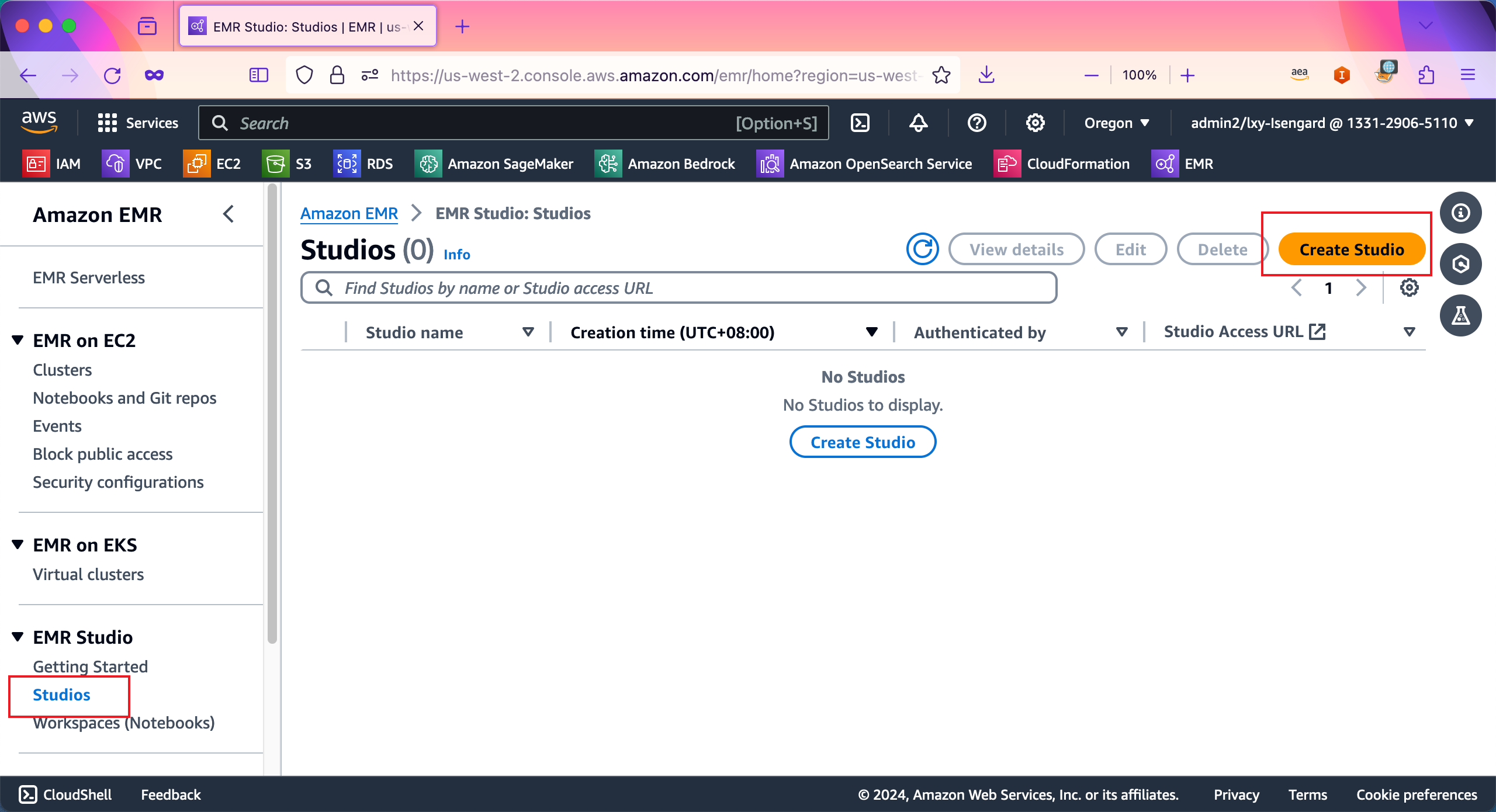
在创建向导中,在Setep options位置选择Custom定制方式创建。在Name位置输入名称。如下截图。
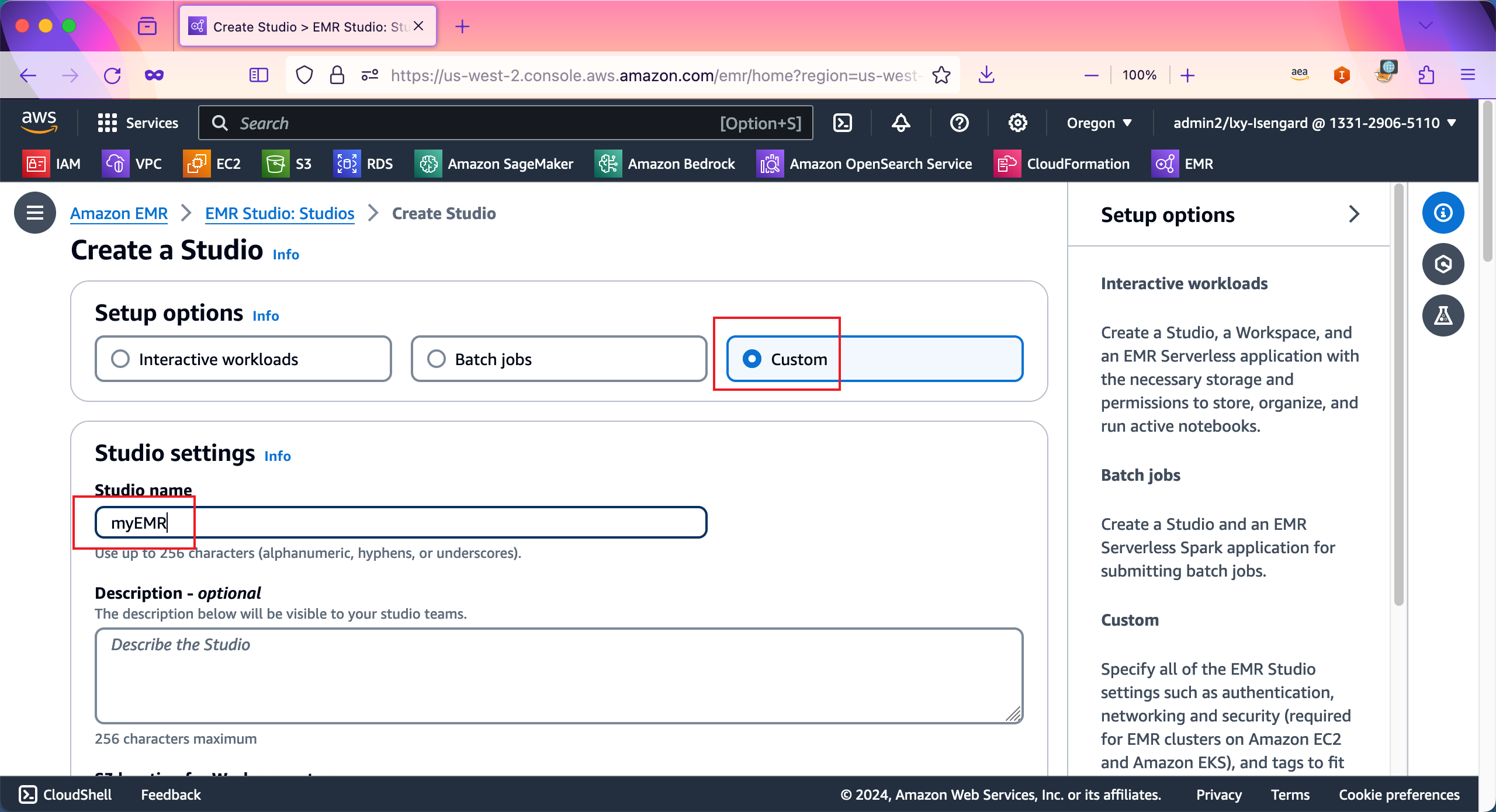
在S3 location for Workspace storage位置,选择Select existing location,然后输入S3存储桶s3://emr-dev-exp-123456789012/workspace,这里的数字是AWS账号12位ID。在存储桶后添加workspace目录,表示workspace工作文件存储在这个目录中。接下来继续向下滚动页面。如下截图。
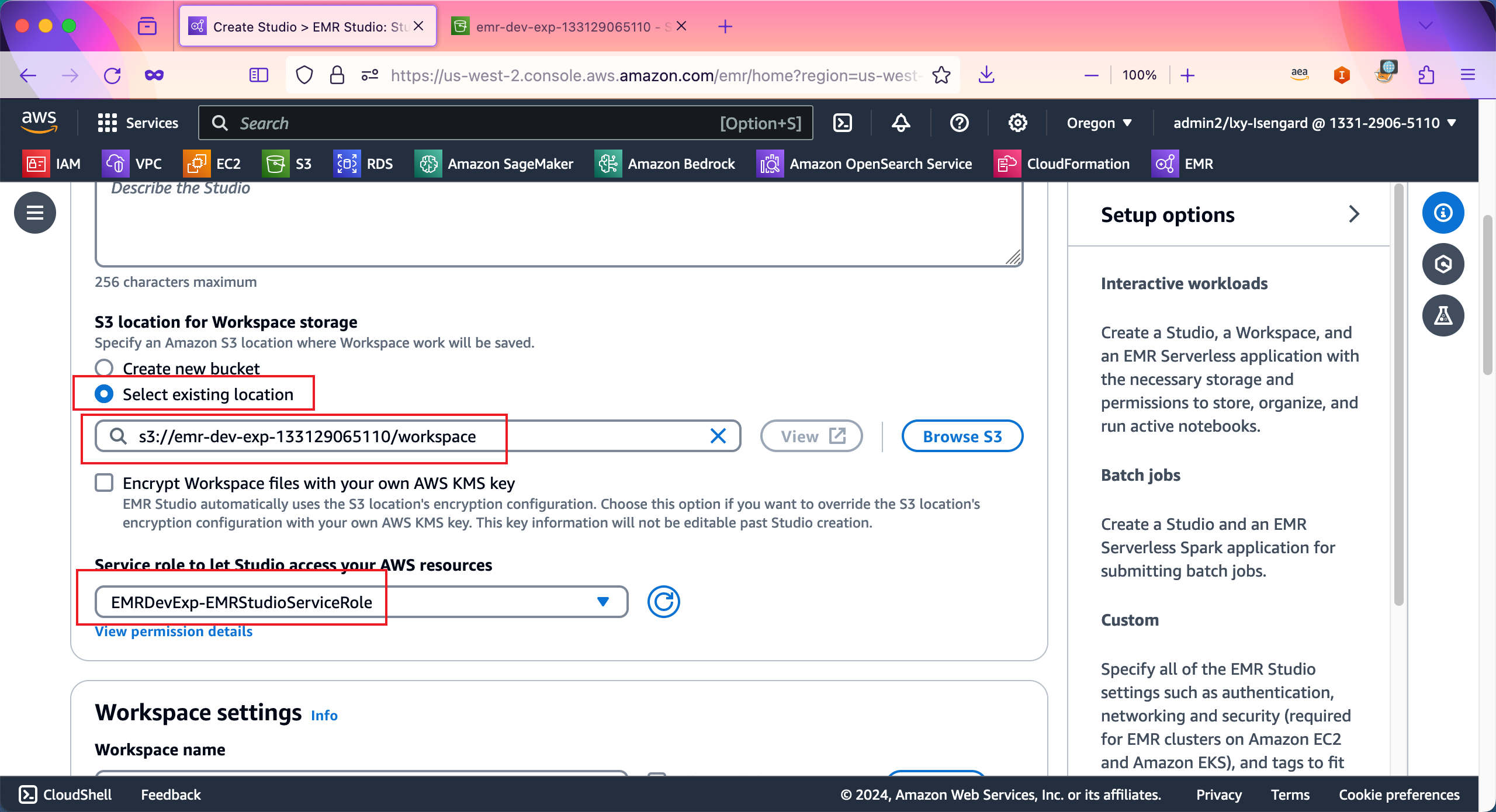
在Workspace settings位置,使用向导默认生成的Workspace_name即可,这里无需修改。在下方Authentication位置,选择第一项AWS Identify and Access Management(IAM)选项。接下来继续向下滚动页面。如下截图。
在IAM下方的三个optional可选认证参数设置上,留空不需要输入。接下来继续向下滚动页面。如下截图。
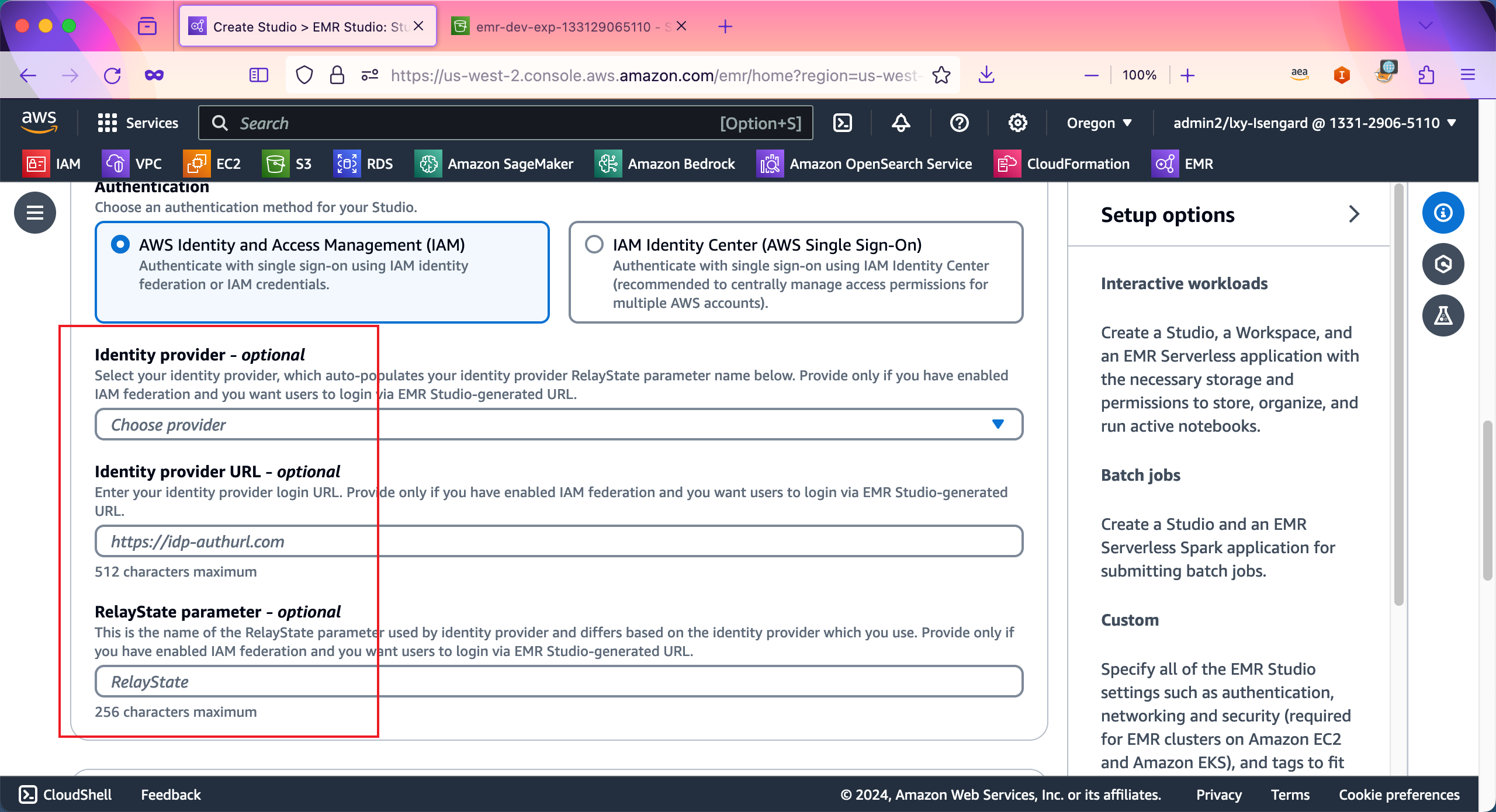
在Networking and security - optional位置,从VPC的下拉框中,选择标签是EMR-Dev-Exp-VPC的VPC,在Subnets位置选择带有标签EMR-Dev-Exp-PublicSubnet1的子网。其中VPC和子网都是上一步CloudFormaiton生成基础环境时候自动生成的。在安全组位置选择Custom security group自定义安全组。接下来继续向下滚动页面。如下截图。
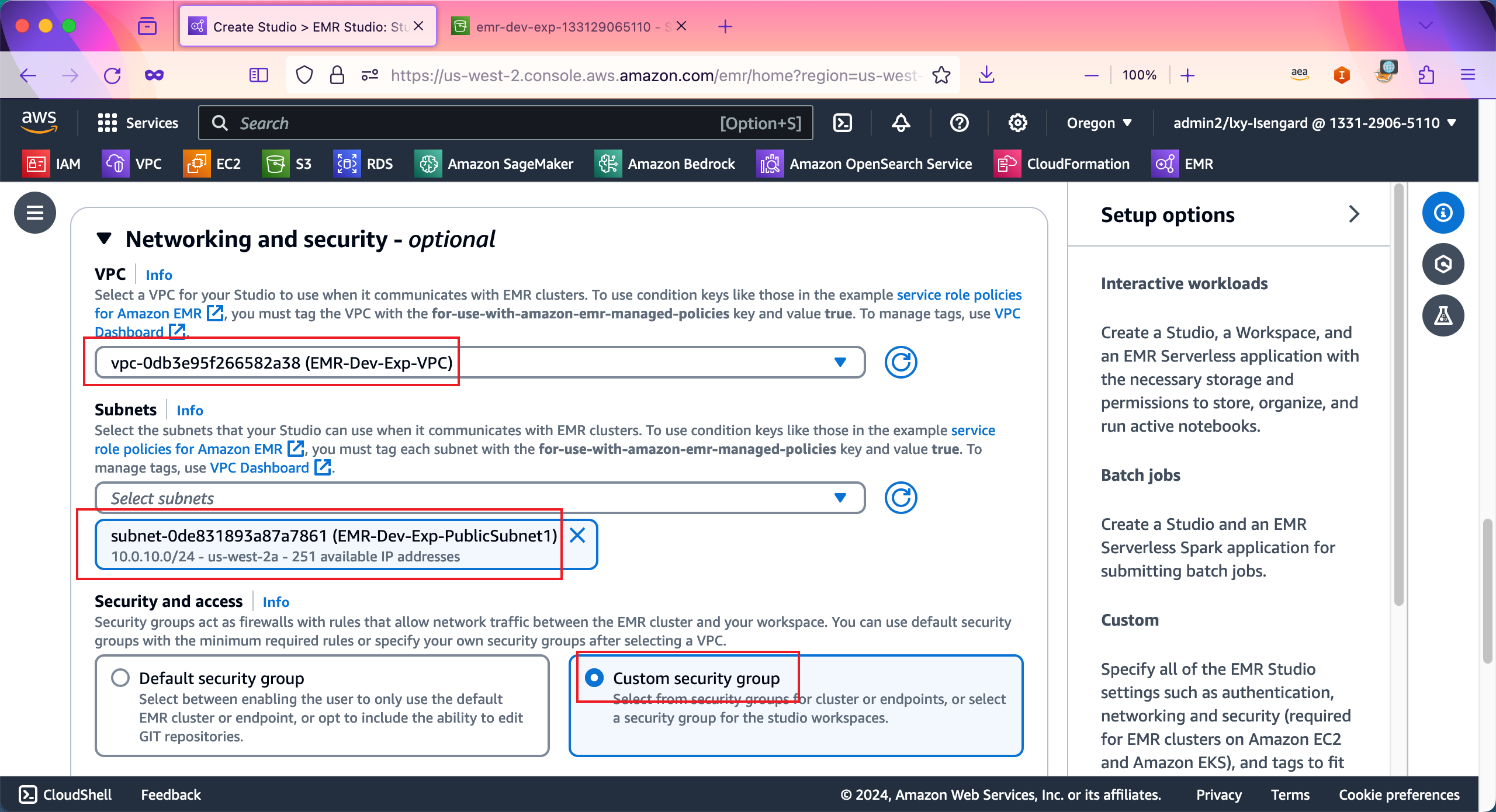
在Cluster/endpoint security group位置,从下拉框中选取标签为EMRDevExp-Cluster-Endpoint-SG的安全组。在Workspace security group位置,从下拉框中选取标签为EMRDevExp-Workspace-SG的安全组。最后点击右下角的Create Studio and Launch Workspace完成创建。如下截图。
EMR Studio创建中。此时如果页面提示弹出窗口失败,弹出窗口被浏览器屏蔽的话,只要打开浏览器允许AWS控制台弹出窗口即可。如下截图。
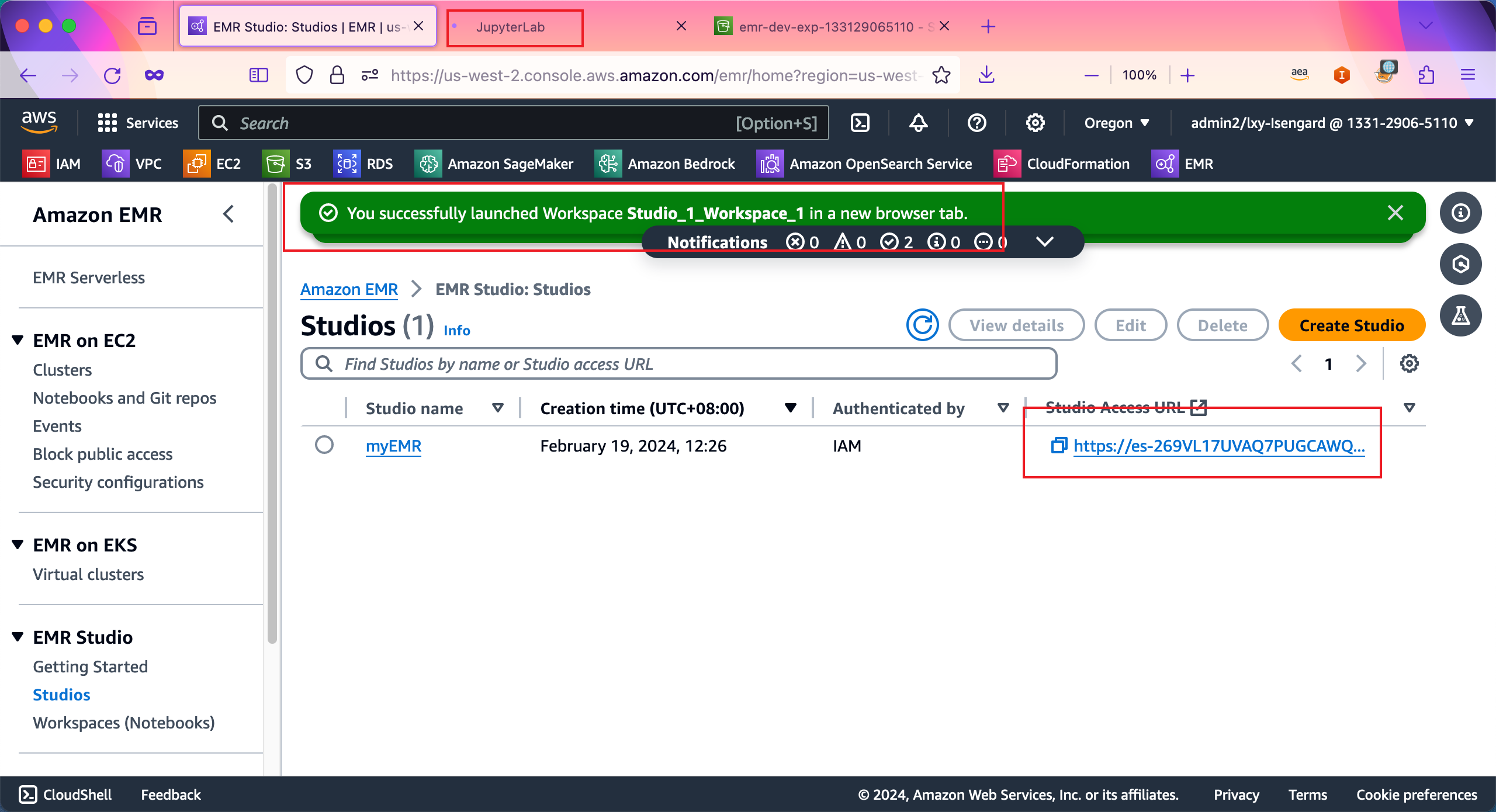
现在浏览器进入了EMR Studio Notebook的界面,在左侧菜单第二个按钮Compute位置,即可连接到EMR集群开始工作(本实验下一章节才会创建EMR没集群)。如下截图。
在EMR Studio Notebook的界面,在左侧菜单中可以找到Notebook examples菜单,里边可以找到若干Notebook实验模版。如下截图。
EMR Studio Notebook提供的sample,在Github地址如下:
https://github.com/aws-samples/emr-studio-notebook-examples
至此EMR Studio Notebook准备就绪。
3、测试数据准备
注:本章节大概需要5分钟。
在CloudFormation创建的实验环境中,包含一个S3存储桶名为s3://emr-dev-exp-123456789012,这里的数字是AWS账号12位ID。现在这个存储桶内,分别创建如下子目录(子目录也叫Prefix):files, logs, input, output, data, workspace。
将测试用数据文件tripdata.csv下载并放到input目录下,将sales.csv下载并放到data目录下。
至此测试数据准备完毕。下边开始创建EMR集群。
三、创建第一个EMR集群并执行Spark任务
创建EMR选项参数较多,请仔细选择,以免配置错误造成权限不足、无法读取数据等问题。。
1、创建集群
注:本章节大概需要20分钟。
EMR节点包括Master节点、Core节点、Task节点三种类型。本实验创建的第一个集群为三种角色各一台的最小规模集群。
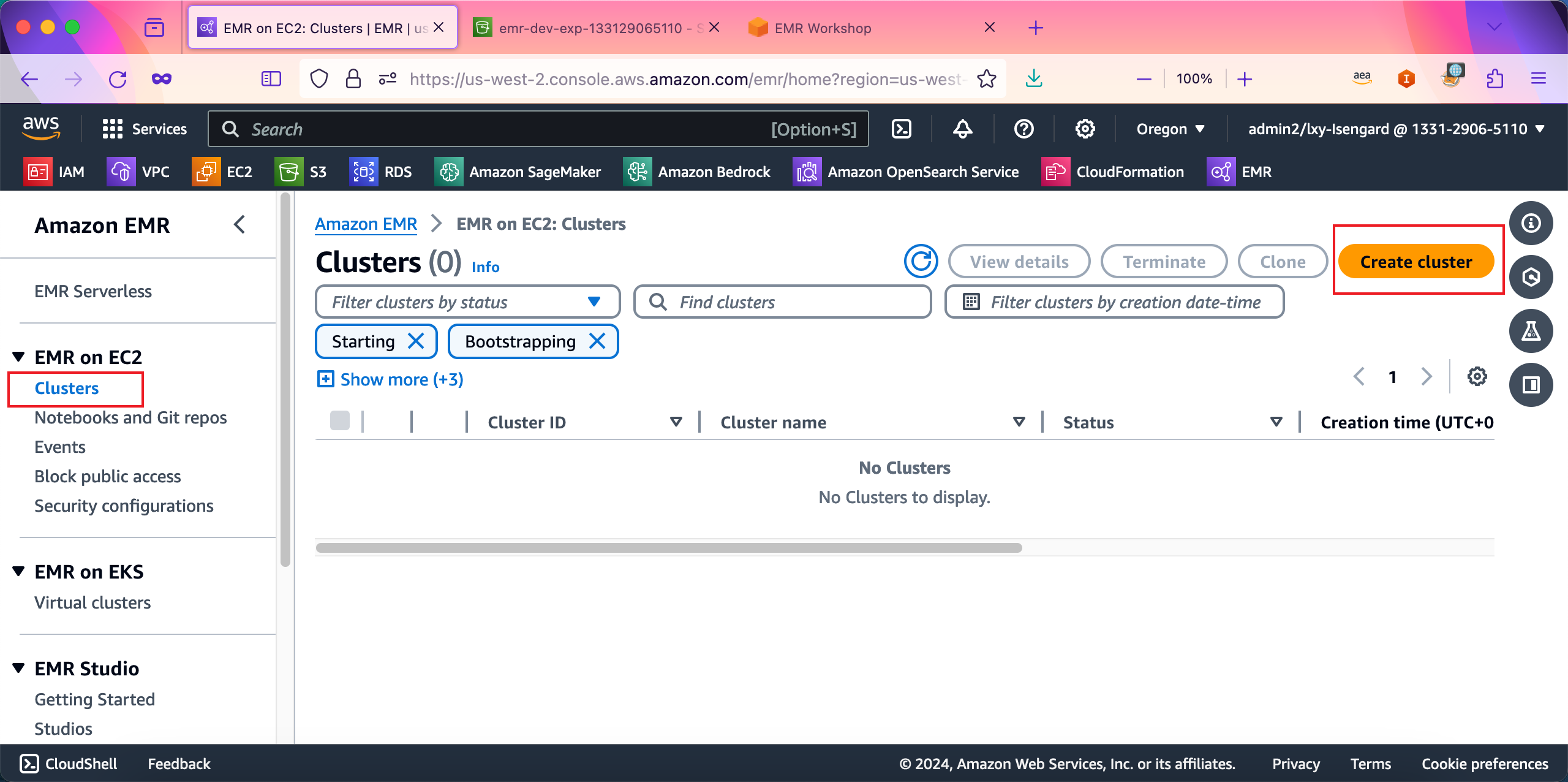
进入EMR服务。在左侧EMR on EC2菜单下,点击Cluster集群。然后点击右上角的Create cluster按钮创建集群。如下截图。
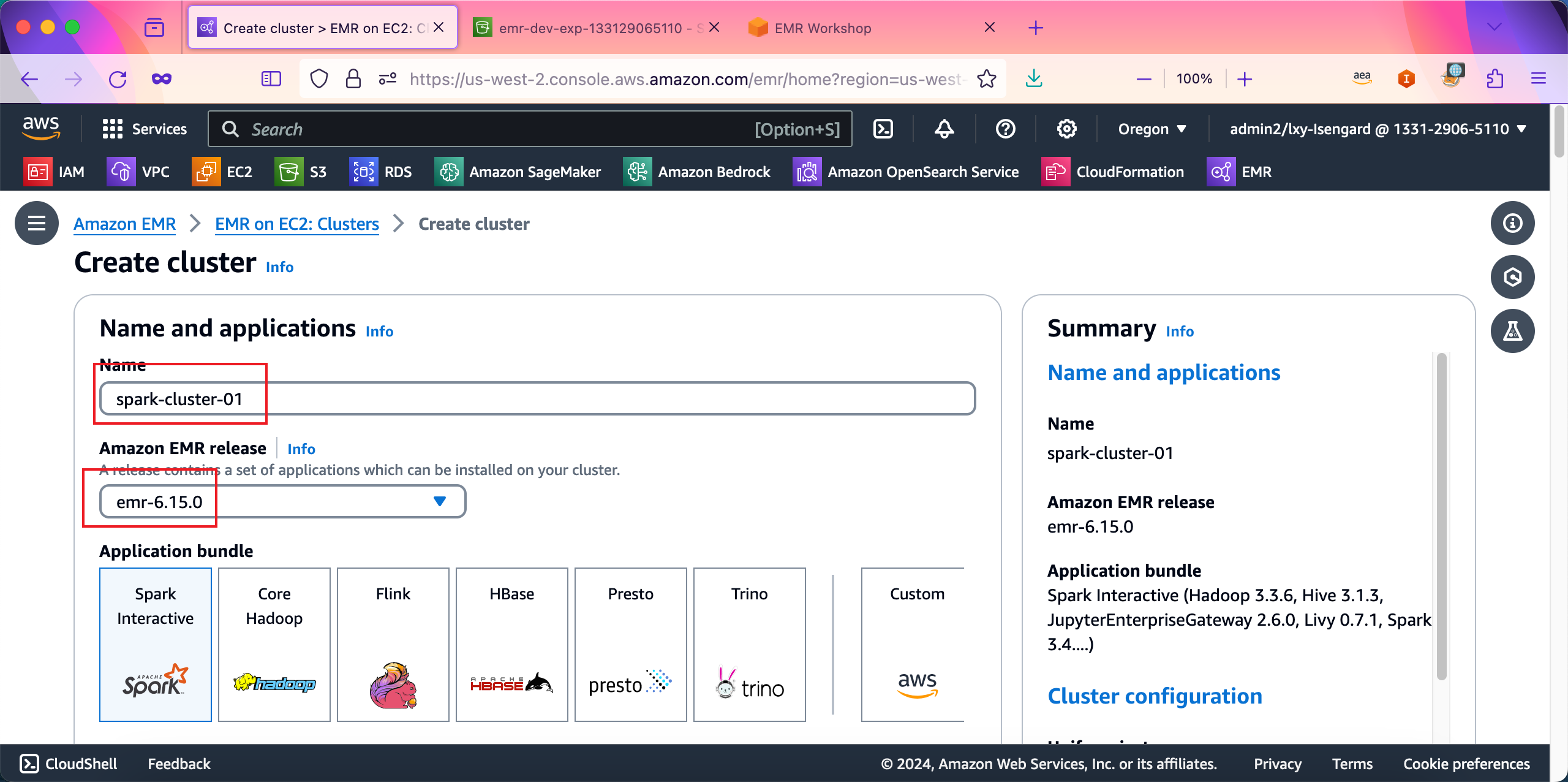
在集群位置输入名称,例如spark-cluster-01,在版本位置选择emr-6.15-0。然后向下滚动屏幕。如下截图。
在选择组件位置,勾选如下组件:Hadoop, Hive, Hue, JupterEnterpriseGateway, JupyterHub, Livy, Pig, Spark, Tez。其他组件暂时不需要安装。后续实验还会再创建别的集群,解释会再选择需要的组件。继续向下配置
在AWS Glue Data Catalog settings位置,选中与Glue Catalog集成,也就是选中Use for Hive table metadata和Use for spark table metadata两个选项。在下方的OS选择位置,选择默认的Amazon Linux release,并选中自动应用补丁更新Automatically apply latest Amazon linux updates的选项。如下截图。
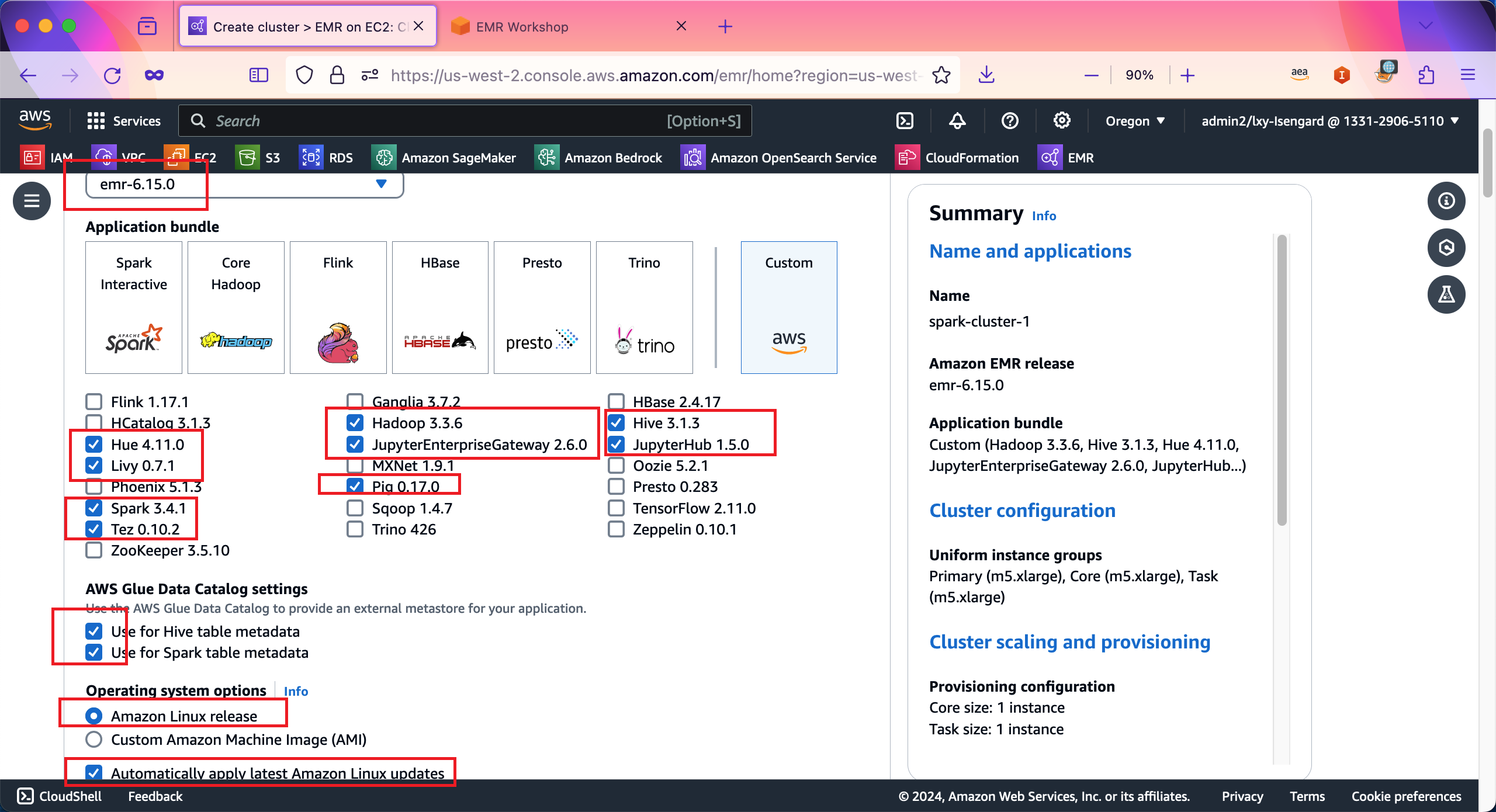
在选择好组件后,在Cluster configuration位置,选择左侧第一个选项Uniform instance groups,这将使得集群内所有的机型均为统一的类型(例如都是On-demand计费方式)。在Primary主节点位置,默认机型无需改动。在Use high availability位置,默认没有选中,这里也不用修改,保留其未选中状态。如下截图。
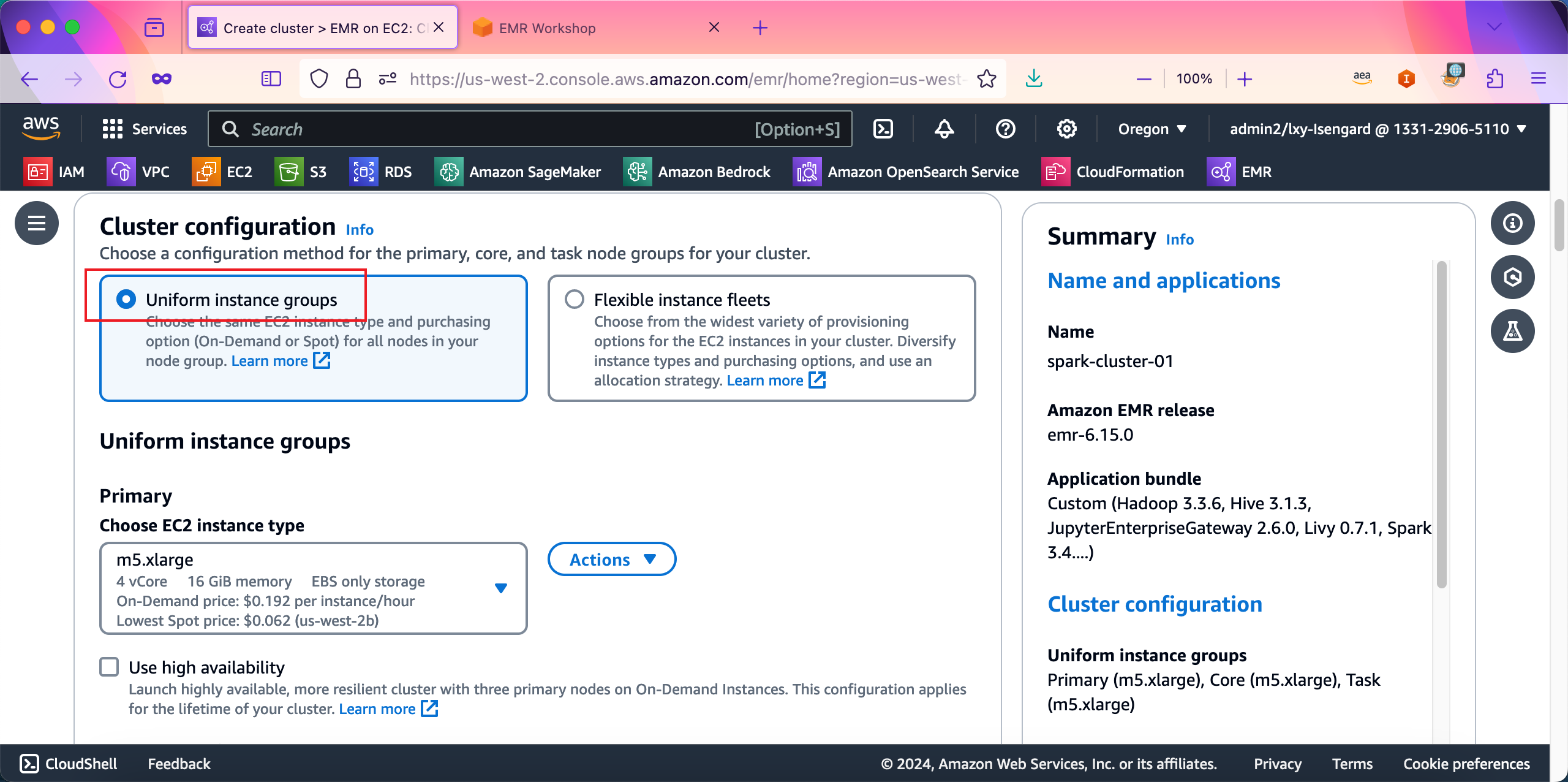
继续向下滚动屏幕。在Core节点和Task节点位置,都保留默认值,无需修改。接下来继续向下滚动屏幕。如下截图。
在磁盘配置EBS root volume位置,保持默认的磁盘空间、配置,无需修改。继续向下滚动屏幕。如下截图。
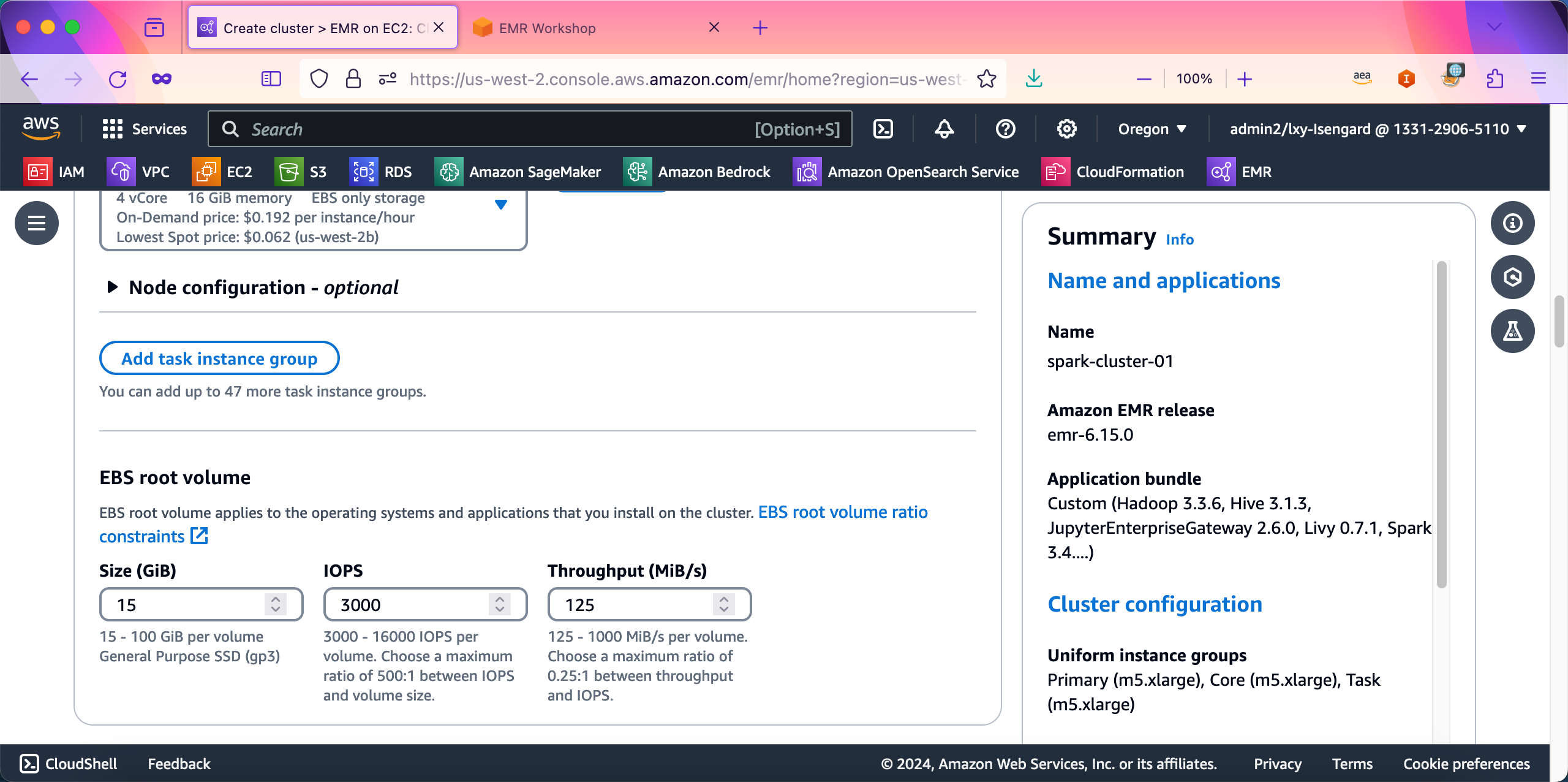
在Cluster scaling and provisioning集群缩放位置,选择第一项Set cluster size manually手工管理集群,然后在Core和Task节点的数量输入对话框,都输入1。创建EMR集群向导默认也是1。然后继续向下滚动页面。如下截图。
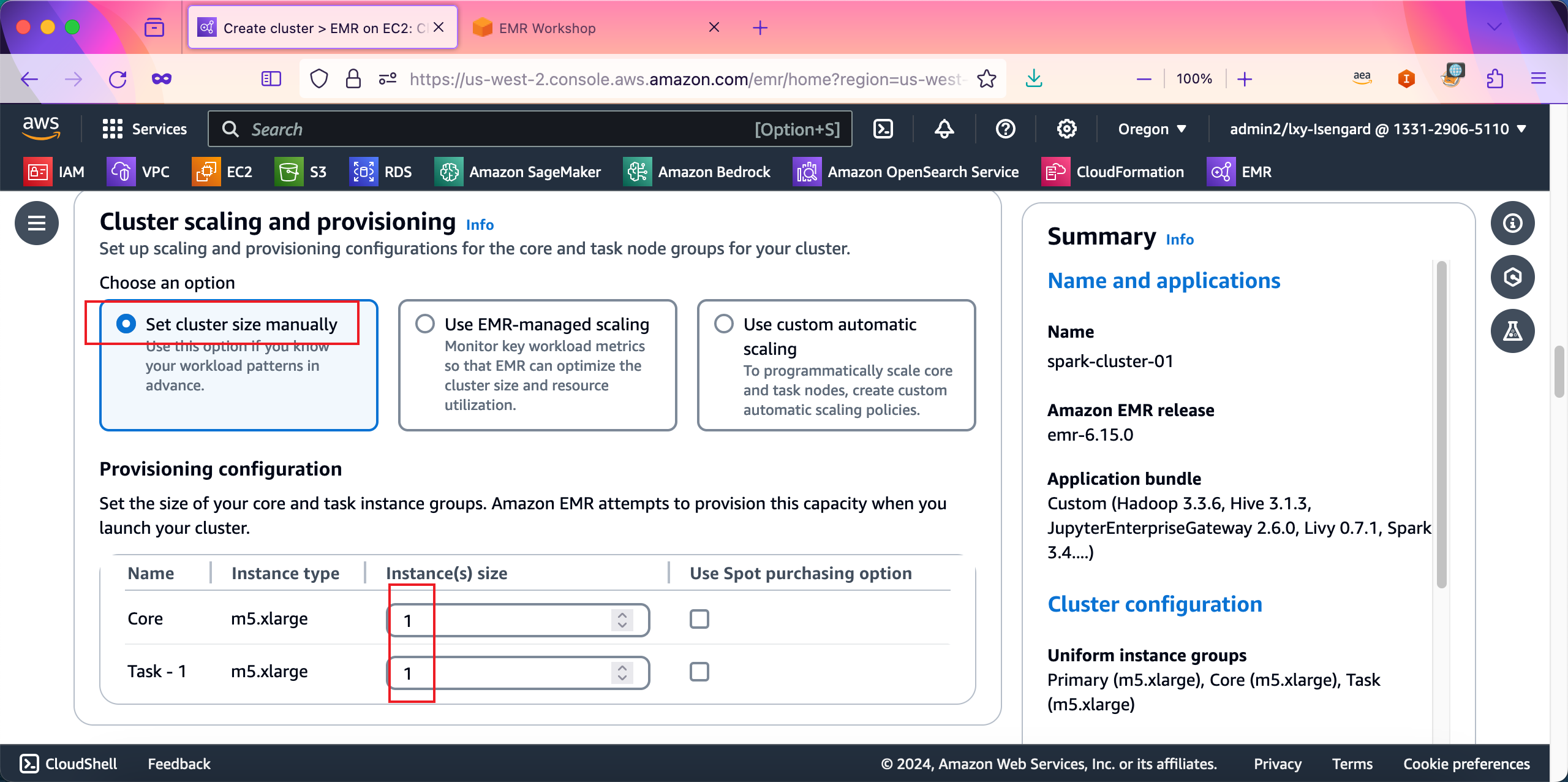
在Networking网络配置页面,从VPC下拉框中,选择标签是EMR-Dev-Exp-VPC的VPC,这个VPC是由CloudFormation在一开始部署实验环境时候自动创建好的。再选择完毕VPC后,子网也会自动刷新出来。因为本实验用VPC只有一个子网,因此就不需要再修改子网了。配置好子网后,在EC2 security groups (firewall)菜单中是安全组设置,这里使用默认的即可,向导会自动创建安全组,因此不需要展开安全组菜单。如下截图。
在EMR的Step任务步骤界面,保持为空,不输入。继续向下滚动页面。如下截图。
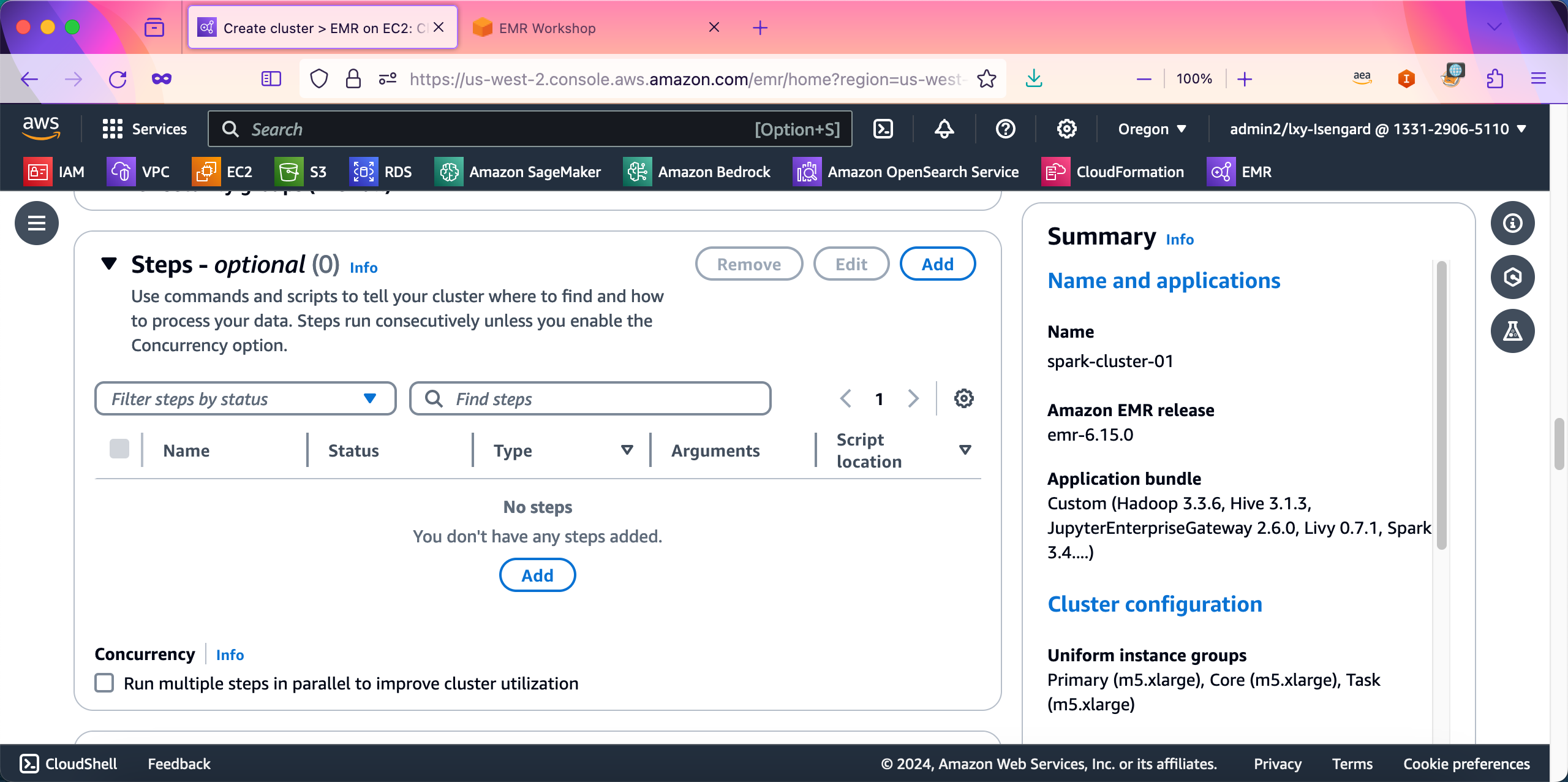
在集群终止配置界面,选择Manually terminate cluster,这表示创建的是长时运行集群,不会自动关闭和终止,只能手工删除集群。EMR创建向导默认选中的是Automatically terminate cluster after idle time (Recommended),则表示创建的EMR集群是短时任务集群,任务运算完毕后会自动终止。自动终止也就是自动释放,相关EC2会被彻底删除。由此可看出,此选项是决定集群是长时任务/短时任务的一个重要选项。此外,Use termination protection选项是一个防止意外删除EC2的选项,推荐选中。这一意味着如果发起错误的删除EC2操作,将会被拒绝,除非人为的禁用本开关,否则不能删除集群。如下截图。
在可选的Bootstrap actions位置,留空,不需要设置。在可选的Cluster logs位置,填写上CloudFormation自动生成的S3存储桶s3://emr-dev-exp-123456789012/logs,其中12位数字是AWS账户ID。在存储桶名后加上logs表示存放日志的目录。接下来继续向下滚动屏幕。如下截图。
在可选的Tag标签位置,跳过,无需输入。在可选的Software settings位置,跳过,无需输入。如下截图。
在Security configuration and EC2 key pair位置,在第一项Security configuration位置留空,不需要输入。在第二项登录到EC2使用的SSH密钥这里,点击浏览Brows按钮,选中本区域可用的EC2登录密钥。如下截图。
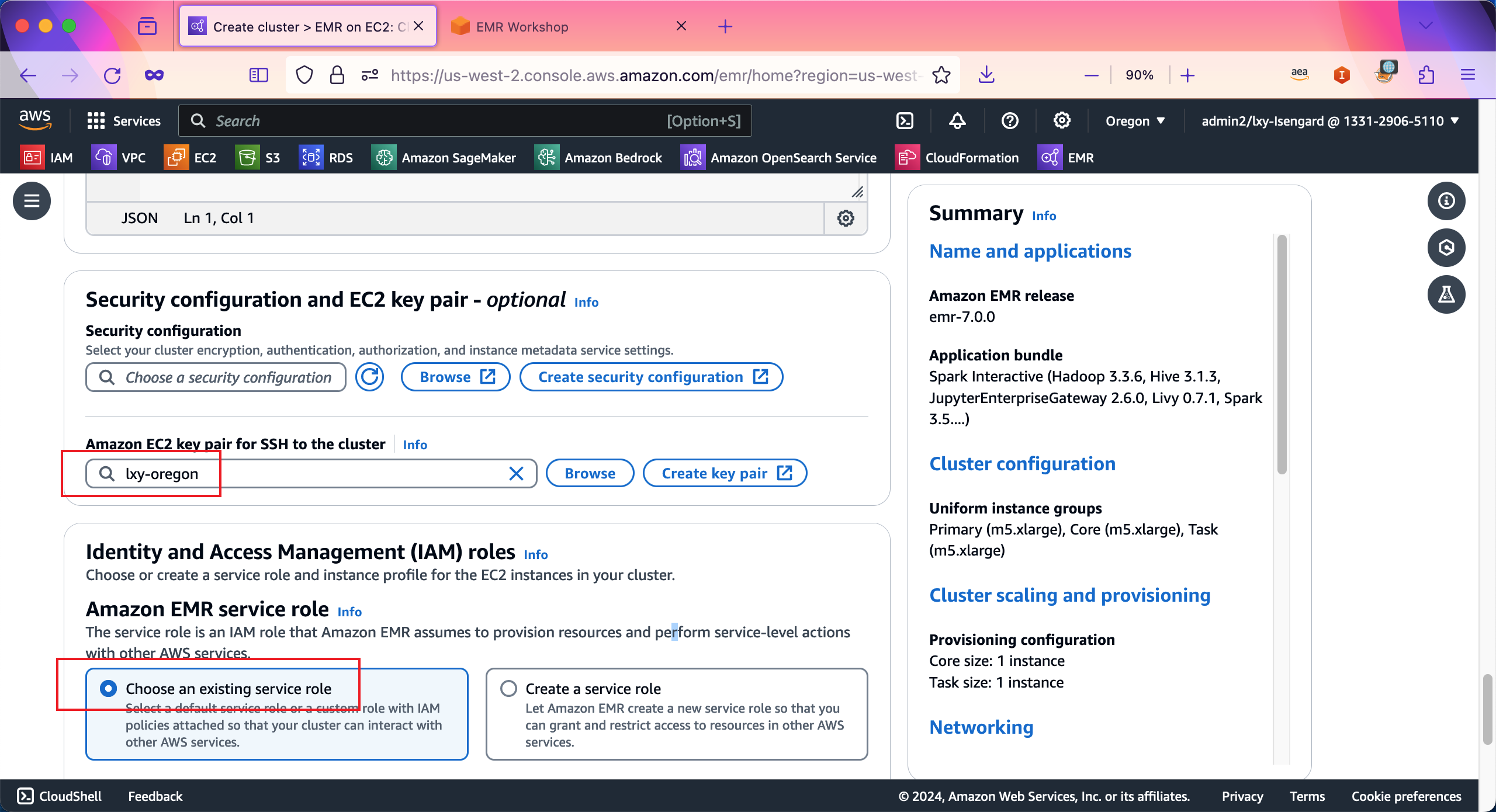
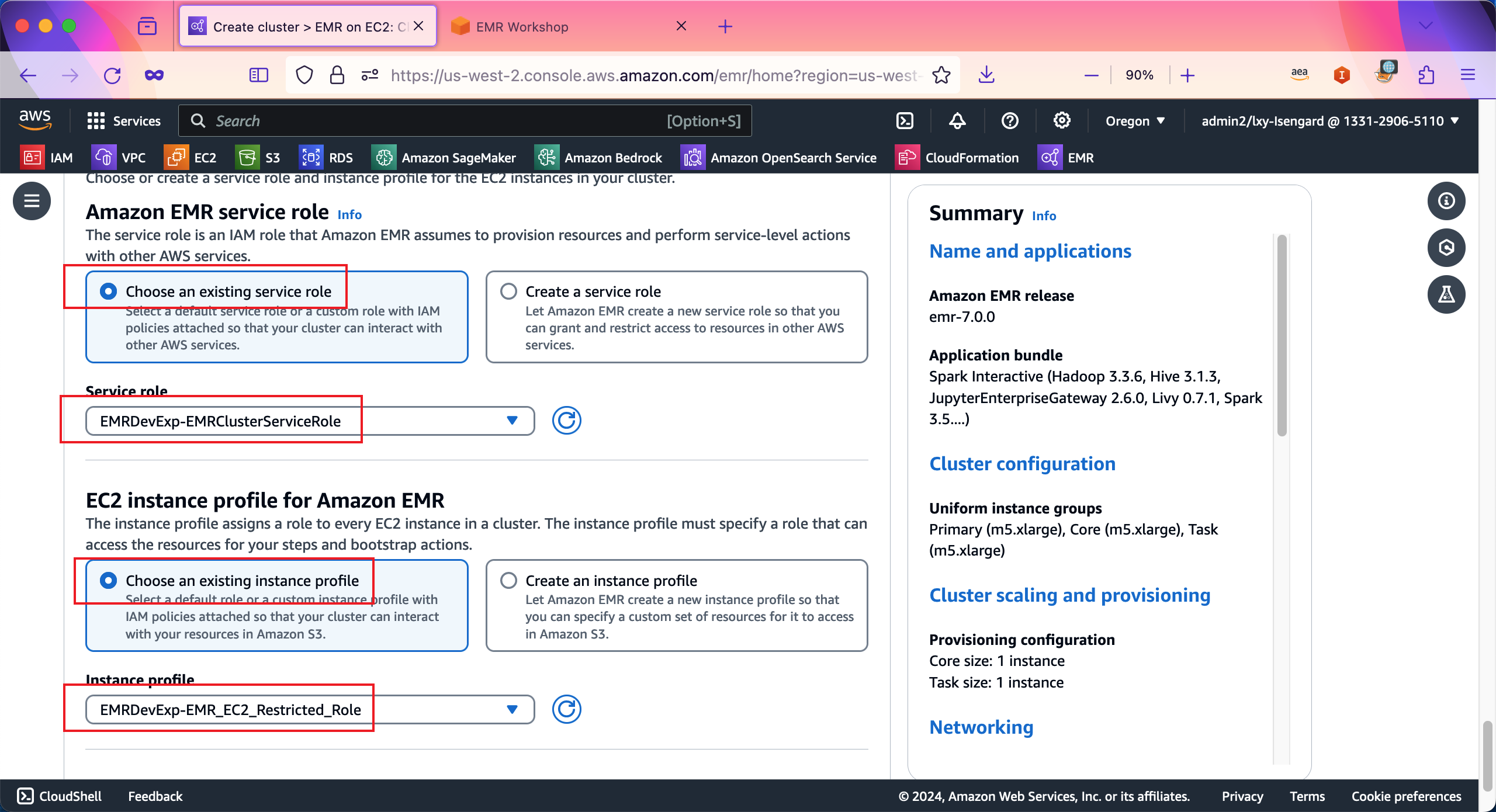
在Amazon EMR service role配置部分,选择第一项Choose an existing service role,然后从下拉框中选中名为EMRDevExp-EMRClusterServiceRole这个角色。然后在EC2 instance profile for Amazon EMR位置,选择Choose an existing instance profile,然后从下拉框中选择名为EMRDevExp-EMR_EC2_Restricted_Role的角色。如下截图。
在创建向导最后一项,在Custom automatic scaling role位置,从下拉框中选择EMR_Autoscaling_DefaultRole。最后可以点击右下角的创建按钮了。
创建向导提示创建集群成功。启动从创建到启动需要3-5分钟。如下截图。
2、获取本EMR集群对应的创建脚本用于未来快速创建集群
本章节大概需要3分钟。
从以上基于图形界面的操作可以看出,配置EMR版本、软件包、各节点机型和数量、VPC和子网、安全组、运行角色、日志、Steps等需要大量界面点击和交互,配置中很容易遗漏或者错误。
为了解决这个问题,EMR在集群创建后提供了自动构造好的脚本,用于未来快速创建相同配置的集群。点击EMR集群页面上的按钮Clone in AWS CLI,即可复制本集群对应的配置脚本。如下截图。
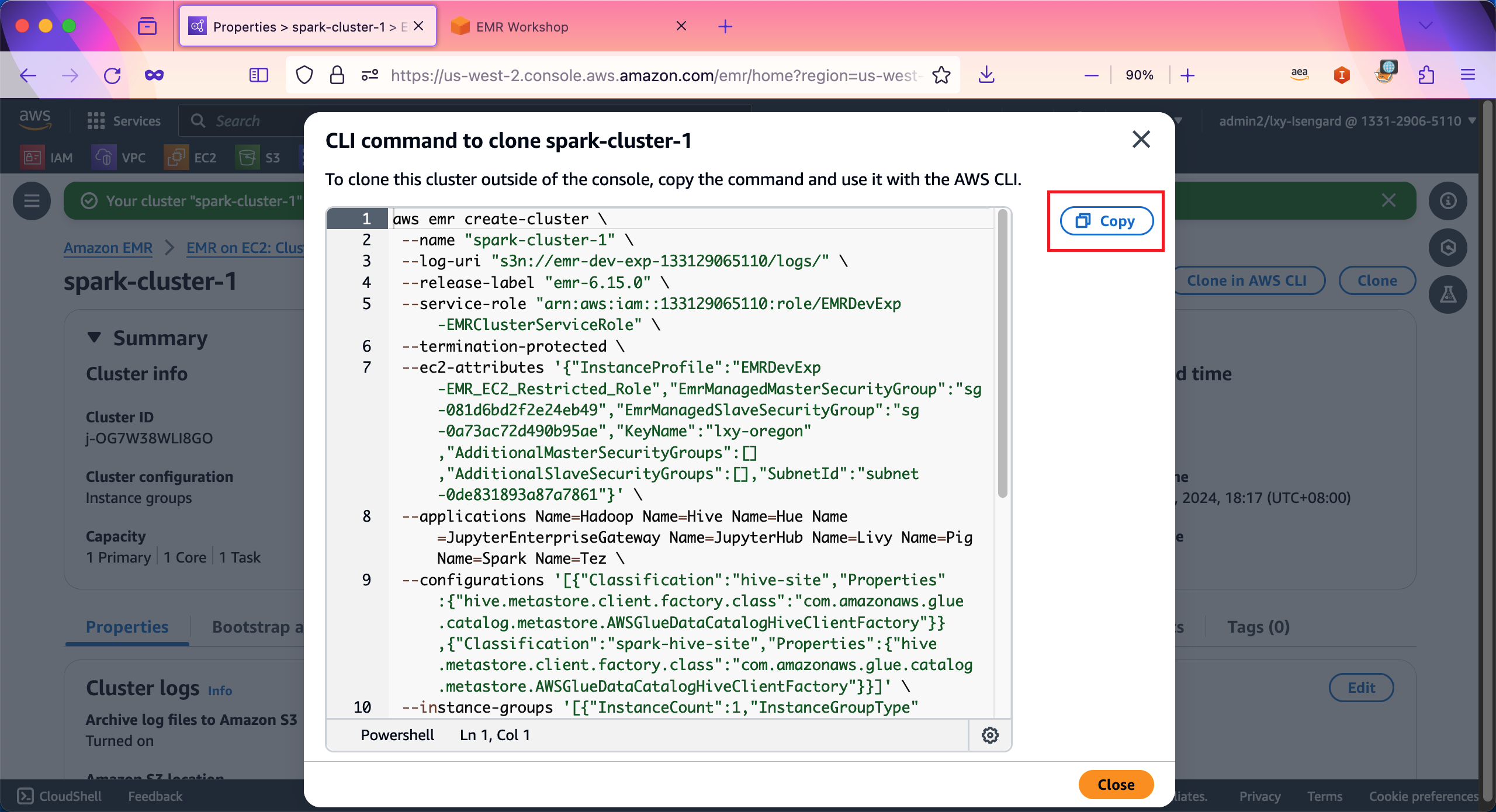
未来希望创建新的集群的时候,需要在开发者本机安装好AWSCLI,配置好Access Key/Secret Key(AK/SK),然后执行上述脚本,即可创建相同配置的集群。
使用AWSCLI创建本实验EMR集群的命令如下:(如果要复制的话,请替换里边的Account ID、S3存储桶、IAM Role等为对应的参数)
aws emr create-cluster \
--name "spark-cluster-1" \
--log-uri "s3n://emr-dev-exp-133129065110/logs/" \
--release-label "emr-6.15.0" \
--service-role "arn:aws:iam::133129065110:role/EMRDevExp-EMRClusterServiceRole" \
--termination-protected \
--ec2-attributes '{"InstanceProfile":"EMRDevExp-EMR_EC2_Restricted_Role","EmrManagedMasterSecurityGroup":"sg-081d6bd2f2e24eb49","EmrManagedSlaveSecurityGroup":"sg-0a73ac72d490b95ae","KeyName":"lxy-oregon","AdditionalMasterSecurityGroups":[],"AdditionalSlaveSecurityGroups":[],"SubnetId":"subnet-0de831893a87a7861"}' \
--applications Name=Hadoop Name=Hive Name=Hue Name=JupyterEnterpriseGateway Name=JupyterHub Name=Livy Name=Pig Name=Spark Name=Tez \
--configurations '[{"Classification":"hive-site","Properties":{"hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"}},{"Classification":"spark-hive-site","Properties":{"hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"}}]' \
--instance-groups '[{"InstanceCount":1,"InstanceGroupType":"MASTER","Name":"Primary","InstanceType":"m5.xlarge","EbsConfiguration":{"EbsBlockDeviceConfigs":[{"VolumeSpecification":{"VolumeType":"gp2","SizeInGB":32},"VolumesPerInstance":2}]}},{"InstanceCount":1,"InstanceGroupType":"CORE","Name":"Core","InstanceType":"m5.xlarge","EbsConfiguration":{"EbsBlockDeviceConfigs":[{"VolumeSpecification":{"VolumeType":"gp2","SizeInGB":32},"VolumesPerInstance":2}]}},{"InstanceCount":1,"InstanceGroupType":"TASK","Name":"Task - 1","InstanceType":"m5.xlarge","EbsConfiguration":{"EbsBlockDeviceConfigs":[{"VolumeSpecification":{"VolumeType":"gp2","SizeInGB":32},"VolumesPerInstance":2}]}}]' \
--steps '[{"Name":"step-1","ActionOnFailure":"CONTINUE","Jar":"command-runner.jar","Properties":"","Args":["spark-submit","s3://emr-dev-exp-133129065110/files/spark-etl.py","s3://emr-dev-exp-133129065110/input/","s3://emr-dev-exp-133129065110/output/step-1/"],"Type":"CUSTOM_JAR"}]' \
--auto-scaling-role "arn:aws:iam::133129065110:role/EMR_AutoScaling_DefaultRole" \
--scale-down-behavior "TERMINATE_AT_TASK_COMPLETION" \
--region "us-west-2"
注意:在界面上按下Clone in AWSCLI按钮的时候,对应的Step任务的定义也会被生成到AWSCLI上。
3、通过Session Manager登录到集群Master节点并手工提交Spark任务
本章节大概需要15分钟。
新创建好的EMR集群,可在EC2管理界面内看到数台EC2虚拟机。接下来就是登录EC2进行操作。
本实验在一开始的CloudFormation创建的实验环境就包含了EMR使用的安全规则组。CloudFormation创建的安全组屏蔽掉了通过互联网任意来源地址0.0.0.0/0登录SSH 22端口。以此作为创建好EMR集群的默认配置更有安全保证,防止因为简单密码等原因造成安全风险。
为了登录EMR的Master节点,可以采用的方法是:
- 1)修改安全规则组,在其中加入新的规则,允许来自VPC内网的EC2/Cloud9开发环境/EMR Studio等环境的登录;
- 2)使用专线从IDC/办公室连接到AWS云端VPC内,内网IP登录,或者使用堡垒机登录;
- 3)使用AWS控制台和Session Manager登录;
- 4)配置安全组放行来自互联网
0.0.0.0/0流量(不推荐)。
以上几个方法中,方法4是有安全隐患最不推荐的。在完成EMR学习的实验阶段,建议使用方法3,备选方法1。在生产环境中,建议使用方法1、2、3结合起来。下面开始登录。
进入EMR服务界面,找到刚才创建好的集群。点击名称进入。如下截图。
在页面中部的Cluster management界面中,找到Primary node public DNS的位置,下边可以看到的节点名称就是本EMR集群的Master节点。使用这个节点名字,就可以在EC2服务台中,找到对应的EC2。
要发起Session Manager登录,点击下方的Connect to Primary node using SSM的链接。如下截图。
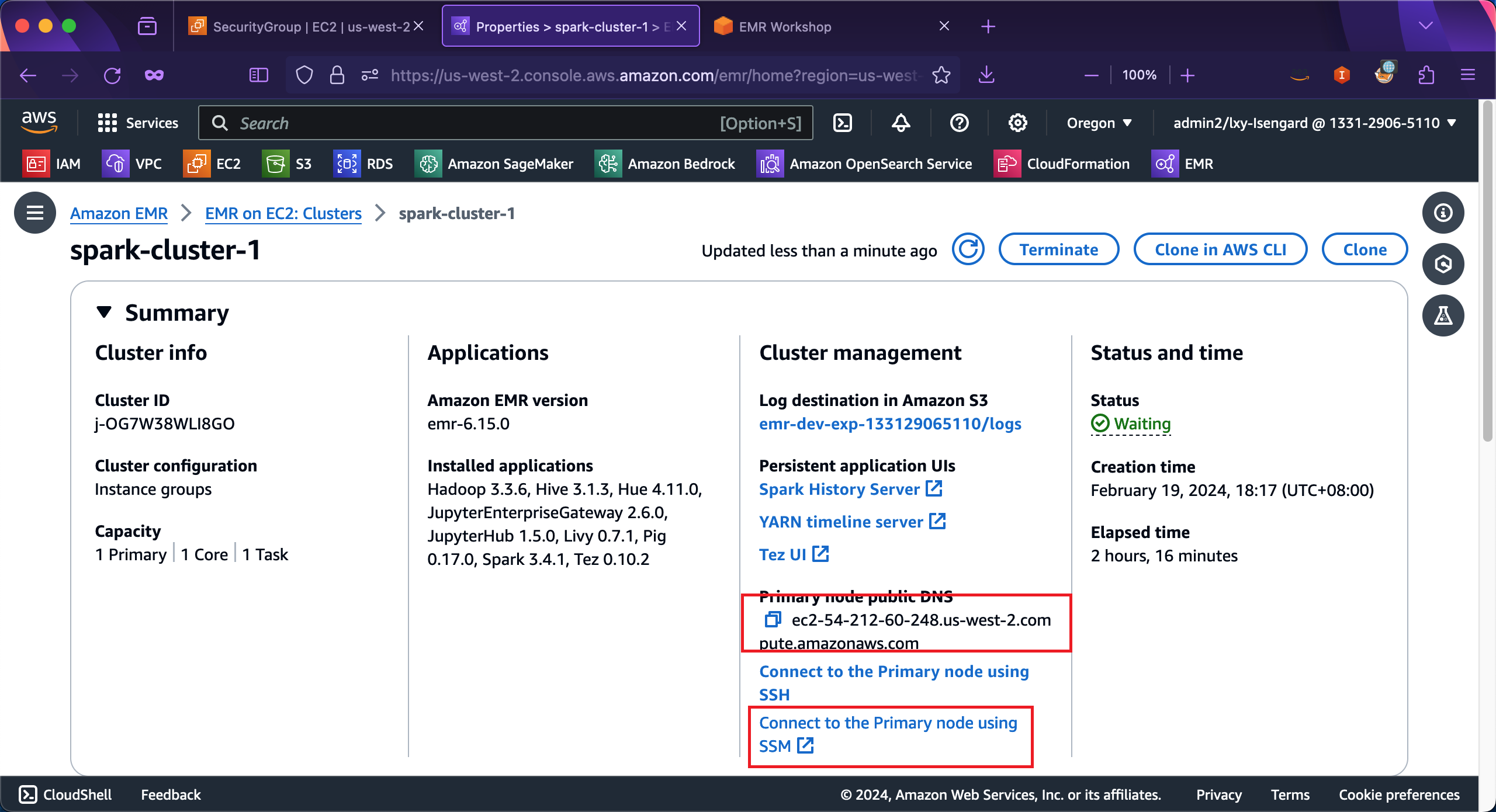
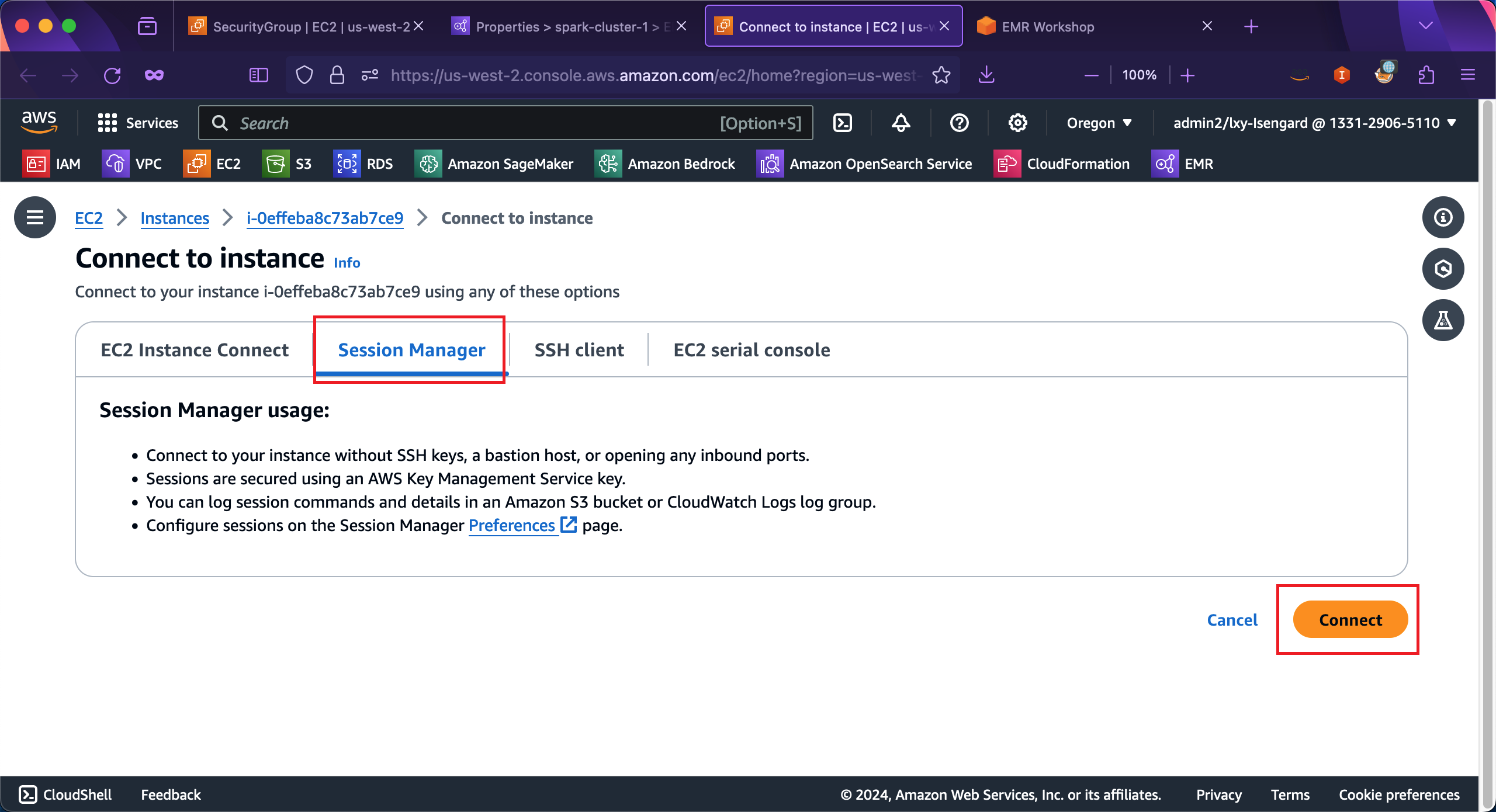
点击后跳转到EC2控制台,在连接到EC2 Instance的界面上,选择第二个标签页Session Manager,然后点击Connect完成连接。如下截图。
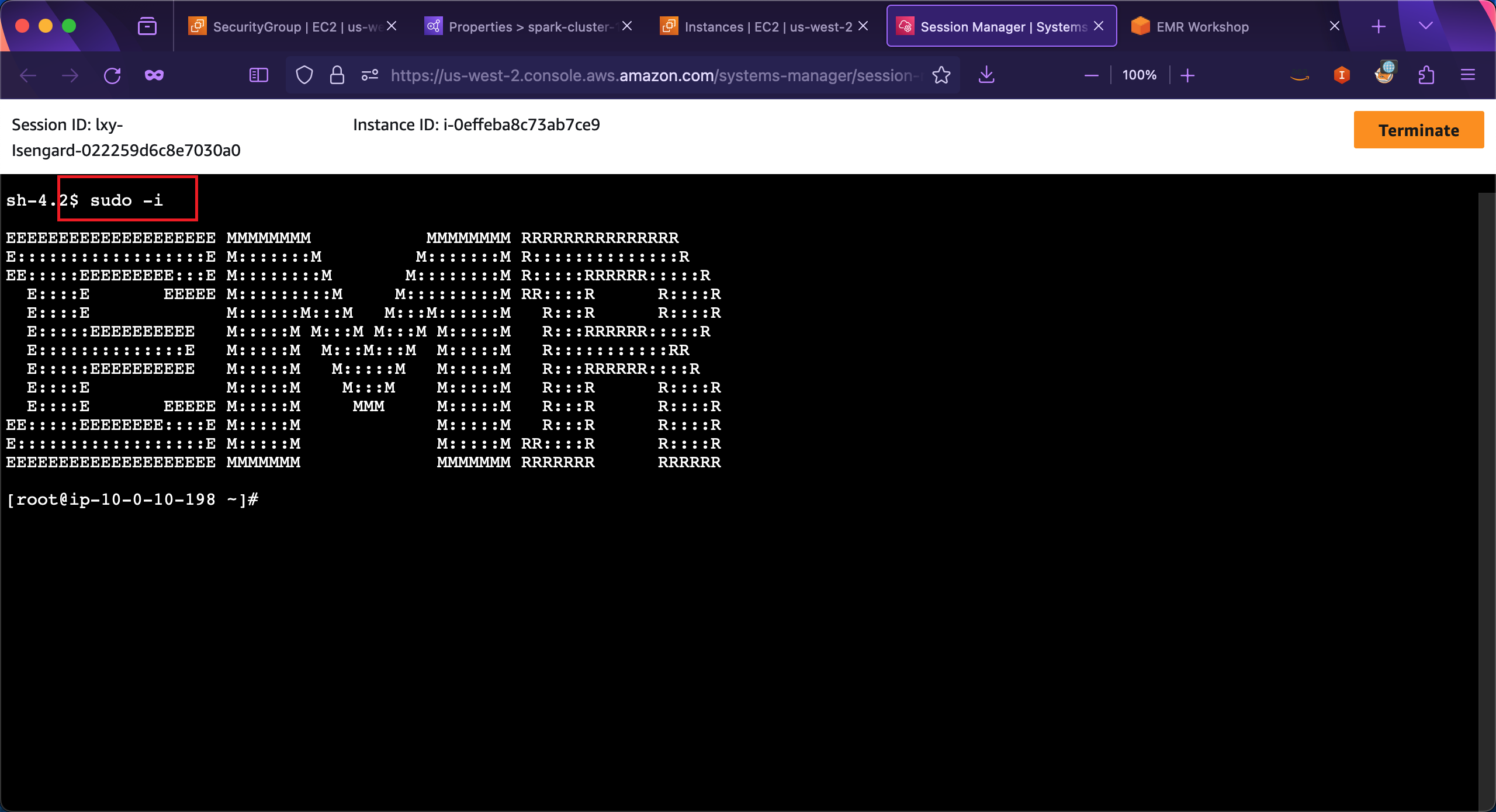
使用Session Manager登录后,shell环境不是完整的环境,可执行sudo -i,即可使用root身份加载完整的环境变量。如下截图。
现在即可开始执行程序。
通过vim编辑器输入如下一段Python代码到EMR的Master节点上。
import sys
from datetime import datetime
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
if __name__ == "__main__":
print(len(sys.argv))
if (len(sys.argv) != 3):
print("Usage: spark-etl [input-folder] [output-folder]")
sys.exit(0)
spark = SparkSession\
.builder\
.appName("SparkETL")\
.getOrCreate()
nyTaxi = spark.read.option("inferSchema", "true").option("header", "true").csv(sys.argv[1])
updatedNYTaxi = nyTaxi.withColumn("current_date", lit(datetime.now()))
updatedNYTaxi.printSchema()
print(updatedNYTaxi.show())
print("Total number of records: " + str(updatedNYTaxi.count()))
updatedNYTaxi.write.format("parquet").mode("overwrite").save(sys.argv[2])
将以上代码保存为spark-etl.py,并保存在Master节点的/root/目录下。这段代码的作用是,调用Spark,从指定的作为输入源的S3存储桶中读取csv格式的文件,并新增一列名为current_date,其数值是当前时刻数据,最后以Parquet列格式存储,保存到S3存储桶的Output路径中。
执行如下命令,请替换<YOUR-BUCKET>为本文一开始CloudFormation创建的S3存储桶,也就是前几个步骤上传测试数据的存储桶。替换完成后,运行这段代码:
spark-submit spark-etl.py s3://<YOUR-BUCKET>/input/ s3://<YOUR-BUCKET>/output/spark-etl/
运行完毕,返回结果如下截图。
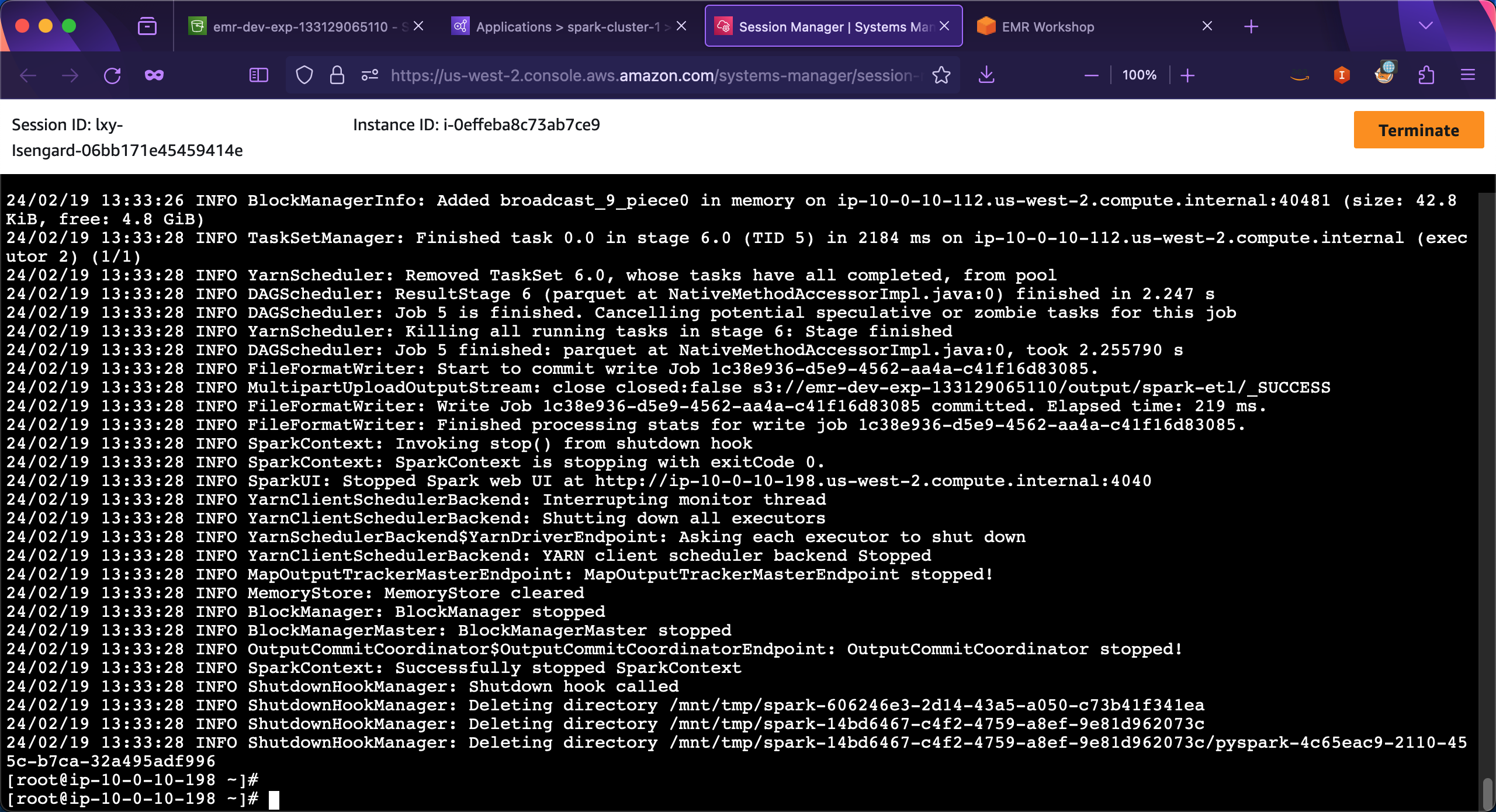
现在检查对应的S3存储桶下的output/spark-etl目录,即可看到名为part-00000-ed9743f2-065e-436d-b9dd-f51e45ee6add-c000.snappy.parquet的文件已经生成。
由此可以看到,通过EMR Master节点提交Spark任务成功。
4、通过EMR控制台查看集群运行情况
本章节大概需要5分钟。
进入EMR集群界面,在页面中部的Cluster management界面的下方Persistent application UIs位置下,有Spark History Server和YARN timeline server的入口。鼠标左键点击这个链接,即可在当前浏览器打开新的标签页,进入Spark History和YARN界面,查看资源。如下截图。
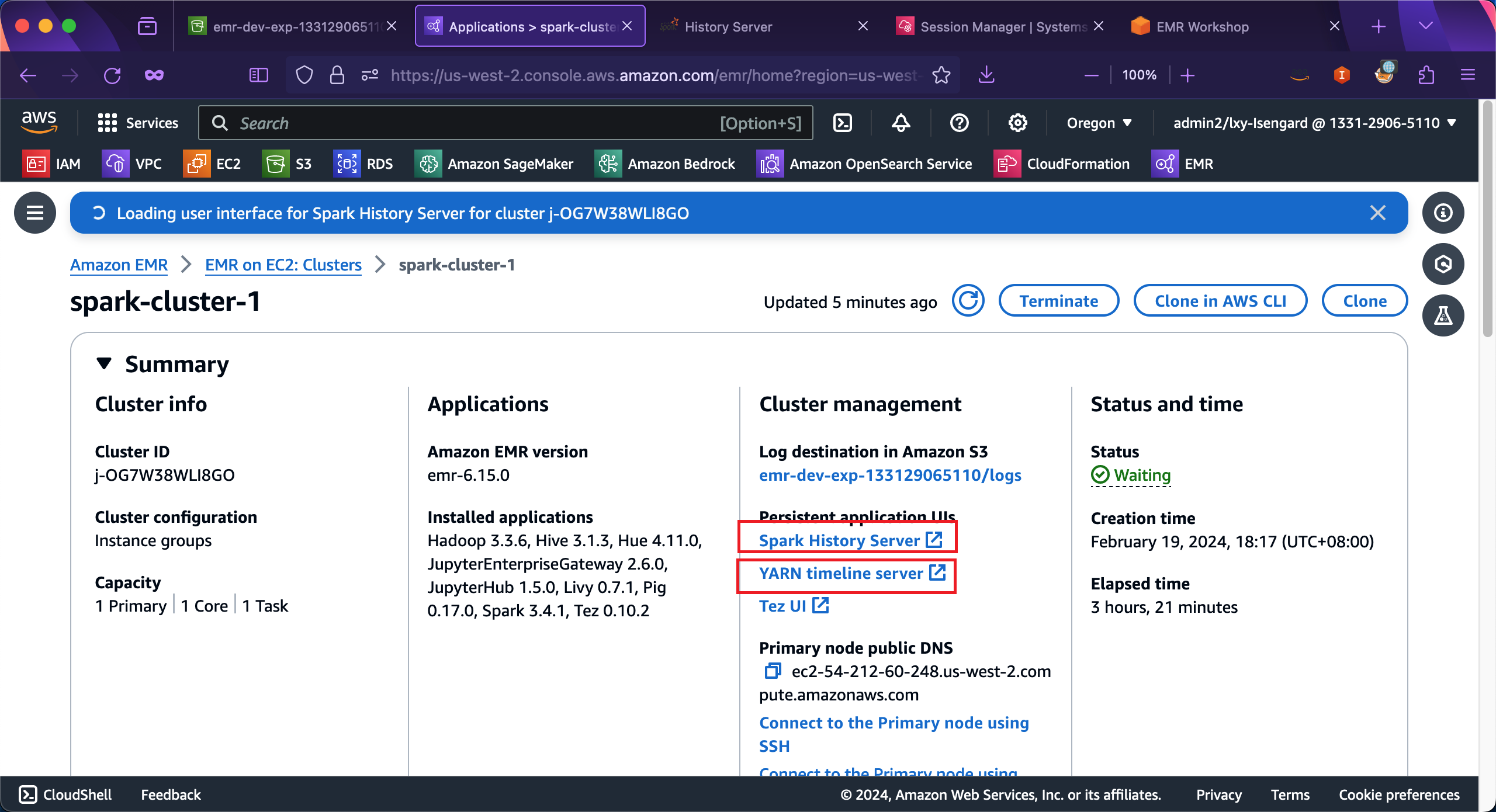
进入Spark History效果如下,可看到上一步在Master节点上使用spark-etl.py脚本发起的任务。如下截图。
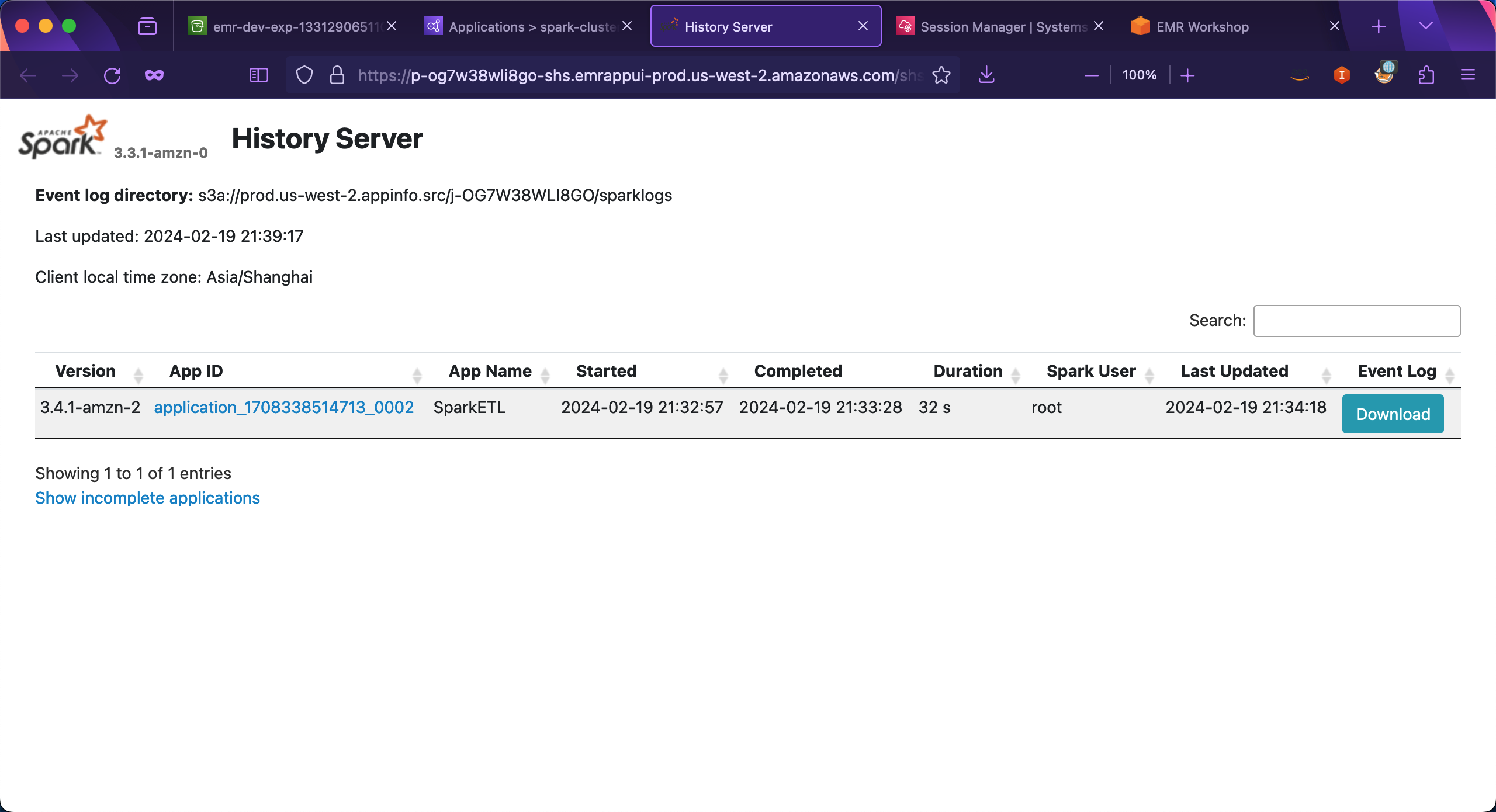
进入YARN资源管理器界面。如下截图。
需要注意的是,在EMR控制台上点击打开Spark History和YARN这两个界面,都是不需要额外添加安全组的,也不需要额外配置安全身份认证,这两个界面的安全防护都是通过特殊的Endpoint入口,映射到EMR集群后对外提供访问的。此外,这个登录也包含了浏览器Session的安全,仅仅将浏览器地址栏上显示的地址复制出来放到其他浏览器或者其他电脑,是不能访问的。因此无需担心这两个界面的跳转和映射安全问题。
至此第一个EMR集群就已经工作起来了。
四、使用EMR Step功能、EMR Studio提交任务和交互式开发
除了使用SSH登录到EMR的Master节点上执行任务之外,还可以通过
1、通过EMR Step功能提交任务
本章节大概需要15分钟。
EMR的Step功能可以进行多个任务编排,支持提交基于Spark、Hive、Pig、Streaming、Java、Shell等脚本的任务。处于运行和等待状态的Step总和的最大限制是256。对于长时间运行的Spark集群,那么在当前一批任务计算完毕后,可以继续提交新的任务,只要运行和排队的总任务在当前时刻不超过256即可。
为了提交Step任务,将上一个实验在Master节点上执行的spark-etl.py脚本,保存下载,并上传到S3存储桶的files目录下,也就是s3://emr-dev-exp-133129065110/file/spark-etl.py。下一步的Step将调用这个脚本。
进入EMR集群,找到Step标签页,点击添加按钮。如下截图。
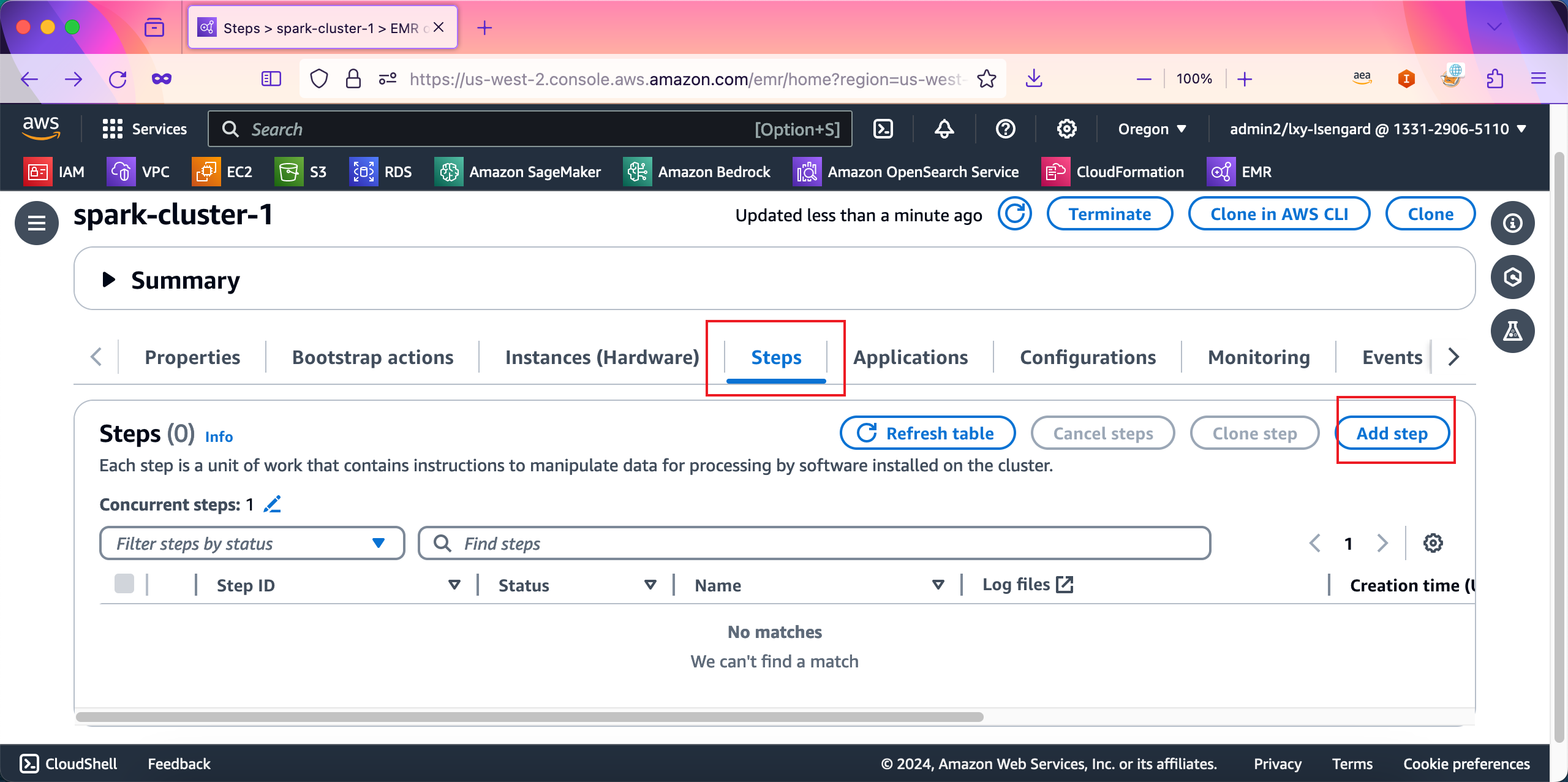
在添加Step界面中,选择第一个类型Custom JAR,在Name位置填写名称例如Step-1。然后继续向下滚动屏幕。如下截图。
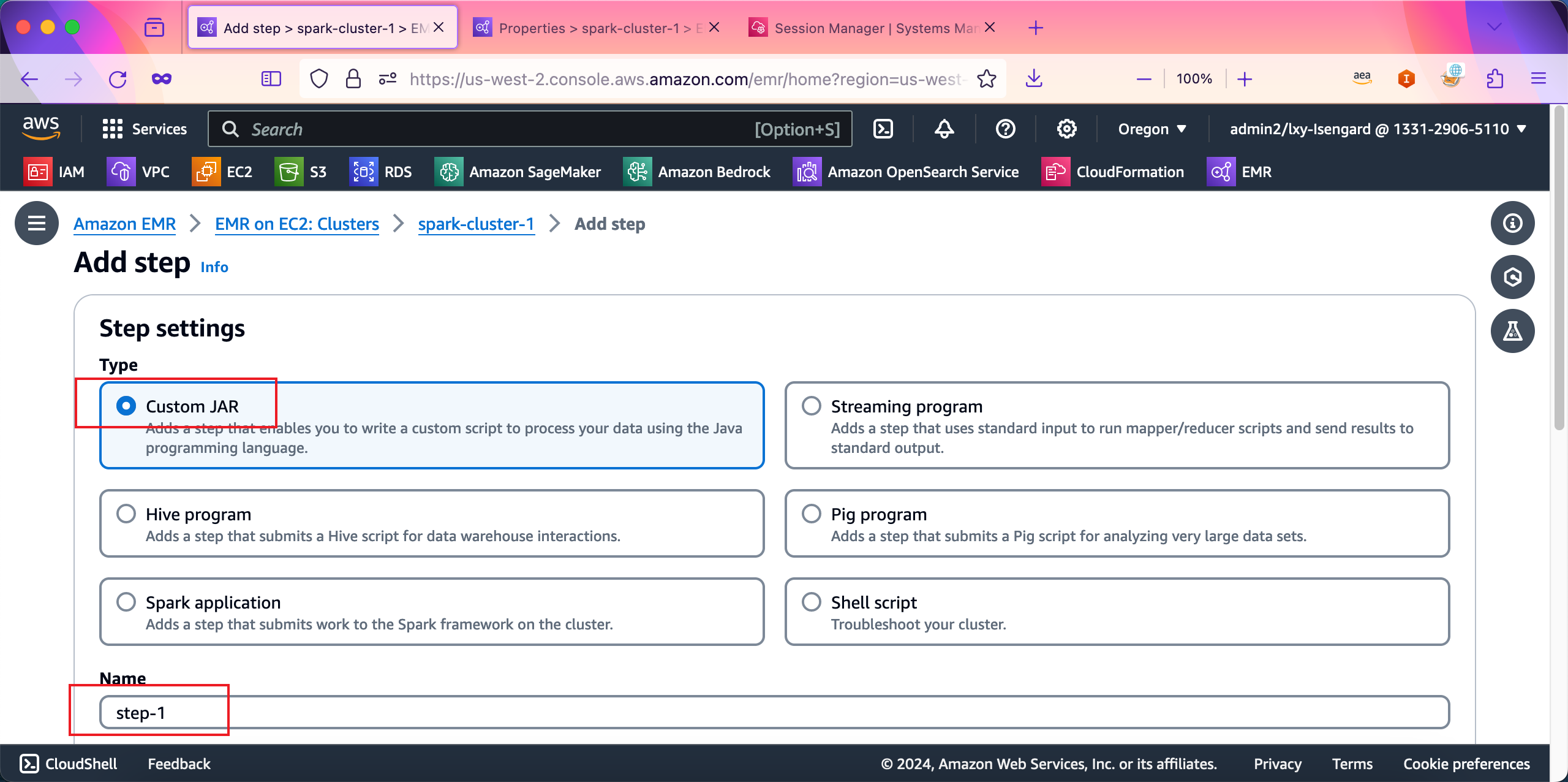
在Step的详细配置中,在Jar location位置,填写command-runner.jar,在Arguments位置,填写如下命令:
spark-submit s3://emr-dev-exp-133129065110/files/spark-etl.py s3://emr-dev-exp-133129065110/input/ s3://emr-dev-exp-133129065110/output/step-1/
注意这条命令与在Master节点上直接启动任务相比,主要是任务脚本所在的路径的不同。在Master节点上启动任务时候是在本地磁盘,通过Step启动任务时候,给出的脚本路径是S3路径。在Step action位置,在Action if step fails位置,设置为Continue。最后点击右下角的按钮提交任务。如下截图。
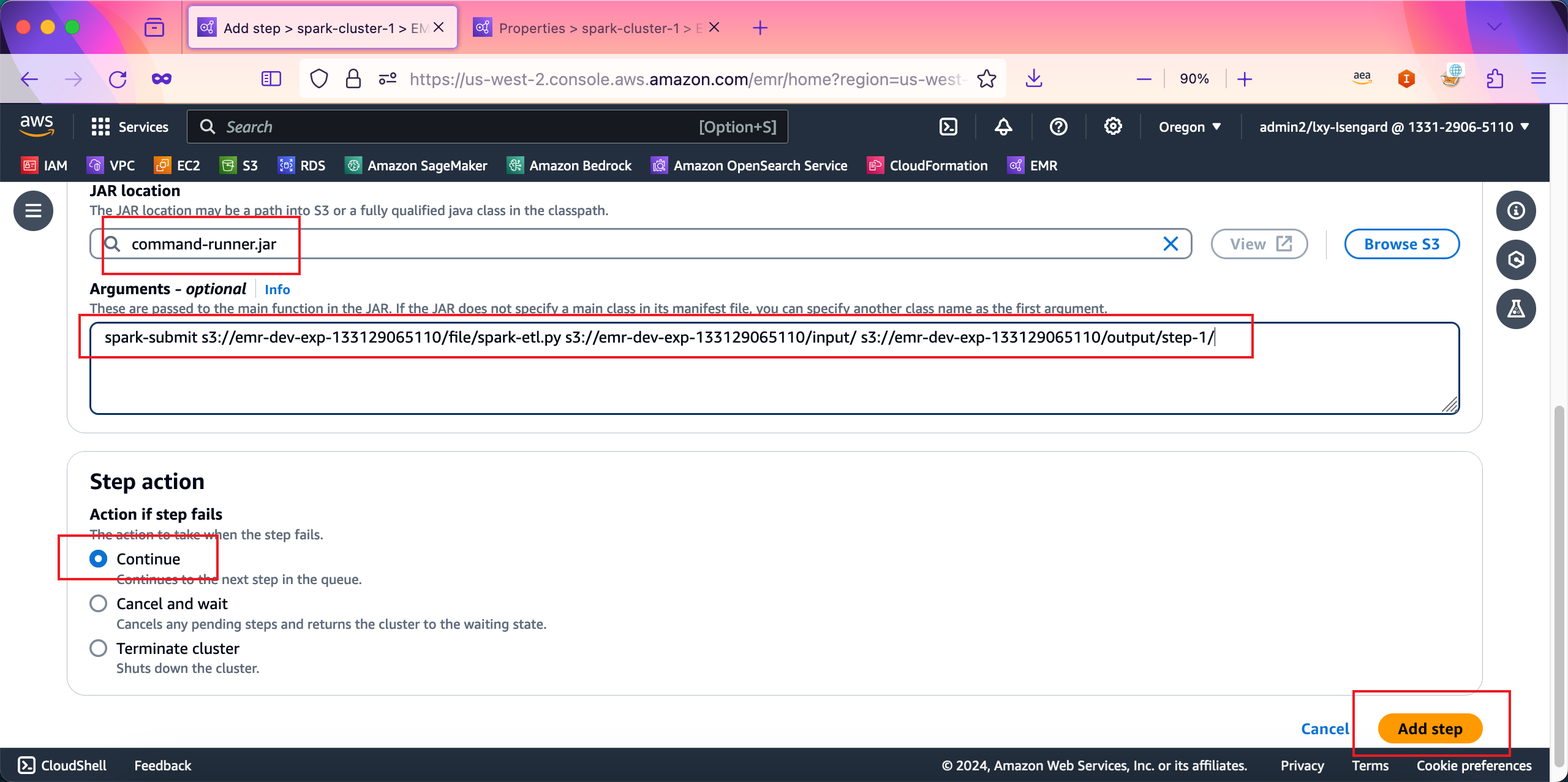
提交任务后,可以看到任务进行中。右侧还可以看到执行日志。不过需要注意的是,只有任务完成(包括成功/失败)之后,日志才会被取回。如下截图。
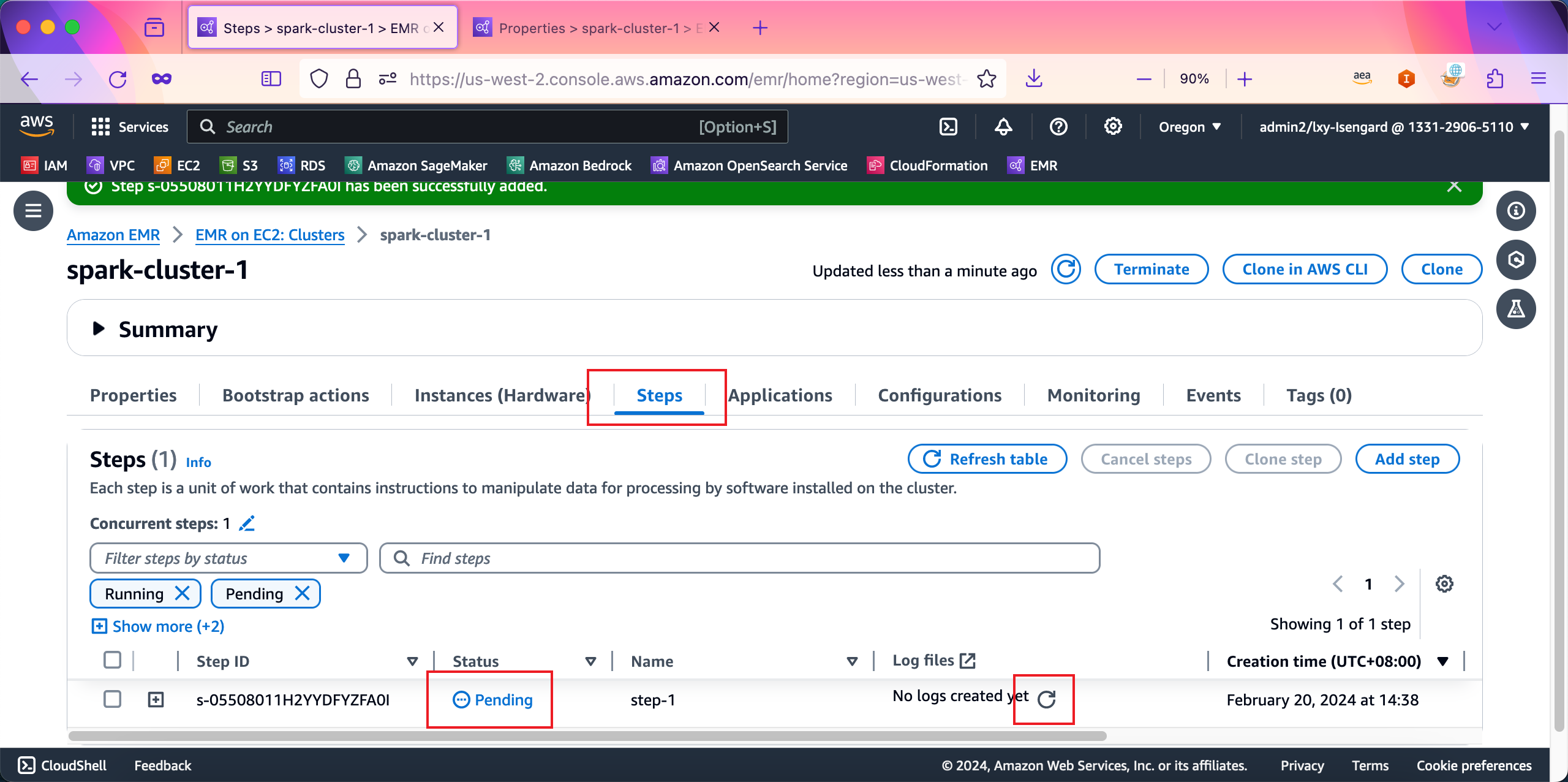
任务成功,且日志取回这里也显示出来了。如下截图。
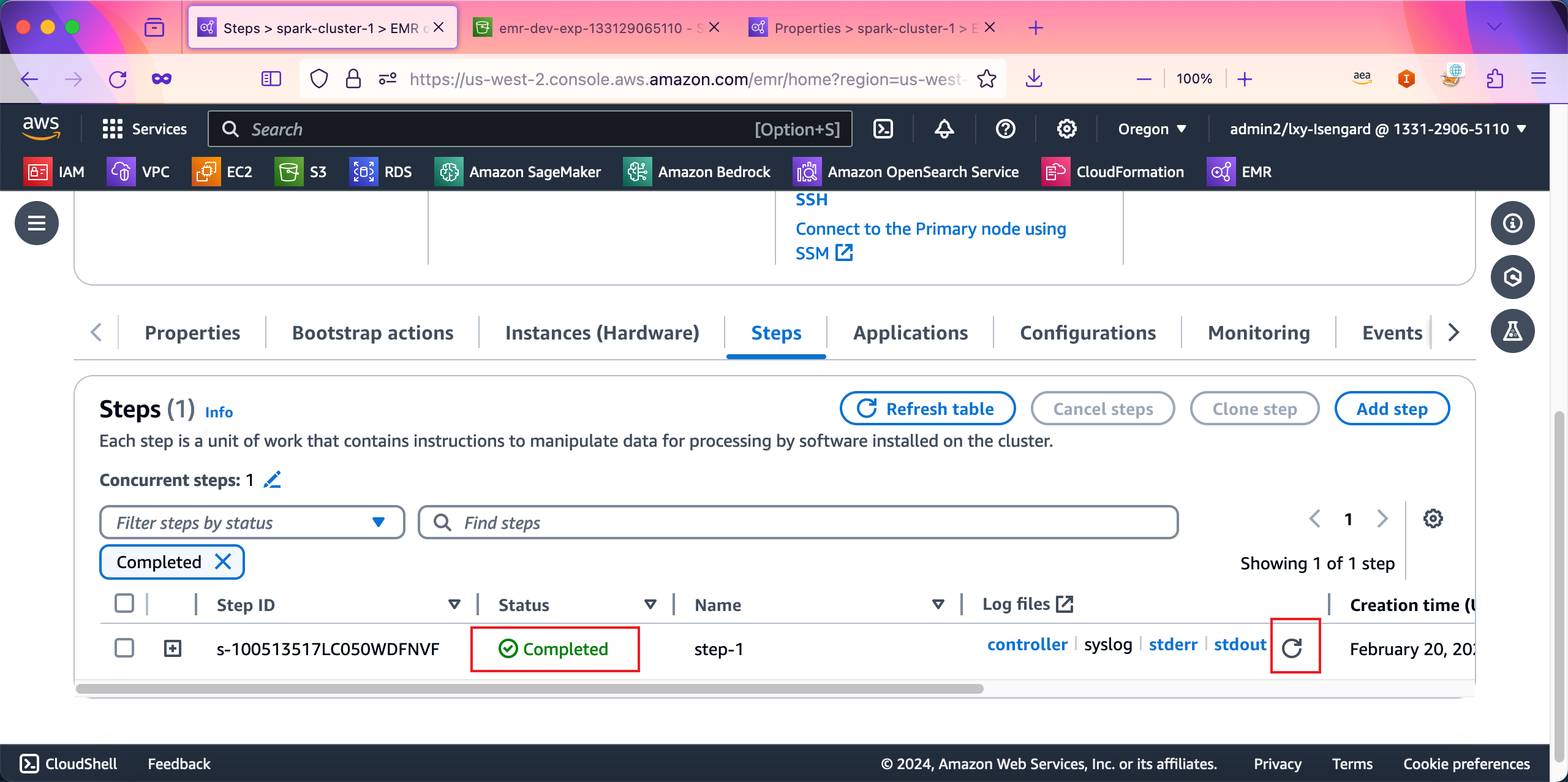
在日志位置点击stdout,即可看到输出日志。如下截图。
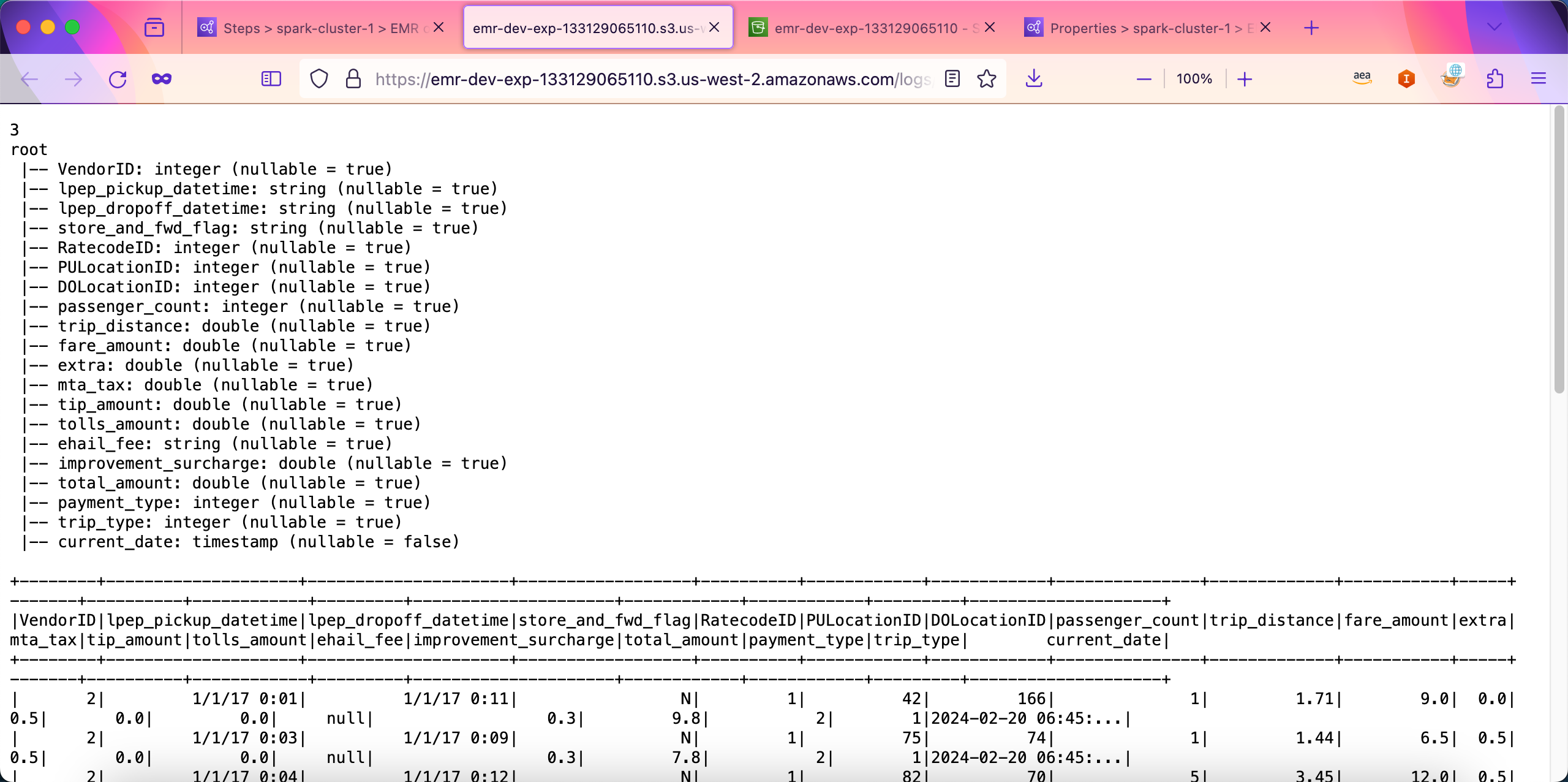
至此使用EMR Step运行Spark任务的实验完成。
2、使用EMR Studio的Notebook进行交互式开发
本章节大概需要15分钟。
上文介绍的使用EMR Step提交计算任务,是无需登录集群,通过AWS控制台或者API调用即可完成的计算任务下发。除此以外,如果希望进行交互式开发,那么可以使用EMR Studio提供的Notebook进行交互式操作。
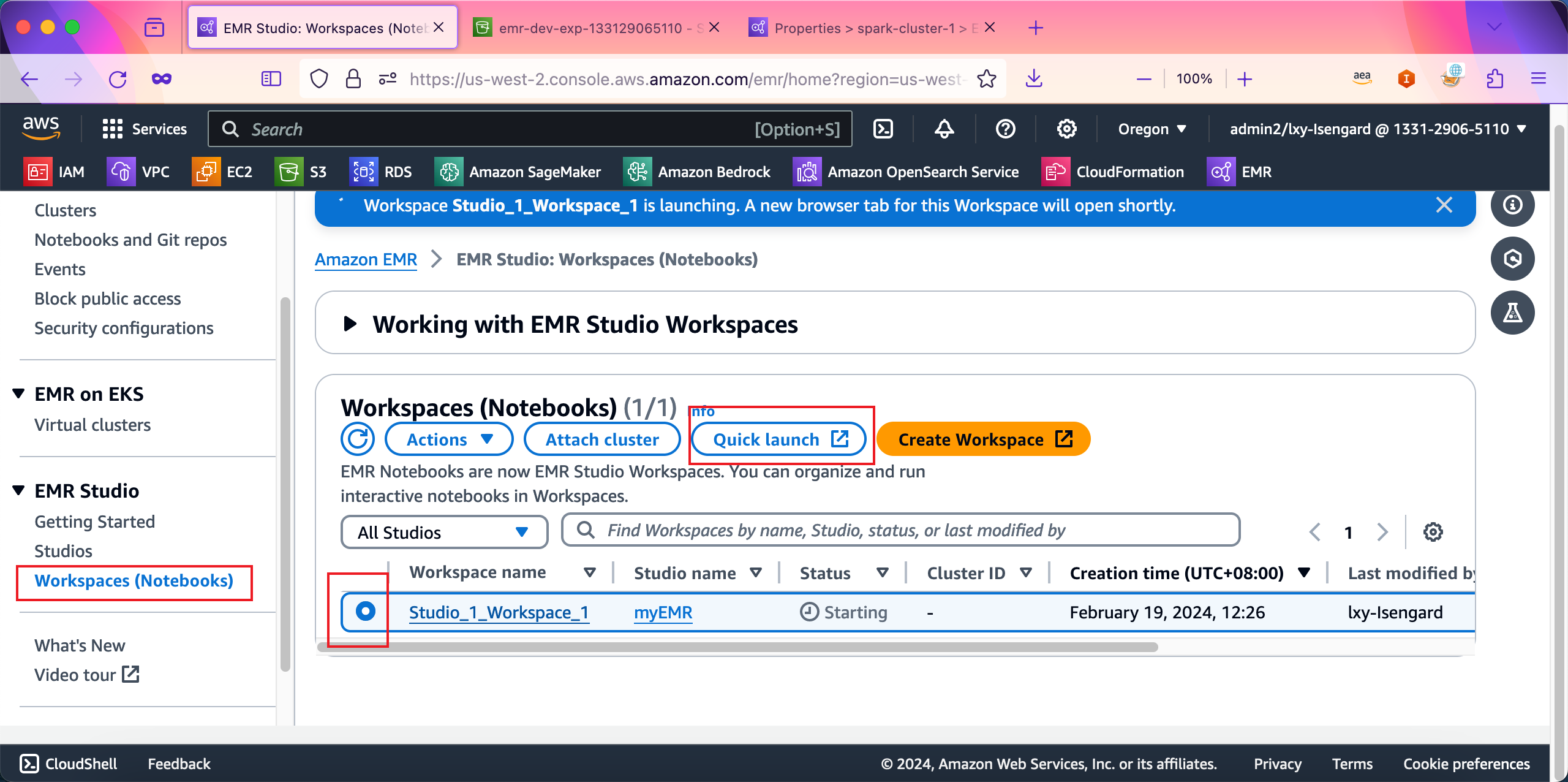
登录到EMR控制台,在左下角找到EMR Studio,点击Workspace(Notebooks),然后在右侧选中本实验一开始时候随EMR Studio自动创建出来的Workspace。点击上方按钮Quick launch即可启动。如下截图。
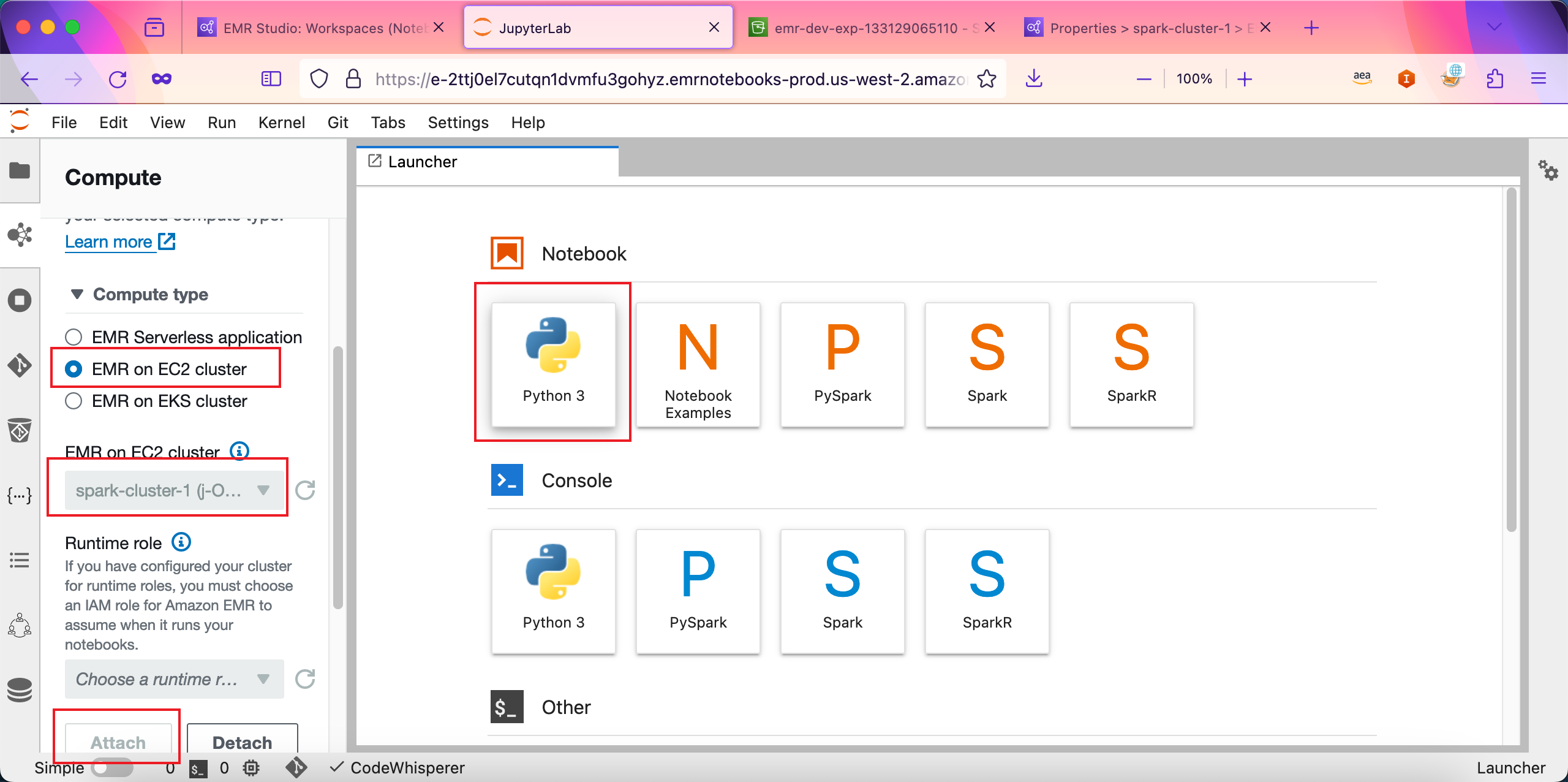
登录到Notebook页面,在左下角找到EMR Studio,在Compute type下选择EMR on EC2,在Runtime role位置,留空,不用原则,然后点击下方的Attach按钮。如下截图。
现在即可登录到Notebook内。
点击上传按钮,可将如下两个Notebook文件上传。下载链接 Lab-01,Lab-02。如下截图。如下截图。
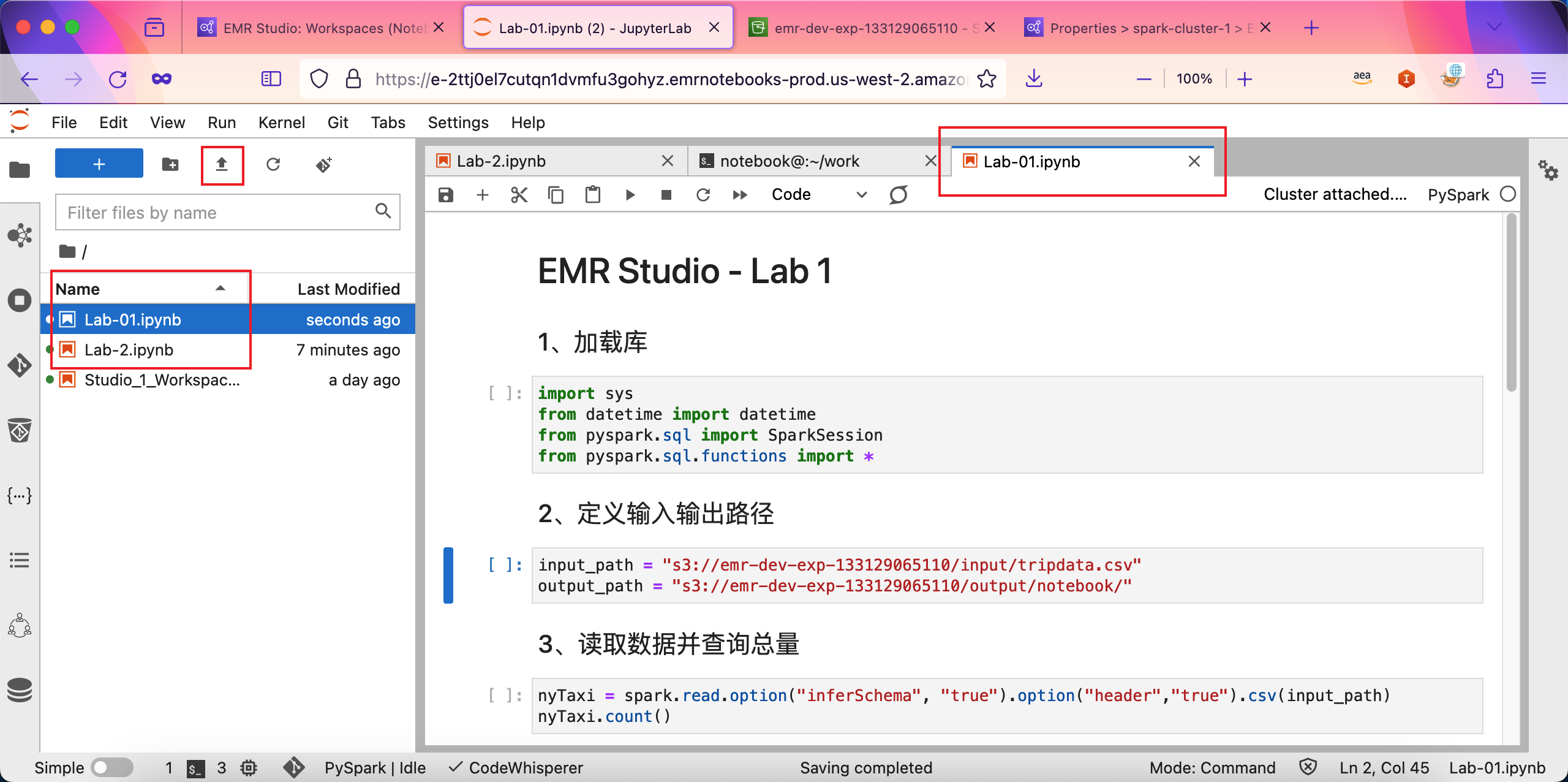
上传完毕后,可在Notebook上执行任务成功。如下截图。
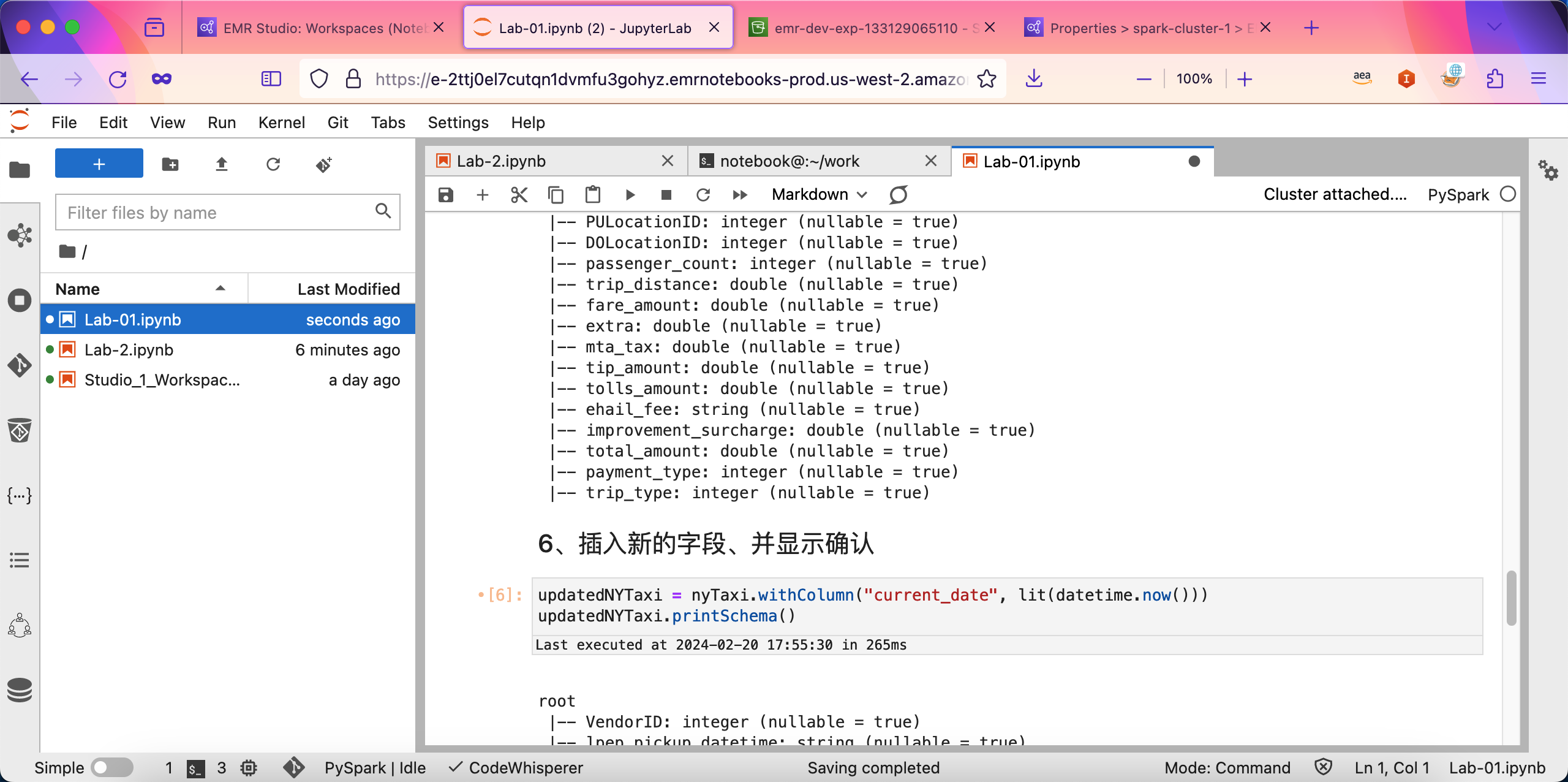
由此可看到,EMR Studio提供的Notebook可以带来很好的交互式操作体验。
至此本文上篇完。
点击这里跳转到本文下篇。
五、参考资料
ETL on Amazon EMR Workshop (英文)
https://catalog.us-east-1.prod.workshops.aws/workshops/c86bd131-f6bf-4e8f-b798-58fd450d3c44/en-US
最后修改于 2024-02-27