EMR 101 Workshop 中文版(下篇)
深入学习EMR数据分析实战:通过Hive、Presto、Glue等工具处理纽约出租车数据,解决大规模数据查询和可视化挑战,掌握云端数据仓库完整工作流。
因篇幅所限和单次实验时间所限,本文拆成上下两篇且只包含Spark/Hive/Presto。HBase、Iceberg、Hudi等将另外编写。
点击这里跳转到上篇:EMR 101 Workshop 中文版(上篇)
接上篇,继续使用上篇执行Spark任务的集群来完成实验。因篇幅所限和单次实验时间所限,本篇只写Spark/Hive/Presto,不包含HBase、Iceberg、Hudi等。
一、在现有EMR集群上运行Hive
Hive是运行在Hadoop上的开源数据仓库。Hive使用类似SQL的查询语言HQL。在EMR上运行的Hive,与自行搭建的开源Hadoop上的Hive稍有不同,主要几个差异包括但不限于:
- EMR 支持使用外部metastore,包括AWS Glue Data Catalog(要求EMR>5.8)以及RDS/Aurora MySQL数据库
- EMR 5.x起的Hive默认直接使用S3读、写(包括临时文件),而不是在HDFS上
- EMR 5.x起,Hive可使用Tez作为执行引擎
- EMR 6.10起的Hive支持ACID一致性
Hive和EMR版本的对应关系,可以在官方文档这里查询。例如EMR 6.1.5包含的Hive版本是3.1.3,EMR 5.36.1版本包含的Hive是2.3.9。
Hive任务可以通过登录到EMR的Master节点,使用交互式命令行的方式提交,也可以通过EMR Step提交Hive任务。下边分别进行两种方式提交计算任务。
1、使用命令行登录EMR集群Master节点执行Hive查询
登录到EMR控制台,点击Connect to the Primary node using SSM按钮,即可通过Session Manager登录到Master节点。如下截图。
在弹出的Session Manager登录窗口中,点击Connect按钮即可登录到SSH。如下截图。
在SSH窗口内,输入sudo -i可以用root身份运行。输入hive命令,可启动Hive。如下截图。
现在,基于上一篇实验使用的数据素材,之前已经上传到S3存储桶内,目录位置在s3://emr-dev-exp-123456789012/input/tripdata.csv,其中12位数字是本AWS账户的ID。我们将这个网址代入到如下SQL(HQL)代码的最后一段。
执行如下代码:
CREATE EXTERNAL TABLE ny_taxi_test (
vendor_id int,
lpep_pickup_datetime string,
lpep_dropoff_datetime string,
store_and_fwd_flag string,
rate_code_id smallint,
pu_location_id int,
do_location_id int,
passenger_count int,
trip_distance double,
fare_amount double,
mta_tax double,
tip_amount double,
tolls_amount double,
ehail_fee double,
improvement_surcharge double,
total_amount double,
payment_type smallint,
trip_type smallint
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION "s3://emr-dev-exp-133129065110/input/";
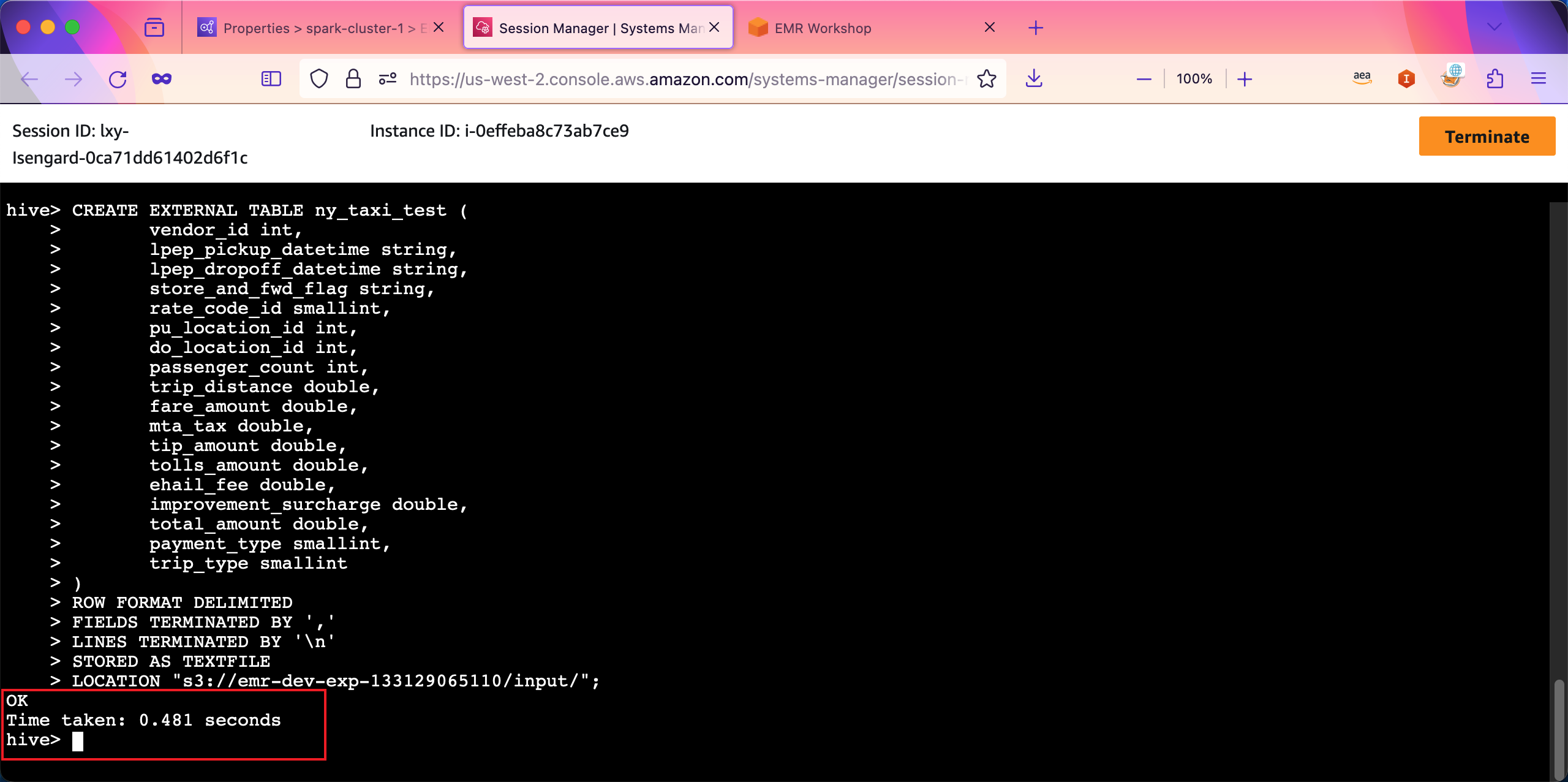
创建表结构执行成功。如下截图。。
接下来执行查询。
select SUM(total_amount), SUM(trip_distance) from ny_taxi_test;
返回结果如下截图。
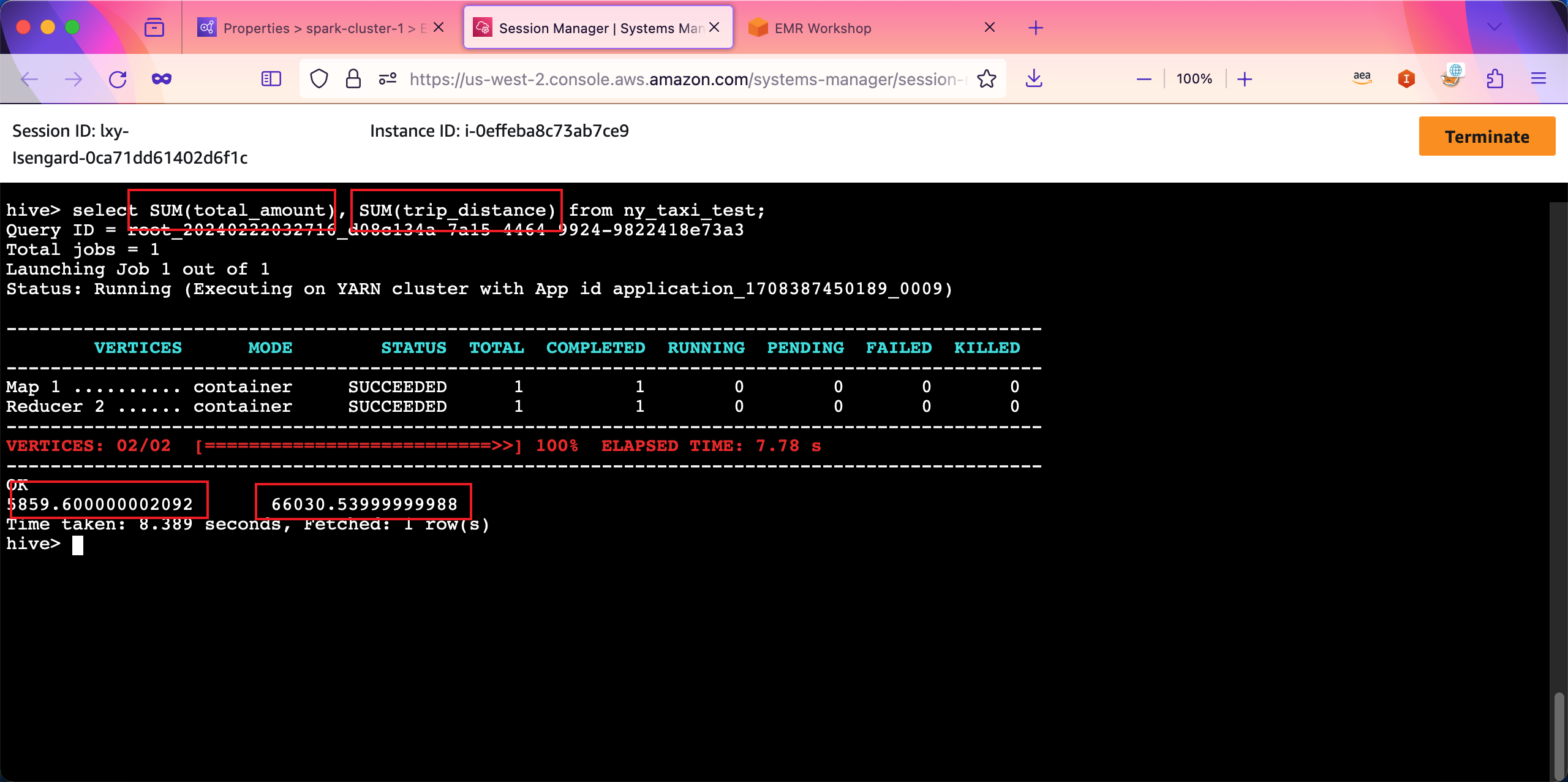
由此可看到以交互方式的Hive运行正常。
2、使用EMR Steps提交Hive任务
在之前的实验中,使用了SSH登录到EMR Master节点的控制台来执行Hive交互式命令的方式。接下来使用EMR Steps以非交互的方式提交Hive任务到集群,完成计算,并将结果写入S3。用于测试的原始数据和上一步使用的文件相同。
首先准备如下一段SQL(HQL)代码。
-- remove existing table
DROP TABLE IF EXISTS ny_taxi;
-- 创建表(注意与上一个实验使用的表名不同)
CREATE EXTERNAL TABLE ny_taxi (
vendor_id int,
lpep_pickup_datetime string,
lpep_dropoff_datetime string,
store_and_fwd_flag string,
rate_code_id smallint,
pu_location_id int,
do_location_id int,
passenger_count int,
trip_distance double,
fare_amount double,
mta_tax double,
tip_amount double,
tolls_amount double,
ehail_fee double,
improvement_surcharge double,
total_amount double,
payment_type smallint,
trip_type smallint
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION "${INPUT}";
-- submit your query
INSERT OVERWRITE DIRECTORY "${OUTPUT}"
SELECT * FROM ny_taxi WHERE rate_code_id = 1;
将以上的脚本保存为ny-taxi.hql,并保存在存储桶的files目录下。完整路径是s3://emr-dev-exp-133129065110/files/ny-taxi.hql的目录下,其中12位数字是本AWS账户的ID。
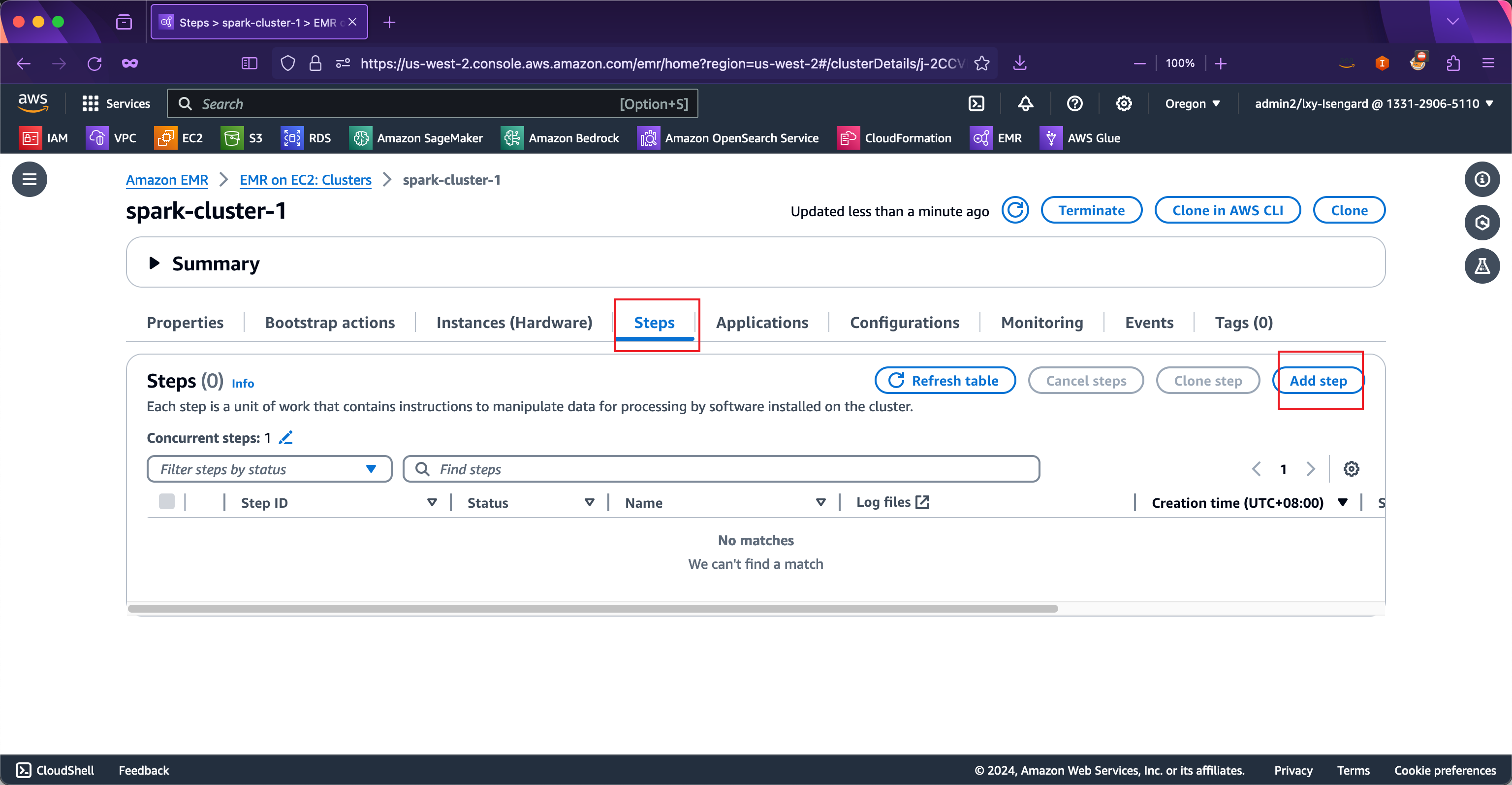
现在进入EMR集群,进入Steps标签页,点击Add step按钮录入新的任务。如下截图。
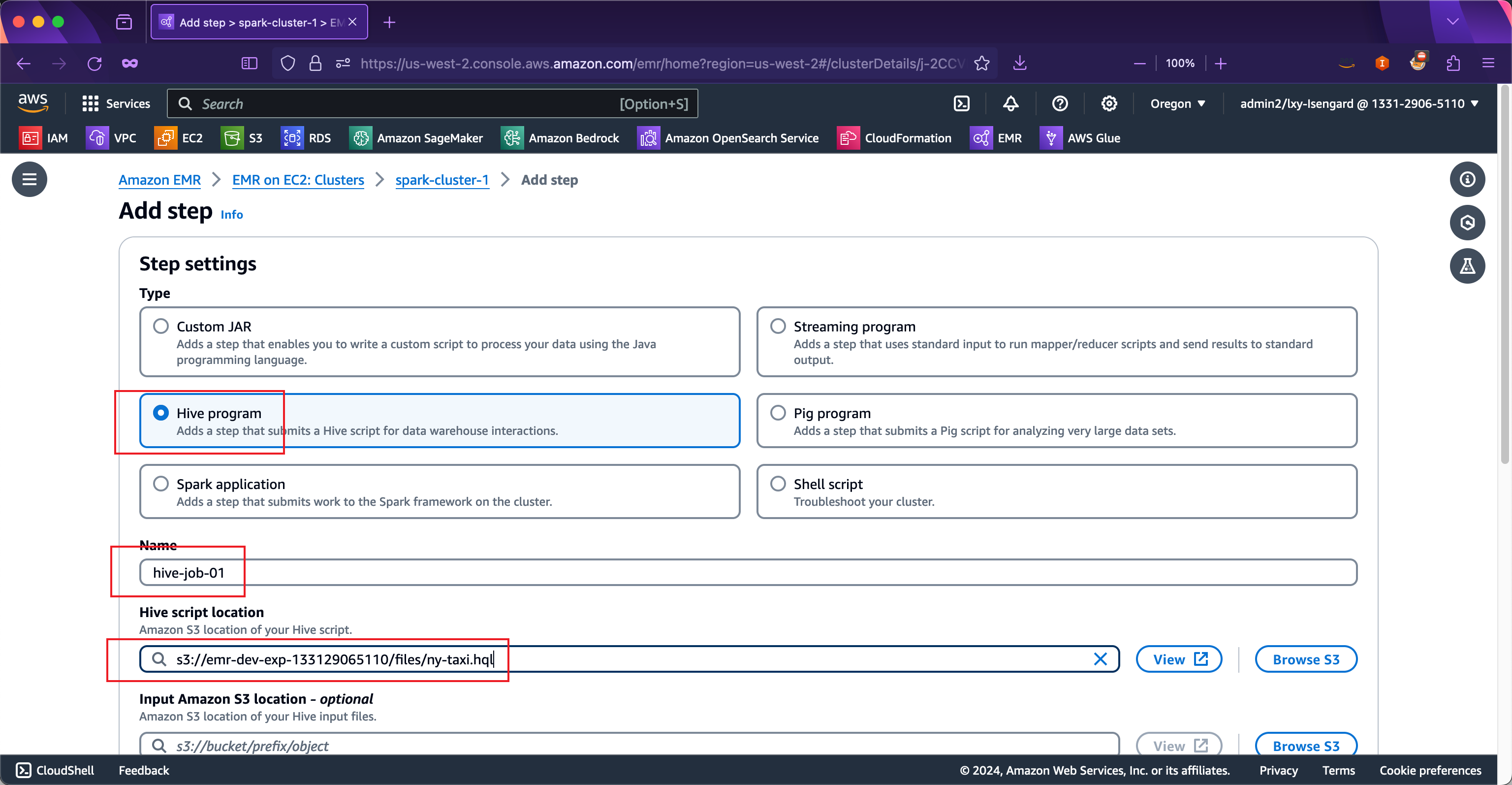
在Steps设置中,选择Type类型是Hive任务,在Name位置输入本任务的名称,在Hive script location位置填写上一步上传的Hive任务脚本在S3的全路径。如下截图。
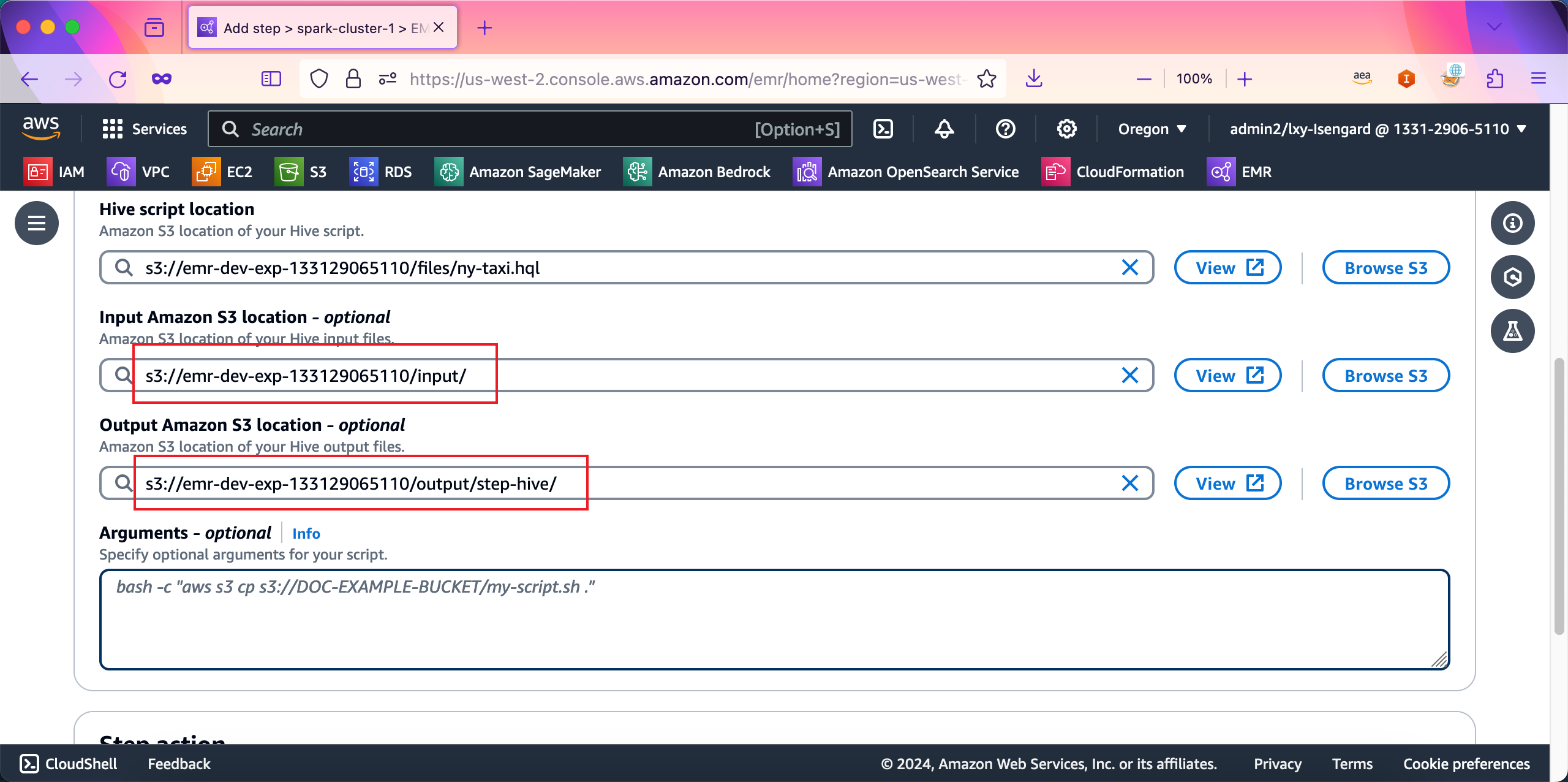
接下来继续向下移动屏幕。在Input Amazon S3 location位置输入数据源的S3存储桶地址,例如本例中是s3://emr-dev-exp-133129065110/input/;在Output Amazon S3 location位置输入数据处理后的目录,在本例中是s3://emr-dev-exp-133129065110/output/step-hive/。如下截图。
在向导最后的位置,Step action选项选择Continue表示任务运行完毕后,不会停止集群,EMR集群将继续保留下长时运行。最后点击Add step按钮提交任务。如下截图。
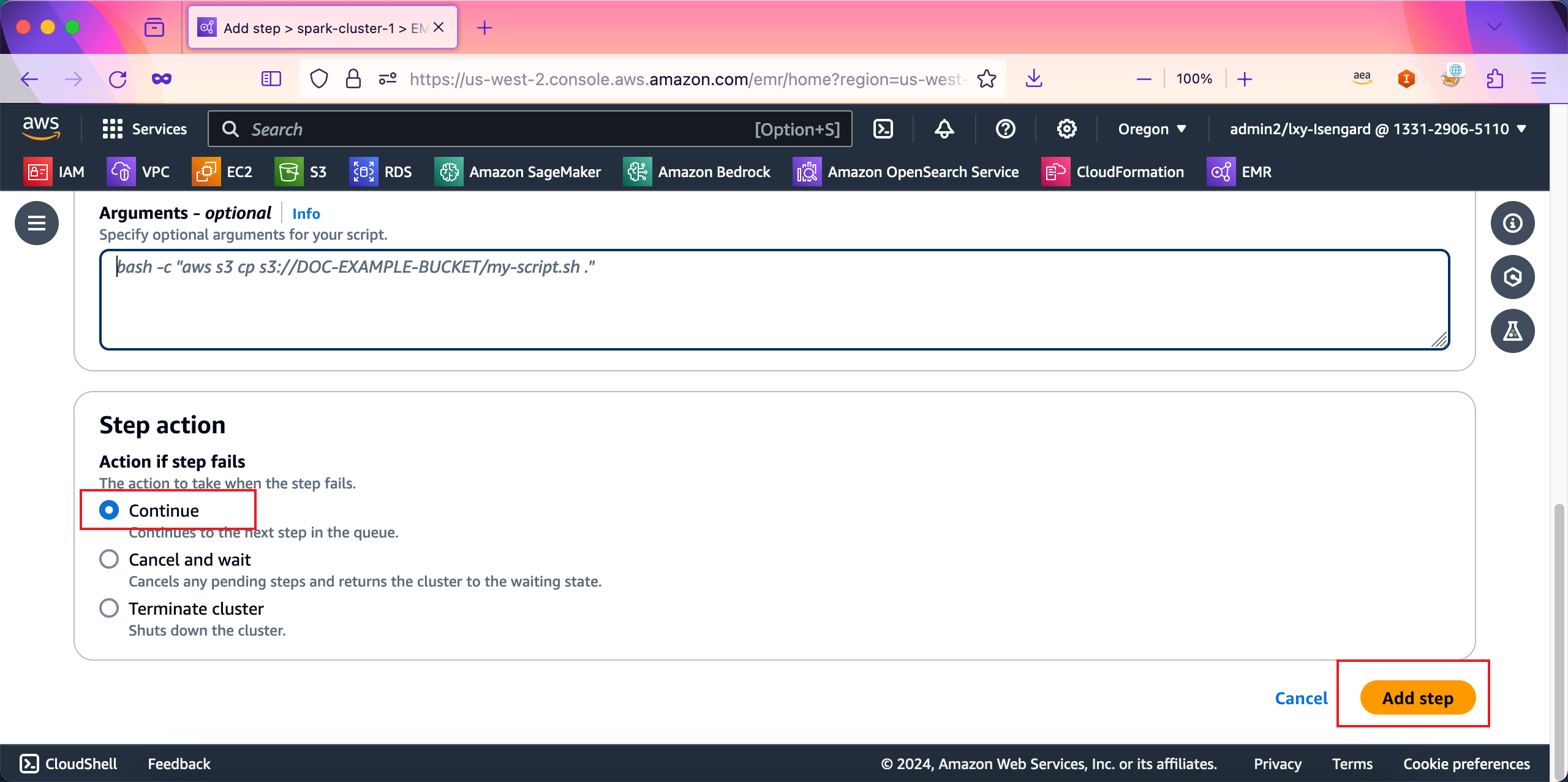
任务提交成功,页面上也会提示任务已经启动,状态显示为Pending。在任务运行完毕后,日志也会被取回来显示在控制台上。如下截图。
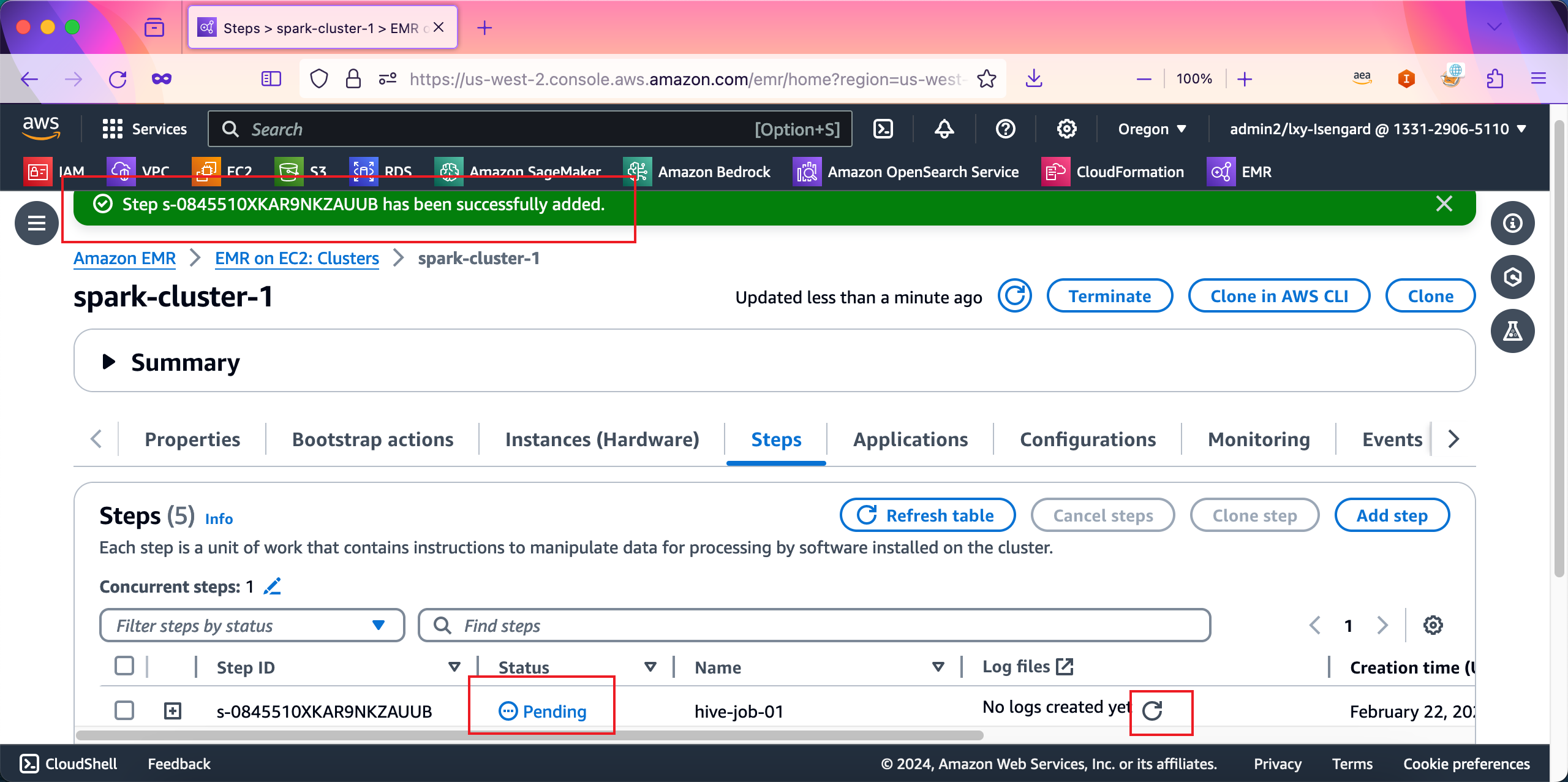
稍等1分钟左右,任务运行完毕。
通过以上实验可以看到,如果要操作的数据量较大,任务是长时间任务,那么可以不登录SSH,而是通过控制台下发EMR Steps来执行Hive任务。EMR Steps除了能通过AWS控制台下发之外,还可以通过CLI等多种方式来下发。
二、创建新集群并使用Presto
在本实验中,将构建一个全新的EMR集群,以S3数据湖为核心,使用Glue做元数据管理,使用Presto/Hue来运行查询任务。
1、Glue数据目录的准备
本例中使用的是一个公开数据集,路径是s3://serverless-analytics/NYC-transportation/,任何AWS账户均可直接操作,本实验可以直接在这个数据集上操作。
如果希望将数据集复制到当前AWS账户的S3存储桶内,那么需要使用AWSCLI工具,并提前设置好Access Key/Secret Key(AKSK)并具有S3写入权限,才可以进行复制。复制命令如下,从原始数据所在的桶serverless-analytics/NYC-transportation复制到本账号内自己创建的存储桶emr-workshop-presto-nytaxi。这里还有个参数--copy-props none是不验证API,必需带有这个参数,否则复制会提示没有读取Tag的权限。
aws s3 cp --recursive s3://serverless-analytics/NYC-transportation/ s3://emr-workshop-presto-nytaxi/ --copy-props none
本文后续按照不复制这个数据,而是直接使用原始存储桶s3://serverless-analytics/NYC-transportation/的方式来进行实验。
进入Glue服务,点击左侧的Data Catalog,点击Database按钮,新建一个数据库。注意这里必需新建一个库,否则本实验生成的表可能会与之前实验的表名字冲突。如下截图。
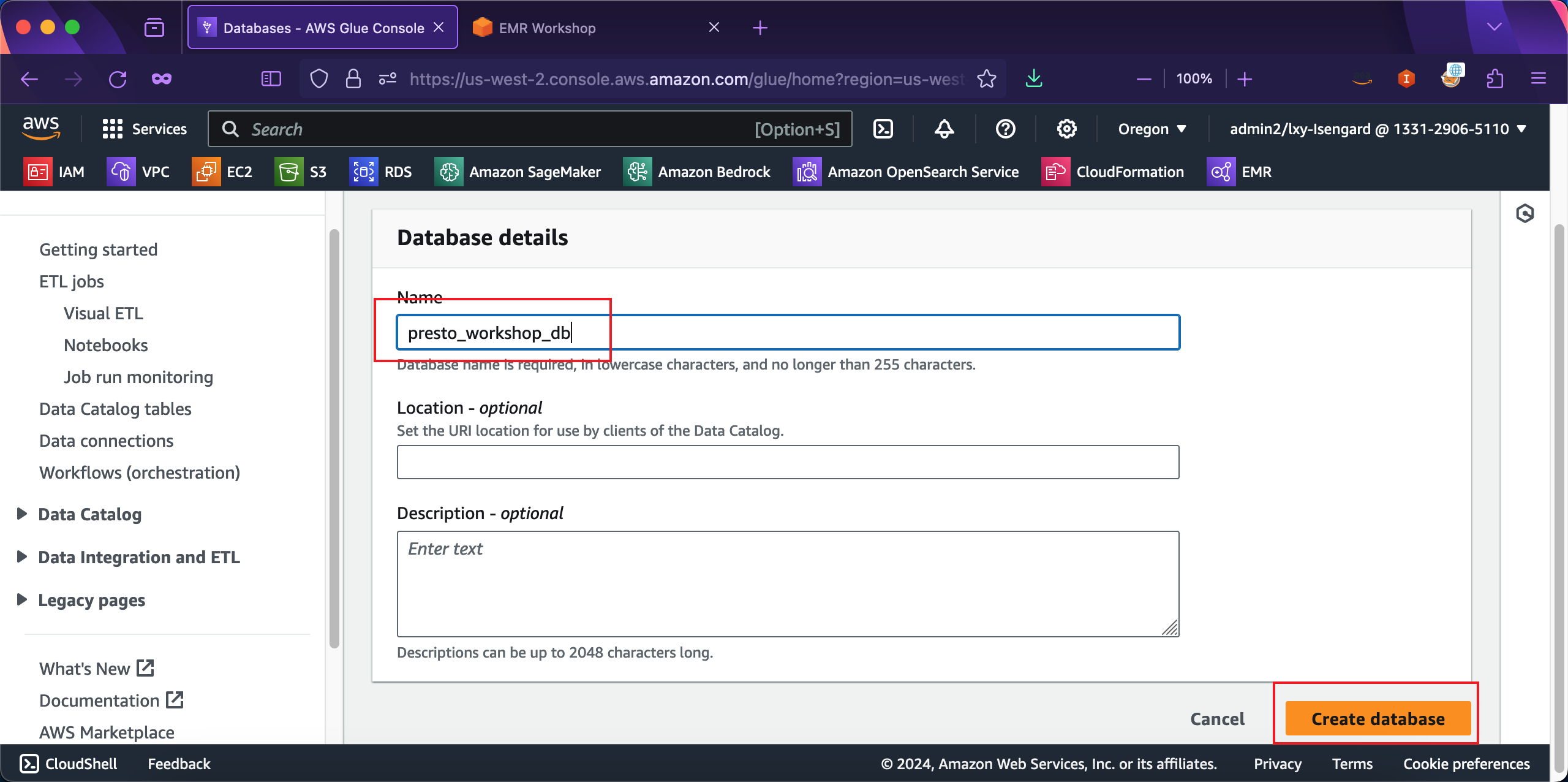
在创建数据库位置,输入名字叫做presto_workshop_db,其他选项留空不需要修改。点击创建按钮完成创建。如下截图。
进入Glue左侧的Data Catalog菜单,点击Crawlers爬虫,在右侧点击Create crawler按钮,创建新的数据结构爬取。如下截图。
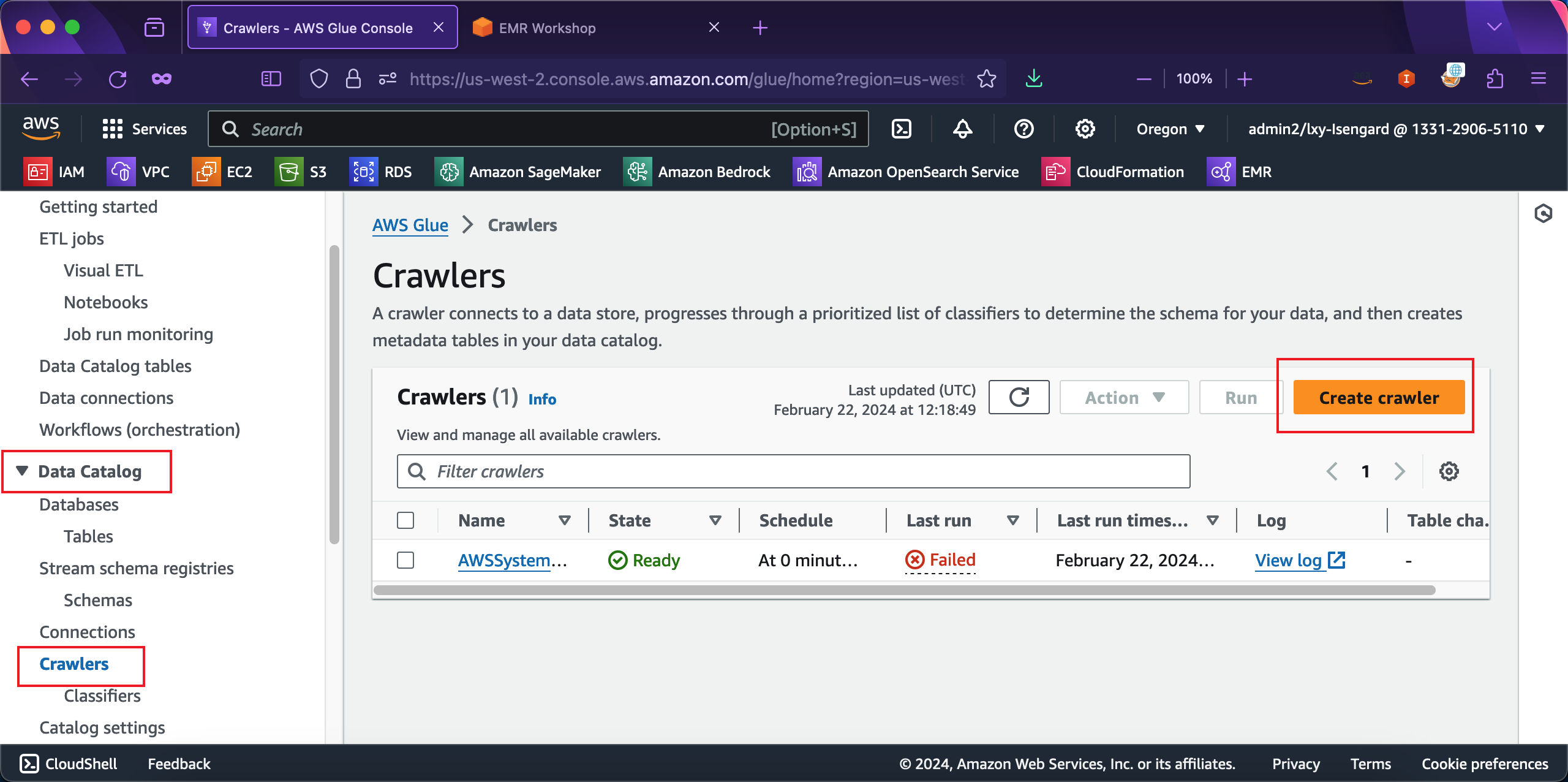
在创建爬虫向导第一步,输入爬虫的名称是presto_workshop_crawler。然后点击下一步继续。如下截图。
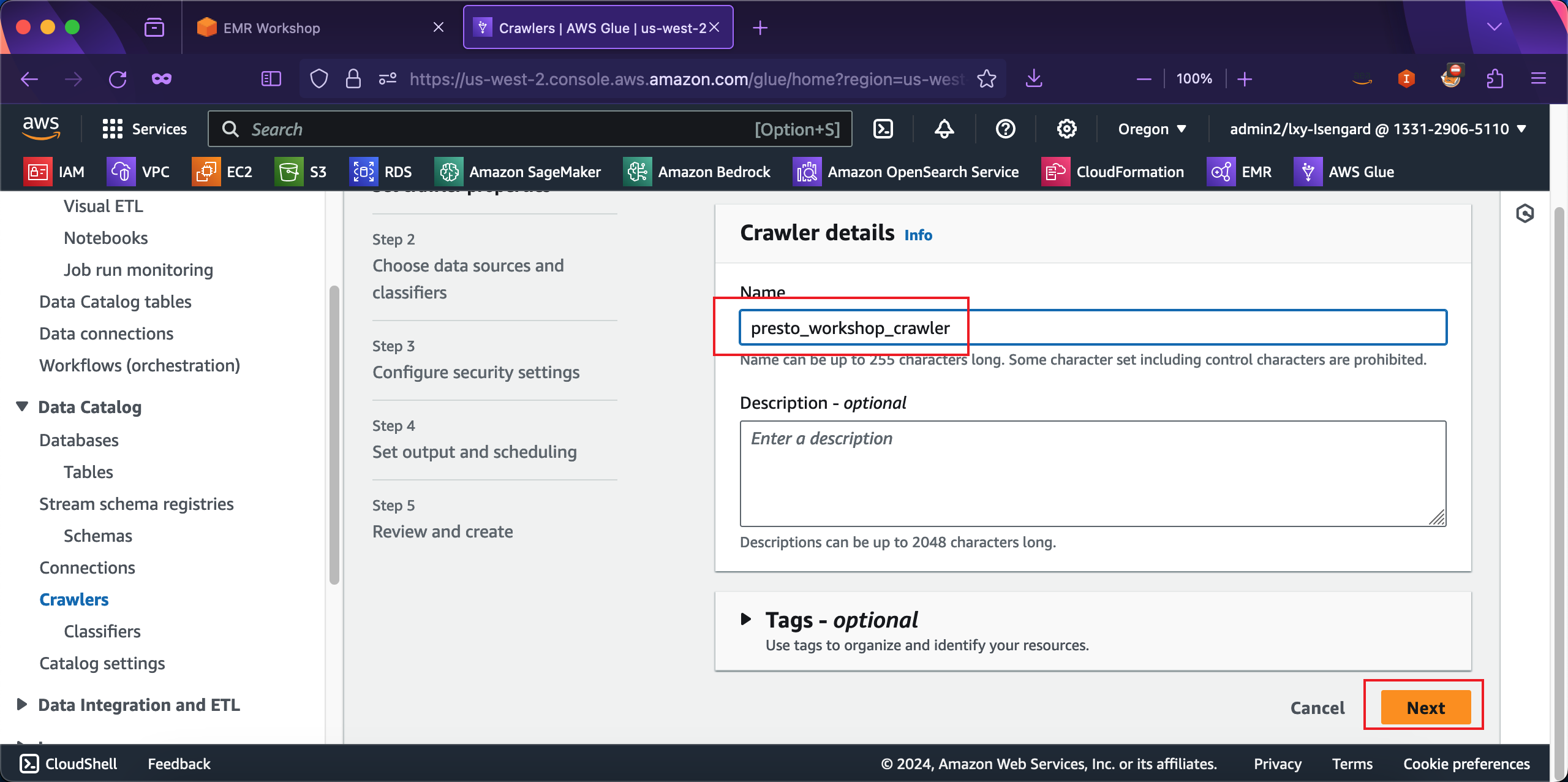
在向导第二步,Data source configuration位置选择Not yet,表示现有数据在Glue table中尚未存在。接下来点击Add a data source按钮新增数据源。如下截图。
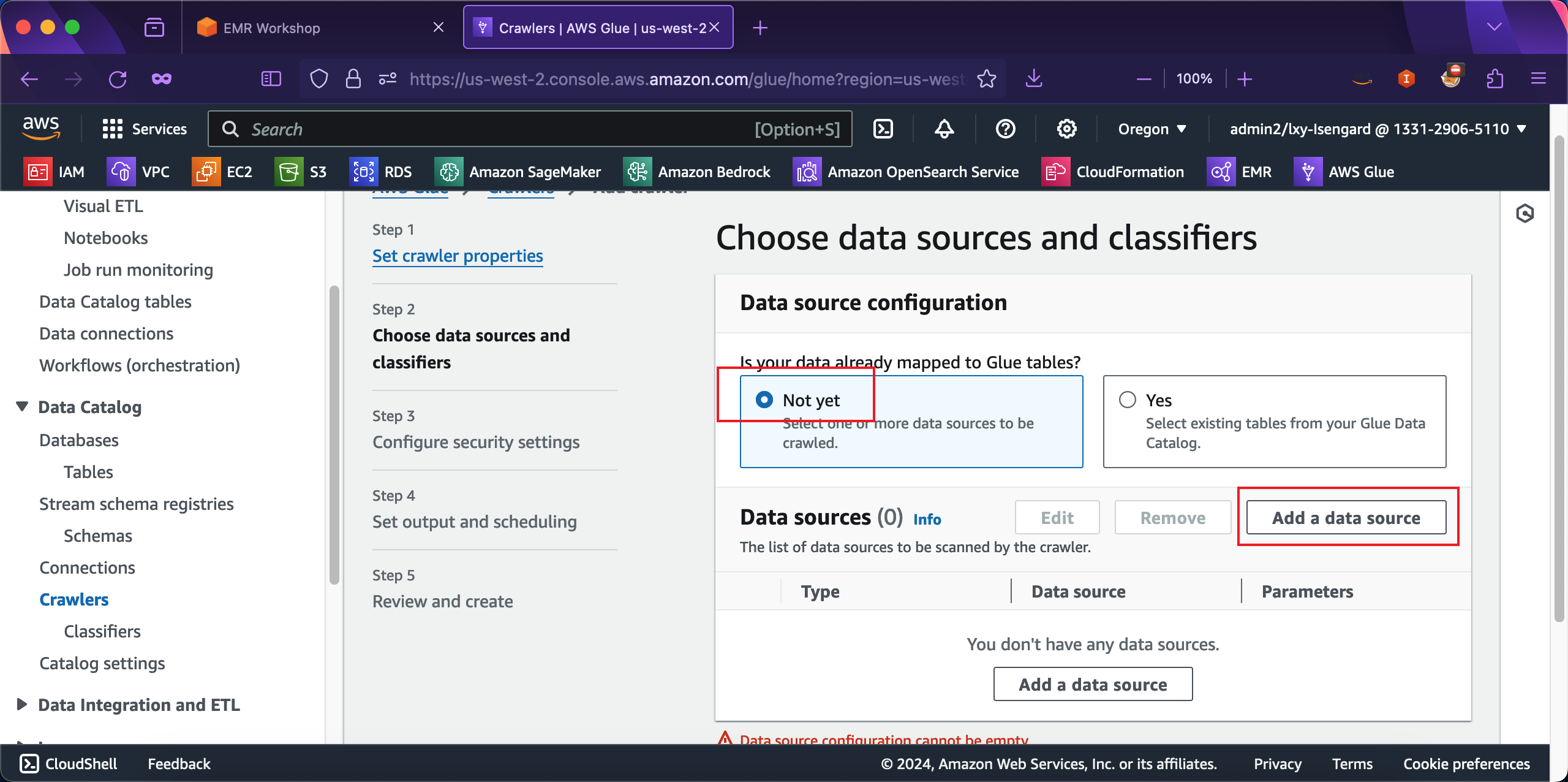
在弹出的数据源向导界面,选择数据源类型是S3,在Network connection留空,表示访问通道不需要任何人和Endpoint。在Location of S3 data位置,选择数据在别的AWS账号In a different account,因为本实验一开始介绍了S3数据源是来自公开数据集,隶属另外的AWS账号。在S3 Path位置输出数据所在存储桶和路径,本实验使用的数据是:s3://serverless-analytics/NYC-transportation/。最后点击Add an S3 data source按钮添加数据源。如下截图。
在添加数据源后,返回到Glue爬虫向导页面,点击下一步继续。如下截图。
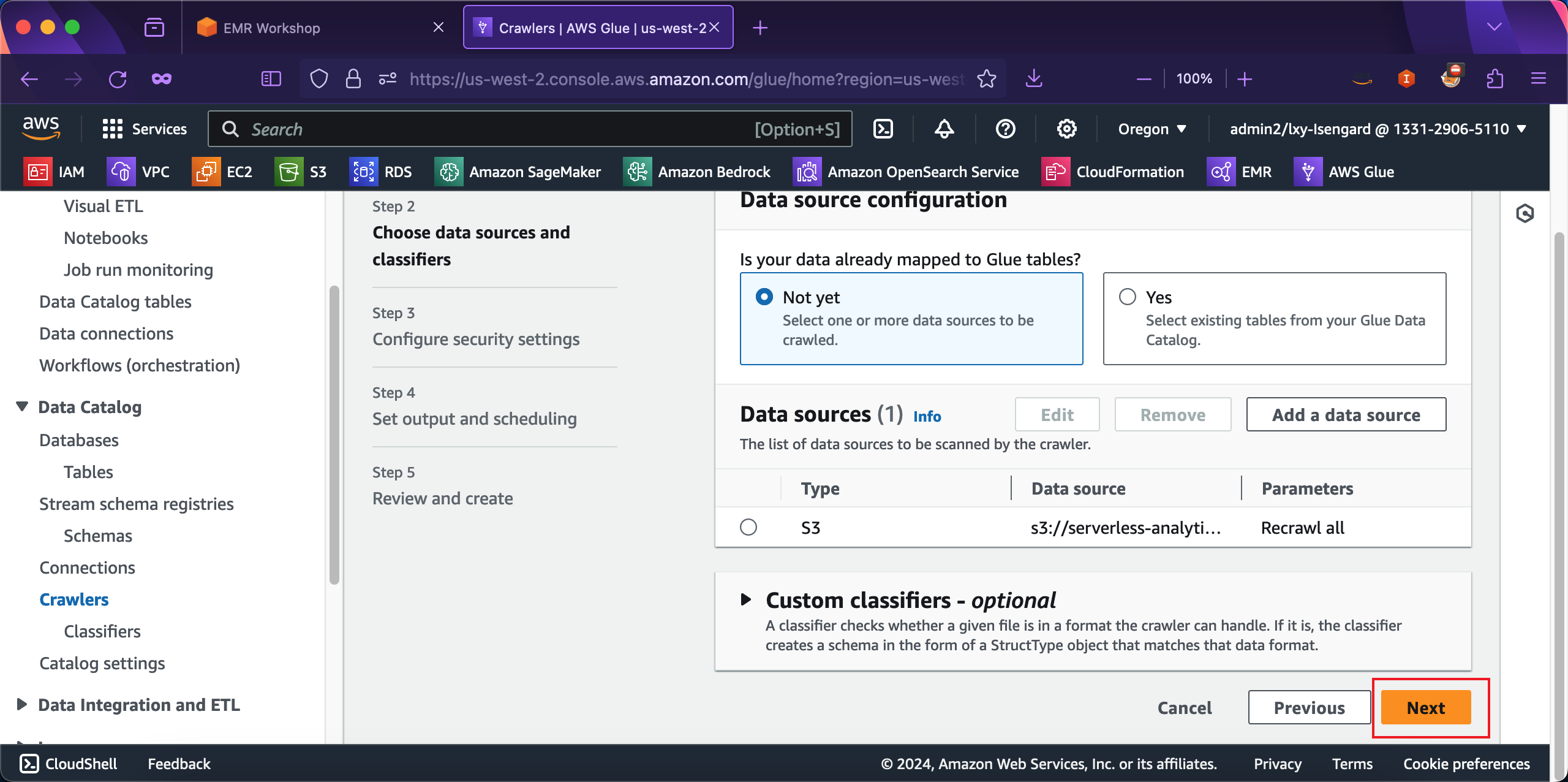
在向导第三步,Glue爬虫使用的IAM角色位置,点击按钮Create new IAM role,这将为Glue爬虫自动创建一个新的IAM角色。如下截图。
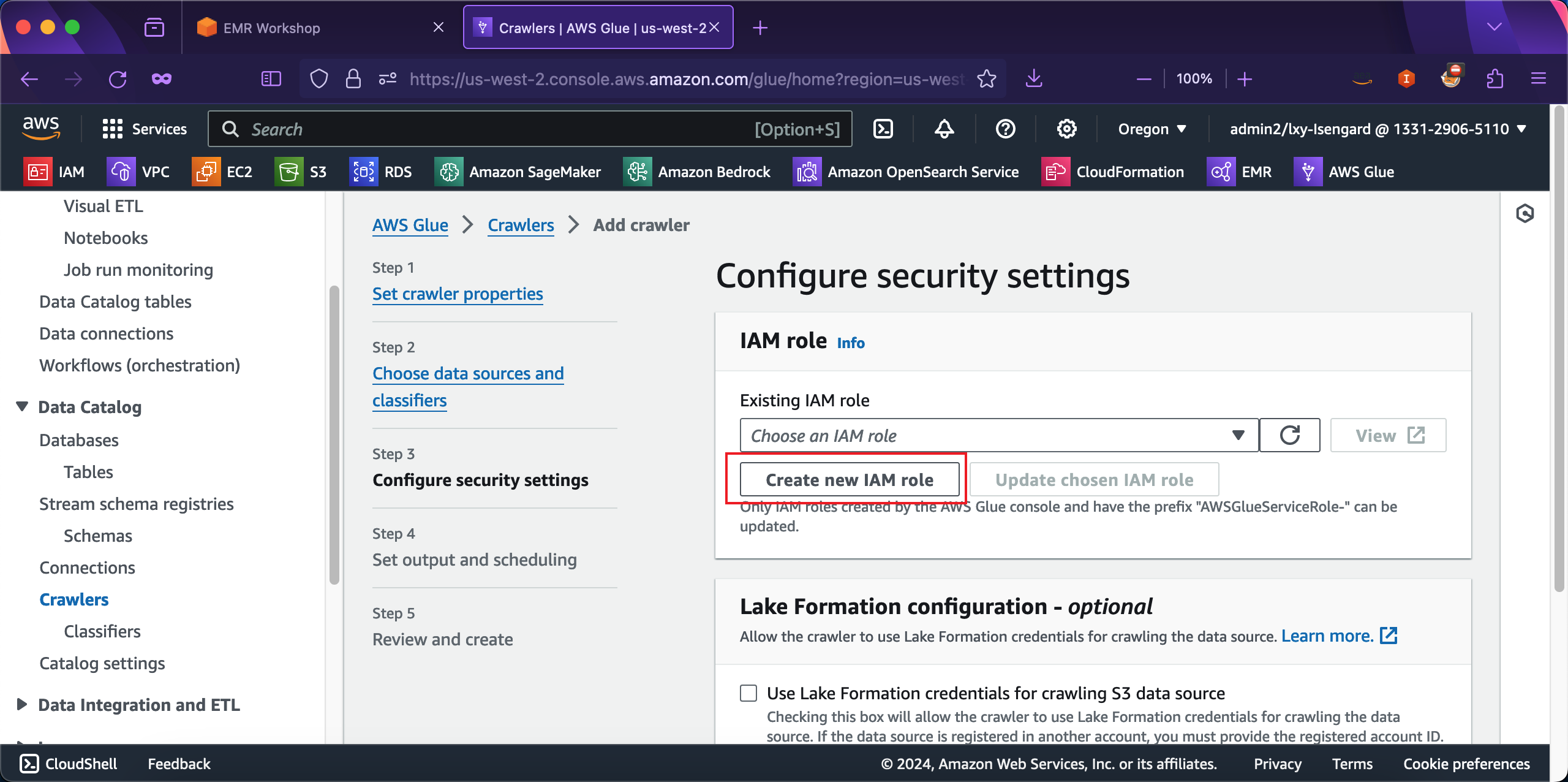
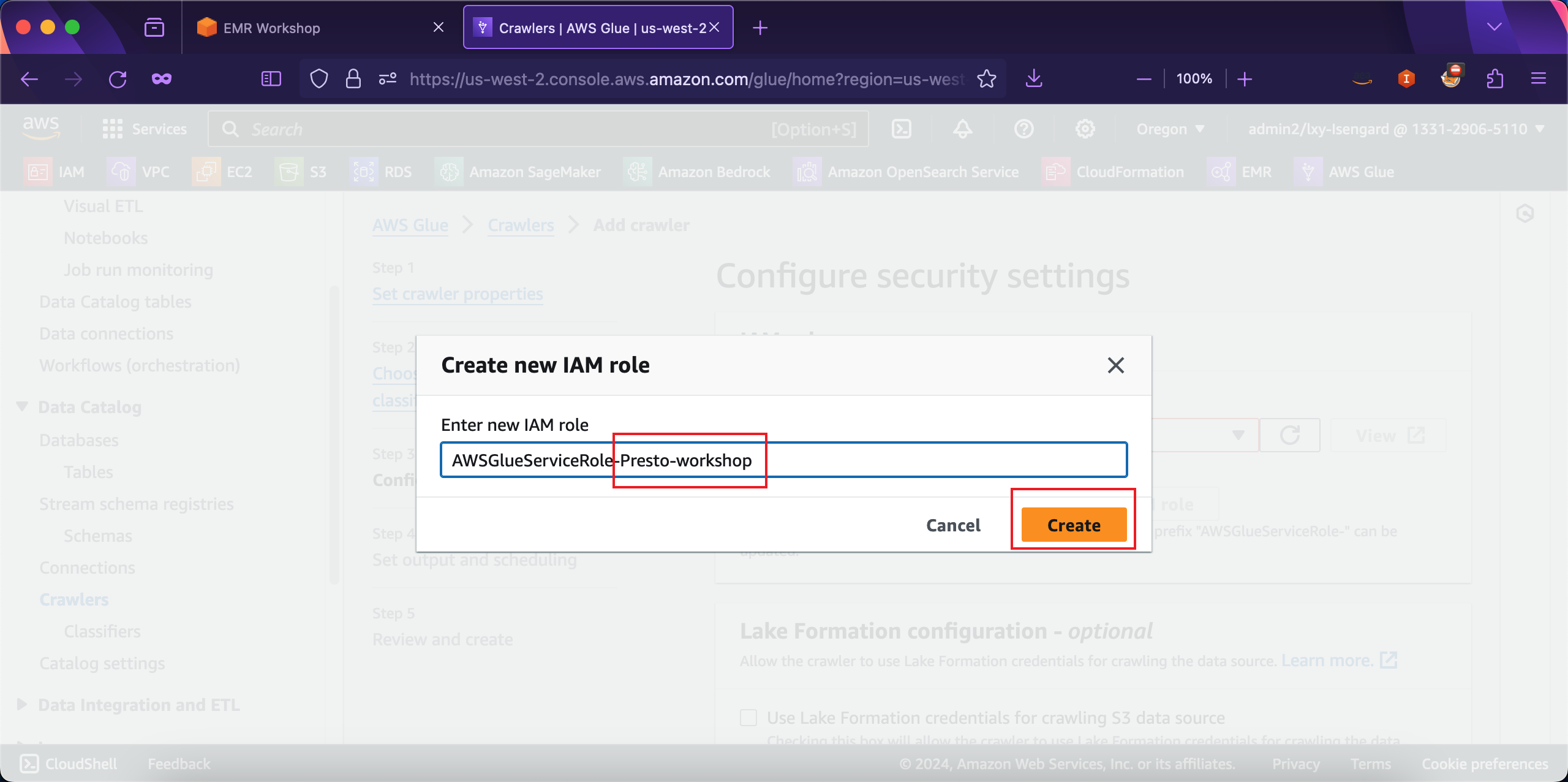
在创建新角色的向导页面,角色名称前缀是AWSGlueServiceRole-是不能修改的,在后边补充上后缀例如Presto-workshop即可。然后点击创建按钮。如下截图。
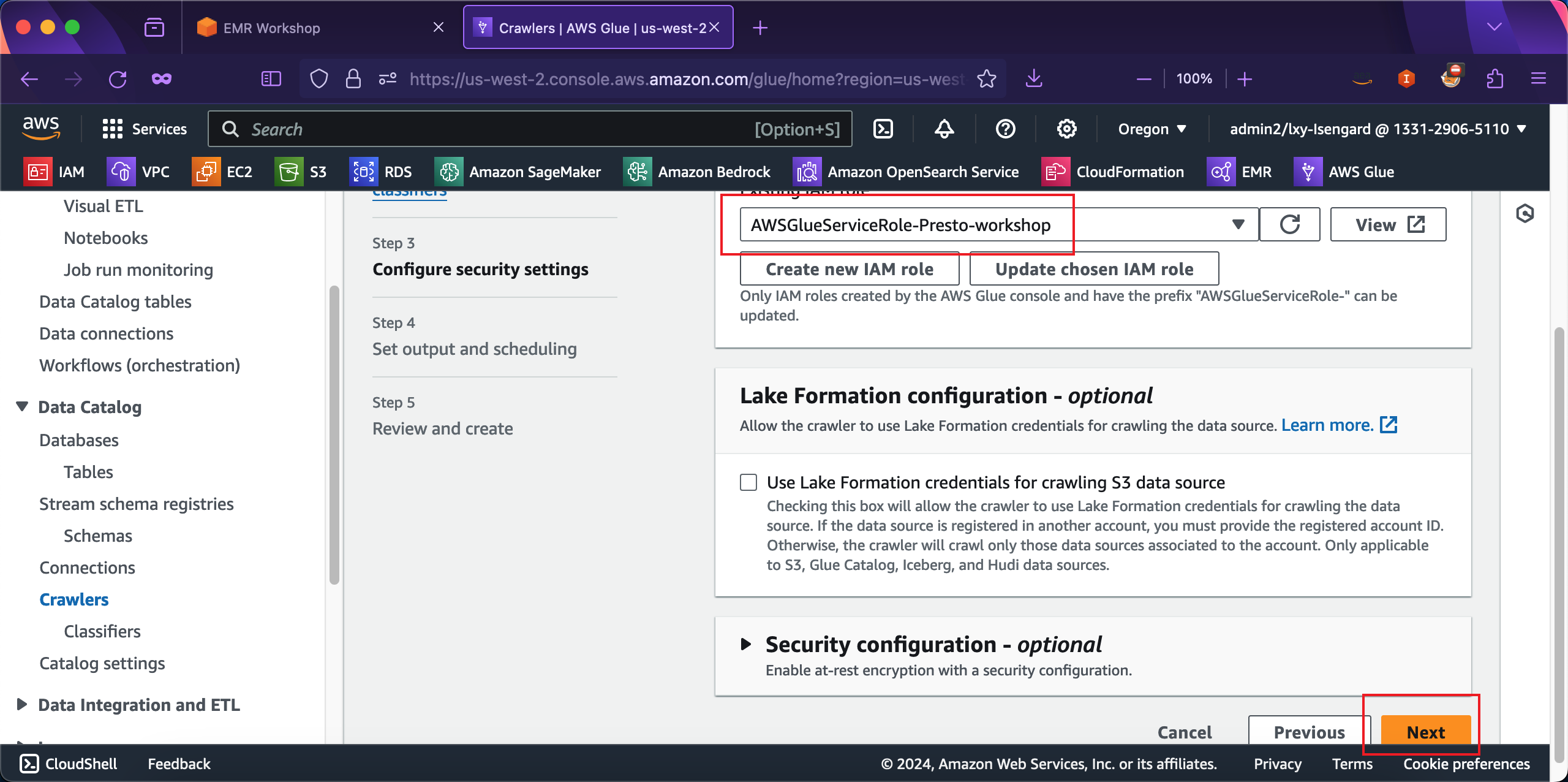
从IAM创建角色向导,返回到Glue爬虫向导,此时上方的IAM角色已经加载出来之前创建的角色了。点击页面右下角的Create按钮继续下一步。如下截图。
在创建向导第四步,爬虫生成的数据库位置,从下拉框中选择本实验新创建的presto_workshop_db库。注意这里不能使用default默认库,否则可能与之前Hive实验生成的表的名字冲突。在Table name prefix表名前缀位置留空不需要填写。在Maximum table threshold位置也留空。如下截图。
将页面向下滚动,在Crawler schedule位置,选择爬虫运行频率Frequency是On demand,按需运行。然后点击下一步继续。如下截图。
在爬虫向导最后一步,点击Create完成爬虫创建。如下截图。
爬虫创建完成后,需要手工触发运行。在爬虫详情右上方点击Run crawler开始运行爬虫。如下截图。
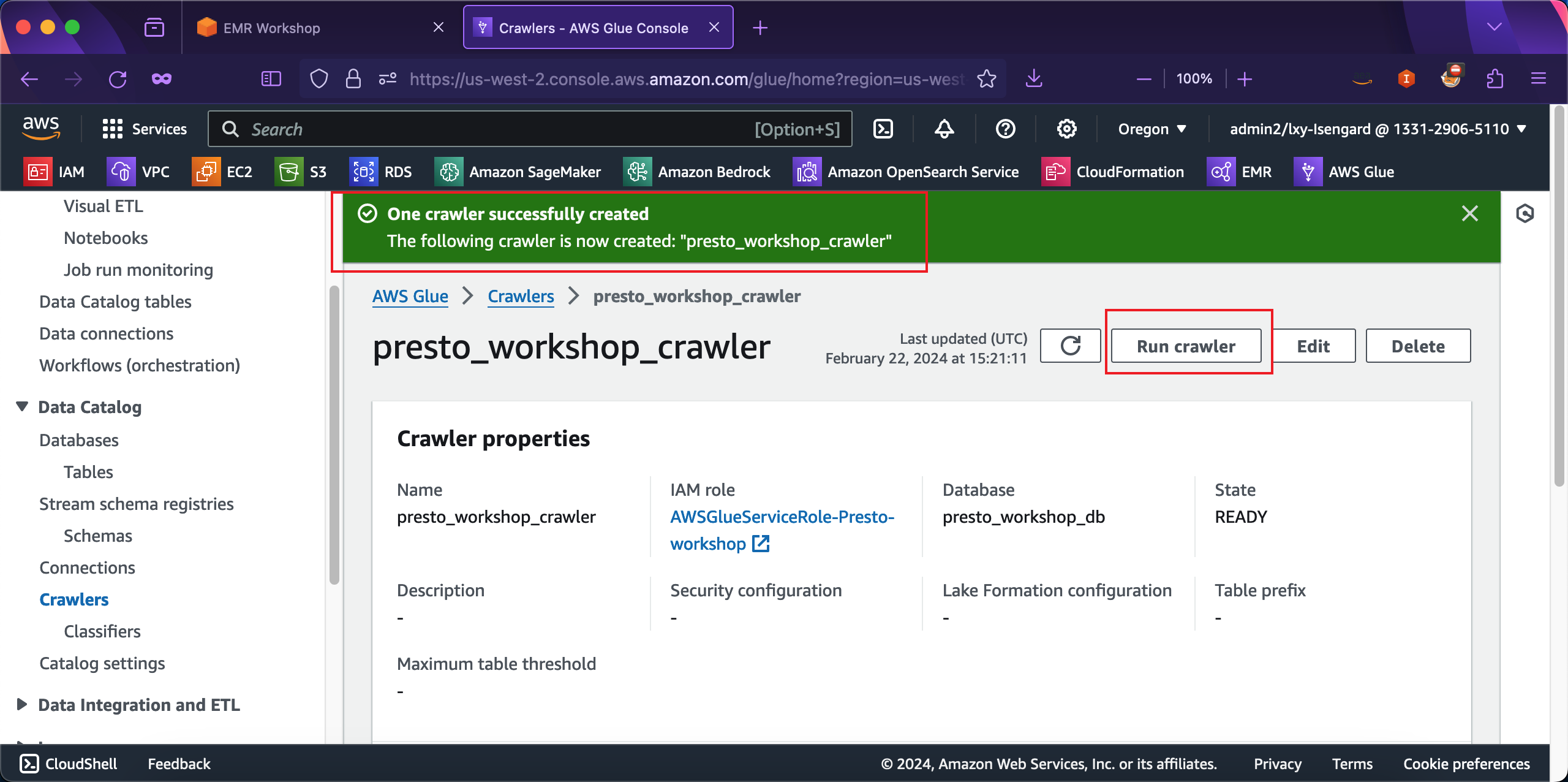
等待几分钟后,爬虫运行成功,页面提示Last run是Successfully。如下截图。
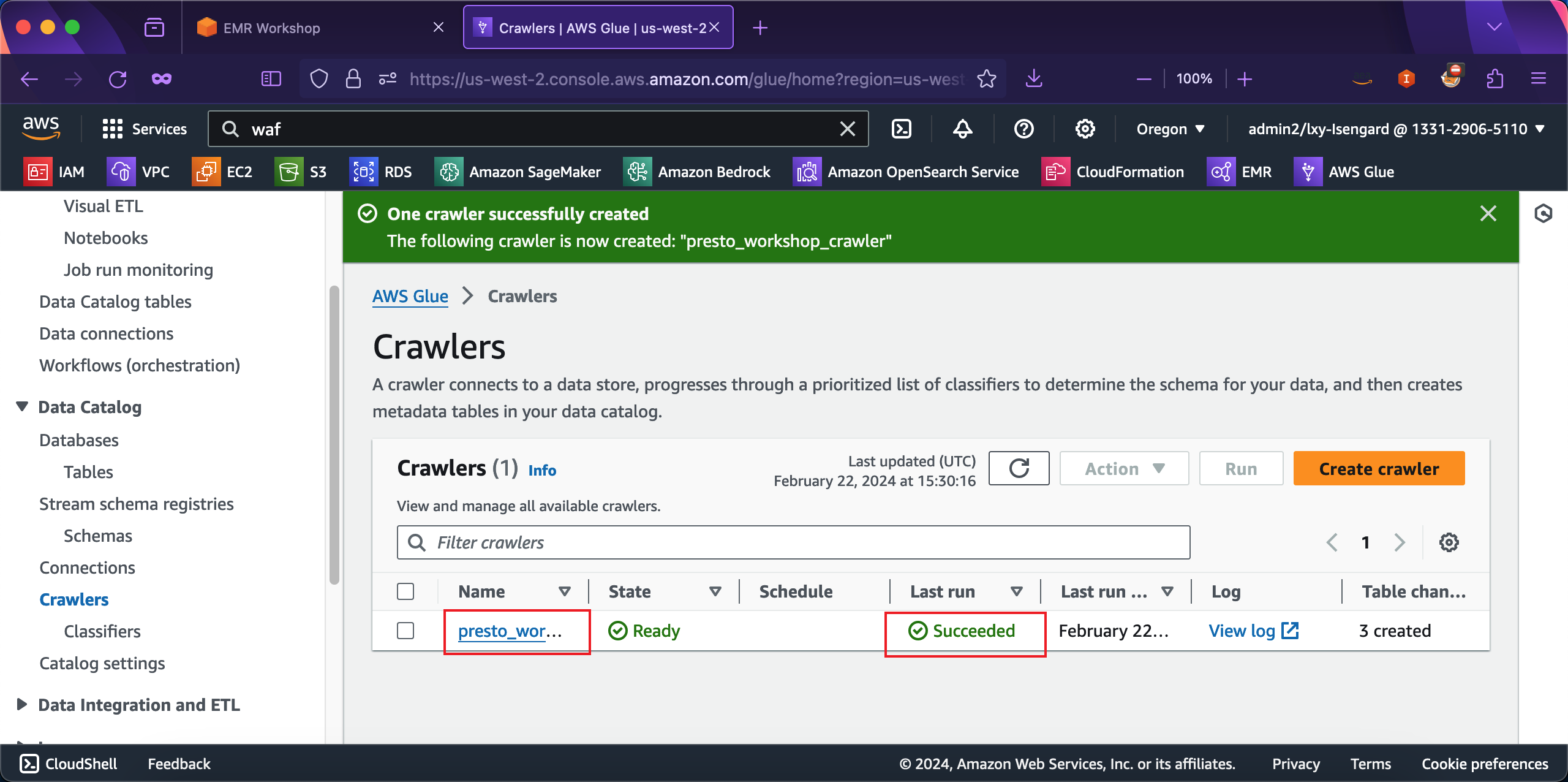
至此,Glue已经对S3存储桶的数据生成了目录,这个目录可以被EMR和Presto直接使用。
现在点击Glue页面左侧的菜单Data Catalog,点击Databases菜单下的Tables,从右侧的表的清单中,可以看到刚才Glue爬虫获取的S3存储桶生成的表。如下截图。
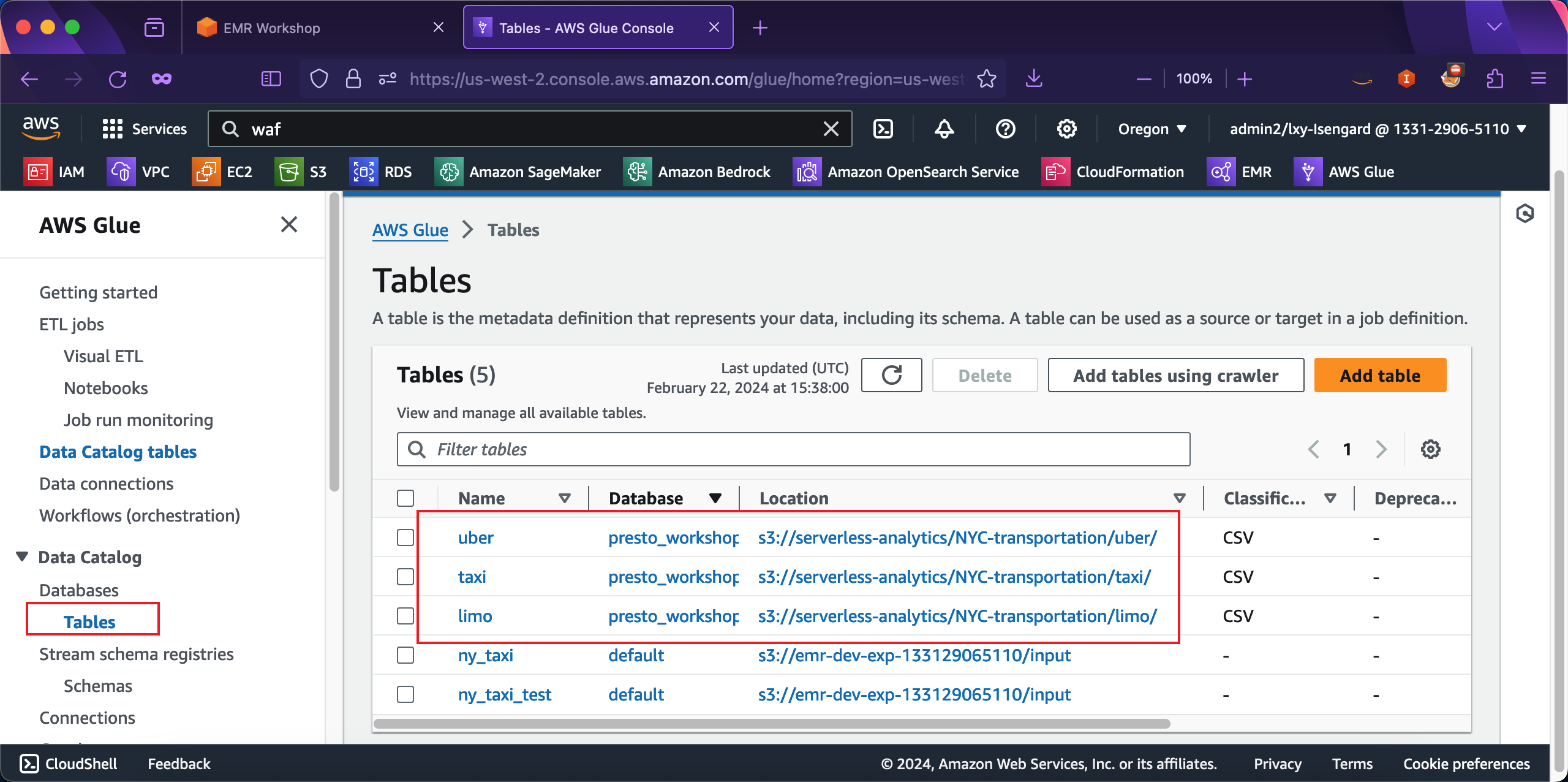
2、手工调整Glue爬虫识别的字段
在上一步的爬虫运行完毕后,还需要手工调整下字段定义,将tpep_pickup_datetime和tpep_dropoff_datetime字段从String类型调整为Timestamp类型。方法如下。
进入Glue服务,点击左侧的Data Catalog菜单,进入Databases,进入Tables菜单,点击右侧上一步爬取出来的taxi库的名称。如下截图。
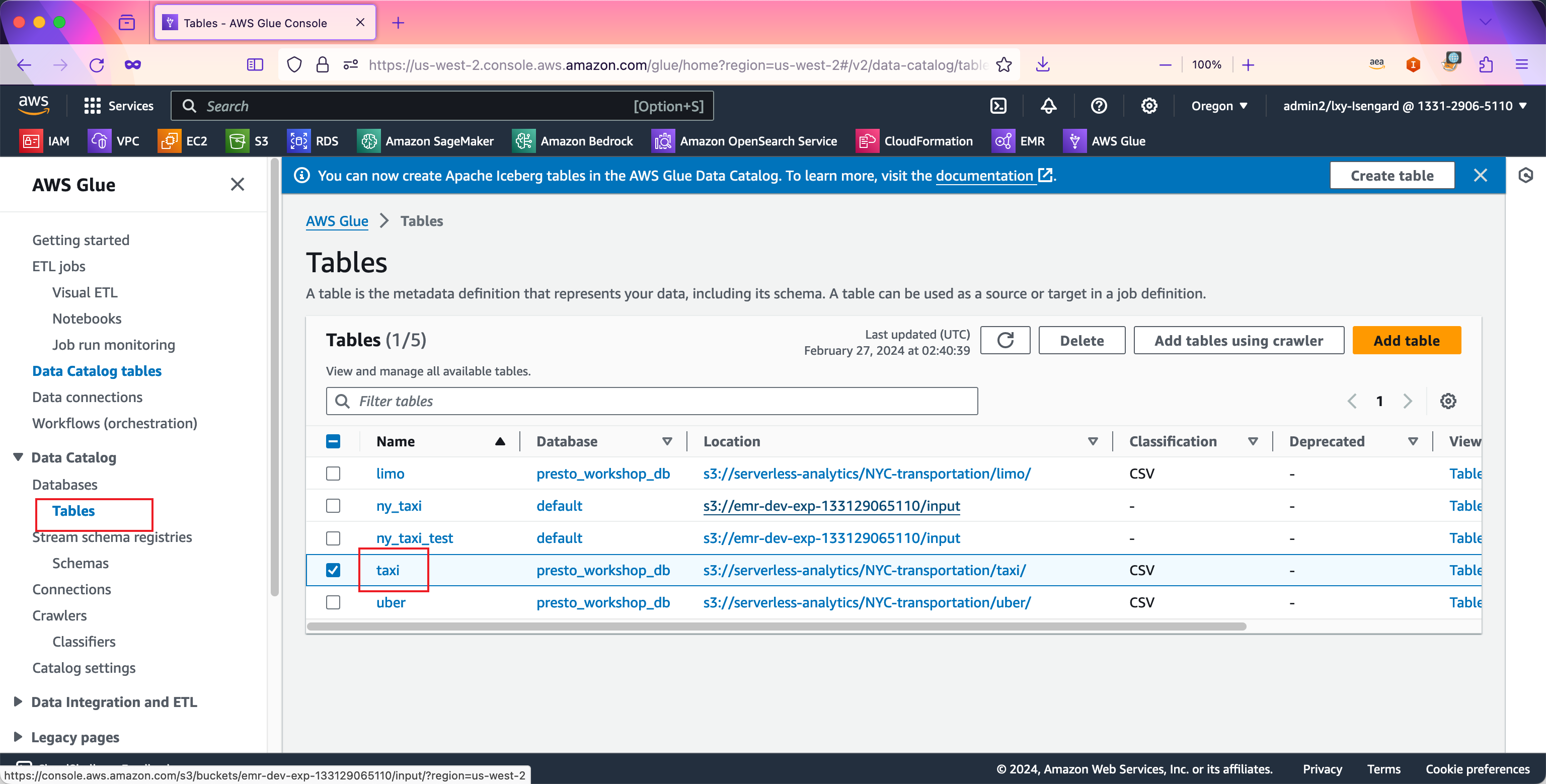
在数据库详情中,进入Schema界面,找到其中要求改定义的两个字段。点击右上角的Edit schema按钮。如下截图。
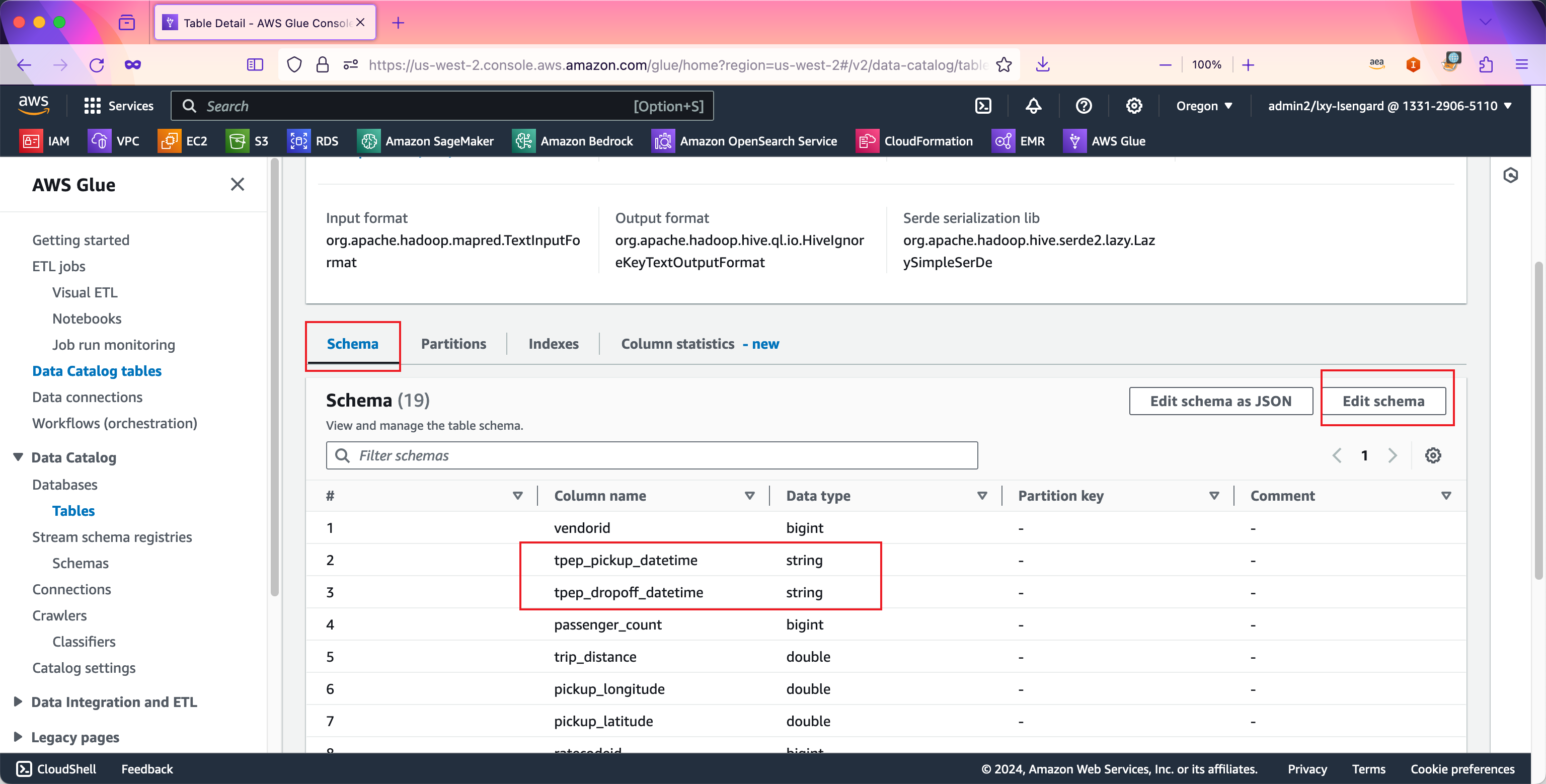
选中第一个字段tpep_pickup_datetime,然后点击Edit按钮。如下截图。
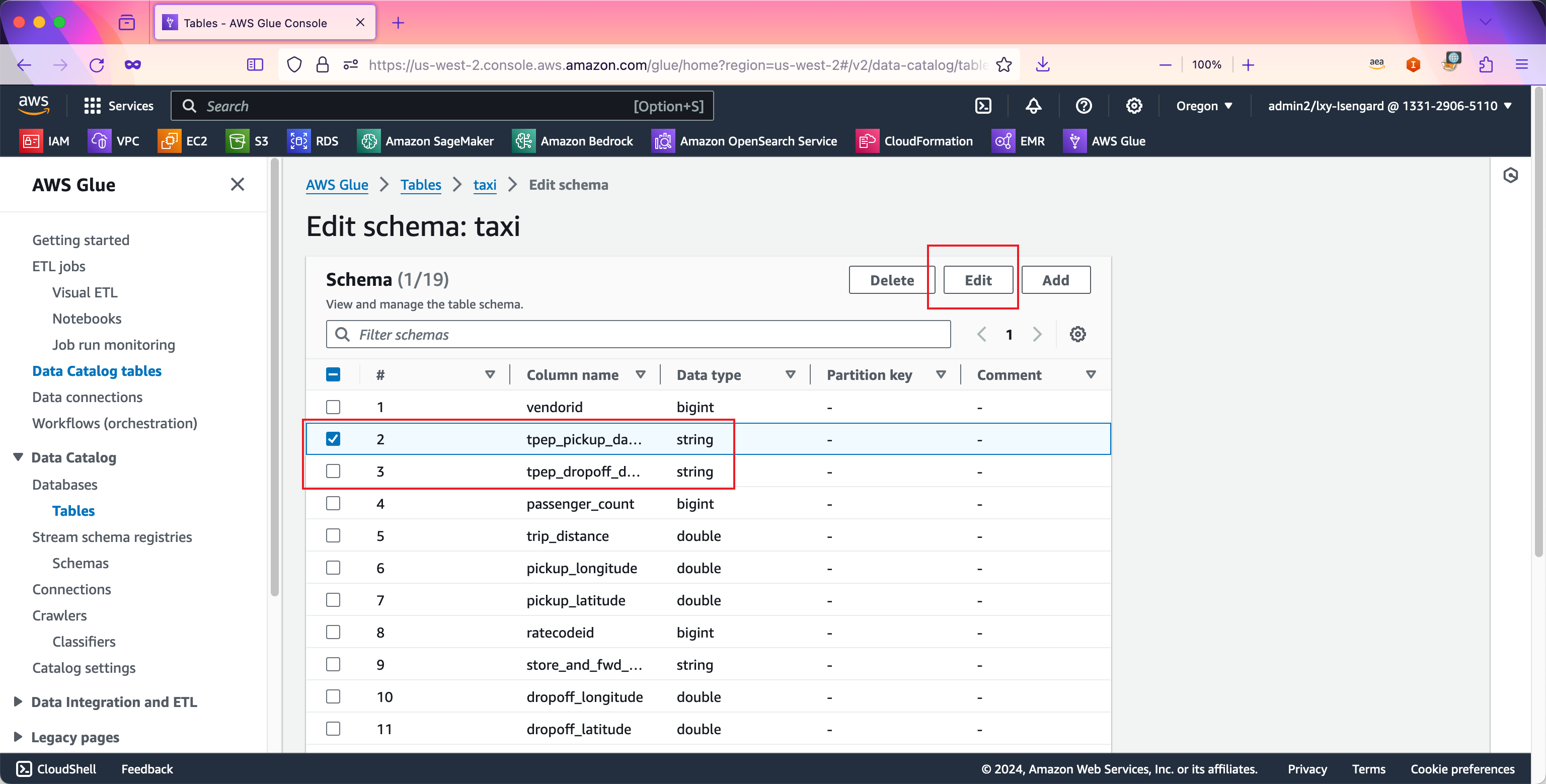
在编辑界面中,将Data type从现有的String类型修改为timestamp类型。然后点击Save按钮。如下截图。
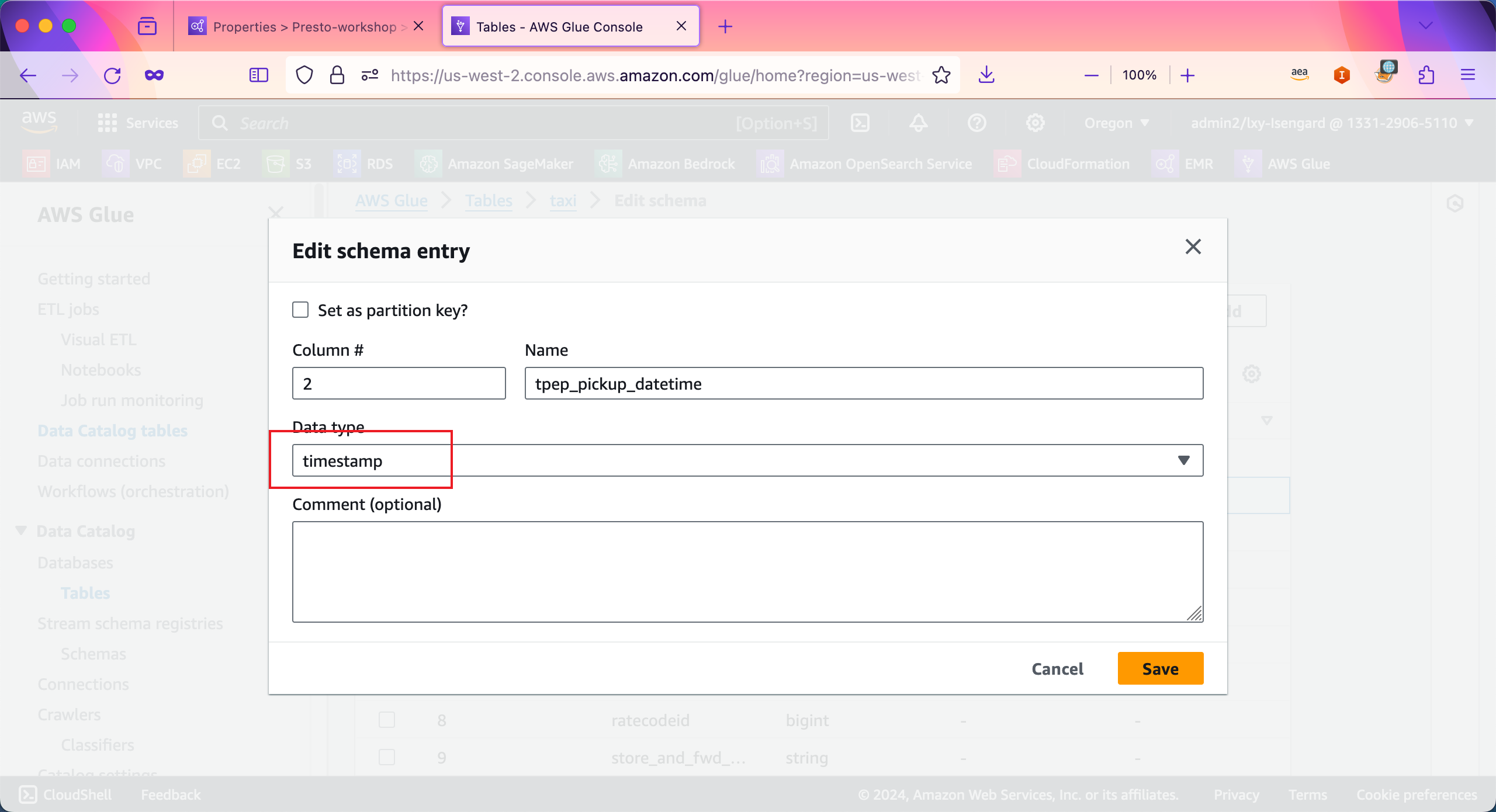
接下来编辑第二个字段,将tpep_dropoff_datetime字段类型进行编辑。如下截图。
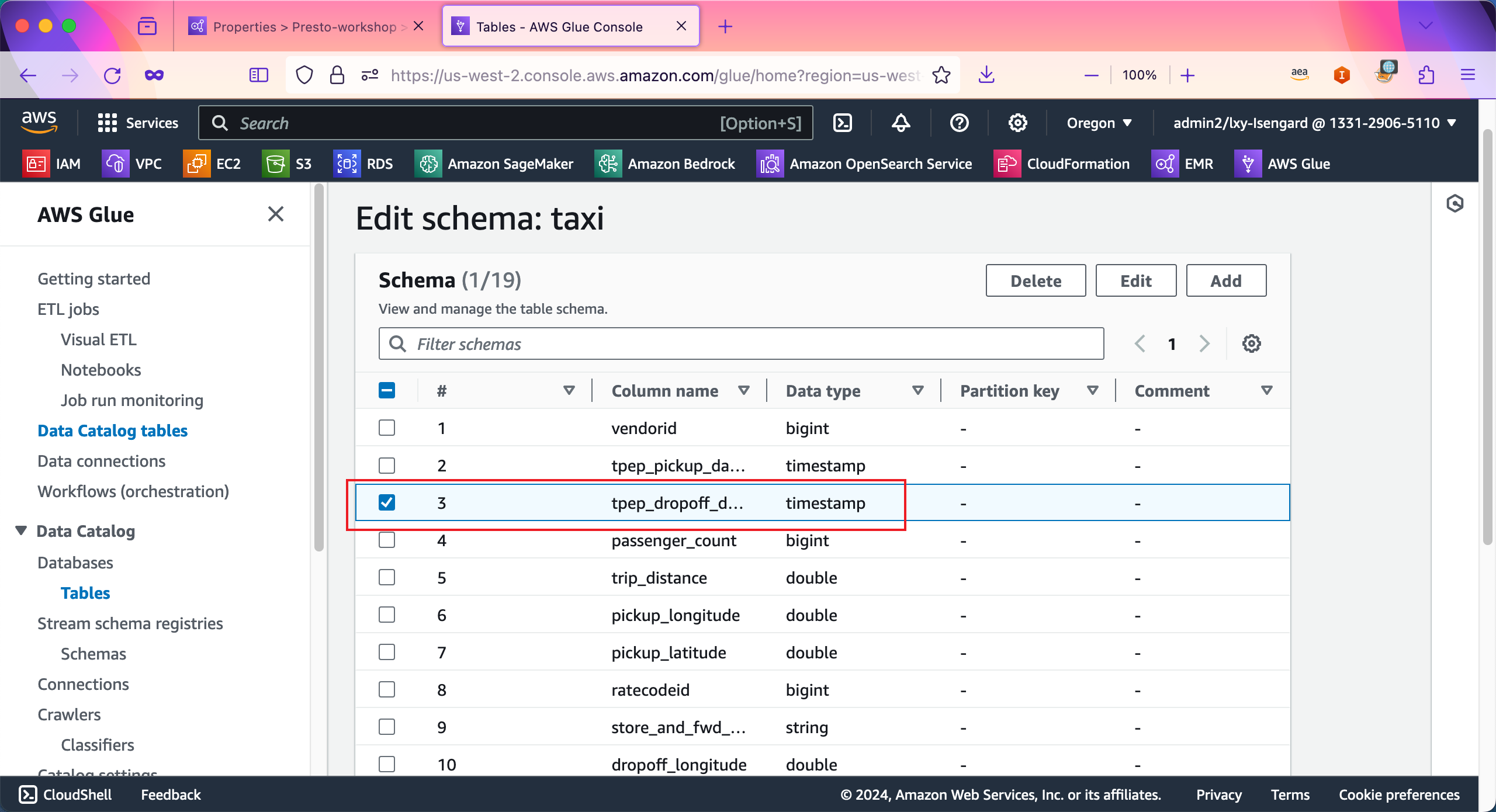
在修改完毕两个字段后,点击右下角的Save as new table version。如下截图。
现在数据准备完成。下面创建EMR集群。
3、通过AWS控制台创建EMR集群用于运行Presto
在EMR集群向导页面,保留原来的Hive实验的集群不要动,在创建一个新的EMR集群。点击创建按钮。如下截图。
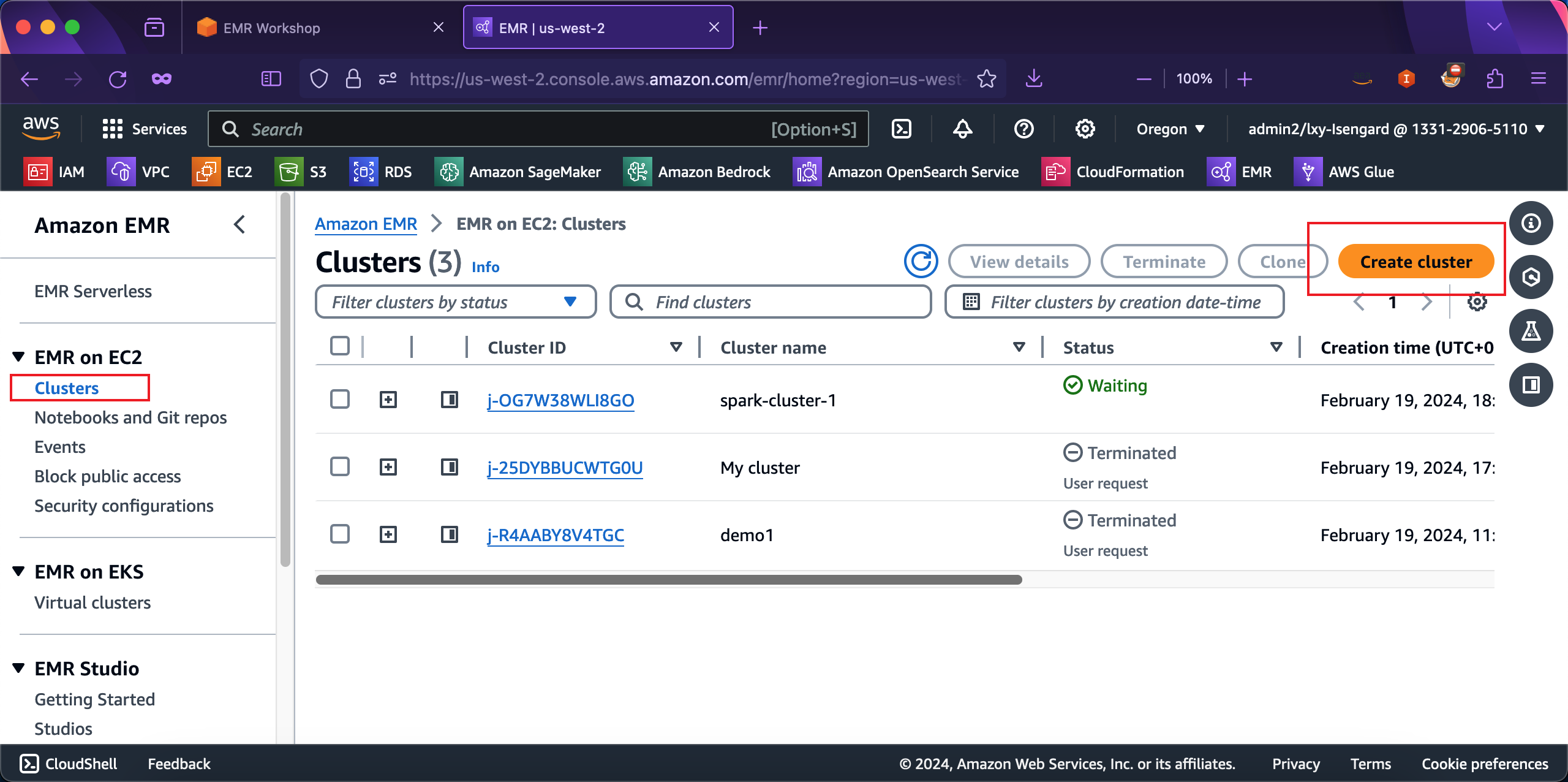
在创建向导最上方,输入集群名称,然后选择EMR版本是6.15.0版本。Presto的实验创建的集群只需要选择三个软件:Hadoop、Hue、Presto。其他的不用选择。接下来继续向下移动屏幕。如下截图。
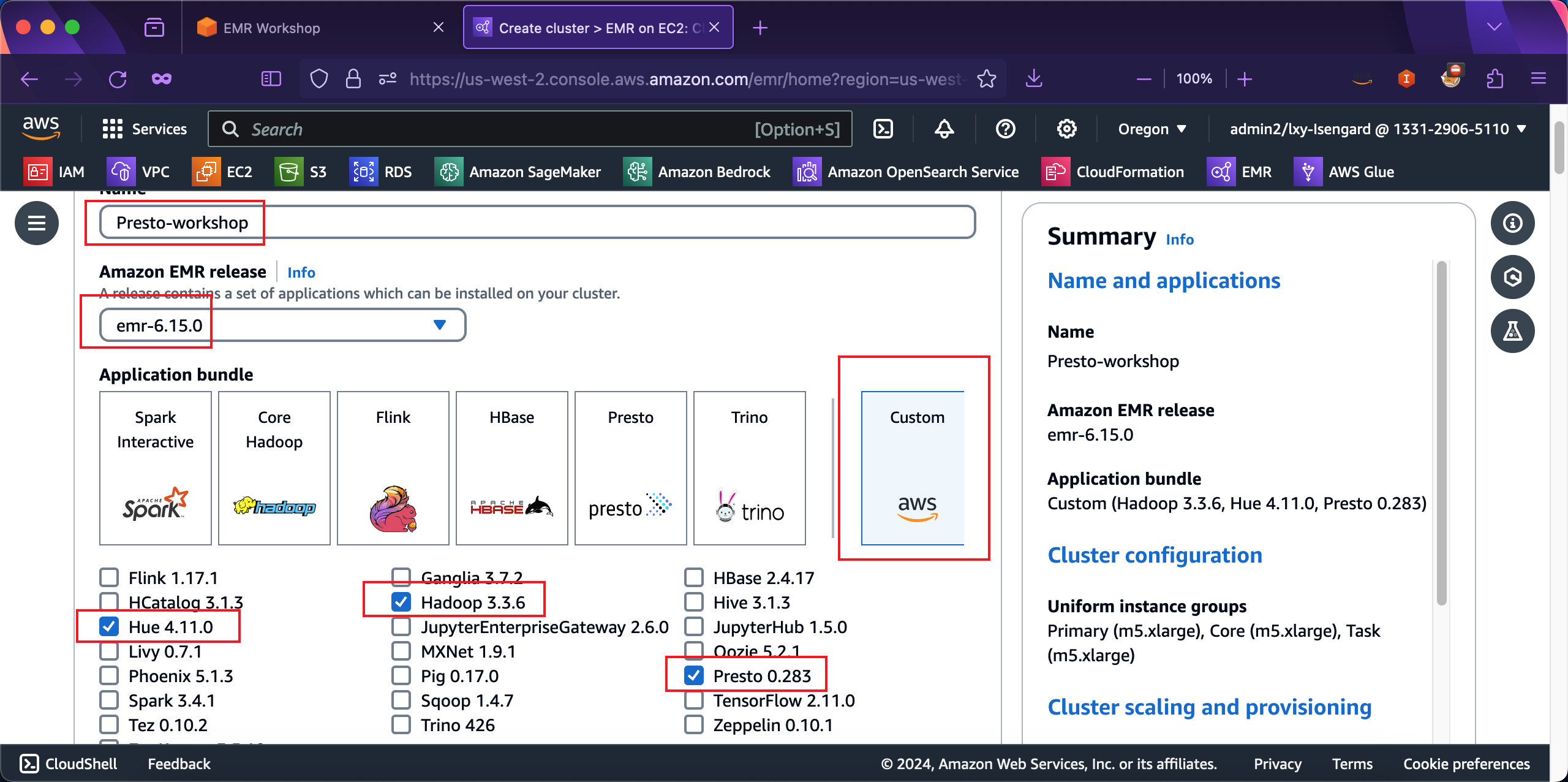
在AWS Glue Data Catalog settings位置,选择Use for Presto table metadata,也就是使用之前创建的Glue爬虫扫描的结果作为Presto的元数据。在Operating system options操作系统选项中,选择Amazon Linux release作为操作系统。在Automatically apply latest Amazon Linux updates选项上,选中之。如下截图。
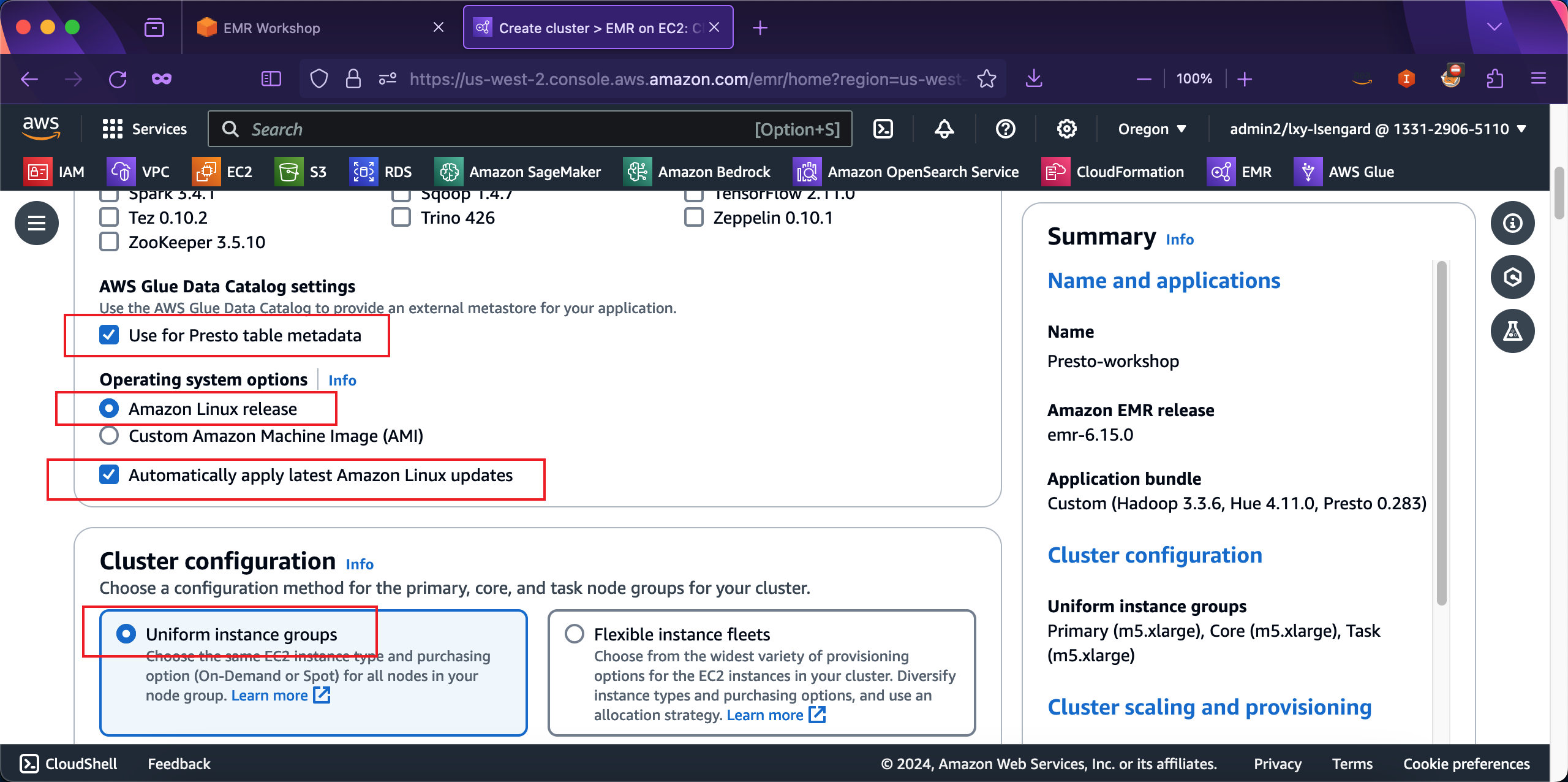
在Cluster configuration位置,选择Uniform instance groups。继续向下滚动屏幕。在Primary节点的机型配置上,保持默认不需要修改。Use high availability选项在测试环境中不需要打开。然后继续向下移动屏幕。如下截图。
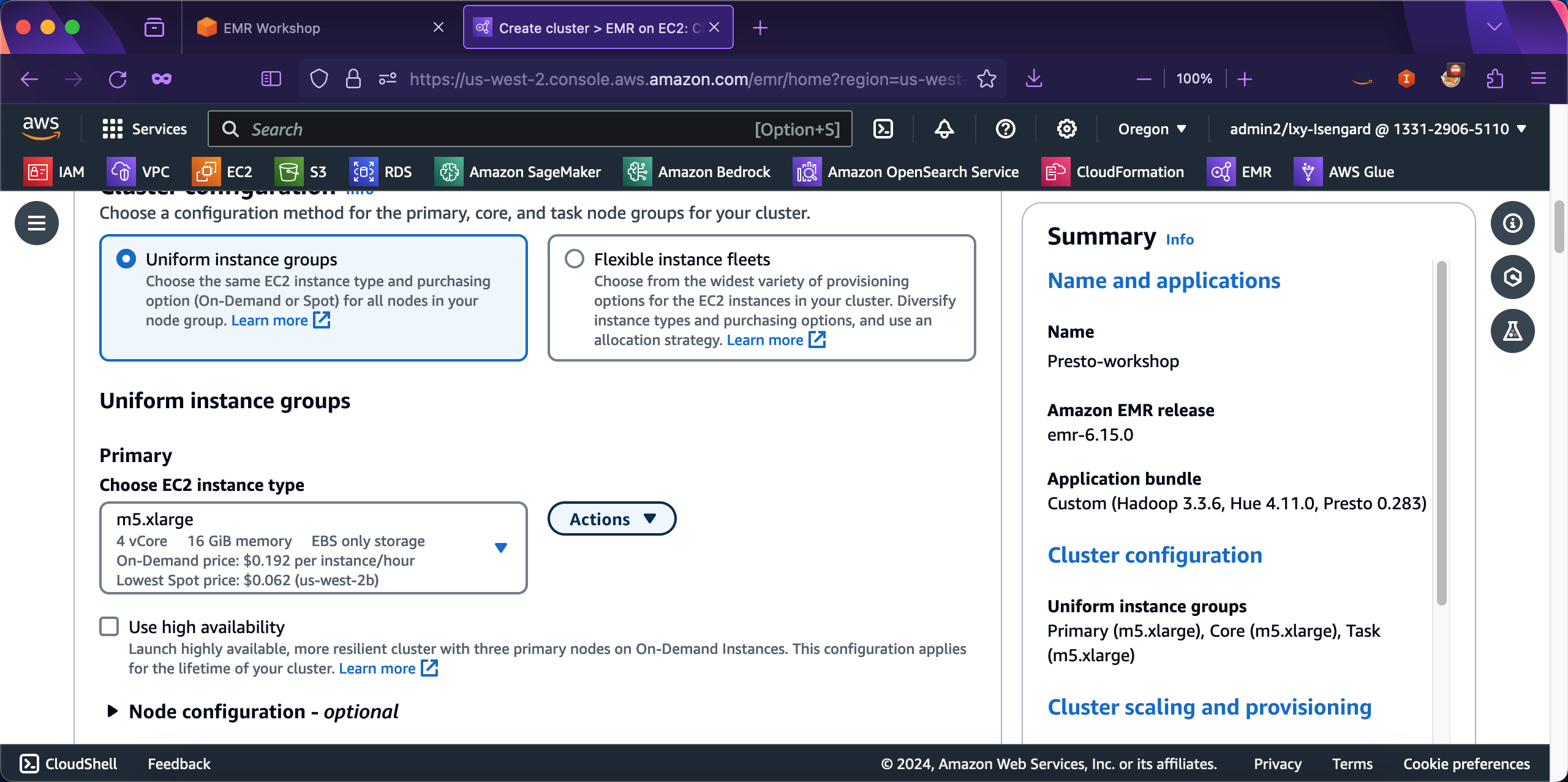
在Core节点位置,不需要修改配置。在Task节点位置,Presto的实验不需要Task节点,因此可以点击Remove instance group按钮,将Task节点从集群中移除。如下截图。
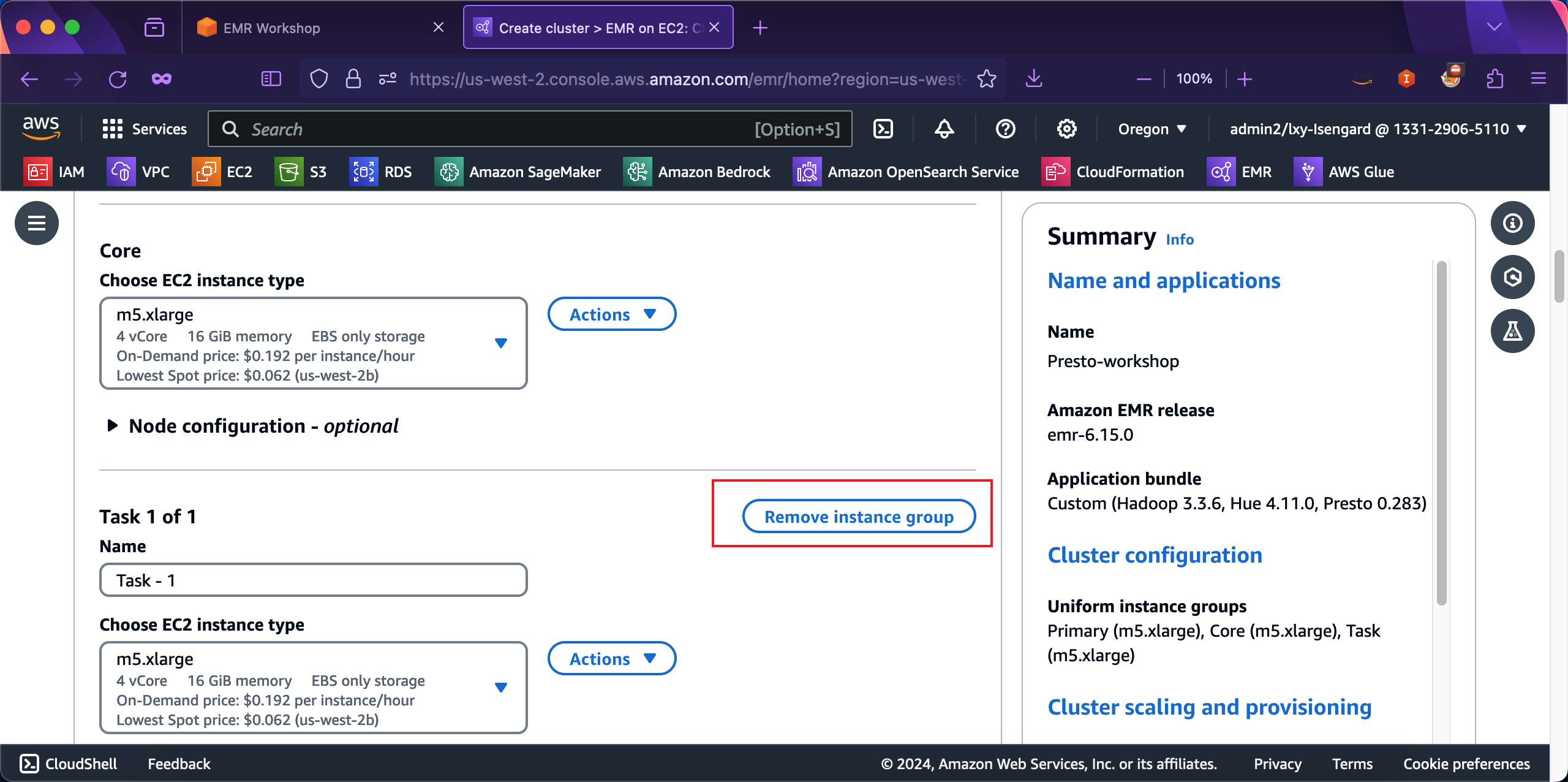
在EBS配置位置,默认的磁盘大小即可,不需要调整。继续向下滚动屏幕。如下截图。
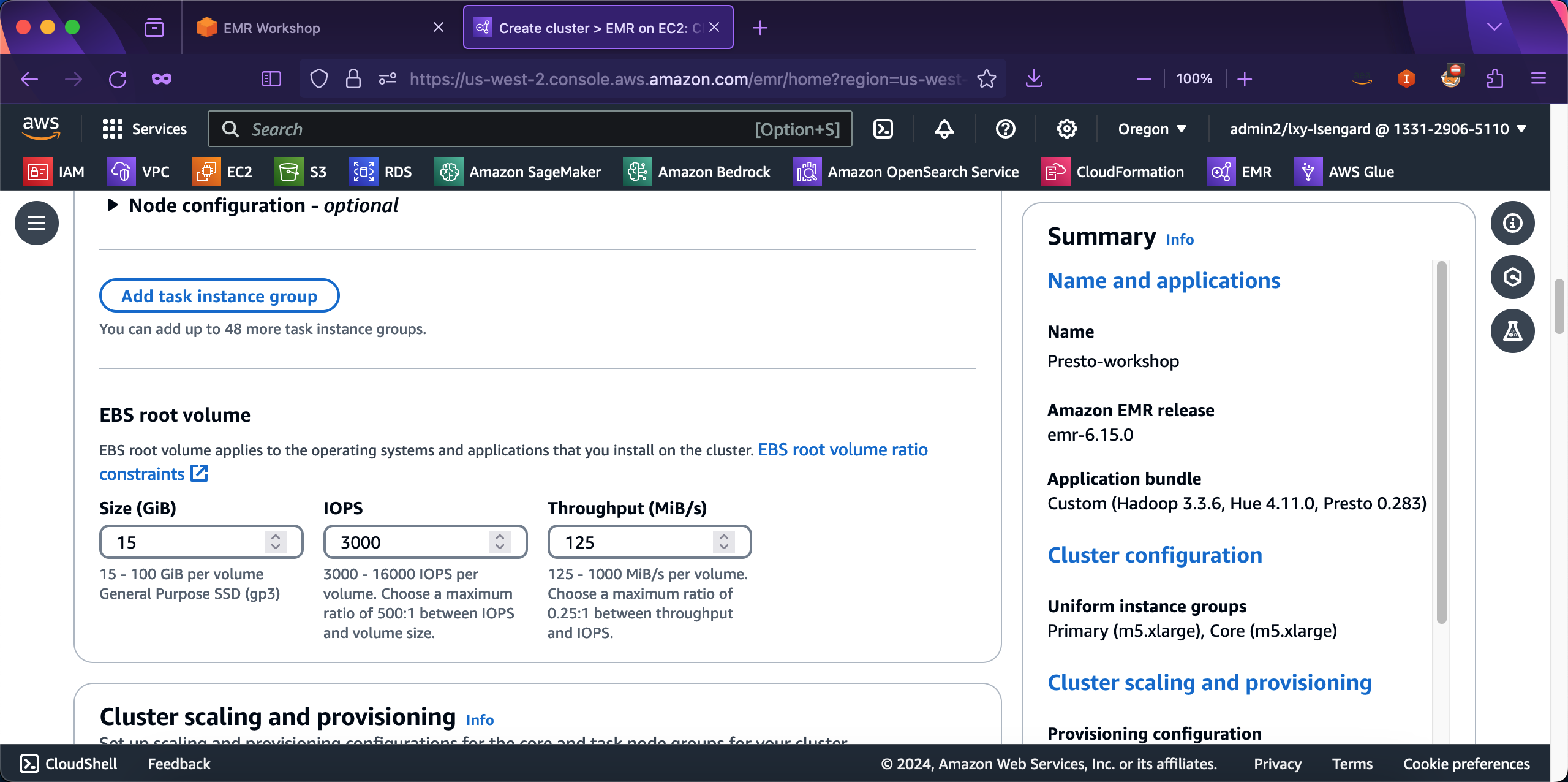
在集群配置Cluster scaling and provisioning - required的选项上,选择第一项Set cluster size manually,然后在Core节点位置,将Instance(s) size的数量从默认的1修改为2。如下截图。
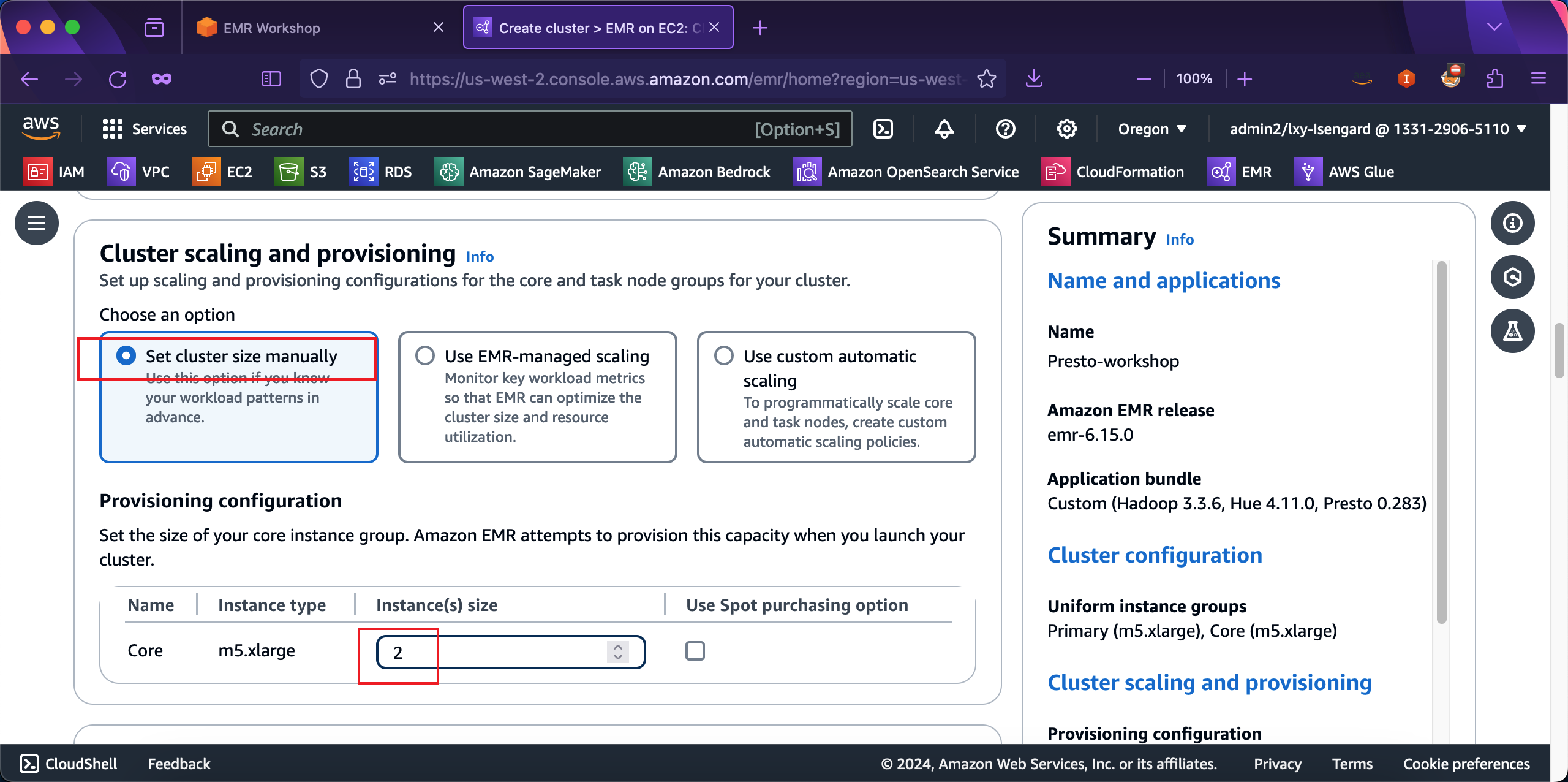
在Networking的地方,在选择VPC的地方,点击Browse按钮,然后从弹出的VPC选择清单中,选择名为EMR-Dev-Exp-VPC的VPC。这个VPC是在本实验上篇的Spark实验之前,通过CloudFormation创建的。当选择好VPC之后,同样选择子网。如果使用的是EMR-Dev-Exp-VPC的VPC,那么其中只包含一个唯一的Public子网,界面上会自动选中。如下截图。
继续向下滚动屏幕。在EC2 security gruops(firewall)选项位置上,不需要展开菜单,向导默认的安全组已经可以满足要求。在下方的Steps配置位置请留空,无需填写。继续向下滚动页面。如下截图。
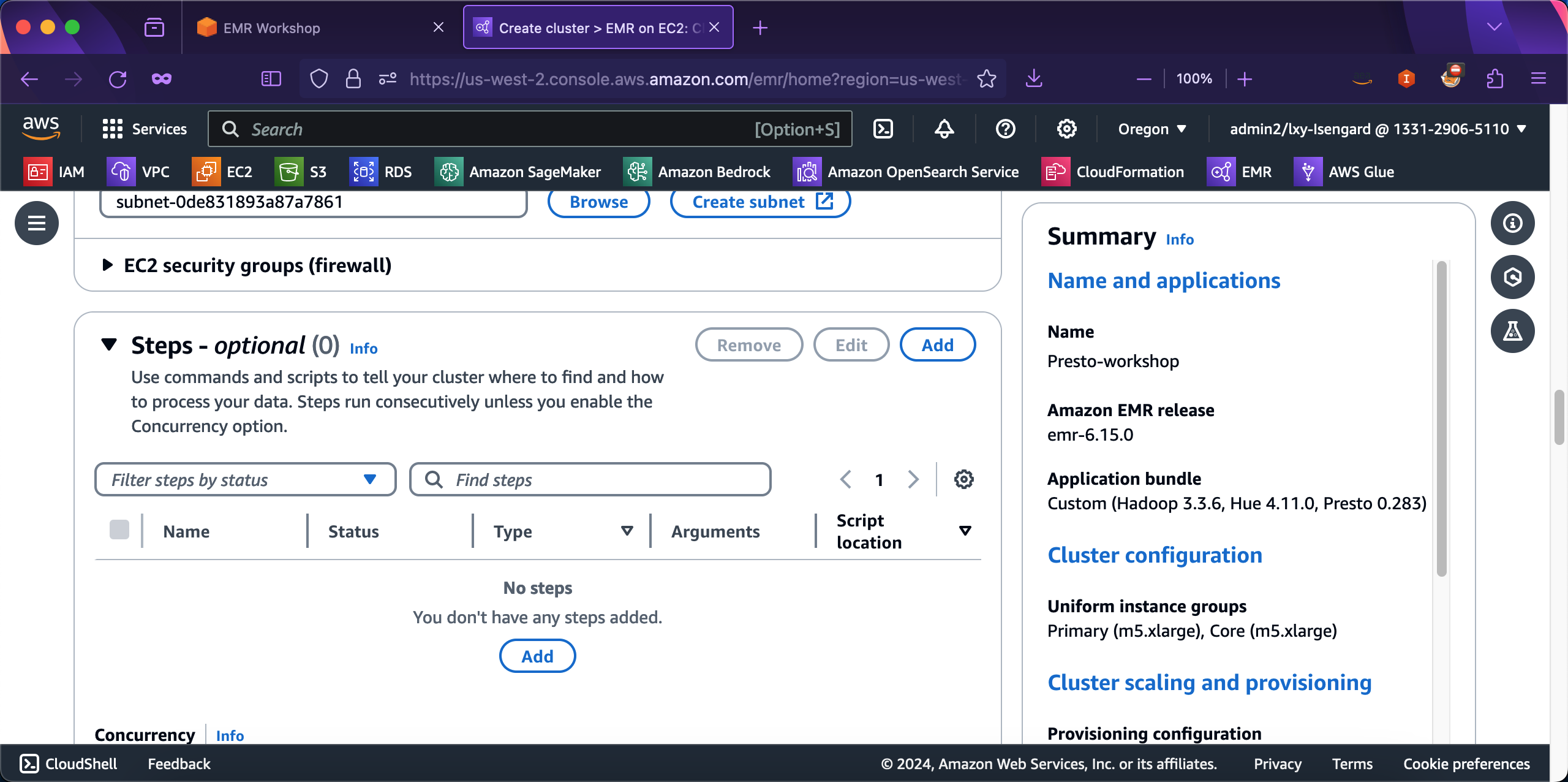
EMR创建向导默认选中的是Automatically terminate cluster after idle time (Recommended),则表示创建的EMR集群是短时任务集群,任务运算完毕后会自动终止。自动终止也就是自动释放,相关EC2会被彻底删除。在集群终止配置界面,选择Manually terminate cluster,这表示创建的是长时运行集群,不会自动关闭和终止,只能手工删除集群。此外,Use termination protection选项是一个防止意外删除EC2的选项,推荐选中。在可选的Bootstrap actions位置,留空,不需要设置。如下截图。
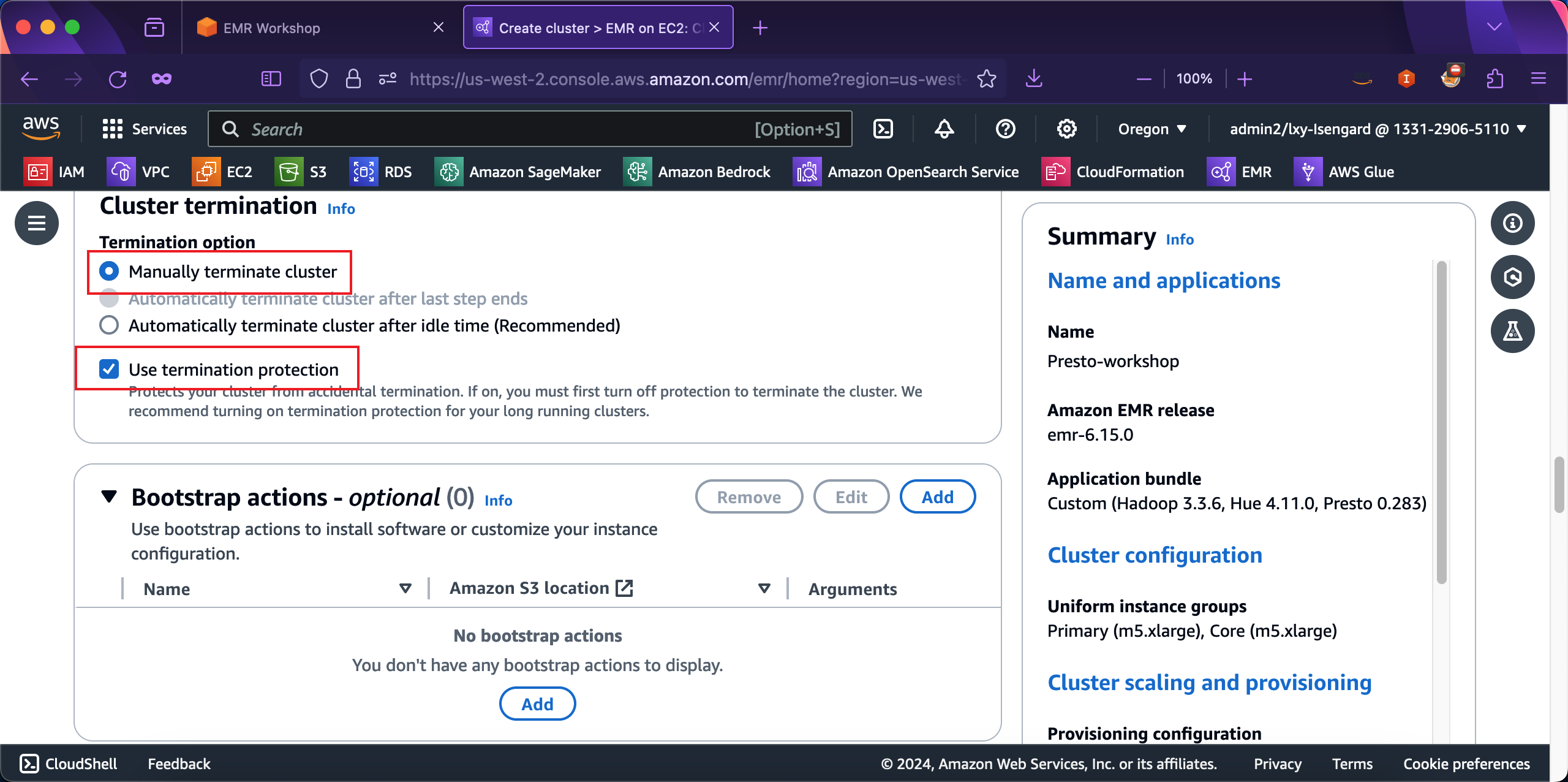
在可选的Cluster logs位置,填写上CloudFormation自动生成的S3存储桶s3://emr-dev-exp-123456789012/logs,其中12位数字是AWS账户ID。在存储桶名后加上logs表示存放日志的目录。接下来继续向下滚动屏幕。如下截图。
在可选的Tag标签位置,跳过,无需输入。在可选的Software settings位置,跳过,无需输入。如下截图。
在Security configuration and EC2 key pair位置,在第一项Security configuration位置留空,不需要输入。在第二项登录到EC2使用的SSH密钥这里,点击浏览Brows按钮,选中本区域可用的EC2登录密钥。如下截图。
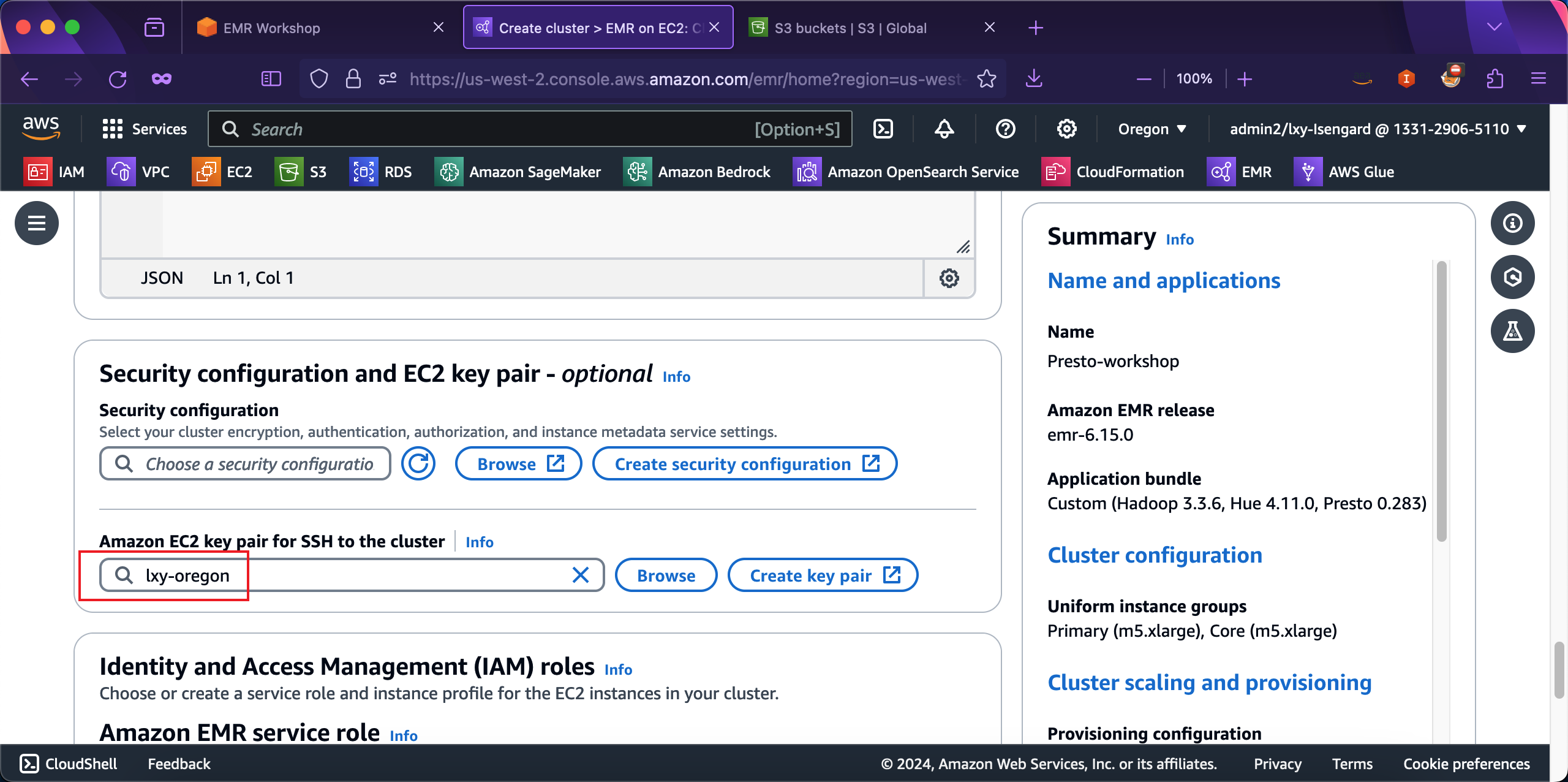
在Amazon EMR service role配置部分,选择第一项Choose an existing service role,然后从下拉框中选中名为EMR_DefaultRole这个角色。如下截图。
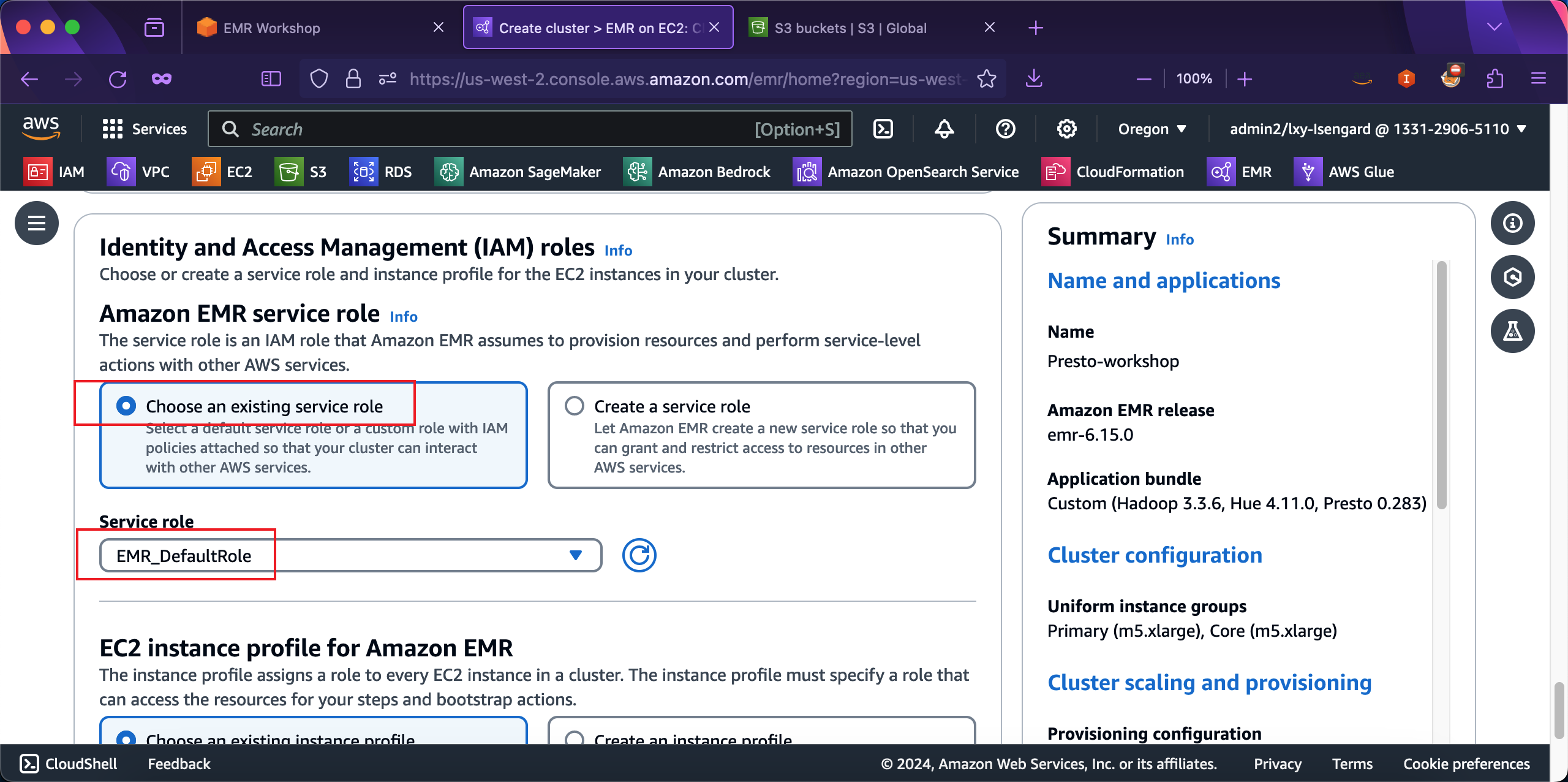
然后在EC2 instance profile for Amazon EMR位置,选择Choose an existing instance profile,然后从下拉框中选择名为EMR_EC2_DefaultRole的角色。如下截图。
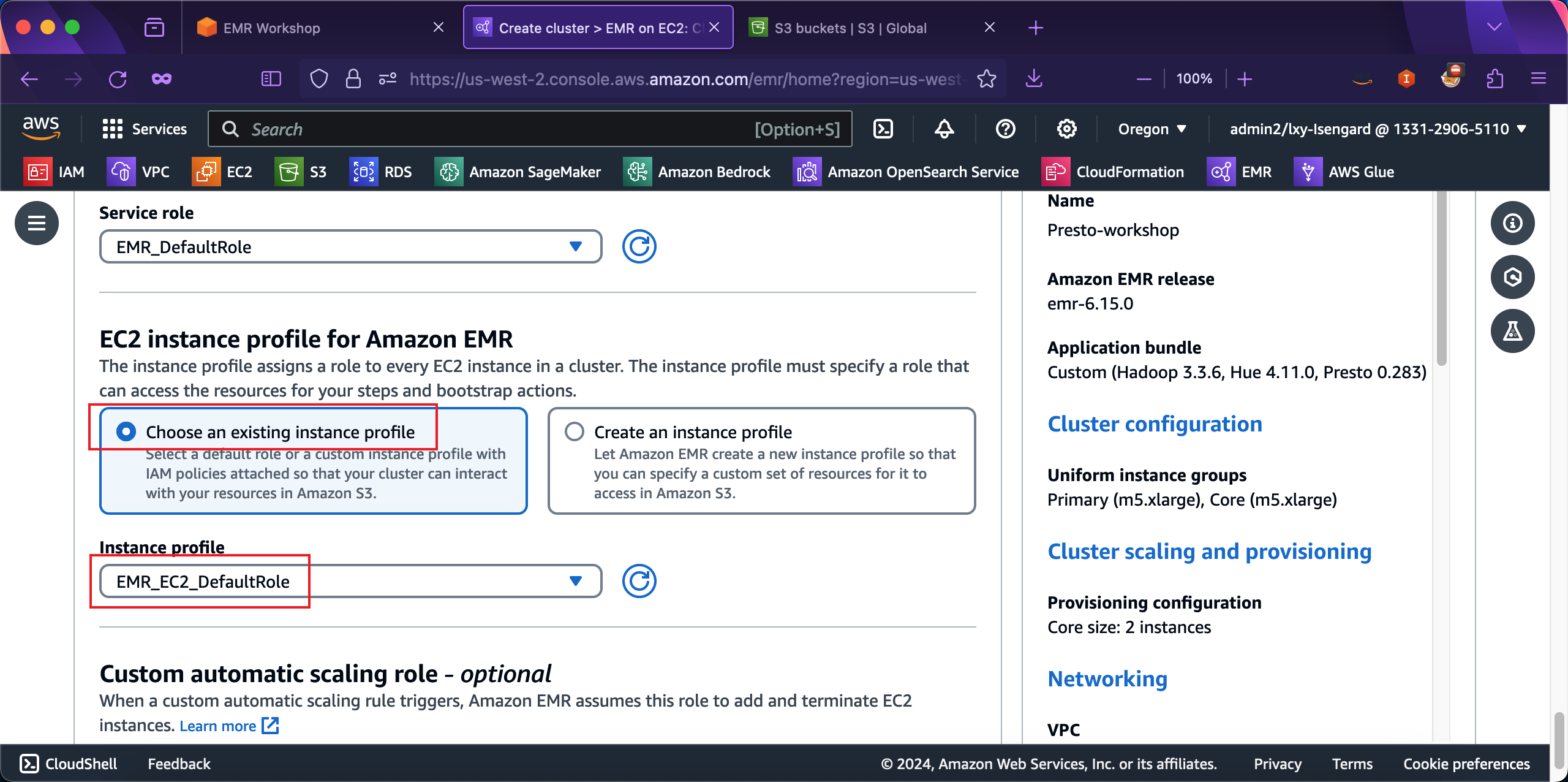
在创建向导最后一项,在Custom automatic scaling role位置,从下拉框中选择EMR_Autoscaling_DefaultRole。最后可以点击右下角的创建按钮了。
至此创建集群完成。
4、使用AWSCLI创建EMR集群用于Presto(可选)
在本实验的上篇中,介绍了通过AWSCLI创建集群的方法。在创建好的集群上,点击Clone in AWS CLI,即可复制对应的脚本。如下截图。
如果希望直接使用的话,需要替换其中的AWS账户、S3存储桶路径、VPC ID、子网ID、安全规则组、IAM Role等。
aws emr create-cluster \
--name "Presto-workshop" \
--log-uri "s3n://emr-dev-exp-133129065110/logs/presto-workshop/" \
--release-label "emr-6.15.0" \
--service-role "arn:aws:iam::133129065110:role/EMR_DefaultRole" \
--termination-protected \
--ec2-attributes '{"InstanceProfile":"EMR_EC2_DefaultRole","EmrManagedMasterSecurityGroup":"sg-081d6bd2f2e24eb49","EmrManagedSlaveSecurityGroup":"sg-0a73ac72d490b95ae","KeyName":"lxy-oregon","AdditionalMasterSecurityGroups":[],"AdditionalSlaveSecurityGroups":[],"SubnetId":"subnet-0de831893a87a7861"}' \
--applications Name=Hadoop Name=Hue Name=Presto \
--configurations '[{"Classification":"presto-connector-hive","Properties":{"hive.metastore.glue.datacatalog.enabled":"true"}}]' \
--instance-groups '[{"InstanceCount":1,"InstanceGroupType":"MASTER","Name":"Primary","InstanceType":"m5.xlarge","EbsConfiguration":{"EbsBlockDeviceConfigs":[{"VolumeSpecification":{"VolumeType":"gp2","SizeInGB":32},"VolumesPerInstance":2}]}},{"InstanceCount":2,"InstanceGroupType":"CORE","Name":"Core","InstanceType":"m5.xlarge","EbsConfiguration":{"EbsBlockDeviceConfigs":[{"VolumeSpecification":{"VolumeType":"gp2","SizeInGB":32},"VolumesPerInstance":2}]}}]' \
--auto-scaling-role "arn:aws:iam::133129065110:role/EMR_AutoScaling_DefaultRole" \
--scale-down-behavior "TERMINATE_AT_TASK_COMPLETION" \
--region "us-west-2"
5、登录到EMR集群的Master节点使用Presto提交查询
进入EMR服务界面,点击EMR集群的名称,进入详情界面。如下截图。
点击EMR集群界面上Cluster management下的Connect to Primary node using SSM的按钮。如下截图。
在弹出的界面中选择标签页Session Manager,点击Connect连接按钮。如下截图。
在打开的SSH窗口内,输入sudo -i成为root身份,运行如下命令启动Presto。
presto-cli --catalog hive
如下截图。
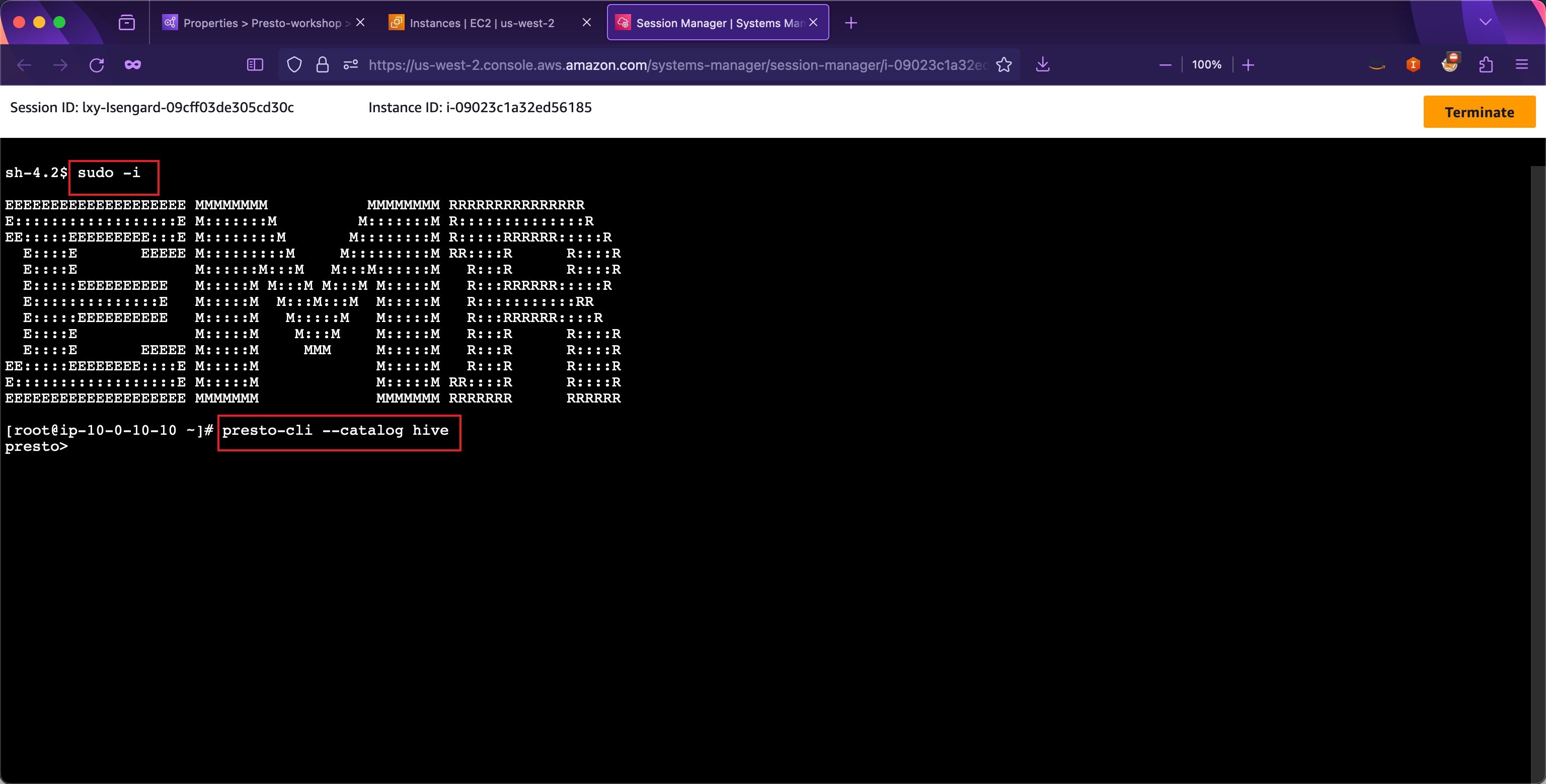
在上一步的Glue爬虫扫描数据的时候,已经创建好了presto_workshop_db库和taxi表。现在执行查询命令:
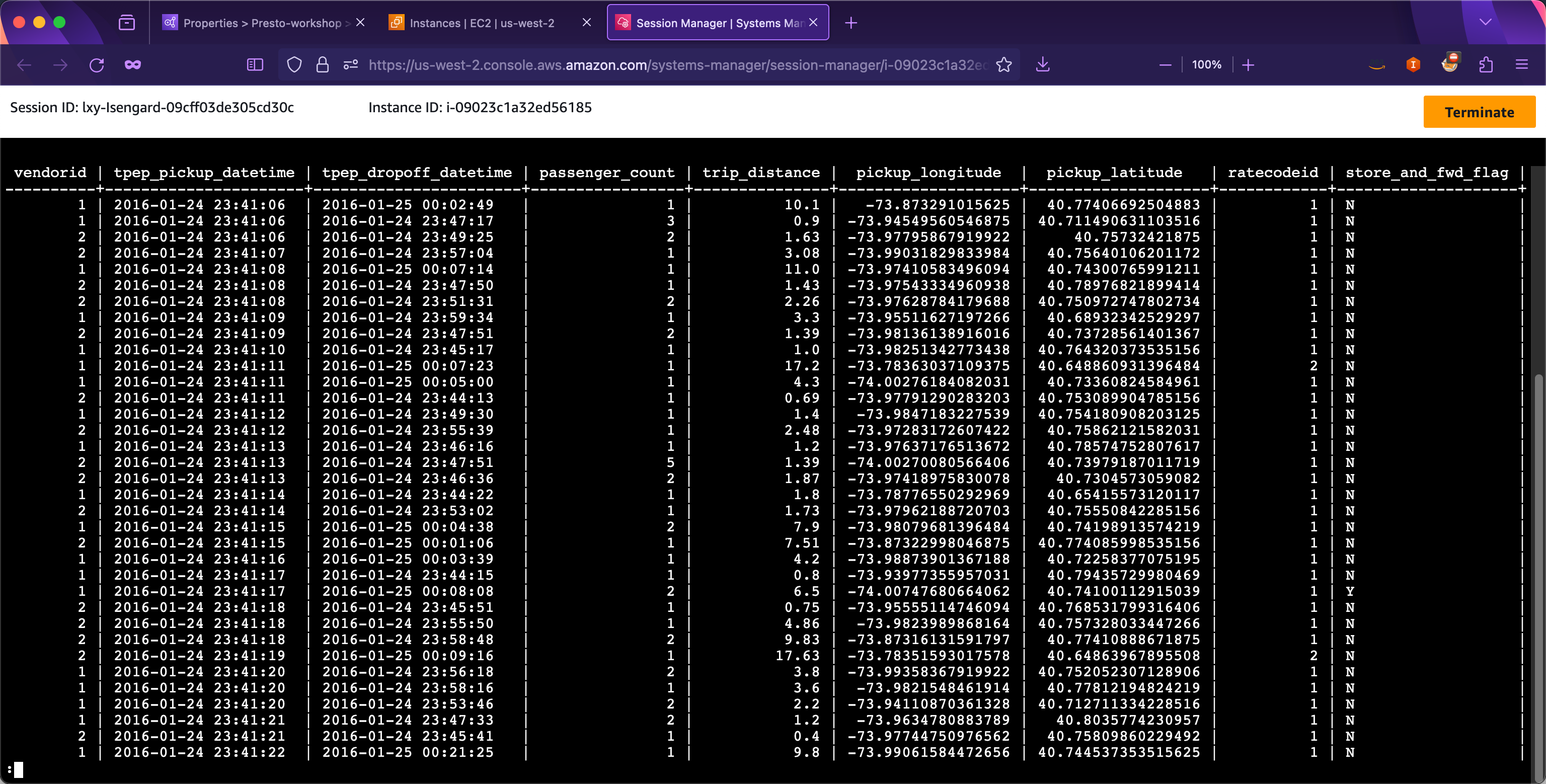
SELECT * FROM presto_workshop_db.taxi limit 50;
这一步将从纽约出租车交通数据集进行查询。执行结果如下,可以看到Presto执行返回了结果。
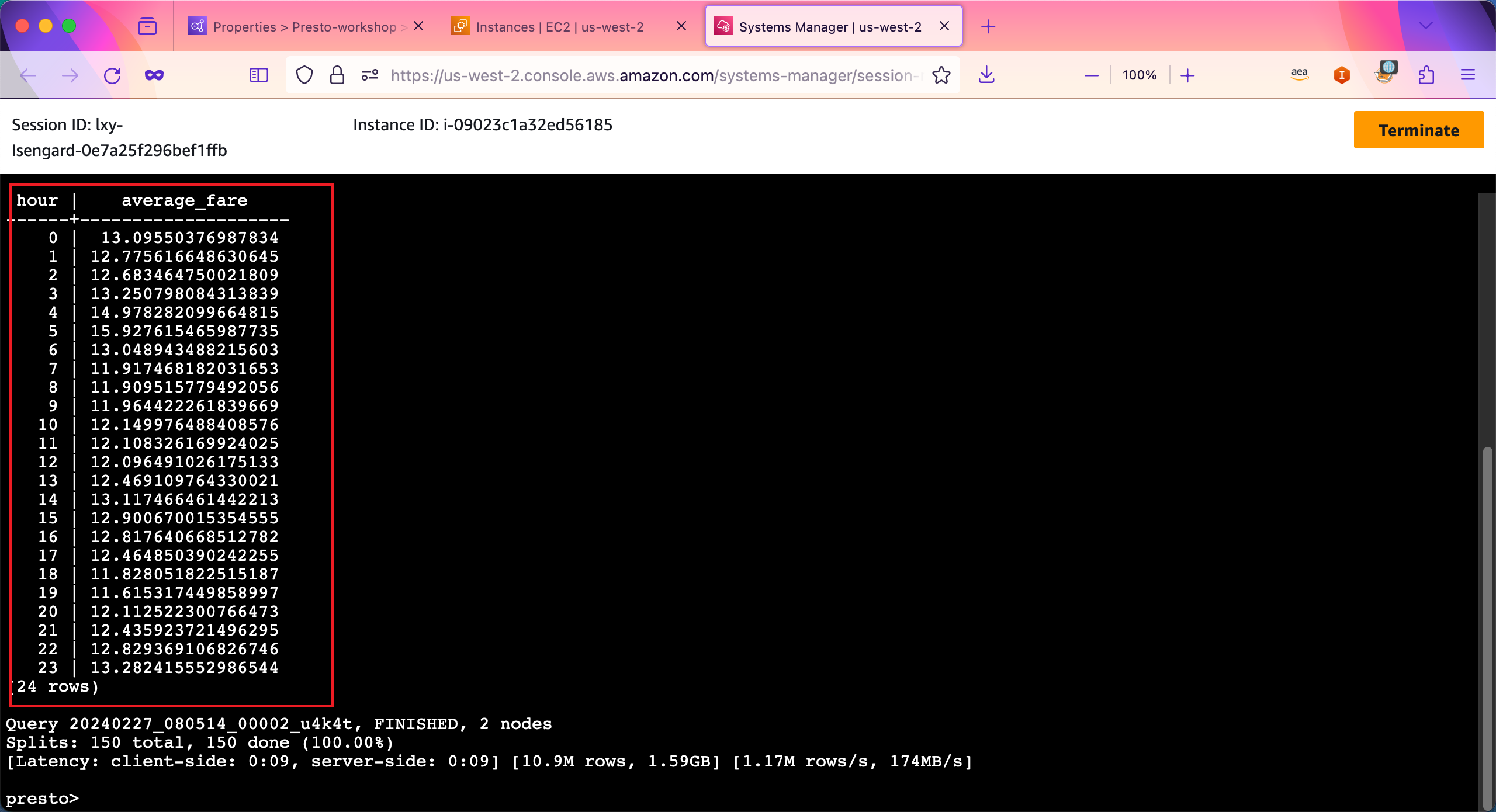
接下来运行稍微复杂的查询,分别查询0~23点,每个小时的中每一单的平均计费金额。
SELECT EXTRACT (HOUR FROM tpep_pickup_datetime) AS hour, avg(fare_amount) AS average_fare FROM presto_workshop_db.taxi GROUP BY 1 ORDER BY 1;
由此查询可看到,平均每小时的价格都在11~13之间,其中凌晨4点平均单价最高。查询结果如下截图。
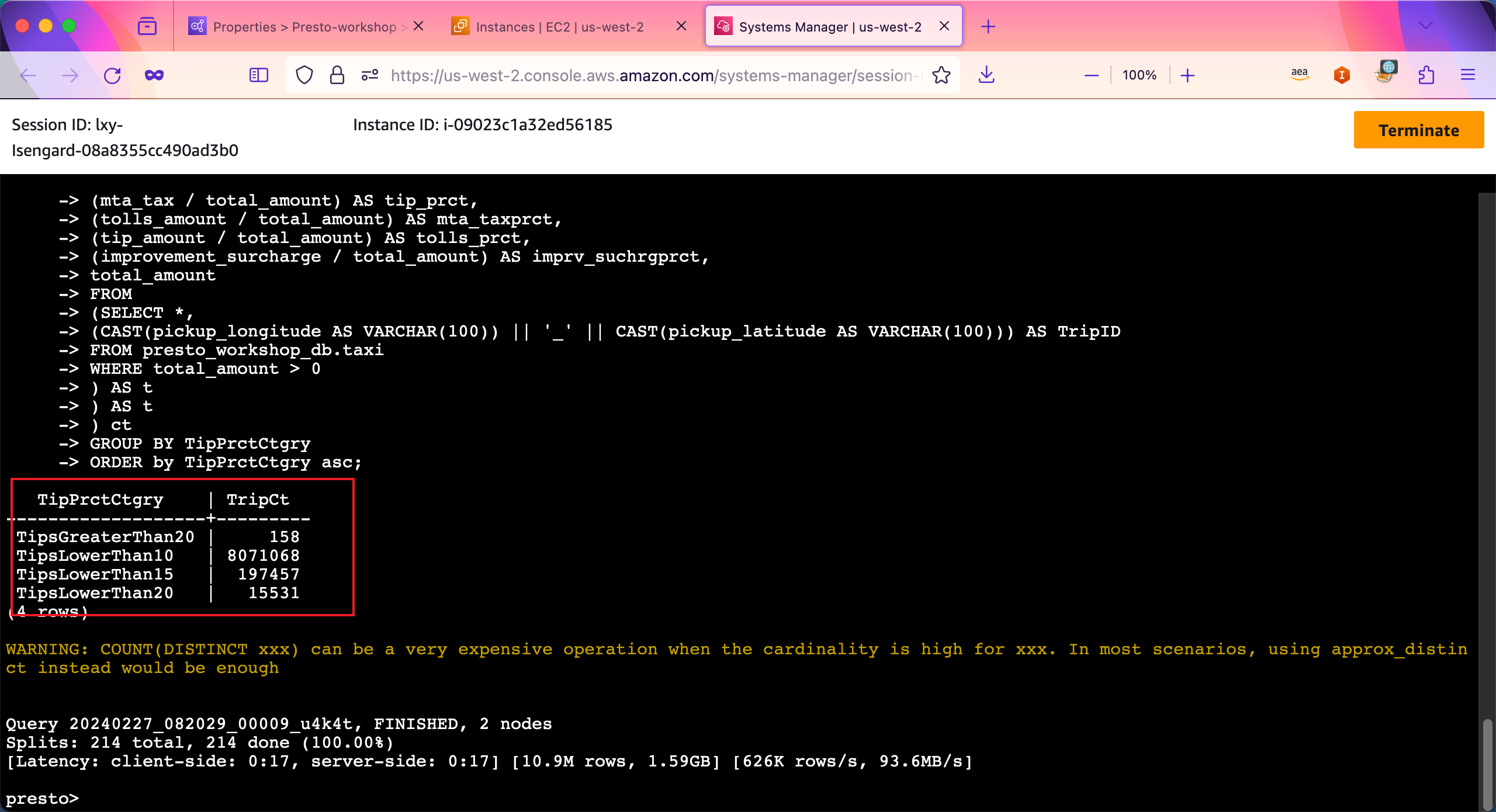
现在运行复杂的查询。如下查询将列出消费小于10%的(标记为TipsLowerThan10)、小于15%的(标记为TipsLowerThan15)、小于20%的(标记为TipsLowerThan20)、大于20%的(标记为TipsGreaterThan20)的总数。
SELECT TipPrctCtgry,
COUNT (DISTINCT TripID) TripCt
FROM
(SELECT TripID,
(CASE
WHEN fare_prct < 0.7 THEN 'FL70'
WHEN fare_prct < 0.8 THEN 'FL80'
WHEN fare_prct < 0.9 THEN 'FL90'
ELSE 'FL100'
END) FarePrctCtgry,
(CASE
WHEN tip_prct < 0.1 THEN 'TipsLowerThan10'
WHEN tip_prct < 0.15 THEN 'TipsLowerThan15'
WHEN tip_prct < 0.2 THEN 'TipsLowerThan20'
ELSE 'TipsGreaterThan20'
END) TipPrctCtgry
FROM
(SELECT TripID,
(fare_amount / total_amount) AS fare_prct,
(extra / total_amount) AS extra_prct,
(mta_tax / total_amount) AS tip_prct,
(tolls_amount / total_amount) AS mta_taxprct,
(tip_amount / total_amount) AS tolls_prct,
(improvement_surcharge / total_amount) AS imprv_suchrgprct,
total_amount
FROM
(SELECT *,
(CAST(pickup_longitude AS VARCHAR(100)) || '_' || CAST(pickup_latitude AS VARCHAR(100))) AS TripID
FROM presto_workshop_db.taxi
WHERE total_amount > 0
) AS t
) AS t
) ct
GROUP BY TipPrctCtgry
ORDER by TipPrctCtgry asc;
执行完毕,返回结果。如下截图。
接下来将使用WEB GUI来进行操作。
三、使用端口转发连接位于内网的EMR GUI管理界面
1、关于EMR开放远程访问GUI的建议
创建EMR时候,根据EMR集群所在的网络环境,有两种配置方式:
- 公开访问:将EMR的Master节点暴露在公网上,此时EMR的Master节点将位于Public子网,EMR节点有Elastic IP或者Public IP,安全组打开从互联网
0.0.0.0/0的地址入站请求。此时,可通过互联网访问; - 非公开访问:EMR部署位置可以是公有子网也可以是私有子网,但是EMR节点的安全组不开放从互联网
0.0.0.0/0的地址入站请求,此时,不能通过浏览器访问,EMR的GUI界面只能从VPC内网访问。
第二种配置方式,明显的更加安全,但是也带来不便,因为不能直接从互联网访问,所以需要额外考虑网络方案。
2、使用不同方式访问EMR GUI的对比
(1) 方法1-专线
在生产环境中,一般使用Direct Connect专线服务,从用户所在地(如办公室)链接到AWS云端VPC内。此时,只要在开发者所在本机上,直接访问EMR集群的VPC内网IP即可,并且所有流量都经过专线。本方法需要专线,因此一般只在生产环境具备使用条件。
(2) 方法2-跳板机
在开发、测试等环境中,可能没有部署专线,此时还需要访问VPC内网的EMR GUI界面。针对这种场景,一般可考虑使用Workspaces服务作为云桌面跳板机,或者是在VPC内创建一个Windows系统的EC2虚拟机,使用RDP远程桌面登录到Windows后,打开浏览器,即可访问EMR的GUI界面。本方案需要额外创建用于跳板机的Workspaces,有额外Cost,另外对于新用户而言配置步骤复杂,相对麻烦。
(3) 方法3-将EMR Master主节点公开、并创建SSH隧道
AWS的EMR官方文档中和英文Workshop中,推荐的方法与以上两种不同,而是另一种方式。即将EMR的Master节点部署在Public子网,并使其具有公网IP,同时开放SSH端口允许互联网登录,但在安全规则组中,禁用来自互联网请求对EMR的GUI端口的访问。
然后,在开发者本机使用SSH工具连接到EMR的Master节点的SSH 22端口,建立转发隧道,在本机上配置一个Sock5隧道。接下来,在本机浏览器上安装Proxy选择插件吗,并配置本机浏览器根据浏览的目标地址自动选择访问路径,包括直接互联网访问、以及通过Sock5隧道访问EMR的GUI。
如此一套组合拳下来,就实现了开发者本机的浏览器即可同时访问互联网,也可以无缝切换的访问EMR的GUI。当然,开发者本机的SSH窗口是不能中断的。详细介绍在官网文档这里。
以上方案虽然是官方推荐的方案,但是有以下问题:
- 从开发者本机,通过普通的互联网,跨国连接到海外某一个公网地址的SSH端口,这个访问路径是非常差的,随时遇到GFW干扰,断线率非常高,而且“假断线”的状态会失去响应很痛苦。
- 开发者本机浏览器安装Proxy切换插件,步骤复杂,需要编写Proxy代理文件脚本,修改其中的域名,来实现无缝切换,这一过程对没有相关使用经验的用户很不友好
因此本文实验将不推荐这个方式。
(4) 方法4-使用Session Manager转发
Session Manager在本EMR实验已经多次使用,主要用于登录EMR Master节点的SSH进行提交任务。除此以外,Session Manager还支持端口转发,可以将云端地址转发到本地。在以往这篇博客中介绍过使用Session Manager登录EC2。现在本文将使用Session Manager登录。
首先开发者本机需要安装有AWSCLI,并配置了正确的AKSK密钥。然后从官网点击->这里地址,下载Session Manager for AWSCLI插件。插件支持Windows、Linux、MacOS,各种系统都可以安装。
以M1处理器的MacOS为例,运行如下命令:
curl "https://s3.amazonaws.com/session-manager-downloads/plugin/latest/mac_arm64/sessionmanager-bundle.zip" -o "sessionmanager-bundle.zip"
unzip sessionmanager-bundle.zip
sudo ./sessionmanager-bundle/install -i /usr/local/sessionmanagerplugin -b /usr/local/bin/session-manager-plugin
session-manager-plugin
当返回如下信息,则表示安装成功:
The Session Manager plugin was installed successfully. Use the AWS CLI to start a session.
3、使用Session Manager连接到Presto GUI
请确认按照上一步,配置好了AWSCLI、AKSK密钥、Session Manager插件for AWSCLI。
接下来通过EMR控制台,查询EMR主节点的EC2 Instance对应的ID。进入EMR集群界面,从Cluster Management下,获取其Primary node public DNS,点击小方块可将其复制到剪贴板。如下截图。
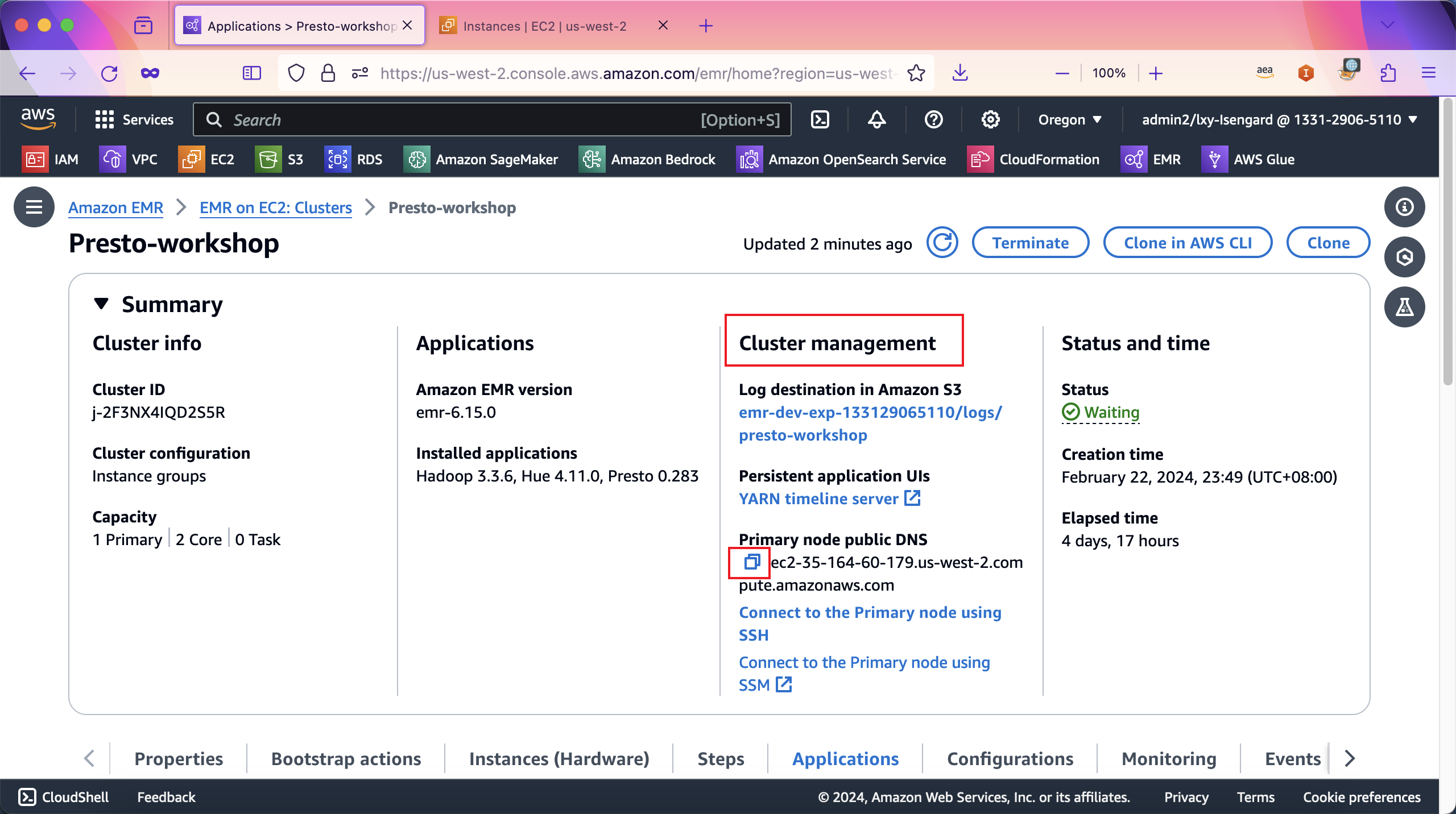
将名称复制到EC2控制台上,输入到搜索框后,当前过滤后显示的EC2就是EMR的Master节点。选中这个EC2实例,点击下方的Details详情标签页,其中Instance ID就是需要复制下来的名字。点击名字前的小方块可将其复制到剪贴板。如下截图。
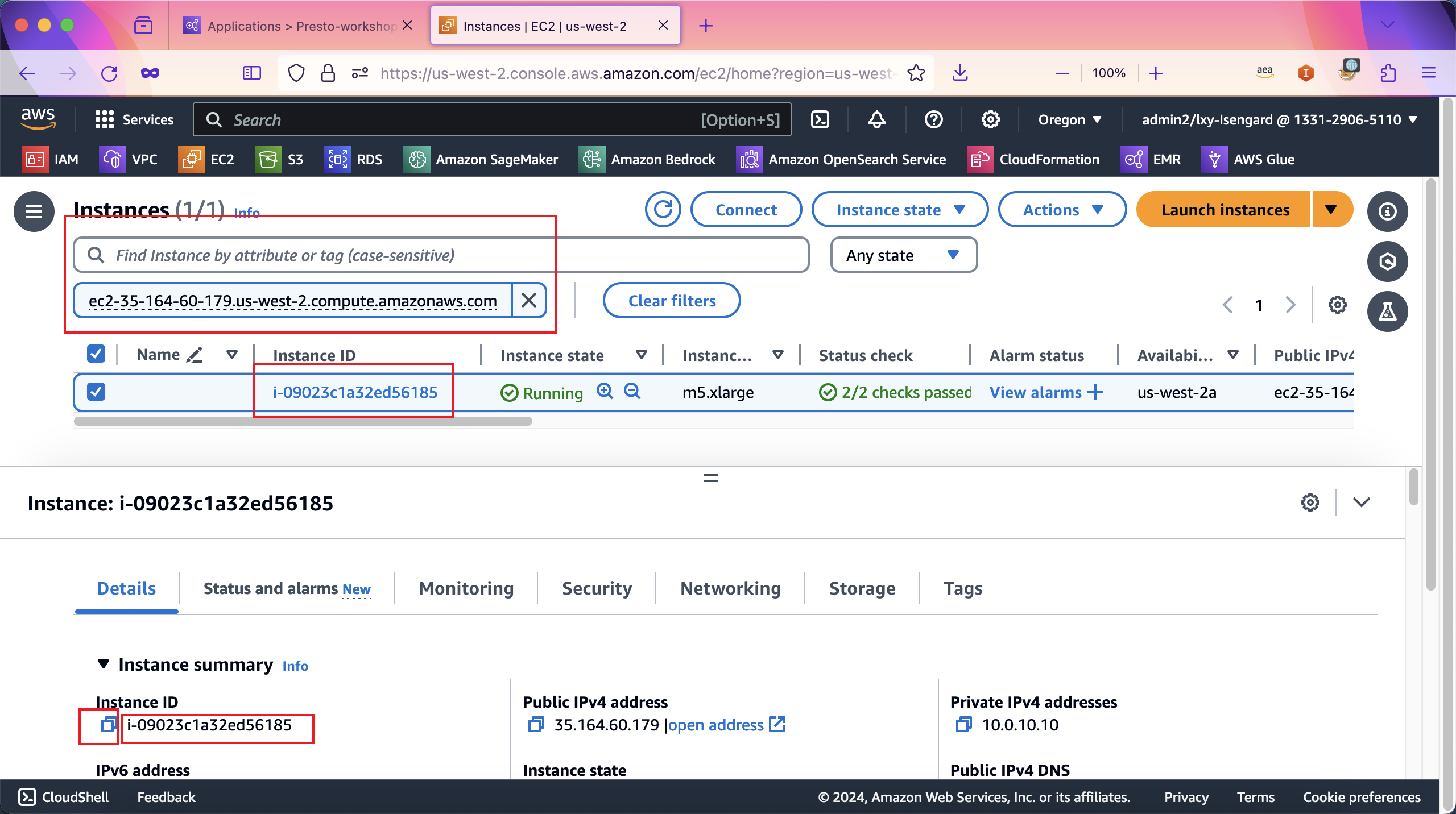
现在构造如下命令,替换其中region为本实验所在的区域,在target部分替换为上一步复制下来的Instance ID,在host位置,将第一步复制下来的Primary node public DNS代入。最后是Presto GUI的端口8889,开发者本机端口映射为58889。
aws ssm start-session \
--region us-west-2 \
--target i-09023c1a32ed56185 \
--document-name AWS-StartPortForwardingSessionToRemoteHost \
--parameters '{"host":["ec2-35-164-60-179.us-west-2.compute.amazonaws.com"],"portNumber":["8889"], "localPortNumber":["58889"]}'
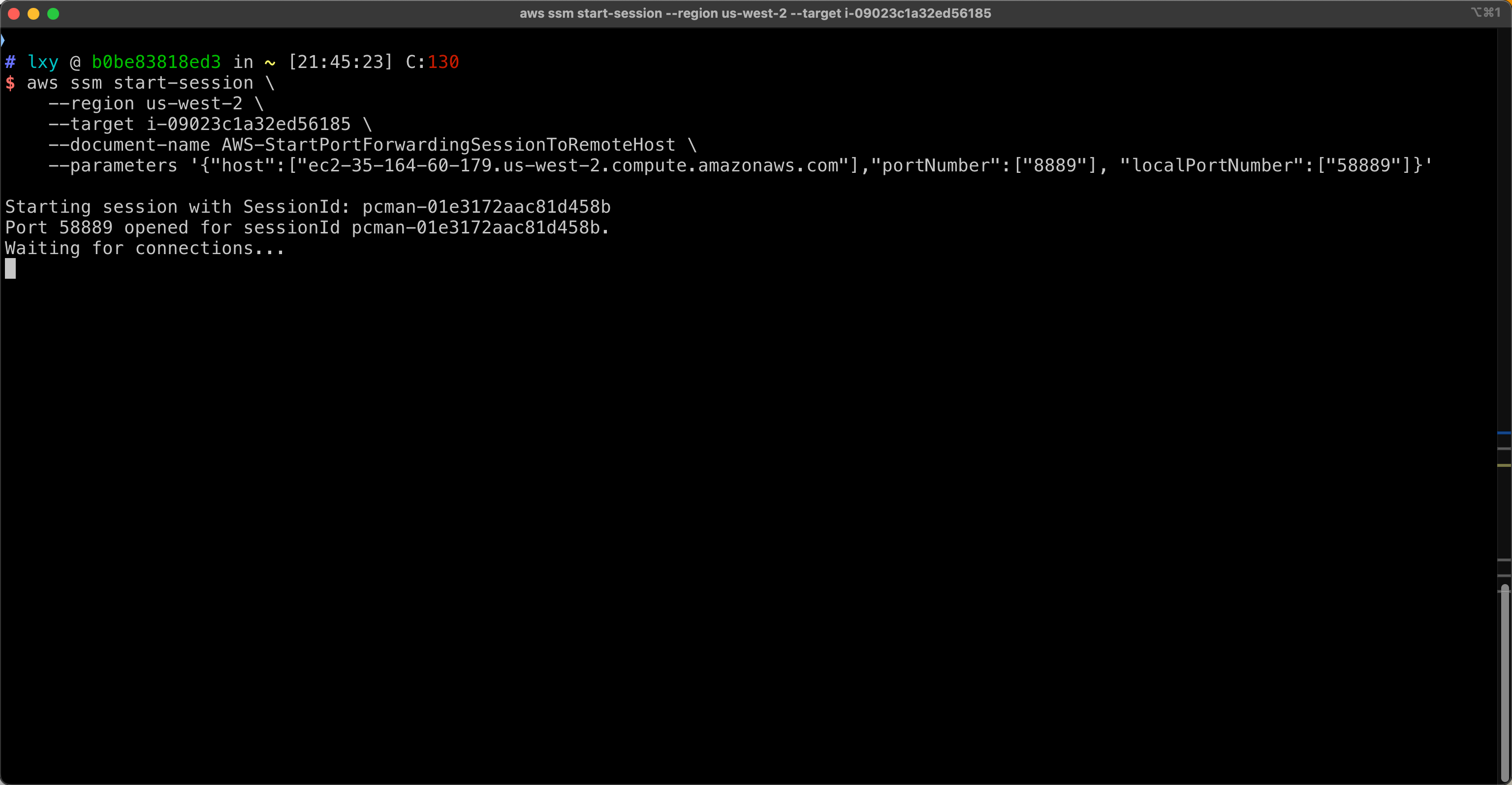
以上命令将EMR集群的Presto GUI所在的8889端口,转发到开发者本机的58889端口。在开发者本机执行。如下截图。
执行后,控制台返回如下:
Starting session with SessionId: xxxxx-01e3172aac81d458b
Port 58889 opened for sessionId xxxxx-01e3172aac81d458b.
Waiting for connections...
连接成功。如下截图。
现在打开浏览器,访问本机http://localhost:58889。注意这里不带https,是http。可看到访问成功。如下截图。
由此确认访问Presto GUI成功。这里注意,Session Manager的进程和窗口不要停止,一旦停止,Presto的8889端口转发就会中断。
4、使用Hue发起查询
按照以上相同方法,保持之前的Session Manager进程持续运行,可以在打开一个终端窗口,然后再启动一个Session Manager进程,连接Hue的GUI界面的8888端口。
构造命令如下。本命令只需要更改端口号,之前复制的EMR的Master节点的EC2的名称和ID都是不变化的,因为Presto和Hue是同一个集群。因此改下端口号,即可运行第二个Session Manager进程。
aws ssm start-session \
--region us-west-2 \
--target i-09023c1a32ed56185 \
--document-name AWS-StartPortForwardingSessionToRemoteHost \
--parameters '{"host":["ec2-35-164-60-179.us-west-2.compute.amazonaws.com"],"portNumber":["8888"], "localPortNumber":["58888"]}'
执行命令的过程与上一步相同。
现在打开浏览器,访问本机http://localhost:58888。注意这里不带https,是http。可看到访问成功。由于是第一次使用Hue,因此需要输入用户名和密码,点击Create Account按钮,这个新输入的用户名和密码就会成为superuser权限。如下截图。
登录到Hue界面成功。现在执行如下查询:
SELECT DAY_OF_WEEK(tpep_dropoff_datetime) as day_of_week, AVG(tip_amount) AS average_tip FROM presto_workshop_db.taxi GROUP BY 1 ORDER BY 1
这条命令表示查看周一到周日,每单平均的小费的数字。如下截图。
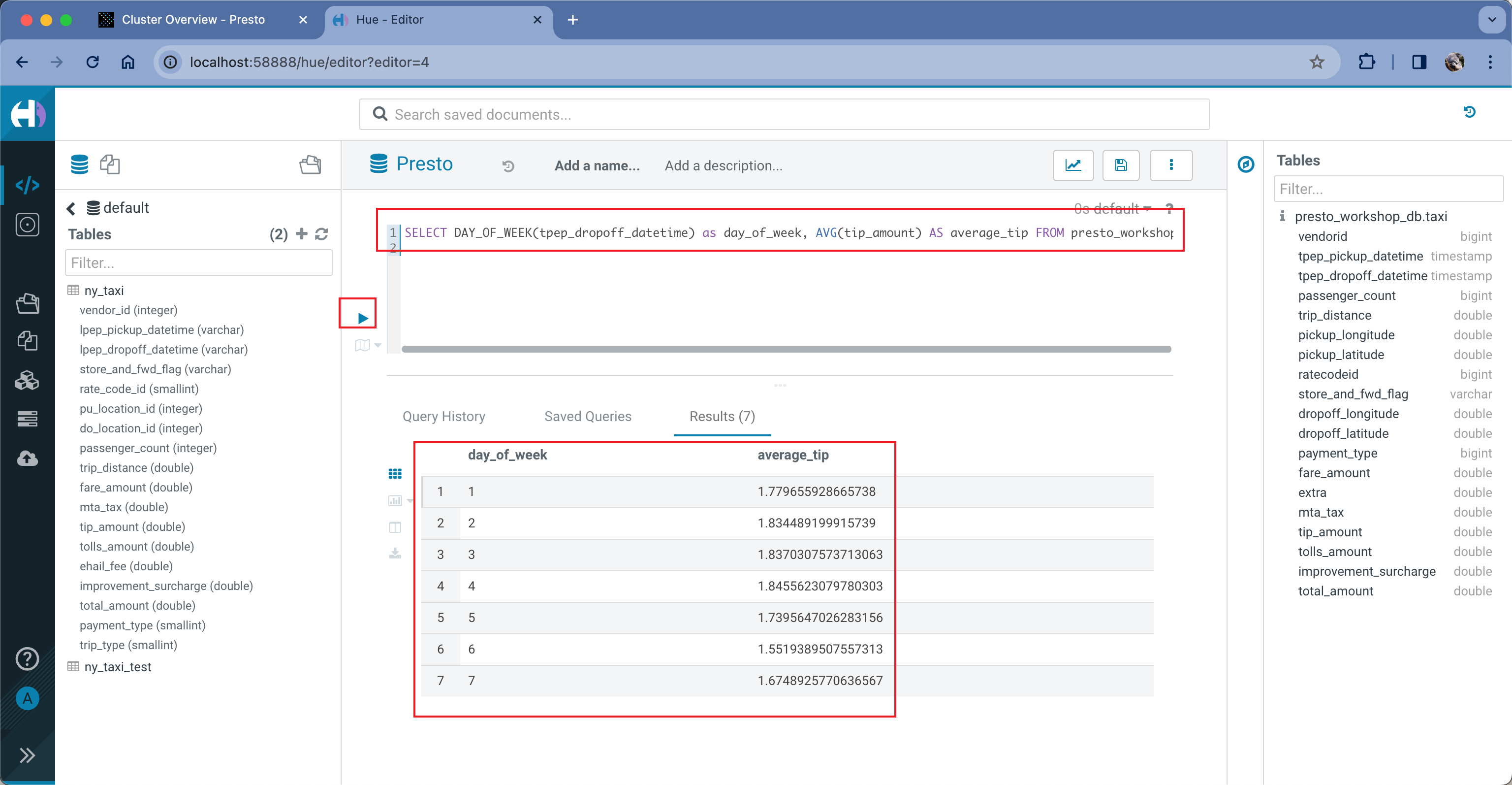
由此看到通过Hue提交Presto任务成功。此外,在任务执行中,还可以切换到Presto的GUI上(也就是本地58889端口),查看当前任务执行情况和资源占用情况。
至此实验完成。
四、参考文档
ETL on Amazon EMR Workshop
最后修改于 2024-03-01