优化S3存储成本:S3智能分层配合S3 Glacier即时检索获得成本节约
本文分析S3 Glacier即时检索的成本特性,通过对比直接使用与配合智能分层两种方案,揭示了数据访问频率对成本的影响,提供了实现存储成本优化的最佳实践方案。
一、背景
S3 Glacier Instant Retrieval(S3 GIR)存储类型是2021年re-Invent新发布的存储类型,原有的异步方式取回数据的Glacier存储类型则改名为S3 Glacier Flexible Retrieval。新发布的S3 Glacier Instant Retrieval的存储费用与S3 Glacier Flexible Retrieval相近,在此基础上提供了立刻可取的性能,适合每年访问2-3次数据场景下的海量数据存储。
S3 Glacier Instant Retrieval的特点如下:
- 从费用方面评估:以亚马逊云科技宁夏区域为例,异步取回的S3 Glacier Flexible Retrieval价格是0.027054元/GB,新的S3 Glacier Instant Retrieval是0.03006元/GB。成本增加不足1分钱,保持在同一个数量级。
- 从数据取回时间评估:原有S3 Glacier Flexible Retrieval是异步机制,取回数据需要几分钟到几小时,即便使用加急检索并支付额外费用,也需要几分钟才能返回数据。而S3 Glacier Instant Retrieval存储类型是访问数据立刻可用。
- 从性能方面而言,S3官网FAQ中提到S3 Glacier Instant Retrieval 提供与 S3 Standard 和 S3 Standard-IA 存储类相同的毫秒延迟和高吞吐量性能。
基于以上特点,本文将分析S3 Glacier Instant Retrieval存储类的最佳使用场景,并结合S3智能分层特性优化成本。
二、是否使用智能分层的的对比
1、数据集假设和基础费用对比
由于智能分层的特性要求文件大小大于128KB,因此本文测算的场景定义如下:
- 数据集容量是50TB,即50000GB;
- 平均文件大小1MB,且单个文件大于128KB;
- 文件在年初被一次性全量写入,并保存12个月满1年;
- 一年期间数据经历几次读取,每次读取是全量读取。
为更好的对比成本,这里将读写等基础费用列表如下。
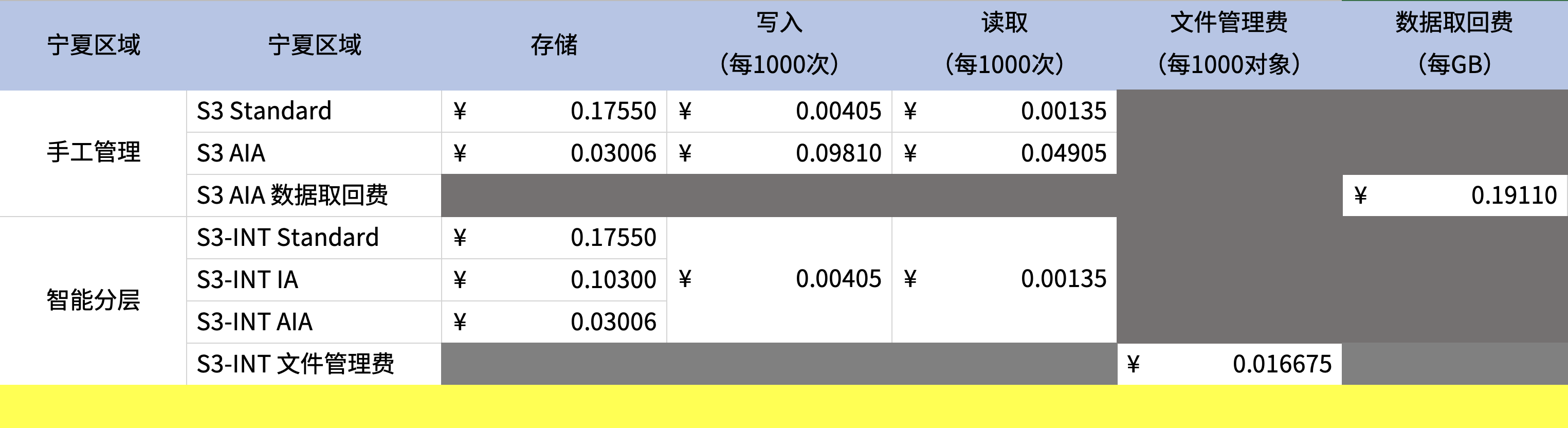
2、不使用智能分层、直接将数据保存在Glacier Instant Retrieval存储类
(1)基础费用
如果直接将文件保存到S3 Glacier Instant Retrieval,则主要成本如下(以宁夏区域为例):
- 写入费(PUT、COPY 或 POST 请求):每1000个请求 ¥0.0981
- 存储成本:每GB ¥0.03006/月
- 读取费(GET、SELECT 及所有其他请求):每10000个请求 ¥0.4905
- 数据检索:每GB ¥0.1911
注意:如果数据写入到S3标准层,而后通过生命周期转换存储级别为S3 Glacier Instant Retrieval,那么还要收取转换费每1000个请求 ¥0.0981。由于本例的测算直接写入S3 Glacier Instant Retrieval因此没有生命周期转换费。
由此可以看到,上传文件时候,直接声明写入S3 Glacier Instant Retrieval存储类,从写入的那一刻即第一天起,存储空间成本上就获得了显著的降低。不过,由此产生的写入费是S3 Standard标准级别的24倍,而后读取时候产生的读取收费是S3 Standard标准级别的36倍,并额外收取读取S3 Standard标准级别并不存在的数据检索费。在此场景下,如果数据在几个月内多次读取将产生大量访问费用,这部分开销甚至可能超过存储容量上节约出来的费用。
(2)访问场景测算
为了进一步测算多次读取后产生的升本影响,我们模拟一年内数据分别被全量读写1次到10次,其成本计算后如下表。
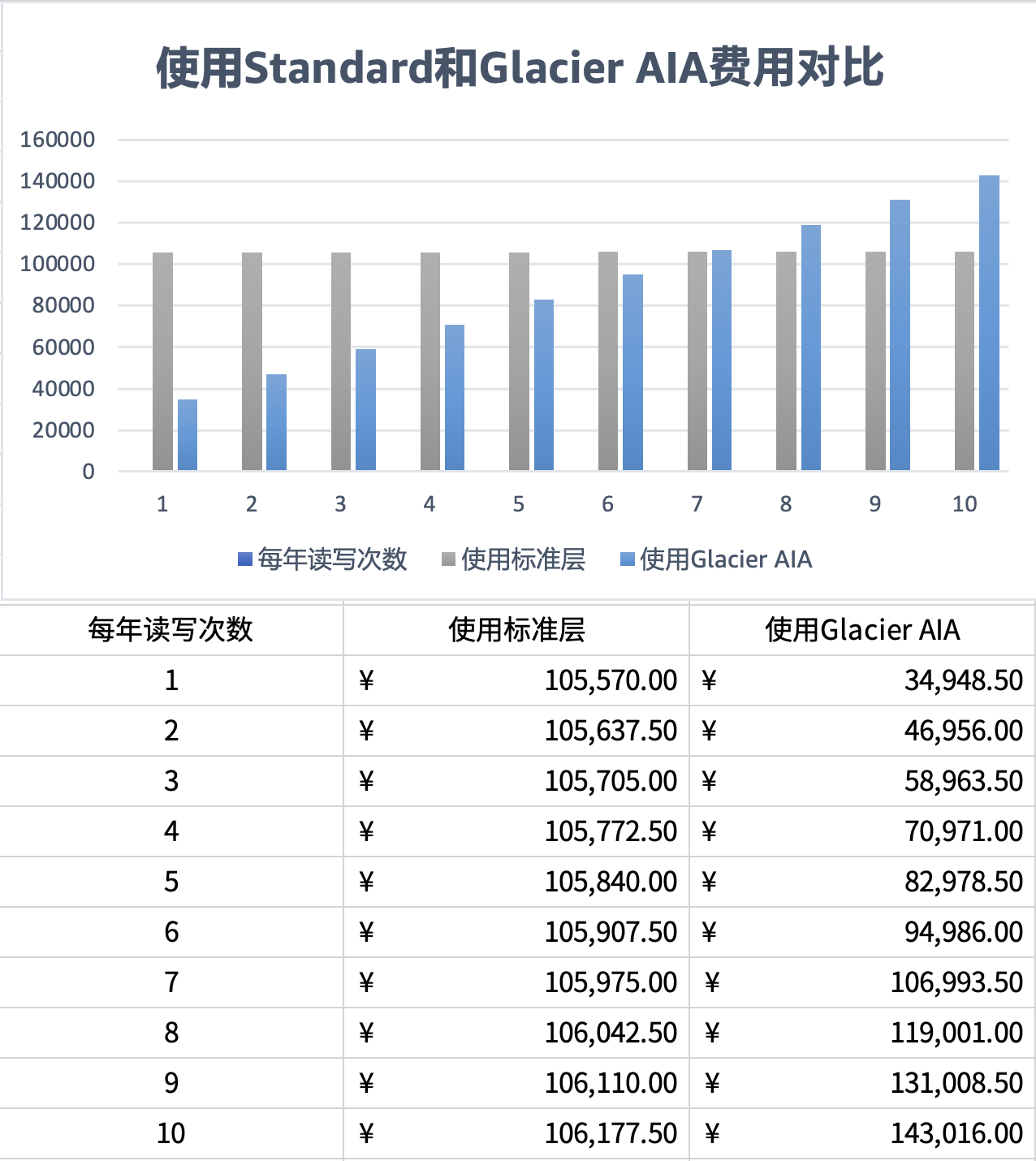
以本文的数据样本为例,当每年数据读写6次后,S3 Glacier Instant Retrieval总体成本和使用S3标准类相当。读取次数大于6次后,读写越多总体成本越高。
(3)结论
综上所述,直接使用S3 Glacier Instant Retrieval的场景需要有明确的数据冷热特征,或需要人为的定义数据访问方式,确保数据读取频率足够低才能产生成本节约。如果已经预期要到发生大量频繁读取,建议先将数据从S3 Glacier Instant Retrieval复制回到S3标准类,然后对S3标准层发起频繁访问即可。
以上如果不希望对以上存储的生命周期做手工管理,则可以引入S3智能分层特性。
3、使用S3智能分层自动将数据下沉到S3 Intelligent-Tiering - Archive Instant Access Tier(S3-INT AIA)
(1)基础费用
在S3 Glacier Instant Retrieval存储类发布后,S3智能分层存储支持的存储分级也新增了名为S3 Intelligent-Tiering - Archive Instant Access Tier(S3-INT AIA)这一级别的存储。当数据保存在S3智能分层存储级别时,S3将根据文件最后访问时间来决定存储级别并适用不同费率:
- 写入费(PUT、COPY、POST 或 LIST 请求):每1000个请求 ¥ 0.00405
- 刚写入的30天内,存储费按照S3标准级(S3-INT Frequent Access)收费,每GB ¥0.1755/月
- 文件最后一次被访问的30天内,存储费按照S3标准级(S3-INT Frequent Access)收费,每GB ¥0.1755/月
- 文件最后一次访问后的30-90天将按照S3不频繁访问级别(S3-INT Infrequent Access)收费,每GB ¥0.1030029/月
- 文件最后一次访问后的90天以上将按照S3归档立刻取回级别(S3-INT Archive Instant Access)收费,每GB ¥0.03006/月
- 不过之前数据存储在那一层、以及最后被访问之后多少天,只要数据被再次访问,数据将被移动到S3智能分层标准级(S3-INT Frequent Access),未来30天重新按照S3-INT Frequent Access存储级别收费
- 以上所有场景的读取费(GET、SELECT 及所有其他请求):每1000个请求 ¥ 0.00135
- 数据检索:不收取
结合以上可看出,使用S3智能分层,写入时候成本就是按照标准层写入费用计算。读取时候不管数据当前保存在哪一层,始终按照S3标准层的读取费用去计算,因此即便发生多次读取费用也很少,不会发生前文描述的当读取次数大于7次后S3 Glacier Instant Retrieval存储类成本反而高于S3标准类的情况。
另外请注意,S3智能分层有如下适用范围和限制请予以考虑:
- 收取文件管理费。费用定义是每1000个对象收取 ¥0.016675。小于128KB级别的文件不被在内;
- 小于128KB的数据将始终保存在频繁访问层。
(2)访问场景测算
在享受到读取费用的好处后,对智能分层存储的调度逻辑可观察到:
- 第一个月新写入数据时候按照标准层存储因此存储费用最高,满30天没有被访问后的转为不频繁访问层,由此第二个月存储费降低;
- 满90天没被访问后,第4个月又显著降低;
- 当文件被读取时,文件将回到S3-INT FA存储层级收费;
- 直到再次经过下一个90天移动到S3-INT AIA按照最低存储成本计费。
这个逻辑的特点是,1年内读写频率足够低才会节省费用,如果隔一个月进行一次读取,那么数据还没有满足90天下沉的条件就又返回到最贵的标准层计费了。如此反复读取,意味着几乎全年数据都保存在标准层,也就没有实现成本节约的效果。
接下来我们模拟下这种场景,分别安排在不同的月份读取数据,测算访问频度对智能分层存储费的影响。
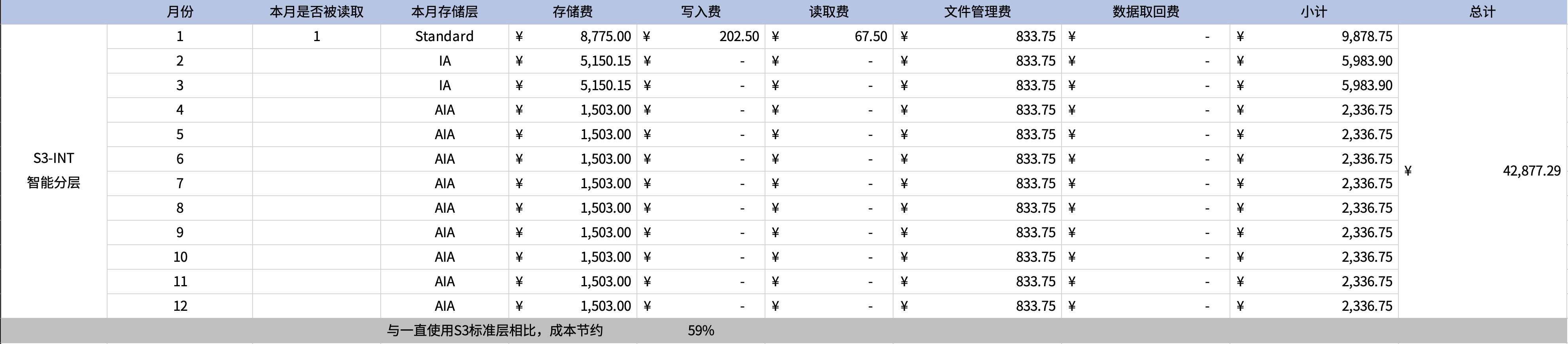
以下模拟数据在1月写入,然后在1月读取1次,后续没有读取的场景,成本节约为59%。
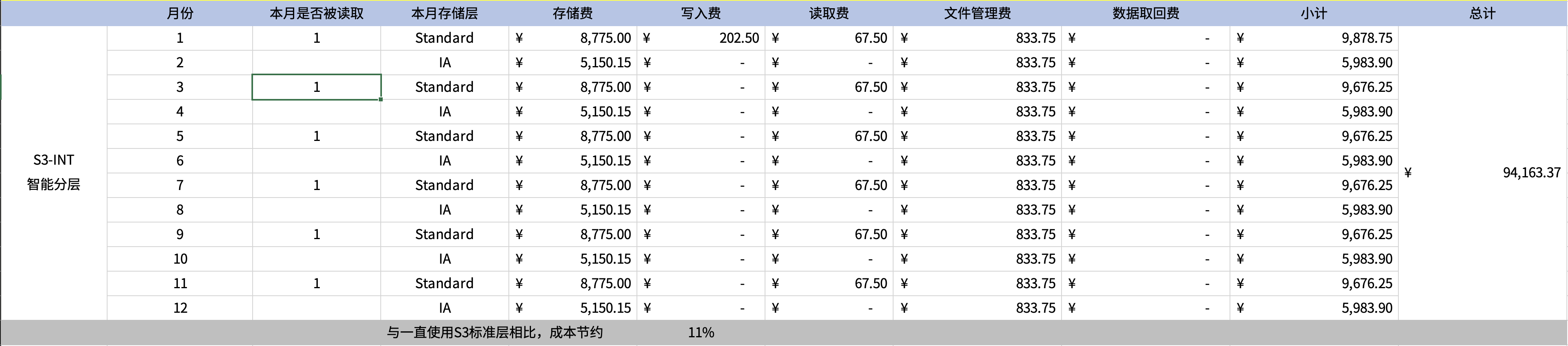
以下模拟数据在1月写入,然后在1月、3月、5月、7月、9月、11月各读写1次的场景,成本节约为11%。
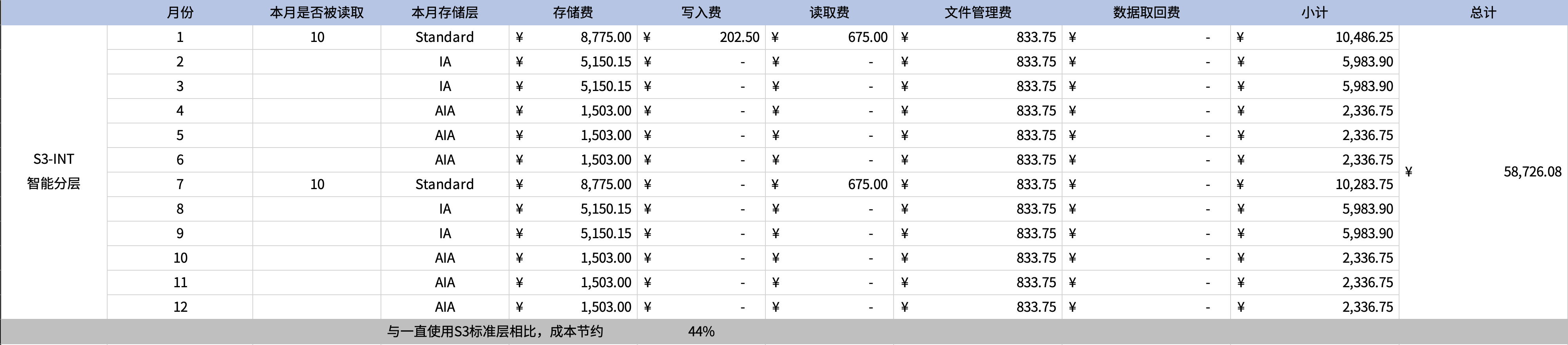
以下模拟数据在1月写入,然后在1月、7月、11月各读写1次的场景,成本节约为35%。
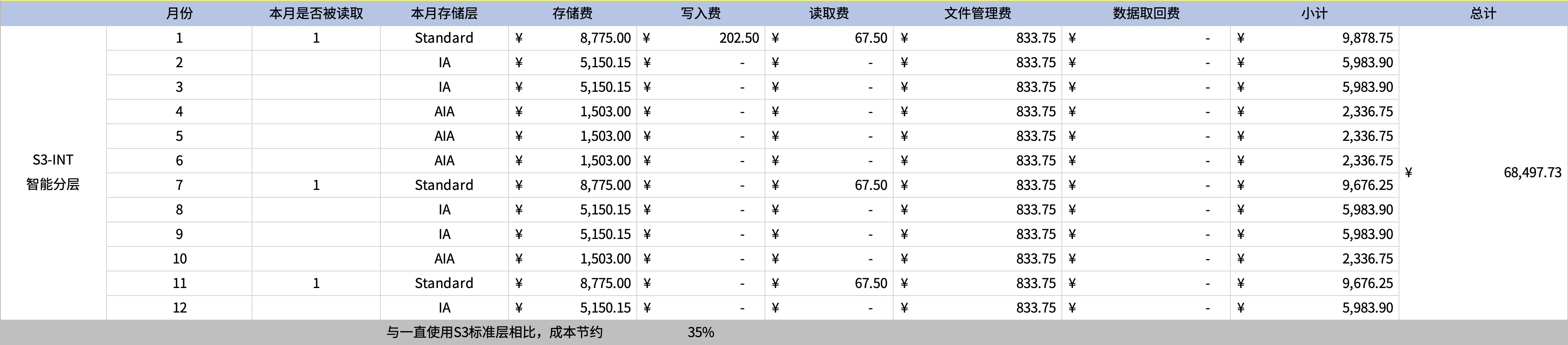
以下模拟数据在1月写入,1月读取10次,7月当月读写了10次,其他月份无读取的场景,成本节约为44%。
通过以上的场景可以看出,使用S3智能分层存储节约费用的秘诀是数据足够“冷”,或者两次访问间隔尽可能长。如果要对数据进行多次读写,建议集中在某窗口内(例如一个月)内集中完成数次读写,然后剩下的时间由S3智能分层自动的降低存储级别节省费用。
(3)结论
综上所述,S3智能分层是大多数存储和数据分析场景下降低成本的好选择。
三、将新数据存储和现有数据保存到S3智能分层
1、修改上传文件代码中的声明直接上传到S3智能分层
以Python代码为例:
import boto3
BucketName = 's3int-workshop'
LocalFileName = "image1.jpg"
FileData = open(LocalFileName, 'rb')
client = boto3.client('s3')
response = client.put_object(
ACL = 'private',
Body = FileData,
Bucket = BucketName,
Key = LocalFileName,
ContentType = 'image/jpeg',
StorageClass = 'INTELLIGENT_TIERING'
)
在上传参数中,指定StorageClass = 'INTELLIGENT_TIERING'即可将文件保存为智能分层类型。
由于修改上传代码只对新上传的文件有效,存量文件如果要修改存储类型则还是要通过生命周期规则实现。
2、使用生命周期将现有数据转换到S3智能分层
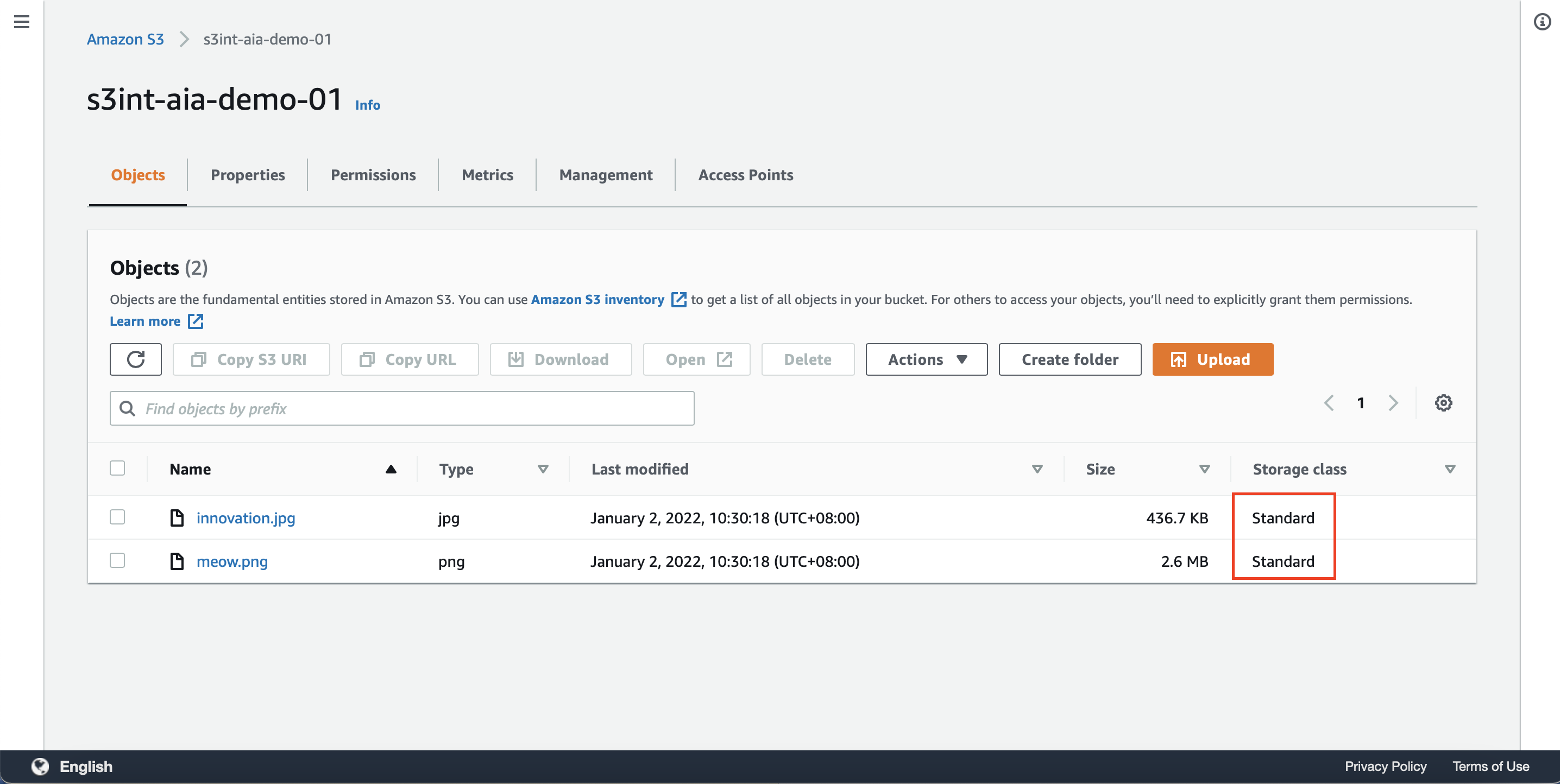
找到要修改的S3存储桶。可看到其中有两个存量文件。如下截图。
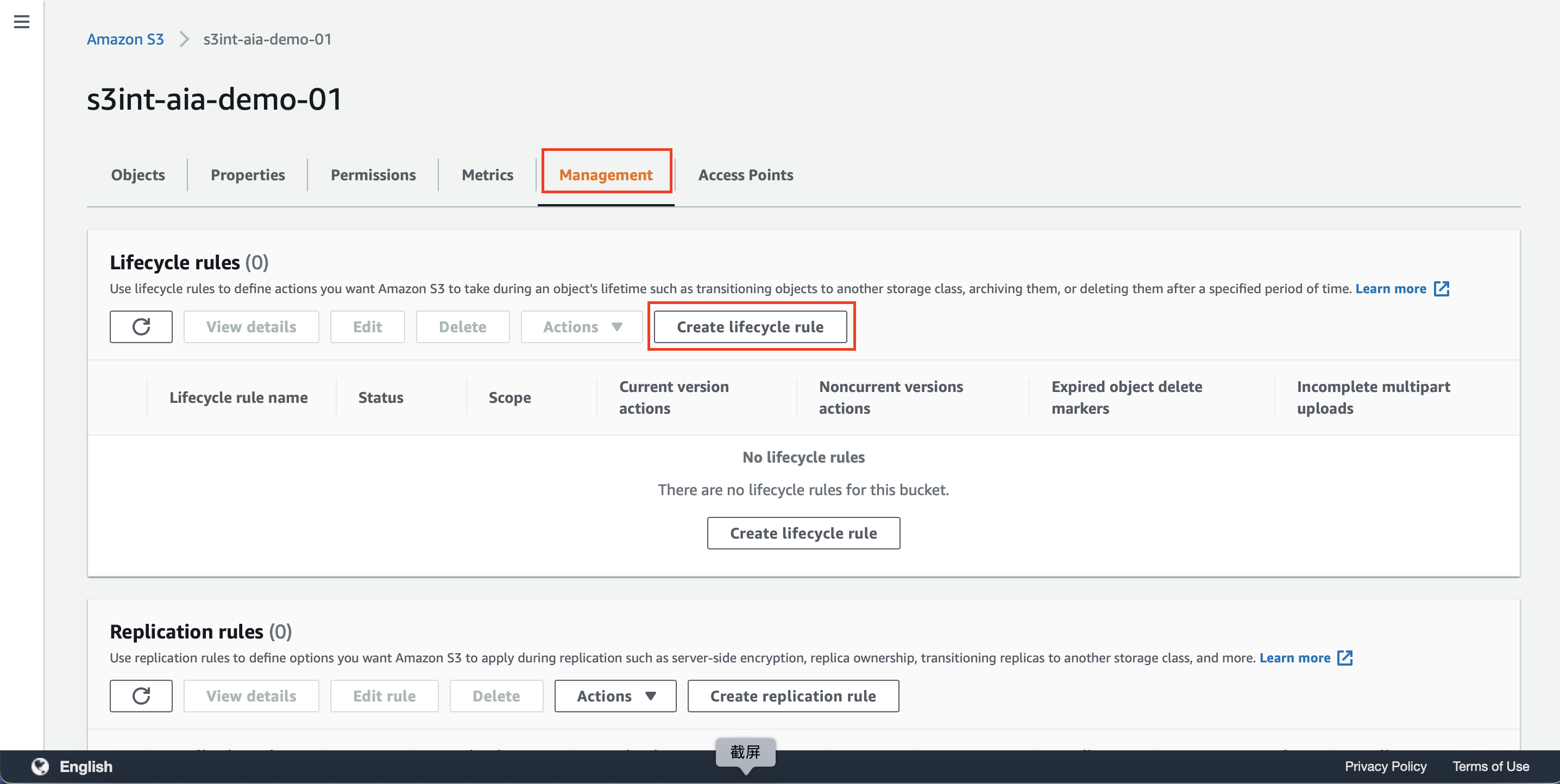
点击Management管理标签页,点击Create lifecycle rule创建生命周期规则按钮。如下截图。
输入规则的名称立刻转换为INT,这里可以使用中文,然后选中下方的Apply to all objects in the bucket对存储桶内所有对象有效的按钮。在下方的第二次确认对话框内,选中I acknowledge that this rule will apply to all objects in the bucket.表示确认本规则将对存储桶内所有文件发起转换。接下来向下滚动页面。如下截图。 注意:慎重使用Apply to all objects in the bucket选项,本选项将对存储桶内所有文件发起转换。请慎重使用以免出现海量对象被错误转换。
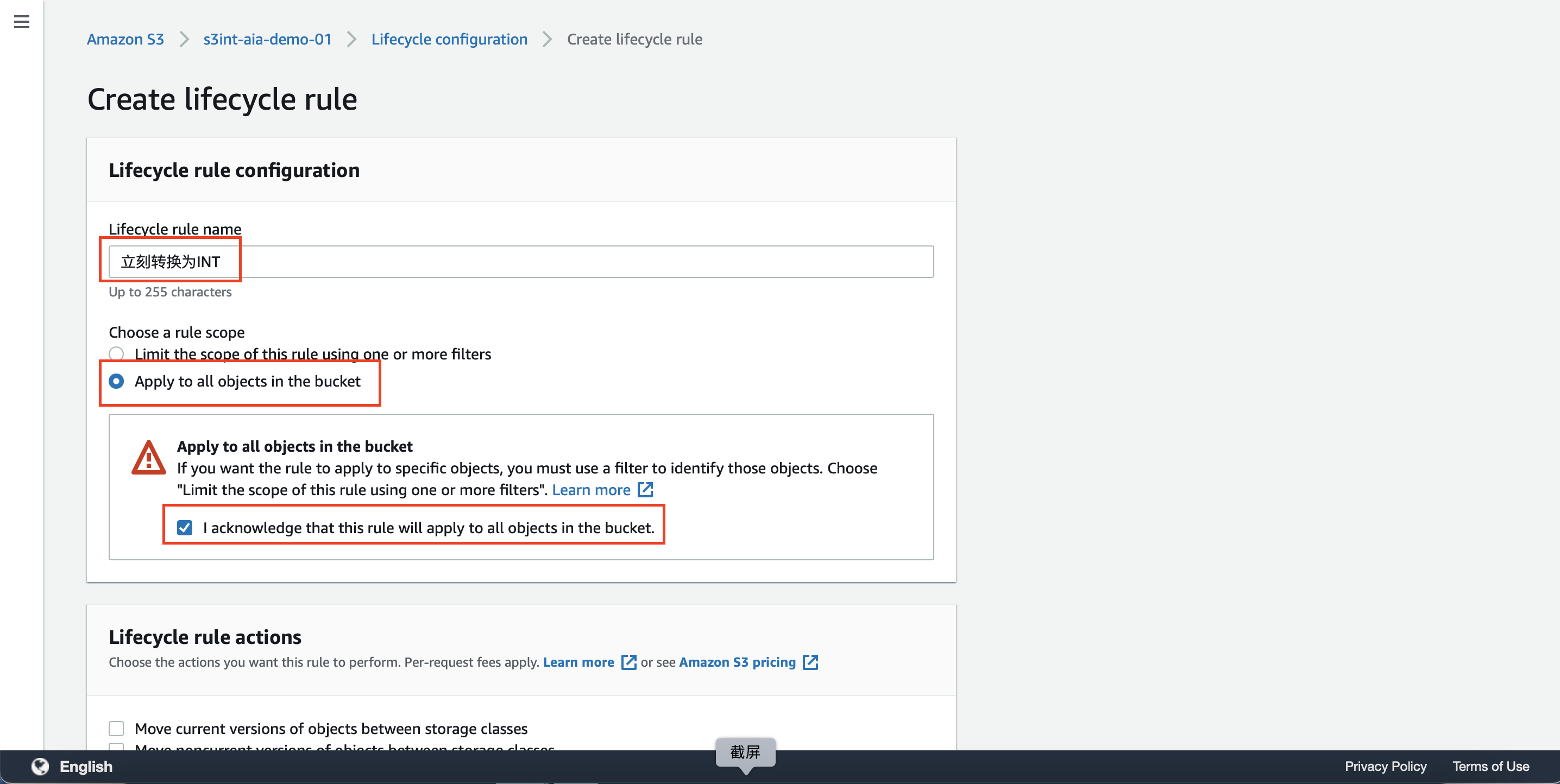
在页面中间部分,生命周期规则位置,选择Move current version移动当前版本和Move noncurrent versions移动非当前版本两个选项。这表示如果本存储桶使用了版本管理功能,那么最新版和历史版本都将被更换存储类型。如下截图。
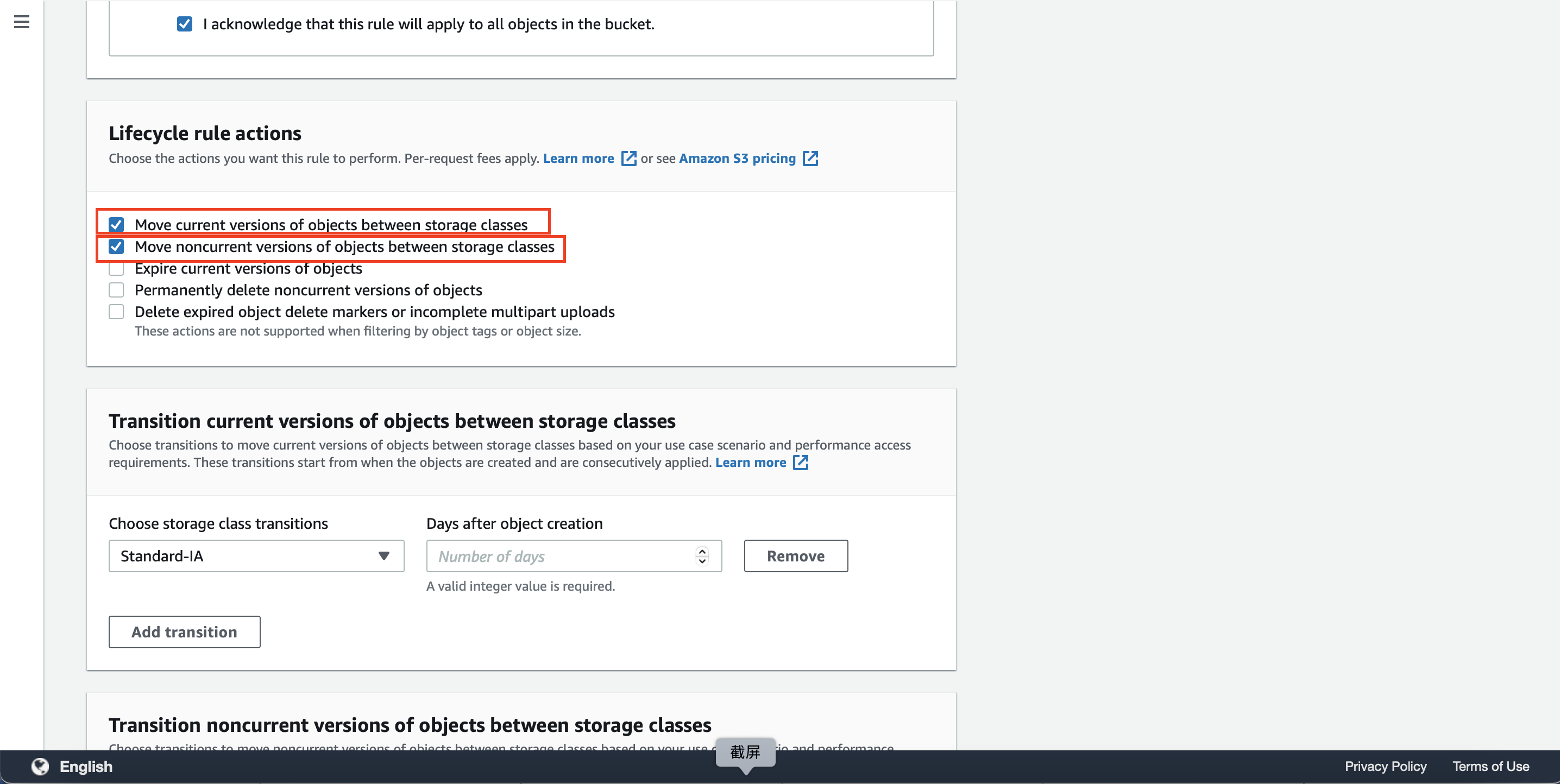
在配置生命周期规则的位置,将转换当前版本的条件设置为目标创建后0天,即立刻转换,将转换类型选择为S3-INT。此外,将转换历史版本的条件设置为目标创建后0天,将转换类型也选择选择为S3-INT。如下截图。
将页面移动到最下方,点击创建规则。如下截图。
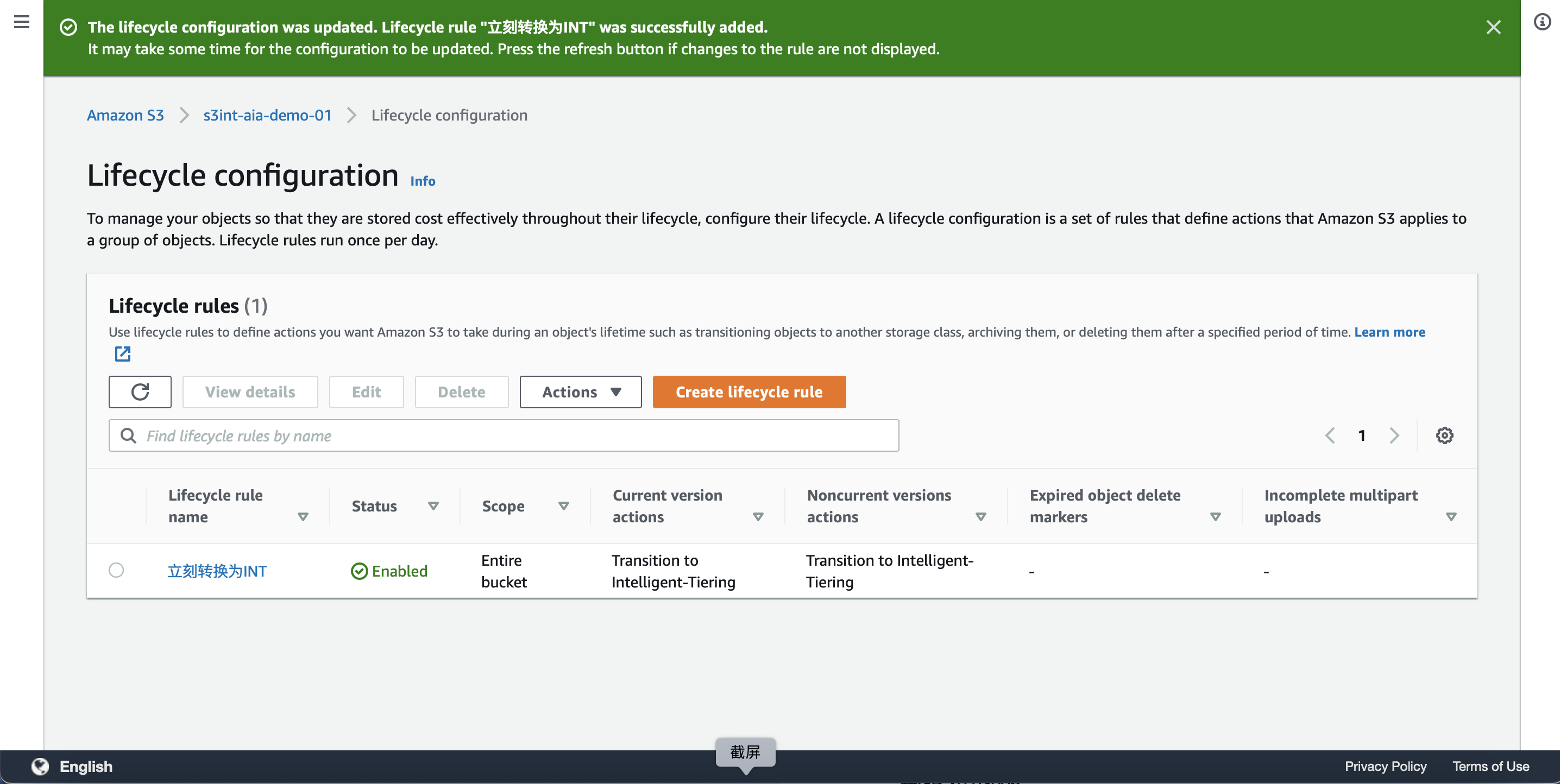
创建规则完成。如下截图。
在经过24小时后,可看到文件级别已经变成了INT类型。
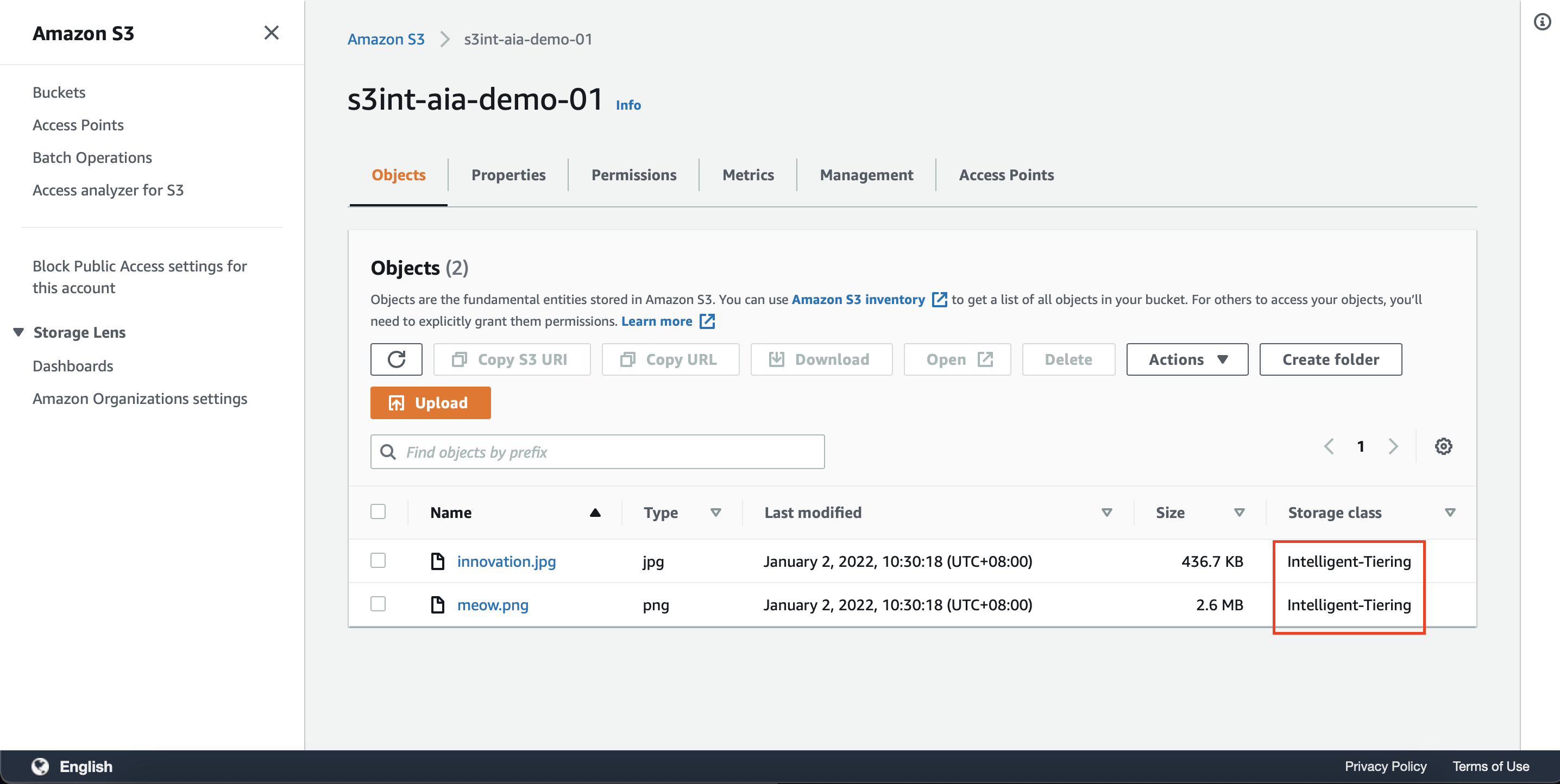
注意:当转换规则填写的是第0天时候,刚上传的文件依然会被保存为Standard存储类。经过24-48小时,才会自动转为S3-INT存储类。因此如果希望文件上传后立刻保存为S3-INT存储类,则还是需要修改上传代码,在代码中指定将文件上传到智能分层。
四、结论
通过本文档模拟的场景可看出,有效的使用S3智能分层搭配S3 Glacier Instant Retrieval,可显著节约存储成本。
五、参考文档
为存储桶配置生命周期:
https://aws.amazon.com/cn/premiumsupport/knowledge-center/s3-lifecycle-rule-delay/
最后修改于 2022-12-15