使用Athena分析在S3上的WAF Log
本文介绍如何使用Athena分析S3上的WAF日志,解决WAF日志查询困难的问题,通过手工配置分区键优化查询性能和成本。
一、背景
在使用WAF保护业务系统的过程中,经常需要查询历史日志,分析特定防护对象的防护效果,查看拦截的请求,或查看访问特定URL的防护效果。这时候就需要用到WAF日志功能。
AWS WAF支持将日志输出到CloudWatch Log Groups,Kinesis,以及S3。将日志输出到CloudWatch Log Groups使用方便,但是存储成本高;将日志输出到Kinesis后可连接多种投递方式,灵活且延迟低,但技术架构稍微复杂。将WAF日志存储到S3数据湖,可实现最低低成本储存日志,通过Athena可快速方便查询。
二、开启WAF日志并了解WAF日志格式
1、创建WAF日志需要的S3存储桶
如果是CloudFront上绑定的WAF ACL,请在us-east-1区域创建S3存储桶用来保存日志。
如果是各Region的ALB负载均衡器和API Gateway绑定的WAF,请在对应资源所在的区域创建S3存储桶。
创建完毕后,继续下一步。
2、开启WAF Log日志
进入WAF ACL的设置,点击最后一个标签页,点击Enable按钮开启WAF日志。如下截图。
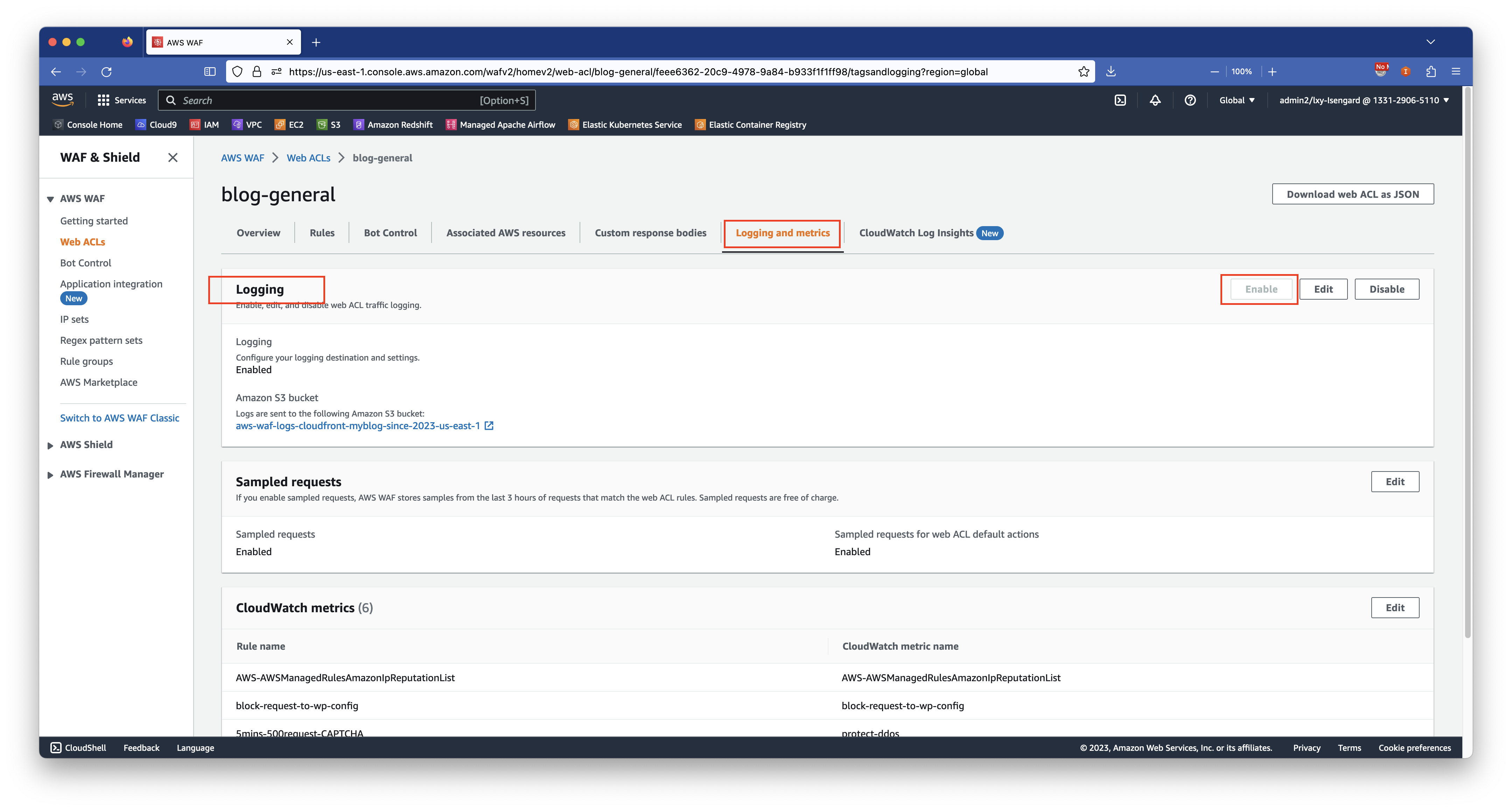
在输出目标位置,选择S3 Bucket,然后选择上一步创建的存储桶名称。
在开启WAF日志的界面,会有四个Redacted的选项,这几个选项不要选中。如果选中的话,WAF会将日志中的关键信息隐藏去,不方便调试错误。如下截图。
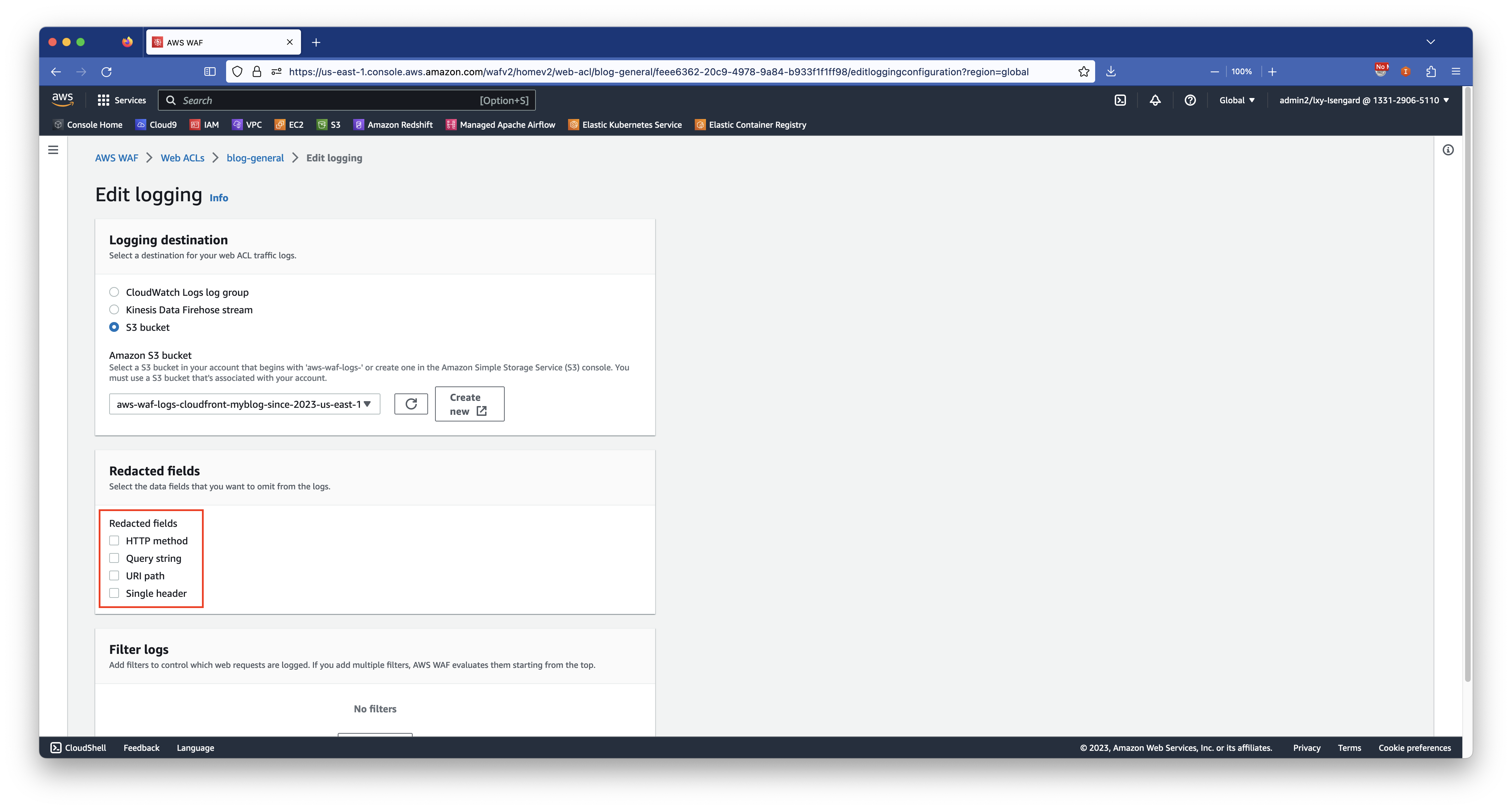
好了现在WAF日志已经打开,可以去S3存储桶看日志了。
3、WAF日志保存路径
WAF日志输出是按照每个ACL输出的,因此,如果您的一个CloudFront、ALB、或者API Gateway上加载了多个WAF ACL,那么他们是各自独立生成WAF日志,将会以名称作为区分。下边以其中一个WAF ACL将日志存储到S3上为例。
日志保存到S3上是按照如下格式:
s3://aws-waf-logs-cloudfront-myblog-since-2023-us-east-1/AWSLogs/133129065110/WAFLogs/cloudfront/blog-general/2023/07/05/14/10/133129065110_waflogs_cloudfront_blog-general_20230705T1410Z_d3b8d075.log.gz
在这串格式中,其中s3://aws-waf-logs-cloudfront-myblog-since-2023-us-east-1/是存储桶名字,可自行定义名称。AWSLogs是默认值不会变化。133129065110是AWS账户12位ID。WAFLogs是默认值不会变化。cloudfront是默认值不会变化。blog-general是WEB ACL的名称,根据真实环境情况名称各不相同。2023是年,07是月,05是日,14是小时,10是分钟。
由此可以看到,WAF日志被按分钟输出进行散列,并存放在S3上。为优化性能,部分Prefix可以作为查询日志时候的分区键。
4、在日志中使用分区键优化查询速度和检索成本
对于S3数据湖,以往的经验是打开Glue直接爬取S3存储桶内的数据,然后由Glue自动生成目录格式。不过由于Glue识别这一长串目录后Glue会将其全部视为分区,从而添加若干几级目录,其效果如下:
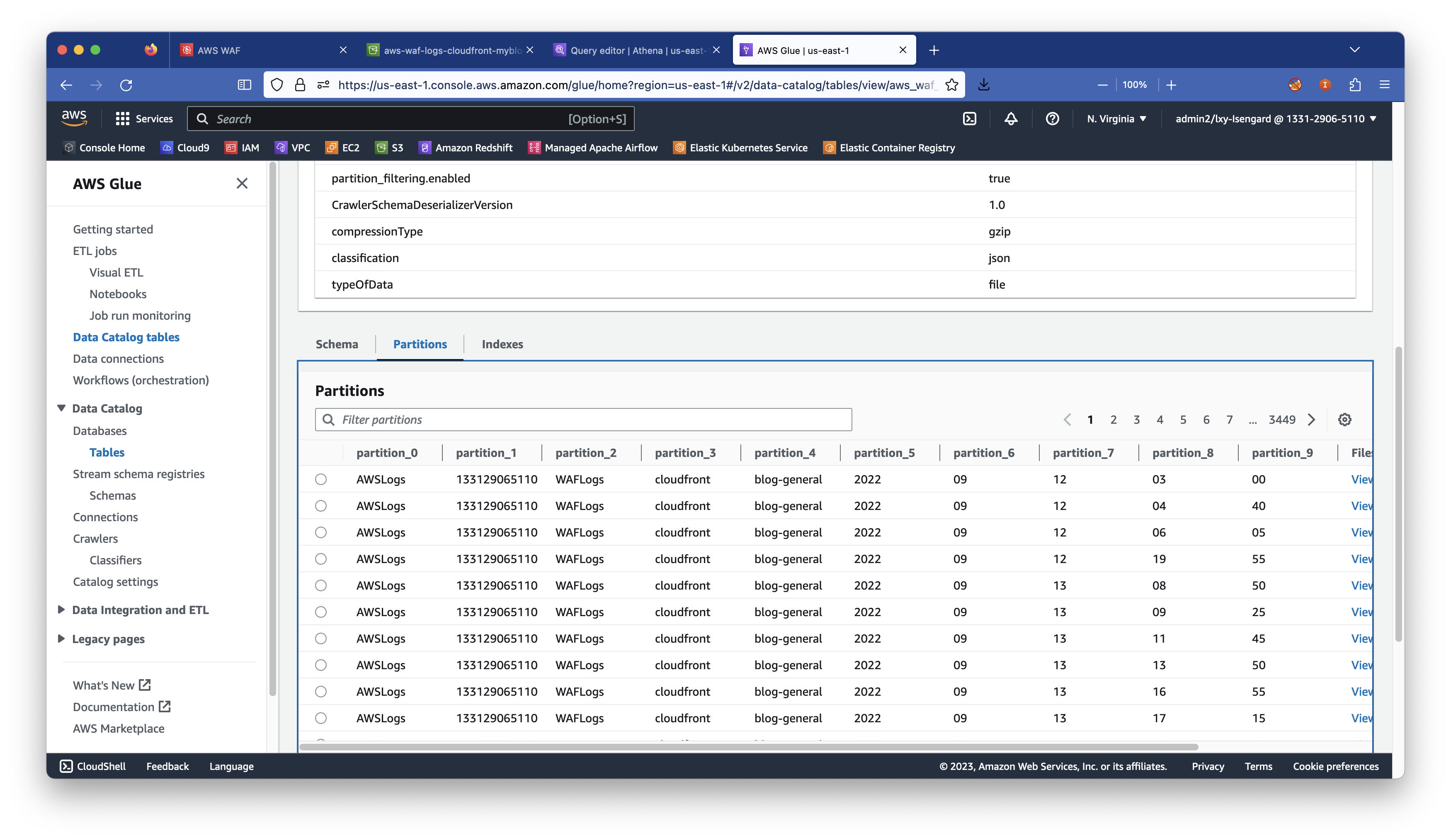
通过这张截图可以看到,让Glue自动识别WAF日志的效果不好,其中S3 Prefix(目录)每一级都被识别为分区,而这些分区因为字段值是固定的不会改变,因此作为分区是无效的分区,并不会起到缩小查询范围的效果。实际使用中,一般需要的分区使用年、月、日即可。也可以按照特定的业务系统和接口来定义分区。
如果完全不使用分区,在日志量大的情况下查询速度会非常差。并且由于Athena是按照扫描的数据量收费,不使用分区意味着一个SQL语句可能发生全桶级别的全量扫描,由此带来很多不必要的Athena和S3访问费用。
因此,在后续的查询中,将不使用Glue自动爬取生成分区,而是手工在Athena上使用SQL生成表结构,并手工指定分区。本文不使用目录,而是直接以格式为20230705的日期并定义为INT类型作为分区。
5、WAF日志格式
本机开发环境为Linux或者MacOS,事先安装jq组件便于处理json。
将S3存储桶内某个目录内的WAF日志下载到本机,将压缩文件解开压缩。文件本身为多条JSON格式,可执行如下命令将日志重新格式化以便于阅读和分析。
cat 133129065110_waflogs_cloudfront_blog-general_20230705T1410Z_d3b8d075.log | jq > waflog.json
由此获得了waflog.json文件。打开后可看到其中一段日子的格式如下:
{
"timestamp": 1688728501392,
"formatVersion": 1,
"webaclId": "arn:aws:wafv2:us-east-1:133129065110:global/webacl/blog-general/feee6362-20c9-4978-9a84-b933f1f1ff98",
"terminatingRuleId": "block-request-to-wp-config",
"terminatingRuleType": "REGULAR",
"action": "BLOCK",
"terminatingRuleMatchDetails": [],
"httpSourceName": "CF",
"httpSourceId": "EYK8QWSIDURGZ",
"ruleGroupList": [
{
"ruleGroupId": "AWS#AWSManagedRulesAmazonIpReputationList",
"terminatingRule": null,
"nonTerminatingMatchingRules": [],
"excludedRules": null,
"customerConfig": null
}
],
"rateBasedRuleList": [],
"nonTerminatingMatchingRules": [],
"requestHeadersInserted": null,
"responseCodeSent": 500,
"httpRequest": {
"clientIp": "103.153.76.105",
"country": "VN",
"headers": [
{
"name": "Host",
"value": "d3kuccziu39w1v.cloudfront.net"
},
{
"name": "Connection",
"value": "keep-alive"
},
{
"name": "Accept-Encoding",
"value": "none"
},
{
"name": "Accept",
"value": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"
},
{
"name": "User-Agent",
"value": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11"
},
{
"name": "Accept-Language",
"value": "en-US,en;q=0.8"
},
{
"name": "Accept-Charset",
"value": "ISO-8859-1,utf-8;q=0.7,*;q=0.3"
}
],
"uri": "/config/.env",
"args": "",
"httpVersion": "HTTP/1.1",
"httpMethod": "GET",
"requestId": "U-KtzImdbxRTLKKvzN6ElWBEJxL3A-e2P1z9BXk0SbCJwFYUUt3JQg=="
}
}
以上这段WAF日志,就是我们希望处理的格式。现在我们来使用Athena查询日志。
三、使用Athena创建Glue表
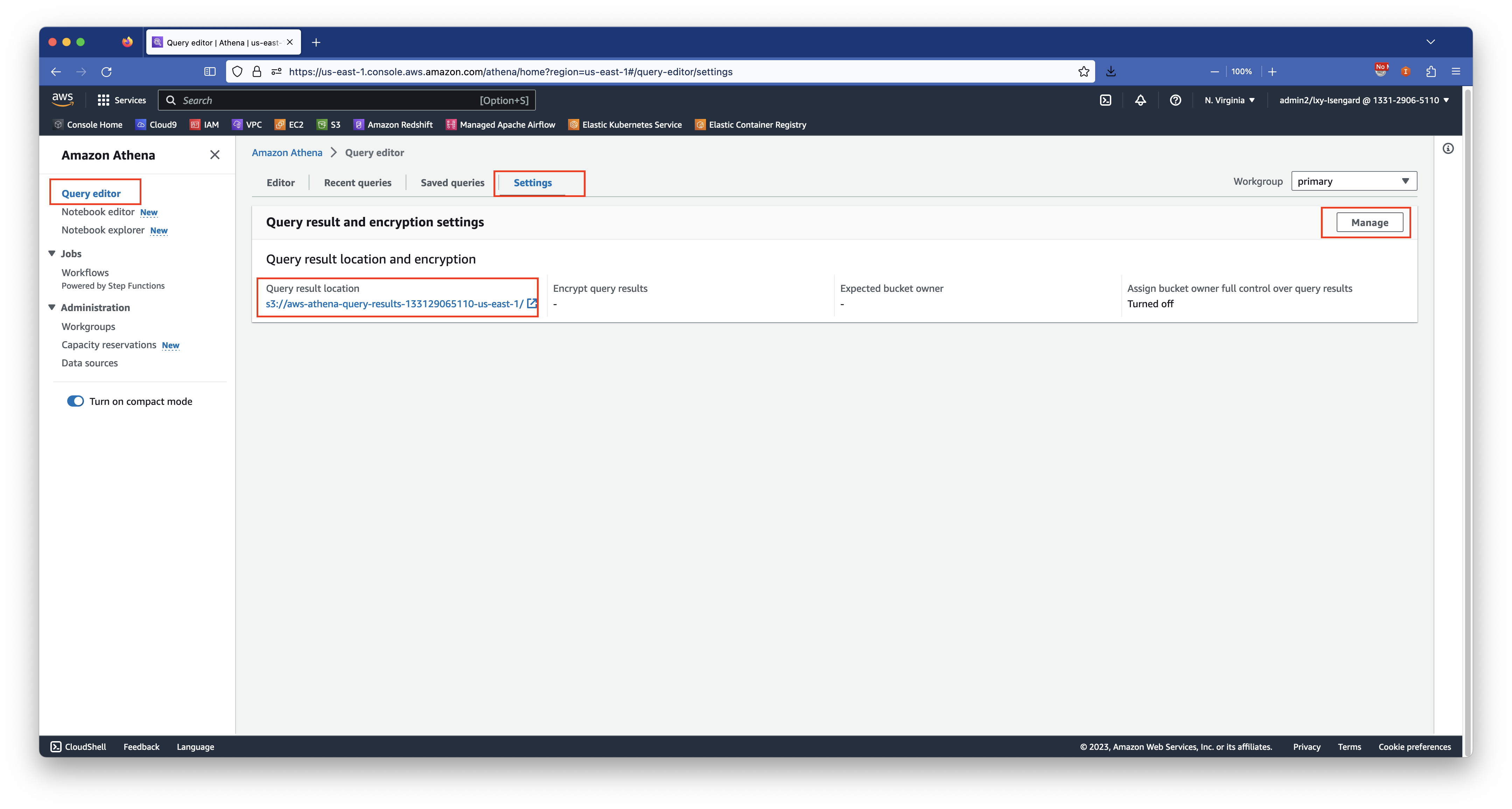
1、设置Athena默认的查询结果保存目录
进入Athena服务,点击最后一个标签页设置,然后设置查询结果存储桶。注意此S3存储桶需要与执行Athena所在的Region一致。由于CloudFront的日志是输出到us-east-1的区域的,因此Athena也需要工作在这个区域。如下截图。
2、执行Athena建表
CREATE EXTERNAL TABLE `aws_waf_logs_cloudfront_myblog_us_east_1`(
`timestamp` bigint,
`formatversion` int,
`webaclid` string,
`terminatingruleid` string,
`terminatingruletype` string,
`action` string,
`terminatingrulematchdetails` array < string >,
`httpsourcename` string,
`httpsourceid` string,
`rulegrouplist` array < string >,
`ratebasedrulelist` array < string >,
`nonterminatingmatchingrules` array < string >,
`requestheadersinserted` string,
`responsecodesent` int,
`httprequest` struct < clientip: string,
country: string,
headers: array < struct < name: string,
value: string >>,
uri: string,
args: string,
httpversion: string,
httpmethod: string,
requestid: string >,
`captcharesponse` struct < responsecode: int,
solvetimestamp: int,
failurereason: string >,
`oversizefields` array < string >,
`labels` array < struct < name: string >>,
`challengeresponse` struct < responsecode: int,
failurereason: string >,
`requestbodysize` int,
`requestbodysizeinspectedbywaf` int
)
PARTITIONED BY (`dt` int)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'paths' = 'action,captchaResponse,challengeResponse,formatVersion,httpRequest,httpSourceId,httpSourceName,labels,nonTerminatingMatchingRules,oversizeFields,rateBasedRuleList,requestBodySize,requestBodySizeInspectedByWAF,requestHeadersInserted,responseCodeSent,ruleGroupList,terminatingRuleId,terminatingRuleMatchDetails,terminatingRuleType,timestamp,webaclId'
)
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://aws-waf-logs-cloudfront-myblog-since-2023-us-east-1/AWSLogs/133129065110/WAFLogs/cloudfront/blog-general/'
TBLPROPERTIES (
'classification' = 'json',
'compressionType' = 'gzip',
'typeOfData' = 'file'
)
3、创建表后首次加载数据分区
WAF输出的日志存储在S3时候,是以年月日的数字作为Prefix(也就是目录),而不是符合Hive要求的Year=2023这种格式。因此,当新的数据写入时候会有新的目录被创建,但是Athena是不能自动识别到这些分区的,也无法通过MSCK命令去自动加载分区。
由此,必须在日期变化后,手工加载分区。例如,加载如下三个时间的分区。请注意分区键的值和实际目录的对应关系一定要正确,否则后续查询无法加载正确数据。
ALTER TABLE aws_waf_logs_cloudfront_myblog_us_east_1
ADD PARTITION (`dt` = 20230705)
location 's3://aws-waf-logs-cloudfront-myblog-since-2023-us-east-1/AWSLogs/133129065110/WAFLogs/cloudfront/blog-general/2023/07/05';
ALTER TABLE aws_waf_logs_cloudfront_myblog_us_east_1
ADD PARTITION (`dt` = 20230706)
location 's3://aws-waf-logs-cloudfront-myblog-since-2023-us-east-1/AWSLogs/133129065110/WAFLogs/cloudfront/blog-general/2023/07/06';
ALTER TABLE aws_waf_logs_cloudfront_myblog_us_east_1
ADD PARTITION (`dt` = 20230707)
location 's3://aws-waf-logs-cloudfront-myblog-since-2023-us-east-1/AWSLogs/133129065110/WAFLogs/cloudfront/blog-general/2023/07/07';
加载分区完毕。
4、查询分区加载成功
show partitions `aws_waf_logs_cloudfront_myblog_us_east_1`
返回类似结果表示加载分区成功:
dt=20230707
dt=20230706
dt=20230705
四、使用Athena发起查询
1、查询某个日期的某时刻之前的所有拦截的请求
查询某个日期的某时刻之前的所有拦截的访问(输出100条):
SELECT
from_unixtime(timestamp / 1000) as "Time",
terminatingruleid as "Blocked rule name",
httprequest.clientip as "Client IP",
httprequest.country as "Country",
httprequest.uri as "Request URI",
httprequest.httpmethod as "Method",
httprequest.httpversion as "Version",
httprequest.headers as "Full request header"
FROM "waflog"."aws_waf_logs_cloudfront_myblog_us_east_1"
where
"action" = 'BLOCK'
and dt = 20230707
and (
from_unixtime(timestamp / 1000) < (TIMESTAMP '2023-07-07 12:00:00.000')
)
limit 100;
查询结果如下截图:
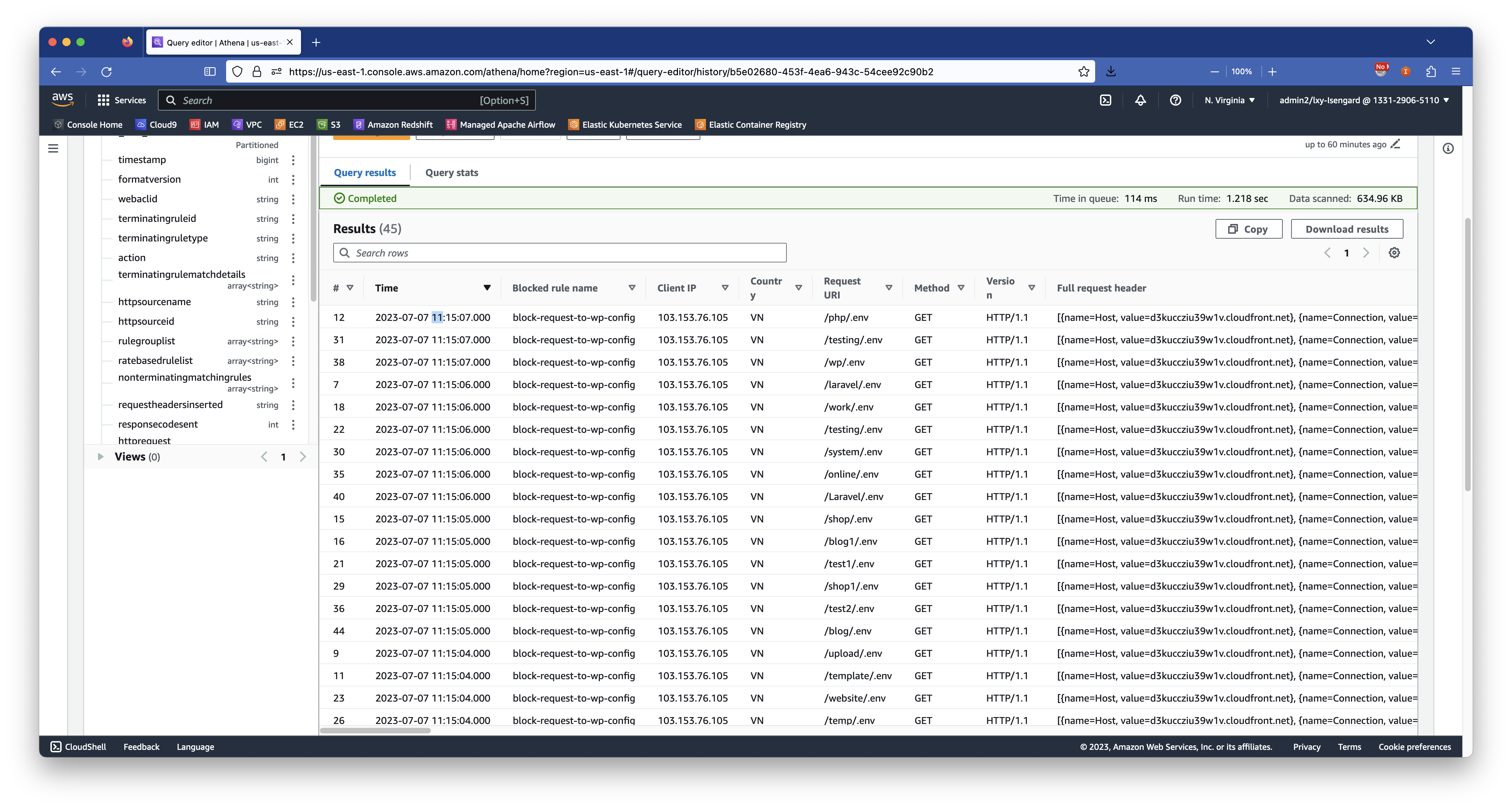
以上截图显示,这些被拦截的请求都是因为触发了特定文件目录的扫描,疑似攻击者探测环境,因此被屏蔽。
2、查询来自特定IP地址和特定时间的请求(含允许和拦截)
查询来自某IP在某时间范围内的访问(输出100条):
SELECT
from_unixtime(timestamp / 1000) as "Time",
terminatingruleid as "Last issued rule",
action as "Action",
httprequest.clientip as "Client IP",
httprequest.country as "Country",
httprequest.uri as "Request URI",
httprequest.httpmethod as "Method",
httprequest.httpversion as "Version",
httprequest.headers as "Full request header"
FROM "waflog"."aws_waf_logs_cloudfront_myblog_us_east_1"
where
httprequest.clientip = '13.248.48.14'
and dt = 20230707
and (
from_unixtime(timestamp / 1000) < (TIMESTAMP '2023-07-07 14:00:00.000')
)
limit 100;
查询结果如下截图:
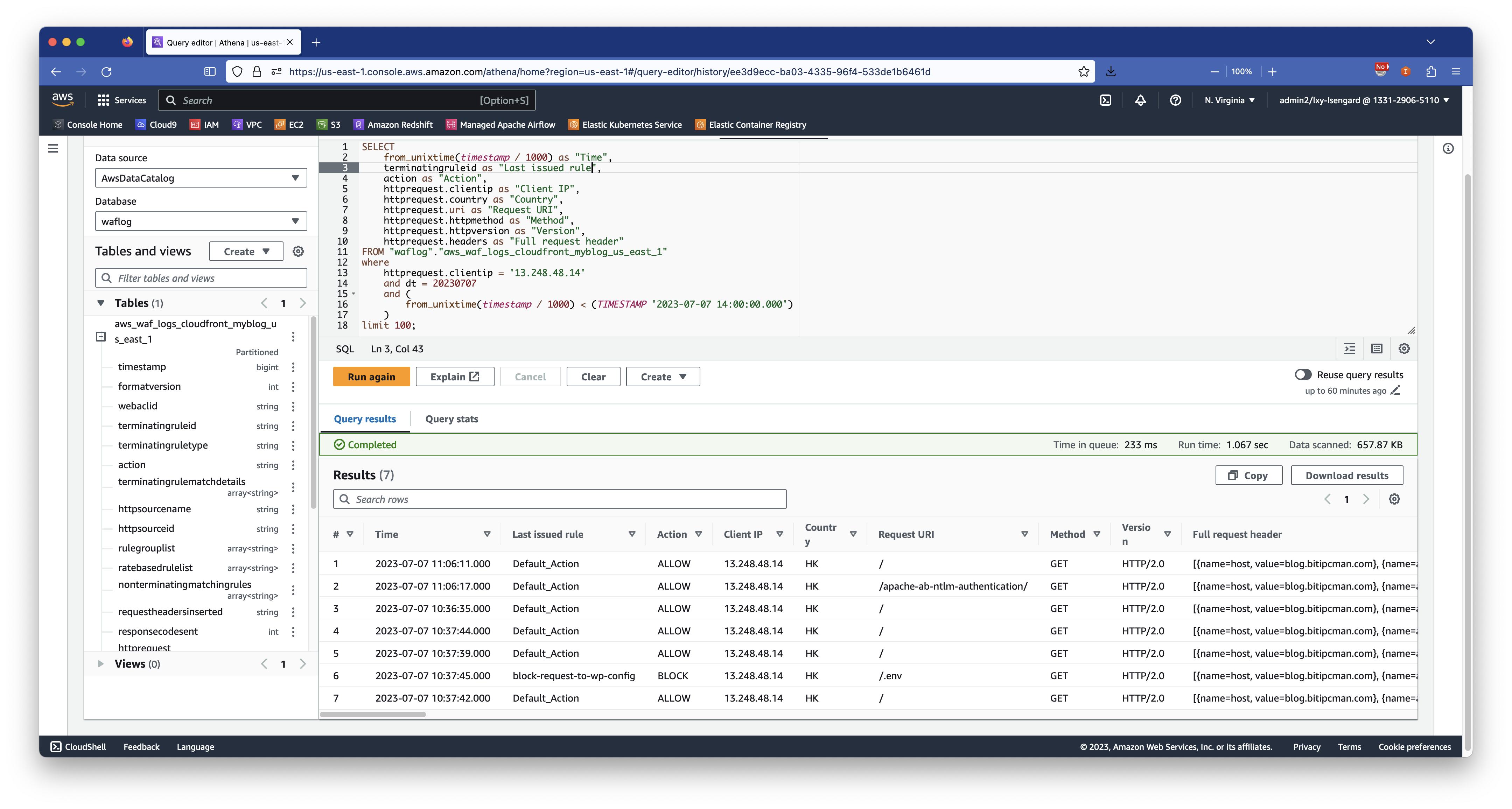
以上搜索结果显示,这些请求都是来自特定IP,根据请求的不同,有的被允许,有的被屏蔽。
3、查询某个时间范围对特定接口的访问
例如希望查看对本系统下的/aws-codecommit-101/这个路径的访问请求,这可以构建如下查询:
SELECT
from_unixtime(timestamp / 1000) as "Time",
terminatingruleid as "Last issued rule",
action as "Action",
httprequest.clientip as "Client IP",
httprequest.country as "Country",
httprequest.uri as "Request URI",
httprequest.httpmethod as "Method",
httprequest.httpversion as "Version",
httprequest.headers as "Full request header"
FROM "waflog"."aws_waf_logs_cloudfront_myblog_us_east_1"
where
httprequest.uri = '/get-real-client-ip-from-nlb-and-alb/'
and dt = 20230707
limit 100;
查询结果如下截图:
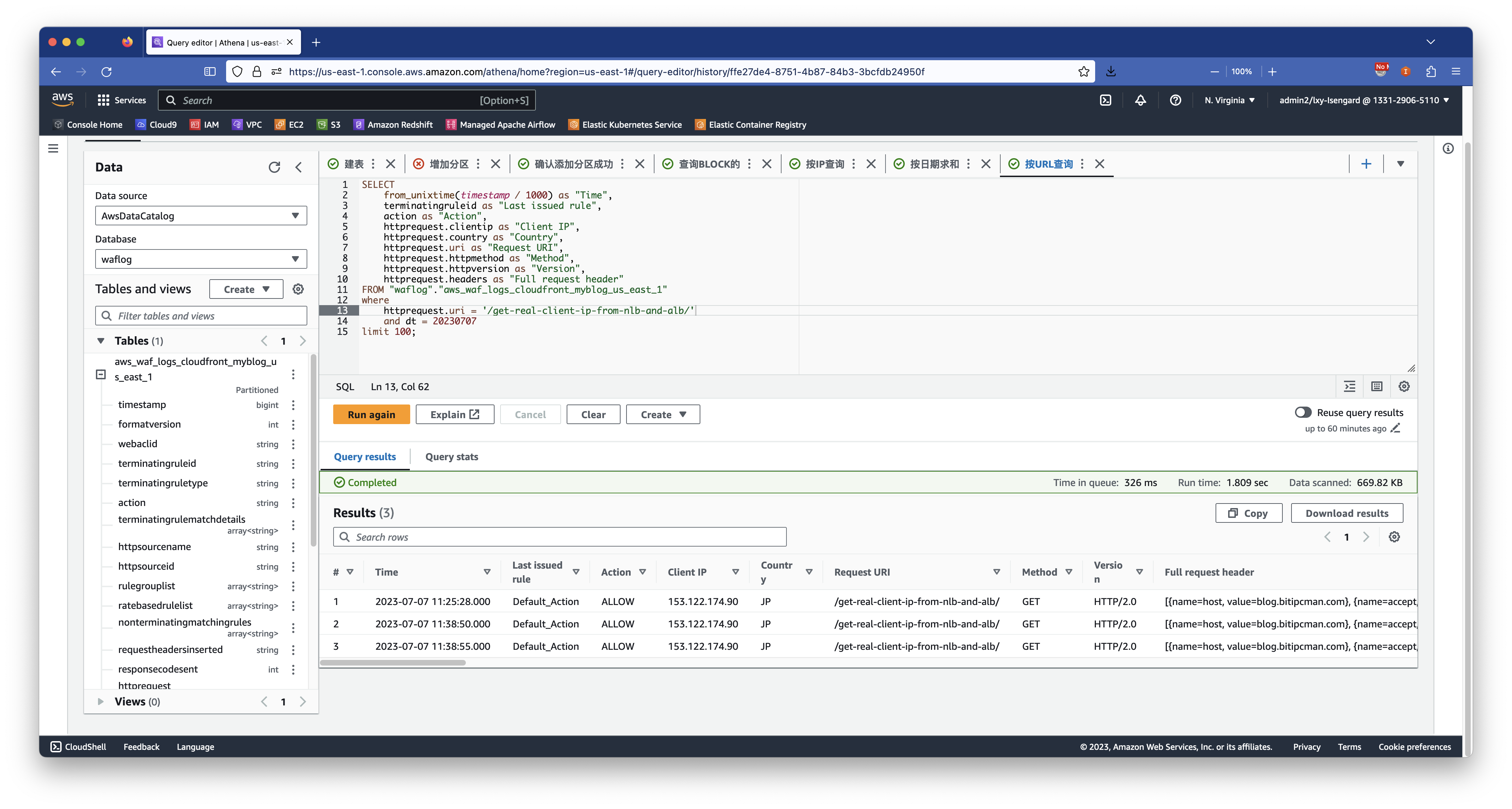
4、查询某特定日期的WAF处理数量
在某场景下,希望知道某几天WAF一共处理了多少条规则(含Allow和BLOCK),可使用如下命令查询。由于本文创建Athena表时候,指定了日期作为分区,且分区键为INT类型,因此这里可以使用between命令指定范围快速查询。
命令如下:
SELECT count(*) as "Total WAF rule processed"
FROM "waflog"."aws_waf_logs_cloudfront_myblog_us_east_1"
where dt between 20230705 and 20230707
返回结果如下:
# Total WAF rule processed
1 8695
请注意,由于WAF日志会按照时间散列,不断的生成新的日期和新的目录,因此请手工添加对应的分区后再进行查询。
5、查询特定Rule在某个时间段内的拦截结果
SELECT
timestamp as "Unix timestamp",
from_unixtime(timestamp / 1000) as "Time",
terminatingruleid as "Last issued rule",
action as "Action",
httprequest.clientip as "Client IP",
httprequest.country as "Country",
httprequest.uri as "Request URI",
httprequest.httpmethod as "Method",
httprequest.httpversion as "Version",
rulegrouplist as "Rule group list",
httprequest.headers as "Full request header"
FROM "waflog"."aws_waf_logs_cloudfront_myblog_us_east_1"
where
"action" = 'BLOCK'
and terminatingruleid = 'AWS-AWSManagedRulesKnownBadInputsRuleSet'
and dt between 20230705 and 20230707
limit 100;
在查询结果中,查看Rule group list字段内的结果,即可获知是那一条规则触发了拦截。
五、优化分区键(可选)
1、选定按月为单位的分区键
在前文的设计上,分区键采用了20230715这样的日期作为分区键。这样做有优点也有缺点:
- 优点:颗粒度细,如果日志量大的话,按天搜索比较精确,单次搜索扫描的数据量小;
- 缺点:按天做分区键,意味着每天都要跑一下Alter table命令为Athena表增加新的分区。如果某一天要查询日志,但是这几天没有运行Alter table增加分区键,那么这次扫描,扫描的这几天的数据都是不可用的。
如果希望减少增加分区键这个每天一次的事情的操作频度,那么可以优化分区键设计,采用月为单位设计分区键。Athena表的分区键和S3存储桶目录是可以不直接相关的,也就是说分区键的命名格式是不一定要和S3存储桶对奇的。
例如可以设计为分区键是dt=202307,未来新增分区键就是dt=202308。这样一个月运行一次命令增加分区键即可。
2、创建新的Athena表并重新添加分区
注意创建好的Athena表是不能修改分区键的,不过可以新创建一个Athena表,S3存储桶的WAF日志的目录格式和数据无需变化,因为多个Athena表可以对应同一个S3存储桶目录。
在上文创建Athena表代码无需修改,但是名字要区分开。
创建Athena表完毕后,添加新的分区键,命令与前文用日期不同,调整为按月,代码如下:
ALTER TABLE aws_waf_logs_cloudfront_myblog_us_east_1
ADD PARTITION (`dt` = 202307)
location 's3://aws-waf-logs-cloudfront-myblog-since-2023-us-east-1/AWSLogs/133129065110/WAFLogs/cloudfront/blog-general/2023/07/';
ALTER TABLE aws_waf_logs_cloudfront_myblog_us_east_1
ADD PARTITION (`dt` = 202308)
location 's3://aws-waf-logs-cloudfront-myblog-since-2023-us-east-1/AWSLogs/133129065110/WAFLogs/cloudfront/blog-general/2023/08/';
这样即可完成按月为单位添加分区键。执行命令
show partitions `aws_waf_logs_cloudfront_myblog_us_east_1`
即可看到分区键是新的按月为单位。今后只需要每月添加一次分区键,即可实现数据检索。
六、参考资料
在 Athena 中对数据进行分区:
https://docs.aws.amazon.com/zh_cn/athena/latest/ug/partitions.html
最后修改于 2023-07-07