
在AWS EMR使用多个Master高可用部署场景下,需要创建3台Master节点上。登录到其中一台节点,运行如下命令:
yarn application -list在某些场景下会遇到如下报错。报错信息:
WARN ipc.Client: Failed to connect to server: ip-172-31-22-134.cn-northwest-1.compute.internal/172.31.22.134:8032: retries get failed due to exceeded maximum allowed retries number: 0
java.net.ConnectException: Connection refused
错误场景如下截图。
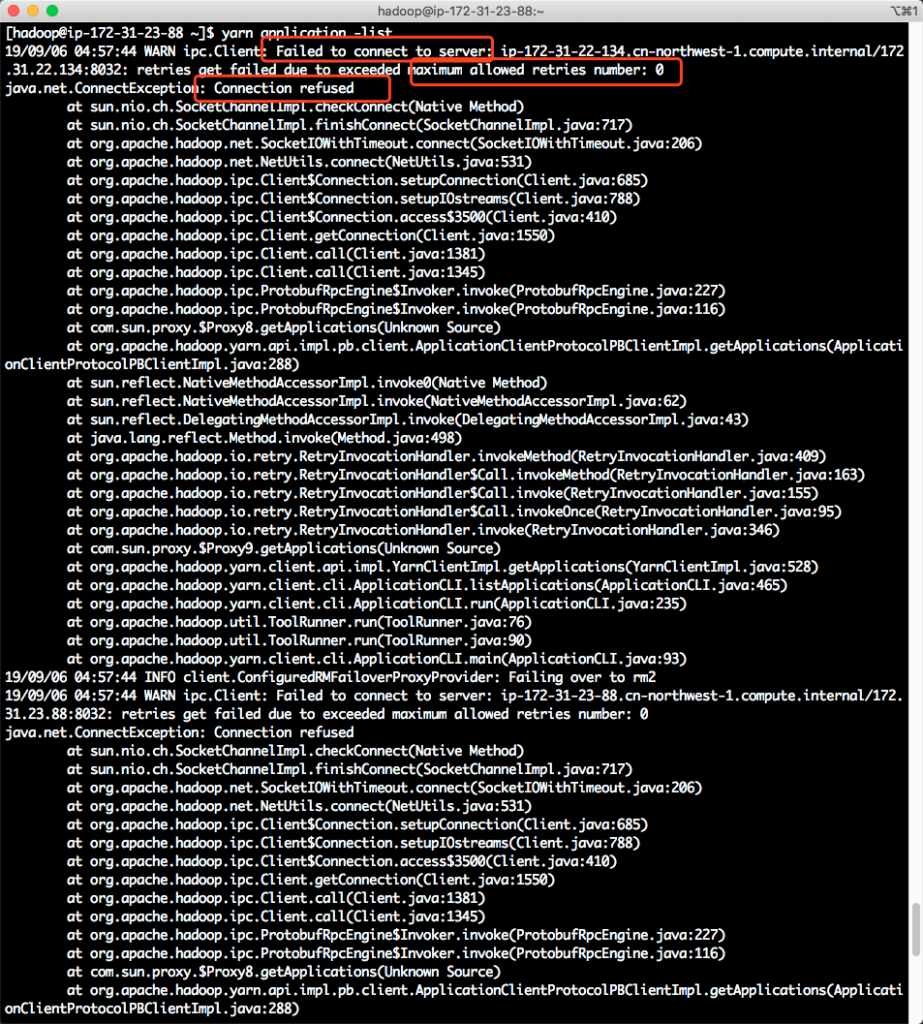
不过在等待一段时间后,也可以看到yarn返回了最终的输出。如下截图。
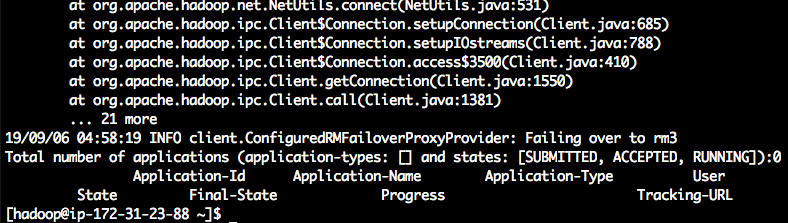
造成这个问题是因为EMR开启了多Master部署,有三台Master节点,分别叫做rm1、rm2、rm3。当前登录的节点可能是rm1,运行yarn查询的时候默认先查询rm1。但是,整个集群的master已经切换走了,rm1并不是master角色,所以yarn会反复查询失败,然后去轮询到下一个节点rm2,继续失败,最后在rm3节点查询完成。
接下来验证下,当前的集群中谁是master节点。执行如下命令:
yarn rmadmin -getAllServiceState执行效果如下截图。
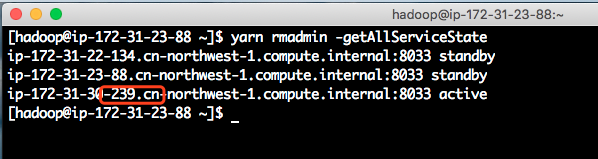
可以从如上命令看出,IP结尾是239的才是master节点。那么这个239节点是否在yarn查询列表的第一位呢?还是排在最后一位?
编辑如下配置文件:
sudo vim /etc/hadoop/conf.empty/yarn-site.xml查看里边的resource manager的顺序如下:
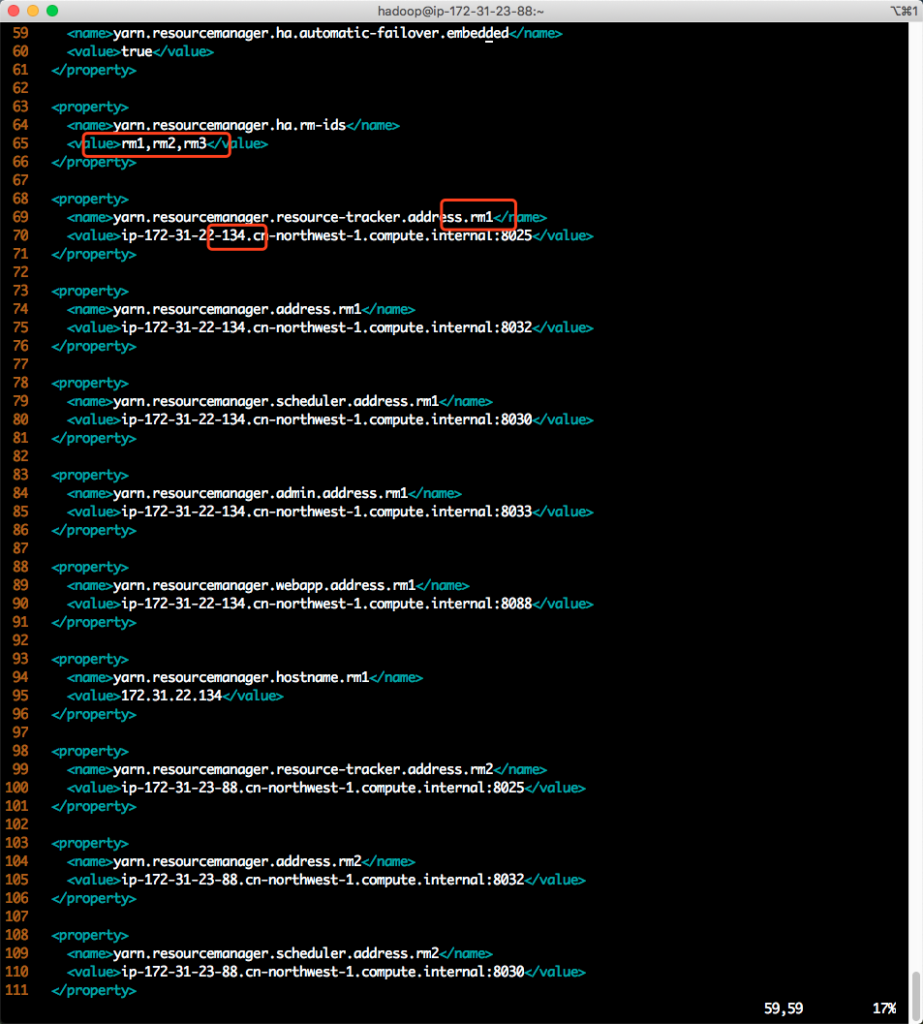
如上截图可以看到,顺序是rm1、rm2、rm3,而rm1对应的IP并不是当前的master节点。所以才有了这个查询失败。
解决办法:把顺序改成rm3、rm2、rm1。改完后,再运行yarn,就没有报错了。如下截图。
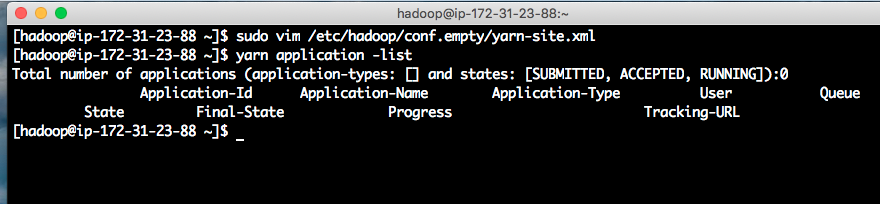
至此问题解决。