【10分钟开箱即用】使用Amazon Bedrock知识库构建RAG检索能力
本文介绍如何使用Amazon Bedrock知识库快速搭建托管RAG系统,解决传统RAG开发复杂、需要自行管理向量数据库等问题,10分钟内实现完整的检索增强生成能力。
Bedrock知识库现已经支持Claude3的集成,可在单一API请求上完成RAG召回和大模型重写。
本文介绍如何使用Bedrock知识库快速搭建托管的RAG体验,在申请模型权限后,整个实验仅需要在AWS控制台上数次点击,10分钟内即可体验完整的RAG能力。本文对应的演示视频跳转到这里观看。
一、Bedrock知识库和托管RAG介绍
1、使用Amazon Bedrock知识库实现托管的RAG检索能力
Retrieval Augmented Generation(以下简称RAG)是为大模型提供私有化知识内容补充的一个重要方式。在不使用RAG的情况下,如果希望大模型能实现私有知识的反馈,那么一般需要微调等模型训练,由此需要比较复杂的技术实现和GPU算力才能完成。为了绕过模型微调训练,可使用RAG方式借助向量生成和向量数据库,用一种较低成本的方式为大语言模型提供了私有内容的存储、检索等访问通道,最终结合大语言模型进行完整的用户交互。
在Amazon Bedrock知识库尚未推出时要实现完整的RAG,用户需要原始数据准备、向量生成、向量数据库搭建、向量数据库写入和查询、召回结果处理、作为Context输入到大语言模型中等多个步骤。这其中要独立编写代码用于文档处理、调用不同的模型、查询向量数据库来实现,不同的向量数据库又使用各自独立的协议和接口,包括但不限于SQL、REST、其他专用协议等。由此带来一定的开发复杂性。
使用Amazon Bedrock知识库,您可以获得完全托管的服务体验,将大语言模型连接到您的私有数据源,几乎一键的方式实现检索增强生成,让大语言模型更加了解您的具体业务领域和私有数据。Amazon Bedrock知识库服务作为托管服务,将向量相关处理过程封装在Bedrock的API内。Bedrock知识库支持从S3存储桶中的多种文档获取数据,自动切片转换为文本块生成向量,并存储在向量数据中。因此业务代码只需要调用单个API,即可同时完成从Bedrock所集成的向量数据库中进行召回和大语言模型的内容生成,大大简化了开发过程。此外,从Amazon Bedrock知识库检索到的所有信息均附有引文,可提高透明度并最大限度地减少幻觉。
目前Bedrock知识库功能在美东1(N.Verginia弗吉尼亚北部)和美西2(Oregen俄勒冈)区域可用。
2、Foundation Model(FM)大模型的选择
如果您是自行搭建整个RAG架构,您可以使用任何大语言模型,包括SaaS方式API化调用的、以及在云上单租户部署其他厂家的大语言模型。
Bedrock服务推出后,您不再需要在云上以单租户方式去自行部署、搭建、托管大语言模型了。Bedrock是Amazon推出的基础模型服务,提供了多个厂家的基础模型(Foundation Model, 以下简称FM),可通过API方式调用。它们包括AI21 Labs、Anthropic的Claude、Cohere、Meta、Stability AI以及Amazon的Titan等等。此外,使用Amazon Bedrock还可通过模型微调(Fine-tune)以达到更好的效果。
在以上模型中,推荐使用Claude 3 Sonnet和Claude 3 Haiku,是效能和成本的最佳平衡。单独使用基础模型的配置方法可参见这两篇博客(上篇配置篇、下篇Prompt调优篇)。如果您的内容较短并且对交互要求较高,可选择Claude V2.1。如果您输入的内容较长且比较在乎成本,建议选择Claude Instant模型。
Bedrock知识库服务集成与Bedrock提供的基础模型深度集成,一般建议使用Claude模型,对Bedrock知识库发起单个API调用,即可自动完成向量召回和大语言模型的同时调用。
3、搭建向量生成模型方案的选择
如果您是自行搭建整个RAG架构,在不使用Amazon Bedrock知识库功能的情况下,您可以自行调用多种模型生成向量。它们可以是单租户方式部署在AWS云上,也可以是以SaaS方式提供接口。出于最佳性能考虑,一般向量生成、向量数据库都放在同一个云上的同一个区域,可以获得最高性能。跨云调用、跨Reigon调用也是可以的,对于只要确保在VPC层面内网的打通,甚至互联网调用Public Endpoint,也都即可实现正常访问。
在Bedrock知识库服务发布后,您不再需要自行搭建向量生成模型了,您可以使用Bedrock知识库服务集成的向量生成功能。Bedrock支持的向量模型是:
- Amazon Titan G1 Embeddings - Text,向量维数1536
- Cohere Embed Multilingual,向量维数1024
以上两种模型可在Bedrock服务的Model Access菜单中申请开通调用权限。
4、向量数据库的选择
如果您是自行搭建整个RAG架构,在不使用Amazon Bedrock知识库功能的情况下,您可以自行搭建向量数据库,并通过程序进行读写。目前AWS云端提供的数据库和数据服务中,能支持向量检索包括:
- Amazon OpenSearch Service (AOS),兼容开源的ElasticSearch,同时提供Provisioned版本和Serverless版本
- Aurora/RDS PostgreSQL with pgVector
- MemoryDB for Redis
- DocumentDB Vector Search (5.0版以上)
- Neptune Analytics
以上几种数据库是在截止2024年初在AWS云上可用的向量数据库。当然,您也可以基于EC2部署其他厂家的向量数据库。以上这几种数据库的检索效能、集群容量、高可用、调用API、与其他服务和开发框架(Langchain等)的各自有差异。从编写代码角度来说,OpenSearch提供的是REST形式的接口,可直接发起HTTPS调用,开发简单。从集群管理角度,OpenSearch Serverless版本免去了底层集群规划和管理的麻烦,开箱即用。OpenSearch可配置API Endpoint可在Public可调用,只要通过IAM身份认证(SignV4签名)即可访问。如果在实际生产环境中,希望将OpenSearch Serverless集群配置为只能从VPC内网访问,那么可以调整相应的策略实现。因此,自行搭建RAG架构时候,向量数据库选择使用OpenSearch实现是较为方便、易用的。
在Bedrock知识库发布后,您不需要自行管理向量数据库了,您可以使用Bedrock知识库服务集成的向量数据库。在Bedrock知识库创建向导界面上,您可以支持选择自动创建全新向量数据库,也可以选择将现有向量数据库集群纳入管理。Bedrock知识库支持的托管数据库包括可选的包括OpenSearch、Aurora PostgreSQL、Pinecone和Redis Enterprise。
对于新用户而言,推荐由Bedrock知识库自动创建一个全新的OpenSearch Serverless集群作为RAG使用的向量数据库。由此即实现了几分钟内开箱即用,又对现有业务的干扰最小。
5、手工搭建RAG与托管RAG的选择
以上分别介绍了FM大语言模型、向量生成模型的选择、向量数据库的选择,这是手工搭建RAG的几个关键步骤。手工搭建RAG需要分别搭建并配置这些服务,然后编写应用代码连接到这些服务进行调用。整个过程步骤多,开发繁琐。为此,您可以使用Bedrock知识库提供的全托管的RAG体验来简化开发。
在数据摄取和向量生成方面,Bedrock知识库提供了整个生命周期流程的托管的服务体验。Bedrock知识库支持S3存储桶作为数据源,可将S3存储桶内的文本、HTML、Markdown、PDF、Word、Excel、CSV等格式的文档进行自动切分(默认是300 Token,可调整),然后调用模型生成向量,并保存在向量数据库中。
在召回和内容生成方面,Bedrock提供了单一API,背后封装了对向量数据库的查询和大语言模型的调用,您可以发起名为Retrieve的请求仅获得向量数据库召回的结果,也可以发起名为RetrieveAndGenerate的请求,将召回结果送给大语言模型处理后,直接返回最终结果。
由此可以看到,Bedrock知识库服务提供了托管的RAG体验,简化了开发,使得业务人员可以迅速交付诸如知识库、问答助手等用户场景。
6、本文操作步骤介绍
本实验使用Bedrock知识库搭建完全托管的RAG环境,几个关键组件如下:
- 数据源:使用PDF格式的文档作为输入,并有Bedrock知识库自动摄取;
- 向量生成模型:使用默认推荐的Amazon Titan Embeddings G1 Text模型,有Bedrock知识库自动生成向量;
- 向量数据库:使用默认推荐的Amazon OpenSearch Serverless作为向量数据库,并由Bedrock知识库自动创建集群;
- 大模型:本文使用Claude 3 Sonnet进行实验
以往很多大语言模型相关的实验都是在Notebook上进行,从Github下载的代码样例也是Notebook的ipynb格式。而为了方便业务开发人员,尤其是没有Amazon Sagemaker Notebook环境的业务开发人员在本地笔记本上上调试代码,本文将不考虑使用Jupyter Notebook环境,末尾直接提供Python的样例代码,方便快速上手。
二、创建Bedrock Knowledgebase知识库
1、开通大模型访问权限
如果之前没有使用过Bedrock,那么默认所有模型都是处于未开启状态,需要申请模型访问权限。申请模型操作权限的位置是在Bedrock服务的左侧菜单。如下截图。
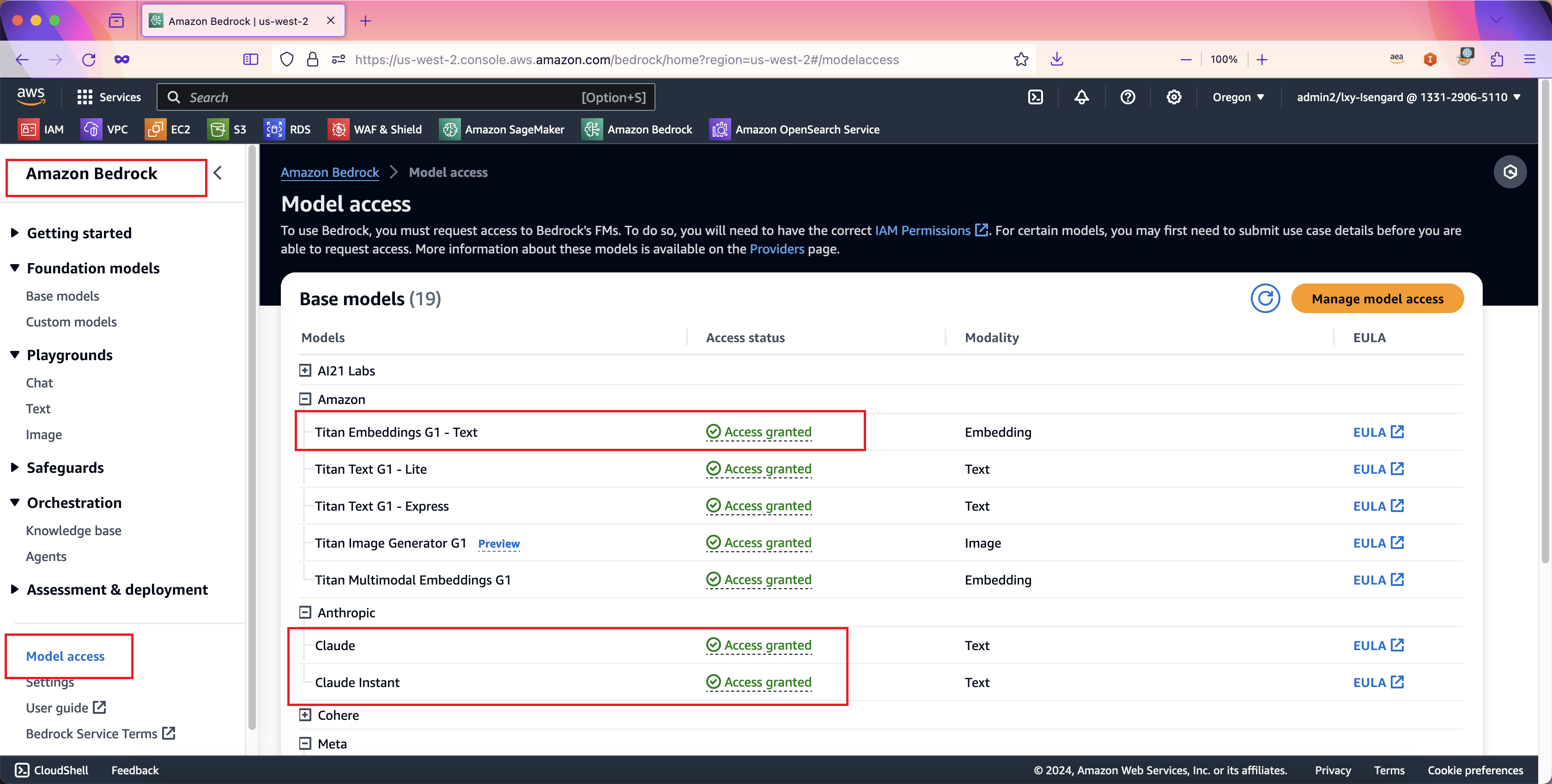
具体操作方法参考本篇博客,建议申请Claude 3 Sonnet和Claude 3 Haiku等模型,可实现小效果和性价比的平衡。此外还要申请Amazon Titan Embeddings模型。
- - Claude 3 Sonnet
- - Claude 3 Haiku
- - Amazon Titan Embeddings G1 - Text
2、创建作为数据源的S3存储桶
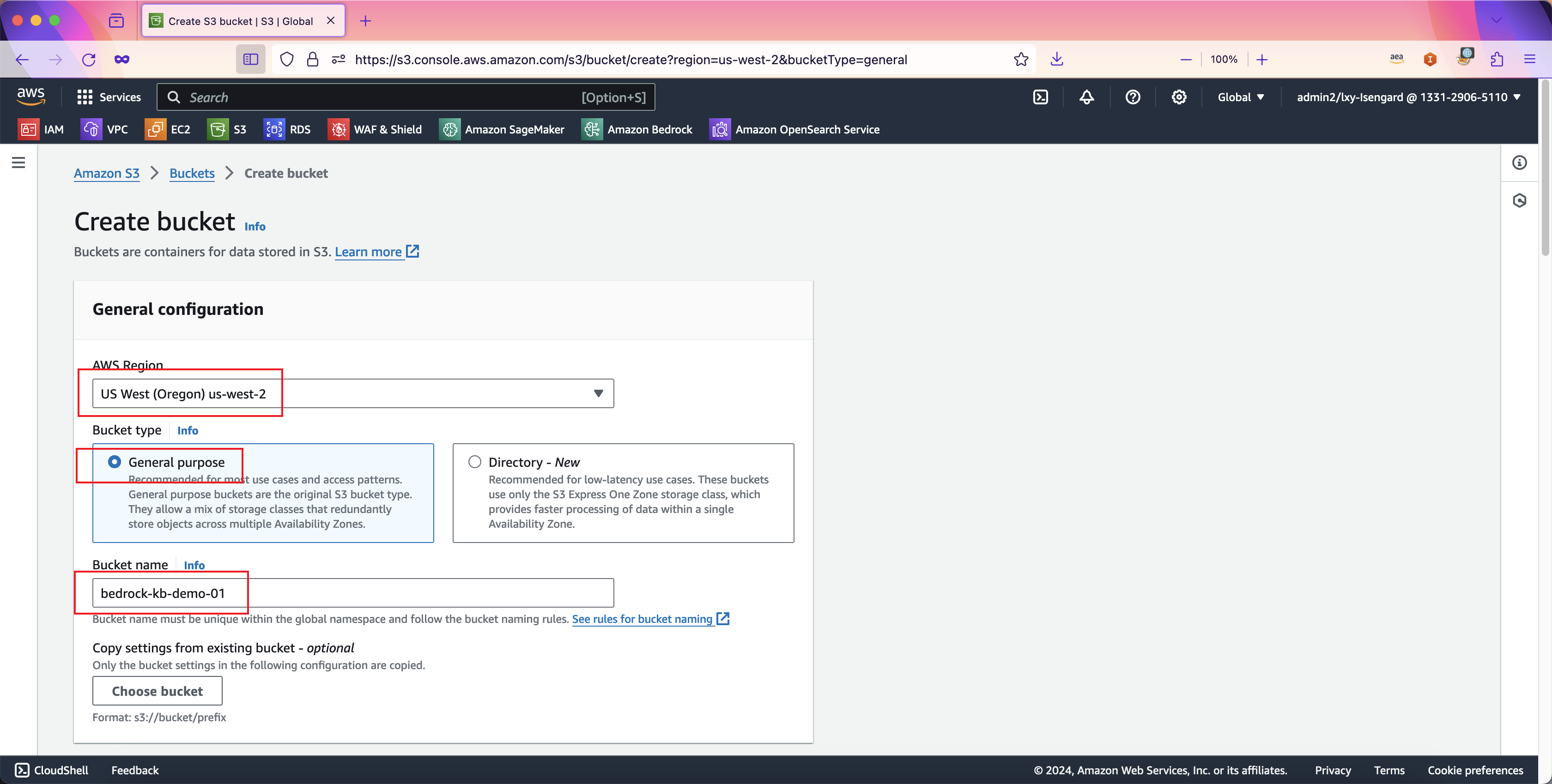
创建S3存储桶时候,需要注意选择存储桶所在的区域要和Bedrock服务在同一个区域。例如Bedrock服务在美西2俄勒冈(us-west-2, Oregen),那么存储桶也创建在这个区域。在存储桶名称位置可根据需要任意输入,在存储桶类型(也就是使用场景)位置,选择General purpose,然后继续向下滚动页面。如下截图。
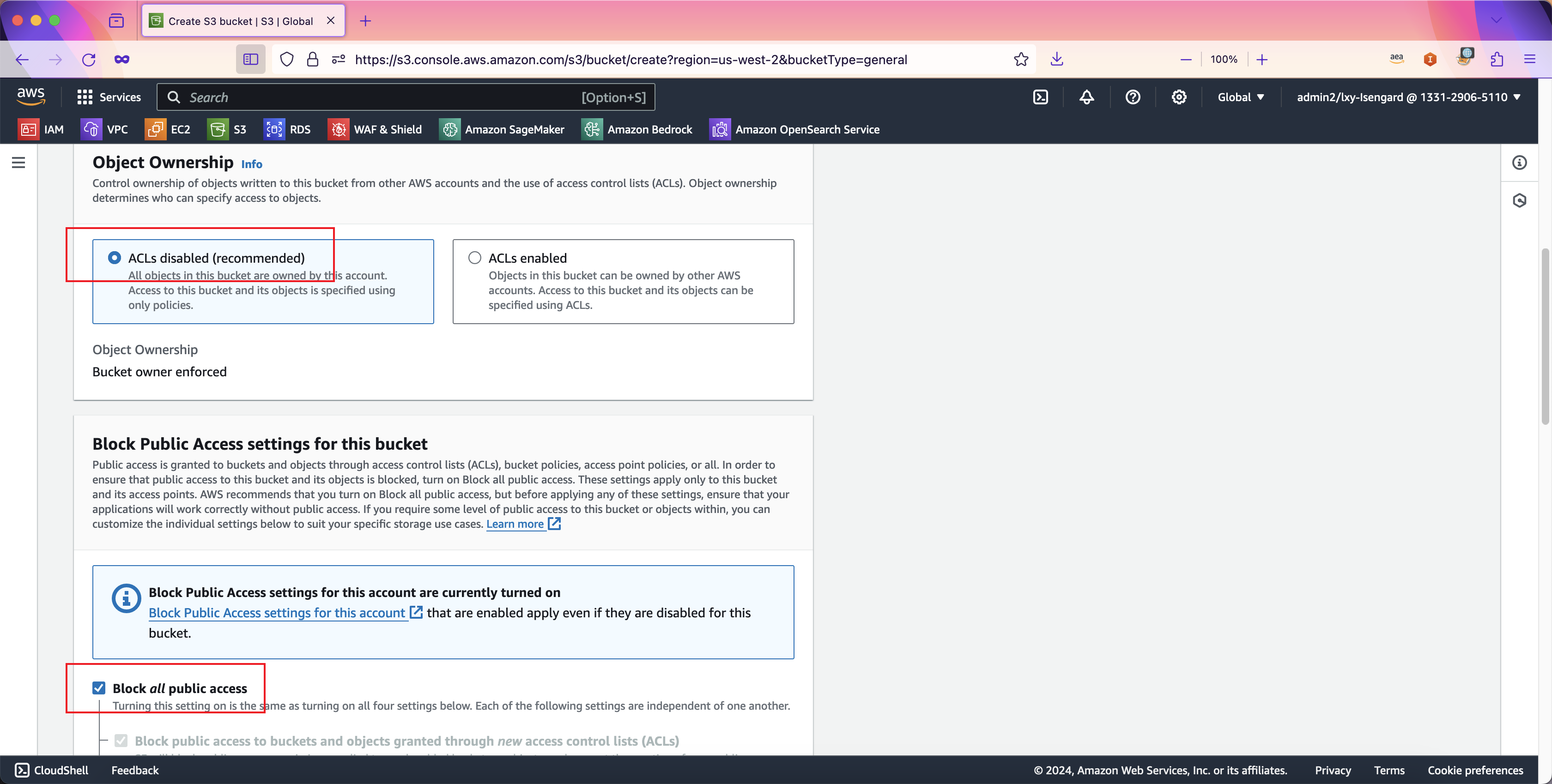
在Object Ownership位置,选择ACL disabled(recommended)选项。在Block Public Access settings for this bucket的选项中,选中第一项Block all public access。由此将确保整个存储桶是完全私有的,即便某个应用上传文件时候额外指定了Public ACL,也将被拒绝公开。以此从最高层面保护存储桶为私有。如下截图。
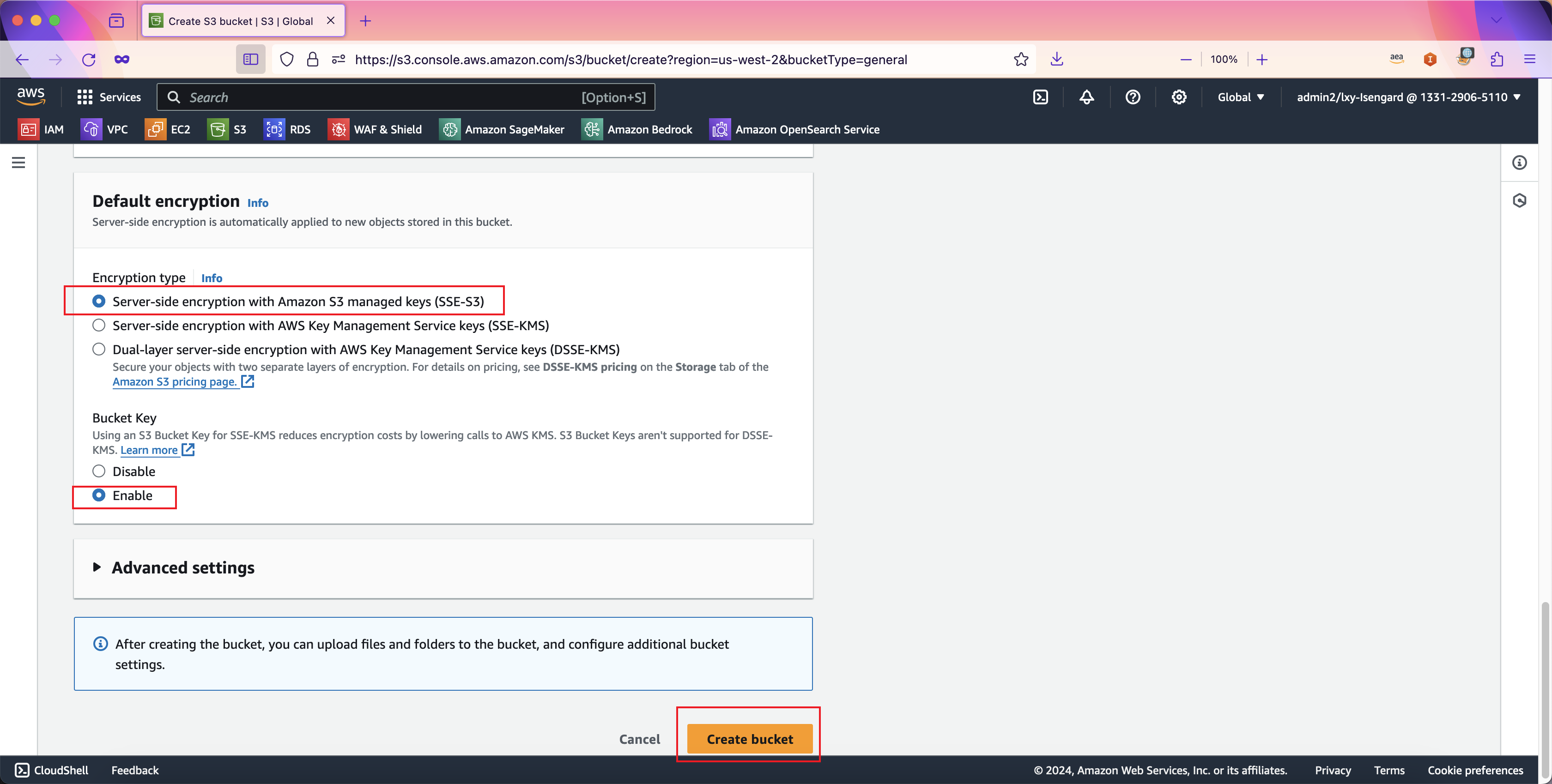
继续向下滚动页面。在默认加密的位置,选择第一项Server-side encryption with Amazon S3 managed keys也就是默认的加密算法(SSE-S3)。在Bucket key位置,选择Enable。最后点击创建按钮完成创建。
存储桶创建完毕。
现在向存储桶内上传文件,可上传PDF、Word等格式。支持的格式清单在下文同步知识库部分有介绍。
3、创建Bedrock知识库(自动生成向量数据库)
进入Bedrock服务,在左侧菜单下找到Knowledge Base,在右侧界面点击创建知识库。如下截图。
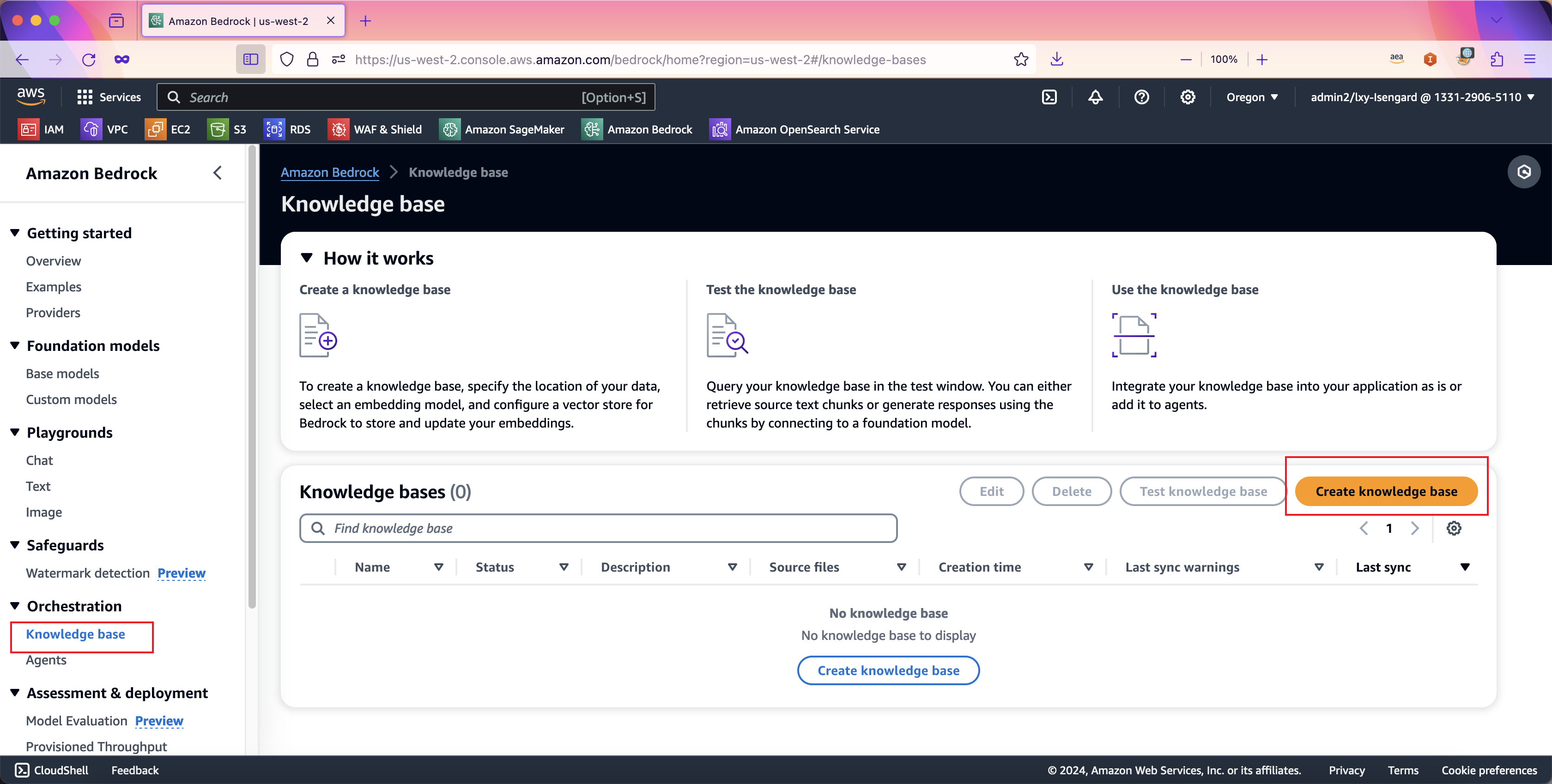
在向导第一步,创建知识库向导会自动生成一个知识库名称,可按需修改。在IAM权限位置,选择Create and use a new service role由Bedrock自动创建一个新的IAM角色用于知识库服务,其中会自动包含对应的Bedrock模型调用策略、S3存储桶访问策略、OpenSearch集群访问策略等。如果您要创建多个知识库,或者反复创建多次,请注意每次创建时候都选择自动生成一个新的IAM Role。这是因为多个知识库之前,他们使用的存储桶、OpenSearch集群是不一样的,因此如果您多个知识库使用一个IAM策略,那么会提示权限错误。因此建议创建新知识库时候都选择自动生成新的IAM策略。如下截图。
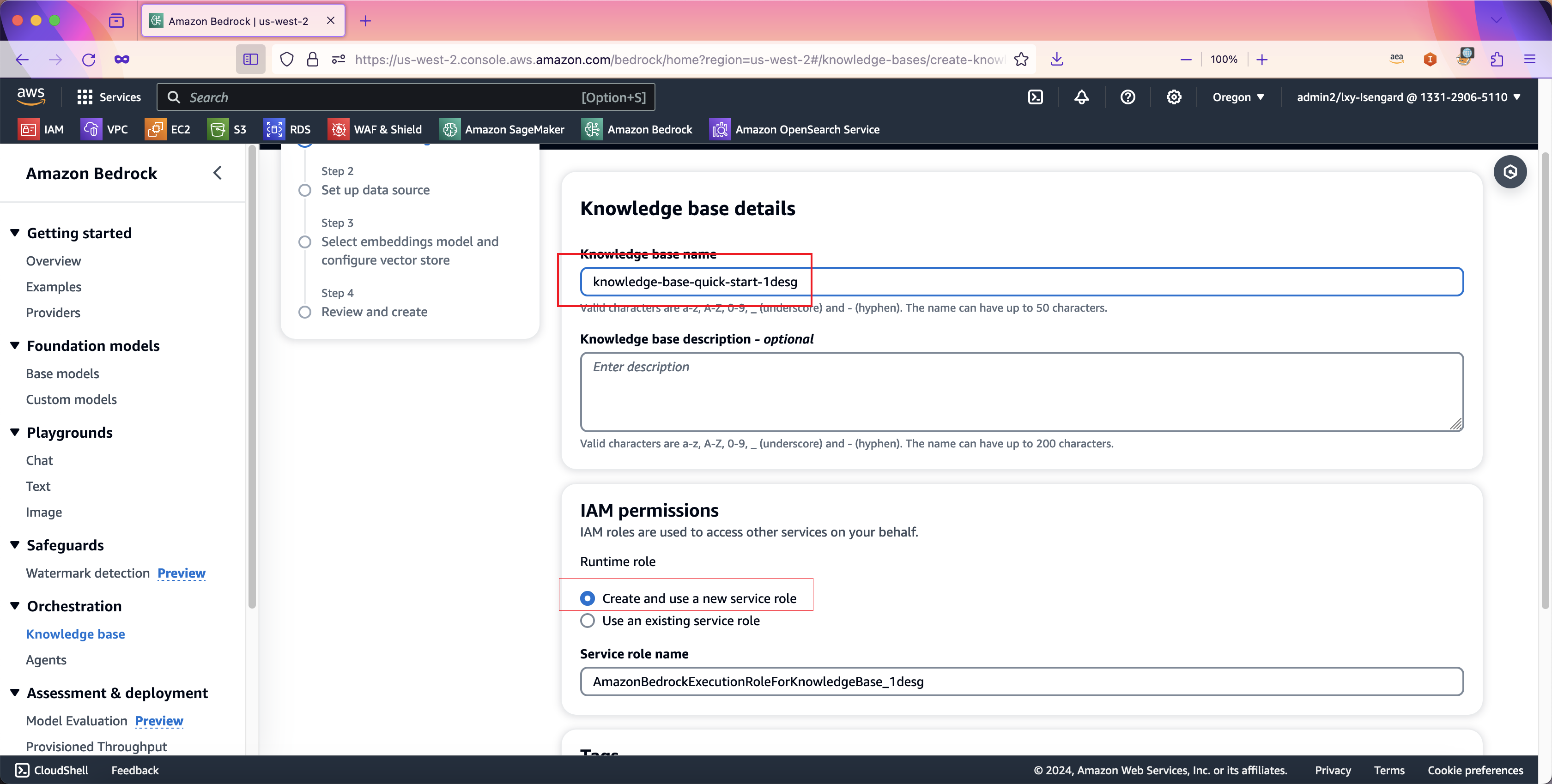
在向导第二步,数据源Data source name位置向导自动生成了一个名称,可按需修改。在数据源位置,输入上一步创建的S3存储桶的名称。如下截图。
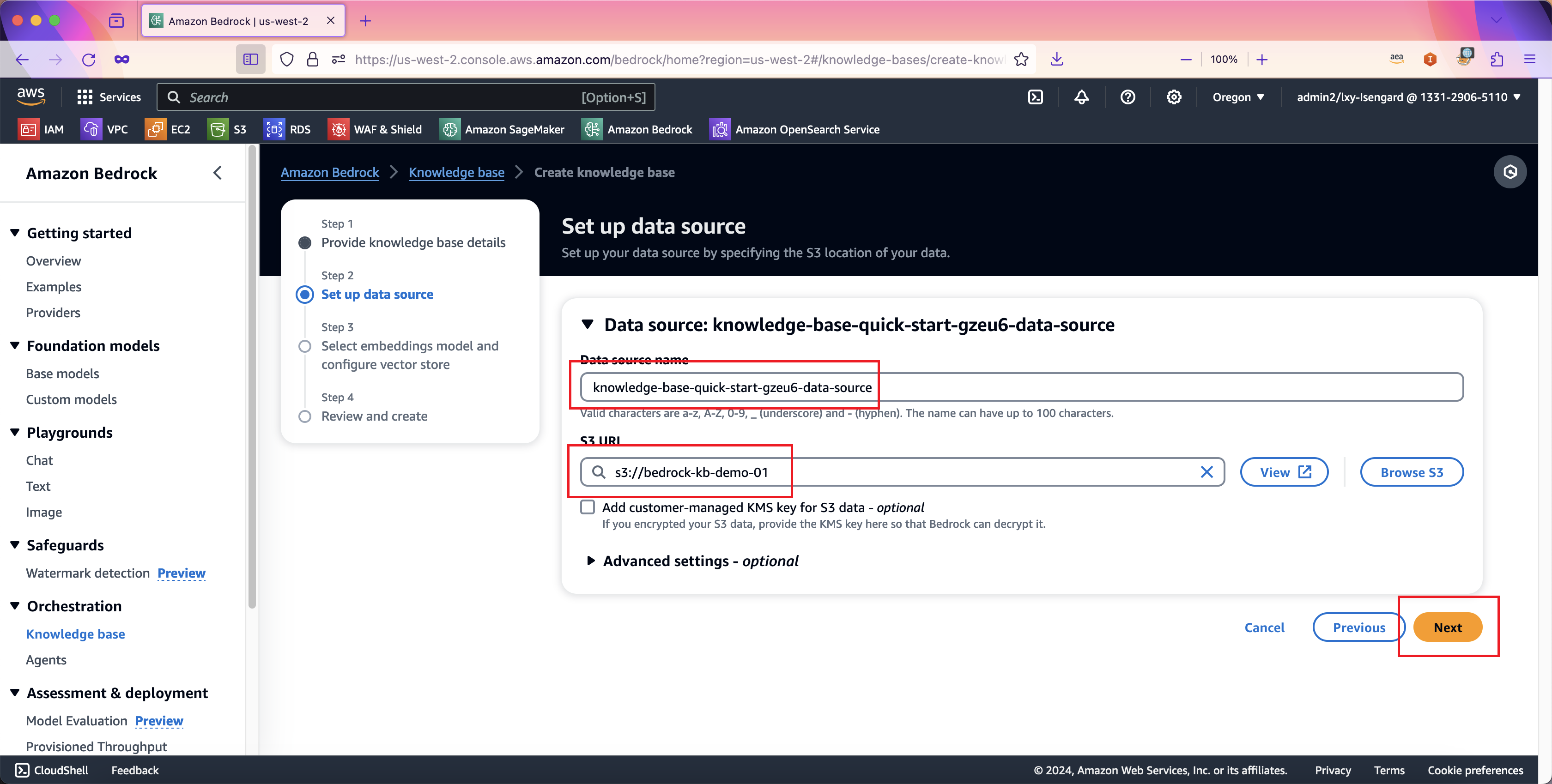
在向导第三步,选择向量Embedding模型位置,选择第一项Amazon Titan模型,至此向量维度是1536。然后向下滚动页面。如下截图。
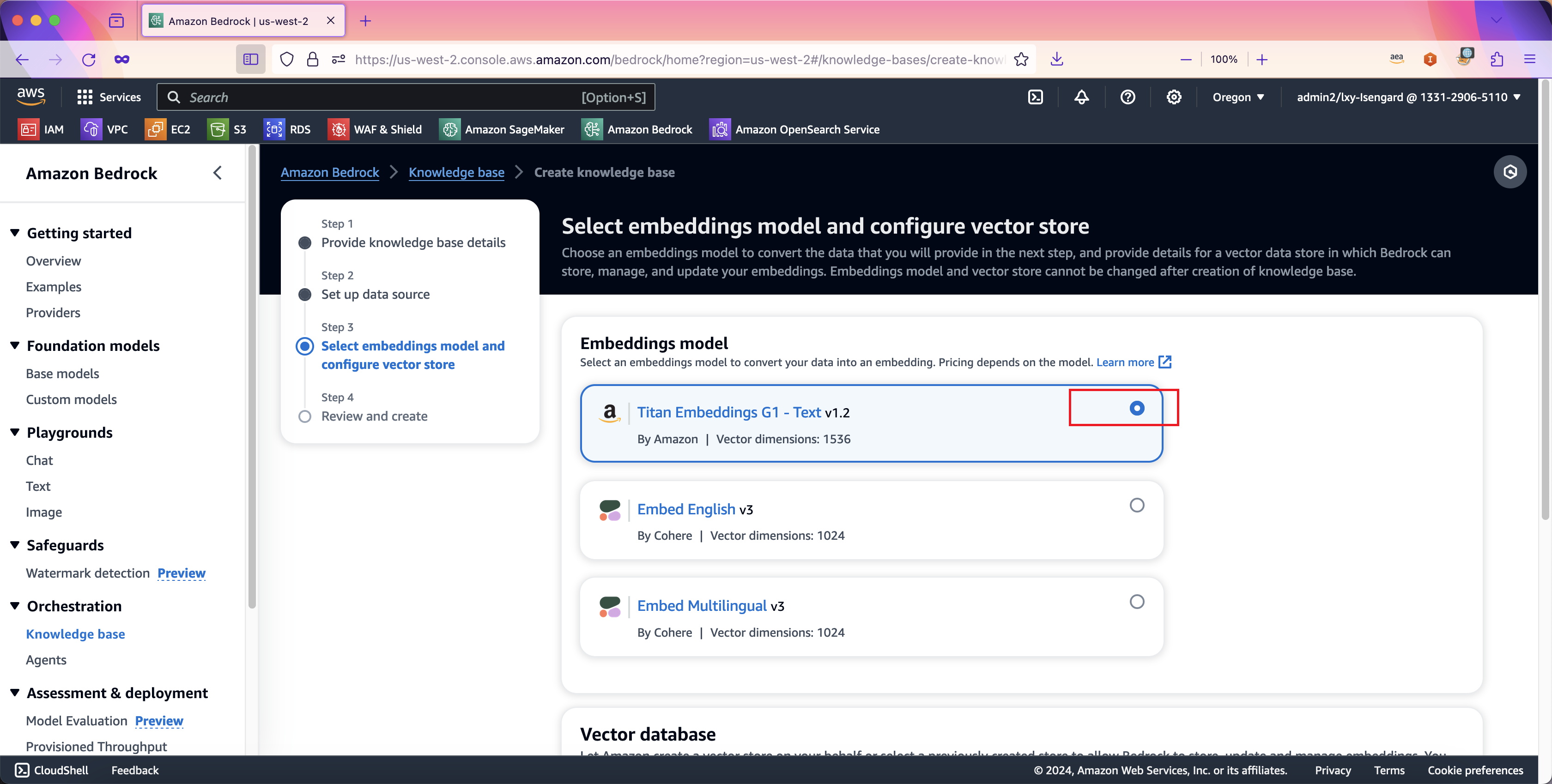
在向量数据库Vector database选择的位置,选择左侧的Quick create a new vector store - Recommended,也就是由Bedrock知识库向导为本知识库创建一个新的OpenSearch Serverless集群。这里还需要注意,默认创建的集群是成本优化型适合非关键业务,如果是关键业务,需要选择下方的选项Enable redundancy (active replicas) - optional来创建具有冗余能力的OpenSearch Serverless集群。然后点击下一步继续。如下截图。
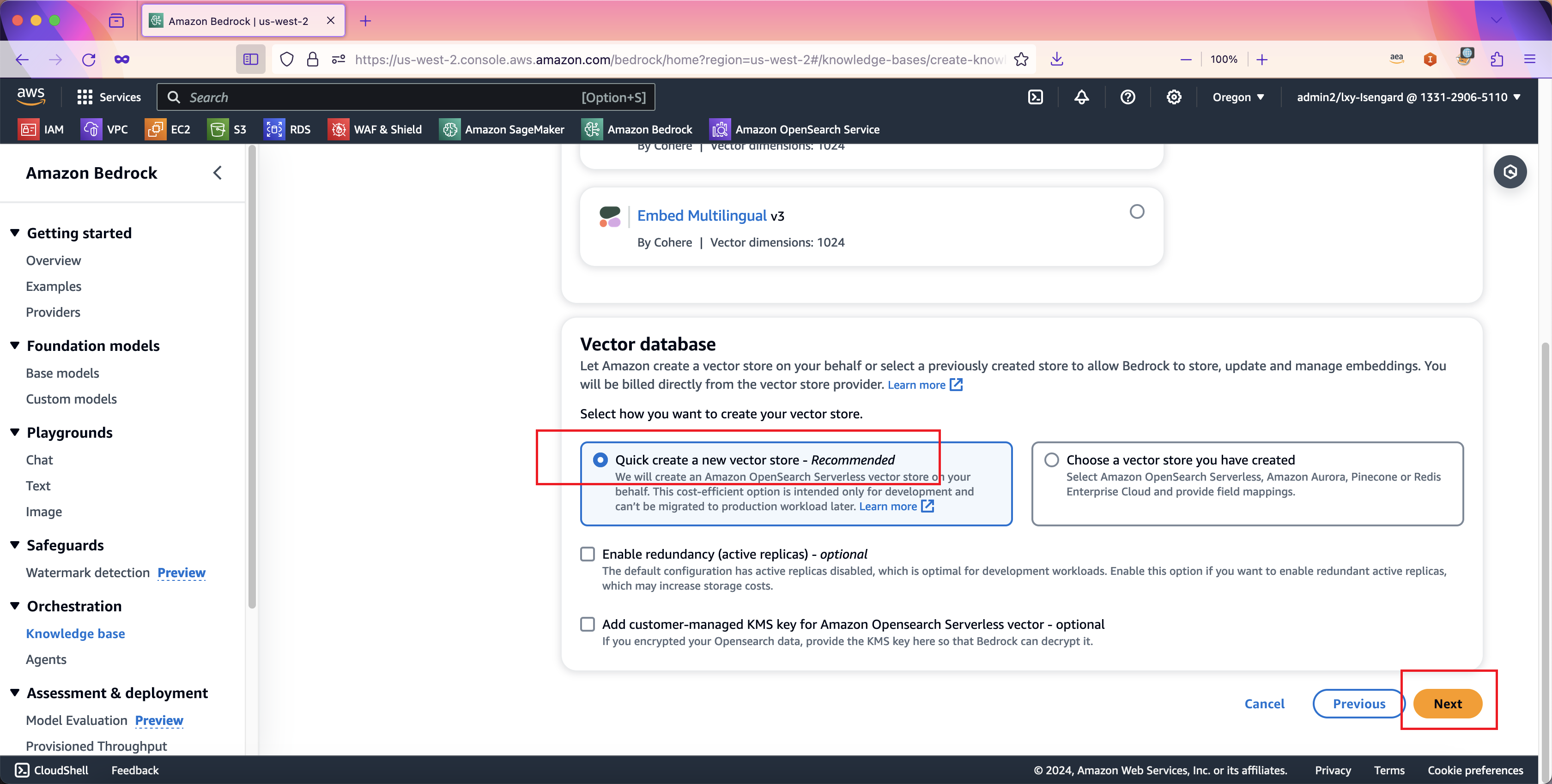
在向导第四步,Review之前的配置,不需要修改,直接点击创建。如下截图。
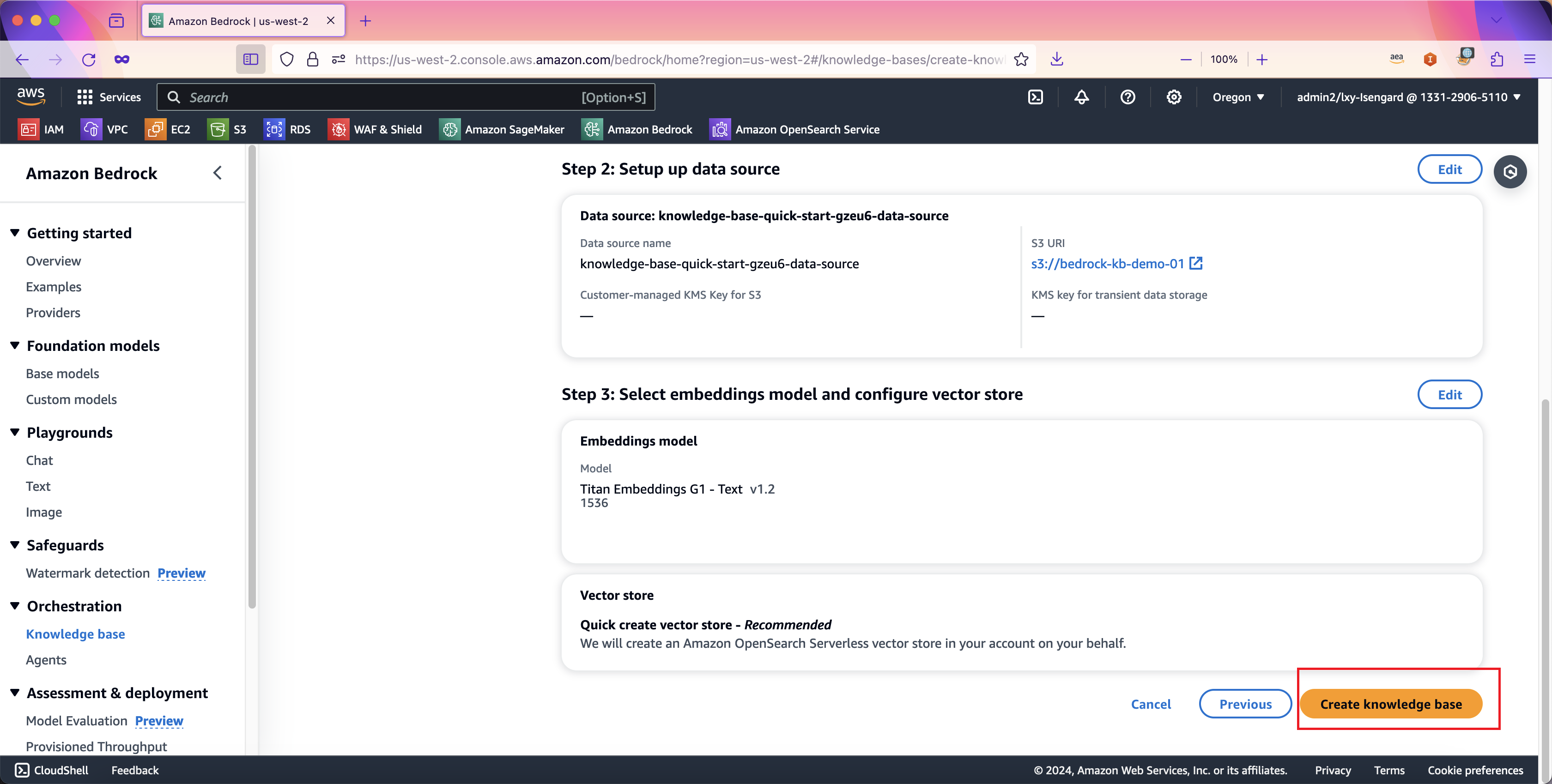
向导会卡在这个位置转圈圈。这是因为在后台创建OpenSearch Serverless集群。如果将页面向上滑动到最上方,可以看到有一个蓝色的条幅提示创建OpenSearch中。如下截图。
此时请不要离开当前页面,如果电脑休眠、网络中断、或者浏览器离开了当前页面,那么向导将只完成OpenSearch Serverless的创建,而不会完成整个Bedrock知识库的创建。如果发生了这种情况,您只能先删除掉OpenSearch Serverless,然后重新运行一遍Bedrock知识库创建向导。本步骤需要大概6分钟时间。因此请保持耐心等待本页面完成。
4、加载数据(同步数据)
当创建向导完成了Bedrock知识库的创建后,需要将S3存储桶内的数据加载到Bedrock服务中,通过向量模型生成向量,写入数据库。本步骤可通过在页面上按同步按钮进行数据加载。在创建知识库成功后,页面多个地方都提示需要进行数据同步。如下截图。
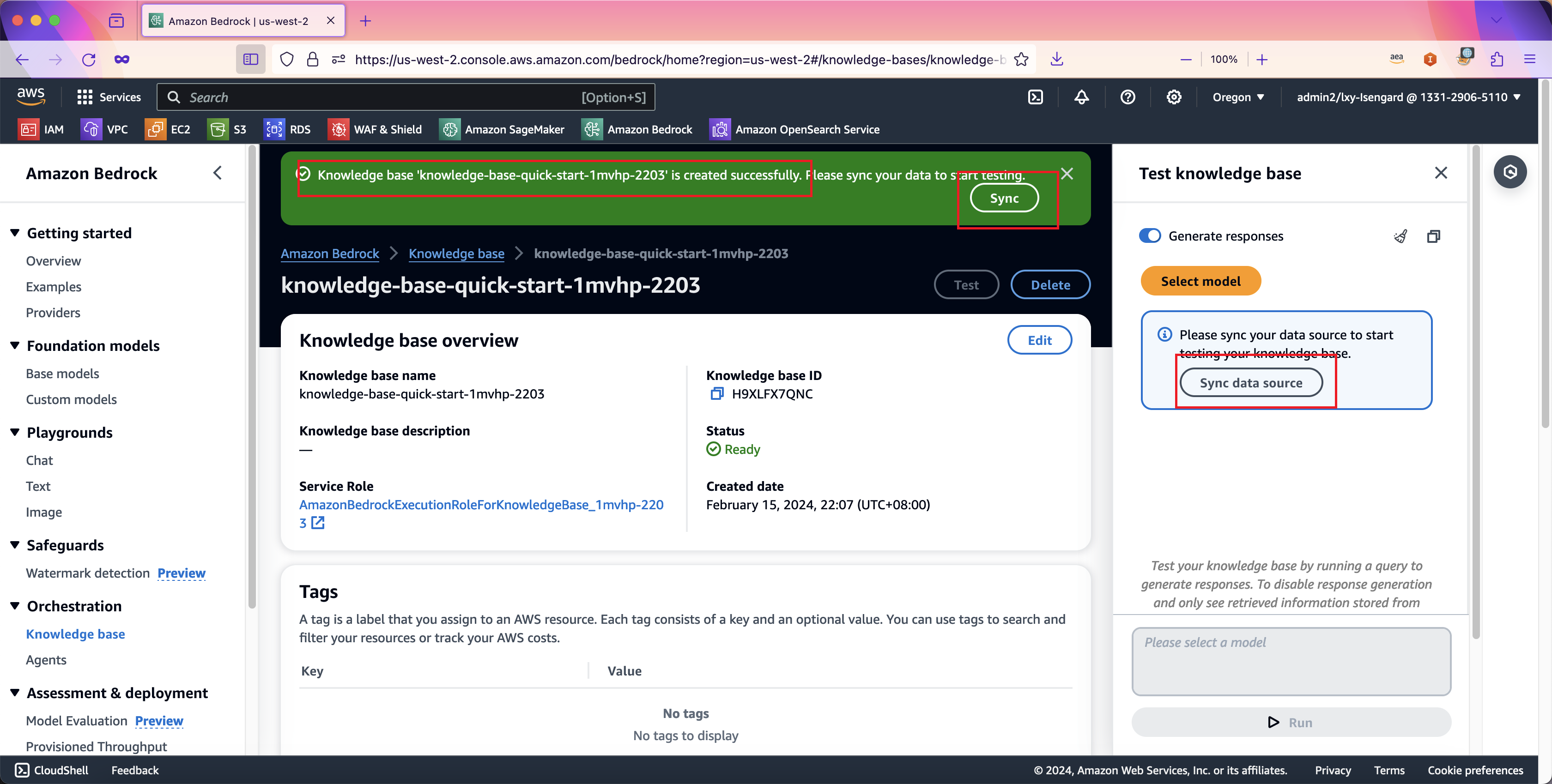
当数据同步进行中时候,Bedrock知识库服务的下方数据源部分,就会提示正在同步中。同步可能需要几分钟时间。如下截图。
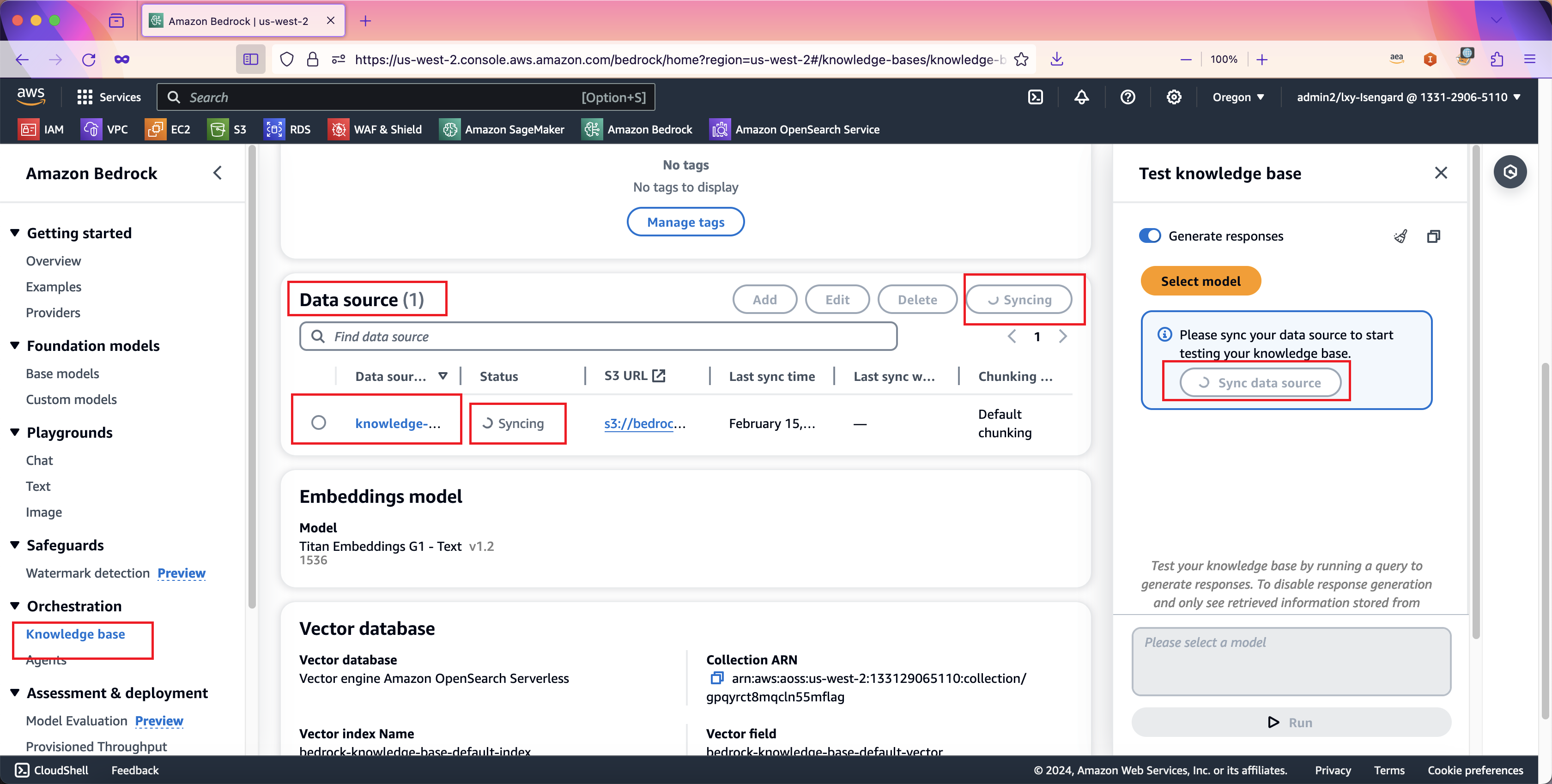
稍等几分钟后同步完成。
5、测试知识库召回
在数据同步完成后,Bedrock知识库界面上可进行测试。首先将上方的Generate respones的开关设置为关闭,这表示将仅测试向量数据库的召回,而不使用Claude等大语言模型进行重写。这样可测试之前的S3数据源和向量数据库是否正常。
输入测试问题,点击Run按钮,即可看到从向量数据库中召回的结果。如下截图。
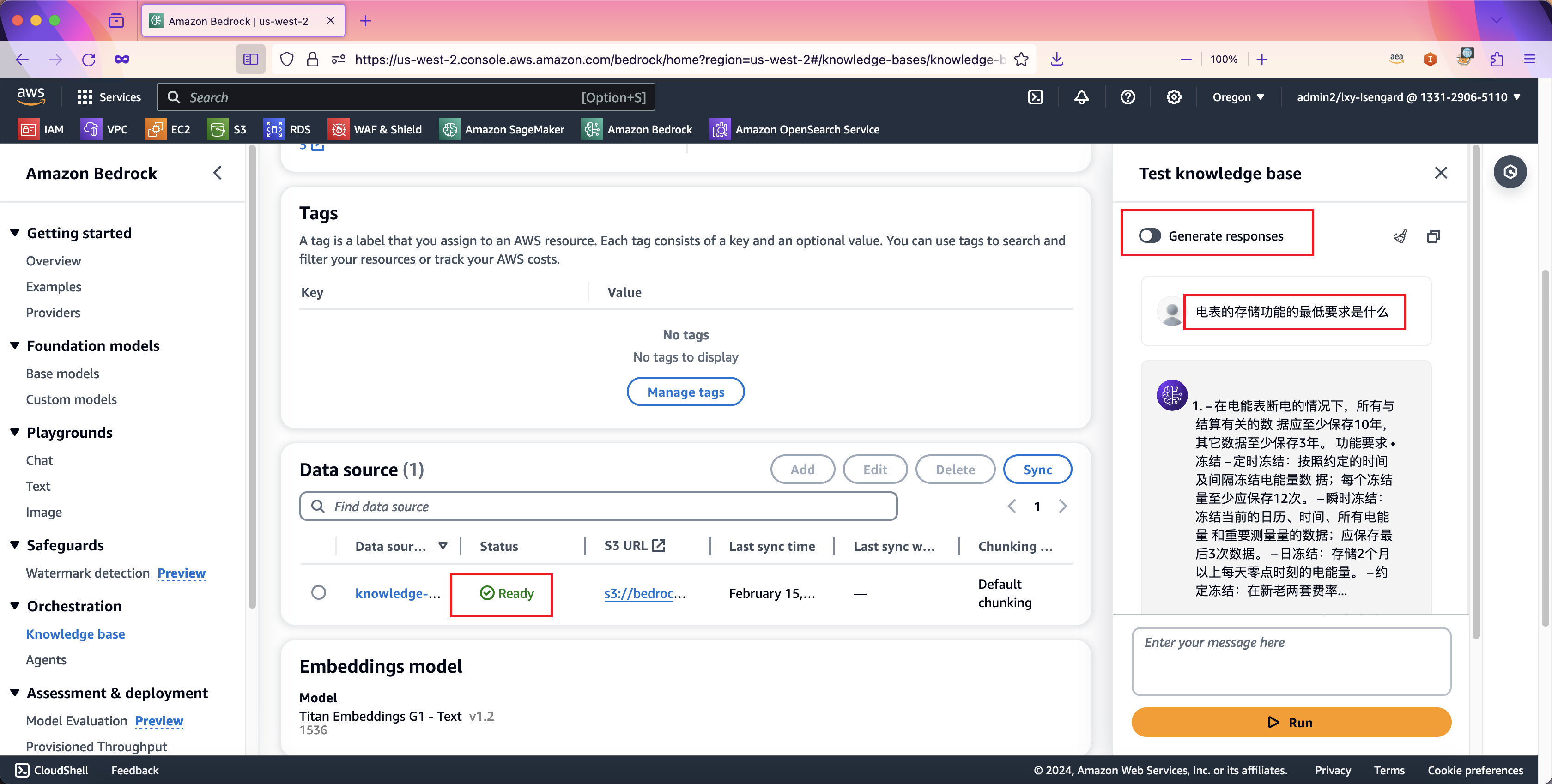
由此表示向量数据库工作正常。
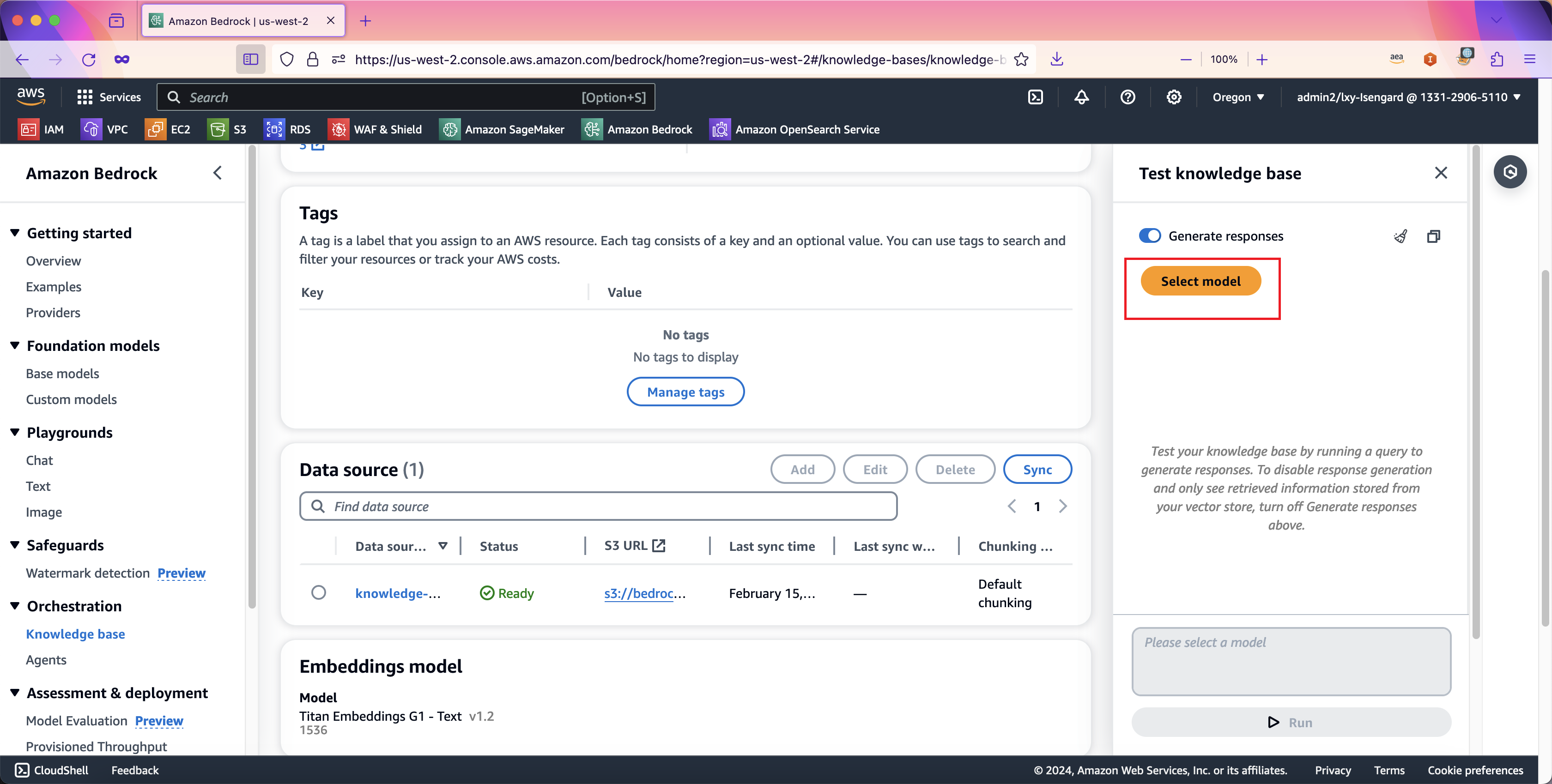
6、测试召回+内容生成
接下来测试将向量数据库召回的内容发送给大语言模型后的文字生成。将页面上Generate respones的开关设置为打开,然后点击Select model选项。如下截图。
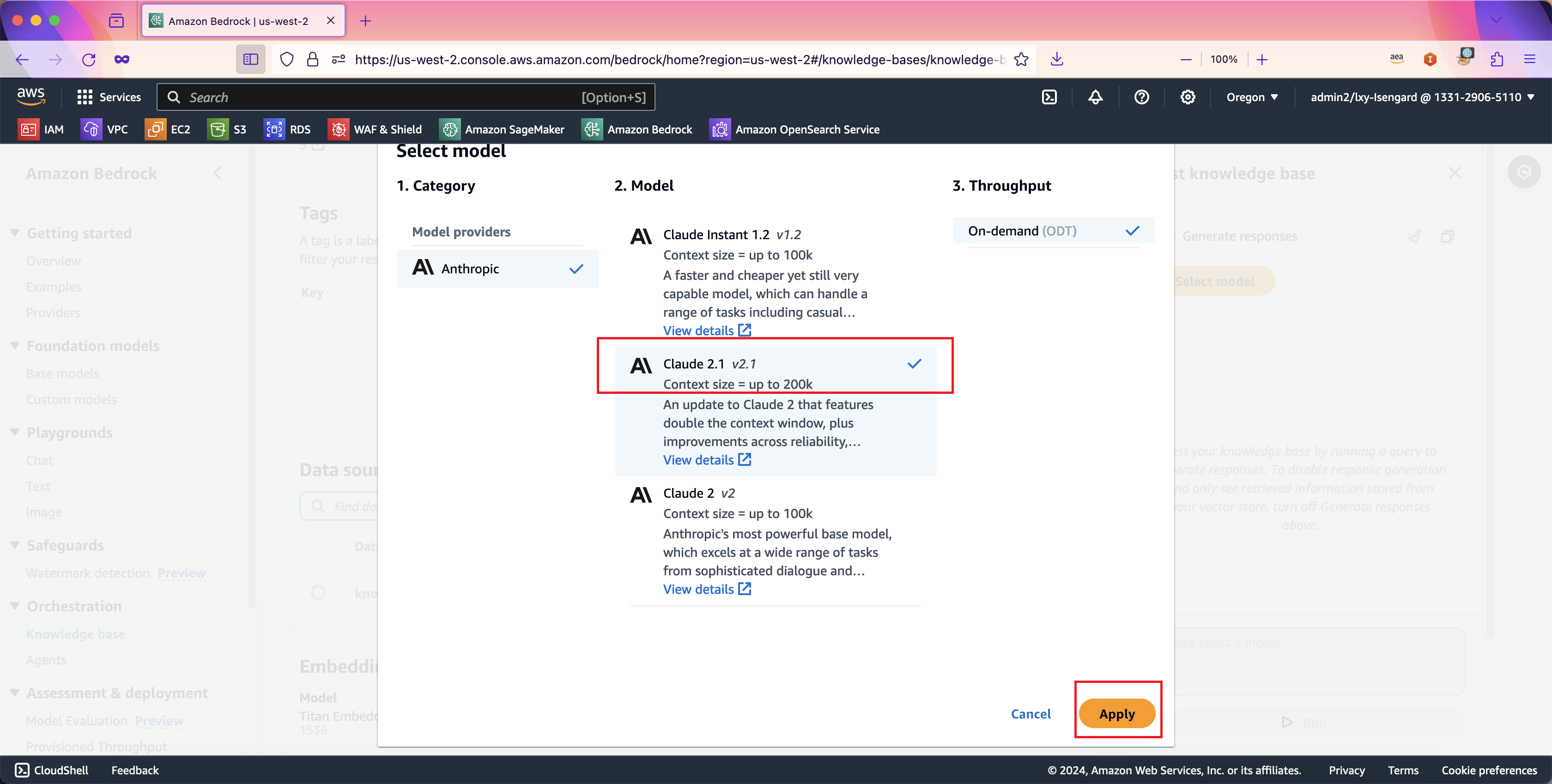
在选择模型的界面上,选择本文开始的已经申请过使用权限的模型,例如选择Claude V2.1版本。(这里在控制台上的测试我们使用Claude V2.1模型,在本文后续的代码样例中,将使用成本更低的Claude Instant模型)。点击下一步继续。如下截图。
在测试知识库的对话框中提出问题,即可看到结合了向量知识库、私有数据、以及大语言模型生成的文字,并且附带有私有文档的原始出处用于参考(避免大模型生成文本的幻想)。如下截图。
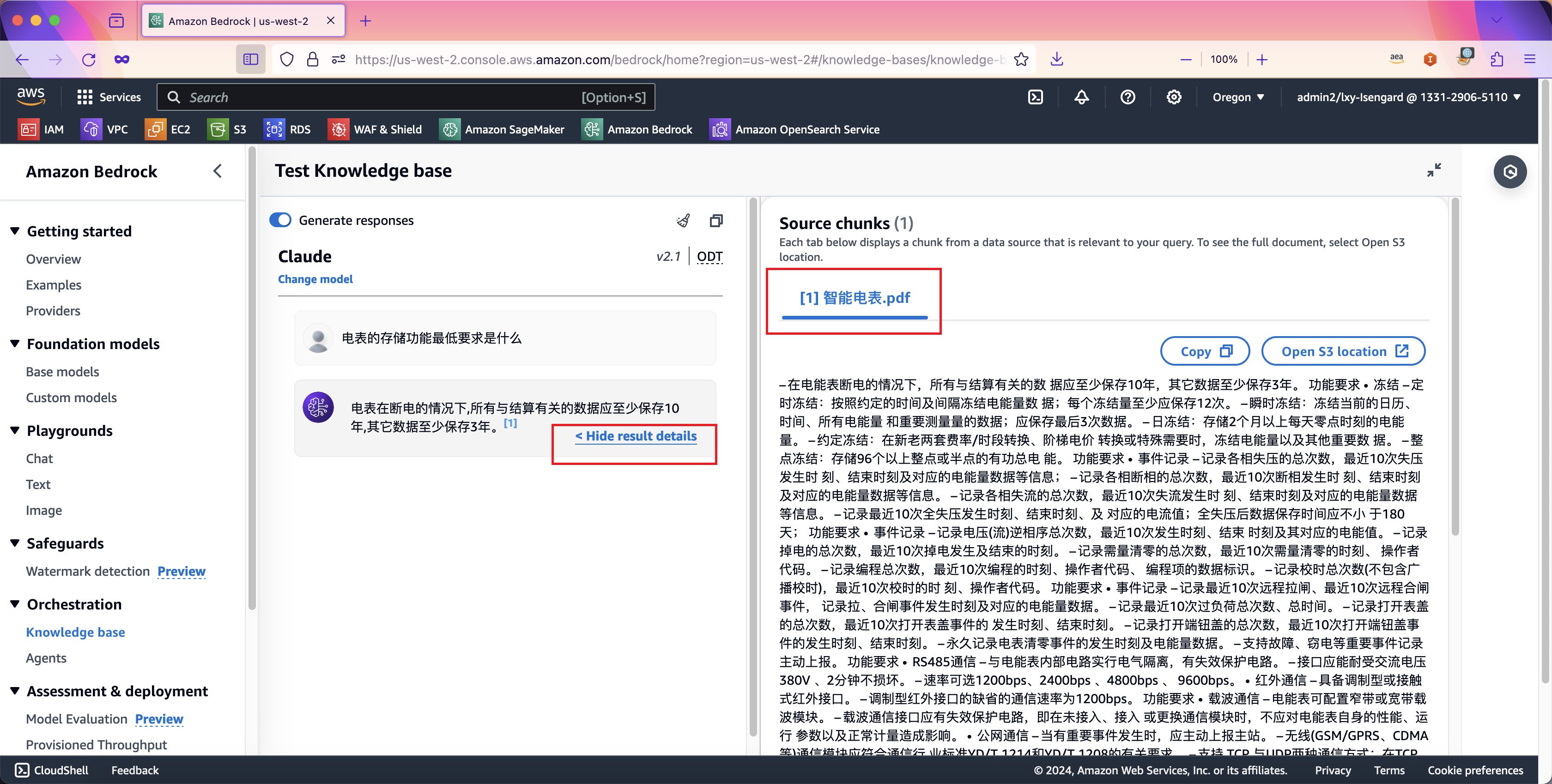
7、新数据导入知识库/旧数据删除
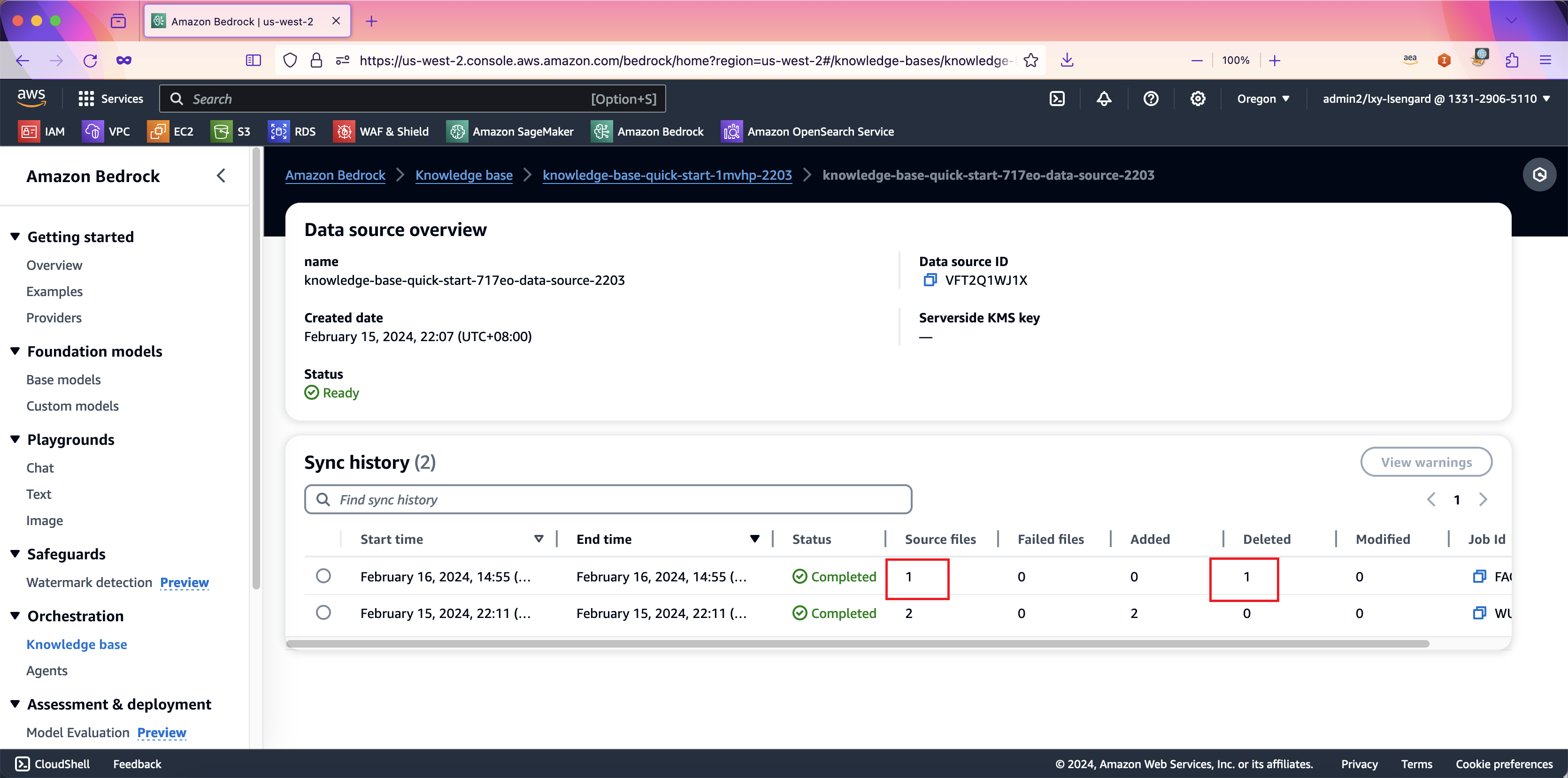
新的数据导入知识库的过程与首批数据导入的方式一样,那就是先将数据以Bedrock支持的格式保存到S3存储桶内,然后在Bedrock知识库服务的下方数据源部分按Sync同步按钮,即可触发导入。新数据是以增量方式导入的,S3上已经存在的文件不会重复加载。Bedrock会将本次新上传的文件发送到模型生成向量,然后保存到向量知识库中。
如果现有数据想要从向量数据库中删除,那么只需要将数据文件从S3存储桶内删除,然后在知识库界面上的数据源位置,再发起一次同步即可。同步后,被删除的文件会显示为已删除。如下截图。
三、编写Prompt实现问答机器人
1、针对知识库的单次提问(召回+生成API)
Bedrock服务将整个RAG过程封装为API,用户不需要再进行向量相关操作。例如您可以发起名为Retrieve的请求来仅仅查询从向量数据库召回的结果,也可以发起名为RetrieveAndGenerate的请求,将召回结果送给大语言模型处理重写后,直接返回最终结果。
在API调用的易用性角度,Bedrock为多种编程语言包括Java、Python等提供了SDK开发包。使用SDK引入Bedrock runtime库文件,您可仅用数行代码就能完成对Bedrock知识库的调用。本机需要事先配置AWSCLI、AWS的Access Key/Secret Key,并安装Python3的Boto3库。
pip install boto3
以下代码中需要注意,Bedrock知识库调用的Runtime的名字和直接访问模型调用的Runtime名字不一样,叫做bedrock-agent-runtime。另外,请查询Bedrock控制台上知识库的界面即可看到其知识库ID,将其也代入如下的代码中。代码样例如下:
import boto3
session = boto3.Session(
region_name="us-west-2"
)
brt = session.client('bedrock-agent-runtime')
query = '智能电表公网通信的要求是什么'
response = brt.retrieve_and_generate(
input={
'text': query
},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': 'H9XLFX7QNC',
'modelArn': 'anthropic.claude-instant-v1'
}
}
)
sessionid= response['sessionId']
answer = response['output']['text']
print(sessionid)
print(answer)
返回信息第一行就是Session ID,然后是生成的内容如下:
d8188f86-d21c-4848-b59e-8f545a25489f
智能电表公网通信的要求是:
- 支持TCP与UDP两种通信方式;在TCP方式下,到心跳周期时,应主动与主站心跳3次;
- 支持“永久在线”、“被动激活”两种工作模式;可由主站设定。
- 无线(GSM/GPRS、CDMA等)通信模块应符合通信行业标准YD/T 1214和YD/T 1208的有关要求。
以上内容为知识库私有内容,原始内容来自S3存储桶中的PDF内。
2、使用Bedrock知识库仅召回API+自行编写Prompt构建问答机器人
在Bedrock知识库的召回+生成API调用时候是不能传入大段的Prompt提示词的,只能传入要query查询的问题。要构建一个完整的问答机器人,编写一段针对问题机器人场景的Prompt又是必需的。此时可以仅调用Bedrock知识库仅召回API,而不触发模型重写文字。然后通过代码与准备好的Prompt拼接到一起,再调用大模型重写即可。由此既能利用Bedrock知识库的全托管RAG的体验,又可实现有自信编写Prompt的自由度。
构建问答机器人需要的API如下(注意是不仅函数不同,Client端也不同):
- 对知识库仅向量召回不重写调用的API:
bedrock-agent-runtime的retrieve - Bedrock模型的调用的API:
bedrock-runtime的invoke_model
结合之前Bedrock Prompt优化最佳实践的这篇博客的例子,这里给出一个Python样例代码,包括Prompt可直接调用。
import boto3
import json
model = "anthropic.claude-3-sonnet-20240229-v1:0"
# step-0
# connection for claude
boto3_session = boto3.session.Session()
bedrock_runtime = boto3_session.client(
'bedrock-runtime',
region_name='us-west-2',
)
# connection for bedrock-knowledge-base
session = boto3.Session(
region_name="us-west-2"
)
brt = session.client('bedrock-agent-runtime')
# query knowledge base (仅召回/retrieve only)
def query_knowledge_base(query):
response = brt.retrieve(
retrievalQuery= {
'text': query
},
knowledgeBaseId = 'FBQL0NDDFZ' ,
retrievalConfiguration= {
'vectorSearchConfiguration': {
'numberOfResults': 5
}
}
)
return response['retrievalResults']
# build prompt structure (召回结果included)
def build_prompts(query, context):
# 向量数据库的相关内容召回
reference = query_knowledge_base(query)
# 组合Prompt并代入召回结果 & 代入历史对话
prompts = """
你是智能电表助手小手雷,了解智能电表相关专业知识。下边<reference>标签中会给出来自知识库的专业知识,<context>标签会提示你之前的对话。根据<rule>标签中的要求,回答用户提问。
参考资料如下:
<reference>
{reference}
</reference>
之前对话的上下文如下:
<context>
{context}
</context>
以下是我要问你的问题:
<question>
{query}
</question>
当你回答问题时你必须遵循以下准则:
<rule>
1. 不要过分解读问题,不要回答和问题无关的内容
2. 回答问题要简明扼要,如果不知道就回答不知道,不要凭空猜想
3. 回答的内容请输出在<response>标签之间
</rule>
""".format(query=query, reference=reference, context=context)
return prompts
# 历史对话记录
def build_context(context, query, output_str):
context.append({'role': 'Human', 'content': query})
context.append({'role': 'Assistant', 'content': output_str})
return context
# 将组合后的Prompt发给Claude重写
def inference(query, context):
query = query
context = context
prompt = build_prompts(query, context)
body = json.dumps({
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 5000,
"temperature": 0,
"anthropic_version": "bedrock-2023-05-31"
})
response = bedrock_runtime.invoke_model_with_response_stream(
modelId = model,
body=body
)
stream = response.get('body')
output_list = []
# 流式输出
for event in response.get("body"):
chunk = json.loads(event["chunk"]["bytes"])
if chunk['type'] == 'content_block_delta':
if chunk['delta']['type'] == 'text_delta':
output_str = chunk['delta']['text']
print(output_str, end="")
# 合并之前所有流的文字到一起输出
output_list.append(output_str)
# 去掉合并所有流时候里边不必要的分隔符
output_list = ''.join(output_list).strip().replace("<response>", "").replace("</response>", "")
return output_list
# main
if __name__=="__main__":
print("\n-----------------------\n")
query = "第1问:你是谁?"
context = []
print("*** 本次提问 *** \n", query)
print("*** 本次回答 ***")
output_str = inference(query, context)
context = build_context(context, query, output_str)
print("\n-----------------------\n")
query = "第2问:智能电表保存那些数据?"
print("*** 之前的对话 *** \n", context)
print("*** 本次提问 *** \n", query)
print("*** 本次回答 ***")
output_str = inference(query, context)
context = build_context(context, query, output_str)
print("\n-----------------------\n")
query = "第3问:智能电表记录下哪些事件?"
print("*** 之前的对话 *** \n", context)
print("*** 本次提问 *** \n", query)
print("*** 本次回答 ***")
output_str = inference(query, context)
context = build_context(context, query, output_str)
print("\n-----------------------\n")
query = "第4问:智能电表遵循哪些国家规范?"
print("*** 之前的对话 *** \n", context)
print("*** 本次提问 *** \n", query)
print("*** 本次回答 ***")
output_str = inference(query, context)
context = build_context(context, query, output_str)
print("\n-----------------------\n")
至此实现了知识库检索。
四、参考文档
Amazon Bedrock知识库官网
https://aws.amazon.com/cn/bedrock/knowledge-bases/
Set up your data for ingestion
https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-setup.html
Query a knowledge base
https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-api-query.html
Bedrock API (Python3): retrieve_and_generate
最后修改于 2024-02-18