在Amazon Bedrock服务以导入模型的方式运行Mimo-VL模型
详解如何在Amazon Bedrock导入Xiaomi-MiMo-VL模型,解决模型部署复杂性问题,实现Serverless推理,包含冷启动处理和成本对比分析。
一、背景
当考虑在云上部署自有模型或第三方模型时,有两条技术路线,一是采用EC2 GPU机型部署,自己构建对外服务API;二是采用Bedrock的Import Model导入功能导入自有模型然后使用Bedrock的ServerlessAPI对外提供服务。
在过往的博客文章中,如下文章分别介绍了这两种部署方式:
Bedrock的模型导入功能,允许用户将自己训练的模型或者第三方模型导入到Bedrock中,并以Serverless的方式对外提供。在2025年初的时候,仅支持Meta开源的Llama架构的模型,在2025年下半年,支持国产Qwen系列模型,目前对Qwen-2.5-VL等提供支持。后续支持的版本以官网为准。
本文将演示如何在Bedrock上导入 Xiaomi-MiMo-VL-Miloco 模型。
关于在这两种方式之间如何选择,这里方案对比如下:
| 对比 | EC2 GPU部署 | Bedrock导入模型 |
|---|---|---|
| 架构限制 | 无,任何架构均可 | 有限制,目前Bedrock仅支持特定架构模型导入,例如Qwen-2.5系列 |
| 部署方便程度 | 复杂 | 简单 |
| 后续维护成本 | 高,需要自建监控、告警、日志等 | 低, Bedrock负责基础设施运维 |
| 安全性 | 手工管理认证、日志等,复杂且风险点和漏洞多 | 借助Bedrock服务API的认证和审计,安全 |
| 高可靠性 | 手工部署多台实例、手工搭建负载均衡、健康检查等 | 借助Bedrock服务的高可用设计,无需关注底层基础设施 |
| 弹性扩展 | 手工配置EC2监控并实现自动弹性扩展 | Bedrock自动管理负载和弹性扩展 |
| 冷启动 | EC2长期不关机时候,不存在冷启动的情况 | 持续2个五分钟无人访问资源暂停,会触发冷启动,因此高频访问需要预热 |
| 成本 | 长期占用EC2、需要买预留实例,适合并发压力巨大、能跑满GPU的场景 | 按需调用,无访问不收费,适合并发不高、波峰波谷变化幅度较大的场景,但如果全天24小时调用成本较高 |
| 适用场景 | 复杂业务逻辑、个性化定制需求强 | 快速部署、标准化API调用、对模型进行推理 |
二、从Huggingface下载模型并上传到S3
1、原始文件下载
由于模型文件体积较大,因此这里不将模型下载到开发者本机了,而是选择在云上创建一个EC2,下载模型后,直接上传到S3并完成导入。
创建一个不含GPU的EC2,例如m7i.large,系统选择Ubuntu 24.04,磁盘选择大于30GB即可(满足下载要求)。创建完毕后,通过SSH登陆到这个EC2,安装Huggingface的软件包。执行如下命令:
sudo apt update
sudo apt upgrade -y
sudo apt install pipx net-tools curl unzip -y
pipx install huggingface_hub
pipx ensurepath
sudo reboot
重启完成后,下载模型文件到用户的根目录下。
cd /home/ubuntu/
hf download xiaomi-open-source/Xiaomi-MiMo-VL-Miloco-7B --local-dir ./Xiaomi-MiMo-VL-Miloco-7B
2、修改模型配置文件
Amazon Bedrock服务支持Qwen-2.5-VL架构的模型的,但是在模型配置文件中,不支持填写rope_scaling字段。因此这个字段需要从配置文件中删除后,再上传到S3。
编辑文件 /home/ubuntu/Xiaomi-MiMo-VL-Miloco-7B/config.json ,找到其中rope_scaling这一段,内容如下:
"rope_scaling": {
"factor": 1.0,
"mrope_section": [
16,
24,
24
],
"original_max_position_embeddings": 128000,
"rope_type": "default",
"type": "default"
},
将以上整个rope_scaling的标签删除。保存退出。
3、配置AWSCLI及密钥用于上传数据的权限
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install
aws configure
按提示配置好AWSCLI的Access key和Secrect key,就具有了上传到S3的权限。
4、创建S3存储桶并上传模型文件
进入AWS控制台,在要使用Bedrock的区域,创建S3存储桶,类型选择General purpose buckets即可。
在刚才的EC2上运行如下命令上传模型:
aws s3 cp --recursive Xiaomi-MiMo-VL-Miloco-7B s3://your-bucket-name/Xiaomi-MiMo-VL-Miloco-7B/
由此即可完成模型上传。
三、导入到Bedrock
1、执行导入
登陆到Bedrock控制台。切换到要使用模型的Region。从左侧的菜单中找到Import models,在右侧点击Import model按钮。如下截图。
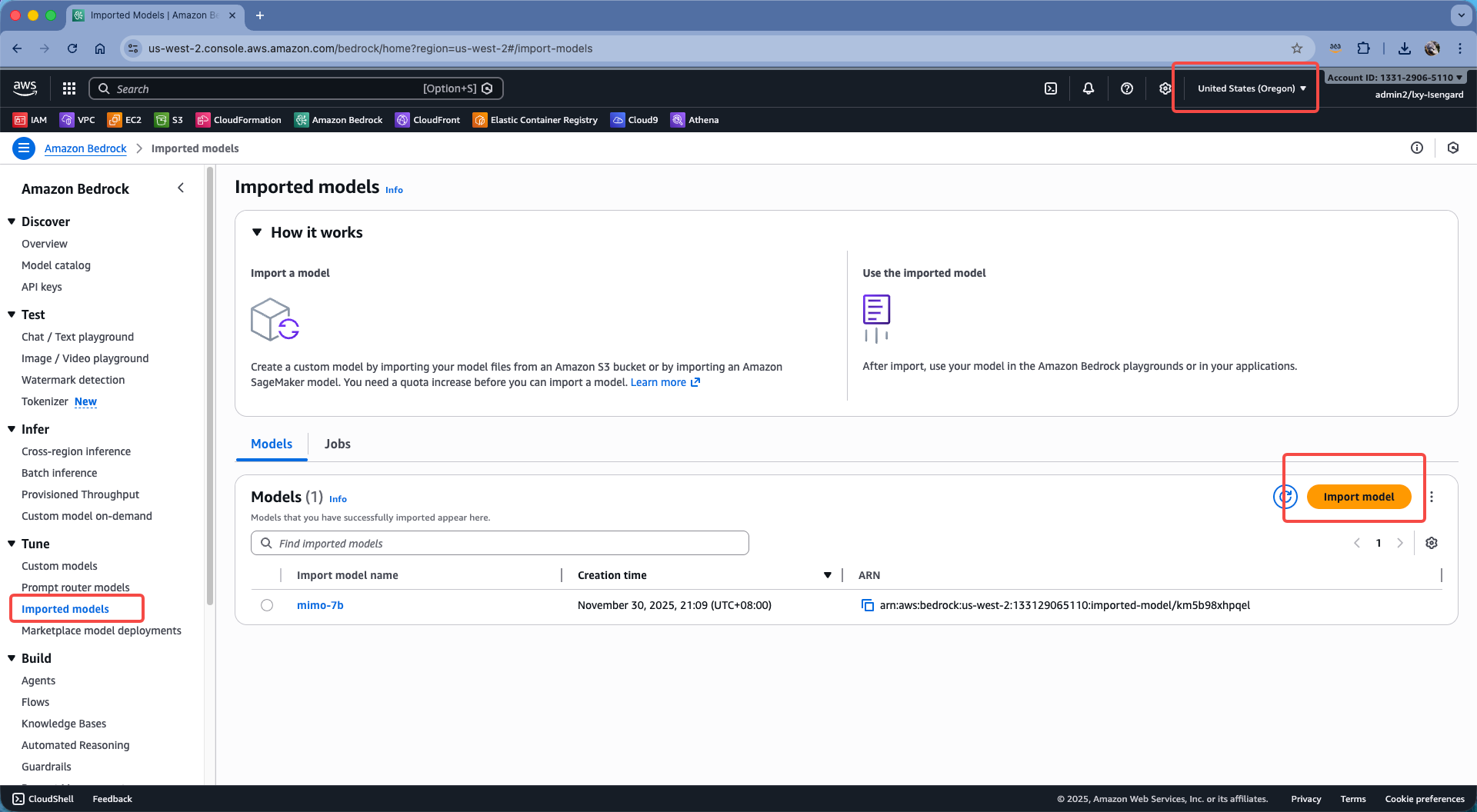
在上方设置任务名称,下方会自动生成Job name。这里无需修改,继续向下滚动屏幕。如下截图。
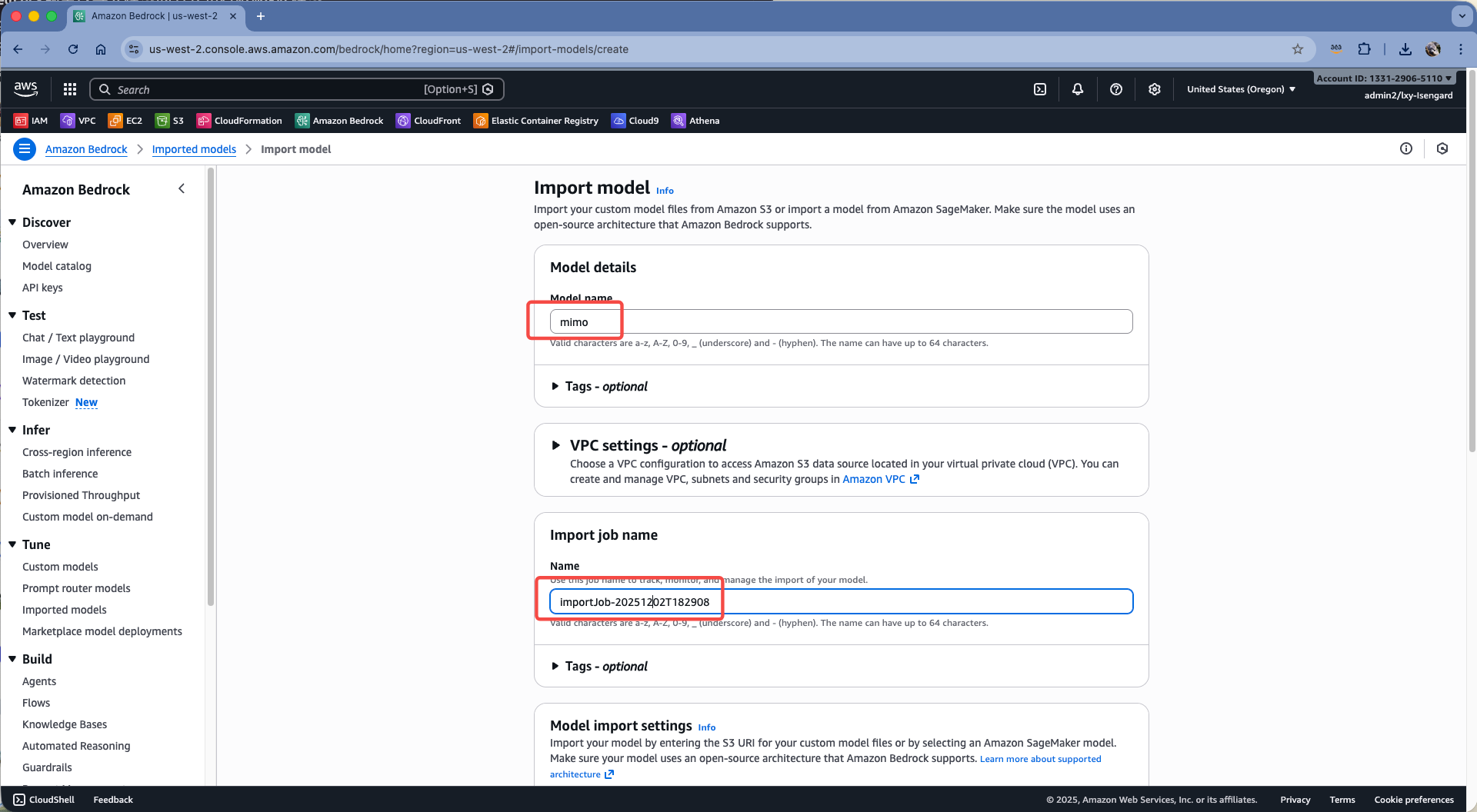
在存储桶位置,选择上一步上传模型的S3桶,注意不要选择存储桶根目录,而是要指定模型所在的目录。然后在Service access位置,选择自动创建service role。如下截图。
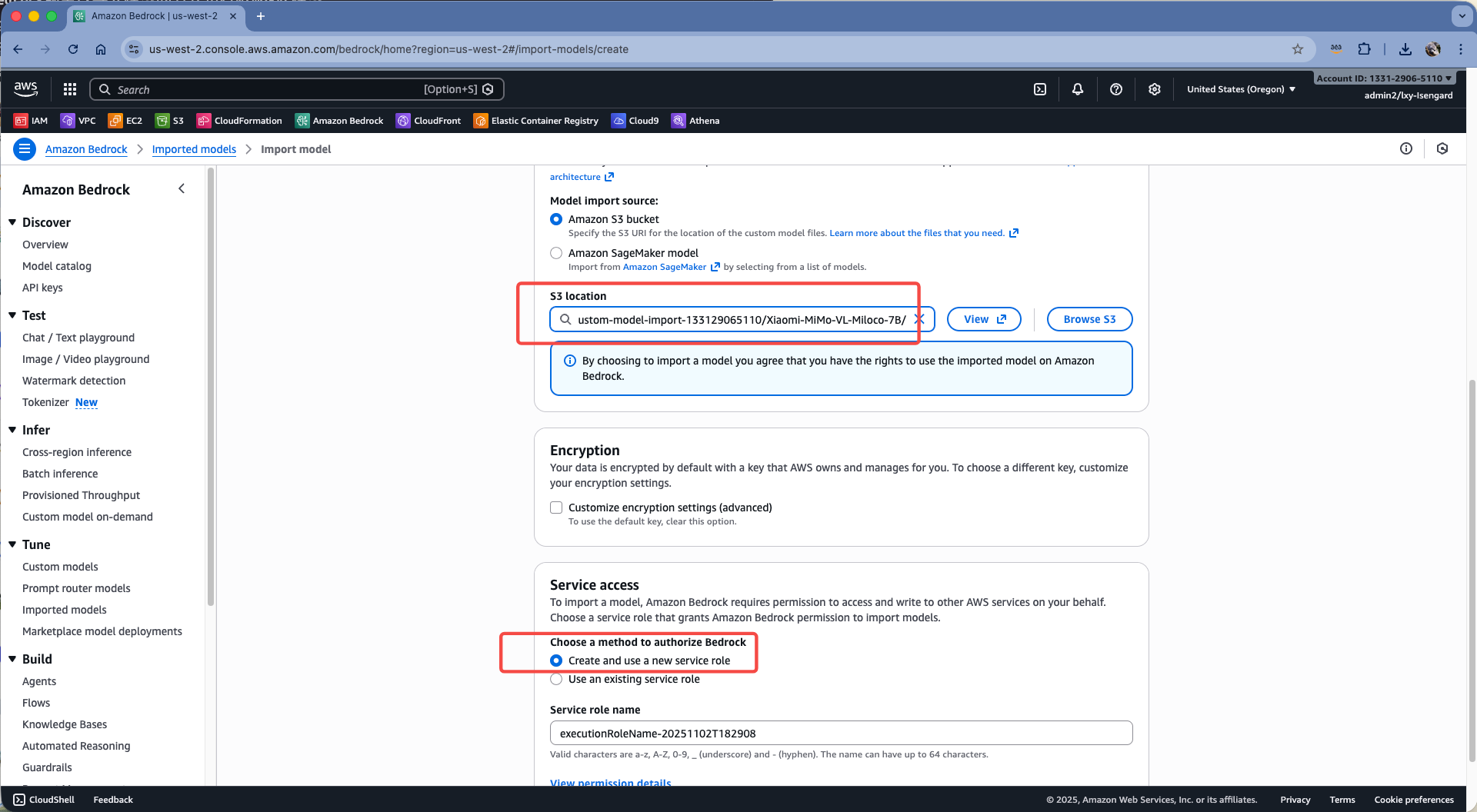
最后点击屏幕右下角的Import model。点击后可能要等待5-10分钟。
注意:前边没有修改模型的Config文件,会遇到报错:
The model configuration violates the following requirements: [Amazon Bedrock could not validate the configuration file. Rope_scaling does not support key (scaling_factor), please remove it from rope_scaling config.]
此时需要编辑S3上的Config文件,删除掉其中的rope_scaling标签有关配置,再次发起模型导入即可。
2、从Bedrock控制台测试
等待大概15分钟后,模型导入完毕。通过Bedrock控制台可看到这个模型。点击模型ID查看详情。如下截图。
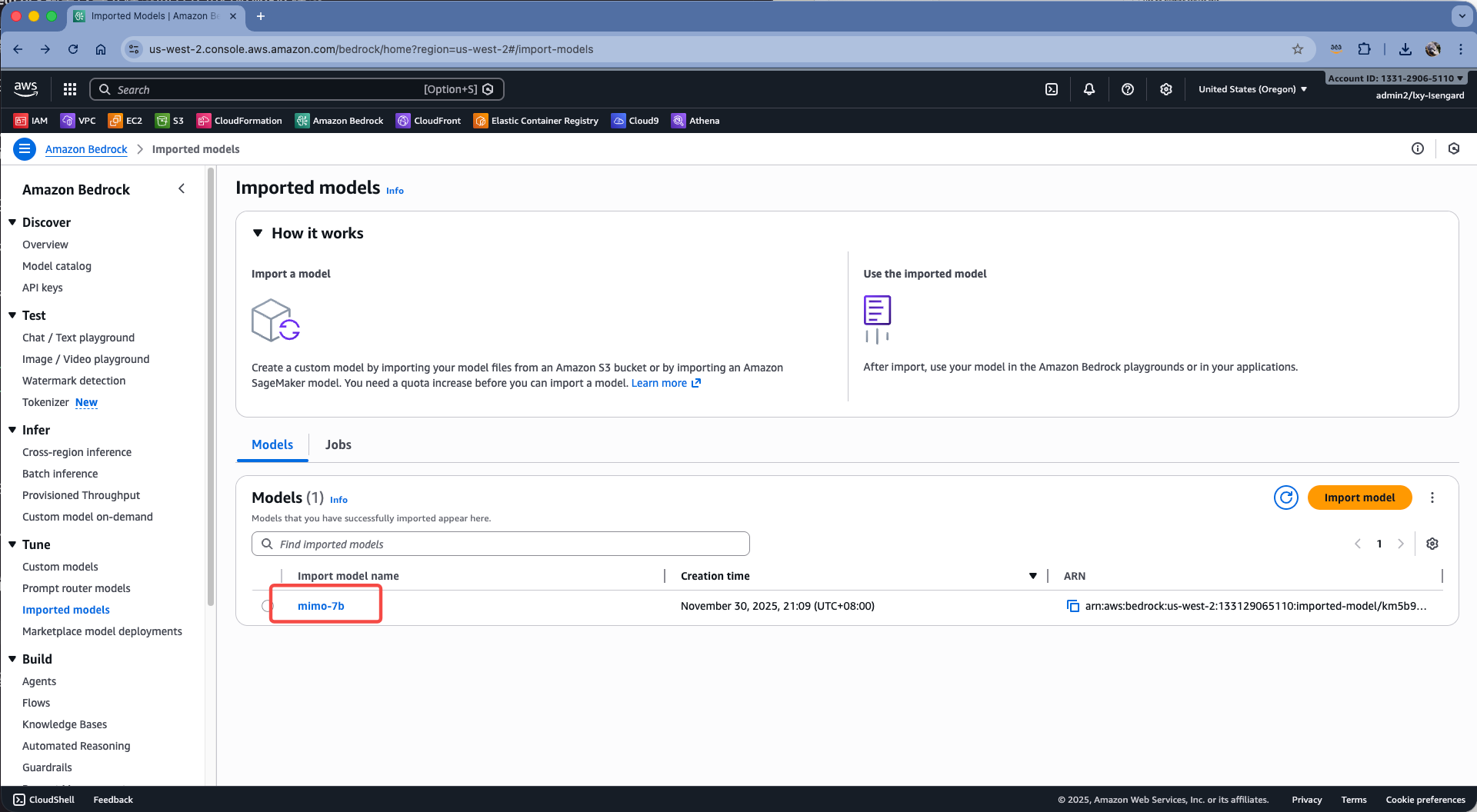
在模型详情位置,点击右上角的Open in playground。如下截图。
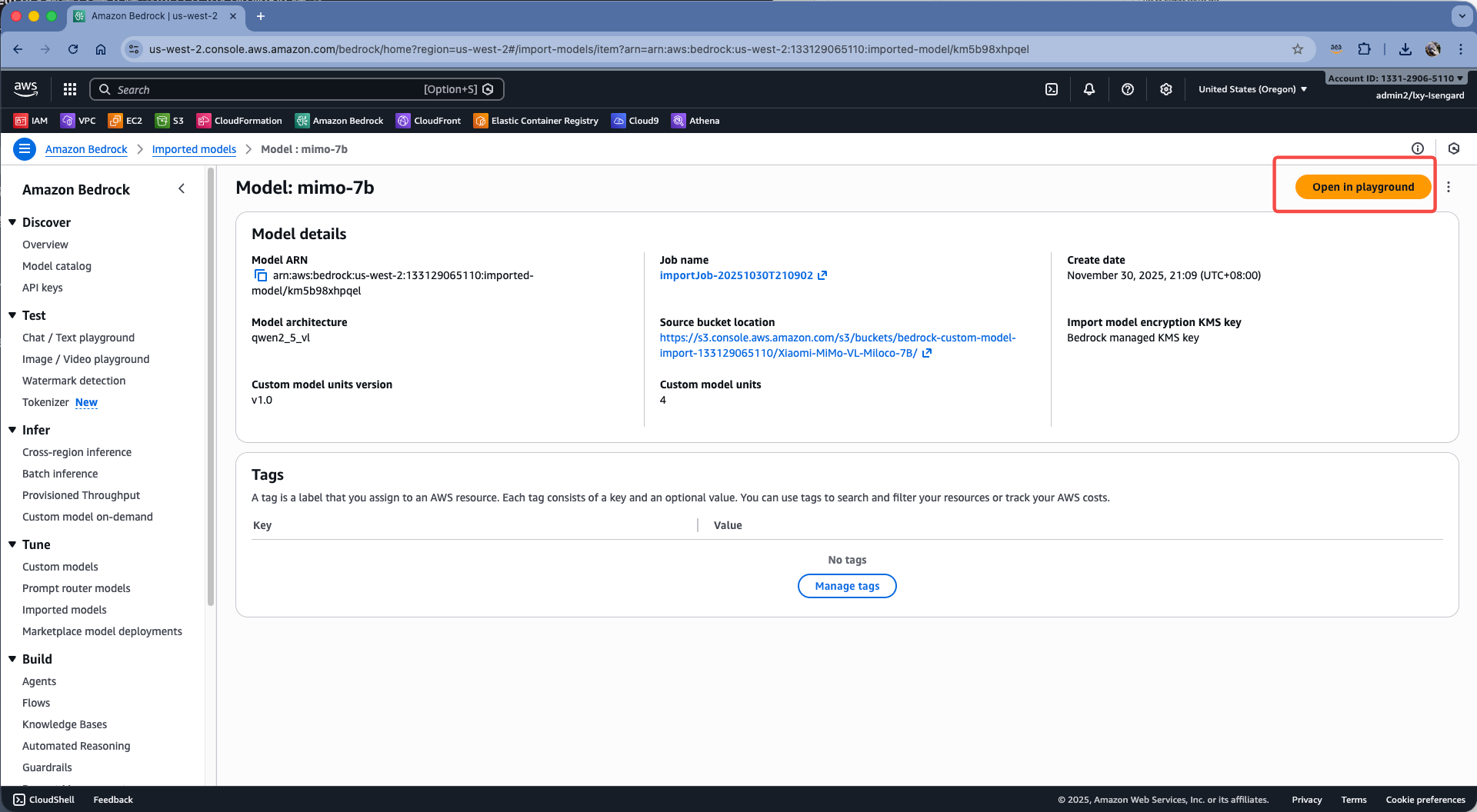
在对话环境中,输入测试Prompt,可获取返回结果。注意此时如果长时间没有调用模型,模型会被释放,再次发起请求会有一个冷启动时间(大概1-2分钟)。此时发送Prompt会收到错误信息:“模型尚未就绪”。此时需要等待一段时间后,刷新整个浏览器页面,然后重新发起调用即可成功。
关于冷启动的,在会第五章节介绍。
四、在代码中使用SDK调用
在前一步导入模型成功后,可以看到导入模型的id,类似如下格式:
arn:aws:bedrock:us-west-2:133129065110:imported-model/km5b98xhpqel
稍后在代码中,就需要指定这个id来交互。代码例子如下(代码已经包含冷启动检测逻辑)。
import boto3
import json
import re
import time
from botocore.config import Config
from botocore.exceptions import ClientError
def chat(prompt: str, show_thinking: bool = True, max_tokens: int = 1024):
"""
调用 Bedrock 上的 MiMo 模型进行对话(使用 Messages API 格式)
Args:
prompt: 用户输入的问题
show_thinking: 是否显示思维过程
max_tokens: 最大生成token数
"""
# 禁用 boto3 的自动重试,改为手动控制,以便立即检测到冷启动
config = Config(
retries={
'max_attempts': 1 # 禁用自动重试,立即返回错误
}
)
bedrock = boto3.client('bedrock-runtime', region_name='us-west-2', config=config)
model_id = "arn:aws:bedrock:us-west-2:133129065110:imported-model/km5b98xhpqel"
# 使用 Messages API 格式(这是 console 使用的格式)
body = json.dumps({
"messages": [
{"role": "user", "content": prompt}
],
"max_tokens": max_tokens,
"temperature": 0.7,
"top_p": 0.9
})
print(f"📝 问题: {prompt}\n")
# 尝试调用模型,处理冷启动情况
max_retries = 60 # 最多重试60次(约5分钟)
retry_count = 0
cold_start_detected = False
start_time = time.time()
result = None
while retry_count <= max_retries:
try:
response = bedrock.invoke_model(
modelId=model_id,
body=body
)
# 如果之前检测到冷启动,现在成功了,显示恢复信息
if cold_start_detected:
elapsed = time.time() - start_time
print(f"✅ 模型已恢复,耗时 {elapsed:.1f} 秒\n")
result = json.loads(response['body'].read())
break # 成功,跳出循环
except ClientError as e:
error_code = e.response['Error']['Code']
if error_code == 'ModelNotReadyException':
if not cold_start_detected:
# 第一次检测到冷启动 - 立即显示
cold_start_detected = True
elapsed = time.time() - start_time
print("🔄 检测到模型冷启动...")
print(" 模型正在恢复中,这通常需要 1-3 分钟")
print(" 系统会自动重试,请稍候...\n")
retry_count += 1
elapsed = time.time() - start_time
# 每10秒显示一次进度
if retry_count % 5 == 0:
print(f" ⏳ 等待中... 已等待 {elapsed:.0f} 秒")
# 等待5秒后重试
time.sleep(5)
else:
# 其他错误,直接抛出
print(f"❌ 调用失败: {error_code}")
print(f" 错误信息: {e.response['Error']['Message']}")
raise
except Exception as e:
print(f"❌ 发生未知错误: {str(e)}")
raise
if result is None:
# 重试次数用尽
elapsed = time.time() - start_time
print(f"❌ 模型恢复超时(已等待 {elapsed:.0f} 秒),请稍后再试或联系 AWS 支持")
return
# 提取响应内容
if 'choices' in result and len(result['choices']) > 0:
full_response = result['choices'][0]['message']['content']
else:
full_response = ""
# 解析 thinking 和 answer 部分
# MiMo 模型使用 <think>...</think> 标记思维过程
think_pattern = r'<think>(.*?)</think>'
think_match = re.search(think_pattern, full_response, re.DOTALL)
if think_match:
thinking_content = think_match.group(1).strip()
# 移除 thinking 部分,剩下的就是回答
answer_content = re.sub(think_pattern, '', full_response, flags=re.DOTALL).strip()
else:
thinking_content = ""
answer_content = full_response.strip()
# 输出结果
if thinking_content and show_thinking:
print("🧠 思维过程:")
print("─" * 60)
print(thinking_content)
print("─" * 60)
print()
print("💬 回答:")
print(answer_content)
print("\n" + "=" * 60 + "\n")
if __name__ == "__main__":
# 测试 1: 显示思维过程
chat(
"请简单介绍一下你自己,你是由谁开发的什么模型,有哪些主要能力?",
show_thinking=True,
max_tokens=1024
)
# 测试 2: 只显示回答
chat(
"北京是中国的首都吗?",
show_thinking=False,
max_tokens=512
)
返回结果如下:
📝 问题: 请简单介绍一下你自己,你是由谁开发的什么模型,有哪些主要能力?
🧠 思维过程:
────────────────────────────────────────────────────────────
嗯,用户想让我简单介绍一下自己,包括开发者、模型类型和主要能力。这是一个很直接的自我介绍请求。
首先,我需要明确我的身份。我是小米大模型core团队开发的MiMo,属于小米大模型core团队。这是一个核心的事实,必须准确传达。
接下来,我需要描述我的模型类型。我属于小米自研的MiMo系列,这是一个多模态大模型,这意味着我能处理文本、图像等多种信息形式。
然后,我需要概括我的主要能力。作为AI助手,我的核心能力包括理解用户意图、进行自然语言对话、提供信息查询服务,以及进行创意写作和内容生成。我还具备多模态理解能力,可以分析和回应图像内容。此外,我还能进行逻辑推理和问题解答。
最后,我需要强调我的核心价值。我的目标是成为用户值得信赖的AI伙伴,通过提供高效、准确、有温度的服务,帮助用户解决各种问题,提升生活和工作的效率与乐趣。
我将把这些信息组织成一个简洁、流畅的回答,确保用户能快速了解我的基本情况和核心功能。
────────────────────────────────────────────────────────────
💬 回答:
好的,非常乐意为您介绍!
我是**MiMo**,由**小米大模型core团队**开发的AI助手。
**关于我的核心信息:**
1. **开发者:** 我是由小米公司自主研发的核心团队(小米大模型core团队)打造的。
2. **模型类型:** 我属于**小米自研的MiMo系列多模态大模型**。这意味着我不仅能理解文本,还能处理和分析图像等多种信息形式。
3. **主要能力:**
* **自然语言理解与对话:** 我能理解您的问题、意图和上下文,进行流畅、自然的对话交流。
* **信息查询与解答:** 我可以提供知识解答、事实核查、信息检索等服务。
* **创意生成:** 我能进行写作、创作、故事生成、诗歌创作等创意活动。
* **多模态理解:** 我能分析和回应图像内容(例如描述图片、回答关于图片的问题)。
* **逻辑推理与问题解决:** 我具备一定的逻辑推理能力,可以帮助您分析问题、提供解决方案。
* **个性化服务:** 我会根据您的需求和偏好,提供定制化的帮助和建议。
**我的核心价值:**
我的目标是成为您值得信赖的AI伙伴,通过提供**高效、准确、有温度**的服务,帮助您解决各种问题,提升生活和工作的效率与乐趣。
很高兴能与您交流!有什么我可以帮您的吗?
============================================================
📝 问题: 北京是中国的首都吗?
💬 回答:
是的,**北京是中国的首都**。
自1949年中华人民共和国成立至今,北京一直作为中国的首都,是中国的**政治中心、文化中心、国际交往中心和科技创新中心**。
* **政治中心**:全国人民代表大会、国务院、最高人民法院、最高人民检察院等国家最高权力机关和行政机关都设在北京。
* **文化中心**:拥有众多故宫、长城、天坛等世界文化遗产,以及北京大学、清华大学等顶尖学府。
* **国际交往中心**:是世界上拥有最多国际组织总部的城市之一,也是举办国际会议和活动的重要场所。
* **科技创新中心**:中关村是世界知名的科技创新中心,聚集了大量的高新技术企业和科研机构。
此外,北京还是中国明清两朝的都城(北京城),拥有悠久的历史和深厚的文化底蕴。
============================================================
五、关于冷启动和预热机制
1、关于冷启动
导入到Bedrock的模型,并不会一直占用GPU资源。Bedrock为其提供了根据访问负载缩放的能力,这就意味着在无人访问时候,模型可以缩放到0,以减少不必要的资源消耗和费用。
查看模型运行占用的资源的方法是:在CloudWatch的Metrics中查看活跃的模型副本数量。方法是进入CloudWatch,点击左侧菜单的Metrics,点击Bedrock服务。如下截图。
在展开的菜单中高,点击By ModelId,按模型ID查看监控参数。如下截图。
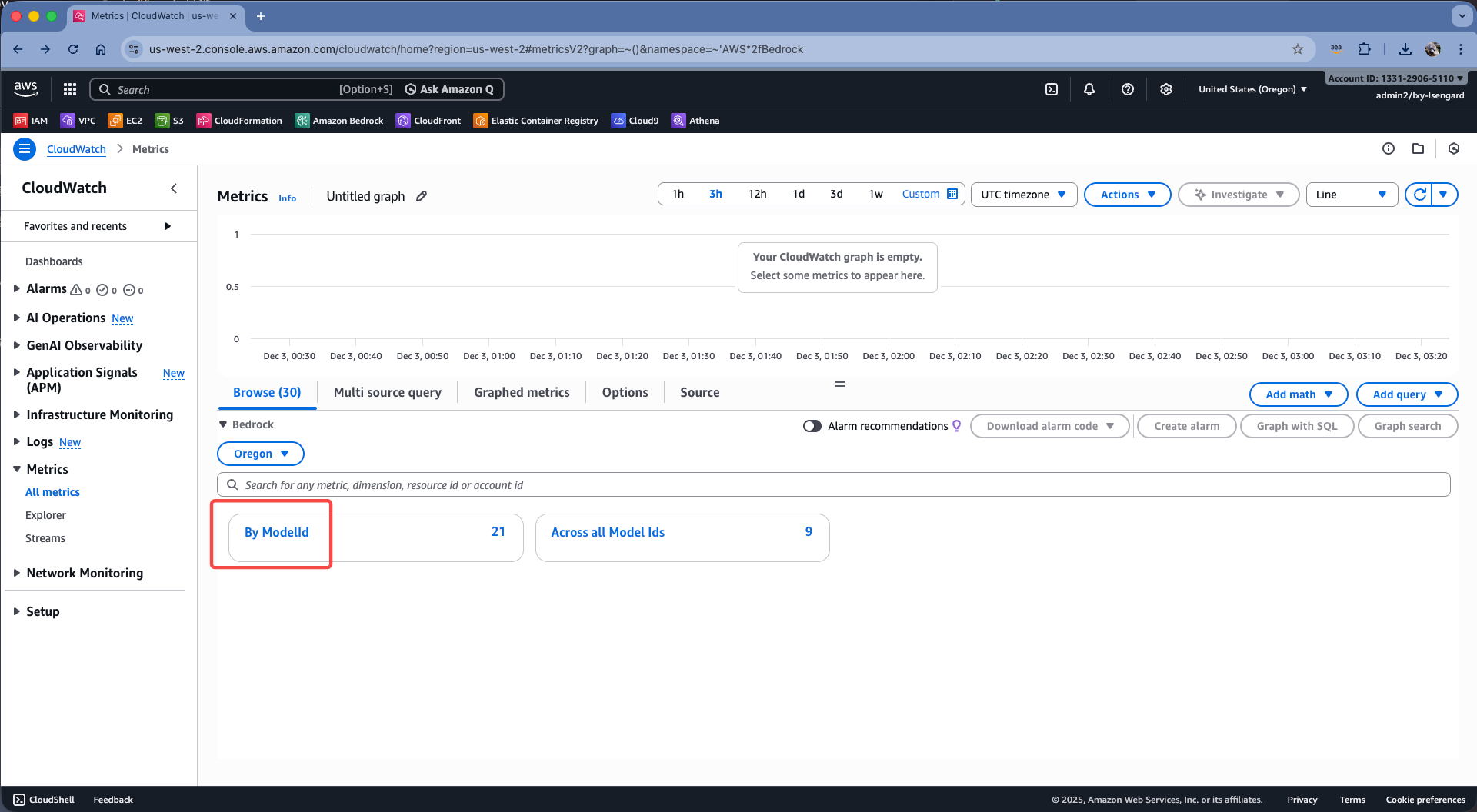
在模型清单中,选择导入的模型ID,在Metric name位置找到ModelCopy参数,这个是在GPU集群中运行的模型副本数量。如下截图。
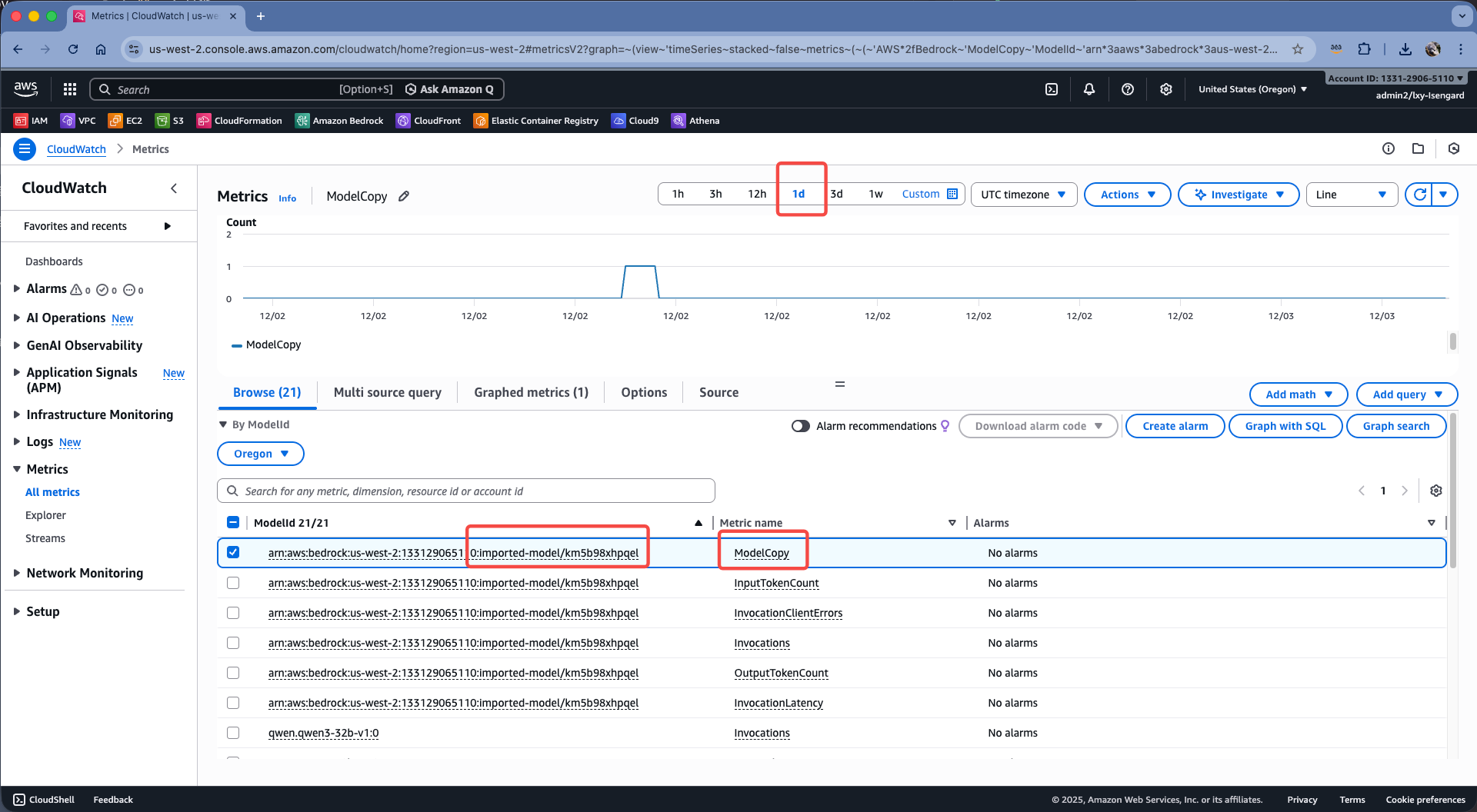
当模型被调用时,ModelCopy的值会增加,当模型不再被调用时,ModelCopy的值会减少。当ModelCopy的值为0时,表示模型被从GPU集群中释放掉。根据导入模型计费的介绍,导入的模型每5分钟一个统计周期,当连续2个5分钟没有访问,模型就会被释放。再次有访问时候,模型需要重新加载。
当模型释放后,新的访问请求打到Bedrock的API端点后,Bedrock会重新拉起模型,此时会触发模型恢复,API将返回429 ModelNotReadyException错误,这个错误信息与限流场景一致,并不是直接返回5xx服务器错误,因此调用API的代码可以过一段时间再去重试访问。重试逻辑需要在客户端自行完成。上一个章节给出的API调用的例子中,就已经包含了冷启动重试逻辑。
例如触发了冷启动时候的API如下。
📝 问题: ...
🔄 检测到模型冷启动... ← 1-2秒内立即显示
模型正在恢复中,这通常需要 1-3 分钟
系统会自动重试,请稍候...
⏳ 等待中... 已等待 25 秒 ← 每25秒更新一次
⏳ 等待中... 已等待 50 秒
✅ 模型已恢复,耗时 67.3 秒 ← 成功后显示总耗时
💬 回答: ...
2、预热机制
导入模型时候,无论是否选择弹性缩放这个选项的开关,模型都会在无人使用的时候释放,从而导致冷启动。为了避免冷启动机制,可以考虑的解决方式定期预热让模型保持最低一份copy(通过CloudWatch可以监控),或者在特定的时间窗口预热(适合非在线业务)。
如果是手工做预热的话,需要每14分钟预热一次。因为导入模型是在一次访问后会保留5分钟,然后再计算连续两个5分钟的空闲周期。因此,每14分钟触发一次访问,即可保持模型的活跃状态。
六、导入自定义模型的计费
1、弹性缩放按需状态
在之前的导入DeepSeek模型的 这篇文章 中,介绍了Bedrock Import Model的计费机制。但不同规格的模型,导入后产生的计费单元的消耗不一样。
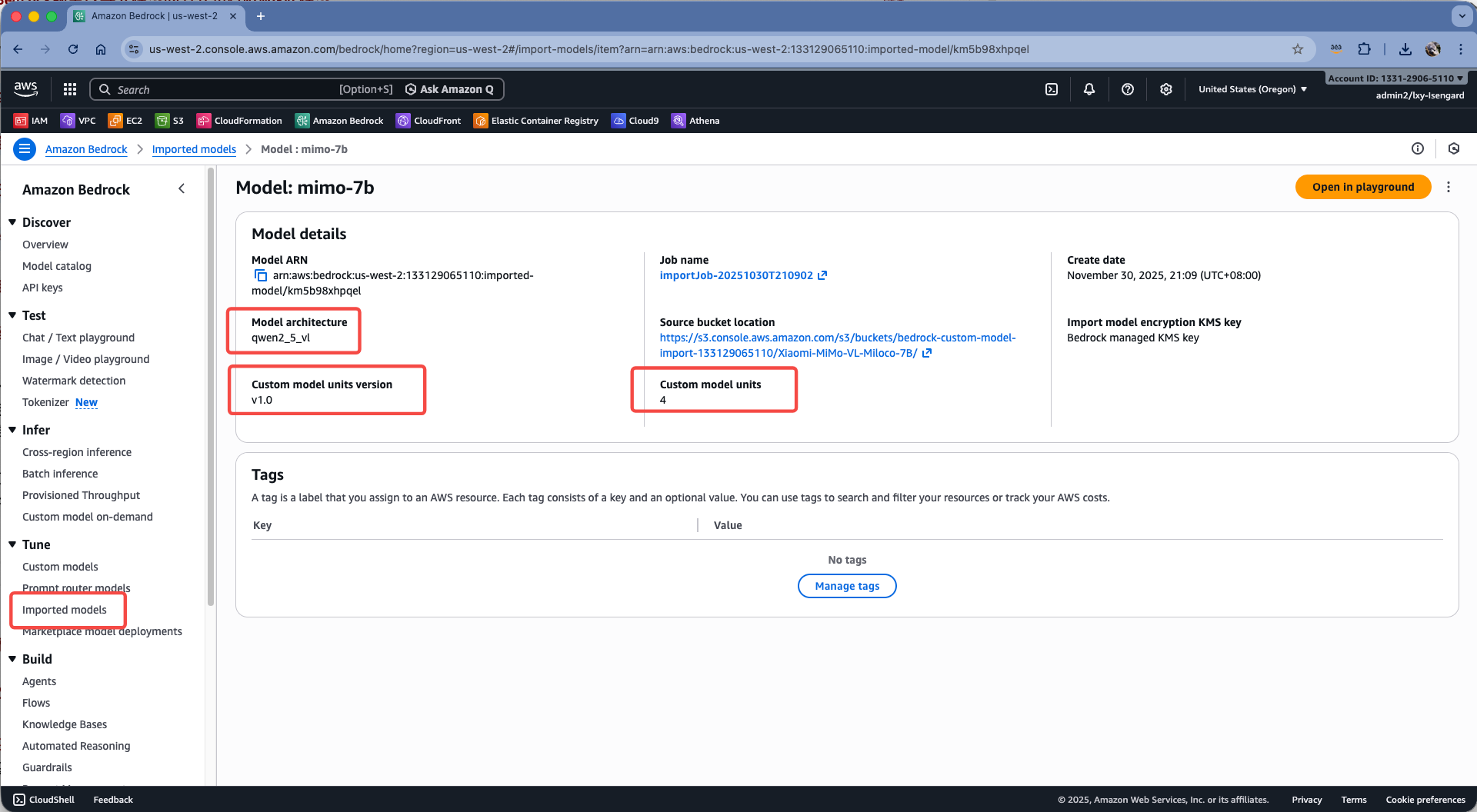
以本文导入的模型是基于Qwen-2.5-VL架构的为例,在查看模型的页面上,可看到模型使用的单元是Custom model units version ,并且占用4个计费单元。这些关键信息将用于核算费用。如下截图。
现在查看官网可以导入自定义模型的对应的分类下看到价格。如下截图。
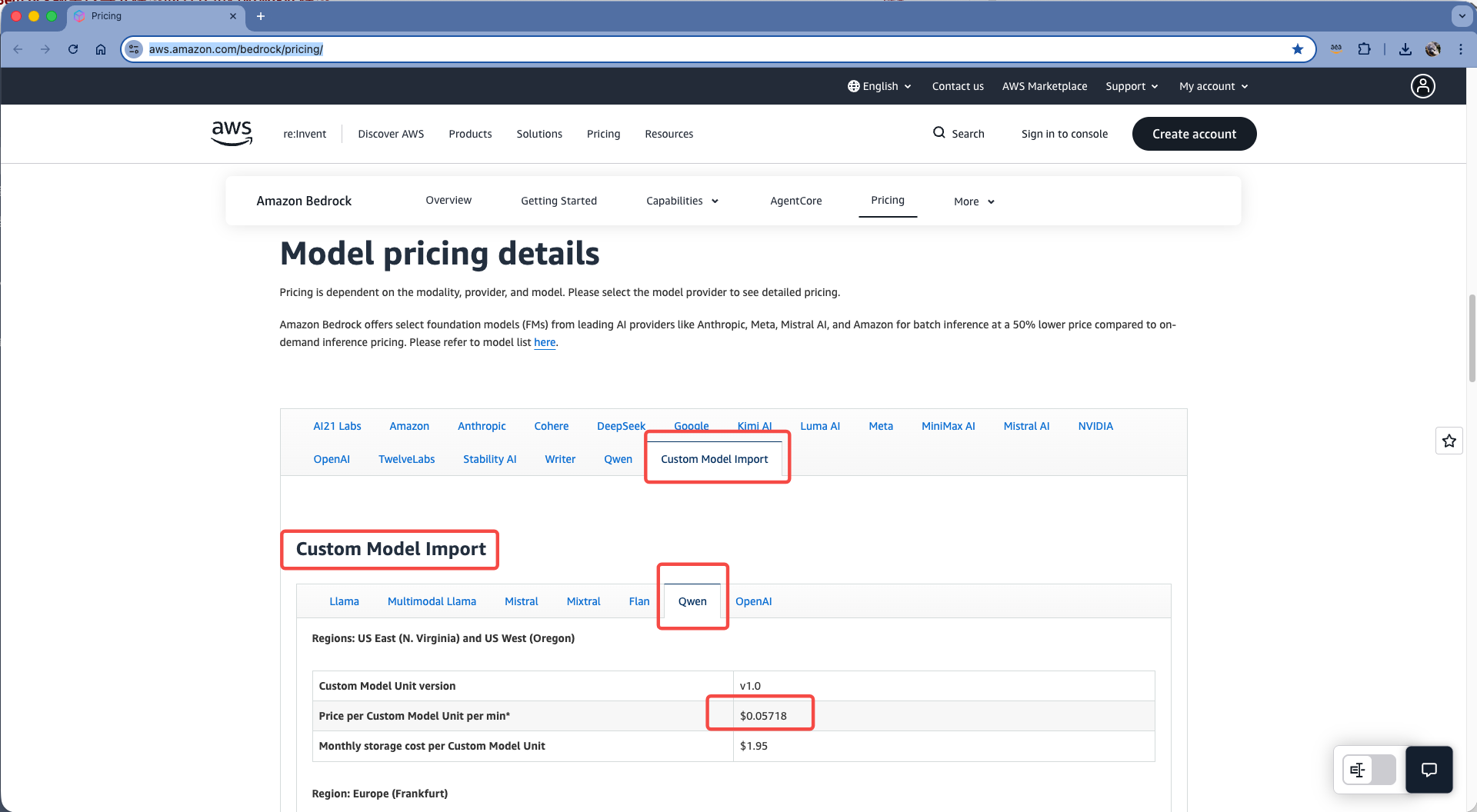
由此可推算出价格:
- 模型计算资源费用:4 Units × $0.05718/Unit/min x 60分钟 x 24小时 x 30天 = $9,880.80
- 模型存储费用:4 Units × $1.95/Unit = $7.80 per month
- 合计 $9,888.60 per month
由此通过预热保持模型在GPU集群中一直被加载的活跃状态,费用是较高的。因此这种弹性缩放状态比较适合开发、测试,以及对实效性没有要求的生产环境,如批量数据处理等定期任务,或者可接受前置-预热拉起方式访问行为(例如企业内部应用9:00预热拉起,保持到18:00下线)。如果是全天在线业务,这种方式成本不划算。
2、与EC2 GPU自行部署模型对比
在之前的文章中,介绍过使用EC2 GPU实例,通过vLLM推理框架部署模型。本文导入到Bedrock的模型是8B规模,使用FP8量化运行在G6e的L40s GPU上有着很好的承载能力。
这里以G6e.2xlarge(8vCPU/64GB,Nvidia L40s GPU*1 48GB显存)机型为例,在美西2俄勒冈区域的1年起无预付RI价格是$1,031.13。考虑到高可用、弹性缩放,如果是在线业务,一次要购买两台。由此成本会是$2000 per month,比用导入模型自带的弹性缩放模式还是具有很大优势的。
3、小结
由此可获得结论,针对低频访问、开发测试、非在线业务,Bedrock导入模型的方式具有很高灵活性,无须学习模型部署和运维相关技术。针对在线业务、全天有访问、高流量的场景下,可尝试EC2 GPU上用vLLM部署模型做推理。
七、参考文档
Invoke your imported model
https://docs.aws.amazon.com/bedrock/latest/userguide/invoke-imported-model.html
Bedrock Pricing
https://aws.amazon.com/bedrock/pricing/
EC2 GPU RI费用
https://aws.amazon.com/ec2/pricing/reserved-instances/pricing/
最后修改于 2025-12-03