使用Nova MME多模态Embedding模型+S3 Vector Bucket向量存储桶进行图片搜索
详解Nova MME多模态Embedding模型与S3 Vector Bucket的集成方案,涵盖CLI快速验证、SDK编程调用、Lambda批量处理等完整实现路径,解决大规模图片向量化和语义搜索问题
一、背景
Amazon Nova Multimodal Embeddings模型(以下简称Nova MME)是亚马逊最新发布的新一代Embedding模型,支持输入高达8192 Tokens。核心能力包括支持多模态输入(视频、图片、文本),可实现以文搜图、以图搜图,支持最高3072维度的向量,也支持1024等较低维度以降低成本。
Nova MME支持的图片格式有JPEG, PNG, GIF, WebP,可通过Bedrock服务的API发起调用,并可根据文件尺寸选择同步调用或者异步调用。针对生成的向量,可使用多种向量数据库存储,包括Amazon OpenSearch Service(普通集群或Serverless集群)、PostgreSQL通过pgvector扩展支持向量存储和检索,此外还可以使用S3 Vector Bucket实现低成本的存储和检索。
Nova MME的典型应用场景包括电商图片搜索、内容生成、视频创作、IoT场景理解、语义搜索等。其基于多模态RAG(检索增强生成)机制,快速检索相似的内容。图片相似度匹配。
在使用方式上,可通过如下路径逐步了解Nova MME模型并开始使用:
- 1、快速验证:使用 s3vectors-embed-cli 命令行工具
- 2、生产环境:通过AWS SDK (如Boto3) 编程调用
- 3、批量处理:结合Lambda + SQS实现并发处理
二、创建S3 Vector Bucket并管理索引
注意:在本文编写的2025年11月,S3 Vector Bucket处于Preview状态,因此部分功能需要通过AWSCLI配合操作。另外,需要AWSCLI的版本是aws-cli/2.31.8,过低的版本是不支持最新的S3 Vector的API调用的。
1、查看现有S3 Vector Bucket
进入S3控制台,可在左侧菜单中点击类型四Vector Bucket,即可看到现有存储桶。如下截图。
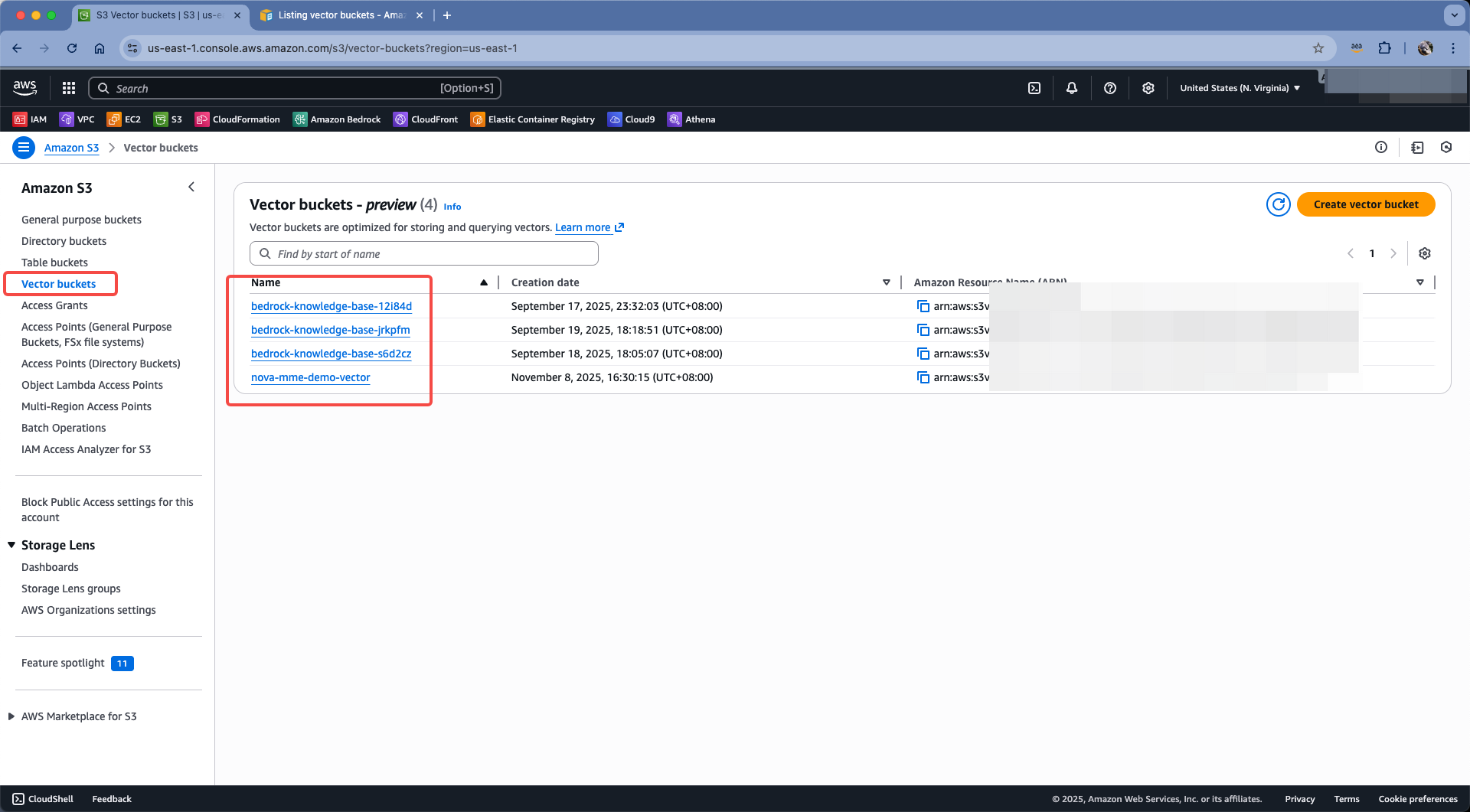
点击这个存储桶的名字后,还可以查看存储桶内的索引(一个桶可以有多个索引)。
2、创建新的向量存储桶及索引
执行如下命令创建向量存储桶。
aws s3vectors create-vector-bucket \
--vector-bucket-name "my-nova-mme-demo-01" \
--region us-east-1
执行如下命令创建索引。注意这里选择的维度是1024,当前Nova MME支持的最高的维度3072。从成本折中角度考虑,选择1024成本较低。后续模型调用要保持一致。
aws s3vectors create-index \
--vector-bucket-name "my-nova-mme-demo-01" \
--index-name my-image-index-01 \
--data-type "float32" \
--dimension 3072 \
--distance-metric "cosine" \
--region us-east-1
创建完毕。此时在AWS S3控制台上也可以看到这个向量存储桶和索引。
3、删除不用的索引和向量存储桶(可选)
首先代入现有向量存储桶的名称,查询其中的索引。
aws s3vectors list-indexes \
--vector-bucket-name "my-nova-mme-demo-01" \
--region us-east-1
返回结果中包含indexName字段,就是索引名称。接下来构建命令,同时代入存储桶名称和索引名称删除索引。
aws s3vectors delete-index \
--vector-bucket-name "my-nova-mme-demo-01" \
--index-name "my-image-index-01" \
--region us-east-1
删除索引成功后,可删除存储桶。
aws s3vectors delete-vector-bucket \
--vector-bucket-name "my-nova-mme-demo-01" \
--region us-east-1
三、使用s3vectors-embed-cli快速入手
Amazon S3 Vectors Embed CLI是一个独立的命令行工具,它是一个开源项目,可在Github上获得源代码。就像日常工作中使用AWSCLI向S3存储桶复制文件的方式类似,Amazon S3 Vectors Embed CLI是一个预先封装好的shell下的二进制程序,其中集成了S3文件客户端、Bedrock API调用Embedding模型操作,并具向S3 Vector Bucket向量存储桶写入向量、检索向量的能力。使用Amazon S3 Vectors Embed CLI可快速进行原型验证、效果展示、场景测试,而无需编写代码。本文先展示使用Amazon S3 Vectors Embed CLI工具,而后再介绍使用AWS SDK的方式操作API。
1、安装s3vectors-embed-cli
执行如下命令安装:
pip install s3vectors-embed-cli
安装完毕。
使用如下命令pip show s3vectors-embed-cli | less可查看安装好的版本。在返回信息的头部,可看到Version: 0.2.1。这个版本是仅支持Nova Embedding的第一代模型,在2025年11月本文编写时候,还不支持Nova MME模型(也就是V2)。因此在这个包安装后,还需要改动下使其支持Nova MME。改动方法是用修改过增加了Nova MME模型的配置文件替换当前软件包中的模型定义文件。由于代码长度比较长,这里不再粘贴代码,原始文件参考本文对应Github中的s3vectors-embed-cli/models.py这个文件。
在本文的例子中,pip包的安装路径中的访问模型的文件是:/opt/homebrew/lib/python3.13/site-packages/s3vectors/utils/models.py。从本文的Github上s3vectors-embed-cli/models.py下载修改后的文件,替换pip安装的默认文件。由此s3vectors-embed-cli工具将支持调用最新的Nova MME。
2、对本地单个文件做Embedding
将本地的单个图片文件进行Embedding,执行如下命令:
s3vectors-embed put \
--vector-bucket-name my-nova-mme-demo-01 \
--index-name my-image-index-01 \
--model-id amazon.nova-2-multimodal-embeddings-v1:0 \
--image "./test-image/image-01.jpg" \
--region us-east-1
由此将本地的文件进行Embedding,然后将Embedding结果写入S3存储桶中。在Embedding时候,每个文件将自动生成唯一的uuid作为在向量数据库中存储key的名称,这样即便遇到文件名相同的场景,他们的uuid也不相同。如果您希望查询原始文件名,可通过查看metadata中的S3VECTORS-EMBED-SRC-LOCATION看到原始文件名。在执行完毕后,控制台上会返回key的名称。
完成后返回如下:
{
"key": "00a00061-79dc-4e5d-a404-b5f7166718c7",
"bucket": "my-nova-mme-demo-01",
"index": "my-image-index-01",
"model": "amazon.nova-2-multimodal-embeddings-v1:0",
"contentType": "image",
"embeddingDimensions": 3072,
"metadata": {
"S3VECTORS-EMBED-SRC-LOCATION": "./test-image/image-01.jpg"
}
}
由此看到单个文件处理完毕。
3、对本地目录内多个文件做Embedding
执行如下命令:
s3vectors-embed put \
--vector-bucket-name my-nova-mme-demo-01 \
--index-name my-image-index-01 \
--model-id amazon.nova-2-multimodal-embeddings-v1:0 \
--image "./test-image/*.jpg" \
--region us-east-1
此时的s3vectors-embed-cli会自动进行分片,分批完成。同时会在控制台下打印出最开始的10个key。
4、对S3存储桶的整个目录做Embedding
将S3存储桶中的文件不下载到本机而是直接Embedding,执行如下命令:
s3vectors-embed put \
--vector-bucket-name my-nova-mme-demo-01 \
--index-name my-image-index-01 \
--model-id amazon.nova-2-multimodal-embeddings-v1:0 \
--image "s3://nova-mme-demo-source-image/*" \
--batch-size 100 \
--region us-east-1
注意如果文件很多,那么这一步会很消耗时间,虽然s3vectors-embed-cli会自动进行分片,但如果断线的话,还没有embedding的文件需要手工再执行embedding。所以如果Source存储桶内的图片文件多,建议把这个步骤放在云端的EC2上执行,并使用tmux/screen等虚拟终端,确保不会发生网络抖动导致的中断。另外这里增加了--batch-size 100参数,这需要根据当前使用的维度来调整,默认的limit是500不能满足吞吐量要求因此设置为100,如果不设置限制,会导致每一批的写入超过上限遇到报错。如果设置为100还报错的话需要限制到50。
返回如下:
Starting streaming batch processing: s3://nova-mme-demo-source-image/*
Processing chunk 1...
Progress: 100/100 files processed (100 successful, 0 failed)
STORED BATCH: 100 vectors
Completed chunk 1: 100 processed, 0 failed
Processing chunk 2...
Progress: 100/100 files processed (100 successful, 0 failed)
STORED BATCH: 100 vectors
Completed chunk 2: 100 processed, 0 failed
Processing chunk 3...
Progress: 100/100 files processed (100 successful, 0 failed)
STORED BATCH: 100 vectors
Completed chunk 3: 100 processed, 0 failed
Processing chunk 4...
Progress: 100/100 files processed (100 successful, 0 failed)
STORED BATCH: 100 vectors
Completed chunk 4: 100 processed, 0 failed
Processing chunk 5...
Progress: 100/100 files processed (100 successful, 0 failed)
STORED BATCH: 100 vectors
Completed chunk 5: 100 processed, 0 failed
Processing chunk 6...
Progress: 100/100 files processed (100 successful, 0 failed)
STORED BATCH: 100 vectors
Completed chunk 6: 100 processed, 0 failed
Processing chunk 7...
STORED BATCH: 68 vectors
Completed chunk 7: 68 processed, 0 failed
{
"type": "streaming_batch",
"bucket": "my-nova-mme-demo-01",
"index": "my-image-index-01",
"model": "amazon.nova-2-multimodal-embeddings-v1:0",
"contentType": "image",
"totalFiles": 668,
"processedFiles": 668,
"failedFiles": 0,
"totalVectors": 668,
"vectorKeys": [
"30f81eeb-be5d-44bc-bbc3-17b3285629fd",
"0d6b1bb5-3edc-4932-acb1-eac623fb1eb8",
"08fd20da-fa9b-4ad5-9623-71facdb92a19",
"523abaa0-21e9-4668-9c3c-ae035c0c2e61",
"36619416-a821-476c-82c5-6be218f23747",
"e5203d22-2a46-4016-bc51-85fc0f08d77b",
"beeb4719-deab-401e-a4d0-49cc4bf4ebc8",
"89baf7bb-f1ee-419f-b559-45e3ea04b52c",
"155bd035-f4ab-40af-a94f-106135bd3156",
"1d341526-0758-463b-8758-b99319813dda"
]
}
Note: Showing first 10 of 668 vector keys
以上生成embedding完成。
5、以文搜图检索例子
Nova MME模型对英文查询的结果理解更到位,因此尽量使用英文作为检索条件。
以文搜图例子:
s3vectors-embed query \
--vector-bucket-name my-nova-mme-demo-01 \
--index-name my-image-index-01 \
--model-id amazon.nova-2-multimodal-embeddings-v1:0 \
--text-value "Wind turbine" \
--return-distance \
--return-metadata \
--k 10 \
--region us-east-1
s3vectors-embed query \
--vector-bucket-name my-nova-mme-demo-01 \
--index-name my-image-index-01 \
--model-id amazon.nova-2-multimodal-embeddings-v1:0 \
--text-value "aircraft engine" \
--return-distance \
--return-metadata \
--region us-east-1 \
--k 5
s3vectors-embed query \
--vector-bucket-name my-nova-mme-demo-01 \
--index-name my-image-index-01 \
--model-id amazon.nova-2-multimodal-embeddings-v1:0 \
--text-value "lovely cat" \
--return-distance \
--return-metadata \
--region us-east-1 \
--k 5
检索结果将包含Key名字、distance距离(相似度)、metadata(原始路径)等信息。参数--k指定了返回数量,如果不传入入k参数默认返回5个结果。
{
"results": [
{
"Key": "06edc227-a2eb-487e-8860-2c2cd5ece2c4",
"distance": 0.7204378247261047,
"metadata": {
"S3VECTORS-EMBED-SRC-LOCATION": "s3://nova-mme-demo-source-image/05/h-33.jpg"
}
},
{
"Key": "a65d1e7f-07f4-4445-aa49-e3bcf1a06349",
"distance": 0.7339481115341187,
"metadata": {
"S3VECTORS-EMBED-SRC-LOCATION": "s3://nova-mme-demo-source-image/05/h-34.jpg"
}
},
{
"Key": "893ba936-0bd1-4f75-8b65-ef1b11ef3580",
"distance": 0.7673828601837158,
"metadata": {
"S3VECTORS-EMBED-SRC-LOCATION": "s3://nova-mme-demo-source-image/05/h-25.jpg"
}
},
{
"Key": "258eda93-9855-4280-aeab-8843e34b200d",
"distance": 0.7673828601837158,
"metadata": {
"S3VECTORS-EMBED-SRC-LOCATION": "s3://nova-mme-demo-source-image/05/h-25.jpg"
}
},
{
"Key": "47c0449a-de74-4d4b-aea7-7ebae18ca5be",
"distance": 0.8898362517356873,
"metadata": {
"S3VECTORS-EMBED-SRC-LOCATION": "s3://nova-mme-demo-source-image/10/p-25.jpg"
}
}
],
"summary": {
"queryType": "text",
"model": "amazon.nova-2-multimodal-embeddings-v1:0",
"index": "my-image-index-01",
"resultsFound": 5,
"queryDimensions": 3072
}
}
这里解释下检索效果:
- Distance越小表示相似度越高
- 以图搜图的distance通常在0.2-0.3之间,代表效果很好
- 以文搜图的distance在0.6-0.8左右可接受
- 通常0.8以内的距离表示有一定相关,0.8~1.0表示相关性不大
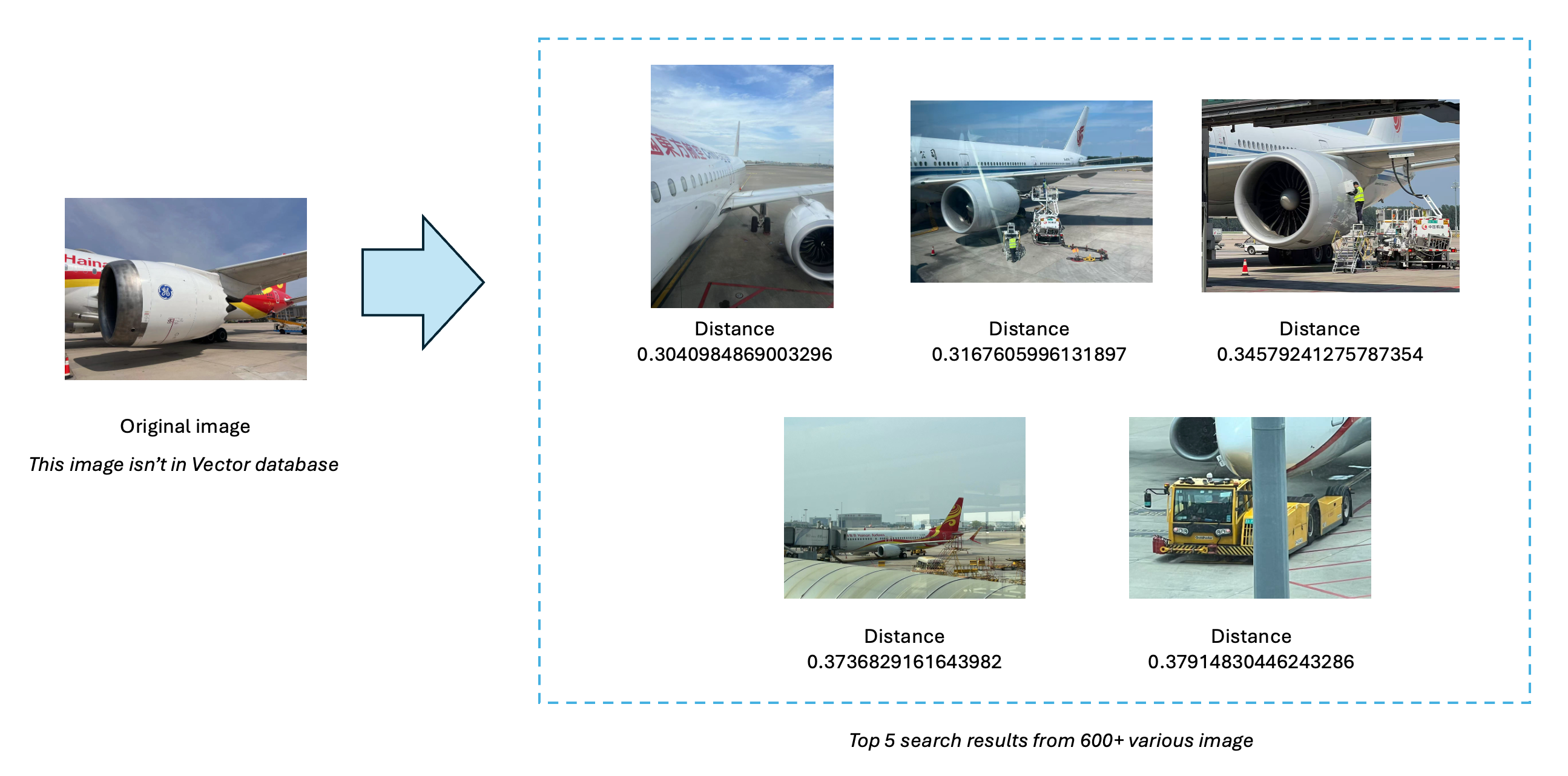
6、以图搜图的例子
假设用于搜索的图片在本地保存,使用相对路径,构建如下命令:
s3vectors-embed query \
--vector-bucket-name my-nova-mme-demo-01 \
--index-name my-image-index-01 \
--model-id amazon.nova-2-multimodal-embeddings-v1:0 \
--image "./search-01.jpg" \
--return-distance \
--return-metadata \
--region us-east-1 \
--k 5
以图搜图的结果如下:
{
"results": [
{
"Key": "df0bb96f-bcc8-4fcc-a5a8-4ea69a73fc01",
"distance": 0.17329424619674683,
"metadata": {
"S3VECTORS-EMBED-SRC-LOCATION": "s3://nova-mme-demo-source-image/10/m-17.jpg"
}
},
{
"Key": "3b3c0e09-076c-4ca4-a97c-a9579618b6a0",
"distance": 0.2002631425857544,
"metadata": {
"S3VECTORS-EMBED-SRC-LOCATION": "s3://nova-mme-demo-source-image/10/m-18.jpg"
}
},
{
"Key": "2ecb2f9b-4611-4a9c-8947-c9f5d5115feb",
"distance": 0.2287510633468628,
"metadata": {
"S3VECTORS-EMBED-SRC-LOCATION": "s3://nova-mme-demo-source-image/10/m-20.jpg"
}
},
{
"Key": "7c94ba0f-4411-49b9-b459-68699db8317a",
"distance": 0.24049735069274902,
"metadata": {
"S3VECTORS-EMBED-SRC-LOCATION": "s3://nova-mme-demo-source-image/10/m-21.jpg"
}
},
{
"Key": "2b29cbf7-30d4-4b6c-bedd-8f29a301fd79",
"distance": 0.27245086431503296,
"metadata": {
"S3VECTORS-EMBED-SRC-LOCATION": "s3://nova-mme-demo-source-image/10/m-19.jpg"
}
}
],
"summary": {
"queryType": "image",
"model": "amazon.nova-2-multimodal-embeddings-v1:0",
"index": "my-image-index-01",
"resultsFound": 5,
"queryDimensions": 3072
}
}
可看到以图搜图的命中率很好,其distance距离比文本搜索更近。
第一个搜索效果如下图所示。

第二个例子如下。
7、删除过期/无效的向量
如果要删除不需要文件在S3向量存储桶中保存的向量,那么需要知道这个文件对应的key值。根据前文执行embedding时候可知,key是随机生成的uuid。但是,在metadata中保存有原始文件名。因此可以先通过metadata来查询原始文件名,然后获取到对应的key名称,再调用key名称删除。
s3vectors-embed query \
--vector-bucket-name my-nova-mme-demo-01 \
--index-name my-image-index-01 \
--model-id amazon.nova-2-multimodal-embeddings-v1:0 \
--text-value "搜索查询文本" \
--filter '{"S3VECTORS-EMBED-SRC-LOCATION": {"$eq": "./test-image/image-01.jpg"}}' \
--return-metadata \
--region us-east-1
返回结果如下:
{
"results": [
{
"Key": "00a00061-79dc-4e5d-a404-b5f7166718c7",
"metadata": {
"S3VECTORS-EMBED-SRC-LOCATION": "./test-image/image-01.jpg"
}
}
],
"summary": {
"queryType": "text",
"model": "amazon.nova-2-multimodal-embeddings-v1:0",
"index": "my-image-index-01",
"resultsFound": 1,
"queryDimensions": 3072
}
}
这里可以看到uuid格式的key了。接下来构建删除命令。由于s3vectors-embed-cli在当前(2025年11月)版本只提供put/query两个方法,暂时没有删除命令的,因此需要调用s3api来完成删除。构建如下命令:
aws s3vectors delete-vectors \
--vector-bucket-name "my-nova-mme-demo-01" \
--index-name "my-image-index-01" \
--keys '["00a00061-79dc-4e5d-a404-b5f7166718c7"]' \
--region us-east-1
执行完毕后,向量已经删除。
四、通过SDK调用Nova MME进行Embedding
上文的例子是通过s3vectors-embed-cli来进行操作的,适合在MacOS和Linux上进行体验和快速验证。接下来介绍使用AWS SDK进行开发,保存向量还继续使用S3 Vector Bucket。本文以Python语言Boto3 SDK为例。
1、对单一文件生成向量并写入S3存储桶
在上文的例子中,S3 Vector Bucket向量存储桶和Index索引已经创建好了,接下来使用SDK方式的调用Nova MME并生成向量,然后继续写入到这个索引中。原始文件参考本文对应Github中的01_embedding_single_file.py这个文件。
#!/usr/bin/env python3
"""Embed a single local image file using Nova MME"""
import boto3
import json
import base64
import uuid
from pathlib import Path
from typing import Dict, Any
# AWS clients
bedrock_client = boto3.client('bedrock-runtime', region_name='us-east-1')
s3vectors_client = boto3.client('s3vectors', region_name='us-east-1')
# Configuration
MODEL_ID = 'amazon.nova-2-multimodal-embeddings-v1:0'
EMBEDDING_DIMENSION = 3072
IMAGE_PATH = 'test-image/01/b-00.jpg'
VECTOR_BUCKET = 'my-nova-mme-demo-01'
INDEX_NAME = 'my-image-index-01'
def get_image_format(file_path: str) -> str:
"""Determine image format from file extension"""
if file_path.lower().endswith('.png'):
return 'png'
return 'jpeg'
def generate_embedding(image_path: str) -> Dict[str, Any]:
"""Generate embedding for a single local image file"""
print(f"\nProcessing: {image_path}")
# Read local image file
path = Path(image_path)
if not path.exists():
raise FileNotFoundError(f"Image file not found: {image_path}")
with open(path, 'rb') as f:
image_bytes = f.read()
image_base64 = base64.b64encode(image_bytes).decode('utf-8')
# Prepare model input
model_input = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"image": {
"format": get_image_format(image_path),
"source": {
"bytes": image_base64
}
}
}
}
# Invoke Bedrock model synchronously
response = bedrock_client.invoke_model(
modelId=MODEL_ID,
body=json.dumps(model_input)
)
# Parse response
result = json.loads(response['body'].read())
embedding = result.get('embeddings', [{}])[0].get('embedding', [])
return {
'image_path': image_path,
'embedding': embedding,
'dimension': len(embedding)
}
def store_embedding_to_s3_vectors(
embedding: list,
image_path: str,
vector_bucket: str,
index_name: str
) -> Dict[str, Any]:
"""Store embedding vector to S3 Vectors with metadata"""
# Generate unique ID using UUID directly (no prefix to avoid hotspot)
vector_key = uuid.uuid4().hex
# Prepare metadata
path_obj = Path(image_path)
metadata = {
'file_path': str(path_obj.parent),
'file_name': path_obj.name,
'full_path': image_path
}
print(f"\nStoring to S3 Vectors...")
print(f" Vector Bucket: {vector_bucket}")
print(f" Index Name: {index_name}")
print(f" Vector Key: {vector_key}")
# Write embedding to S3 Vectors using put_vectors API
response = s3vectors_client.put_vectors(
vectorBucketName=vector_bucket,
indexName=index_name,
vectors=[
{
'key': vector_key,
'data': {'float32': embedding},
'metadata': metadata
}
]
)
print(f"✓ Stored to S3 Vectors!")
print(f"\n Vector Information:")
print(f" Vector Key: {vector_key}")
print(f" Embedding Dimension: {len(embedding)}")
print(f" Vector Bucket: {vector_bucket}")
print(f" Index Name: {index_name}")
print(f"\n Metadata:")
for key, value in metadata.items():
print(f" {key}: {value}")
print(f"\n API Response:")
print(f" {json.dumps(response, indent=2, default=str)}")
return {
'vector_key': vector_key,
'vector_bucket': vector_bucket,
'index_name': index_name,
'metadata': metadata,
'response': response
}
def main():
"""Main function to generate embedding for single image"""
print("=" * 60)
print("Nova MME Single Image Embedding")
print("=" * 60)
try:
# Generate embedding
result = generate_embedding(IMAGE_PATH)
print(f"✓ Embedding generated!")
print(f" Image: {result['image_path']}")
print(f" Dimension: {result['dimension']}")
print(f" First 5 values: {result['embedding'][:5]}")
print(f" Last 5 values: {result['embedding'][-5:]}")
# Store to S3 Vectors
store_result = store_embedding_to_s3_vectors(
embedding=result['embedding'],
image_path=result['image_path'],
vector_bucket=VECTOR_BUCKET,
index_name=INDEX_NAME
)
print("\n" + "=" * 60)
print("✓ Embedding Process Completed Successfully!")
print("=" * 60)
except Exception as e:
print(f"✗ Error: {e}")
if __name__ == '__main__':
main()
将以上文件保存到embedding_single_file.py中,执行这个文件。返回结果如下:
============================================================
Nova MME Single Image Embedding
============================================================
Processing: test-image/01/b-00.jpg
✓ Embedding generated!
Image: test-image/01/b-00.jpg
Dimension: 3072
First 5 values: [0.022440236, 0.0052655814, -0.0038876724, 0.03149507, -0.016928598]
Last 5 values: [0.013975936, 0.01653491, 0.02972347, -0.0019069279, -0.0067419126]
Storing to S3 Vectors...
Vector Bucket: my-nova-mme-demo-01
Index Name: my-image-index-01
Vector Key: b3014d28baba40bfb4651c123f43f0c7
✓ Stored to S3 Vectors!
Vector Information:
Vector Key: b3014d28baba40bfb4651c123f43f0c7
Embedding Dimension: 3072
Vector Bucket: my-nova-mme-demo-01
Index Name: my-image-index-01
Metadata:
file_path: test-image/01
file_name: b-00.jpg
full_path: test-image/01/b-00.jpg
API Response:
{
"ResponseMetadata": {
"RequestId": "2726c011-78f1-4aee-9fd9-76e3bac529f3",
"HostId": "",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"date": "Thu, 13 Nov 2025 06:45:34 GMT",
"content-type": "application/json",
"content-length": "2",
"connection": "keep-alive",
"x-amz-request-id": "2726c011-78f1-4aee-9fd9-76e3bac529f3",
"access-control-allow-origin": "*",
"vary": "origin, access-control-request-method, access-control-request-headers",
"access-control-expose-headers": "*"
},
"RetryAttempts": 0
}
}
============================================================
✓ Embedding Process Completed Successfully!
============================================================
由此看到新的图片被索引成功,同时打印出来了Vector Key的ID。同时,原始文件路径也作为metadata被一并存储到了索引中。
2、使用文本检索图片
将如下代码保存为query_text.py,输入文本进行查询。原始文件参考本文对应Github中的02_query_text.py这个文件。
#!/usr/bin/env python3
"""Query S3 Vector Bucket using text with Nova MME"""
import boto3
import json
from typing import Dict, Any, List
# AWS clients
bedrock_client = boto3.client('bedrock-runtime', region_name='us-east-1')
s3vectors_client = boto3.client('s3vectors', region_name='us-east-1')
# Configuration
MODEL_ID = 'amazon.nova-2-multimodal-embeddings-v1:0'
EMBEDDING_DIMENSION = 3072
VECTOR_BUCKET = 'my-nova-mme-demo-01'
INDEX_NAME = 'my-image-index-01'
QUERY_TEXT = 'Wind turbine'
TOP_K = 5 # Number of results to return
def generate_text_embedding(text: str) -> List[float]:
"""Generate embedding for text using Nova MME"""
print(f"\nGenerating embedding for text: '{text}'")
# Prepare model input for text embedding
# Use GENERIC_RETRIEVAL to match GENERIC_INDEX used during indexing
model_input = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {
"truncationMode": "END",
"value": text
}
}
}
# Invoke Bedrock model
response = bedrock_client.invoke_model(
modelId=MODEL_ID,
body=json.dumps(model_input)
)
# Parse response
result = json.loads(response['body'].read())
embedding = result.get('embeddings', [{}])[0].get('embedding', [])
print(f"✓ Embedding generated (dimension: {len(embedding)})")
return embedding
def query_vectors(
query_embedding: List[float],
vector_bucket: str,
index_name: str,
top_k: int = 3
) -> List[Dict[str, Any]]:
"""Query S3 Vectors for similar vectors"""
print(f"\nQuerying S3 Vectors...")
print(f" Vector Bucket: {vector_bucket}")
print(f" Index Name: {index_name}")
print(f" Top K: {top_k}")
# Query vectors using query_vectors API
response = s3vectors_client.query_vectors(
vectorBucketName=vector_bucket,
indexName=index_name,
queryVector={'float32': query_embedding},
topK=top_k,
returnDistance=True,
returnMetadata=True
)
# Extract results from response (field name is 'vectors', not 'results')
results = response.get('vectors', [])
print(f"✓ Found {len(results)} results")
return results
def display_results(results: List[Dict[str, Any]]):
"""Display query results in a formatted way"""
print("\n" + "=" * 60)
print("Query Results")
print("=" * 60)
if not results:
print("\nNo results found.")
return
for idx, result in enumerate(results, 1):
print(f"\n--- Result {idx} ---")
# Extract key
key = result.get('key', 'N/A')
print(f" Key: {key}")
# Extract distance/score
distance = result.get('distance')
if distance is not None:
print(f" Distance: {distance}")
score = result.get('score')
if score is not None:
print(f" Score: {score}")
# Extract metadata
metadata = result.get('metadata', {})
if metadata:
print(f" Metadata:")
# Display full path
full_path = metadata.get('full_path')
if full_path:
print(f" Full Path: {full_path}")
# Display file name
file_name = metadata.get('file_name')
if file_name:
print(f" File Name: {file_name}")
# Display file path
file_path = metadata.get('file_path')
if file_path:
print(f" File Path: {file_path}")
# Display any other metadata
for key, value in metadata.items():
if key not in ['full_path', 'file_name', 'file_path']:
print(f" {key}: {value}")
def main():
"""Main function to query vectors using text"""
print("=" * 60)
print("Nova MME Text-to-Image Query")
print("=" * 60)
try:
# Generate embedding for query text
query_embedding = generate_text_embedding(QUERY_TEXT)
# Query S3 Vectors
results = query_vectors(
query_embedding=query_embedding,
vector_bucket=VECTOR_BUCKET,
index_name=INDEX_NAME,
top_k=TOP_K
)
# Display results
display_results(results)
print("\n" + "=" * 60)
print("✓ Query Completed Successfully!")
print("=" * 60)
except Exception as e:
print(f"\n✗ Error: {e}")
import traceback
traceback.print_exc()
if __name__ == '__main__':
main()
查询结果如下:
============================================================
Nova MME Text-to-Image Query
============================================================
Generating embedding for text: 'Wind turbine'
✓ Embedding generated (dimension: 3072)
Querying S3 Vectors...
Vector Bucket: my-nova-mme-demo-01
Index Name: my-image-index-01
Top K: 5
✓ Found 5 results
============================================================
Query Results
============================================================
--- Result 1 ---
Key: 1fc27f6c-7cc9-4f7c-804b-5ba788e4a165
Distance: 0.6080319881439209
Metadata:
S3VECTORS-EMBED-SRC-LOCATION: s3://nova-mme-demo-source-image/10/h-02.jpg
--- Result 2 ---
Key: a89ba4b1-332e-42f9-9a53-03f96aed1069
Distance: 0.614193320274353
Metadata:
S3VECTORS-EMBED-SRC-LOCATION: s3://nova-mme-demo-source-image/04/w-13.jpg
--- Result 3 ---
Key: 59e3ed9d-0858-4cc7-9906-334680b3cdc9
Distance: 0.6258848309516907
Metadata:
S3VECTORS-EMBED-SRC-LOCATION: s3://nova-mme-demo-source-image/10/h-36.jpg
--- Result 4 ---
Key: c3f83d5d-9a7d-45cf-be43-6edaeb643b2e
Distance: 0.6270856857299805
Metadata:
S3VECTORS-EMBED-SRC-LOCATION: s3://nova-mme-demo-source-image/02/x-35.jpg
--- Result 5 ---
Key: 2f733bcc-e59c-4318-a8fc-0e75a533eba3
Distance: 0.628294825553894
Metadata:
S3VECTORS-EMBED-SRC-LOCATION: s3://nova-mme-demo-source-image/10/h-32.jpg
============================================================
✓ Query Completed Successfully!
============================================================
可看到正常检索到了结果。
3、以图搜图
将如下代码保存为query_image.py,输入本地目录下的一个图片文件,进行图片查询。原始文件参考本文对应Github中的03_query_image.py这个文件。
#!/usr/bin/env python3
"""Query S3 Vector Bucket using image with Nova MME"""
import boto3
import json
import base64
from pathlib import Path
from typing import Dict, Any, List
# AWS clients
bedrock_client = boto3.client('bedrock-runtime', region_name='us-east-1')
s3vectors_client = boto3.client('s3vectors', region_name='us-east-1')
# Configuration
MODEL_ID = 'amazon.nova-2-multimodal-embeddings-v1:0'
EMBEDDING_DIMENSION = 3072
VECTOR_BUCKET = 'my-nova-mme-demo-01'
INDEX_NAME = 'my-image-index-01'
QUERY_IMAGE = 'search-01.jpg' # Local image file
TOP_K = 5 # Number of results to return
def get_image_format(file_path: str) -> str:
"""Determine image format from file extension"""
if file_path.lower().endswith('.png'):
return 'png'
elif file_path.lower().endswith('.gif'):
return 'gif'
elif file_path.lower().endswith('.webp'):
return 'webp'
return 'jpeg'
def generate_image_embedding(image_path: str) -> List[float]:
"""Generate embedding for image using Nova MME"""
print(f"\nGenerating embedding for image: '{image_path}'")
# Read local image file
path = Path(image_path)
if not path.exists():
raise FileNotFoundError(f"Image file not found: {image_path}")
with open(path, 'rb') as f:
image_bytes = f.read()
image_base64 = base64.b64encode(image_bytes).decode('utf-8')
# Prepare model input for image embedding
# Use GENERIC_RETRIEVAL to match GENERIC_INDEX used during indexing
model_input = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL",
"embeddingDimension": EMBEDDING_DIMENSION,
"image": {
"format": get_image_format(image_path),
"source": {
"bytes": image_base64
}
}
}
}
# Invoke Bedrock model
response = bedrock_client.invoke_model(
modelId=MODEL_ID,
body=json.dumps(model_input)
)
# Parse response
result = json.loads(response['body'].read())
embedding = result.get('embeddings', [{}])[0].get('embedding', [])
print(f"✓ Embedding generated (dimension: {len(embedding)})")
return embedding
def query_vectors(
query_embedding: List[float],
vector_bucket: str,
index_name: str,
top_k: int = 3
) -> List[Dict[str, Any]]:
"""Query S3 Vectors for similar vectors"""
print(f"\nQuerying S3 Vectors...")
print(f" Vector Bucket: {vector_bucket}")
print(f" Index Name: {index_name}")
print(f" Top K: {top_k}")
# Query vectors using query_vectors API
response = s3vectors_client.query_vectors(
vectorBucketName=vector_bucket,
indexName=index_name,
queryVector={'float32': query_embedding},
topK=top_k,
returnDistance=True,
returnMetadata=True
)
# Extract results from response (field name is 'vectors', not 'results')
results = response.get('vectors', [])
print(f"✓ Found {len(results)} results")
return results
def display_results(results: List[Dict[str, Any]]):
"""Display query results in a formatted way"""
print("\n" + "=" * 60)
print("Query Results")
print("=" * 60)
if not results:
print("\nNo results found.")
return
for idx, result in enumerate(results, 1):
print(f"\n--- Result {idx} ---")
# Extract key
key = result.get('key', 'N/A')
print(f" Key: {key}")
# Extract distance/score
distance = result.get('distance')
if distance is not None:
print(f" Distance: {distance}")
score = result.get('score')
if score is not None:
print(f" Score: {score}")
# Extract metadata
metadata = result.get('metadata', {})
if metadata:
print(f" Metadata:")
# Display source_key (from Lambda)
source_key = metadata.get('source_key')
if source_key:
print(f" Source Key: {source_key}")
# Display s3_uri (from Lambda)
s3_uri = metadata.get('s3_uri')
if s3_uri:
print(f" S3 URI: {s3_uri}")
# Display full_path (from custom script)
full_path = metadata.get('full_path')
if full_path:
print(f" Full Path: {full_path}")
# Display file name
file_name = metadata.get('file_name')
if file_name:
print(f" File Name: {file_name}")
# Display file path
file_path = metadata.get('file_path')
if file_path:
print(f" File Path: {file_path}")
# Display any other metadata
for key, value in metadata.items():
if key not in ['source_key', 's3_uri', 'full_path', 'file_name', 'file_path']:
print(f" {key}: {value}")
def main():
"""Main function to query vectors using image"""
print("=" * 60)
print("Nova MME Image-to-Image Query")
print("=" * 60)
try:
# Generate embedding for query image
query_embedding = generate_image_embedding(QUERY_IMAGE)
# Query S3 Vectors
results = query_vectors(
query_embedding=query_embedding,
vector_bucket=VECTOR_BUCKET,
index_name=INDEX_NAME,
top_k=TOP_K
)
# Display results
display_results(results)
print("\n" + "=" * 60)
print("✓ Query Completed Successfully!")
print("=" * 60)
except Exception as e:
print(f"\n✗ Error: {e}")
import traceback
traceback.print_exc()
if __name__ == '__main__':
main()
4、查询并删除向量
如果向量数据库中存储的向量对应的图片不再有效,那么可以根据其Key进行删除。如果不知道Key ID而是仅知道S3存储桶的原始图片文件名,那么可先根据metadata中的原始文件名和路径进行检索,检索后获得Key,然后再使用Key删除。这时候注意要使用query_vectors的API进行查询,不要用list_vectors的方式遍历所有向量,这样遍历全桶会导致巨大的查询成本。
下文是使用query_vectors查询的例子。原始文件参考本文对应Github中的04_query_metadata_for_key.py这个文件。
#!/usr/bin/env python3
"""Query S3 Vector Bucket to find key by metadata path"""
import boto3
import json
import sys
from typing import List, Dict, Any
# AWS clients
bedrock_client = boto3.client('bedrock-runtime', region_name='us-east-1')
s3vectors_client = boto3.client('s3vectors', region_name='us-east-1')
# Configuration
VECTOR_BUCKET = 'my-nova-mme-demo-01'
INDEX_NAME = 'my-image-index-01'
MODEL_ID = 'amazon.nova-2-multimodal-embeddings-v1:0'
EMBEDDING_DIMENSION = 3072
SEARCH_PATH = 'test-image/01/b-00.jpg' # Default value
def generate_text_embedding(text: str) -> List[float]:
"""Generate embedding for text using Nova MME"""
print(f"\nGenerating query embedding...")
# Prepare model input for text embedding
# Use GENERIC_RETRIEVAL to match GENERIC_INDEX used during indexing
model_input = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {
"truncationMode": "END",
"value": text
}
}
}
# Invoke Bedrock model
response = bedrock_client.invoke_model(
modelId=MODEL_ID,
body=json.dumps(model_input)
)
# Parse response
result = json.loads(response['body'].read())
embedding = result.get('embeddings', [{}])[0].get('embedding', [])
print(f"✓ Embedding generated (dimension: {len(embedding)})")
return embedding
def query_by_metadata(
vector_bucket: str, index_name: str, search_path: str
) -> List[Dict[str, Any]]:
"""Query vectors using metadata filter with query_vectors API"""
print("=" * 60)
print("Query Vector Key by Metadata")
print("=" * 60)
print(f"\n Vector Bucket: {vector_bucket}")
print(f" Index Name: {index_name}")
print(f" Searching for path: {search_path}")
try:
# Generate a valid query embedding using text
query_embedding = generate_text_embedding("metadata query")
# Create metadata filter for full_path
metadata_filter = {"full_path": {"$eq": search_path}}
print(f"\n Querying with metadata filter...")
print(f" Filter: {json.dumps(metadata_filter, indent=2)}")
# Query vectors with metadata filter
response = s3vectors_client.query_vectors(
vectorBucketName=vector_bucket,
indexName=index_name,
queryVector={'float32': query_embedding},
topK=10,
filter=metadata_filter,
returnDistance=True,
returnMetadata=True
)
results = response.get('vectors', [])
print(f"✓ Found {len(results)} matching vector(s)")
return results
except Exception as e:
print(f"\n✗ Error: {e}")
import traceback
traceback.print_exc()
return []
def display_results(results: List[Dict[str, Any]]):
"""Display query results"""
print("\n" + "=" * 60)
print("Results")
print("=" * 60)
if not results:
print("\nNo matching vectors found.")
return
for idx, vector in enumerate(results, 1):
print(f"\n--- Vector {idx} ---")
# Display key
key = vector.get('key', 'N/A')
print(f" Key: {key}")
# Display distance
distance = vector.get('distance')
if distance is not None:
print(f" Distance: {distance}")
# Display metadata
metadata = vector.get('metadata', {})
if metadata:
print(f" Metadata:")
for meta_key, meta_value in metadata.items():
print(f" {meta_key}: {meta_value}")
def main():
"""Main function"""
# Check if path is provided as command line argument
if len(sys.argv) > 1:
search_path = sys.argv[1]
else:
search_path = SEARCH_PATH
# Query vectors by metadata
results = query_by_metadata(
vector_bucket=VECTOR_BUCKET,
index_name=INDEX_NAME,
search_path=search_path
)
# Display results
display_results(results)
print("\n" + "=" * 60)
if results:
print("✓ Query Completed Successfully!")
else:
print("No matching vectors found.")
print("=" * 60)
if __name__ == '__main__':
main()
将以上代码保存为query_metadata_for_key.py。替换其中要搜索的原始图片路径和名称,即可获得Key ID。执行后返回结果如下:
============================================================
Query Vector Key by Metadata
============================================================
Vector Bucket: my-nova-mme-demo-01
Index Name: my-image-index-01
Searching for path: test-image/01/b-00.jpg
Generating query embedding...
✓ Embedding generated (dimension: 3072)
Querying with metadata filter...
Filter: {
"full_path": {
"$eq": "test-image/01/b-00.jpg"
}
}
✓ Found 1 matching vector(s)
============================================================
Results
============================================================
--- Vector 1 ---
Key: b3014d28baba40bfb4651c123f43f0c7
Distance: 0.9716207981109619
Metadata:
file_name: b-00.jpg
full_path: test-image/01/b-00.jpg
file_path: test-image/01
============================================================
✓ Query Completed Successfully!
============================================================
可以看到这里正确的返回了Key ID。
有了Key ID,即可构建删除向量的程序。原始文件参考本文对应Github中的05_delete_vector.py这个文件。代码如下:
#!/usr/bin/env python3
"""Delete a vector from S3 Vector Bucket"""
import boto3
import json
import sys
from typing import Dict, Any
# AWS clients
s3vectors_client = boto3.client('s3vectors', region_name='us-east-1')
# Configuration
VECTOR_BUCKET = 'my-nova-mme-demo-01'
INDEX_NAME = 'my-image-index-01'
VECTOR_KEY = 'b3014d28baba40bfb4651c123f43f0c7' # Set this to the key you want to delete
def delete_vector(
vector_bucket: str,
index_name: str,
vector_key: str
) -> Dict[str, Any]:
"""Delete a vector from S3 Vectors"""
print("=" * 60)
print("Delete Vector from S3 Vectors")
print("=" * 60)
print(f"\n Vector Bucket: {vector_bucket}")
print(f" Index Name: {index_name}")
print(f" Vector Key: {vector_key}")
try:
# Delete vector using delete_vectors API
response = s3vectors_client.delete_vectors(
vectorBucketName=vector_bucket,
indexName=index_name,
keys=[vector_key]
)
print(f"\n✓ Vector deleted successfully!")
print(f"\n API Response:")
print(f" {json.dumps(response, indent=2, default=str)}")
return {
'success': True,
'vector_key': vector_key,
'response': response
}
except Exception as e:
print(f"\n✗ Error deleting vector: {e}")
return {
'success': False,
'vector_key': vector_key,
'error': str(e)
}
def main():
"""Main function to delete vector"""
# Check if vector key is provided
if len(sys.argv) > 1:
vector_key = sys.argv[1]
elif VECTOR_KEY:
vector_key = VECTOR_KEY
else:
print("Error: No vector key provided!")
print("\nUsage:")
print(f" python {sys.argv[0]} <vector_key>")
print(f" Or set VECTOR_KEY in the script")
sys.exit(1)
# Delete the vector
result = delete_vector(
vector_bucket=VECTOR_BUCKET,
index_name=INDEX_NAME,
vector_key=vector_key
)
print("\n" + "=" * 60)
if result['success']:
print("✓ Deletion Completed Successfully!")
else:
print("✗ Deletion Failed!")
print("=" * 60)
if __name__ == '__main__':
main()
将其保存为delete_vector.py,执行后结果如下:
============================================================
Delete Vector from S3 Vectors
============================================================
Vector Bucket: my-nova-mme-demo-01
Index Name: my-image-index-01
Vector Key: b3014d28baba40bfb4651c123f43f0c7
✓ Vector deleted successfully!
API Response:
{
"ResponseMetadata": {
"RequestId": "e6aba995-efb4-4235-87bf-e846d7e0a498",
"HostId": "",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"date": "Thu, 13 Nov 2025 09:07:38 GMT",
"content-type": "application/json",
"content-length": "2",
"connection": "keep-alive",
"x-amz-request-id": "e6aba995-efb4-4235-87bf-e846d7e0a498",
"access-control-allow-origin": "*",
"vary": "origin, access-control-request-method, access-control-request-headers",
"access-control-expose-headers": "*"
},
"RetryAttempts": 0
}
}
============================================================
✓ Deletion Completed Successfully!
============================================================
由此删除向量完成。
五、使用同步方式批量Embedding的方案
以上几个例子是使用SDK编程对单个文件的Embedding处理,另外在上一章节也介绍了使用s3vector-embed-cli批量文件处理S3存储桶的文件,此时s3vector-embed-cli自己做了分批处理。如果是有大量文件需要处理,而且不是使用s3vector-embed-cli,那么需要设计一个异步处理的解决方案,并自己编写调用API的代码。主要思路如下。
1、批量处理思路
批量处理的方式有很多种,这里仅列出部分思路供参考。
| 处理过程 | 少量文件 | 大量文件 |
|---|---|---|
| 获取文件清单 | 直接在代码中分批处理 | 将文件清单存储DynamoDB或者使用SQS队列管理任务 |
| Embedding调用 | 调用Bedrock invoke API同步调用 | - 如果处理时限要求高,那么小文件和图片可使用同步调用InvokeModel;视频等文件使用异步调用StartAsyncInvoke; - 如果处理时限不敏感,可接受几个小时的处理时间,那么可使用批量推理Batch Inference,其计费方式只有实时的一半左右 |
| Embedding任务管理 | 同步调用不需要 | 使用DynamoDB保存异步任务的状态 |
| 并发机制 | 可单线程或多线程 | - 同步或者异步调用时候可单线程或多线程,也可借助Lambda执行并发 - 批调用可提交多个任务 |
| 向量保存 | 同步处理时可直接写入,但注意S3 Vector Bucket的写入Limit | 异步调用和批量推理场景,模型输出结果会保存在S3普通存储桶内格式是jsonl,需要被二次处理、读取后分批写入S3 Vector Bucket,且需要注意写入Limit |
根据以上分析,最简单的方式是在云端启动一台EC2,然后直接在EC2上运行Embedding程序,并写入S3 Vector Bucket。如果希望后续能持续对S3存储桶内新增文件进行Embedding,可使用多种AWS服务组合的方式。
本文选择使用使用同步调用的方式,这样立刻就可以获取Embedding后的向量进行后续测试,而无需等待数分钟到数小时才能获得结果。在方案中,SQS队列作为任务管理,使用Lambda执行并发处理,使用S3 Vector Bucket作为向量存储的架构方式。通过限制Lambda并发,来避免遇到S3 Vector Bucket的写入Limit。同时,在使用Lambda作为SQS的下游时候,一条消息处理完毕后SQS会自动删除,因此就不需要人为地在处理完毕后删除SQS消息的步骤了。
如果您已经熟悉了整个体系架构,可以批量加载大量数据进行Embedding,那么您可以使用Bedrock Batch Inference批量推理,这将在另外一篇博客中进行介绍。
注意,以下代码中S3 Vector Bucket名字没变,但是Index重新创建了一个。这样由此与前一步的测试分开。
aws s3vectors create-index \
--vector-bucket-name "my-nova-mme-demo-01" \
--index-name my-image-index-02-lambda \
--data-type "float32" \
--dimension 3072 \
--distance-metric "cosine" \
--region us-east-1
2、创建SQS队列
使用AWSCLI创建SQS队列,且创建类型是FIFO的,以确保处理结果是唯一的。
aws sqs create-queue \
--queue-name embedding-queue.fifo \
--attributes FifoQueue=true,ContentBasedDeduplication=false \
--region us-east-1
返回结果:
{
"QueueUrl": "https://sqs.us-east-1.amazonaws.com/133129065110/embedding-queue.fifo"
}
注意保存这个URL,下一步将会使用。
配置SQS可见性超时时间(注意替换命令中的AWS Account ID和SQS队列名称):
aws sqs set-queue-attributes \
--queue-url https://sqs.us-east-1.amazonaws.com/133129065110/embedding-queue.fifo \
--attributes VisibilityTimeout=900 \
--region us-east-1
注意这一步是必须的,SQS消息可见时间(默认30秒,这里修改为900秒)必须大于Lambda超时时间(60秒),否则无法将Lambda和SQS关联。
3、创建Lambda函数需要的IAM Role和Policy
首先创建运行Lambda所需要的IAM Policy和Role。以下文件是IAM Policy示例,其中的原始文件S3存储桶、模型ID、向量存储桶的Index索引、SQS队列等名称都需要替换为实际使用的名称。将这个文件保存为iam_policy.json。原始文件参考本文对应Github中的batch-lambda/iam-for-lambda/iam_policy.json这个文件。内容如下。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": "arn:aws:s3:::nova-mme-demo-source-image/*"
},
{
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel"
],
"Resource": "arn:aws:bedrock:us-east-1::foundation-model/amazon.nova-2-multimodal-embeddings-v1:0"
},
{
"Effect": "Allow",
"Action": [
"s3vectors:PutVectors"
],
"Resource": [
"arn:aws:s3vectors:us-east-1:133129065110:bucket/my-nova-mme-demo-01",
"arn:aws:s3vectors:us-east-1:133129065110:bucket/my-nova-mme-demo-01/index/my-image-index-02-lambda"
]
},
{
"Effect": "Allow",
"Action": [
"sqs:ReceiveMessage",
"sqs:DeleteMessage",
"sqs:GetQueueAttributes"
],
"Resource": "arn:aws:sqs:us-east-1:133129065110:embedding-queue.fifo"
}
]
}
将以上内容保存为iam_policy.json。
将如下内容保存为trust-policy.json。原始文件参考本文对应Github中的batch-lambda/iam-for-lambda/trust-policy.json这个文件。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
然后通过AWSCLI创建IAM Role(Policy暂时空的Role)。
aws iam create-role \
--role-name EmbeddingWithNovaByLambda \
--assume-role-policy-document file://trust-policy.json
接下来附加IAM Policy到刚才创建的Role上。
aws iam put-role-policy \
--role-name EmbeddingWithNovaByLambda \
--policy-name EmbeddingWithNovaByLambda \
--policy-document file://iam_policy.json
另外还要附加Lambda基础执行权限。
aws iam attach-role-policy \
--role-name EmbeddingWithNovaByLambda \
--policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
执行成功的话直接返回到命令行输入状态。
4、创建Lambda函数并设置并发
由于Lambda函数的代码长度比较长,这里不再粘贴代码,原始文件参考本文对应Github中的batch-lambda/lambda_embedding.py这个文件。内容如下。
将文件下载到本地后,文件名lambda_embedding.py保持不变,执行如下命令打包为zip文件。
zip lambda_embedding.zip lambda_embedding.py
接下来构建创建Lambda的AWSCLI命令。以下命令中有函数名称、AWS Account ID、IAM Role的ARN三个地方需要替换。由于只处理图片,超时使用60秒足够,内存大小使用512MB足够。
aws lambda create-function \
--function-name embedding-nova-mme \
--runtime python3.13 \
--role arn:aws:iam::133129065110:role/EmbeddingWithNovaByLambda \
--handler lambda_embedding.lambda_handler \
--zip-file fileb://lambda_embedding.zip \
--timeout 60 \
--memory-size 512 \
--region us-east-1
创建成功返回消息如下。
{
"FunctionName": "embedding-nova-mme",
"FunctionArn": "arn:aws:lambda:us-east-1:133129065110:function:embedding-nova-mme",
"Runtime": "python3.13",
"Role": "arn:aws:iam::133129065110:role/EmbeddingWithNovaByLambda",
"Handler": "lambda_embedding.lambda_handler",
"CodeSize": 2089,
"Description": "",
"Timeout": 60,
"MemorySize": 512,
"LastModified": "2025-11-13T11:09:28.187+0000",
"CodeSha256": "/t1GtzJwvnihPeciTnHWuPKiuPxdcwI8BkOxmLDppvQ=",
"Version": "$LATEST",
"TracingConfig": {
"Mode": "PassThrough"
},
"RevisionId": "f5accd66-f9f9-4cf2-baef-36a4f1f0371c",
"State": "Pending",
"StateReason": "The function is being created.",
"StateReasonCode": "Creating",
"PackageType": "Zip",
"Architectures": [
"x86_64"
],
"EphemeralStorage": {
"Size": 512
},
"SnapStart": {
"ApplyOn": "None",
"OptimizationStatus": "Off"
},
"RuntimeVersionConfig": {
"RuntimeVersionArn": "arn:aws:lambda:us-east-1::runtime:65146f0fbf5cb9d34934e5b4ab5f3cab46f46064159f046fd14cb06e649a6f60"
},
"LoggingConfig": {
"LogFormat": "Text",
"LogGroup": "/aws/lambda/embedding-nova-mme"
}
}
设置刚才的lambda函数的并发,限制为5,避免遇到S3 Vector Bucket写入API限制。替换命令中的函数名称为实际的名称。然后执行。
aws lambda put-function-concurrency \
--function-name embedding-nova-mme \
--reserved-concurrent-executions 5 \
--region us-east-1
返回信息如下:
{
"ReservedConcurrentExecutions": 5
}
5、关联Lambda和SQS
将Lambda和SQS队列关联,设置--batch-size 1表示每次Lambda自动从SQS拿回一条消息。由于我们的Lambda本身设计上一次只能接受并处理一个文件,因此这里不要提升batch size,否则lambda不能运行。
替换如下命令中的AWS Account ID和SQS队列名称,然后执行:
aws lambda create-event-source-mapping \
--function-name embedding-nova-mme \
--event-source-arn arn:aws:sqs:us-east-1:133129065110:embedding-queue.fifo \
--batch-size 1 \
--region us-east-1
关联成功,返回信息如下:
{
"UUID": "9b0f2680-71c5-47de-ab0c-a738b4601d58",
"BatchSize": 1,
"MaximumBatchingWindowInSeconds": 0,
"EventSourceArn": "arn:aws:sqs:us-east-1:133129065110:embedding-queue.fifo",
"FunctionArn": "arn:aws:lambda:us-east-1:133129065110:function:embedding-nova-mme",
"LastModified": "2025-11-13T19:18:56.146000+08:00",
"State": "Creating",
"StateTransitionReason": "USER_INITIATED",
"FunctionResponseTypes": [],
"EventSourceMappingArn": "arn:aws:lambda:us-east-1:133129065110:event-source-mapping:9b0f2680-71c5-47de-ab0c-a738b4601d58"
}
好了,准备就绪,现在往SQS队列上发送S3原文文件存储桶的对象清单,Lambda就会被触发,执行Embedding处理后生成的向量会写入S3 Vector Bucket。如果您需要修改要写入的S3 Vector Bucket名称、索引的名称,那么需要更新Lambda代码,还需要更新Lambda使用的IAM Policy中的授权的index索引名称。更新完毕后,要在Lambda控制台上点击Deploy按钮完成部署。另外还需要注意,不管是修改代码,还是修改IAM Role/Policy的定义,任何与本Lambda相关的环境变化了,都需要重新按一下部署按钮,让Lambda函数重新加载所有运行条件。
为便于管理,未来可将这些参数作为Lambda环境变量代入(需要修改Lambda代码获取环境变量),这样就不用每次更新Lambda代码了。
6、提交单一文件到SQS队列进行测试
为了降低调试难度,先不要批量将S3对象路径发送到SQS,而是发送单一文件进行测试。
代码长度比较长,这里不再粘贴代码,原始文件参考本文对应Github中的batch-lambda/test_sqs.py这个文件。将文件下载到本地后,保存为test-sqs.py。接下来执行这个代码。
执行成功的话,返回:
============================================================
Send Test Message to SQS
============================================================
Parsed S3 URI:
Bucket: nova-mme-demo-source-image
Key: 01/b-00.jpg
Message body:
{
"bucket": "nova-mme-demo-source-image",
"key": "01/b-00.jpg",
"size": 0,
"last_modified": "2025-11-13T20:12:29.460883"
}
Sending message to SQS...
✓ Message sent successfully!
Message ID: 16eb7ba3-c3d6-4e78-952e-f77df4ab9d46
Sequence Number: 18898081277019887616
============================================================
Next Steps:
============================================================
1. Check SQS queue in AWS Console
2. Monitor Lambda function logs in CloudWatch
3. Verify embedding is written to S3 Vector Bucket
To check Lambda logs:
aws logs tail /aws/lambda/embedding-processor --follow --us-east-1
检查方法:
aws sqs get-queue-attributes \
--queue-url https://sqs.us-east-1.amazonaws.com/133129065110/embedding-queue.fifo \
--attribute-names ApproximateNumberOfMessages \
--region us-east-1
返回结果是SQS队列中的消息。如果被lambda正常获取到,不论Lambda执行是否成功,只要从SQS取走,这里就会显示0。
{
"Attributes": {
"ApproximateNumberOfMessages": "0"
}
}
检查Lambda日志的方法:
aws logs tail /aws/lambda/embedding-nova-mme --follow --region us-east-1
可看到Lambda返回日志:
2025-11-13T12:12:30.602000+00:00 2025/11/13/[$LATEST]d238428ccf7e4b03856c3d7181bd5a72 INIT_START Runtime Version: python:3.13.v68 Runtime Version ARN: arn:aws:lambda:us-east-1::runtime:65146f0fbf5cb9d34934e5b4ab5f3cab46f46064159f046fd14cb06e649a6f60
2025-11-13T12:12:31.196000+00:00 2025/11/13/[$LATEST]d238428ccf7e4b03856c3d7181bd5a72 START RequestId: f07f3f34-5f33-5d85-8251-5ebb926d93bb Version: $LATEST
2025-11-13T12:12:31.197000+00:00 2025/11/13/[$LATEST]d238428ccf7e4b03856c3d7181bd5a72 Received 1 messages
2025-11-13T12:12:31.197000+00:00 2025/11/13/[$LATEST]d238428ccf7e4b03856c3d7181bd5a72 Processing: s3://nova-mme-demo-source-image/01/b-00.jpg
2025-11-13T12:12:31.766000+00:00 2025/11/13/[$LATEST]d238428ccf7e4b03856c3d7181bd5a72 ✓ Embedding generated (dimension: 3072)
2025-11-13T12:12:31.766000+00:00 2025/11/13/[$LATEST]d238428ccf7e4b03856c3d7181bd5a72 Storing to S3 Vectors with key: da038d1978674f1bb51a560bca845c57
2025-11-13T12:12:32.020000+00:00 2025/11/13/[$LATEST]d238428ccf7e4b03856c3d7181bd5a72 ✓ Stored to S3 Vectors
2025-11-13T12:12:32.020000+00:00 2025/11/13/[$LATEST]d238428ccf7e4b03856c3d7181bd5a72 Summary: 1 succeeded, 0 failed
2025-11-13T12:12:32.022000+00:00 2025/11/13/[$LATEST]d238428ccf7e4b03856c3d7181bd5a72 END RequestId: f07f3f34-5f33-5d85-8251-5ebb926d93bb
2025-11-13T12:12:32.023000+00:00 2025/11/13/[$LATEST]d238428ccf7e4b03856c3d7181bd5a72 REPORT RequestId: f07f3f34-5f33-5d85-8251-5ebb926d93bb Duration: 826.23 ms Billed Duration: 1417 ms Memory Size: 512 MB Max Memory Used: 96 MB Init Duration: 590.33 ms
注意:aws logs tail是一直持续刷新Lambda函数在CloudWatch LogGroup的日志组的,直到按下Ctrl+C才会中断。否则后续会一直不断刷新的Lambda日志。
由此可以看到,单个文件已经通过SQS+Lambda机制,完成了Embedding并存储到S3 Vector Bucket中了。下一步就是批量提交S3文件到SQS。
7、批量发送要处理的文件清单到SQS队列
上一个章节是提交单一文件到SQS队列的测试,接下来要准备批量提交。需要注意的是,遍历S3存储桶获取所有文件清单的cost等同于做了一次全桶访问,因此遍历存储桶的方式适合于存储桶文件数量适中的场景。如果是数据巨大的存储桶,例如百万到千万级别或者更高,那么不要遍历存储桶,而是使用S3 Inventory自动生成S3文件清单,然后按清单来处理。本文的代码例子假设文件数量在可接受的范围内,因此直接遍历生成文件清单。
此外,考虑到生成文件清单时候,如果文件数量较多,可能意外的网络中断导致遍历存储桶失败,因此可以在本地保存一个进度文件叫做embedding_progress.json,已经获取到的文件名放入这个文件中。如果程序中断,或者人为按Ctrl+C终止了脚本,下次再运行时候,已经在这个文件中的文件名叫不会被重复提交。
由于代码长度比较长,这里不再粘贴代码,原始文件参考本文对应Github中的batch-lambda/list_bucket_sqs.py这个文件。将文件下载到本地后,保存为list_bucket_sqs.py。接下来执行python list_bucket_sqs.py这个代码。
执行后,可看到文件清单被提交到SQS队列。
============================================================
List S3 Images and Send to SQS
============================================================
Listing images from s3://nova-mme-demo-source-image/...
✓ Found 668 image files
Total files: 668
Already processed: 0
Pending to send: 668
Sending 668 messages to SQS...
Batch 1: 10 messages sent
Batch 2: 10 messages sent
Batch 3: 10 messages sent
Batch 4: 10 messages sent
Batch 5: 10 messages sent
Batch 6: 10 messages sent
Batch 7: 10 messages sent
Batch 8: 10 messages sent
....
....
Batch 66: 10 messages sent
Batch 67: 8 messages sent
✓ Summary:
Total sent: 668
Failed: 0
Success rate: 100.0%
============================================================
✓ Process Completed!
Progress saved to: embedding_progress.json
============================================================
在同时,可使用AWSCLI查看SQS队列中等待处理的消息,使用watch命令每2秒刷新一次。
watch aws sqs get-queue-attributes \
--queue-url https://sqs.us-east-1.amazonaws.com/133129065110/embedding-queue.fifo \
--attribute-names ApproximateNumberOfMessages \
--region us-east-1
可看到SQS队列中的消息数字随着不断被消费,而逐渐减少。
Every 2.0s: aws sqs get-queue-attributes --queue-url https://sqs.us-east-1.amazonaws.com/13312906… 74a6cdcebdcb: 1140:05
in 1.847s (0)
{
"Attributes": {
"ApproximateNumberOfMessages": "632"
}
}
通过AWS调用CloudWatch LogGroup可以查看Lambda执行Embedding的情况:
aws logs tail /aws/lambda/embedding-nova-mme --follow --region us-east-1
Lambda的日志中显示Embedding正常完成的效果如下。
2025-11-14T03:40:40.452000+00:00 2025/11/14/[$LATEST]800effc4b94e41319d2740c273dc02df START RequestId: a57f6444-9aa3-542d-bd9c-05d43c4cc03e Version: $LATEST
2025-11-14T03:40:40.453000+00:00 2025/11/14/[$LATEST]800effc4b94e41319d2740c273dc02df Received 1 messages
2025-11-14T03:40:40.453000+00:00 2025/11/14/[$LATEST]800effc4b94e41319d2740c273dc02df Processing: s3://nova-mme-demo-source-image/02/w-05.jpg
2025-11-14T03:40:40.868000+00:00 2025/11/14/[$LATEST]800effc4b94e41319d2740c273dc02df ✓ Embedding generated (dimension: 3072)
2025-11-14T03:40:40.868000+00:00 2025/11/14/[$LATEST]800effc4b94e41319d2740c273dc02df Storing to S3 Vectors with key: 53d456f0bb0d4b59a959487f3f9bec95
2025-11-14T03:40:41.049000+00:00 2025/11/14/[$LATEST]800effc4b94e41319d2740c273dc02df ✓ Stored to S3 Vectors
2025-11-14T03:40:41.049000+00:00 2025/11/14/[$LATEST]800effc4b94e41319d2740c273dc02df Summary: 1 succeeded, 0 failed
2025-11-14T03:40:41.050000+00:00 2025/11/14/[$LATEST]800effc4b94e41319d2740c273dc02df END RequestId: a57f6444-9aa3-542d-bd9c-05d43c4cc03e
2025-11-14T03:40:41.050000+00:00 2025/11/14/[$LATEST]800effc4b94e41319d2740c273dc02df REPORT RequestId: a57f6444-9aa3-542d-bd9c-05d43c4cc03e Duration: 597.68 ms Billed Duration: 598 ms Memory Size: 512 MB Max Memory Used: 101 MB
由此等待一段时间,即可完成批量Embedding。
由于检索方式与上一章节介绍的过程相同,本章节只是介绍批量Embedding,所以查询这块不再赘述。
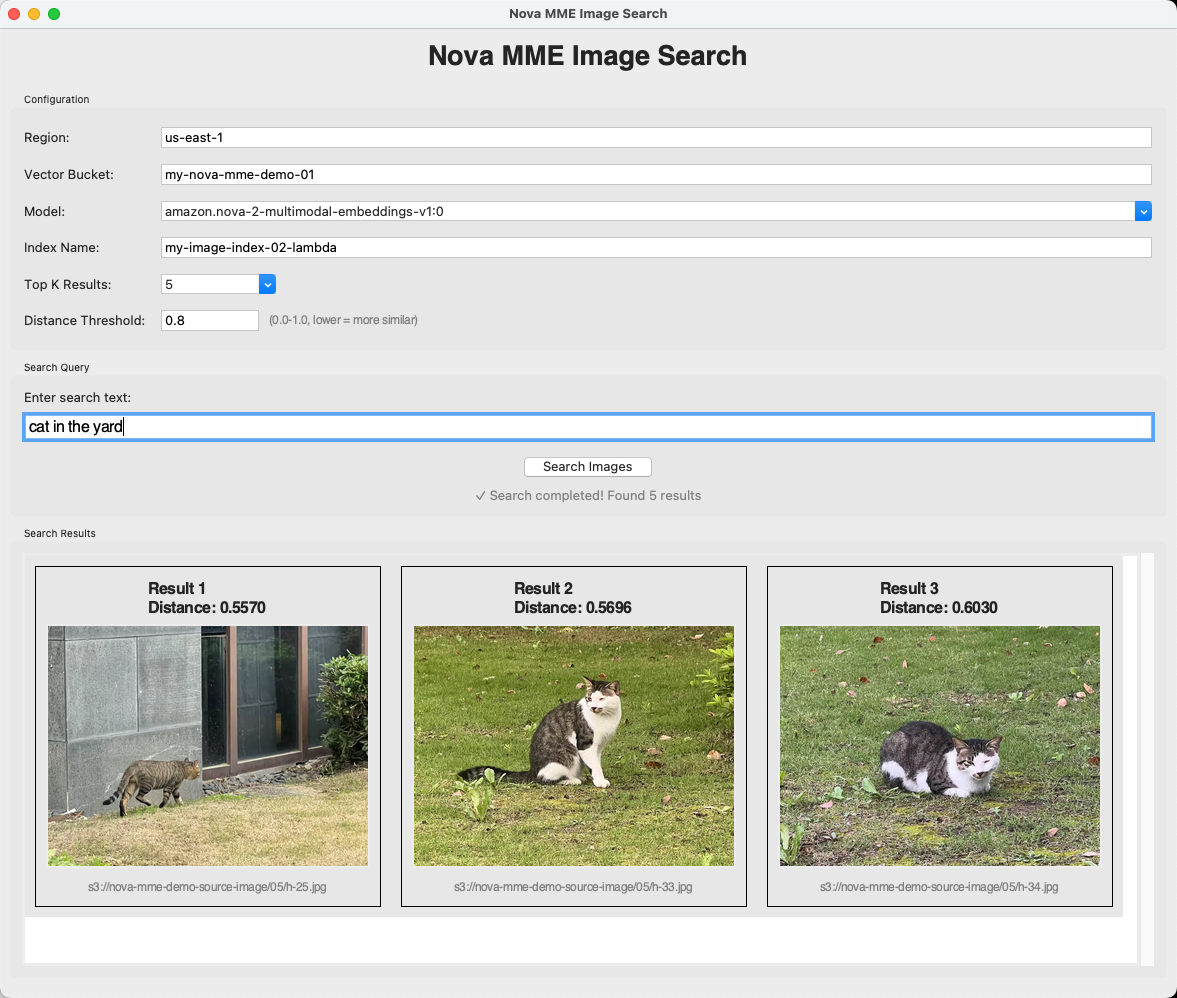
8、GUI查询工具
为了更好的确认检索数据的效果,这里使用了GUI工具,由于代码长度比较长,这里不再粘贴代码,原始文件参考本文对应Github中的GUI-query.py这个文件。
# 安装依赖包
brew install python-tk@3.13
执行如下命令启动GUI
python GUI-query.py
检索效果如下截图。
至此批量Embedding方案完成。
六、Nova MME与Twelvelabs的Marengo Embed 3.0的对比
Amazon Bedrock服务在2025年10月新增了Twelvelabs的Marengo Embed 3.0模型,也是提供了Bedrock的Serverless API调用,开箱即用,无须私有化部署模型。模型上架时候的文档如下:
https://aws.amazon.com/about-aws/whats-new/2025/10/twelvelabs-marengo3-embed-amazon-bedrock/
Marengo Embed 3.0模型支持更大尺寸的视频输入,最大允许6GB体积。参数如下:
https://docs.aws.amazon.com/bedrock/latest/userguide/model-parameters-marengo-3.html
However,虽然这样,但是,Marengo Embed 3.0采用的维度是512与Nova MME的3072差别较大。因此在实际文搜图场景中,以本文采用的数据集来看,效果不如Nova MME。Nova MME文搜图时候,召回图片的距离在0.6~0.8,而Marengo Embed 3.0甚至达到0.9,相比有比较显著差距。但是,Marengo Embed 3.0的维度是512,由此带来较低的成本,而且支持高达6GB的视频输入也是其特色。由此可以看到Marengo Embed 3.0与Nova MME各有不同擅长的领域。
在测试Marengo Embed 3.0时候,Nova MME和Marengo Embed 3.0输出的结果不一样,解析输出数据代码也有所差别。本文的Github代码样例中,文件名带有-tme3的后缀的文件,用于测试Marengo Embed 3.0的文件。可参考这部分已经验证通过的代码。注意里边的存储桶、索引名称、SQS队列、Lambda名称、Lambda Handler等名称的对应关系。篇幅所限,这里不再展开讨论Marengo Embed 3.0了。
七、参考文档
Amazon Nova Multimodal Embeddings: State-of-the-art embedding model for agentic RAG and semantic searchAmazon Nova Multimodal Embeddings: State-of-the-art embedding model for agentic RAG and semantic search
https://aws.amazon.com/blogs/aws/amazon-nova-multimodal-embeddings-now-available-in-amazon-bedrock/
Creating a vector bucket
https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-vectors-buckets-create.html
Deleting vectors from a vector index
https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-vectors-delete.html
Amazon S3 Vectors Embed CLI
https://github.com/awslabs/s3vectors-embed-cli
File limitations for Nova Embeddings
https://docs.aws.amazon.com/nova/latest/userguide/embeddings-schema.html#w73aac21c20b7
Amazon S3 Vectors Limitations and restrictions
https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-vectors-limitations.html
Bedrock batch inference 批量推理
本文有关脚本在Github这里:
https://github.com/aobao32/nova-mme-demo
最后修改于 2025-11-14