在Redshift上使用Spectrum查询S3中的数据
本文详解在Redshift上使用Spectrum查询S3数据的完整实现方案,涵盖IAM角色配置、外部表创建、联合查询等关键步骤,解决跨存储查询的技术难题。
一、配置Redshift使用的IAM Role
1、新建Redshift运行角色
进入IAM界面,点击新建角色。如下截图。
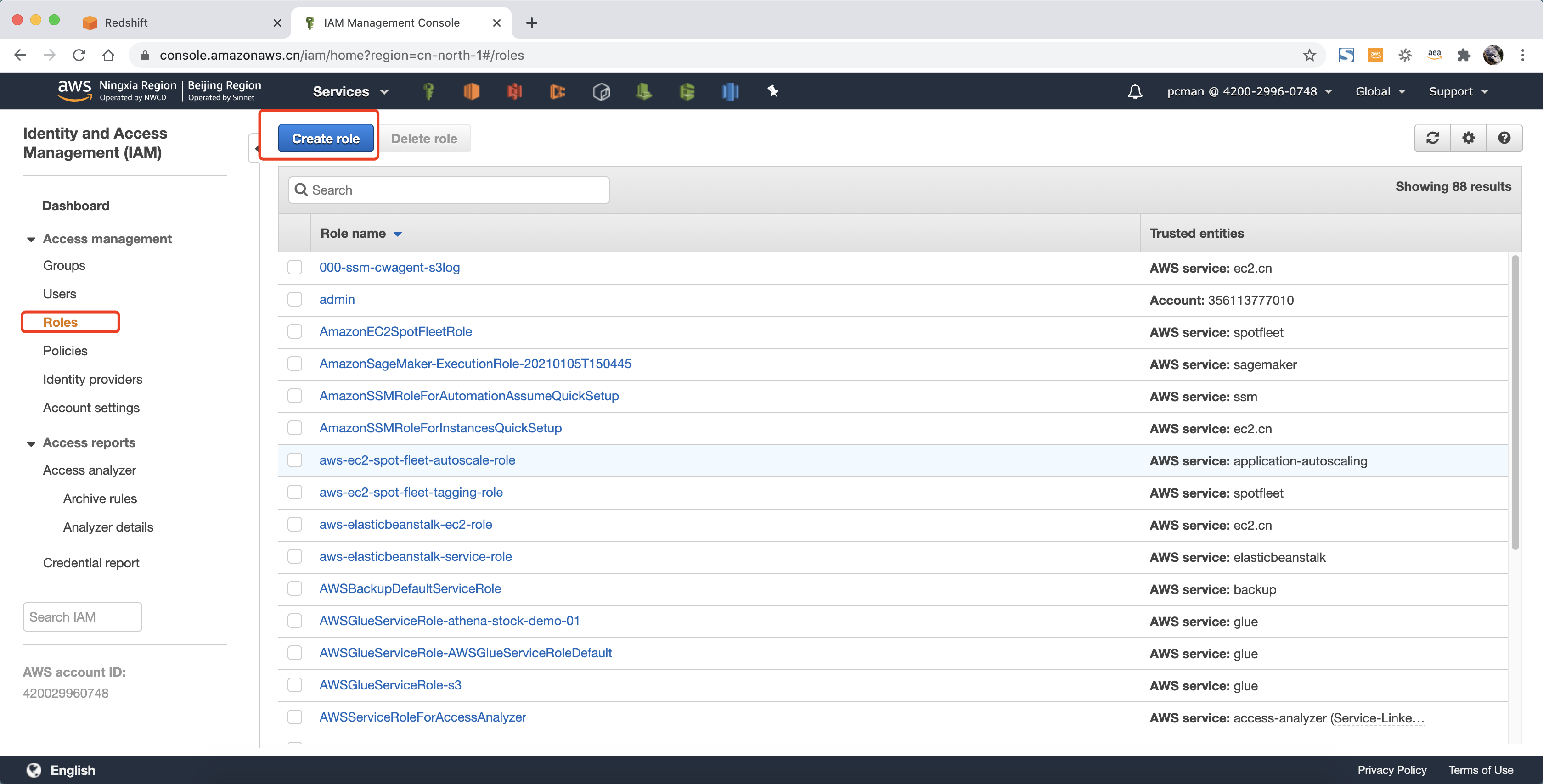
选择服务类型是Redshift,在服务场景用也选择Redshift,点击下一步继续。如下截图。
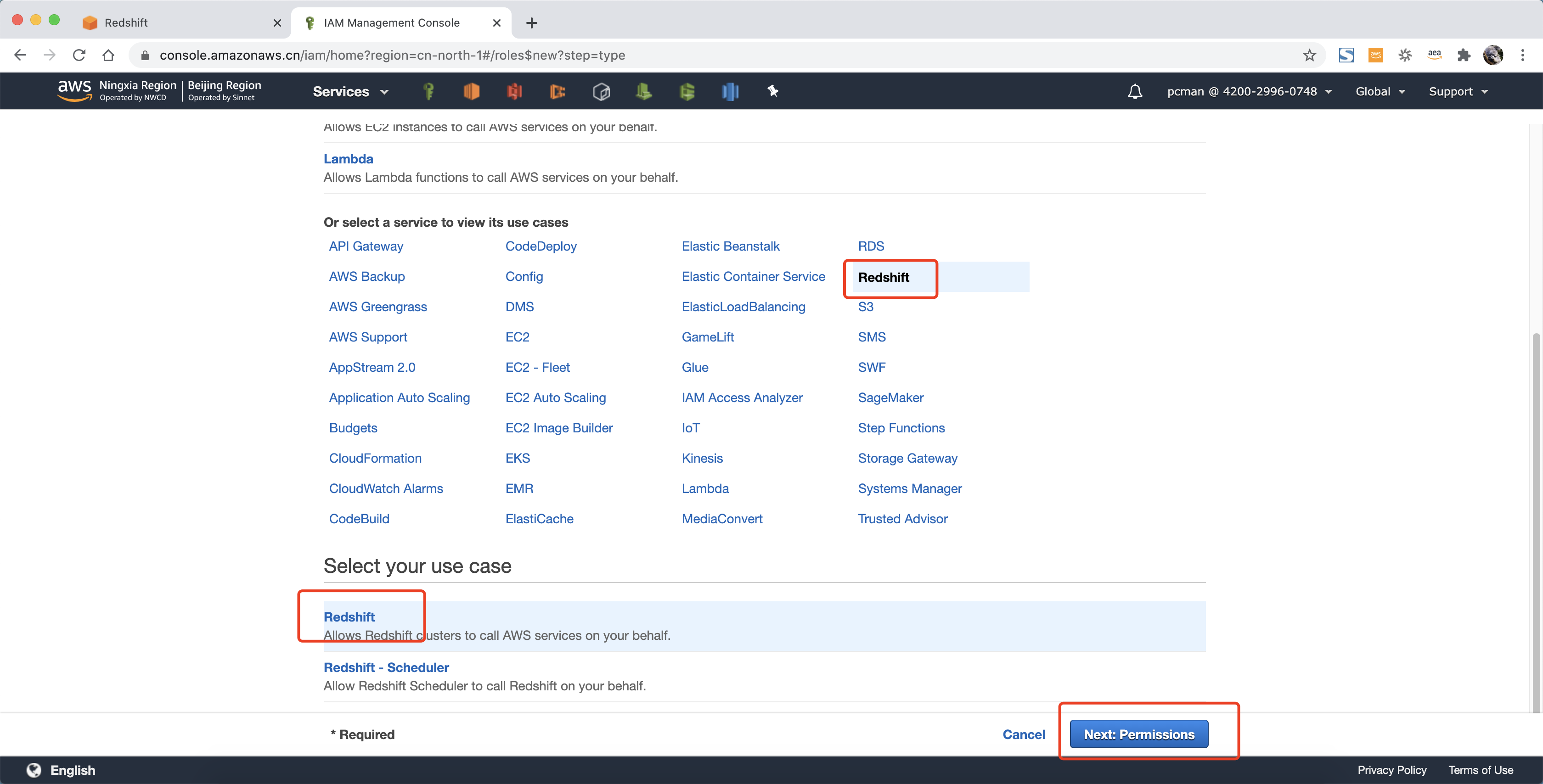
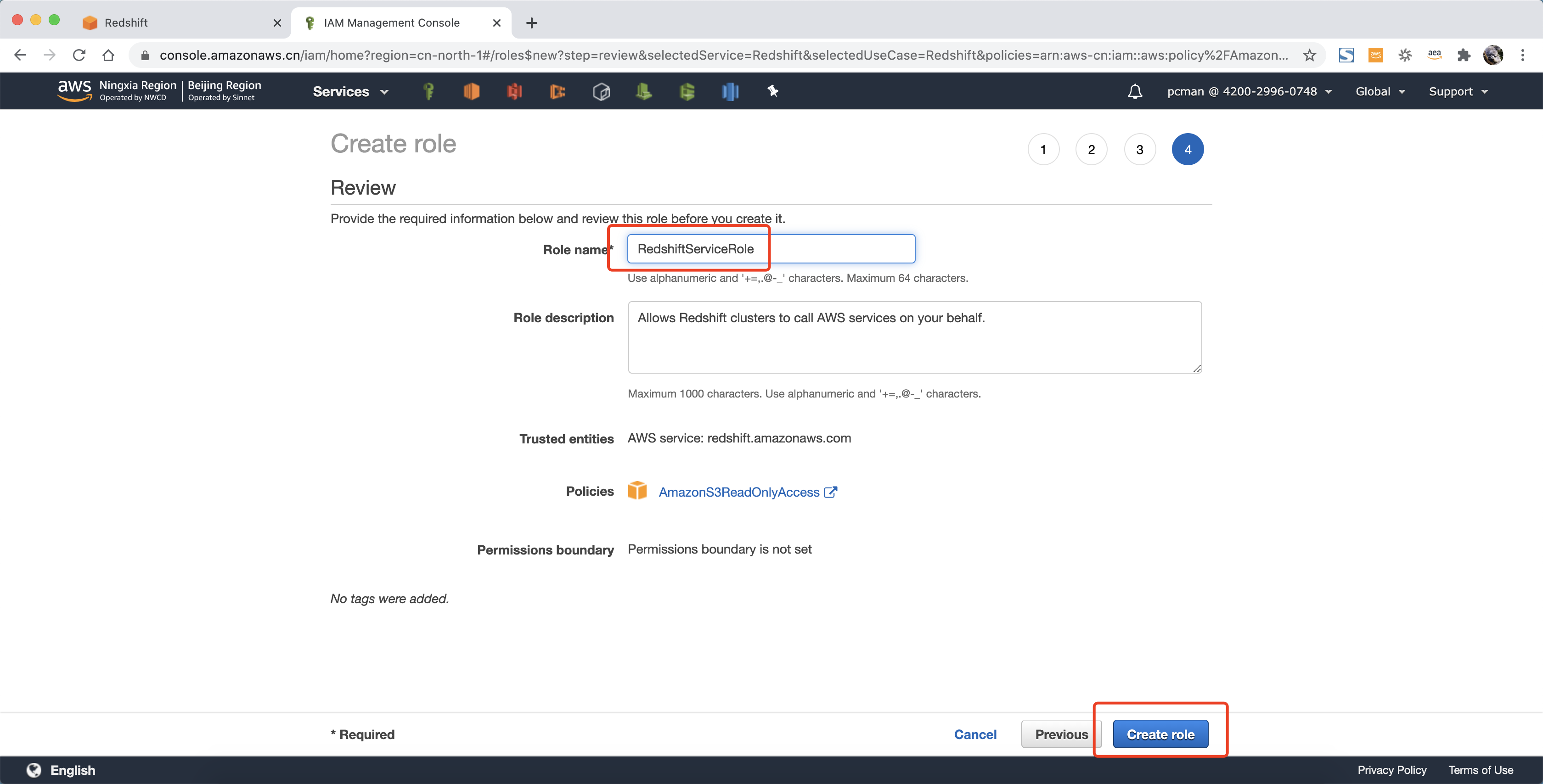
在权限策略界面,搜索框中输入s3,在查询结果中,选中 AmazonS3ReadOnlyAccess ,点击下一步标签继续。如下截图。

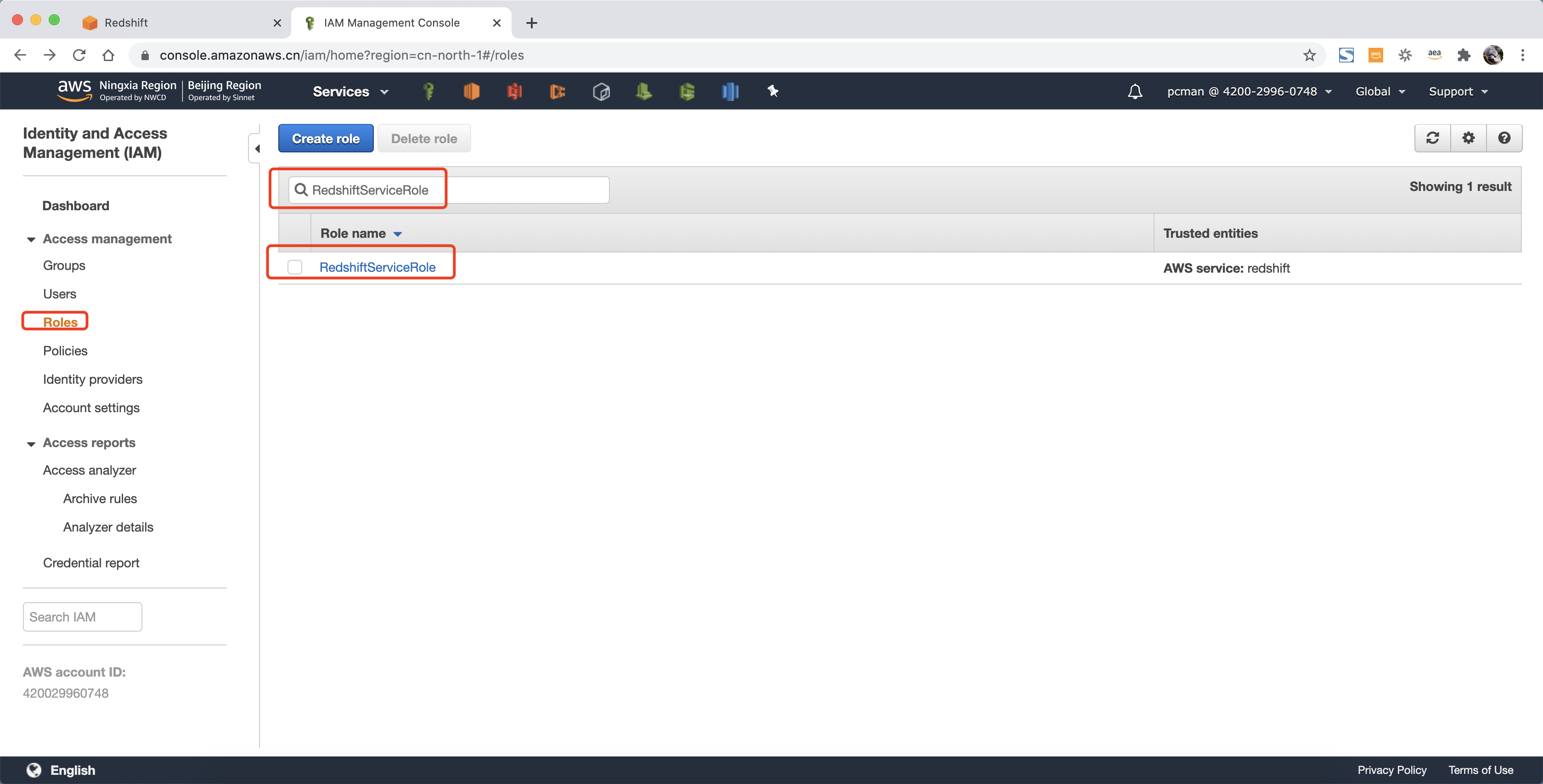
在创建角色的最后一步名称位置,输入RedshiftServiceRole作为名称。点击右下角创建按钮完成角色创建。
2、增加调用Glue权限
在角色页面,搜索刚才创建好的RedshiftServiceRole,点击进入。
点击右侧的Add inline policy 按钮,如下截图。
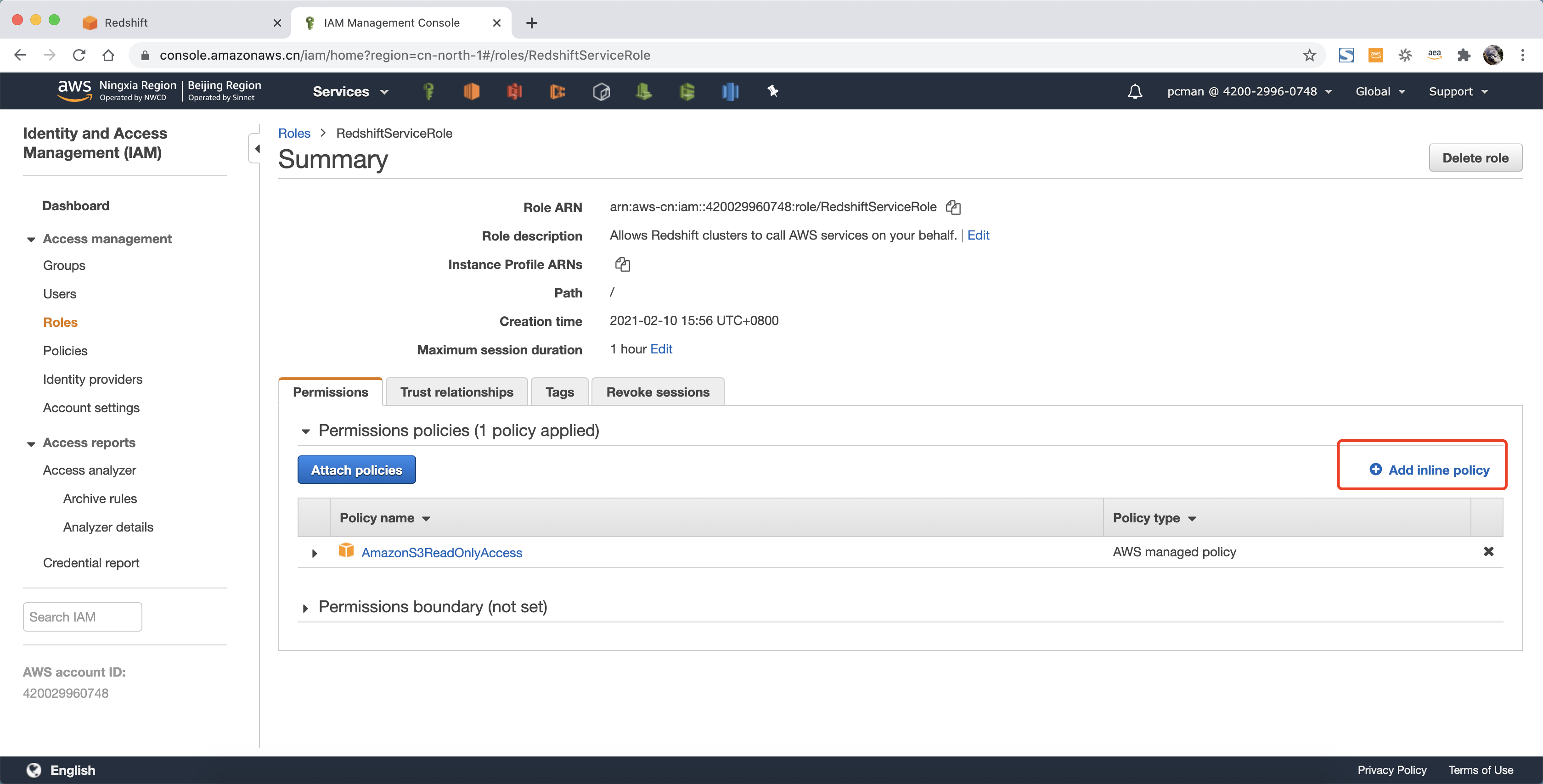
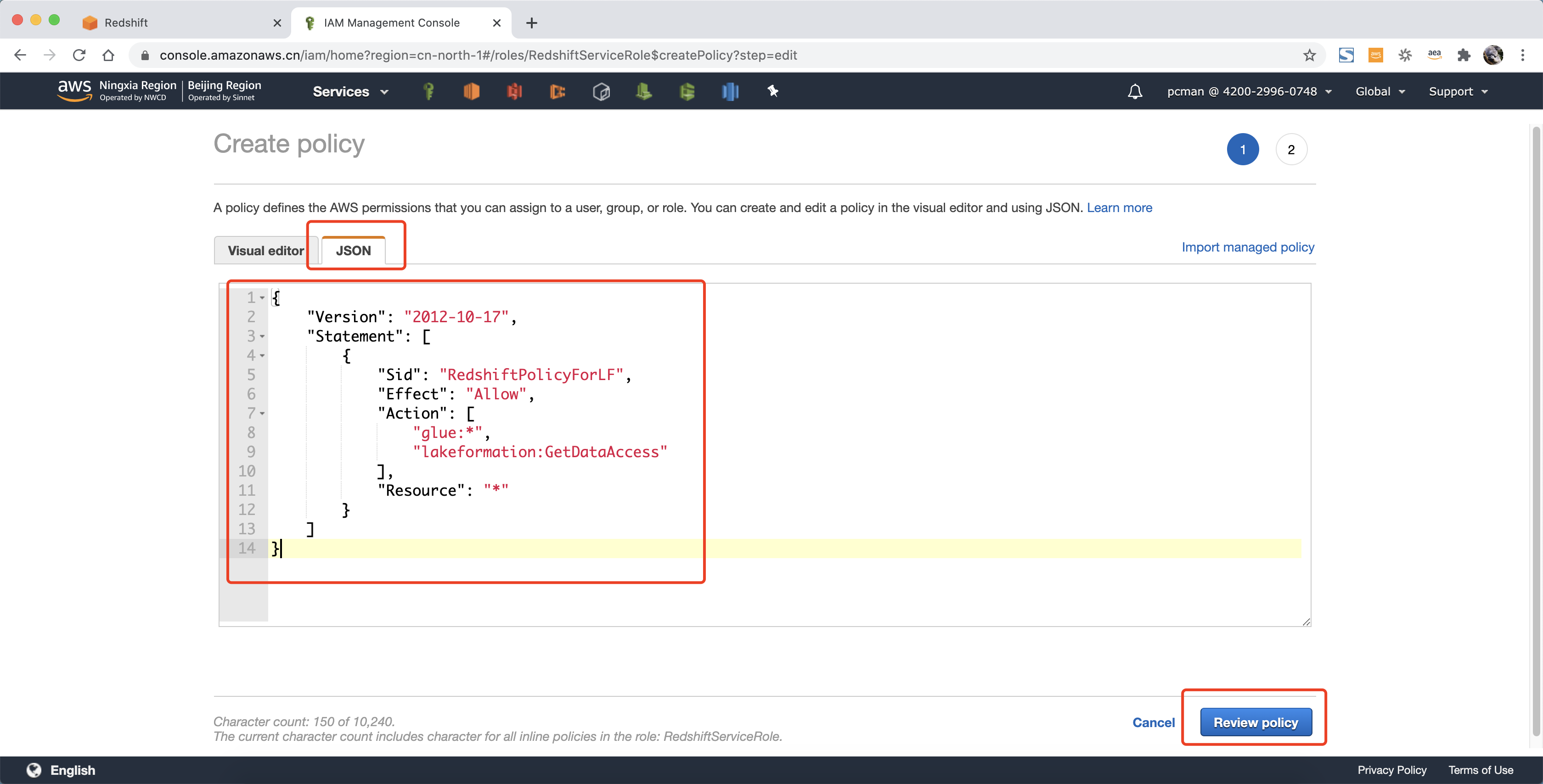
在添加策略页面,点击第二个标签页JSON,直接输入策略如下。
{
"Version": "2012-10-17",
"Statement": \[
{
"Sid": "RedshiftPolicyForLF",
"Effect": "Allow",
"Action": \[
"glue:\*",
"lakeformation:GetDataAccess"
\],
"Resource": "\*"
}
\]
}
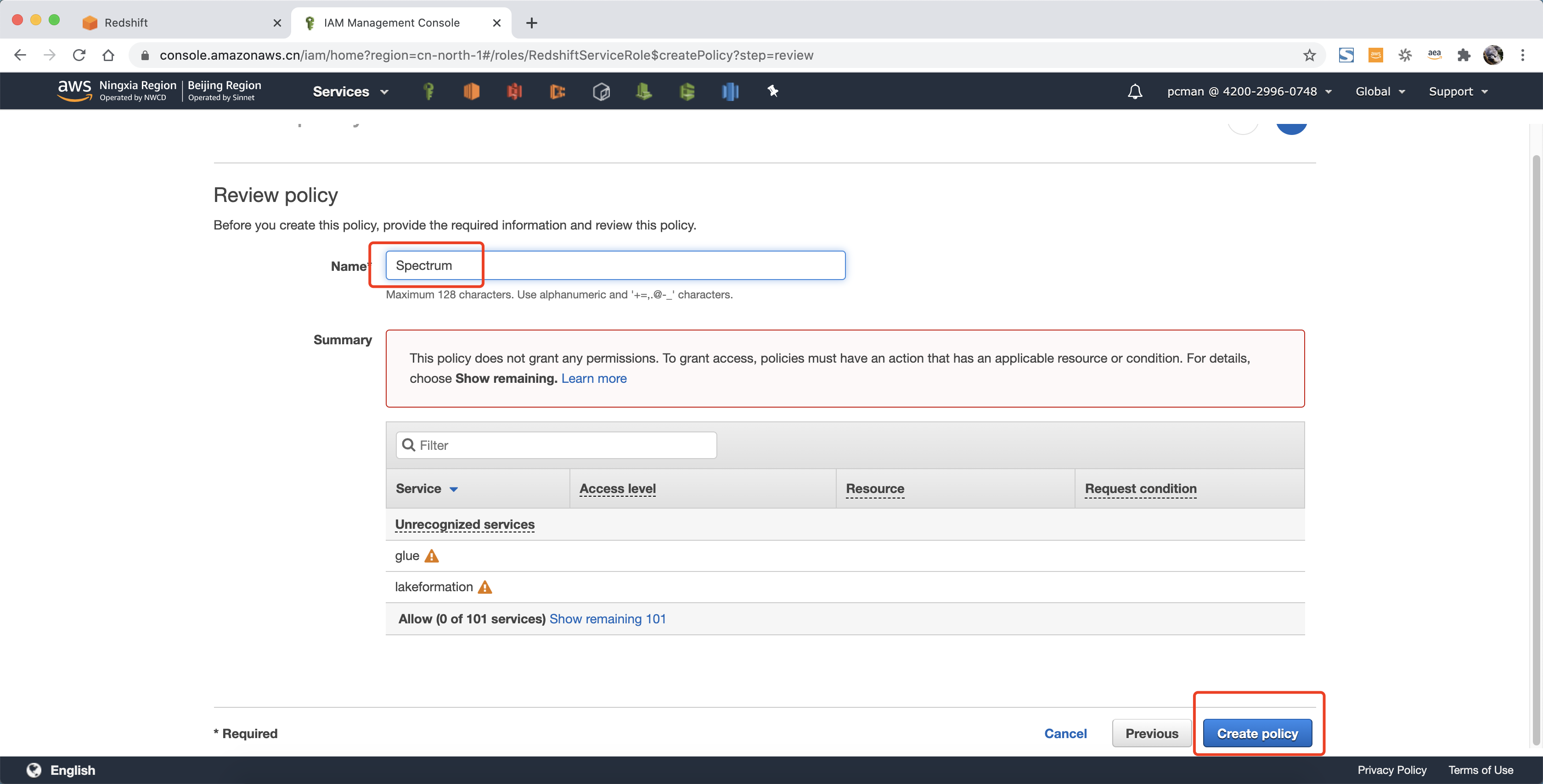
输入后点击右下角Review策略。如下截图。
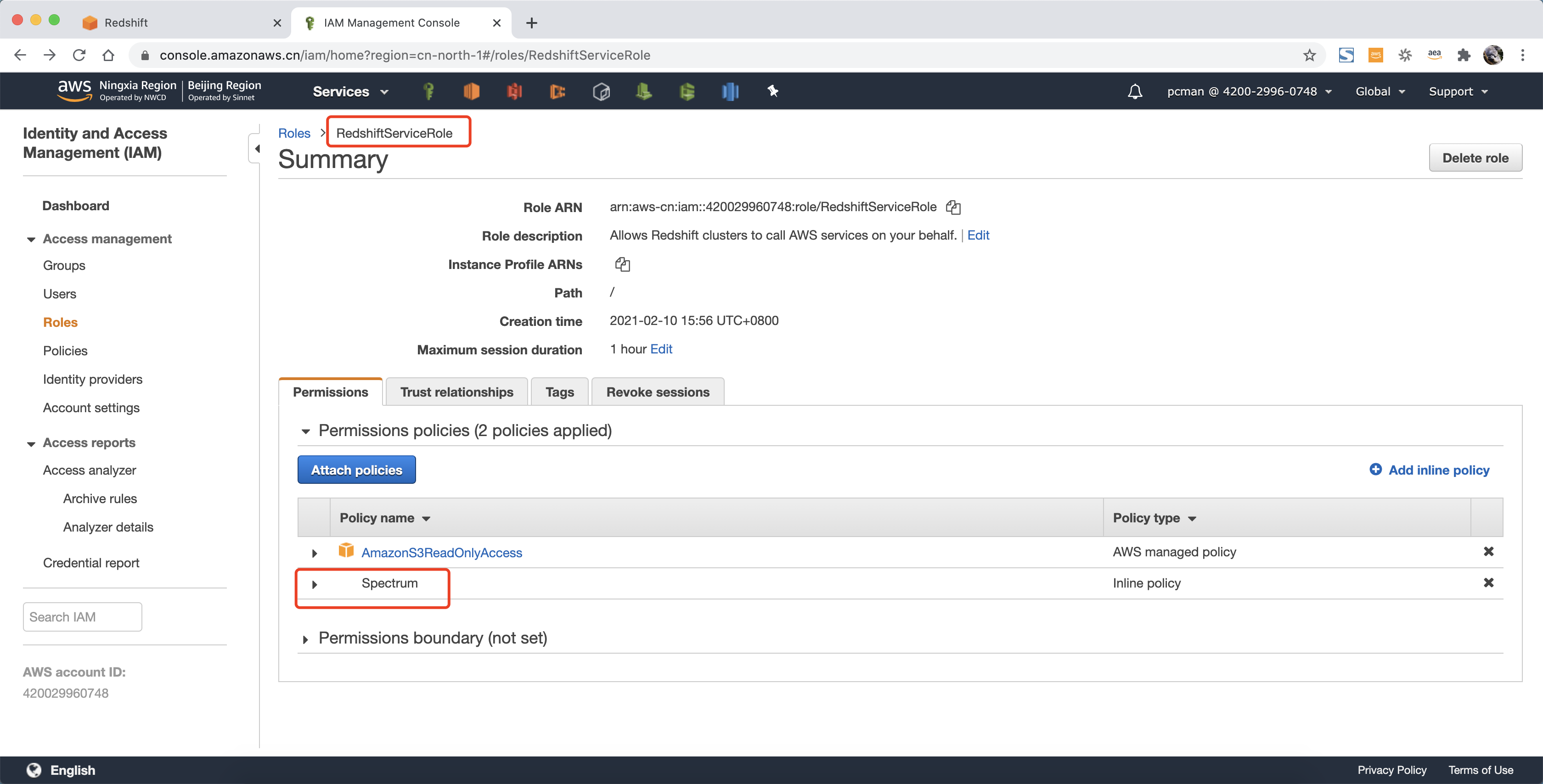
在策略名称界面输入 spectrum 作为名称,点击右下角创建。如下截图。
创建策略完成。角色中可以看到一个名为 spectrum 的策略已经挂载到角色上。
在以上过程完成后,创建Redshift数据库,注意选择使用刚创建的角色。
如果Redshift数据库已经存在,则请修改他的运行角色,然后重启生效。修改已经存在的Redshift数据仓库的方法如下。
进入Redshift界面,点击右上角的体验新UI。如下截图。
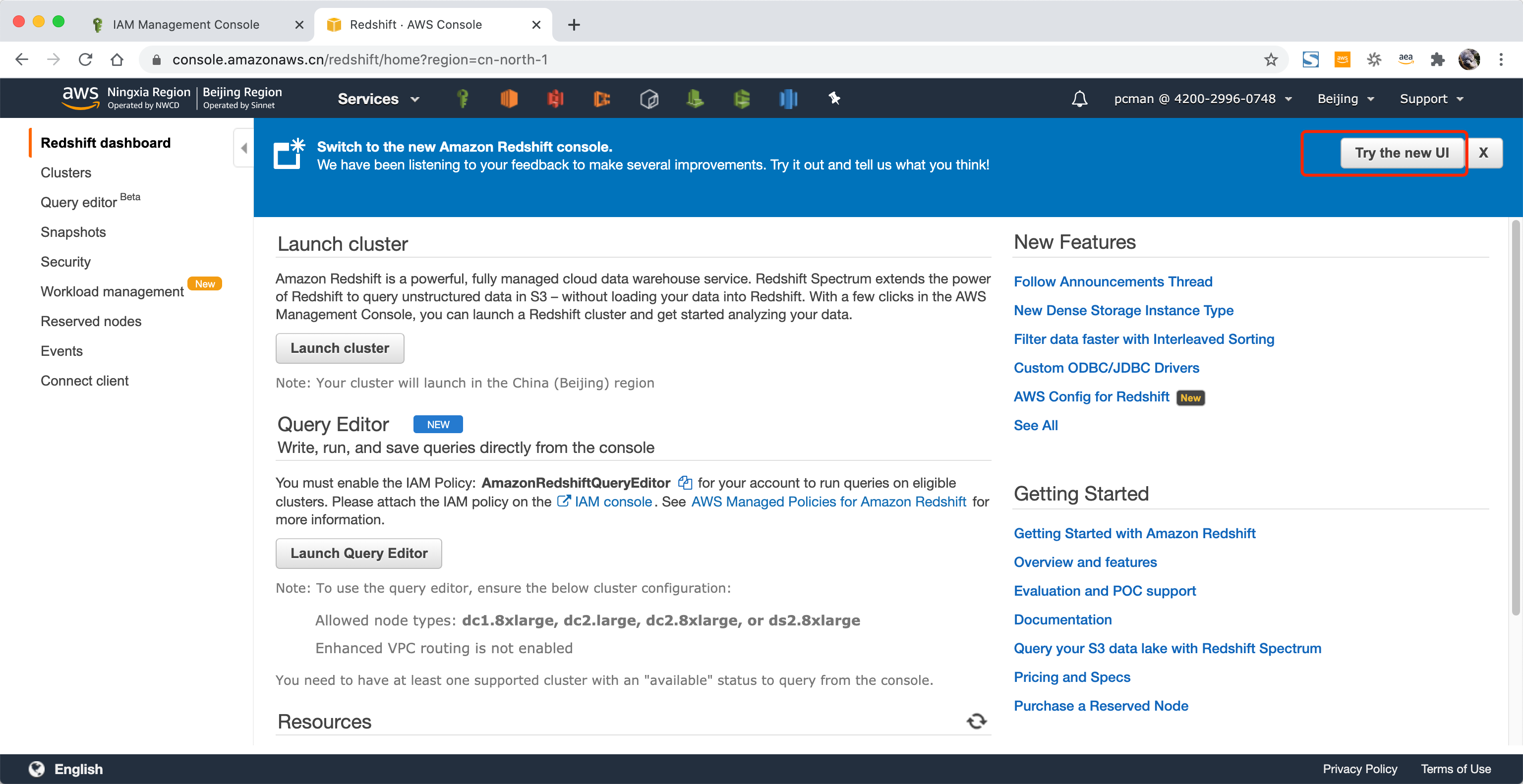
在新版UI界面上,点击Cluster,如下截图。
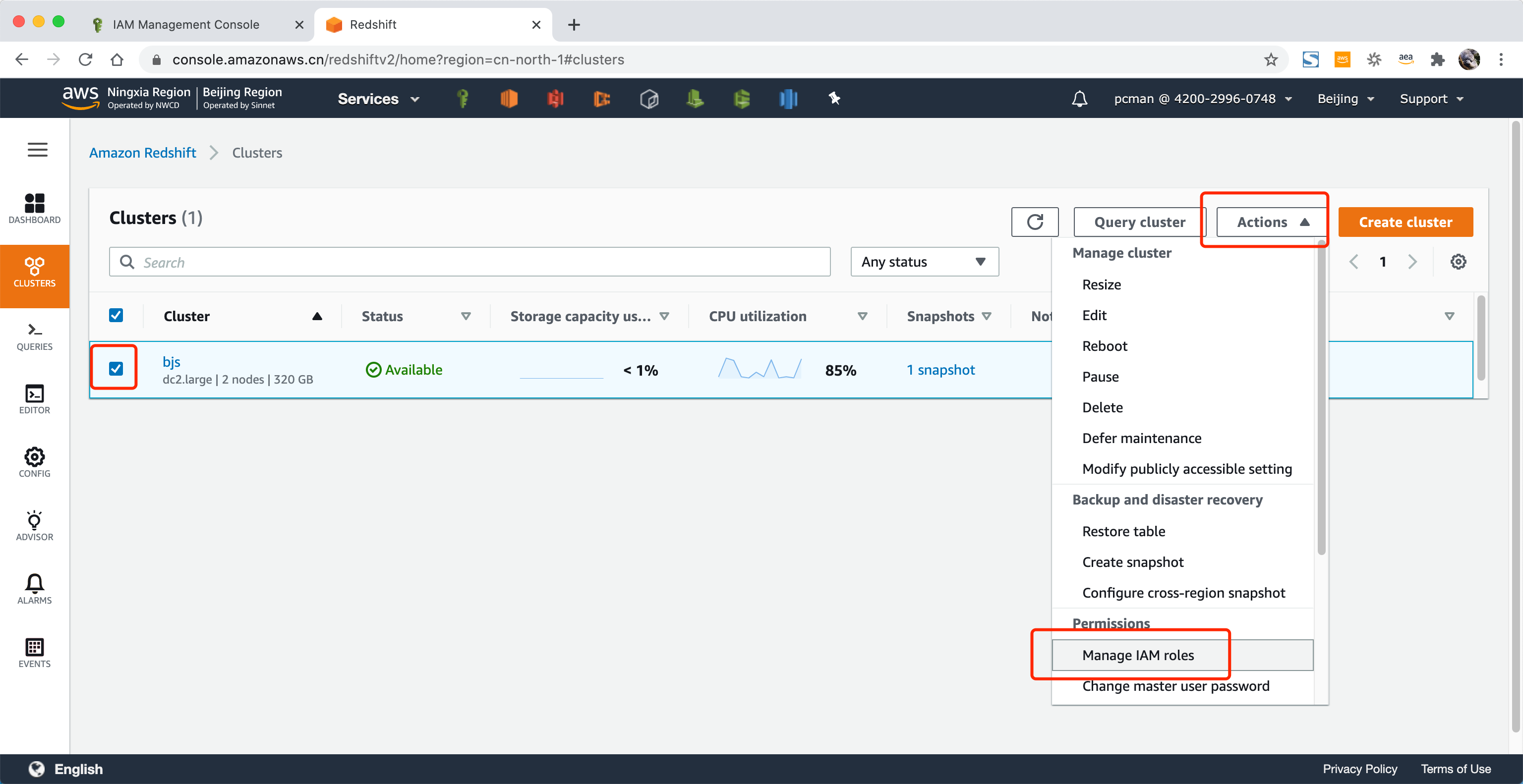
在数据库集群界面,选中现有集群,点击操作,从下拉框中选择 Manage IAM roles 。如下截图。
将角色添加到正在运行的集群后,点击保存。
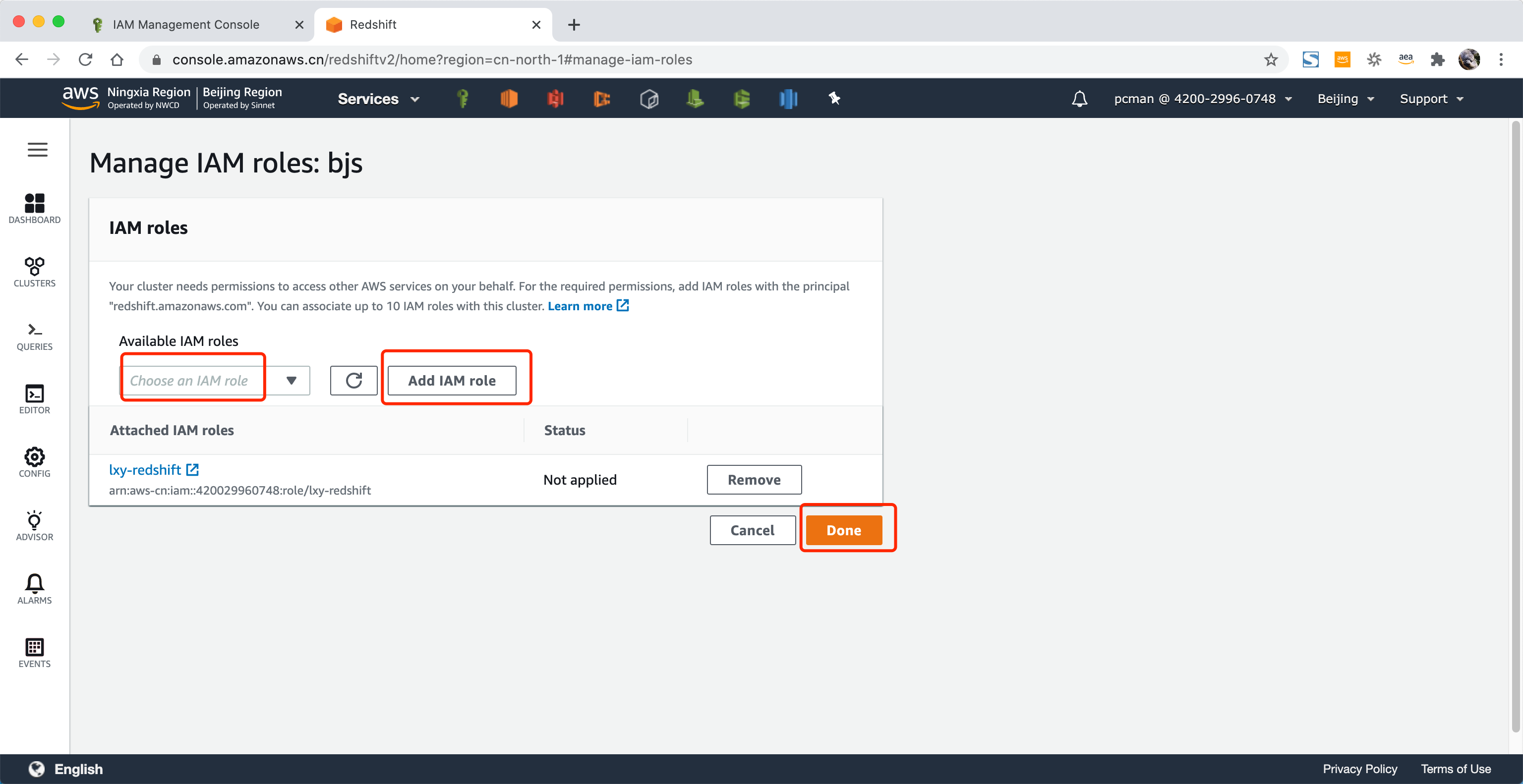
修改运行角色后,等待一段时间即可生效。不希望等待的话,也可以重启数据库。
至此角色操作完成。
二、关闭Lake Formation(仅AWS北京区域)
如果您使用的是AWS宁夏区域,由于截止2021年1月,宁夏区域没有提供Lake Formation服务,因此可以跳过这个章节。
在不使用数据湖管理界面的情况下,可以暂时关闭数据湖的权限管理,以免对IAM授权产生影响。
进入Lake Formation界面,找到左侧的Settings按钮,点击进入。如下截图。
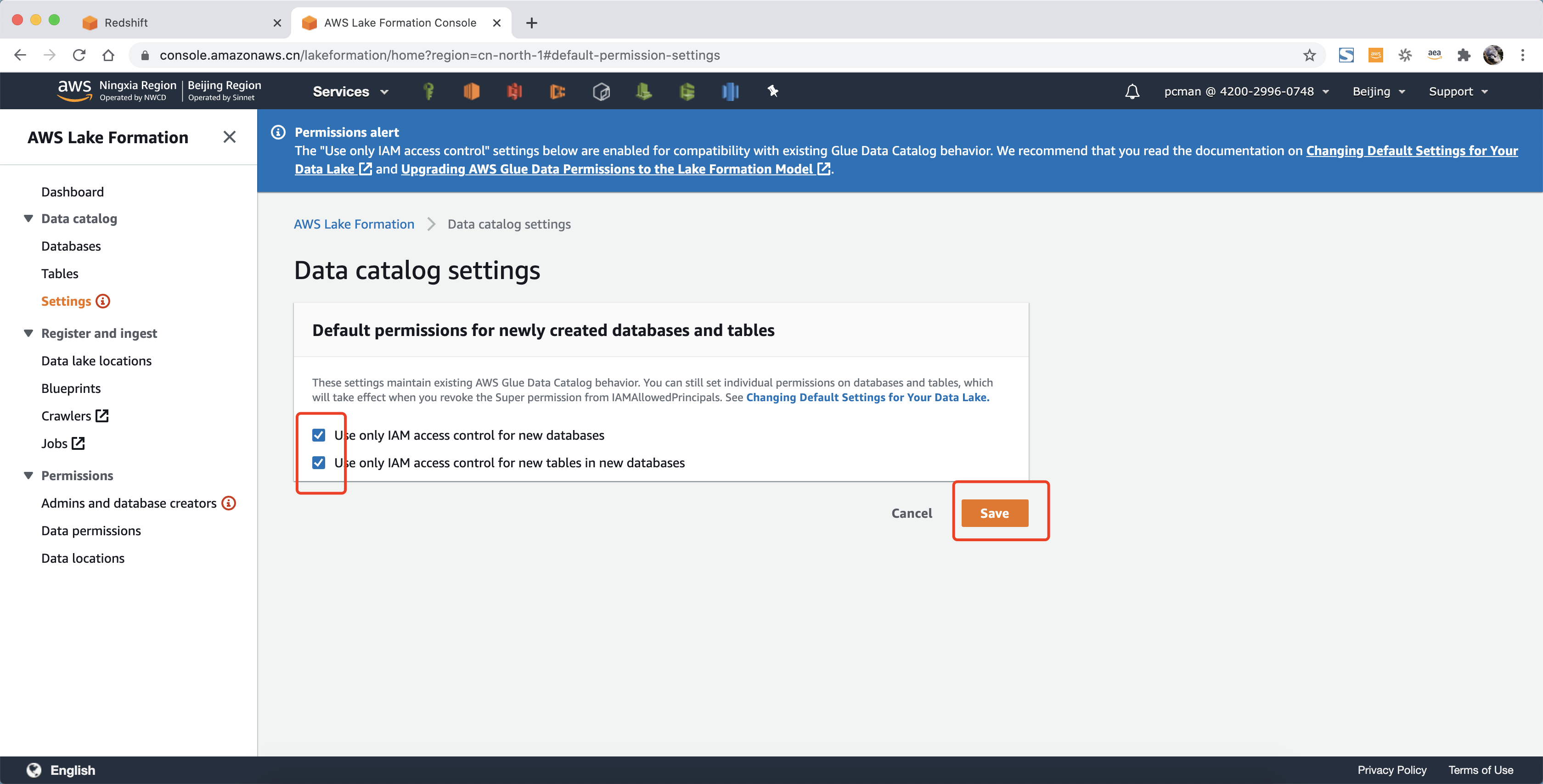
在设置界面中,选中两个选项,点击保存。如下截图。
三、准备S3数据
本测试共准备三个数据集:
s3://redshift-demo-bjs/spectrum/sales\_ts.000
s3://redshift-demo-bjs/spectrum2/allusers\_pipe.txt
s3://redshift-demo-bjs/spectrum3/allevents\_pipe.txt
请从如下网址下载测试数据集,下来后解压缩获得此三个文件,并上传到实验者自己的S3存储桶内,目录关系如上位置。
https://docs.aws.amazon.com/zh_cn/redshift/latest/gsg/samples/tickitdb.zip
有关示例数据库的说明请参考这里。
https://docs.aws.amazon.com/zh_cn/redshift/latest/dg/c_sampledb.html
四、创建外部表和查询
1、创建Schema
执行如下命令,创建schema。请替换其中的IAM Role为前文创建的角色。
create external schema spectrum\_schema from data catalog
database 'spectrum\_db'
iam\_role 'arn:aws-cn:iam::420029960748:role/lxy-redshift'
create external database if not exists;
创建成功返回如下。
Schema spectrum created
Execution time: 0.26s
2、创建表
执行如下命令,请替换S3路径为本实验中的真实路径。注意Spectrum加载外部表时候,支持分区,因此只提供整个目录的路径即可,不需要指定文件名。
create external table spectrum.sales(
salesid integer,
listid integer,
sellerid integer,
buyerid integer,
eventid integer,
dateid smallint,
qtysold smallint,
pricepaid decimal(8,2),
commission decimal(8,2),
saletime timestamp)
row format delimited
fields terminated by '\\t'
stored as textfile
location 's3://redshift-demo-bjs/spectrum/';
create external table spectrum.users(
userid integer,
username char(8),
firstname varchar(30),
lastname varchar(30),
city varchar(30),
state char(2),
email varchar(100),
phone char(14),
likesports boolean,
liketheatre boolean,
likeconcerts boolean,
likejazz boolean,
likeclassical boolean,
likeopera boolean,
likerock boolean,
likevegas boolean,
likebroadway boolean,
likemusicals boolean)
row format delimited
fields terminated by '|'
stored as textfile
location 's3://redshift-demo-bjs/spectrum2/';
创建成功的话,返回信息如下:
Table spectrum.sales created
Execution time: 0.31s
Statement 1 of 2 finished
Table spectrum.users created
Execution time: 0.27s
Statement 2 of 2 finished
Script execution finished
Total script execution time: 0.58s
创建表完成。
3、查询数据
select count(\*) from spectrum.sales;
select count(\*) from spectrum.users;
select \* from spectrum.sales limit 10;
select \* from spectrum.users limit 10;
查询结果是sales表共172456行,users表49990行。查询成功。
五、联合查询
1、将一张新的表导入Redshift
在联合查询中,将较大的事实表保存在S3上,将较小的维度表加载到Redshift本机。请替换其中的IAM role和S3地址为实际实验中对应的地址
create table event(
eventid integer not null distkey,
venueid smallint not null,
catid smallint not null,
dateid smallint not null sortkey,
eventname varchar(200),
starttime timestamp);
copy event from 's3://redshift-demo-bjs/spectrum3/allevents\_pipe.txt'
iam\_role 'arn:aws-cn:iam::420029960748:role/lxy-redshift'
delimiter '|' timeformat 'YYYY-MM-DD HH:MI:SS';
数据加载完成返回结果如下。
Warnings:
Load into table 'event' completed, 8798 record(s) loaded successfully.
0 rows affected
COPY executed successfully
Execution time: 40.01s
2、同时查询Redshift和S3上的表
执行如下命令。将外部表 SPECTRUM.SALES 与本地表 EVENT 联接以查找排名前十的活动的销量总额。
select top 10 spectrum.sales.eventid, sum(spectrum.sales.pricepaid) from spectrum.sales, event
where spectrum.sales.eventid = event.eventid
and spectrum.sales.pricepaid > 30
group by spectrum.sales.eventid
order by 2 desc;
联合查询结果如下。
eventid | sum
--------+---------
289 | 51846.00
7895 | 51049.00
1602 | 50301.00
851 | 49956.00
7315 | 49823.00
6471 | 47997.00
2118 | 47863.00
984 | 46780.00
7851 | 46661.00
5638 | 46280.00
3、查看SQL Explain解释
执行如下命令可以看到 S3 Seq Scan、S3 HashAggregate 和 S3 Query Scan 步骤。
explain
select top 10 spectrum.sales.eventid, sum(spectrum.sales.pricepaid)
from spectrum.sales, event
where spectrum.sales.eventid = event.eventid
and spectrum.sales.pricepaid > 30
group by spectrum.sales.eventid
order by 2 desc;
返回结果如下。
XN Limit (cost=1001197430001.12..1001197430001.14 rows=10 width=31)
-> XN Merge (cost=1001197430001.12..1001197430001.62 rows=200 width=31)
Merge Key: sum(sales.derived\_col2)
-> XN Network (cost=1001197430001.12..1001197430001.62 rows=200 width=31)
Send to leader
-> XN Sort (cost=1001197430001.12..1001197430001.62 rows=200 width=31)
Sort Key: sum(sales.derived\_col2)
-> XN HashAggregate (cost=1197429992.97..1197429993.47 rows=200 width=31)
-> XN Hash Join DS\_BCAST\_INNER (cost=141666776.64..1197429646.75 rows=69244 width=31)
Hash Cond: ("outer".derived\_col1 = "inner".eventid)
-> XN S3 Query Scan sales (cost=141666666.67..141667336.84 rows=67000 width=31)
-> S3 HashAggregate (cost=141666666.67..141666666.84 rows=67000 width=16)
-> S3 Seq Scan spectrum.sales location:"s3://redshift-demo-bjs/spectrum" format:TEXT (cost=0.00..125000000.00 rows=3333333334 width=16)
Filter: (pricepaid > 30.00)
-> XN Hash (cost=87.98..87.98 rows=8798 width=4)
-> XN Seq Scan on event (cost=0.00..87.98 rows=8798 width=4)
至此实验完成。
六、删库跑路
执行如下命令删除实验环境。
DROP TABLE spectrum.sales CASCADE;
DROP TABLE spectrum.users CASCADE;
DROP TABLE event CASCADE;
DROP SCHEMA spectrum CASCADE;
至此实验完成。
最后修改于 2021-02-12